数据库管理命令介绍
命令概述
GBase 8s 数据库服务器允许使用命令行命令执行管理任务。除了oninit、onlog、oncheck三个命令外,其他命令,必须在数据库服务器处于online状态下使用。
在使用命令时,请不要使用 UNIX™ 命令 CTRL-C 向进程发送中断信号,因为这可能引起错误。
获取当前命令的版本信息
许多 GBase 8s 命令都允许使用 -V 和 -version 选项来获取版本信息。这两选项主要用于调试。

-V 选项显示了软件版本号和序列号。
-version 选项扩展 -V 选项,显示关于创建操作系统、创建号码以及创建日期的更多信息。
-V** 和 **-version** 选项不能与任何其他命令选项一起使用
例1:onstat -version 命令可能显示以下输出。
onstat -version
Program: onstat
Build Version: 8.8
Build Host: connla
Build OS: SunOS 5.6
Build Number: 009
Build Date: Sat Nov 20 03:38:27 CDT 2011
GLS Version: glslib-4.50.xC2
例2:onstat -V 命令返回结果格式为:产品名称+主版本号+_+版本级别+_+版本号+专用版本代号及版次+_+迭代序号(送测序号)+补充版本标识+_+6位哈希ID。可能显示以下信息:
GBase8sV8.8_AEE_3.0.0G5_1P20200918_1fc8fc
查看 GBase 8s 上详细错误消息
使用 finderr 命令来查看 GBase 8s 上错误消息的额外信息。在 UNIX™ 和 Linux™ 平台上,该信息通过命令行显示。
语法

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| error_number | 错误消息编号为其提供额外信息 | 在 UNIX 或 Linux 上: 如果错误消息不包含减号 (-) 或加号 (+),并且存在正版本和负版本的错误消息,那么将会显示负版本的消息。若错误消息的编号前带一个加号则显示的信息是正的错误消息。 |
用法
在消息日志中输出的错误消息内容包含了消息的编号及其简要概述。使用 finderr 消息编号命令来查找错误和可能的用户操作的原因的更详细的描述,以纠正或防止错误。
示例
下面的命令显示了在 UNIX 或 Linux 平台上有关错误消息 -201 的信息:
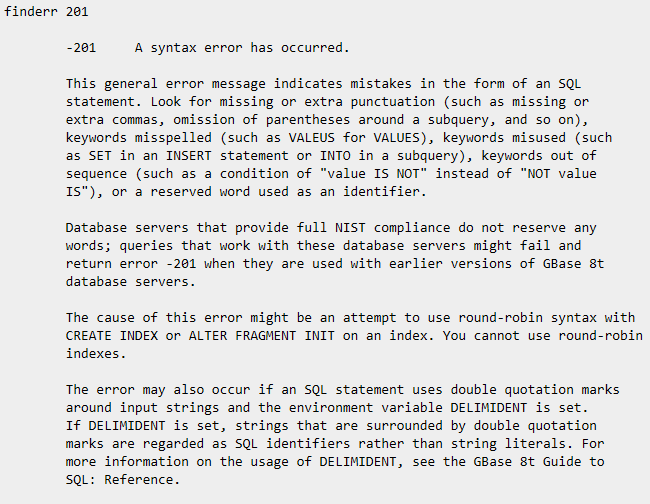
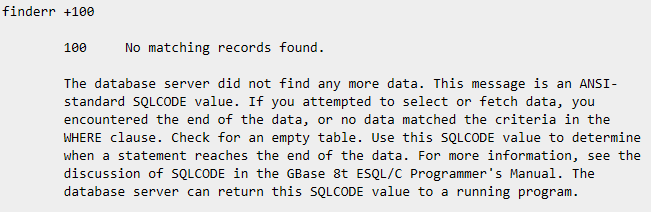
下列命令显示了有关错误消息 100 ,即对应于 SQLCODE 值为 100 的信息:
GBase 8s 配置文件定制
使用 genoncfg 命令可加快根据您主机环境以及数据库服务器的预期用途对缺省的 GBase 8s 配置文件 (onconfig.std) 进行定制的过程。
语法

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| input_file | 包含参数设置的输入文件的名称 | |
| gbs_home | 您希望配置的 GBase 8s 安装路径 | 如果 GBASEDBTDIR 环境变量已被设置,那么您可以省略安装路径。如果已设置 GBASEDBTDIR 变量并且在命令行进入了该安装路径,那么命令会在此命令行的路径下运行 。 |
| -h | 有关 genoncfg 命令的帮助信息 | |
| -V | 显示短的版本信息并退出命令行命令 | |
| -version | 显示扩展的版本信息并退出命令行命令 |
用法
在运行此命令前,请以 root 或用户 gbasedbt 的身份登入主机。
在您成功运行 genoncfg 命令之前,必须在输入文件中设置参数对主机环境是可用的。对于所有的环境,disk 参数在输入文件中是必不可少的。也可以在输入文件中输入指令。这些指令对于运行命令时是非必要的,但是它们在一些场景下会有帮助。
该命令不会读取和修改任何已存在的配置文件。如有您在主机环境里有一个预先存在的 ONCONFIG 文件,当您运行该命令,此文件中的参数值不会发生改变。因此,在将参数应用在数据库服务器实例中之前,可以查看这些建议的参数设置。
使用 genoncfg 命令的步骤:
- 用文本编辑器创建包含 genoncfg 命令处理过程的参数值的输入文件。
- 用输入文件运行该命令。该配置文件(名为onconfig)将生成并保存在该工作目录下。
- 可选: 重命名生成的配置文件。
- 如果您想要使用已生成的配置文件运行数据库服务器实例,将该文件复制到 $GBASEDBTDIR/etc。
genoncfg 命令的输入文件
使用输入文件来指定以下关于数据库服务器实例的信息:
- 预计联机事务处理系统(OLTP)的连接数
- 预计决策支持系统(DSS)的连接数
- 磁盘空间
- CPU 初始化
- 网络服务连接设置
- 恢复时间
输入文件是一个 ASCII 文本文件。对参数的排列顺序没有要求。 以下是一个输入文件的样本:
cpus 1
memory 1024 m
connection name demo_on onsoctcp 9088
servernum 1
oltp_connections 10
dss_connections 2
disk /opt/gbs_server/data/storage/online_root 0 k 300 m
directive one_crit
directive debug
表. genoncfg 命令的输入文件的参数
| 元素 | 描述 |
|---|---|
| connection | 服务器连接参数: ● 名称 或者 别名 ,取决于连接器的功能。是特定的服务器名(还是替代服务器名)。 ● 连接器的名称 ● 连接服务器的类型(在配置文集中等同于 NETTYPE ) ● 服务的端口号 例如:connection name demo_on onsoctcp 9088 |
| cpus | 分配给实例的中央处理单元数(CPUs) 例如: cpus 1 |
| directive | genoncfg 命令可以使用的指令。 ● one_crit: 配置数据库服务器只在 root dbspace 上存储物理日志、逻辑日志和数据。 ● debug: 实时显示有关主机环境和配置文件上操作的信息。 例如: directive one_crit 此信息在解决数据库服务器配置问题时会有帮助。 一种场景是,调试指令可以导致节省时间。在该场景下,通过读取显示的信息注意到该命令在创建您不想要或不起作用的 onconfig 文件。您停止该命令(尽管它仍在运行),调整输入文件的设置,然后用修改完成后的输入文件返回命令。 |
| disk | 为实例设置的磁盘存储空间: ● root dbspace 的位置 ● 偏移量的大小,以兆字节(m)或千字节(k)为单位 ● root dbspace 的大小,以兆字节(m)或千字节(k )为单位 例如: UNIX™: /opt/gbs_server/data/storage/rootdbs 重要: 如果进入 root dbspace 工作实例的路径下,该实例将被覆盖,并不能使用。 |
| dss_connections | 预估该实例的决策处理系统(DSS)的连接数。例如:一个查询客户端或其它可以获得商业智能设置结果的应用程序可以是一个 DSS 连接。例如: dss_connections 2 |
| memory | 实例的内存量(兆字节)。例如 : memory 1024 m |
| oltp_connections | 估计该实例的联机处理系统(OLTP)的连接数。典型的是,在实例中修改数据库状态的应用程序时一个 OLTP 连接。例如: oltp_connections 10 |
| rto_server_restart | 指定在重启 GBase 8s 后,进入在线或静态模式,数据库服务器不得不从一个问题中恢复的时间量(以秒为单位)。该值可设置为 0 以禁用配置参数,或设置为在 60 和 1800 中的任意一值以启用参数并指示秒数。 例如: rto_server_restart 100 指定恢复时间对象为 100 秒 |
| servernum | 数据库服务器实例的唯一 ID 例如: servernum 1 |
磁盘结构检查及修复
oncheck 命令概览
使用 oncheck 命令来检查特定磁盘结构的不一致性,修复不一致的索引结构并显示有关磁盘结构的信息。
oncheck 命令的限制
差异修复限制
oncheck 命令如果检测到下面类型的磁盘结构,会进行检查并修复。检测到其他结构的不一致性,只会发送消息警告通知不会进行修复。
- 分区页统计信息
- 位图页
- 分区 blobpage
- blobspace blobpage
- 索引
- sbspace 页
- sbspace 元数据分区
分类空间大小限制
oncheck 命令检查索引时,oncheck 命令需要分类空间。所需的分类空间量与创建索引所需要的空间一样大。如果收到 “no free disk space for sort ” 的错误信息,须重新预估所需的临时空间量。
锁占用限制
以下操作期间,oncheck 命令在表上放置了共享锁,因此其他用户在检查完成之前将不能执行更新、插入或删除:
- 检查数据时
- 检查索引(使用 -ci 、-cI 、-pk 、-pK 、-pl 或 -pL)且表使用页锁定时
- 当指定带有 -ci 、-cI 、-pk 、-pK 、-pl 或 -pL 的 -x 选项且表使用行锁定时
如果表不使用页锁定,那么使用 oncheck -ci 、-cI 、-pk 、 -pK 、 -pl 或 -pL 选项检查索引时,数据库服务器不在表上放置共享锁。当做索引检查过程中表上没有共享锁时,其他用户可以在检查过程中更新行。
如果在索引检查过程中未在使用行锁的表上放置共享锁,那么 oncheck 命令无法进行准确的索引检查。要绝对确保完全的索引检查,可以用 -x 选项执行 oncheck 。使用 -x 选项, oncheck 在表上放置共享锁,这样其他用户就不能再检查完成之前执行更新、插入或删除。
高可用限制
若在高可用集群的辅助服务器上运行 oncheck 命令,它将返回不可靠的结果。
系统目录表限制
在检查系统目录表时,oncheck 命令在这些表上放置共享锁。在执行时,它在表上放置互斥锁。
oncheck 命令选项及其功能概览
| 对象 | 检查 | SQL 管理 API 命令字符串 | 修复 | 显示 |
|---|---|---|---|---|
| Blobspace 简单大对象 | -pB | |||
| 系统目录表 | -cc | -pc | ||
| 数据行,没有简单大对象或智能大对象 | -cd | -pd | ||
| 数据行,简单大对象但没有智能大对象 | -cD | -pD | ||
| 带有用户定义存取方法的表 | -cd, -cD | CHECK DATA | ||
| Chunks 和 extents | -ce | CHECK EXTENTS | -pe | |
| 索引(键值) | -ci, -cix | -ci -y -pk -y, -pkx -y | -pk | |
| 索引(键加 rowid) | -cI, -cIx | -cI -y -pK -y, -pKx -y | -pK | |
| 带有用户定义存取方法的索引 | -ci, -cI | |||
| 索引(叶键值) | -pl -y, -plx -y | -pl | ||
| 索引(叶键加 rowid) | -pL -y, -pLx -y | -pL | ||
| 页(按表或分片) | -pp | |||
| 页(按 chunk) | -pP | |||
| Root 保留页 | -cr, -cR | -pr, -pR | ||
| 智能大对象的元数据 | -cs, -cS | -ps, -pS | ||
| 空间使用量(按表或分片) | CHECK PARTITION PRINT PARTITION | -pt | ||
| 空间使用量(按表,带索引) | -pT |
oncheck 命令语法概览
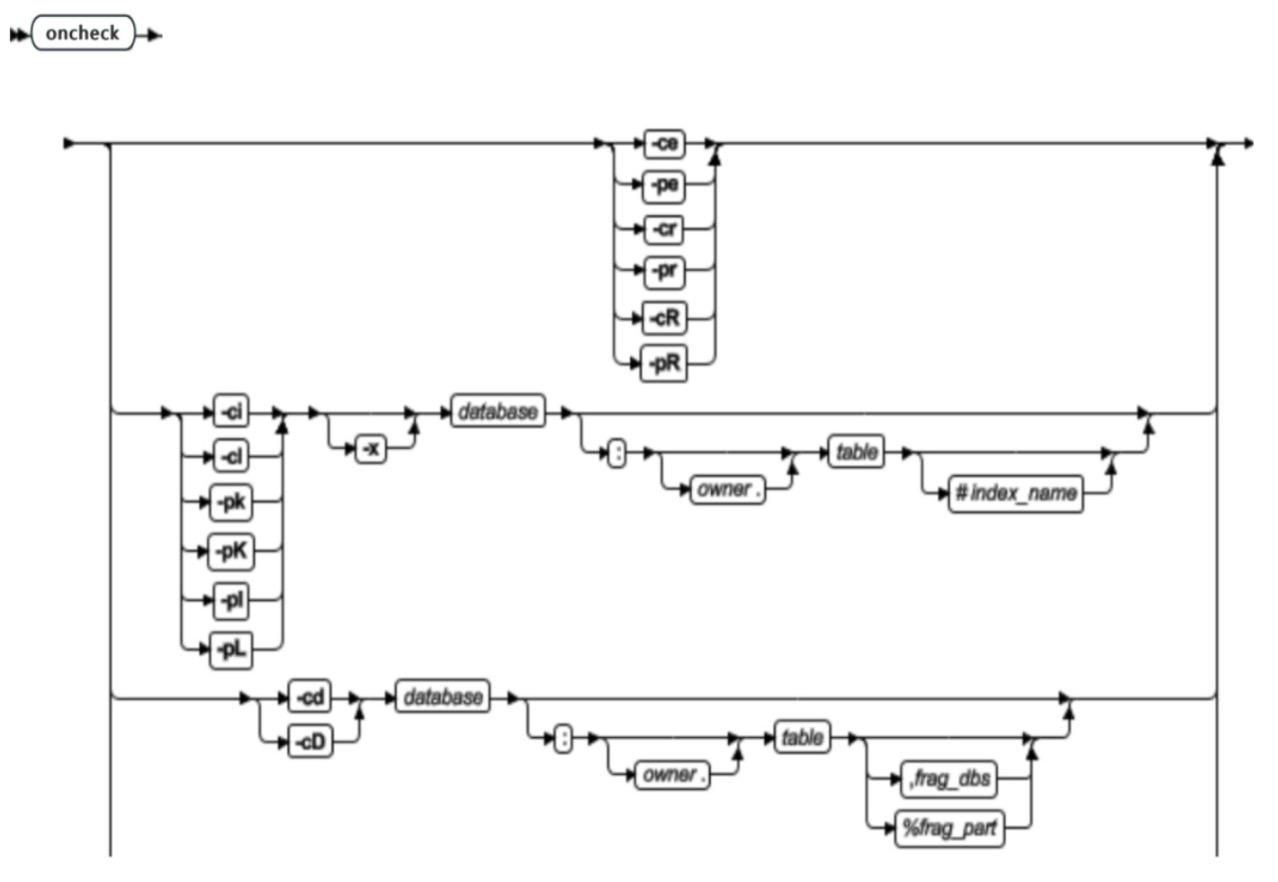
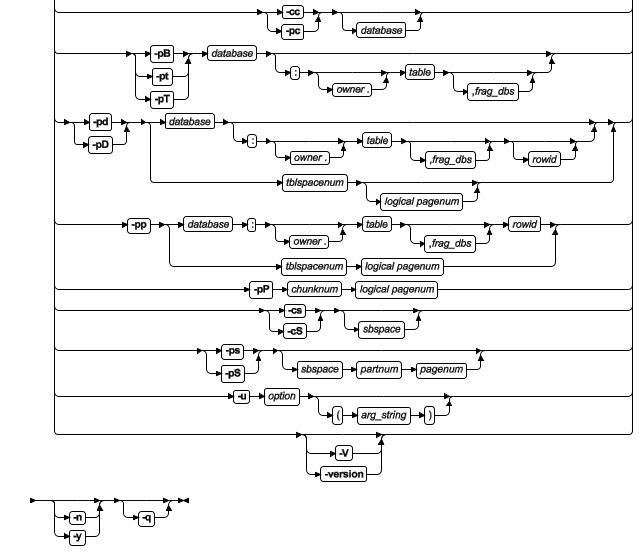
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -cc | 检查系统目录表中的指定数据库 | 请参阅 oncheck -cc 和 -pc:检查系统目录表 |
| -cd | 从指定数据库、表或分片的 tblspace 中读取除简单大对象之外的所有页,并检查每页的一致性 还检查使用用户定义存取方法的表 | 不检查简单智能大对象 请参阅 oncheck -cd 和 oncheck -cD :检查页 |
| -cD | 与 -cd 相同,但还读取每个 blobpage 的头并检查其一致性 | 检查简单大对象但不检查智能大对象 请参阅 oncheck -cd 和 oncheck -cD :检查页 |
| -ce | 检查每个可用 chunk 列表和相应的可用空间以及每个 tblspace extent 。还检查智能大对象 extent 和 sbspace 元数据 | oncheck 进程验证磁盘上的 extents 与描述它们的当前控制信息相对应。 请参阅 oncheck -ce 、-pe: 检查可用 chunk 列表。 |
| -ci | 检查键值顺序和与指定表相关联的所有索引的水平和垂直节点链接的一致性 还检查使用用户定义存取方法的索引 | 请参阅 oncheck -ci 和 -cI: 检查索引节点链接 |
| -cI | 与 -ci 相同,但是还检查索引中 rowid 关联的键值是否与行中的键值相同 | 请参阅 oncheck -ci 和 -cI: 检查索引节点链接 |
| -cr | 检查每个 root dbspace 保留页是否存在几种情况 | 请参阅 oncheck -cr 和 -cR: 检查保留页 |
| -cR | 检查 root dbspace 保留页、物理日志页和逻辑日志页 | 请参阅 oncheck -cr 和 -cR: 检查保留页 |
| -cs | 检查 sbspace 的智能大对象和 sbspace 元数据 | 请参阅 oncheck -cs 、-cS 、-ps、-pS: 检查并显示 sbspace |
| -cS | 检查 sbspace 的智能大对象和 sbspace 元数据以及 extent | 请参阅 oncheck -cs 、-cS 、-ps、-pS: 检查并显示 sbspace |
| sbspace | 指示可选的 sbspace 名称 如果未提供,那么检查所有的 sbspace | 无 |
| -n | 指示不应执行任何索引修复,即使检测到错误也是如此 | 与索引修复选项(-ci 、-cI 、-pk 、-pK 、-pl 和 -pL)一起使用 |
| -pB | 显示描述指定表中 blobspace blobpage 的平均充满度的统计信息 | 这些统计信息衡量数据库或表中的个别简单大对象的存储效率。如果未指定表或分片,那么显示整个数据库的统计信息。 请参阅 oncheck -pB:显示 blobspace 统计信息。 |
| -pc | 与 -cc 相同,但在检查系统目录表时还显示系统目录信息,包括每个表的 extent 使用情况 | 无 |
| -pd | 以十六进制格式显示行 | 请参阅 oncheck -pd 和 pD :以十六进制格式显示行 |
| -pD | 显示十六进制格式的行和存储在 tblspace 中的简单大对象值或存储在sbspace sbpage 中的智能大对象和存储在 blobspace blobpage 中简单大对象的头信息 | 请参阅 oncheck -pd 和 pD :以十六进制格式显示行 |
| -pe | 与 -ce 相同,但在检查可用 chunk 列表、相应可用空间以及每个 tblspace extent 时还显示 chunk 和 tblspace extent 信息 | 请参阅 oncheck -ce 、-pe: 检查可用 chunk 列表 |
| -pk | 与 -ci 相同,但在检查它们时还显示指定表上所有所有的键值 | 请参阅 oncheck -pk 、-pK 、-pl 、-pL:显示索引信息 |
| -pK | 与 -cI 相同,但在检查它们时还显示键值和 rowid | 请参阅 oncheck -pk 、-pK 、-pl 、-pL:显示索引信息 |
| -pl | 与 -ci 相同,但还显示键值。只检查叶节点索引页 | 请参阅 oncheck -pk 、-pK 、-pl 、-pL:显示索引信息 |
| -pL | 与 -cI 相同,但还只显示叶节点索引页的键值和 rowid | 请参阅 oncheck -pk 、-pK 、-pl 、-pL:显示索引信息 |
| -pp | 显示逻辑页的内容 | 请参阅 oncheck -pp 和 -pP: 显示逻辑页的内容 |
| -pP | 与 -pp 相同,但是需要 输入 chunk 编号和逻辑页号或内部 rowid | 请参阅 oncheck -pp 和 -pP: 显示逻辑页的内容 |
| -pr | 与 -cr 相同,但在检查保留页时还显示保留页信息 | 请参阅 oncheck -pr 和 pR:显示保留页信息 |
| -pR | 与 -cR 相同,但还显示保留页、物理日志页和逻辑日志页的信息 | 请参阅 oncheck -pr 和 pR:显示保留页信息 |
| -ps | 检查和显示 sbspace 的智能大对象和 sbspace 元数据 | 请参阅 oncheck -cs 、-cS 、-ps、-pS: 检查并显示 sbspace |
| -pS | 检查并显示简单大对象和sbspace 元数据。列出个别智能大对象的 extent 和头信息 | 请参阅 oncheck -cs 、-cS 、-ps、-pS: 检查并显示 sbspace |
| -pt | 显示表或分片的 tblspace 信息 | 请参阅 oncheck -pt 和 -pT:显示表或分片的 tblspaces |
| -pT | 与 -pt 相同,但还显示特定于索引的信息和按页类型排列的页分配信息(对于 dbspace) | 请参阅 oncheck -pt 和 -pT:显示表或分片的 tblspaces |
| -q | 不显示所有检查和确认信息 | 无 |
| -x | 检查和打印索引时在表上放置共享锁 | 与 -ci、-cI、-pk、-pK、-pl 或 -pL 选项一起使用。 请参阅 使用 -x 开启锁,获取全部信息 |
| -y | 当检测到错误时修复索引 | 无 |
| -V | 显示软件版本号及序列号 | |
| -version | 显示构件版本、主机、操作系统、编号、日期及 GLS 版本 | |
| chunknum | 指定用于指示特定 chunk 的十进制值 | 值必须是大于 0 的无符号整数。Chunk 必须存在。 执行 -pe 选项可了解哪些 chunk 号是与特定的 dbspace、blobspace 或 sbspace 相关联的 |
| database | 指定要检查其一致性的数据库名称 | |
| db1 | 指定包含想要检查的数据类型的本地数据库 | 可以选择使用格式 db1@server1 指定本地数据库服务器名 |
| db2 | 指定包含想要检查的数据类型的远程数据库 | 可以选择使用格式 db2@server2 指定远程数据库服务器名 |
| frag_dbs | 指定包含想要检查其一致性的分片的 dbspace 名称 | Dbspace 必须存在并包含要检查一致性的分片。 |
| index_name | 指定想要检查其一致性的索引名称 | 指定的表和数据库必须存在索引。 |
| logical pagenum | 指定用于指示 tblspace 中特定页的整数值 | 值必须是在 0 和 16,777,215(包括 0 和 16,777,215 )之间的无符号整数。值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
| object | 指定想要检查的 DataBlade 、强制转型、运算符类、用户定义的数据类型或 UDR 的名称 | 如果未指定对象名称,那么数据库服务器将比较相同类型(具有相同的名称和所有者)的所有对象 |
| owner | 指定表的所有者 | 必须指定并的当前所有者。 |
| pagenum | 标识要检查和显示的 sbspace 元数据部分的页号 | 无 |
| partnum | 标识要检查和显示的 sbspace 元数据分区 | 无 |
| rowid | 标识要显示其内容的行的 rowid 。Rowid 是作为 oncheck -pD 输出的一部分进行显示的 | 值必须是 0 和 4,277,659,295(包括 0 和 4,277,659,295)之间的无符号整数。值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
| sbspace | 指定想要检查其一致性的 sbspace 的名称 | 无 |
| server | 指定数据库服务器名称 | 如果省略数据库服务器名称,那么 oncheck 使用 sqlhosts 文件中的 dbservername 条目指定的名称 |
| table | 指定想要检查其一致性的表的名称 | 执行命令时,表应存在。语法必须符合 Table Name 段; |
| tblspacenum | 标识要显示其内容的 tblspace | 值必须是 0 和 208,666,624(包括 0 和 208,666,624)之间的无符号整数。值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
oncheck -cc 和 -pc:检查系统目录表
语法:
-cc 选项检查指定数据库的所有系统目录表。如果未指定数据库,那么它检查所有数据库的所有系统目录表。
-pc 选项对系统目录表执行相同的检查,并且还会显示系统目录信息。包括每张表的物理地址、所使用的锁定类型、行大小、键的数量、extent 使用情况、已分配和使用的页数量、tblspace 分区号以及索引的使用情况。
在执行 oncheck -cc 或 oncheck -pc 之前,请执行 SQL 语句 UPDATE STATISTICS ,以确保发生准确的检查。为检查表,oncheck 将每个系统目录表与其在 tblspace 中的相应条目作比较。
oncheck -cd 和 oncheck -cD :检查页
使用 oncheck -cd 和 oncheck -cD 命令检查每页的一致性。使用 oncheck -cd -y 或 oncheck -cD -y 命令修复其不一致性。
语法:

oncheck -cd 选项从指定数据库、表、分片或多个分片(碎片)的 tblspace 中读取 blobpages 和 sbpages 除外的所有页,并检查每页的一致性。它对照这些页检查位图页中的条目,以验证映射。
oncheck -cD 选项执行与 oncheck -cd 相同的检查,并检查每个 blobpage 头的一致性。oncheck -cD 选项不会比较开始时间戳记(存储在头中)和结束时间戳记(存储在 blobpage 的末尾)。使用 oncheck -cD -y 选项可以清除 blobspace 中孤立的简单大对象(它可能在跨几个日志文件执行回滚后产生)。
如果数据库包含分片表,但您未指定分片,那么 oncheck -cd 选项检查表中的所有分片。如果您未指定表,该选项会检查数据库中的所有表。通过进行比较, oncheck -pd 选项将显示指定页的十六进制转储,但不检查一致性。
对于 oncheck -cd 和 oncheck -cD 选项,oncheck 命令在检查表的索引时锁定每张表。要修复这些页,请使用 oncheck -cd -y 或 oncheck -cD -y。
如果表在相同的 dbspace 中的多个分区上分片,那么 oncheck -cd 和 oncheck -cD 命令将显示分区名称。以下示例显示了在相同 dbspace 中的多个分区上分片的表的典型输出:

当使用 oncheck -cd 或 oncheck -cD 命令,您可以指定 frag_dbs 或 %frag_dbs 选项,但不能都指定它们:
- 当使用 frag_dbs 选项时,该命令检查 frag_dbs dbspace 中所有的分片。
- 当使用 %frag_dbs 选项时,如果 PARTITION 语法在分片或表创建时被使用,该命令只检查名为 frag_part 的分片。
尽管可以用 PARTITION 语法分片索引,但是不能限制只对一个分片或分区检查索引。例如,您可以指示 oncheck -cDI my_db:my_tab,data_dbs1 or oncheck -cDI my_db:my_tab%part1 。该检查的 D(数据)部分根据规范限制,然而 I(索引) 检查不会被限制。
例子
以下示例检查 catalog 表中的数据行,包括简单大对象和智能大对象:
oncheck -cD superstores_demo:catalog
如果您指定一个单独的分片,oncheck 命令只单独显示该分片的头。对于分片表来说,每个头显示了每个分片。
TBLspace data check for stores_demo:tab1
Table fragment in DBspace db1
消息
如果 oncheck 命令未找到不一致性,那么对于其检查的每张表,它显示类似于下行的头:
TBLSPACE data check for stores_demo:customer
如果 oncheck 命令找到不一致性,它显示类似如下的消息:
BAD PAGE 2:28: pg_addr 2:28 != bp-> bf_pagenum 2:69
物理地址 2:28 表示 chunk 号 2 的页 28 。
如果使用 DataBlade 模块提供的存取方法的索引无法找到存取方法,那么您接收到以下信息:
-9845 Access method access_method_name does not exist in database.
Ensure that the DataBlade installation was successful.
参考
要监视 blobspace blobpage ,请参阅 oncheck -pB:显示 blobspace 统计信息。
oncheck -ce 、-pe: 检查可用 chunk 列表
语法:
-ce 选项检查每个可用 chunk 列表和相应的可用空间及每个 tblspace extent 。 oncheck 进程验证磁盘上 extent 与描述它们的当前控制信息相对应。
-pe 选项执行相同的检查,并还在检查过程中显示 chunk 和 tblspace extent 信息。-ce 和 -pe 选项还检查 sbspace chunk 中的 blobspace 、智能大对象 extent 以及用户数据和元数据信息。
oncheck -ci 和 -cI: 检查索引节点链接
使用 oncheck -ci 和 oncheck -cI 命令检查键值顺序和与指定表相关联的所有索引的水平和垂直节点链接的一致性。
oncheck -cI 选项还检查索引中与 rowid 相关联的键值是否与该行中的键值相同。-cI 选项不在功能检索上交叉检查数据。
语法:

如果未指定索引,该选项检查所有的索引。如果未指定表,该选项检查数据库中所有的表。
相同的 -ci 修复选项可以与 -cI 一起使用。如果 oncheck -ci 或 oncheck -cI 检测到不一致,那么它会提示您确认修复该问题索引。如果指定了 -y (是)选项,那么自动修复索引。如果指定了 -n (否)选项,那么报告该问题,但不进行修复;不出现任何提示。
如果 oncheck 未找到不一致性,那么以下消息出现:
validating indexes......
该消息显示 oncheck 正在检查的索引的名称。
使用 oncheck 重新构建索引可能会消耗很长时间。如果使用 SQL 语句 DROP INDEX 和 CREATE INDEX 删除并重建索引,那么处理速度通常会较快。
以下示例检查 customer 表上的所有索引:
oncheck -cI -n stores_demo:customer
以下示例检查 customer 表上的 zip_ix 索引:
oncheck -cI -n stores_demo:customer#zip_ix
如果索引在相同的 dbspace 中的多个分区上分片,那么 oncheck -ci 和 oncheck -cI 命令将显示分区名称。以下示例显示了在相同 dbspace 中的多个分区上分片的索引的典型输出:
Validating indexes for multipart:t1...
Index idx_t1
Index fragment partition part_1 in DBspace dbs1
Index fragment partition part_2 in DBspace dbs1
Index fragment partition part_3 in DBspace dbs1
Index fragment partition part_4 in DBspace dbs1
Index fragment partition part_5 in DBspace dbs1
缺省情况下,当您使用 oncheck -ci 或 oncheck -cI 选项检查索引时,数据库服务器不在表上放置共享锁,除非该表使用页锁定。要绝对确保完全的索引检查,可以在执行 oncheck -ci 或 oncheck -cI 时使用 -x 选项。使用 -x 选项, oncheck 在表上放置共享锁,这样其他用户就不能在检查完成之前执行更新、插入或删除。
当在外部索引上执行 oncheck 时,用户定义的存取方法负责检查和修复索引。如果使用用户定义存取方法的索引无法找到该存取方法,那么数据库服务器报告错误。oncheck 命令不会修复外部索引中的不一致。对于包含多种索引类型的表,不应使用 oncheck -cI。
oncheck 命令在检查索引时需要排序空间 。所需排序的空间量与需要创建索引的空间量大小相同。如果您收到该错误 "no free disk space for sort" ,您必须重新预估所需的临时空间量并使其可用。
如果正在使用 Verity Text Search DataBlade 模块,那么 -cI 选项执行索引合并而不是通常的操作。
oncheck -cr 和 -cR: 检查保留页
语法:
-cr 选项按以下方式检查每个 dbspace 保留页:
- 它对 PAGE_CONFIG 保留页验证 ONCONFIG 文件的内容。
- 它确保所有 chunk 都可以打开、chunk 不重叠以及 chunk 大小是正确的。
-cR 选项执行相同的检查和验证,并且它还会检查所有逻辑日志和物理日志页的一致性。-cr 选项是相当快的,因为它不检查日志文件页。
如果您已更改了配置参数值(通过 onparams 、onmonitor 、onspaces 或通过编辑配置文件),但还未重新初始化共享内存,那么 oncheck -cr 和 oncheck -cR 将会检测到不一致并返回错误消息。
如果 oncheck -cr 在执行之后不显示任何错误消息,那么您可以认为前述列表中的所有三项都已成功通过了检查。
oncheck -cs 、-cS 、-ps、-pS: 检查并显示 sbspace
语法:

-cs 选项检查 sbspace 。-ps 选项检查 sbspace 和 extents 。
-cS 选项验证并显示 sbspace 元数据。
-ps 选项检查 sbspace 和 extent 。如果未指定 sbspace 名,这些选项检查所有的 sbspace 。
-pS 选项验证并显示 sbspace 元数据,并且还列出智能大对象的 extent 和头信息。
如果未指定 sbspace 名,那么将会检查所有的 sbspace。以下示例检查和显示 test_sbspace 的元数据:
oncheck -ps test_sbspace
如果使用 -cs 或 -ps 选项将 rootdbs 指定为 sbspace 的名称,那么 oncheck 检查该 root dbspace 。
oncheck -pB:显示 blobspace 统计信息
语法:

-pB 选项显示描述指定表中 blobspace blobpage 的平均充满度的统计信息。这些统计信息衡量数据库或表中的个别简单大对象的存储效率。如果未指定表或分片,那么此选项显示整个数据库的统计信息。
oncheck -pd 和 pD :以十六进制格式显示行
语法:

-pd 将数据库、表、分片分区(碎片)和特定 rowid 或 tblspace 号以及逻辑页号作为输入。在每种情况中,-pd 会打印页头信息并显示数据库对象(数据库、表、分片、内部 rowid 或页号)的指定行,这些数据库对象是以十六进制和 ASCII 格式指定的。不执行任何一致性检查。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| database | 指定要检查其一致性的数据库名称 | |
| frag_dbs | 指定包含想要检查其一致性的分片的 dbspace 名称 | Dbspace 必须存在并包含要检查一致性的分片。 |
| frag_part | 指定分片分区 | 对于使用基于表达或循环法分发计划的分片表,您可以创建多个分区,这些分区在一个 dbspace 内集合了表或索引的页面。该分区称为分片分区或分片 |
| logical pagenum | 指定用于指示 tblspace 中的特定页的整数值 | 值可以表示为无符号整数或以 0x 标识符开始的十六进制数。 值必须是 0 和 16,777,215(包括 0 和 16,777,215)之间的无符号整数 |
| owner | 指定表的所有者 | 必须指定表的当前所有者。 |
| rowid | 标识要显示其内容的行的 rowid 。Rowid 是作为 oncheck -pD 输出的一部分进行显示的。 | 值必须是 0 和 4,277,659,295(包括 0 和 4,277,659,295)之间的无符号整数。 值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
| table | 指定想要检查其一致性的表的名称 | 执行命令时,表应存在。 语法必须符合 Table Name 段; |
| tblspacenum | 标识要显示其内容的 tblspace | 值必须是 0 和 208,666,624(包括 0 和 208,666,624)之间的无符号整数。 值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
如果指定了内部 rowid(以十六进制值表示),那么该 rowid 映射到特定的页,且打印该页中的所有行。
如果指定了逻辑页号(以十进制值表示),那么打印具有该逻辑页号的 tblspace 号的所有行。
如果指定了分片,那么打印该分片中的所有行,带有其 rowid 、转发指针和页类型。
如果指定了表,那么打印该表中的所有行,带有其 rowid 、转发指针和页类型。
如果指定了数据库,那么打印该数据库中所有表的所有行。将会打印存储在数据行中的 TEXT 和 BYTE 列描述符,但不会打印 TEXT 和 BYTE 数据本身。
-pD 选项打印与 -pd 相同的信息。此外,-pD 打印存储在 tblspace 中的 TEXT 和 BYTE 值和存储在 blobspace blobpage 中简单大对象的头信息。以下示例显示了 oncheck -pd 和 oncheck -pD 命令的不同选项:
oncheck -pd stores_demo:customer,frgmnt1
oncheck -pd stores_demo:customer
oncheck -pD stores_demo:customer 0x101
以下示例显示了 oncheck -pD 命令的部分输出:
oncheck -pD multipart:t1 :
TBLspace data check for multipart:t1
Table fragment partition part_1 in DBspace dbs1
page_type rowid length fwd_ptr
HOME 101 24 0
0: 0 0 0 a 47 48 49 20 20 20 20 20 20 20 20 20 ....GHI
16: 20 20 20 20 20 20 20 20
........
oncheck -pk 、-pK 、-pl 、-pL:显示索引信息
语法:

-pk 选项执行与 -ci 选项相同的检查,此外,在进行检查时,它还会显示所有指定的表中的所有索引的键值。
-pK 选项执行与 -cI 选项相同的检查,此外,在进行检查时,它还会显示键值和 rowid 。
-pl 选项执行与 -ci 选项相同的检查,并显示键值,但它只检查叶节点索引页。它忽略根和分支节点。
-pL 选项执行与 -cI 选项相同的检查,并显示键值和 rowid ,但它只检查叶节点索引页。它忽略根和分支节点。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| database | 指定要检查其一致性的数据库名称 | 语法必须符合 Identifier 段; |
| index_name | 指定要检查其一致性的索引名称 | 索引必须存在于特定数据库中的表上。 |
| owner | 指定表的所有者 | 必须指定表的当前所有者。 |
| table | 指定想要检查其一致性的表的名称 | 执行命令时,表应存在。 |
| -x | 检查和打印索引时在表上放置共享锁 | 更多完整信息,请参阅使用 -x 开启锁 |
如果任何一个 oncheck 选项检测到不一致,那么将会提示您确认修复问题索引。如果指定了 -y (是)选项,那么自动修复索引。如果指定了 -n (否)选项,那么报告该问题,但不进行修复;不出现任何提示。
以下示例显示有关 customer 表上所有索引的信息:
oncheck -pl -n stores_demo:customer
以下示例显示了有关索引 zip_ix 的信息,该索引时创建在 customer 表上的:
oncheck -pl -n stores_demo:customer#zip_ix
缺省情况下,当您使用 oncheck -pk 、-pK 、-pl 或 -pL 选项检查索引时,数据库服务器不在表上放置共享锁,除非该表使用页锁定。要绝对确保完全的索引检查,可以在执行 oncheck –pk 、oncheck -pK 、oncheck -pl 或 oncheck -pL 时使用 -x 选项。使用 -x 选项,oncheck 在表上放置共享锁,这样其他用户就不能在检查完成之前执行更新、删除或插入。有关使用 -x 选项的更多信息,请参阅使用 -x 开启锁 。
有关更多 oncheck -ci 的信息,请参阅 oncheck -ci 和 -cI: 检查索引节点链接。
oncheck -pp 和 -pP: 显示逻辑页的内容
语法:

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| database | 指定要检查其一致性的数据库名称 | 语法必须符合 Identifier 段; |
| chunknum | 指定用于指示特定 chunk 的十进制值 | 值必须是大于 0 的无符号整数。Chunk 必须存在 |
| frag_dbs | 指定包含想要检查其一致性的分片的 dbspace 名称 | Dbspace 必须存在并包含要检查一致性的分片。 |
| frag_part | 指定要检查分片的分区名。这会在在同一 dbspace 中创建的表上有多个分片的情况下有所帮助 | 对于使用基于表达或循环法分发计划的分片表,您可以创建多个分区,这些分区在一个 dbspace 内集合了表或索引的页面。该分区称为分片分区或分片 |
| logical pagenum | 指定用于指示 tblspace 中特定页的整数值 | 值可以表示为无符号整数或以 0x 标识符开始的十六进制数。值必须是 0 和 16,777,215(包括 0 和 16,777,215)之间的无符号整数 |
| owner | 指定表的所有者 | 必须指定表的当前所有者。 |
| rowid | 标识要显示其内容的行的 rowid 。Rowid 是作为 oncheck -pD 输出的一部分进行显示的。 | 值必须是 0 和 4,277,659,295(包括 0 和 4,277,659,295)之间的无符号整数。 值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
| table | 指定想要检查其一致性的表的名称 | 执行命令时,表应存在。 |
| tblspacenum | 标识要显示其内容的 tblspace | 值必须是 0 和 208,666,624(包括 0 和 208,666,624)之间的无符号整数。 值可以表示为无符号整数或以 0x 标识符开始的十六进制数 |
-pp 选项具有以下语法变化:
| 调用 | 解释 |
|---|---|
| oncheck -pp tblspc lpn | 使用 tblspace 号和逻辑页号,显示逻辑页的内容,也可以指定用于指示要打印页数的可选参数 |
| oncheck -pp tblspc lpn -h | 使用 tblspace 号和逻辑页号,只显示逻辑页头 |
| oncheck -pp database:table rowid | 使用数据库名、表名和 GBase 8s 内部 rowid ,显示逻辑页的内容。可以使用 oncheck -pD 命令获得该内部 rowid 。该内部 rowid 不是在用 CREATE TABLE tabname WITH ROWIDS 语句创建的表中指定的序列 rowid 。 |
该页内容以 ASCII 格式显示。显示还包括页上slot 表条目数。以下示例显示了oncheck -pp 命令的其他调用:
oncheck -pp stores_demo:orders 0x211 # database:owner.table, # fragment rowid
oncheck -pp stores_demo:gbasedbt.customer,frag_dbspce1 0x211
oncheck -pp 0x100000a 25 # specify the tblspace number and # logical page number
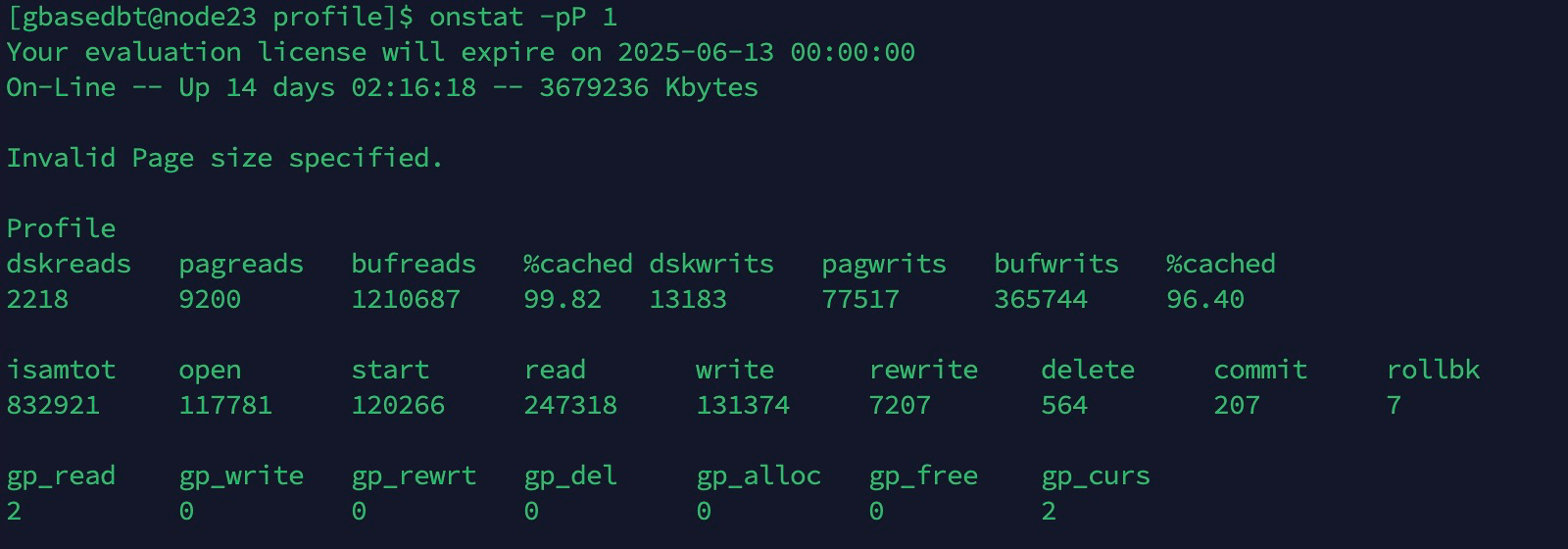
-pP 选项具有以下语法变化:
| 调用 | 解释 |
|---|---|
| oncheck -pP chunk# offset pages | 使用 chunk 号和偏移量,显示逻辑页的内容。也可以指定用于指示要打印页的可选参数 |
| oncheck -pP chunk# offset -h | 使用 chunk 号和偏移量,只显示逻辑页头 |
chunk 页的输出以十进制格式显示 start 和 length 字段。
以下示例显示使用了 onstat -pP 命令的典型输出:
oncheck -pr 和 pR:显示保留页信息
语法:
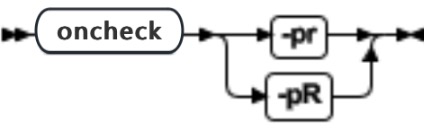
-pr 选项执行与 oncheck -cr 相同的检查并显示保留页的信息。
-pR 选项执行与 onchdeck -cR 相同的检查,显示保留页的信息,并显示有关逻辑日志和物理日志页的详细信息(标记活动物理日志页的开始和结束)。
如果已更改了配置参数信息(通过编辑配置文件),但还未重新初始化共享内存,那么 oncheck -pr 和 oncheck -pR 检测到不一致性并返回错误消息。
oncheck -pt 和 -pT:显示表或分片的 tblspaces
oncheck -pt 和 oncheck -pT 选项打印指定表或分片的 tblspace 报告。它们之间的仅有一个区别:oncheck -pT 打印更多的信息,包括一些特定索引的信息。
语法

表. oncheck -pt 和 oncheck -pT 命令的选项
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| database | 指定要检查其一致性的数据库名称 | 语法必须符合 Identifier 段; |
| frag_dbs | 指定包含想要检查其一致性的分片的 dbspace 名称 | Dbspace 必须存在并包含要检查一致性的分片。 语法必须符合 Identifier 段; |
| owner | 指定表的所有者 | 必须指定表的当前所有者。 语法必须符合 Owner Name 段; |
| table | 指定想要检查其一致性的表的名称 | 表应存在。 语法必须符合 Table Name 段; |
-pt 选项打印给定分片和数据库的 tblspace 报告。如果未指定表,该选项显示数据库中所有表的信息。该报告包含一般的分配信息,包括最大行大小、键数量、extent 数量、其大小、每个 extent 所分配和使用的页、当前的序列值以及表的创建日期。-pt 输出打印了 tblspace 页大小、逻辑页的页数(分配的页、使用的页和数据页)。
TBLspace Flags 字段显示了 tblspace 的配置信息,包括该 tblspace 是用于 Enterprise Replication 还是时间序列数据。
Extents 字段列出了该表中 tblspace tblspace 条目的物理地址和第一个 extent 的首页地址。该 extent 列表显示了每个事件中的逻辑页号和物理页号。
-pT 选项打印与 -pt 选项相同的信息。此外,-pT 选项还显示以下信息:
- 特定索引信息
- 按页类型分配页的信息(为 dbspace)
- 表或表分片中压缩的行数以及其压缩的百分比
如果表或分片行没有被压缩,那么“Compressed Data Summary”段落不会出现在输出中。
当您想要运行选项时请做出计划,因为它要完整扫描一个分区。
-pt 和 -pT 的输出包含已使用页数的列表。输出中显示的该字段的值绝不会减小,因为作为 extent 的一部分分配给 tblspace 的磁盘空间仍保持专用于该 extent,即使在通过删除行而释放空间之后也是如此。有关当前使用页数的准确计数,请参阅 -pT 选项提供的有关 tblspace 使用情况(按页类型组织)的详细信息。
oncheck -pt 输出样本
以下示例显示了 oncheck -pt 命令输出的样本:
TBLspace Report for testdb:tab1
Physical Address 2:10
Creation date 10/07/2004 17:01:16
TBLspace Flags 801 Page Locking
TBLspace use 4 bit bit-maps
Maximum row size 14
Number of special columns 0
Number of keys 0
Number of extents 1
Current serial value 1
Pagesize (k) 4
First extent size 4
Next extent size 4
Number of pages allocated 340
Number of pages used 337
Number of data pages 336
Number of rows 75806
Partition partnum 2097154
Partition lockid 2097154
Extents
Logical Page Physical Page Size Physical Pages
0 2:106 340 680
oncheck -pT 输出示例
以下示例显示了oncheck -pT 命令的输出:
TBLspace Report for database_a:nilesh.table_1a
Table fragment partition dbspace1 in DBspace dbspace1
Physical Address 3:5
Creation date 03/21/2009 15:35:47
TBLspace Flags 8000901 Page Locking
TBLspace contains VARCHARS
TBLspace use 4 bit bit-maps
TBLspace is compressed
Maximum row size 80
Number of special columns 1
Number of keys 0
Number of extents 1
Current serial value 100001
Current SERIAL8 value 1
Current BIGSERIAL value 1
Current REFID value 1
Pagesize (k) 2
First extent size 8
Next extent size 8
Number of pages allocated 24
Number of pages used 22
Number of data pages 14
Number of rows 500
Partition partnum 3145730
Partition lockid 3145730
Extents
Logical Page Physical Page Size Physical Pages
0 3:16053 24 24
Type Pages Empty Semi-Full Full Very-Full
---------------- ---------- ------- ------------ ------ --------
Free 9
Bit-Map 1
Index 0
Data (Home) 14
Data (Remainder) 0 0 0 0 0
----------
Total Pages 24
Unused Space Summary
Unused data bytes in Home pages 1177
Unused data bytes in Remainder pages 0
Home Data Page Version Summary
Version Count
0 (current) 14
Compressed Data Summary
Number of compressed rows and percentage of compressed rows 500 100.00
使用-y 自动执行修复
-y 选项指示 oncheck 自动执行修复,如果不使用 -y 选项,那么 oncheck 会在遇到不一致性时提示您,并允许您请求修复。如下例所示:
oncheck -cd -y
oncheck -cD -y
oncheck -ci -y
oncheck -cI -y
使用-n 不执行修复
-n 选项指示 oncheck 不执行修复。
如下例所示:
oncheck -cd -n
oncheck -cD -n
oncheck -ci -n
oncheck -cI -n
使用 -x 开启锁
-x 选项可以附加到 -ci 、-cI 、-pk 、-pK 、-pl 和 -pL 选项后,用于在受影响的表上放置共享锁。在表被锁定时,其他用户在 oncheck 检查或打印索引时无法执行插入、更新和删除。对于带有行锁定的表,在未使用 -x 选项时,oncheck 只在该表上放置 IS (意向共享)锁,该锁阻止在检查过程中执行删除表或索引之类的操作。
例如:以下样本命令指示当 oncheck 验证键值顺序、验证水平链接和确保索引中没有节点出现两次时,它锁定 customer 表的索引:
oncheck -cix stores_demo:customer
当指定选项 -x 时,oncheck 锁定使用行锁定的表的索引。如果 oncheck 检测到页锁定方式,它显示警告消息并在表上放置共享锁。
退出时的返回码
oncheck 命令退出时返回以下代码。
GLS failures:-1
Invalid srial/key:2
Onconfig access error:2
Invalid onconfig settings:2
Invalid arguments to oncheck:2
Error connecting database server:1
Warning reported by oncheck:1
error detected by oncheck:2
no errors detected by oncheck:0
强制关闭数据库
oncleank命令概述
如果 onmode 命令无法关闭数据库服务器或您无法重启服务器,可使用 onclean 命令强制执行立即关闭数据库服务器。onclean 命令试图去清除共享内存和信号量并且停止数据库服务器的虚拟进程。
语法
在 UNIX™ 和 Linux™ 上,必须以用户 root 或 gbasedbt 的身份执行 onclean 命令。
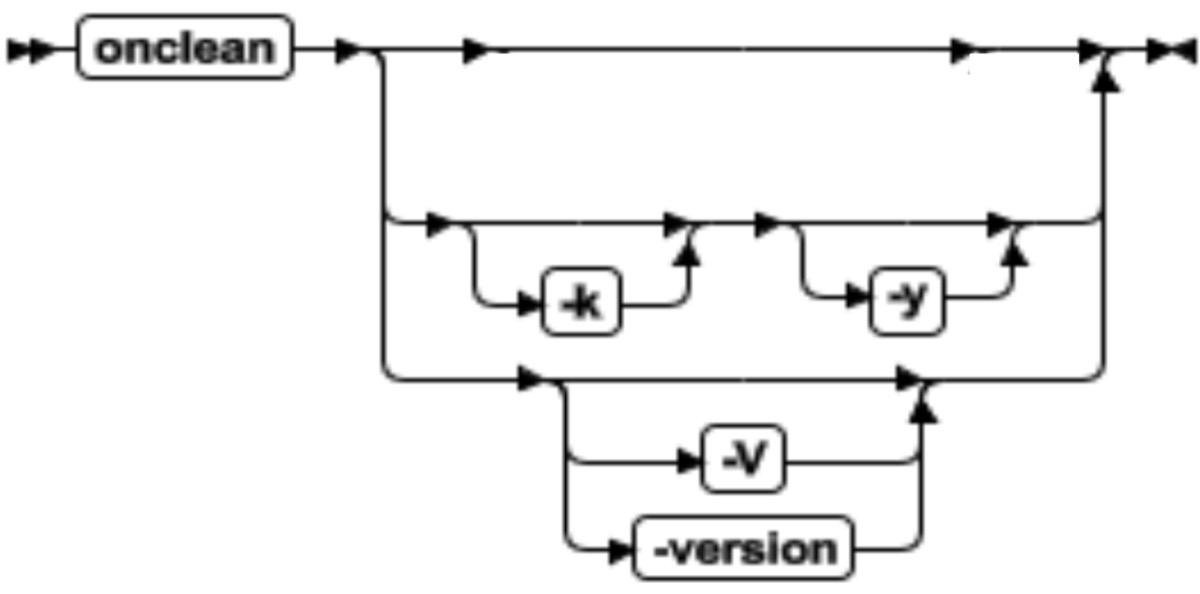
表 1. onclean 命令语法元素
| 元素 | 用途 |
|---|---|
| -k | 通过停止数据库服务器虚拟进程和尝试清除剩余信号量、共享内存片段(尽管它们仍在运行中)来关闭在线的服务器 |
| -V | 显示简短的版本信息 |
| -version | 显示所有的版本信息 |
| -y | 不提示输入确认 |
用法
只能在 onmode 命令无法关闭数据库服务器或您无法重启服务器的情况下,使用 onclean 命令去停止数据库服务器。数据库服务器可能由于不可控的方法关闭并且无法恢复,或者它被挂载。如果数据库服务器无法重启,它以前的实例却仍会连接共享内存片段。可以检查消息日志来查看数据库服务器是否正常关闭。onclean 命令停止所有的 oninit 进程并尝试移除所有的共享内存片段和在 $GBASEDBTDIR/etc/.conf.dbservername 文件中记录的信号量。
请谨慎使用 onclean 命令。当运行 onclean 时,任意挂起的事务和进程将无法完成并且用户会话会突然断线。然而,当数据库服务器重新启动后,它会回滚这些事务。
GBASEDBTDIR 环境变量必须设置可用的值以运行该命令。
onclean 命令在下例情况下使用:
- 如果不确定数据库服务器是否离线,可使用不带有选项的 onclean 命令。如果数据库服务器仍然在线,将会显示一个指导您运行 onclean -k 命令的消息。
- 如果数据库服务器离线,可使用 onclean 命令。
- 如果数据库服务器在线并且您确定要强制关闭它,可使用 onclean -k 命令。
使用 onclean 命令只能关闭本地数据库服务器;不能关闭远程数据库服务器。onclean 命令无法用于关闭一个整个高可用集群或远程数据库服务器。
onclean 命令在任何情况下可能不能清除数据库服务器使用的共享内存片段。onclean 命令会尝试只终止 oninit 进程。onclean 命令在以下情况下不会成功:
- 如果在运行 onclean 命令前有一非数据库服务器连接共享内存,onclean 命令将无法停止该进程以清除共享内存片段。
- 当应用程序或数据库服务器命令连接了网络端口时,onclean 可能无法保证一个干净的服务器启动。如果用户试图在同一网络端口初始化数据库服务器,数据库服务器会无法启动监听器进程并启动失败。onclean 命令无法停止释放网络端口的应用程序。
如果必要,您可以使用 onshutdown 脚本自动关闭数据库服务器,它会调用 onclean -ky 命令。
返回码
0
成功
1
因为以下其中一个问题失败:
- 错误的环境变量配置
- 运行 onclean 命令的权限错误
- 命令的语法错误
- 已损坏的信息
- 在在线的服务器上运行 onclean 命令时,没有使用 -k 选项
2
由于 onclean 使用的一个或多个操作系统的系统调用返回错误而失败。
onshutdown 脚本
可以使用 onshutdown 脚本自动关闭数据库服务器。该脚本尝试正常关闭服务器。如果该服务器在指定的时间后没有关闭,此脚本会强制关闭服务器。
onshutdown 脚本首先执行 onmode -ky 命令。在等待指定时间后,该脚本运行 onclean -ky 命令。
在 UNIX™ 和 Linux™ 上,您必须是用户 root 或 gbasedbt ,才能执行 onshutdown 脚本。
语法

表 1. onshutdown 脚本的语法元素
| 元素 | 用途 |
|---|---|
| timeout | 在 onmode -ky 命令执行之后和 onclean -ky 命令执行之前中间的等待时间(以秒为单位)。 必须是从 10 到 60 的正整数。缺省值是 30 秒 |
用法
在想强制关闭数据库服务器的情况下使用 onshutdown 脚本会比较合适。
请谨慎使用 onshutdown 脚本。如果此脚本需要运行 onclean -ky 命令,那么任意挂起的事务和进程将无法完成并且用户会话会突然断线。然而,当数据库服务器重新启动后,它会回滚这些事务。
GBASEDBTDIR、GBASEDBTDIR 环境变量必须设置可用的值以运行该命令。
您只能使用 onshutdown 脚本关闭本地数据库服务器;不能关闭远程数据库服务器。onshutdown 脚本无法用于关闭一个整个高可用集群或远程数据库服务器。
onshutdown 脚本有十秒时间段期间,在该期间内它可以被中止。
启动或关闭连接管理器
可以使用 oncmsm 命令启动或关闭连接管理器、加载新的配置文件到连接管理器以便修改连接管理器的设置或更新配置文件格式。
语法
UNIX 语法图:

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -c | 启动连接管理器或转换当前的连接管理器配置文件的格式 | |
| connection_manager_name | 指定连接管理器实例的名称 | |
| -k | 关闭连接管理器实例 | |
| -n | 指定转换配置文件的名称 | |
| new_configuration_file | 输出到 $GBASEDBTDIR/etc 目录下作为格式转换过程的一部分的文件名称 | |
| configuration_file | 位于 $GBASEDBTDIR/etc 目录下配置文件的名称 | 如果没有指定配置文件,连接管理器会试图加载到 $GBASEDBTDIR/etc/cmsm.cfg |
| -r | 在不停止和重启的连接管理器的情况下重新加载连接管理器 |
用法
从命令行运行 oncmsm 命令来初始化连接管理器。连接管理器运行时,您可以添加、更改或删除服务等级协议(SLAs),然后重新加载该配置文件。
仅 UNIX : 下列用户可以执行 oncmsm 命令:
- gbasedbt 用户
- root 用户,如果用户有连接到 sysadmin 数据库的权限
- DBSA 群组成员,如果用户有连接到 sysadmin 数据库的权限
示例 1: 启动连接管理器(UNIX)
以下示例中的连接管理器的 configuration_file_1 存在于 $GBASEDBTDIR/etc 目录。在已安装连接管理器的电脑上运行以下命令行,即可启动连接管理器:
oncmsm -c configuration_file_1
连接管理器启动。
示例 3: 终止连接管理器
在已安装连接管理器的电脑上运行以下命令行,即可终止连接管理器:
oncmsm -k connection_manager_3
名为 connection_manager_3 的连接管理器停止。
示例 4: 重新加载连接管理器
对于以下示例,名为 connection_manager_4 管理器的 $GBASEDBTDIR\etc\configuration_file_4会被更改。要更新该连接管理器的设置,在已安装 connection_manager_4 的电脑上执行以下命令:
oncmsm -r connection_manager_4
示例 5: 转换连接管理器配置文件成当前的格式
以下示例中名为 cmsm.cfg 的文件存储在$GBASEDBTDIR/etc 目录下。要启动该连接管理器,在已安装连接管理器的电脑上执行以下命令:
oncmsm -n configuration_file_5
oncmsm 命令转换 cmsm.cfg 成当前配置文件的格式。然后在 $GBASEDBTDIR/etc/ 目录下输出名为 configuration_file_5 的文件。
示例 6: 转换指定的连接管理器配置文件成当前的格式
以下示例中名为 configuration_file_4 的文件存储在 $GBASEDBTDIR/etc 目录下。要启动该连接管理器,在已安装连接管理器的电脑上执行以下命令:
oncmsm -c configuration_file_6 -n configuration_file_7
oncmsm 命令转换 configuration_file_6 成当前配置文件格式。然后在 $GBASEDBTDIR/etc/ 目录下输出名为 configuration_file_7 的文件。
比较两个 onconfig 文件
使用 onconfig_diff 命令比较两个 onconfig 文件。
语法

| 元素 | 用途 |
|---|---|
| -d | 对照当前的 onconfig 文件的设置来进行不同设置 |
| -c | 同另一个 onconfig 文件做比较 |
| -f filepath_1 | 指定要比较的第一个文件名称。除非该文件在 $GBASEDBTDIR/bin目录下,否则需提供该文件的路径 |
| -s filepath_2 | 指定要比较的第二个文件名称。除非该文件在 $GBASEDBTDIR/bin目录下,否则需提供该文件的路径 |
用法
可以执行 onconfig_diff 命令比较两个不同的 onconfig 文件。该 onconfig_diff 命令在 $GBASEDBTDIR/bin 里。
要比较的这两个文件必须在同一目录下。
以下为使用该命令的以下方法:
- 比较当前的 onconfig 和同版本的 onconfig。
- 比较当前的 onconfig 和新版本的 onconfig。
- 比较两个在不同服务器上的 onconfig 文件。
示例
在该示例中,onconfig.std 文件与 onconfig.production 文件作比较:
$ onconfig_diff -c -f onconfig.std -s onconfig.production
以下是该命令的输出:
==========================================
File 1: onconfig.std
File 2: onconfig.production
==========================================
Parameters Found in File 1, not in File 2
==========================================
FULL_DISK_INIT 0
NETTYPE ipcshm,1,50,CPU
NUMFDSERVERS 4
...
==============================================
Parameters Found in File 2, not in File 1
==============================================
JVPJAVAHOME $GBASEDBTDIR/extend/krakatoa/jre
...
==============================================
Parameters Found in both files, but different
==============================================
ROOTPATH
File 1: $GBASEDBTDIR/tmp/demo_on.rootdbs
File 2: /usr2/support/grantf/g1150fc8/rootdbs
LOGFILES
File 1: 6
File 2: 10
LOGSIZE
File 1: 10000
File 2: 3000
...
更改数据库的日志记录方式
使用 ondblog 命令可以更改一个或多个数据库的日志记录方式。ondblog 命令将其输出记录到 BAR_ACT_LOG 文件。
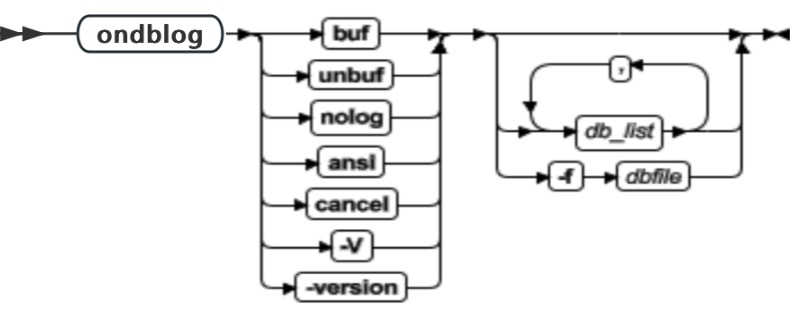
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| buf | 设置日志记录方式,以便事务信息在写入逻辑日志之前写入缓冲区中 | 无 |
| unbuf | 设置日志记录方式,以便数据在写入逻辑日志之前写入缓冲区中 | 无 |
| nolog | 设置日志记录方式,以便不对数据库事务进行日志记录 | 无 |
| ansi | 将数据库日志记录更改为服从 ANSI | 一旦创建或将数据库转换为 ANSI 方式,就不能再将它更改回其他任何日志记录方式 |
| cancel | 在发生下一次 0 级备份之前取消日志记录方式更改请求 | 无 |
| -f dbfile | 更改文本文件中列出的(每行一个)数据库日志记录状态。该文本文件的路径由 dbfile 给出 | 如果数据库列表很长或经常使用,那么此命令是有用的 |
| db_list | 给出要更改其日志记录状态的数据库的空间限定列表的名称 | 如果未指定任何内容,那么修改数据库服务器管理的所有数据库 |
说明及限制:
- 如果开启数据库的事务记录日志,那么在更改生效之前,您必须对数据库中包含数据的所有存储空间创建 0 级备份。
- 不能在高可用数据复制(HAC)辅助服务器、远程独立(RHAC)辅助服务器和共享磁盘(RHAC)辅助服务器上使用 ondblog 命令。
启动数据库服务
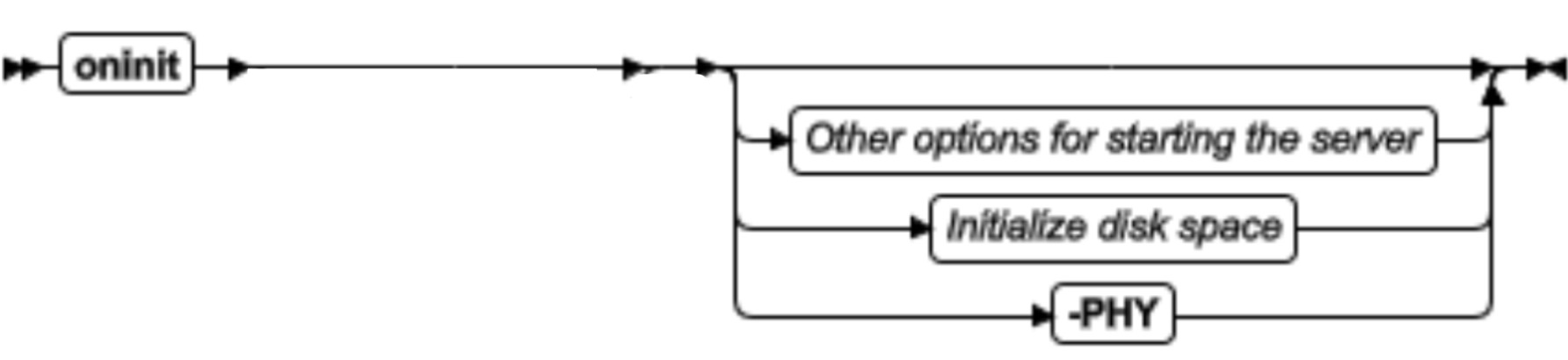
oninit 命令简介
oninit 命令用于启动数据库服务器。
语法
说明及限制
- 在 UNIX™ 和 Linux™ 上,必须作为用户 root 或 gbasedbt 登录才能执行 oninit。
- 确保 gbasedbt 用户是组 gbasedbt 的唯一成员。
- 配置后允许属于 DBSA 群组的用户执行 oninit 命令。
oninit 命令初始化磁盘空间
在系统上首次安装 GBase 8s 后,需要初始化数据库服务器的根 dbspace 的磁盘空间。该根 dbspace 由 ROOTPATH 配置参数指定。
如果以典型安装模式安装并且选择创建数据库服务器此时会自动初始化。否则,就须通过执行 oninit -i 命令进行磁盘空间初始化。
Initialize disk space
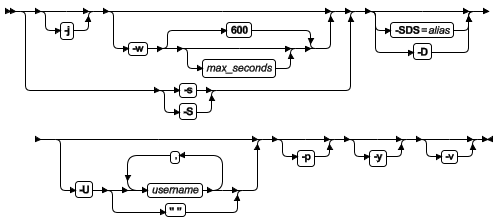
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -D | 用 Enterprise Replication 启动数据库服务器并禁用高可用集群复制 | |
| -i | 初始化根 dbspace 的磁盘空间,以至于它可以被数据库服务器用于执行启动操作。 | 磁盘空间需要被初始化一次,以对服务器准备的数据存储。 缺省情况下,为了防止数据丢失,不能重新初始化磁盘空间。要重新初始化现有的根 dbspace,必须设置 FULL_DISK_INIT 配置参数为 1 并执行 oninit -i 命令。 |
| -j | 在管理员模式下启动服务器 | |
| -p | 在不删除临时表的条件下启动数据库服务器 | 如果使用该选项,数据库服务器将加快启动,但是磁盘上临时表使用的空间不会被回收 |
| -PHY | 启动服务器最新的检查点。该 -PHY 选项用于告诉服务器只做物理恢复而不需要逻辑恢复。 | 该选项常用于启动辅助服务器。必须使用下列命令来连接辅助服务器到主服务器:onmode -d secondary onmode -d RSS 如果主服务器上最新的检查点没有在辅助服务器上运行,那么上述连接失败 |
| -s | 在静态模式下启动服务器 | 使用该选项时,必须关闭数据库服务器。 当数据库服务器处于静态模式,只有用户 gbasedbt 可以访问数据库服务器 |
| -S | 在静态模式下,以标准方式启动数据库;禁用 HAC | 当数据库服务器处于静态模式,只有用户 gbasedbt 可以访问数据库服务器 |
| -SDS= alias | 对于共享磁盘服务器,启动当前的服务器并用序列名指定主服务器 | 当主服务器和所有的 SSC 服务器都关闭时,使用 -SDS=alias 选项启动已设计的 SSC 服务器作为主服务器。The -SDS=alias 标志不能与 -i 标志结合。 |
| -U username | 指定哪些用户可以以管理员模式访问服务器当前的会话 | gbasedbt 用户和 DBSA 群组成员都是具有管理员模式的用户。 使用 oninit -U 命令或 onmode -j -U 命令指定的用户。 ● -U 选项可以重写 onconfig文件中 ADMIN_MODE_USERS 配置参数列出的任何用户。 ● 要使用 -U 选项添加在线模式用户时,用逗号分隔用户名 ,例如: Karin,Sarah,Andrew. ● 使用 -U " " 选项移除除 gbasedbt 用户和 DBSA 群组之外的所有在线模式用户:oninit -U " "。 |
| -v | 显示服务器启动时的详细信息 | |
| -w max_seconds | 启动数据库服务器,并等待指示成功或失败,直到该服务器在在线模式下完全启动或经过 max_seconds 指定的秒数 | 修改成任一整型值,等待时间的缺省值是 600 。 该选项在高可用集群的辅助服务器上不可用。 ● -w 选项强制服务器等待,直到启动完全成功,并表明服务器在在线模式下,通过返回到 shell 的提示符为 0的返回码 。 ● 如果服务器不在在线模式下的超时期限内,服务器将返回代码 1 返回到 shell 提示符,并在在线日志中写入一条警告消息。可以修改成任一整型值。在下列命令运行完毕之后,如果数据库在 60 秒内启动失败,会出现一个码为 1 的提示:oninit -w 60。 ● 要确定服务器无法启动的原因,请检查启动日志。 ● 在脚本里使用 oninit -w 命令,可用 onstat - (打印输出头)命令检查该服务器是否处于在线模式。 |
| -y | 防止验证提示 | -y 选项默认所有验证提示为是 |
- 在数据使用过程中也可以重新初始化磁盘空间。但重新初始化磁盘会损坏数据库已有的数据。
- 当重新初始化时,数据库服务器必须处于关闭状态。
- 重新初始化磁盘时不能重新初始化正在被数据库服务器使用的根 dbspace 。如果一个 0 页在根路径下(位于第一个 chunk 的第一页) ,磁盘初始化失败。可以通过设置 FULL_DISK_INIT 配置参数为 1 来运行现有的根 dbspace 的磁盘重新初始化。
- 数据库服务器只同意下列用户的请求:gbasedbt 用户、DBSA 群组成员、ADMIN_MODE_USERS 配置参数指定的用户。
- 要允许属于 DBSA 群组的用户,而不是用户 gbasedbt 执行 oninit 命令,必须以用户 root 身份登录并更改 $GBASEDBTDIR/bin 目录下 oninit 命令的权限,将 6754 改为 6755 。
用法
缺省情况下,oninit 命令显示在服务器启动过程中的验证提示。可以使用 -y 选项忽略这些验证提示。使用 -v 选项查看其详细信息。在UNIX 和 Linux , oninit 输出显示的是标准输出。
可以以不同操作方式启动服务器。缺省情况下,如果执行不带选项的 oninit 命令,那么该服务器以在线模式启动。当数据库服务器在在线模式下,所有被授权的用户都可访问此服务器。
oninit 命令的返回码
如果 oninit 命令发生错误,数据库服务器会返回错误消息及相应返回码值。下表包含了 oninit 命令的返回码、消息内容及其用户操作。
| 返回码 | 消息内容 | 用户操作 |
|---|---|---|
| 0 | 数据库服务器初始化成功 | 数据库服务器启动 |
| 1 | 服务器初始化失败,查看写入 stderr 或联机日志的错误消息 | 根据写入stderr 或联机日志的错误消息,采取合适的操作 |
| 87 | 数据库服务器检测到违反安全或某些系统必备组件丢失或不正确 | (仅 UNIX™ 上)检查用户和 gbasedbt 群组是否存在 。检查服务器配置文件 (onconfig) 和 sqlhosts 文件是否存在并有正确的权限。检查环境变量 GBASEDBTDIR、ONCONFIG 和 SQLHOSTS 的值是否有效并且其长度不能超过 255 字符数。检查环境变量 GBASEDBTDIR 是否指定了绝对路径并且没有空格、tab 、新行或其它不正确的字符。检查 $GBASEDBTDIR 目录下相关角色分离的子目录(例如:aaodir 和 dbssodir)是否有正确的所有权。运行 onsecurity 命令去诊断并修复这些问题。 |
| 170 | 数据库服务器初始化 dataskip 结构失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 172 | 数据库服务器初始化监听器线程失败 | 释放一些系统资源,检查数据库服务器启动时要启动的监听器线程编号的配置参数值,并尝试再次重启数据库服务器 |
| 173 | 数据库服务器初始化数据复制失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 174 | 数据库服务器启动快速恢复线程失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 175 | 数据库服务器初始化 root dbspace 失败 | 检查服务器配置文件(onconfig)上的 root dbspace 的相关参数,并确保 root dbspace 的路径有效 |
| 176 | 共享磁盘辅助服务器初始化失败 | 检查 sqlhosts 文件中的条目(UNIX™),确保使用的关于主服务器的 dbdervername 配置值是正确的。检查服务器配置文件(onconfig)中 SDS_PAGING 配置参数的值是正确的。释放一些系统资源并尝试再次重启数据库服务器 |
| 177 | 数据库服务器启动 main_loop 线程失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 178 | 数据库服务器初始化页转换所需的内存失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 179 | 数据库服务器无法启动 CPU VPs | 释放系统上的物理内存并尝试重启数据库服务器 |
| 180 | 数据库服务器无法启动 ADM VP | 释放系统上的物理内存并尝试重启数据库服务器 |
| 181 | 数据库服务器初始化 kernel AIO 失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 182 | 数据库服务器无法启动 IO VPs | 释放系统上的物理内存并尝试重启数据库服务器 |
| 183 | 数据库服务器初始化异步 I/O 操作所需的内存失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 184 | 数据库服务器初始化并行数据库查询(PDQ)所需的内存失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 185 | 数据库服务器初始化各种 SQL 缓存失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 186 | 数据库初始化全球语言支持(GLS)组件失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 187 | 数据库服务器初始化关联服务设施(ASF)组件失败 | 检查 sqlhosts 文件上的条目 |
| 188 | 数据库服务器无法启动 CRYPTO VP | 释放系统上的物理内存并尝试重启数据库服务器 |
| 189 | 数据库服务器初始化报警程序失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 190 | 数据库服务器初始化审计组件失败 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 193 | 数据库服务器创建守护进程失败 | (仅 UNIX ) 释放一些系统资源并尝试重启数据库服务器 |
| 194 | 数据库服务器重定向文件描述符失败 | (仅 UNIX )检查 /dev/null 设备的可用性并尝试重启数据库服务器 |
| 195 | 数据库服务器初始化当前使用的目录失败 | 检查数据库服务器初始化的当前工作目录的是否可用 |
| 196 | 数据库服务器初始化 /dev/null 设备失败 | (仅 AIX®)检查 /dev/null 设备的可用性 |
| 197 | 数据库服务器查找要初始化该数据库服务器的用户的密码的信息失败 | 验证用户密码是否有效 |
| 198 | 数据库服务器设置资源限制失败 | (仅 UNIX™ )验证,如果必要,增加主机上限制进程的资源 |
| 200 | 数据库服务器在初始化的过程中没有足够的内存分配结构 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 206 | 数据库服务器无法分配一个常驻分段 | 检查服务器配置文件(onconfig)上的 BUFFERPOOL 和 LOCKS 配置参数的值,确保它们可以装载在主机的可用内存上 |
| 207 | 数据库服务器初始化共享内存和磁盘空间失败 | 释放系统上的物理内存,检查该数据库服务器上所有 chunk 的有效性并且尝试再次重启数据库服务器 |
| 208 | 数据库服务器从共享内存分配结构失败 | 释放一些系统资源并尝试重启数据库服务器 |
| 209 | 数据库服务器在共享内存创建的过程中遭遇致命错误 | 释放系统上的物理内存并尝试重启数据库服务器 |
| 210 | 数据库服务器驻留的分段请求的内存量超出了最大允许范围 | 通过降低 BUFFERPOOL 和 LOCKS 配置参数的值,减少驻留分段的大小 |
| 220 | 数据库服务器无法读取审计配置文件 | 检查该神经配置文件(adtcfg)存在并有效 |
| 221 | 数据库服务器无法检测到 DUMPDIR 的缺省目录。它通常是 $GBASEDBTDIR/tmp 目录 | 创建 $GBASEDBTDIR/tmp 目录如果该目录不存在 |
| 224 | 数据库服务器检测到服务器配置文件中 HA_ALIAS 配置参数值错误 | 修正服务器配置文件(onconfig)中 HA_ALIAS 配置参数的值 |
| 226 | 数据库服务器无法在 sqlhosts 文件内的 DBSERVERNAME 配置参数中找到条目或者 sqlhosts 文件的内容无效 | 检查 sqlhosts 文件中的条目 |
| 227 | 错误的序列号 | 重新安装数据库服务器 |
| 233 | 数据库服务器初始化插入式身份验证模块失败(PAM) | 检查系统上的 PAM 库的配置 |
| 235 | 数据库服务器检测到服务器配置文件中现有配置参数有误 | 根据错误检查服务器配置文件(onconfig) |
| 236 | 数据库服务器检测到其尝试限制 GBase 8s 使用版的允许值有误 | 检查服务器配置文件(onconfig)中 SDS_ENABLE 配置参数值为 1 。检查用 oninit -SDS 命令指定的服务器名称与 HA_ALIAS配置参数或 sqlhosts 文件中的 dbservername 条目相匹配。检查使用的共享磁盘是否为现有的共享磁盘群集的一部分 |
| 237 | 数据库服务器无法找到服务器配置文件 | 确保该服务器配置文件存在并有效 |
| 240 | 向数据库服务器发出不正确的命令行选项 | 启动时纠正向数据库服务器发出不正确的命令行选项 |
| 248 | 数据库服务器创建 GBase 8s 加载程序域文件失败 | (仅 AIX)检查 /var/adm/ifx_loader_domain 文件是否存在 |
| 249 | 数据库服务器动态加载 PAM 库失败 | 数据库服务器的 PAM 库不可用。安装 PAM 库 |
| 250 | 数据库服务器动态加载 ELF 库失败 | 数据库服务器的 ELF 库不可用。安装 libelf 包 |
| 255 | 在服务器初始化过程中出现内部错误。查看写入 stderr 或联机消息日志的错误消息 | 根据写入 stderr 或联机消息日志的错误消息采取适当的操作 |
查看逻辑日志文件内容
onlog 命令概述
onlog 命令显示逻辑日志文件(无论在磁盘上或备份上)的内容。执行 onlog 时数据库服务器处于关闭状态,那么只读取磁盘上的文件。如果数据库服务器处于静态模式或在线模式,那么 onlog 还读取存储在共享内存中逻辑日志缓冲区的逻辑日志记录(在读取磁盘上的所有记录之后)。
onlog 语法

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -q | 不显示缺省情况下每 18 个记录出现一次的初始头和单行头 | 无 |
| -V | 显示软件版本号及序列号 | |
| -version | 显示构件版本、主机、操作系统、编号、日期及 GLS 版本 |
- 只有用户 gbasedbt(在 UNIX™ 上)可以运行 -l 选项。
- 当数据库服务器在在线模式下从磁盘中读取具有状态 U 的逻辑日志文件时,数据库服务器拒绝对逻辑日志文件的所有访问,有效地停止所有会话的数据库活动。出于这个原因,建议您等到备份了文件之后再从备份中读取逻辑日志文件的内容。
过滤日志记录读取
onlog 命令使用存储在 root dbspace 保留页中的路径名定位逻辑日志文件。如果使用 ON-Bar 备份逻辑日志,那么 onlog 请求存储管理器从备份介质中检索想要的逻辑日志记录。
LOG-Record Read Filters:

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -b | 显示与 blobspace blobpage 相关联的逻辑日志记录 | 数据库服务器将这些记录作为 blobspace 日志记录的一部分存储在逻辑日志备份介质上 |
| -d device | 给出所需逻辑日志备份安装到的存储设备的路径名 | 如果使用 ontape ,那么所指定的设备必须与指定给配置参数 LTAPEDEV 的设备的路径名相同。如果未使用 -d 选项,那么 onlog 读取存储在磁盘上的逻辑日志文件(以具有最低 logid 的逻辑日志文件开始)。 如果您使用 ON-Bar 来备份逻辑日志,请使用 onbar -P 命令来查看逻辑日志文件的内容。 |
| -n starting_uniqid-ending_uniqid | 指示 onlog 读取包含在您指定的日志文件中从 starting uniqid 到 ending uniqid 的所有的逻辑日志记录 | starting_uniqid 和 ending_uniqid 都是逻辑日志的唯一 ID 。要确定特定逻辑日志文件的 uniqid ,请使用 onstat -l 命令。 如果您没有使用 -n 选项,那么 onlog 将读取所有可用的逻辑日志文件(在磁盘上或磁带上)。 |
过滤日志记录显示
当 onlog 索引要显示的记录时,您指示它读取逻辑日志的以下部分:
- 存储在磁盘上的记录
- 存储在备份介质上的记录
- 所指定逻辑日志文件中的记录
缺省情况下,onlog 显示逻辑日志记录头,它描述事务号和记录类型。记录类型标识所执行操作的类型。
除头之外,可以使用读取过滤器指示 onlog 显示以下信息:
- 逻辑日志记录头和数据(包含存储在 dbspace 或 tblspace 中的简单大对象的副本)
- blobspace 中 blobpage 的副本
它们是只从逻辑日志备份复制的,它们不可从磁盘上得到。
您可以显示每个逻辑日志记录头或可以基于以下条件指定输出:
- 与特定表相关联的记录
- 特定用户启动的记录
- 与特定事务相关联的记录
如果 onlog 在日志文件中检测到错误(例如无法识别日志类型),那么它以十六进制格式显示整个日志页并终止。
LOG-Record display Filters:
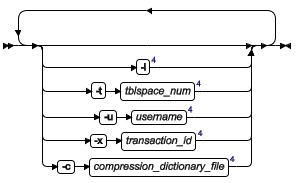
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -l | 显示逻辑日志记录的长列表 | 日志记录的长列表包含整个日志记录的复合十六进制和 ASCII 转储。该列表不是供随意使用的。 |
| -ttblspace_num | 显示与所指定 tblspace 相关联的记录 | 无符号整数。编号(大于 0 )必须在 systables 系统目录的 partnum 列中。 将该值指定为整数或十六进制值(如果不使用 0x 前缀,那么该值作为整数解释)。要确定特定 tblspace 的 tblspace 编号,请查询 systables 系统目录表,它在 Tblspace 编号 中进行描述。 |
| -u username | 显示特定用户的记录 | 用户名必须是现有的登录名。用户名必须符合特定于操作系统的登录名规则 |
| -x transaction_id | 只显示与所指定事务相关联的记录 | 值必须是 0 和 TRANSACTIONS - 1(包括 0 和 TRANSACTIONS - 1)之间的无符号整数。 只在前滚过程中生成了错误的情况(不太可能发生的情况)下才能使用 -x 选项。当发生这种情况时,数据库服务器向消息日志发送消息,消息包含出错事务的事务 ID 。可以使用此事务 ID 和 onlog 的 -x 选项调查错误原因 |
| -c compression_dictionary_file | 使用压缩字典来扩展压缩数据并显示未压缩的数据 | 如果 onlog 命令包含 -l 选项和 -c 选项并且日志记录中有压缩图像,那么 onlog 命令使用压缩字典扩展该日志记录中的所有可扩展的图像。 压缩图像只在压缩字典文件中具有有效压缩字典的日志记录的条件下是可扩展的。如果 -c 没有被指定或压缩字典文件没有一个该压缩图像的有效压缩字典,那么 onlog 命令将显示其压缩格式中的行图像。 |
如果您没有压缩字典文件,可以使用 UNLOAD 命令加载该压缩字典给压缩字典文件,它将包含在 sysmaster 数据库的 syscompdicts_full 表中,示例如下:
UNLOAD TO 'compression_dictionary_file'
SELECT * FROM sysmaster:syscompdicts_full;
如果未指定任何选项,onlog 显示日志记录中所有记录的简单列表。可以将这些选项与任何其他选项组合使用,以生成更有选择性的过滤器。例如:如果同时使用 -u 和 -x 选项,那么 onlog 只显示在指定事务过程中指定用户启动的活动。如果同时使用 -u 和 -t 选项,那么 onlog 只显示由指定用户启动并与指定 tblspace 相关联的活动。
数据库常用操作
onmode 命令概览
使用 onmode 命令变更数据库服务器操作方式,并在共享内容、会话、事务、参数和分段上执行其他各种操作。
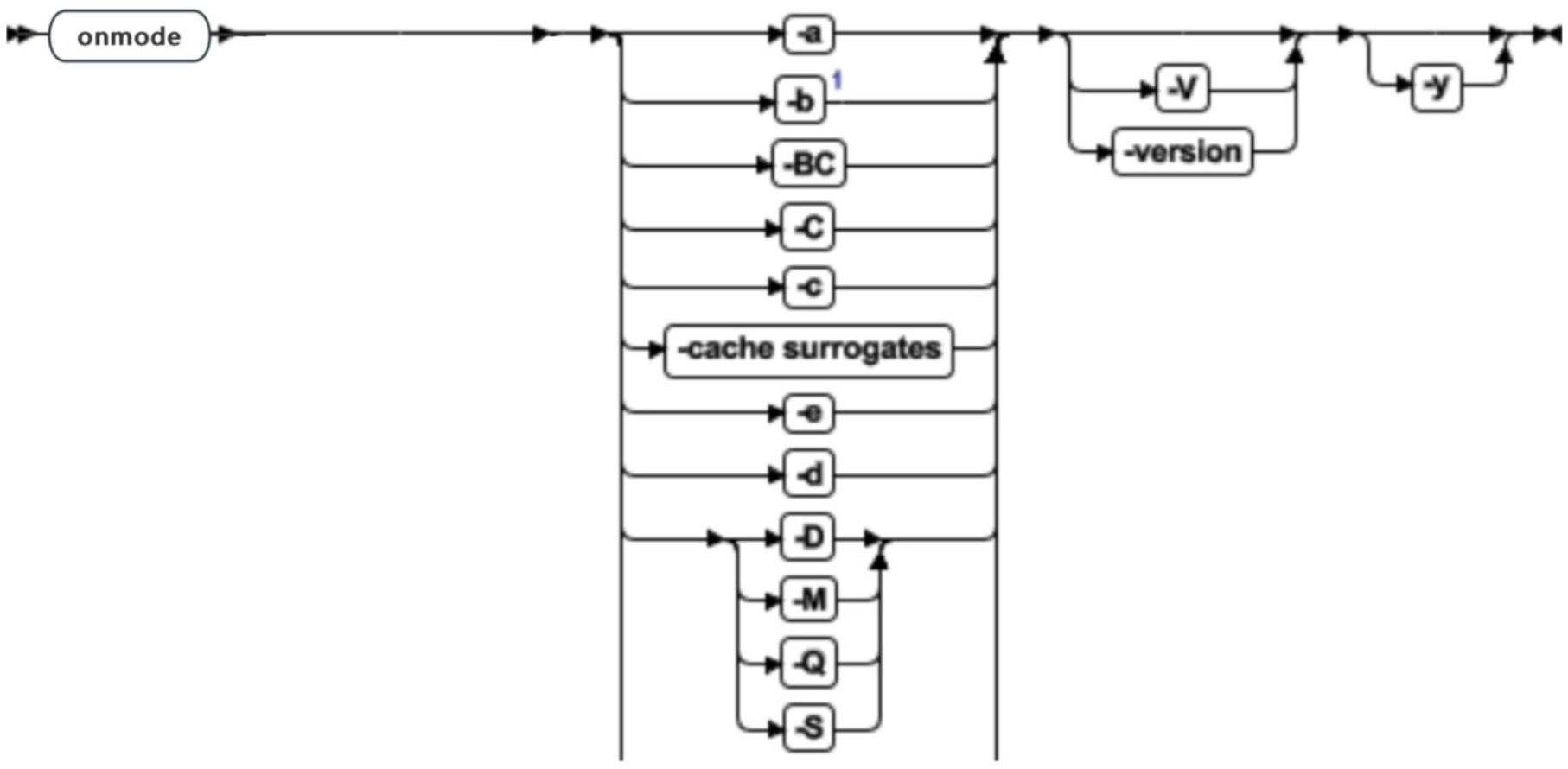
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| -V | 显示软件版本号和序列号 | |
| -version | 显示了构件版本、主机、操作系统、数量、日期以及 GLS 版本 |
- 在 UNIX™ 上,必须是用户 root 或用户 gbasedbt 才能执行该 onmode 命令。
onmode -a: 添加共享内存段
通常,您无需向共享内存的虚拟部分添加段,因为数据库服务器会在需要时自动添加段。然而,随着段的添加,数据库服务器可能在获得其需要的内存之前达到段最大数量的操作系统限制。这种情况通常在 SHMADD 配置参数设置得太小,以致数据库服务器在获得某些操作所需内存之前耗尽可用段的数量时发生。
如果手工添加的段大于 SHMADD 所指定的段,那么可以避免耗尽这些段的操作系统限制数,但仍满足数据库服务器对额外内存的需要。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -a seg_size | 允许添加新的虚拟共享内存段。以千字节为单位 | 限制: seg_size 的值必须是正整数。它不得超过操作系统对共享内存段大小的限制 |
onmode -BC:允许大 chunk 方式
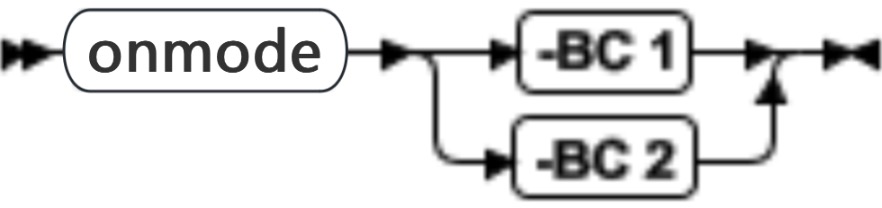
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -BC 1 | 启用大 chunk 、大于 2 GB 的偏移量并允许每个实例增大到32,768 个 chunk 。 | 此选项允许创建大 chunk 。如果 chunk 没有均大于 2 GB ,那么可以在不删除的情况下进行转换。没有大于 2 GB chunk 的 dbspace 和 blobspace 将保持旧格式。在向 dbspace 和 blobspace 添加了大于 2 GB 的 chunk 之后,随后在该dbspace 和 blobspace 中添加或更改的所有 chunk 都是新的格式。 |
| -BC 2 | 对所有 dbspace 允许 “仅大 chunk ”方式 | 复原是不可能的。对所有 dbspace 或 blobspace 启用 9.4 大 chunk 功能。所添加或修改的任何 chunk 或偏移量都是新的格式。未更改的现有 chunk 保持旧格式。 |
执行 onmode -BC 命令之后,请执行一次完全的系统 0 级备份。
onmode -c:强制 checkpoint
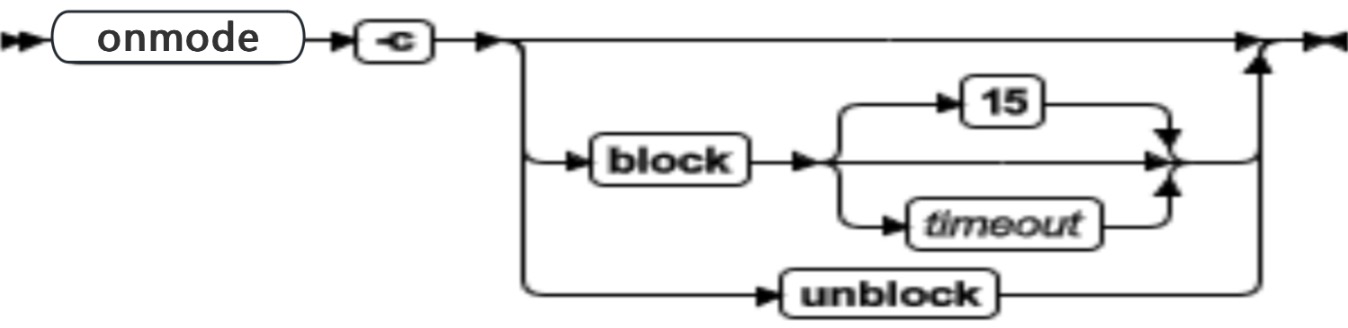
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -c | 强制用于将缓冲区清仓到磁盘的 checkpoint | 如果逻辑日志中的最新检查 checkpoint 记录正在阻止释放逻辑日志文件(状态 U-B-L),那么可以使用 -c 选项强制同步 checkpoint 。 |
| block | 阻塞数据库服务器运行任何事务 | 当数据库服务器阻塞后,用户可以以只读方式访问它。使用此选项在 GBase 8s 上执行外部备份。 |
| timeout | 指示在返回命令提示符之前等待 checkpoint 清除的秒数 | timeout 选项只有在配置了 DELAY_APPLY 配置参数后才能应用。如果启用了 DELAY_APPLY 配置参数,那么主服务器请求的 checkpoint 可能在扩展的时间段内无法到达辅助服务器。也可能是没有其它 checkpoint 暂存在暂存目录中。缺省的 timeout 值为 15 秒,允许的最大 timout 值为 10 分钟(600 秒)。 |
| unblock | 不阻塞数据库服务器 | 当数据库服务器未阻塞时,可以继续数据事务和正常的数据库服务器操作。请在完成了 GBase 8s 上的外部备份之后使用此选项。 |
onmode -C: 控制 B-tree 扫描程序
可以使用 onmode -C 命令控制 B-tree 扫描程序并且指定关于 B-tree 扫描程序线程的信息。
B-tree 扫描程序有追踪索引的有效性以及当前索引放在服务器上的额外工作量的统计信息。基于由删除的索引项引起的索引已完成的额外工作量,B-tree 扫描程序生成了称为“热表”的整齐索引列表,这使得服务器做了额外的工作。将清除导致最高额外工作量的索引,然后以递减的方式清除剩下的索引。 DBA 可以动态地分配清除线程,因此允许可配置的工作负载。
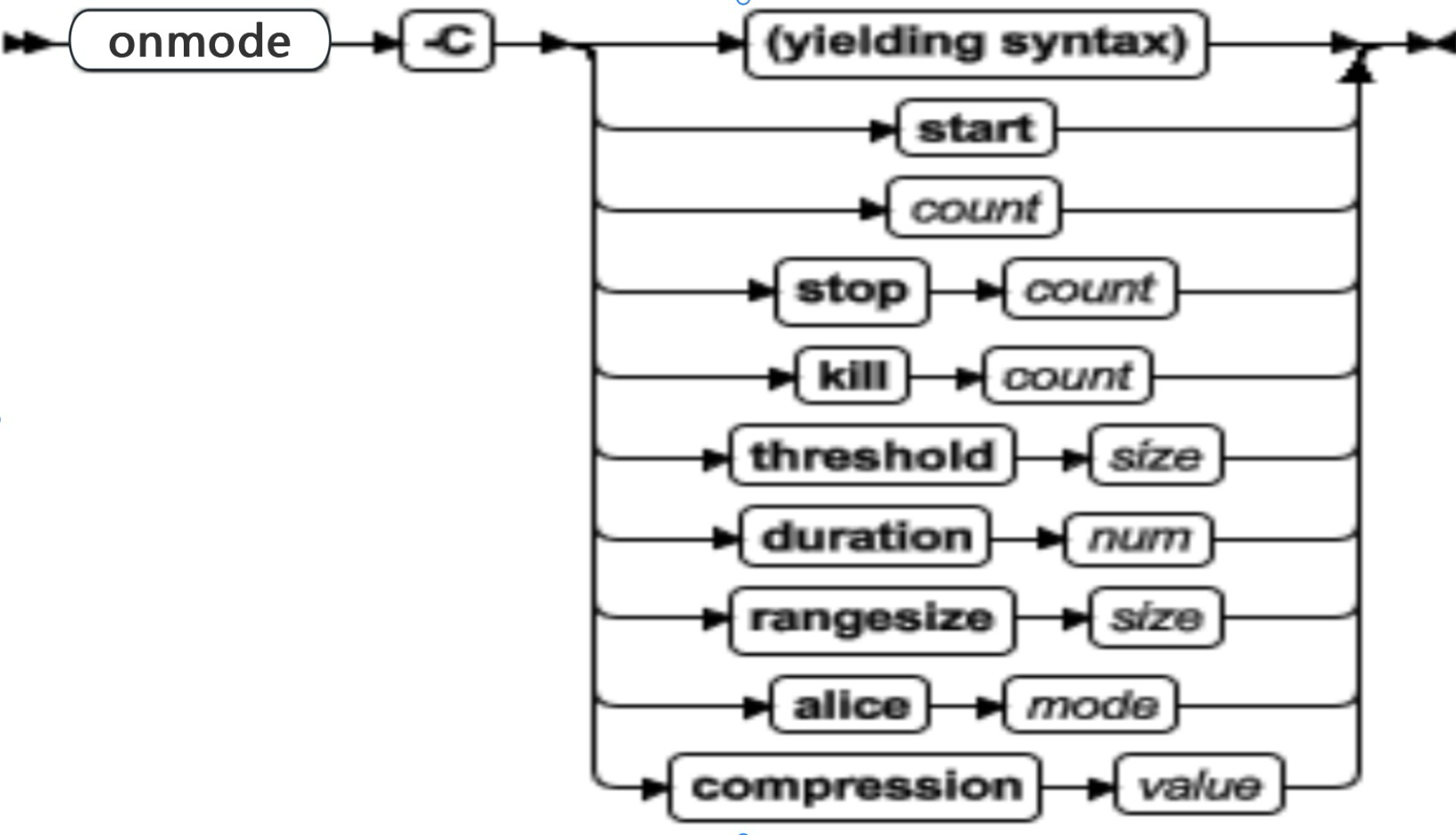
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -C | 控制用于清除已删除项索引的 B-tree 扫描程序 | 对同时运行的线程的数量没有限制。然而,可同时启动的线程数限制为 128 个。 例如:如果您想要运行 150 个线程,那么要执行两条命令:onmode -C 100 和 onmode -C 50 |
| start count | 启动其他的 B-tree 扫描程序线程 | 如果没有指定 count ,那么假定count 1。对可以指定扫描程序线程数量没有限制。 |
| stop countkill count | 停止 B-tree 扫描程序线程 | 如果没有指定 count ,那么假定count 1 。 停止所有的所有扫描程序以阻止所有的所有被清除。 上述任一命令都可以停止 B-tree 扫描程序 |
| threshold size count | 设置在热列表上放置之前索引必须遇到的已删除项的最小数量 | 一旦所有超过阈值的索引都被清除并且 B-tree 扫描仪也没有别的工作,在该阈值之下的索引就会被添加到热列表 |
| duration num | 热列表处于有效状态的秒数 | 在秒数到期之后,热列表会由下一个可用的 B-tree 扫描程序重建,即使表上有未处理的项目。不会中断扫描程序当前正在处理的请求 |
| rangesize size | 在启用索引范围清除之前,确定索引的大小 | 大小为 -1 的值可用来禁用范围扫描 |
| alice num | 设置系统的 alice 方式 | 有效 num 值的范围是:0 (OFF) 到 12 |
| compression value | 对于数据库服务器实例,更改,合并两个部分使用的索引页的级别。如果这些页上的数据合计设定级别,那么页合并 | 级别的可用值为: low 、med (中等)、high 和 default 。系统的缺省值是 med |
onmode -cache 代理: 缓存 allowed.surrogates 文件

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -cache surrogates | 读取 /etc/gbasedbt/allowed.surrogates 文件并将户 ID 和群组 ID 存储在共享内存缓存中 。 allowed.surrogates 文件中指定的用户名和群组名必须是有效的操作系统用户和群组,名称会转换成相应的 UID 和 GID | 在会话加载 allowed.surrogates 文件时,可以使用 onmode -cache surrogates。allowed.surrogates 文件用于指定可作为映射用户代理的用户和群组。在新的连接创建到数据库服务器之前或当创建或变更用户时,会自动检查 allowed.surrogates文件。 如果缓存刷新失败,清除现有代理缓存,即时禁用已映射的用户。服务器上现有的连接不会被共享内存缓存变化所影响。但共享内存的变化会影响新的会话 |
onmode -d: 设置数据复制类型

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d | 用于设置服务器数据复制类型 | -d standard 删除数据复制对中数据库服务器之间的连接(如果存在一个连接)并将当前数据库服务器的数据库服务器类型设置为标准。此选项不更改对中其他数据库服务器的方式或类型。 ● 可在数据库服务器处于静态、在线或只读方式 ● RSS 断开服务时 在主服务器上: onmode -d delete RSS dbservername 在 RS 辅助服务器上: onmode -d standard ● 该命令使 HAC 辅助服务器转变成一个独立的服务器。 the -d primary 将数据库服务器类型设置为主并尝试与 dbservername 指定的数据库服务器连接。如果连接成功,那么开启数据复制。主数据库服务器变成在线模式,而辅助数据库服务器变成只读方式。如果连接失败,那么数据库服务器变成在线模式,但不开启数据复制。 the -d secondary 将数据库服务器类型设置为辅助,并尝试与 dbservername 指定的数据库服务器连接。如果连接成功,那么开启数据复制。主数据库服务器变成在线模式,而辅助数据库服务器变成只读方式。如果连接失败,那么数据库服务器变成只读方式,但不开启数据复制。 |
| dbservername | 标识主或辅助服务器的数据库服务器名 | dbservername 参数必须对应于目的主数据库服务器的数据库名。在共享内存重新初始化之后,数据复制对中的其他数据库服务器的名称和数据库服务器的类型(标准、主或辅助)将保留 |
onmode -d: 设置高可用服务器的特性
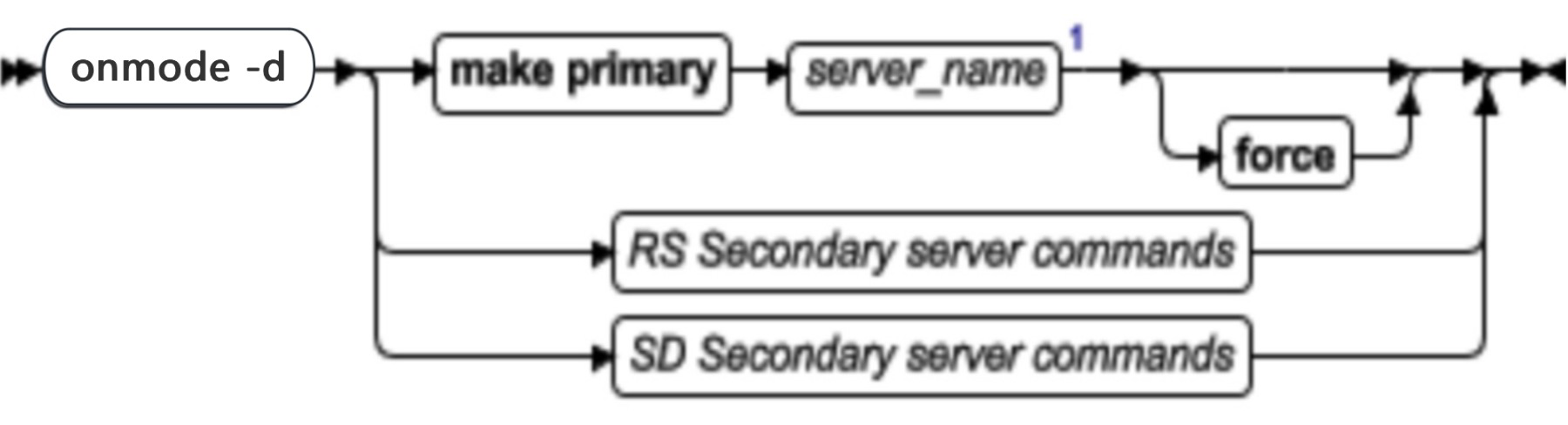
RHAC 辅助服务器命令
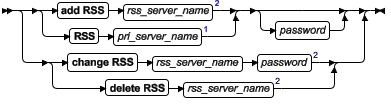
SSC 辅助服务器命令

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d | 用来在高可用性配置中创建、修改或删除辅助服务器 | |
| add RSS | 添加 RHAC 辅助服务器 | 该命令须在主数据库服务器上运行 |
| rss_server_name | 标识 RHAC 辅助服务器名称 | servername 参数可以是 数据库服务器名称和 ER 群组名称。 |
| password | 指定辅助服务器密码 | 此密码只能在第一次尝试连接时使用。在主或辅助服务器建立连接后,密码将无法变更。 |
| RSS | 设置 RHAC 辅助服务器类型 | 该命令须在辅助数据库服务器上运行 |
| pri_server_name | 标识主服务器的名称 | |
| change RSS | 变更 RHAC 辅助服务器 | 该命令须在主数据库服务器上运行 |
| delete RSS | 移除 RHAC 辅助服务器定义 | 该命令须在主数据库服务器上运行 |
| set SDS primary | 将服务器定义为共享磁盘主服务器 | |
| server_name | 数据库服务器名 | 当和 set SDS 或 make primary 一起使用时,它为角色变更的服务器的名称 |
| force | 用于强制变更 | 如果制定了 force 选项,那么无须请求将辅助服务器连接到当前服务器即可执行操作。如果没有指定 force 选项,那么必须根据当前主服务器调整操作。只能在 DBA 确定当前主服务器不在活动时使用 force 选项;否则会毁坏共享磁盘子系统 |
| clear SDS primary | 禁用共享磁盘环境。该服务器的名称不再作为 SSC 主服务器 | |
| make primary | 创建主服务器 | make primary 命令可用来声明辅助服务器的类型,包括 HAC 辅助服务器、RHAC 辅助服务器和 SSC 辅助服务器。如果运行 make primary : ● HDR Secondary:关闭当前主服务器并且将辅助服务器变为主服务器。 ● RS secondary:服务器变为标准服务器。 ● SD secondary:服务器成为新的主服务器 |
onmode -d 命令:使用数据复制来复制索引

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d | 指定当辅助服务器上的索引毁坏时,如何将索引复制到 High-Availability Data-Replication (HAC) 辅助服务器 | 当服务器处于在线模式时,您可以使用 onmode -d idxauto 和 onmode -d index 命令 |
| idxauto | 当辅助服务器的索引毁坏时,启用自动索引复制 | 使用 onmode -d idxauto 命令覆盖会话中 DRIDXAUTO 配置参数的值。 |
| index | 将索引从主服务器复制到辅助服务器 | 如果您检测到辅助服务器上索引毁坏,请使用 onmode -d index 命令来启动将索引从主服务器复制到辅助服务器 |
| database | 指定包含要复制的索引的数据库 | 语法必须符合 Identifier 段; |
| index | 指定要复制的索引的名称 | 指定的表和数据库中必须存在索引 语法必须符合 Identifier 段; |
| owner | 指定表的所有者 | 必须指定表的当前所有者。 语法必须符合 Table Name 段。 |
| table | 指定建立索引的表的名称 | 语法必须符合 Table Name 段; |
- onmode -d idxauto 和 onmode -d index 命令提供了将索引复制到包含损坏索引的辅助服务器的方法。在传送索引期间,基本表将被锁定。使用这些选项的另一种方法是在主服务器上删除并重建毁坏的索引。
- 如果是分片索引的一个分片毁坏,那么 onmode -d idxauto 命令将只传送单个受影响的分片,而 onmode -d index 命令则传送整个索引。
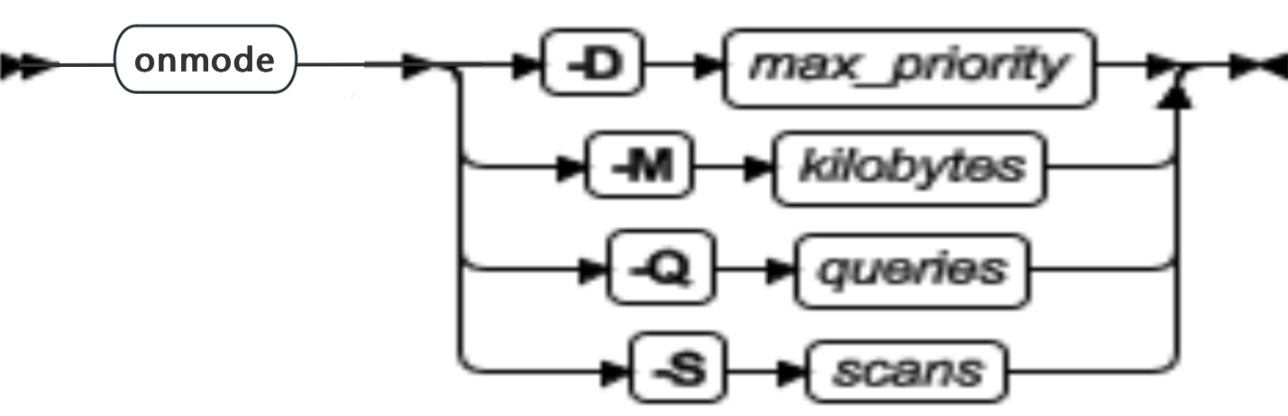
onmode -D, -M, -Q, -S: 更改支持决定的参数
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -D max_priority | 更改 MAX_PDQPRIORITY 的值 | 该值必须是 0 到 100 之间的无符号整数。 指定 max_priority 作为调节用户对 PDQ 资源的请求的因素 |
| -M kilobytes | 更改 DS_TOTAL_MEMORY 的值 | 该值的上限取决于平台。如果您输入一个大于您平台的值,那么会收到一条关于您的平台取值范围的消息。 将 kilobytes 指定为可用于并行查询的最大内存量。 |
| -Q queries | 更改 DS_MAX_QUERIES 的值 | 该值必须是 1 和 8,388,608 之间的无符号整数。 将 queries 指定为并发地执行的并行查询的最大数量。 |
| -S scans | 更改 DS_MAX_SCANS 的值 | 该值必须是 10 和 1,048,576 之间的无符号整数。 将 scans 指定为并发地执行的并行扫描的最大数量。 |
- 这些选项只允许在数据库服务器在线时使用。
- 修改后的值只影响数据库服务器的当前实例,不记录在 ONCONFIG 文件中。如果关闭并重启数据库服务器,那么这些参数的值还原到 ONCONFIG 文件中的值。
补充说明: 要检查 MAX_PDQPRIORITY 、 DS_TOTAL_MEMORY 、DS_MAX_SCANS 、DS_MAX_QUERIES 和 DS_NONPDQ_QUERY_MEM 配置参数的当前值,请使用 onstat -g mgm 。
onmode -e: 更改 SQL 语句高速缓存的用途
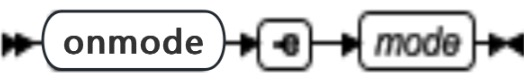
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| onmode -e ENABLE | 启用 SQL 语句高速缓存。 | 用户会话只在执行以下操作之一时才使用缓存: ● 将环境变量 STMT_CACHE 设置为 1 ● 执行 SQL 语句 SET STATEMENT CACHE ON |
| onmode -e FLUSH | 从 SQL 语句高速缓存中清仓不在使用的语句 | onstat -g ssc ref_cnt 字段显示 0 |
| onmode -e OFF | 关闭 SQL 语句高速缓存 | 不高速缓存任何语句 |
| onmode -e ON | 开启 SQL 语句高速缓存 | 所有语句都是高速缓存的,除非用户使用以下操作之一关闭它: ● 将环境变量 STMT_CACHE 设置为 0 ● 执行 SQL 语句 SET STATEMENT CACHE OFF |
- onmode -e 变更只对当前数据库服务器会话生效。重新启动数据库服务器时,它使用 ONCONFIG 文件中的缺省的 STMT_CACHE 参数值。
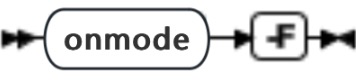
onmode -F: 释放未使用的内存段
在执行 onmode -F 时,内存管理器检查每个内存池的未使用内存。当内存管理器找到未使用内存块时,它立即释放该内存。在内存管理器检查了每个内存池之后,它开始检查内存段并释放数据库服务器不再需要的所有段。
建议在数据库服务器执行了任何创建额外内存段的功能(包括大索引构建、排序或备份)之后从操作系统调度工具定期运行 onmode -F。
运行 onmode -F 会造成执行该命令时处于活动状态的所有用户的显著性能降级。尽管执行时间很短(1 到 2 秒),但对于用户数据库服务器的降级可能达到 100%。具有多个 CPU 虚拟处理器的系统经历的降级成比例地减小。
要确认 onmode 已释放了未使用内存,请检查消息日志。如果内存管理器释放了一个或多个段,那么它显示一条标识已释放了多少内存段和字节的消息。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -F | 释放未使用的内存段 | 无 |
onmode -I: 控制诊断信息收集
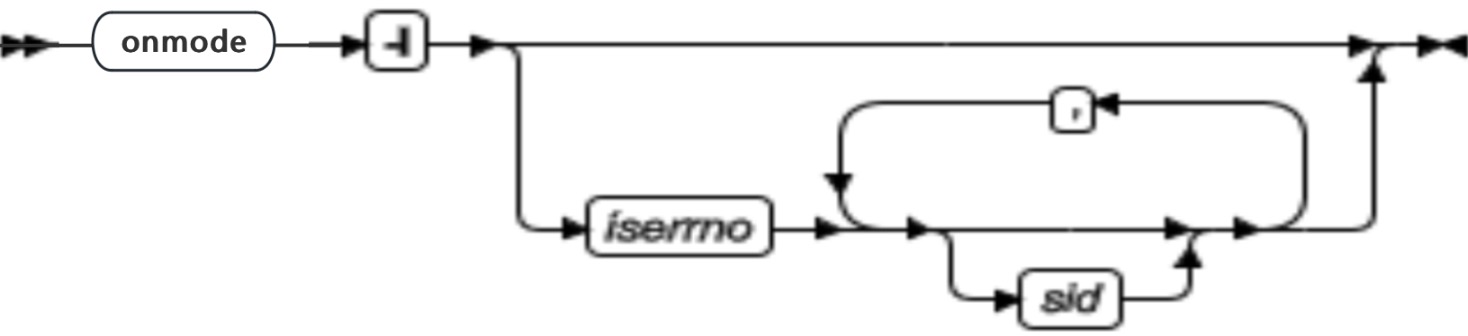
首次使用 onmode -I 选项开始和停止诊断信息的收集。遇到错误时,可以指定 onmode -I iserrno 选项启动收集诊断信息。也可以指定会话 ID 或收集仅指定的会话的信息。
二次使用 -I 选项(不需要附加其他参数)停止诊断信息的收集。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| iserrno | 要收集诊断信息的错误的错误编号 | 无 |
| sid | 要收集诊断信息的会话的会话 ID | 无 |
onmode -k, -m, -s, -u, -j: 更改数据库服务器方式
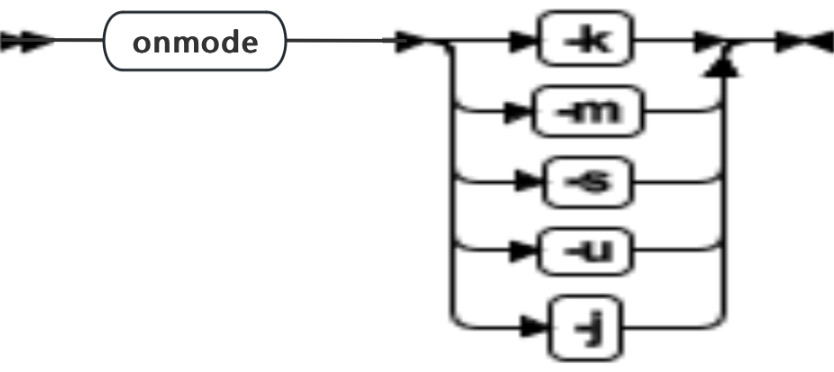
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -k | 关闭数据库,并除去共享内存 | 要重新初始化共享内存,请关闭并重新启动数据库服务器 ● 在数据库服务器成为离线方式之前,另一个提示请求对终止用户线程进行确认。如果想要消除这些提示,请执行 -y 选项和 -s 选项。 ● 当使用 onmode -k 命令关闭数据库服务器时,正在等待用户响应的命令可能不终止。例如:ontape 可能正在等待另一个磁带、onstat -i 可能正在等待用户响应或 onspaces 可能正在等待 y 或 n 以继续。如果发生这种问题,请使用 onmode -uk 或 -uky ,而不是在除去共享内存之前回滚工作。 |
| -m | 将数据库服务器从静态模式或管理员模式更改为在线模式 | |
| -s | 以宽限方式关闭数据库服务器 | 在数据库服务器变成静态模式之前,允许正在使用数据库服务器的用户完成,但不允许新的连接,当所有处理完成时,-s 使数据库服务器成为静态模式。 -s 选项使共享内存保持不变。 |
| -u | 立即关闭数据库服务器 | -u 选项引起立即关闭,此选项使数据库服务器处于静态模式,而不等待用户完成其会话。它们的当前事务回滚,且它们的会话终止。 在数据库服务器变成静态模式之前,另一个提示请求对终止用户线程进行确认。如果想要消除这些提示,请执行 -y 选项和 -s 选项。 |
| -j | 使数据库服务器进入在线模式 | -j 选项使数据库服务器进入在线模式,在该方式中,只允许 DBSA 群组和用户 gbasedbt 连接到服务器。 |
- -j -U 选项使 DBSA 能够授权个别用户以在线模式访问数据库服务器。一旦连接,这些个别用户就能够执行任何 SQL 或 DDL 命令。当数据库更改为在线模式时,所有的用户会话(非 gbasedbt 用户会话)、DBSA 群组用户会话以及 onmode -j -U 命令中标识的会话断开与数据库服务器的连接。以下示例使三个用户连接到数据库服务器并一直持续到数据库服务器方式改为离线、静态或在线模式:
onmode -j -U karin,sarah,andrew
可以通过执行 onmode -j -U 将他们的姓名从命令中的新名单中删除个别用户进行访问。例如,在下列命令中,第一个命令只授权 Karin 访问,第二个命令授权 Karin 和 Sarah 访问,第三个命令只授权 Sarah 访问(除去了 Karin 的访问)。
onmode -j -U karin
onmode -j -U karin,sarah
onmode -j -U sarah
要允许用户 gbasedbt 和 DBSA 组用户在在线模式下访问数据库服务器并阻止所有单个用户访问数据库服务器,请使用以下命令
onmode -j -U ' '
onmode -l:切换逻辑日志文件

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -l | 将当前逻辑日志文件切换为下一个逻辑日志文件 |
onmode -n, -r: 更改共享内存驻留
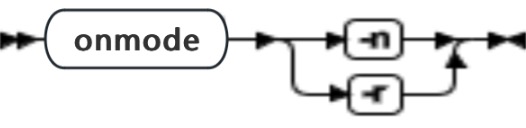
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -n | 结束共享内存的常驻部分的强制驻留 | 此命令不影响 RESIDENT(ONCONFIG 文件中的强制驻留参数) |
| -r | 开始共享内存的常驻部分的强制驻留 | 此命令不影响 RESIDENT(ONCONFIG 文件中的强制驻留参数) |
在使用 onmode -r 或 -n 选项之前,请将 RESIDENT 参数设置为 1 。
onmode -O: 重设 ONDBSPACEDOWN WAIT 方式
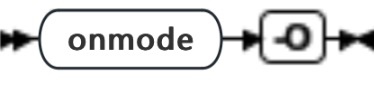
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -O | 重设 ONDBSPACEDOWN 配置参数的 WAIT 方式 | 只能在以下情况中使用 onmode -O 选项: ● ONDBSPACEDOWN 设置为 WAIT。 ● 发生禁用 I/O 错误,导致数据库服务器阻塞所有正在更新的线程。 ● 您无法或不想更正导致禁用 I/O 错误的问题。 ● 您想要使数据库服务器将已禁用 dbspace 标记为关闭并继续进程。 当您执行此选项时,数据库服务器会将导致禁用 I/O 错误的 dbspace 标记为关闭,完成检查点,并释放已阻塞的线程。然后,onmode 提示您一下消息: This will render any dbspaces which have incurred disabling I/O errors unusable and require them to be restored from an archive. Do you wish to continue?(y/n) 当您运行 -O 选项时,如果 onmode 在非临界 dbspace 上未找到任何禁用 I/O 错误,它将通知您以下消息: There have been no disabling I/O errors on any noncritical dbspaces. |
onmode -p: 添加或删除虚拟管理器
可以使用 onmode -p 命令动态地添加或移除数据库服务器实例的虚拟管理器。onmode -p 命令不会修改 onconfig 文件,
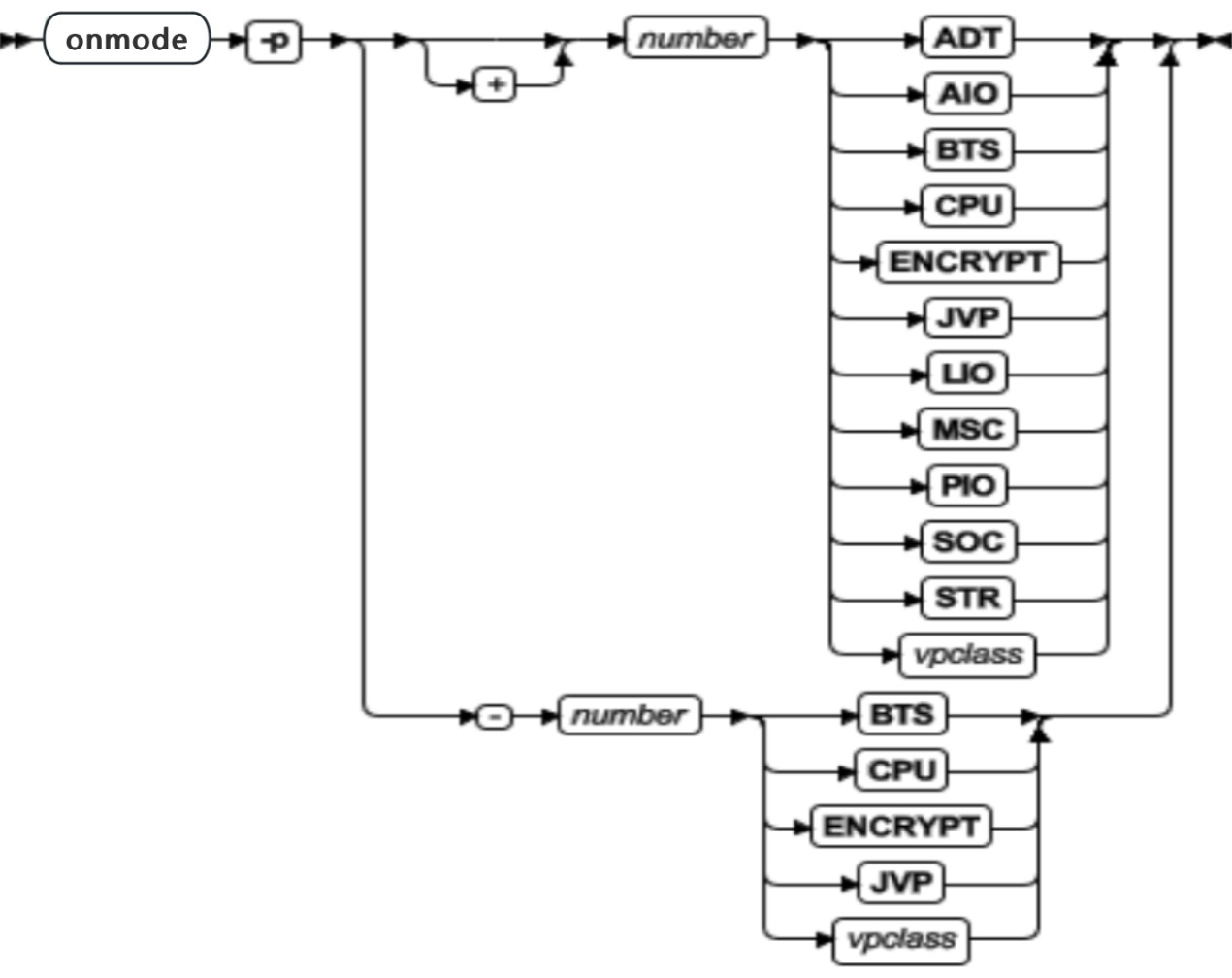
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -p number | 添加或移除虚拟处理器。 number 参数指示要添加或删除的虚拟处理器的数量。 如果该值是负整数,那么删除处理器。如果该值时正整数,那么添加处理器。 | 仅当数据库服务器处于在线模式时才能使用 -p 选项,且一次只能添加一类虚拟处理器。 如果正在删除虚拟处理器,那么最大数不能超过指定类型的实际处理器数量。如果正在添加虚拟处理器,那么最大数依赖于操作系统。 |
| ADT | 运行审计处理过程 | 当通过设置 ONCONFIG 文件中的 ADTMODE 参数开启审计方式时,数据库服务器在审计类里开始虚拟处理器 |
| AIO | 对格式化的磁盘空间执行非日志记录磁盘 I/O | 如果内核异步 I/O (KAIO) 未使用,那么还对原始磁盘空间执行非日志记录I/O |
| BTS | 运行基本文本搜索索引操作和查询 | BTS 虚拟处理器是非放弃的。如果想要同时运行多个基本文本搜索,那么指定多个 BTS 虚拟处理器。 使用 onconfig 文件中的 VPCLASS 参数创建至少一个 BTS 虚拟处理器。 |
| CPU | 运行所有会话线程和一些系统线程 | 建议 CPU VP 的数量不要大于物理处理器的数量。如果使用了 KAIO ,那么对原始磁盘空间执行 I/O ,包括对物理和逻辑日志的 I/O 。可用时运行 KAIO 线程或运行单个轮询线程。数据库服务器将 CPU VP 数用于为并行数据库查询 (PDQ) 分配资源。如果删除 CPU VP,查询运行将显著减慢。 onstat -g mgm 输出的 Reinit字段显示有关在 onmode -p 命令之后等待正在运行的查询完成的查询数量的信息。另见 GBase 8s 性能指南 |
| ENCRYPT | 执行列级别的加密和解密例程 | 指定更多 ENCRYPT 虚拟处理器(如果您有多个加密的列) |
| JVP | 在 Java™ 虚拟机(JVM)中执行 Java 用户定义的例程 | 如果正在运行许多 Java UDR ,那么指定更多 JVP |
| LIO | 如果在格式化的磁盘空间中,那么写入逻辑日志文件中 | 只有在逻辑日志位于镜像数 dbspace 中时才使用 2 个 LIO 虚拟处理器。数据库服务器最多允许 2 个 LIO 虚拟处理器 |
| MSC | 管理需要大量的堆栈空间的系统调用的请求 | 用于杂项内部任务 |
| PIO | 如果在格式化的磁盘空间中,那么写入物理日志文件中 | 只有在物理日志位于镜像数 dbspace 中时才使用 2 个 PIO 虚拟处理器。数据库服务器最多允许 2 个 PIO 虚拟处理器 |
| SOC | 使用 sockets 来执行网络通信 | 只能在数据库服务器通过 scokets 配置网络通信时,使用 SOC 虚拟处理器 |
| STR | 执行流管道连接 | |
| vpclass | 给出用户自定义的虚拟处理器类的名称 | 使用 onconfig 中的 VPCLASS 参数定义用户自定义虚拟处理器类。如果想要运行多个 UDR,那么可以指定多个用户自定义处理器。 |
- 不能删除最后的虚拟处理器。至少保留一台虚拟处理器。
- 不能添加或删除 ADM 或 OPT。
- 下列是可添加或删除的虚拟处理器,并且可添加多个虚拟处理器
| 虚拟处理器名称 | 添加 | 删除 |
|---|---|---|
| ADT | Yes | No |
| AIO | Yes | No |
| BTS | Yes | Yes |
| CPU | Yes | Yes |
| ENCRYPT | Yes | Yes |
| JVP | Yes | Yes |
| LIO | Yes | No |
| MSC | Yes | No |
| PIO | Yes | No |
| SOC | Yes | No |
| STR | Yes | No |
| vpclass | Yes | Yes |
- 当数据库服务器在线时,不能删除正在运行轮询线程的 CPU 虚拟处理器。要确定在 CPU 虚拟处理器上运行的轮询线程,请使用以下命令:
onstat -g ath | grep 'cpu.*poll'
tid tcb rstcb prty status vp-class name
8 a362b90 0 2 running 1cpu tlitcppoll
9 a36e8e0 0 2 cond wait arrived 3cpu
以上 onstat -g ath 输出显示了带有轮询线程的 2 个 CPU 虚拟处理。在这情况下,不能降到低于 2 个 CPU 虚拟处理器。status 字段包含下列信息:running 、cond wait 、IO Idle 、IO Idle 、sleeping secs: number_of_seconds 或 sleeping forever。为了提高性能,可以移除或减少标识为 sleeping forever 线程的数量。
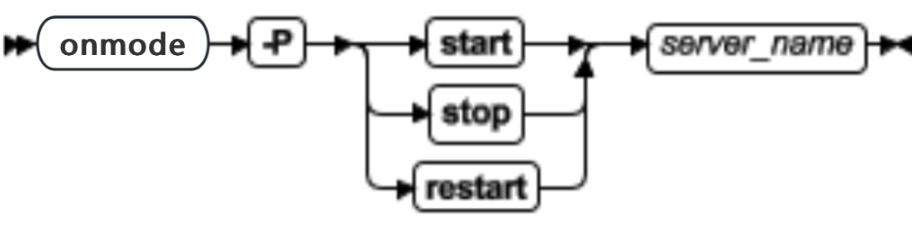
onmode -P: 动态地启动、停止或重启监听线程
在不中断现有连接的情况下,可以使用 onmode -P 命令动态地启动、停止或重启当前 SOCTCP 或 TLITCP 网络端口的监听线程。这些命令不能修改 sqlhosts 文件。
语法:
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| start | 不中断现有连接的情况下,启动新的 SOCTCP 或 TLITCP 网络端口的监听线程 | 该监听线程的定义必须存在于此服务器的 sqlhosts 文件中。如果不存在,您必须在动态地启动监听线程之前添加它 |
| stop | 不中断现有连接的情况下,停止当前 SOCTCP 或 TLITCP 网络端口的监听线程 | 该监听线程的定义必须存在于此服务器的 sqlhosts 文件中 |
| restart | 不中断现有连接的情况下,重新启动当前 SOCTCP 或 TLITCP 网络端口的监听线程 | 该监听线程的定义必须存在于此服务器的 sqlhosts 文件中 |
| server_name | 要启动、停止或重启的数据库服务器名称 |
示例
下列命令显示停止并重启名为 ids_serv1 的服务器的监听线程:
onmode -P restart ids_serv1
onmode -R: 重新生成 .infos.dbservername 文件
当数据库服务器访问命令时,它使用 $GBASEDBTDIR/etc/.infos.dbservername 文件中的信息。 如果意外删除了,那么必须重建该文件或关闭并重启数据库服务器。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -R | 重新创建 .infos.dbservername 文件 | 无 |
onmode -W: 更改 SQL 语句高速缓存的设置

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| STMT_CACHE_HITS hits | 指定语句完全插入到 SQL 语句高速缓存之前,对它的命中(引用)数。将 hits 设置为 1 或更大可防止特定查询进入高速缓存 | 仅可增加或重设STMT_CACHE_HITS 的值。新值显示在 onstat -g ssc 输出的 #hits 字段中。如果 hits = 0 ,数据库服务器在高速缓存中插入所有符合条件的语句及其内存结构。如果 hits > 0 并且 SQL 语句的已执行次数小于 STMT_CACHE_HITS ,那么数据库服务器会在高速缓存插入 key-only 条目。在已将语句执行了指定命中次数之后,它在高速缓存中插入符合条件的语句。ONCONFIG 参数:STMT_CACHE_HITS |
| STMT_CACHE_NOLIMIT value | 控制语句是否插入 SQL 语句高速缓存 | 如果 value = 0,那么数据库服务器在高速缓存中插入语句。如果 value = 1,数据库服务器总是在高速缓存中插入语句。如果没有共享任何查询,那么关闭 STMT_CACHE_NOLIMIT 可防止数据库服务器为高速缓存分配大量内存。ONCONFIG 参数:STMT_CACHE_NOLIMIT |
示例
以下是用于更改 SQL 语句高速缓存(SSC)设置的 onmode -W 命令的示例。更改只对当前数据库会话生效,且不能更改 ONCONFIG 值。重新启动数据库服务器时,它使用缺省的 SSC 设置(如果未在 ONCONFIG 文件中指定)或 ONCONFIG 设置。要做出永久更改,请设置相应的配置参数。
onmode -W STMT_CACHE_HITS 2 # number of hits before statement is
# inserted into SSC
onmode -W STMT_CACHE_NOLIMIT 1 # always insert statements into
# the cache
onmode -we: 导出包含当前配置参数的文件
onmode -we 命令自动创建 ASCII 并给它命名您在命令中指定的名称。该文件的格式与 onconfig.std 文件格式相同。
- 如果在当前会话中动态地变更值,导出的文件包含已更改的值而不是在 onconfig 文件中永久保存的值。
- 导出配置文件之后,可以导入它并作为配置文件使用。
- 如果运行 onmode -we 命令并指定之前导出的文件,那么该命令导出该文件的最新版本,并重写之前导出的文件。

| 元素 | 描述 | 关键注意事项 |
|---|---|---|
| path_name | 配置文件的完整或相对路径名 | 不能添加扩展 |
示例
以下命令导出了 /tmp 目录下 onconfig3 文件中所有配置参数和它们当前值:
onmode -we /tmp/onconfig3
onmode -wf,-wm: 动态更改某个配置参数
使用 onmode -wf 或 onmode -wm 命令动态更改指定的可配置参数。您可以动态使用 onmode -wm 或 -wf command ,运行 onstat -g cfg tunable 命令查看配置参数列表。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -wf | 更新 onconfig 文件中指定配置参数的值 | DBA 用户必须具有包含 onconfig文件的目录的写入权限 |
| -wm | 动态设置内存中指定配置参数的值 | 重启服务器时,指定的 value 不会预留 |
| config_param = value | 指定配置参数及其新值 |
onmode -wi: 导入配置参数文件
使用 onmode -wi 导入配置文件比运行有关多个可调整配置参数的 onmode -wm 命令更加快速和方便。
导入操作会忽略文件中不可调整的配置参数。该操作也会忽略与被当前实例使用所匹配的新的参数的值。该操作不会影响 $GBASEDBTDIR/etc/$ONCONFIG 文件中的值。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| path_name | 上一次导出的配置文件的完整或相对路径 |
示例
以下命令导出了 /tmp 目录下名为 onconfig3 文件中的配置参数:
onmode -wi /tmp/onconfig3
onmode -Y: 动态更改 SET EXPLAIN

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| file_name | 解释输出文件的名称 | 如果不包含绝对路径,那么将在该样本输出文件的位置创建样本输出文件。如果存在该文件,解释输出会附加在其中。如果文件正用于 SET EXPLAIN 语句中,那么该文件不能使用直到动态解释关闭 |
| session_id | 指示特定会话 | 无 |
| -Y | 动态更改 SET EXPLAIN 语句的值 | 无 |
当使用 onmode -Y 命令开启 SET EXPLAIN 时,输出显示在解释的输出文件中。
对于单独的会话,onmode -Y 命令动态更改 SET EXPLAIN 语句的值。使用该命令时,以下调用是有效的:
| 调用 | 解释 |
|---|---|
| onmode -Y session_id 2 | 开启对 session_id 的 SET EXPLAIN |
| onmode -Y session_id 1 | 开启对 session_id 的 SET EXPLAIN 并且在解释输出文件中显示查询统计一节 |
| onmode -Y session_id 1 /tmp/myexplain.out | 开启对 session_id 的 SET EXPLAIN 并将解释写入到 /tmp/myexplain.out 输出文件 |
| onmode -Y session_id 0 | 关闭对 session_id 的 SET EXPLAIN |
onmode -z: 终止数据库服务器会话
要使用 -z 选项,首先使用 onstat -u 获得会话标识(sessid),然后执行 onmode -z ,以该会话标识号代替 sid 。当使用 onmode -z 时,数据库服务器尝试终止指定的会话。如果数据库服务器成功,那么它释放该会话占用的所有资源。如果数据库服务器无法释放这些资源,那么不终止该会话。如果会话不退出扇区或释放锁存器,数据库服务器管理员可以使用-k使数据库服务器离线。
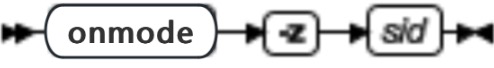
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -z sid | 终止 sid 中指定的会话 | 该值必须是大于 0 的无符号整数。且必须是当前正在运行的会话的会话标识号 |
日志、缓存池常用操作
onparams 命令概览
可以使用 onparams 命令添加或删除逻辑日志文件、更改物理日志参数和添加新的缓冲池。
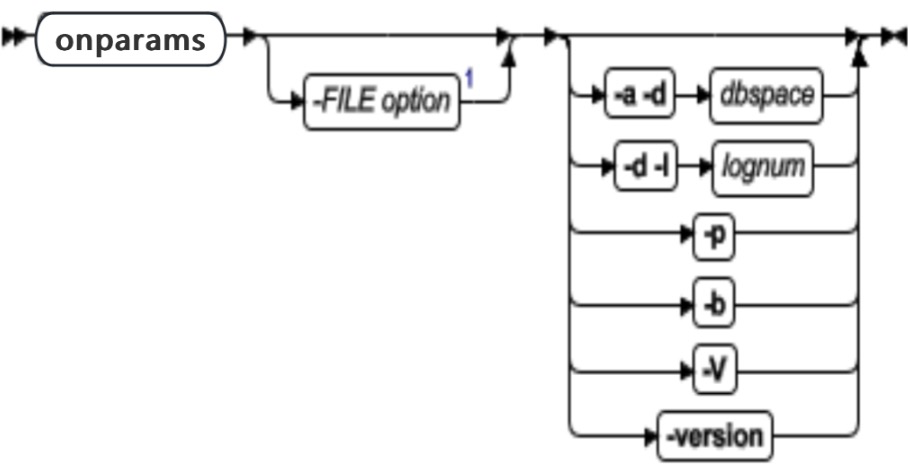
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -V | 显示软件版本号及序列号 | |
| -version | 显示构件版本、主机、操作系统、编号、日期及 GLS 版本 |
- 如果正在进行存储空间备份,那么任何 onparams 命令都会失败。
- 如果不使用任何选项,那么 onparams 返回用法语句。
- 不能在高可用数据复制(HAC)辅助服务器、远程独立(RHAC)辅助服务器或共享磁盘(SSC)辅助服务器上使用 onparams 命令。
- 在 UNIX™ 上,必须作为用户 root 或用户 gbasedbt 登陆才能执行 onparams 。
onparams -a -d dbspace: 添加逻辑日志文件

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -a -d dbspace | 在所指定的 dbspace 的日志文件列表末尾添加逻辑日志文件 | 仅当数据库服务器具有足够的连续空间时,才可以向 dbspace 添加日志文件。新添加的日志文件具有状态 A ,并立即可以使用。可以在备份过程中添加日志文件。最多可以有 32,767 个逻辑日志文件。请使用 onstat -l 查看逻辑日志文件的状态。建议尽早对 root dbspace 和包含日志文件的 dbspace 采用 0 级备份。 不能向 blobspace 或 sbspace 添加日志文件。 语法必须符合 Identifier 段; |
| -i | 在当前日志文件的后面插入逻辑日志文件 | 在“需要日志文件”警告提示您添加逻辑日志文件时使用此项 |
| -s size | 指定新逻辑日志文件的大小(千字节) | 该值必须是大于或等于 200 千字节的无符号整数。 如果您没有使用 -s 选项指定大小,那么数据库服务器磁盘空间初始化时,日志文件的大小将取自 ONCONFIG 文件中的 LOGSIZE 参数的值。 |
onparams -d -l lognum: 删除逻辑日志文件

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d -l lognum | 删除日志文件号所指定的逻辑日志文件 | Restrictions: lognum 值必须是大于或等于 0 的无符号整数。 可以从 onstat -l 的 number 字段获得 lognum。lognum 的可能是无序的 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
- 一次只能删除一个日志文件。
- 在所有时间,数据库服务器最少需要三个逻辑日志文件。如果数据库服务器配置有三个逻辑日志文件,那么您不能删除日志文件。
- 在删除任意前三个逻辑日志文件前,您必须添加新的逻辑日志文件并对逻辑日志文件进行备份。必须使用 ontape -a 命令或 ontape -c 命令执行备份。在添加新的逻辑日志文件并执行备份之后,您可以使用 onparams -d -llognum 删除前三个逻辑日志文件。
- 如果删除一个从未被写入的状态为|“新添加”(A)日志文件,数据库服务器删除日志文件并立即释放空间。
- 如果删除一个已使用的状态为“已使用”(U)或 “空闲”(F)的文件,那么数据库服务器将它标记为“已删除” (D)。并在对包含该日志文件的 dbspace 和 root dbspace 采用 0 级备份之后,数据库服务器删除此日志文件并释放空间。
- 您不能删除当前使用(C)的日志文件或包含最近检查点记录(L)的日志文件。
- 将逻辑日志文件移动到另一个 dbspace 时,使用 onparams 命令添加或删除逻辑日志文件。
onparams -p: 更改物理日志参数

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -p | 更改物理日志 | 使用 onparams -p 命令时,必须包含 -s 参数。另外,您可以指定 -d 和 -y 参数。数据库服务器必须处于管理、在线或静态模式才能指定 -p 参数。数据库服务器无须重启,这些更改即可生效。 |
| -s size | 更改物理日志的大小(千字节) | 该值必须是大于等于 200 千字节的无符号整数。 注意: 如果将日志移动到没有足够连续空间的 dbspace 中或将日志大小增至超出可用连续空间,那么操作将发生失败,并且物理日志不会更改。 |
| -d dbspace | 将物理日志的位置更改为指定的 dbspace | 分配给物理日志的空间必须是连续的。 语法必须符合 Identifier 段; |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
- 当您更改物理日志时,数据库服务器必须处于在线或静态模式。且无需重启数据库服务器,这些更改即可生效。
- 更改物理日志大小或位置后请立即创建 root dbspace 的 0 级备份。该备份对于数据库服务器的正确恢复具有至关重要的作用。
onparams -b: 添加缓冲池
可以使用 onparams -b 命令创建与 dbspace 页大小相关联的缓冲池。
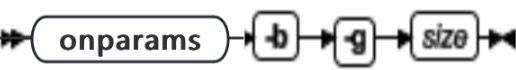
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -b | 创建缓冲池 | 可以在数据库服务器运行的同时添加缓冲池 |
| -g size | 指定要创建的缓冲区页的大小,以千字节 | 缓冲区页的大小必须在 2 到 16 KB 之间,并且必须是缺省页大小的倍数 |
- 创建的缓冲池中的所有其他特性将会设置为 BUFFERPOOL 配置参数的缺省值行中的字段的值。
- 使用非缺省页大小创建的每个 dbspace 都必须具有相应页大小的缓冲池。如果您创建的 dbspace 的页大小没有缓冲池,那么系统将自动使用 BUFFERPOOL 参数的缺省值行中的字段来创建缓冲池。
- 当您添加缓冲池时,新的 BUFFERPOOL 配置参数条目将会添加到 onconfig 文件中。
示例
onparams -a -d rootdbs -s 1000 # adds a 1000-KB log file to rootdbs
onparams -a -d rootdbs -i # inserts the log file after the current log
onparams -d -l 7 # drops log 7
onparams -p -d dbspace1 -s 3000 # resizes and moves physical-log to dbspace1
onparams -b -g 6 -n 3000 -r 2 -x 2.0 -m 1.0 # adds 3000 buffers of size
6K bytes each with 2 LRUS with maximum dirty of 2% and minimum dirty of 1%
从数据库服务器快照创建服务器
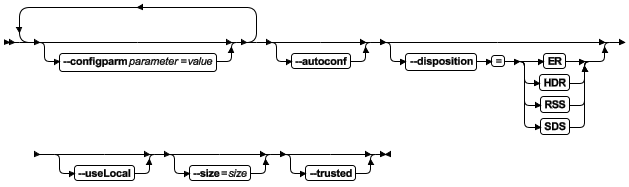
ifxclone 命令概览
可以使用 ifxclone 命令从当前的数据库服务器快照创建服务器。

Mandatory parameters

Optional parameters
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| disposition | 指定新服务器的最终规范 | 如果没有指定 --disposition (-d) 参数,那么将会创建一台标准服务器 |
| ER | 指定新服务器实例创建为复制服务器 | |
| HDR | 指定新服务器实例创建成为 HAC 辅助服务器 | |
| parameter=value | 指定可选的配置参数并且将值设置到目标服务器 | 确定源服务器的配置参数必须与目标服务器相符。 |
| RSS | 指定新数据库实例创建为远程独立辅助服务器 | |
| SDS | 指定新数据库实例创建为共享磁盘辅助服务器 | ifxclone 命令设置目标服务器的 SDS_PAGING 和 SDS_TEMPDBS 配置参数,但是全配置不在 ifxclone 命令范围之内。 如果命令中指定了 --disposition=SDS 但没指定 --useLocal ,您必须将 SSC 辅助服务器的 ROOTPATH 配置参数值设置得与主服务器上 ROOTPATH 配置参数值相同 |
| size | 指定目标服务器的大小。有效的值有 tiny 、small 、medium 和 large | 如果没有指定该大小参数,将会使用源实例的大小参数 |
| source_name | 指定源实例的名称 | 源服务器必须是主服务器并且不能是辅助服务器 |
| source_IP | 指定源服务器实例的 TCP/IP 地址 | |
| source_port | 指定源服务器实例的 TCP/IP 端口地址或与该端口关联的服务名称 | |
| target_name | 指定目标服务器实例的名称 | |
| target_IP | 指定目标服务器实例的 TCP/IP 地址 | |
| target_port | 指定目标服务器实例的 TCP/IP 端口地址或与该端口关联的服务名称 |
下表描述了有关 ifxclone 命令的选项。
| 长格式 | 短格式 | 含义 |
|---|---|---|
| --autoconf | -a | 新克隆服务器和高可用集群或 Enterprise Replicatio 域的其他服务器之间的自动配置连接。如果该选项用于创建复制服务器,那么 --autoconf 选项可以自动配置复制。 --autoconf 选项具有以下要求: ● 在目标服务器、源服务器和其他群集或复制服务器上,CDR_AUTO_DISCOVER 配置参数必须设置为 1。 ● REMOTE_SERVER_CFG 必须设置在所有群集或复制服务器上。 ● 源服务器的信任主机文件必须有目标服务器的主机信息 ● 如果使用 --disposition=ER 选项,并且主服务器为 Enterprise Replication 的一部分,那么在该域内的其他复制服务器必须是活动的 |
| --configParm | -c | 指定要设置到目标服务器上的配置参数的名称和值 |
| --disposition | -d | 指定新服务器示例的规定 |
| --help | -h | 显示用法信息 |
| --size | -s | 指定目标实例的大小 |
| --source | -S | 指定源服务器实例的名称 |
| --sourceIP | -I | 指定源服务器实例的 TCP/IP 地址 |
| --sourcePort | -P | 指定源服务器实例的 TCP/IP 端口地址或与该端口相关联的服务名 |
| --target | -t | 指定目标服务器实例的名称 |
| --targetIP | -i | 指定目标服务器实例的 TCP/IP 地址 |
| --targetPort | -p | 指定目标服务器实例的 TCP/IP 端口地址或与该端口相关联的服务名 |
| --trusted | -T | 指定该服务器是可以信任的,并且在访问服务器时不需要获取用户 ID 和密码 |
| --useLocal | -L | 指定源服务器 onconfig 文件中的配置信息应与目标服务器 onconfig 文件合并。 确定源服务器的配置参数必须与其在目标服务器上的内容相一致。 |
用法
源服务器是包含希望被克隆日期的服务器。目标服务器是从源服务器中加载数据的服务器。您必须从目标服务器运行 ifxclone 命令。
要在 UNIX™ 上运行 ifxclone 命令,在目标服务器上您必须以用户 root 、gbasedbt 或 gbasedbt 群组成员的身份运行该命令。您也必须是源服务器的 DBSA。
ifxclone 命令使用来自源服务器的 onconfig 和 sqlhosts 配置文件配置目标服务器。ifxclone 命令配置一些额外配置设置,不仅仅是配置克隆服务器的那些要求。--autoconf 选项提供额外配置 sqlhosts 文件记录的能力 ,之后会传播 sqlhosts 并对高可用集群服务器或 Enterprise Replication 域信任主机文件信息。ifxclone 命令并不意味着要配置所有可能的配置选项,而是提供克隆源服务器所需的足够的配置。
可以使用大小参数来配置 CPU VP 和缓冲区的数量。 表 1 列出了创建在目标服务器上每一大小选项的 CPU VP 和缓冲池的数量。目标系统创建之后,应执行额外细化的生成配置。如果大小配置省略,则使用在源服务器上配置的参数。
表. 大小参数值列表
| 大小 | CPU VP 数量 | 缓冲池数量 |
|---|---|---|
| tiny | 1 | 50,000 |
| small | 2 | 100,000 |
| medium | 4 | 250,000 |
| large | 8 | 500,000 |
可以使用 -c 选项在目标服务器上指定配置参数及其值。也可以使用已有的配置文件。如果目标服务器包含与源服务器配置文件不同的配置文件,ifxclone 命令不会重写该文件但是会修改那些克隆过程中必须与源服务器匹配的参数。
如果目标服务器位于与源服务器相同的主机上,那么需要使用 useLocal (-L) 参数。
如果指定了 useLocal 参数,ifxclone 命令会合并主服务器的 onconfig 文件和目标服务器的 onconfig 文件。所有服务器的前提条件 列出的配置参数会被 ifxclone 命令重写,其余的参数则不会受影响。
如果 useLocal 参数没有被指定为输入参数,ifxclone 命令使用源服务器的 onconfig 文件作为目标服务器的 onconfig 文件并且使用 ifxclone 命令输入的参数作为服务器的名称。
如果没有指定 useLocal 参数,ifxclone 命令使用目标服务器条目更新主机上的 sqlhosts 文件并且复制这些条目到目标服务器的 sqlhosts 文件中去。
以下是 ifxclone 参数选项的优先顺序:
- 在源服务器上 --configParm (-c) 参数优先于配置文件。
- --size (-s) 参数优先于合并的配置参数或本地配置文件中的设置。
- --configParm (-c) 参数优先于 --size (-s) 参数。
- 必须在每个服务器上相同的参数优先于所有其他选项。
所有服务器的前提条件
克隆服务器前请执行以下前提条件:
- 有关服务器硬件和软件的要求与与 HAC 辅助服务器的要求相同。(参考特定支持平台的machine notes)
- 源服务器和目标服务器必须在可信任的网络环境下。
- 如果目标服务器的配置被指定为 ER 或 RHAC ,那么在源服务器上您必须提供用户有连接到 sysadmin 数据库的权限。缺省情况下,仅允许用户 gbasedbt 连接 sysadmin 数据库。
- 同一时刻只能执行一次服务器克隆。直到第一次克隆完全结束才能开始第二次克隆。
- 源服务器必须将 onconfig 文件中的 ENABLE_SNAPSHOT_COPY 配置参数设置为 1 。
- 目标服务器必须没有旧 ROOTPATH 页。如果目标服务器有旧 ROOTPATH 页,那么创建一个零长度的 ROOTPATH 文件或将目标服务器的 onconfig 文件中的 FULL_DISK_INIT 配置参数设置为 1。
在克隆服务器的过程中不允许执行存档操作命令(例如:ontape 和 ON-Bar 命令)。请在开始克隆服务器之前执行存档活动。
在开始克隆服务器之前,必须在目标服务器上设置以下环境变量:
- GBASEDBTDIR
- ONCONFIG
- GBASEDBTSQLHOSTS
- GBASEDBTSERVER
必须在源和目标服务器上标识以下配置参数的值:
- DRAUTO
- DRINTERVAL
- DRTIMEOUT
- LOGBUFF
- LOGFILES
- LOGSIZE
- LTAPEBLK
- LTAPESIZE
- ROOTNAME
- ROOTSIZE
- PHYSBUFF
- PHYSFILE
- STACKSIZE
- TAPEBLK
- TAPESIZE
如果目标服务器中的 MIRROR 配置参数可用,那么以下配置参数必须在源和目标服务器之间相匹配:
- MIRRORPATH
- MIRROROFFSET
数据库服务器在源和目标服务器上允许只有某些组合 MIRROR 配置参数。请参阅下表.
表. 源和目标服务器上 MIRROR 配置参数允许的设置
| 设置于源服务器上的MIRROR 配置参数 | 设置于目标服务器上的 MIRROR 配置参数 | 允许或不允许 |
|---|---|---|
| No | No | 允许 |
| Yes | Yes | 允许 |
| Yes | No | 允许 |
| No | Yes | 不允许。如果配置了该设置,那么服务器会在目标服务器的 onconfig 文件中提出警告并禁用 MIRROR 参数。 |
克隆 RHAC 辅助服务器的前提条件
- 在目标服务器上设置一下环境变量:
- GBASEDBTDIR
- ONCONFIG
- GBASEDBTSQLHOSTS
- GBASEDBTSERVER
-
在目标服务器上,创建存在于源服务器上所有的 chunk 和镜像 chunk 。如果目标服务器使用镜像,那么镜像 chunk 的路径必须与其在与服务器上的路径相匹配并且这些 chunk 必须存在。执行以下步骤来为目标服务器创建 chunk 和(如果必要)镜像 chunk :
a. 在源服务器上,运行 onstat -d 命令显示 chunk 和 镜像 chunk 的列表:
onstat -db. 在目标服务器上,以用户 gbasedbt 的身份登录并使用命令 touch 、chown 和 chmod 创建被 onstat -d 命令报告的 chunk 。例如,要创建名为 /usr/gbasedbt/chunks/rootdbs.chunk 的 chunk,请执行以下步骤:
$ su gbasedbt
Password:
$ touch /usr/gbasedbt/chunks/rootdbs.chunk
$ chown gbasedbt:gbasedbt /usr/gbasedbt/chunks/rootdbs.chunk
$ chmod 660 /usr/gbasedbt/chunks/rootdbs.chunkc. 对 onstat -d 命令报告的每个 chunk 重复执行上一步中的所有命令。3. 在目标服务器上,运行带适当参数的 ifxclone 命令。4. 可以选择在目标服务器上创建 onconfig 和 sqlhosts 文件。
-
在目标服务器上,运行带适当参数的 ifxclone 命令。
-
可以选择在目标服务器上创建 onconfig 和 sqlhosts 文件。
示例 1,使用源服务器配置克隆一台 RHAC 辅助服务器
该示例显示了如何使用来自源服务器上的 onconfig 和 sqlhosts 配置文件配置服务器。
在本示例中,忽略了 -L 选项引起的 ifxclone 命令从源服务器检索重要配置信息。该配置文件作为创建目标服务器配置的模板。使用 ifxclone 命令创建配置文件可以节省时间并减少其向配置文件中介绍错误的的机会。
对于本示例,假设源服务器 (Amsterdam)将 sqlhosts 文件配置如下:
#Server Protocol HostName Service Group
Amsterdam onsoctcp 192.168.0.1 123 -
还必须具有目标服务器的名称、IP 地址和端口号。本示例使用了以下信息:
- 源:服务器名称 Amsterdam
- 源 IP 地址:192.168.0.1
- 源端口: 123
- 目标服务器名称: Berlin
- 目标 IP 地址: 192.168.0.2
- 目标端口: 456
- 在目标服务器上,以用户 gbasedbt 的身份登录并使用 touch 、chown 和 chmod 命令创建 chunk、更改其所有者并更改其许可权。Chunk 路径必须与 chunk 在源服务器上的路径匹配。
- 在目标服务器上,运行 ifxclone命令:
ifxclone -T -S Amsterdam -I 192.168.0.1 -P 123 -t Berlin -i 192.168.0.2 -p 456 -d RSS
ifxclone 命令修改源服务器上的 sqlhosts 文件,并在新目标服务器上创建该文件的副本。目标服务器上的 sqlhosts 文件与源服务器上的相同:
#Server Protocol HostName Service Group DEFAULT
Amsterdam onsoctcp 192.168.0.1 123 - N
Berlin onsoctcp 192.168.0.2 456 N
示例 2,通过合并源服务器配置克隆 RHAC 辅助服务器
使用 -L (--useLocal) 选项在远程主机上创建服务器的克隆:-L 选项用于将源 onconfig 文件配置信息与目标 onconfig 文件合并。此选项还将把源 sqlhosts 文件复制到目标服务器。本示例使用以下信息:
- 源服务器名称: Amsterdam
- 源 IP 地址:192.168.0.1
- 源端口: 123
- 目标服务器名称: Berlin
- 目标 IP 地址: 192.168.0.2
- 目标端口: 456
- 在目标计算机上创建 onconfig 和 sqlhosts 文件并设置环境变量。
- 在目标服务器上,以用户 gbasedbt 的身份登录并使用 touch 、chown 和 chmod 命令创建 chunk、更改其所有者并更改其许可权。Chunk 路径必须与 chunk 在源服务器上的路径匹配。
- 在目标服务器上 ,运行 ifxclone 命令:
ifxclone -T -L -S Amsterdam -I 192.168.0.1 -P 123 -t Berlin -i 192.168.0.2 -p 456 -d RSS
示例 3,向集群添加一台 RHAC 辅助服务器
该示例显示了如何向现有的 GBase 8s 高可用性集群添加 RHAC 辅助服务器。本示例使用以下信息:
- 源服务器名称: Amsterdam
- 源 IP 地址:192.168.0.1
- 源端口: 123
- 目标服务器名称: Berlin
- 目标 IP 地址: 192.168.0.2
- 目标端口: 456
- 在目标计算机上创建 onconfig 和 sqlhosts 文件并设置环境变量。
- 在目标服务器上,以用户 gbasedbt 的身份登录并使用 touch 、chown 和 chmod 命令创建 chunk、更改其所有者并更改其许可权。Chunk 路径必须与 chunk 在源服务器上的路径匹配。
- 在目标服务器上 ,运行 ifxclone 命令:
ifxclone -T -L -S Amsterdam -I 192.168.0.1 -P 123 -t Berlin -i 192.168.0.2 -p 456 -s medium -d RSS
克隆 ER 服务器的前提条件
在尝试克隆 ER 服务器前请完成以下前提条件。
- 源服务器(要被克隆的服务器)必须有 ER 配置并激活。
- 对于指定目录名的配置参数,其目录名必须存在于目标服务器上。例如:如果在源服务器上要将 CDR_LOG_STAGING_DIR 配置参数设置为目录名,那么此目录也必须在目标服务器上存在。
- 如果源服务器上的 ATS 或 RIS 可用,那么目标服务器上必须有适当的 ATS 或 RIS 目录。如果目录不存在那么 ATS/RIS spooling 将会失败。
- 如果源服务器已设置了 CDR_SERIAL 配置参数,那么您必须在要克隆的服务器上将 CDR_SERIAL 的值设置成不同的值。在所有复制服务器上,CDR_SERIAL 的值必须都不相同。可以在 ifxclone 命令行中使用 --configParm (-c) 参数指定 CDR_SERIAL 配置参数的唯一值。
- 新 ER 克隆上的时间必须适当同步。
- 源服务器(要被克隆的服务器)必须没有任何已停止或暂停的复制,也不能有任何影子复制定义。
在 ifxclone 命令运行过程中,避免执行更改目标服务器参与的复制集的 ER 管理任务。
示例:创建一台 ER 服务器克隆
假设有五台服务器:S1、S2、S3、S4 和 S5。它们在 ER 域中并配置为根服务器。您想要在名为 machine6 的电脑上添加新的服务器—— S6,并且希望它拥有和 S3 服务器一样的数据。
- 在 machine6 上安装并配置 GBase 8s 数据库软件。您可以使用部署命令部署预配置的数据库服务器实例。
- 将 S3 服务器上的 sqlhosts 文件辅导到 S6 服务器并修改它,为新服务器添加新条目。例如,假设新服务器的 ER 群组名为 g_S6 且ID 为 60,sqlhosts 文件将添加如下新行:
g_S6 group - - i=60
S6 onsoctcp machine6 service6 g=g_S6
- 向其他五台服务器( S1 到 S5)上的 sqlhosts文件中添加以上两行内容。
- 将 S3 服务器上的 onconfig 文件复制到 S6 服务器。并将 DBSERVERNUM 配置参数更改为 S6 服务器的端口号。不要修改除路径信息以外的任意存储或 chunk 参数。
- S6 服务器 (machine6) 提供 chunk 路径和其他存储到服务器 S3 大小相同。确保 S6 有足够的内存和磁盘空间资源。
- 以用户 gbasedbt 的身份运行以下命令:
ifxclone -L -S S3 -I machine3 -P service3 -t S6 -i machine6 -p service6 -d ER
执行时,输入用户 gbasedbt 的用户名 gbasedbt 及其密码。
- 监视 S6 和 S3 服务器的服务器日志。当克隆进程结束后,可以在服务器 S3 和 S6 上运行以下命令来检查服务器的状态:
cdr list server
您可以看到新的 ER 服务器 g_S6 连接了所有其他五台服务器。此外,ER 节点 g_S6 将加入所有 g_S3 所加入的 ER 节点。
管理数据库存储空间
onspaces 语法概述
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -V | 显示软件版本号及序列号 | |
| -version | 显示构件版本、主机、操作系统、编号、日期及 GLS 版本 |
onspaces -a: 向 dbspace 或 blobspace 添加 chunk

使用 onspaces -a 向 dbspace 或 blobspace 添加 chunk 。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -a | 指示要添加 chunk | 一个实例中至多包含 32766 个 chunk 。可以将所有的这些 chunk 放置到一个存储空间或分割在多个存储空间中 |
| -m pathname offset | 指定镜像新 chunk 的 chunk 的可选路径名和偏移量。另见此表中的 pathname 和 offset 条目 | |
| -o offset | 在 -a 选项之后,offset 指示为到达新 blobspace 或 dbspace 的初始 chunk 所发生的磁盘分区或设备中的偏移量(千字节) | 无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小,最大偏移量是 4 太字节。 |
| -p pathname | 指示正在添加的 blobspace 或 dbspace 的初始 chunk 的磁盘分区或为缓冲设备 Chunk 必须是现有的未缓冲设备或已缓冲文件 | Chunk 名最多可以有 128 字节。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始数据库服务器时的当前目录的目录。 UNIX™ 示例(未缓冲的设备) : /dev/rdsk/c0t3d0s4 UNIX 示例(已缓冲的设备): /ix/ids9.2/db1chunk 有关路径名语法。 |
| -s size | 指示新 blobspace 或 dbspace chunk 的大小(以千字节) | 无符号整数。大小必须等于或大于 1000 字节,并且必须是页大小的倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。最大偏移量是 4 太字节 |
| blobspace | 给出 chunk 将添加至的 blobspace 的名称 | |
| dbspace | 给出 chunk 将添加至的 dbspace 的名称 |
onspaces -a: 向 sbspace 添加 chunk

使用 onspaces -a 可向 sbspace 添加 chunk 。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -a | 指示要添加的 chunk | 一个实例中至多包含 32766 个 chunk 。可以将所有的这些 chunk 放置到一个存储空间或分割在多个存储空间中 |
| -m pathname offset | 指定镜像新 chunk 的 chunk 的可选路径名和偏移量。另见此表中的 pathname 和 offset 条目 | |
| -Mo mdoffset | 指示应存储元数据的磁盘空间或设备中的偏移量(千字节) | 值可以是 0 到 chunk 大小之间的整数。您不能指定导致元数据空间结束处超过 chunk 结束处的偏移量。 |
| -Ms mdsize | 指定在初始 chunk 中分配的元数据区域的大小(千字节)。剩下的是用户数据空间 | 值可以是 0 到 chunk 大小之间的整数。 |
| -o offset | 在 -a 选项之后,offset 指示为到达新 blobspace 或 dbspace 的初始 chunk 所发生的磁盘分区或未缓冲设备中的偏移量(千字节) | 无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。最大偏移量为 2 或 4 千兆字节,这与平台有关。 |
| -p pathname | 指示正在创建的 sbspace 初始 chunk 的磁盘分区或未缓冲设备。 Chunk 必须是现有的未缓冲设备或已缓冲文件 | Chunk 名最多可以有 128 字节。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器的当前目录的目录。 |
| -U | 指定应将整 chunk 用于存储用户数据 | -M 和 -U 选项是互斥的。 |
| -s size | 指定新 sbspace chunk 的大小(千字节) | 无符号整数。大小必须等于或大于 1000 字节,并且必须是页大小的倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大偏移量是 4 太字节 |
| sbspace | 给出 chunk 将添加至的 sbspace 的名称 |
onspaces -c -b: 创建 blobspace

可以使用 onspaces -c -b 创建 blobspace。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -b blobspace | 给出要创建 blobspace 的名称 | Blobspace 名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 |
| -c | 创建 dbspace 、blobspace 、 sbspace 或 extspace 最多可以创建 2047 个任意类型的存储空间 | 创建存储空间之后,必须备份该存储空间和 root dbspace。如果所创建的存储空间名称与已删除存储空间的名称相同,那么执行另一个 0 级备份,以确保以后的恢复不混淆新存储空间和旧存储空间。 |
| -g pageunit | 根据 page_unit(实例基本页大小的数量,2 K 或 4 K)指定 blobspace blobpage 的大小 | 无符号整数。值必须大于 0 。 Blobspace 最多能包含 2147483647 页。因此,blobspace 大小限制为 blobpage 大小 x 2147483647。它包括组成 blobspace 的所有的 chunk 中的 blobpage。 |
| -m pathname offset | 指定 chunk 的可选路径名和偏移量,该 chunk 镜像新 blobspace 或 dbspace 的初始 chunk | |
| -o offset | 指示为到达新 blobspace 、dbspace 或 sbspace 的初始 chunk 所发生的磁盘分区或设备中的偏移量(千字节) | 无符号整数。无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。最大偏移量为 2 或 4 太兆字节,这与平台有关。 |
| -p pathname | 指示正在创建的 blobspace 或 dbspace 的初始 chunk 的磁盘分区或设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 UNIX™ 示例 (未缓冲的设备):/dev/rdsk/c0t3d0s4 UNIX 示例(已缓冲的设备) /ix/ids9.2/db1chunk |
| -s size | 指定新 blobspace 或 dbspace 初始 chunk 的大小(千字节) | 无符号整数。大小必须等于或大于 1000 千字节,并且必须是页大小的整倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大 chunk 大小为 2 或 4 太字节。这与平台有关。 |
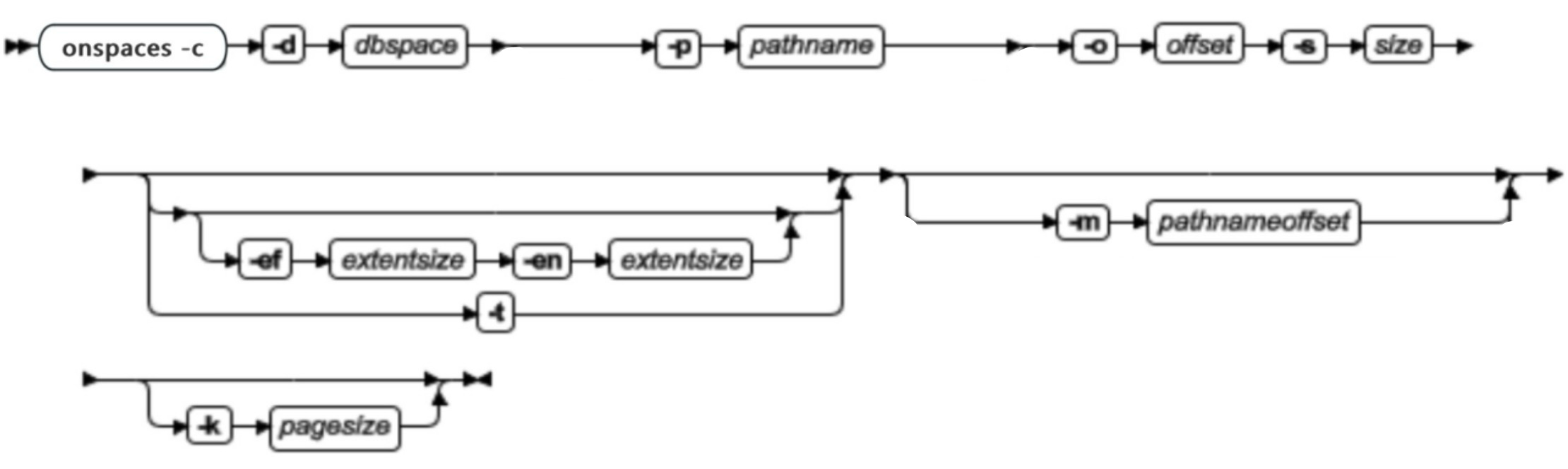
onspaces -c -d: 创建 dbspace
可以使用 onspaces -c -d 命令创建 dbspace 或临时 dbspace 。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -c | 创建 dbspace 最多可以创建 2047 个任意类型的存储空间 | 创建存储空间之后,必须备份该存储空间和 root dbspace。如果所创建的存储空间名称与已删除存储空间的名称相同,那么执行另一个 0 级备份,以确保以后的恢复不混淆新存储空间和旧存储空间。 有关更多信息,请参管理数据库空间。 |
| -d dbspace | 给出要创建的 dbspace 的名称 | Dbspace 名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 |
| -ef extentsize | 指定 tblspace tblspace 的第一个 extent 的大小(千字节) | 非根 dbspace 的 tblspace tblspace 的第一个 extent 的最小和缺省大小等于 50 个 dbspace 页(以 KB 为单位)。例如,对于页大小为 2 KB 的dbspace,该大小为 100 KB ;对于页大小为 4 KB 的 dbspace,该大小为 200 KB ;对于页大小为 8 KB 的 dbspace,该大小为 400 KB。 Tblspace tblspace extent 的最大大小为 1048572 个页。在页面大小为 2 KB 的系统上,这将等于大约 2 GB 。 |
| -en extentsize | 指定 tblspace tblspace 的下一个 extent 的大小(千字节) | 非根 dbspace 的 tblspace tblspace 的下一个 extent 的最小大小等于 4 个 dbspace 页(以 KB 为单位)。例如,对于页大小为 2 KB 的 dbspace,该大小为 8 KB ;对于页大小为 4 KB 的dbspace,该大小为 16 KB ;对于页大小为 8 KB 的 dbspace,该大小为 32 KB。 下一个 extent 的缺省大小是 50 个 dbspace 页。 Tblspace tblspace extent 的最大大小为 1048572 个页。在页面大小为 2 KB 的系统上,这将等于大约 2 GB 。 如果主要 chunk 中没有足够的空间分配给下一个 extent ,那么extent 将从另一个 chunk 分配。如果指定的空间不可用,那么将分配最接近的可用空间。 |
| -k pagesize | 指示新的 dbspace 的非缺省的页大小(千字节) 对于具有充足的存储空间的系统,使用较大的页面大小具有以下性能优点: ● 可降低 B-tree 索引的深度,即使是对于较小的索引键 ● 您可以将当前跨越多个页面(页面大小为缺省页面大小)的长行组合到同一页中 ● 检查点时间通常会随页面大小的增大而减少 ● 您可以为临时表定义不同的页面大小,这样它们将具有独立的缓冲池 | 页大小必须在 2 KB 和 16 KB 之间,并且必须是缺省页大小的倍数。例如:如果缺省页大小是 2 KB ,那么 pagesize 可以是 2 、4 、6 、8 、10 、12 、14 或 16 。 |
| -m pathname offset | 指定 chunk 的可选路径名和偏移量,该 chunk 对新的 dbspace 的初始 chunk 执行镜像操作 另见此表中的 -p pathname 和 -o offset 条目 | |
| -o offset | 指示为到达新的 dbspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 无符号整数。无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大偏移量为 2 或 4 太兆字节,这与平台有关。 |
| -p pathname | 指示正在创建的 dbspace 的初始 chunk 的磁盘分区或设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 UNIX™ 示例 (未缓冲的设备):/dev/rdsk/c0t3d0s4 UNIX 示例(已缓冲的设备) /ix/ids9.2/db1chunk |
| -s size | 指示新的 dbspace 初始 chunk 的大小(千字节) | 无符号整数。大小必须等于或大于 1000 千字节,并且必须是页大小的整倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大 chunk 大小为 2 或 4 太字节。这与平台有关。 |
| -t | 创建临时 dbspace 以存储临时表 | 不能镜像临时 dbspace 。您不能为临时 dbspace 的 tblspace tblspace 指定第一个 extent 和下一个 extent 的大小。 |
- dbspace 的最大大小等于 chunk 的最大数量乘以 chunk 的最大大小。
- 每个实例中 chunk 的最大数量为 32766 。
- Chunk 最大大小等于 2147483647 页乘以页大小。
- 创建 dbspace 之后,您不能更改它的页大小。
- 在不是缺省的平台页大小的 dbspace 中,您不能存储逻辑日志或物理日志。
- 如果 dbspace 创建时该页大小的缓冲池不存在,那么 GBase 8s 会使用 BUFFERPOOL 参数的 default 行的字段值来创建一个缓冲池。
- 不能使多个缓冲池具有相同页大小。
- 当使用 onspaces 创建临时 dbspace 时,需要将新的临时 dbspace 的名称添加到临时 dbspace 的列表中并重新启动数据库服务器。
- 不能指定临时 dbspace 的第一个 extent 和下一个 extent 。
- 临时 dbspace 的extent 大小是 100 KB (2 KB 页的系统) 或者 200 KB( 4 KB 页的系统)。
onspaces -c -P: 创建 plogspace
使用 onspaces -c -P 命令创建 plogspace 以存储物理日志。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -c | 创建 plogspace | 一个实例只能有一个 plogspace 。如果 plogspace 存在,那么创建新 plogspace 将物理日志移动到此新的空间中,并删除旧的 plogspace 。 |
| -m pathname offset | 指定 chunk 的可选路径名和偏移量,并对新的 plogspace 的初始 chunk 执行镜像操作 另见此表中的 -p pathname 和 -o offset 条目 | 如果镜像了该 plogspace ,那么 plogspace chunk 不能被扩展 |
| -o offset | 指示为到达新的 plogspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 无符号整数。无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 偏移量必须是页大小的倍数。最大偏移量为 2 或 4 TB,这与平台有关。 |
| -P plogspace | 给出要创建的 plogspace 的名称 | Plogspace 名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 语法必须符合 Identifier 段。 |
| -p pathname | 指示正在创建的 plogspace 的初始 chunk 的磁盘分区或设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 UNIX™ 示例(未缓冲的设备): /dev/rdsk/c0t3d0s4 UNIX 示例(已缓冲的设备): /ix/ifmx/db1chunk |
| -s size | 指示新的 plogspace chunk 的大小(千字节) | 无符号整数。大小必须等于或大于 1000 千字节,并且必须是页大小的整倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大 chunk 大小为 2 或 4 TB。这与平台有关。 |
- 物理日志必须存储在单独的 chunk 中。缺省情况下,plogspace 的 chunk 是可扩展的,并且数据库服务器会扩展 plogspace 以提高性能。
示例
以下示例创建了一个名为 plogdbs 的 plogspace,它有 40000 KB 大小且偏移量为 0 :
onspaces -c -P plogdbs -p /dev/chk1 -o 0 -s 40000
以下示例创建了一个已镜像的 plogspace,它的名称为 pdbs1 ,大小为 60000 KB ,偏移量为 500 KB:
onspaces -c -P pdbs1 -p /dev/pchk1 -o 500 -s 60000 -m /dev/mchk1 0
onspaces -c -S: 创建 sbspace
可以使用 onspaces -c -S 选项创建 sbspace 或临时 sbspace 。
语法:

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -S sbspace | 给出要创建的 sbspace 名 | Sbspace 名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 语法必须符合 Identifier 段; |
| - c | 创建 sbspace 最多可创建 32767 个任意类型的存储空间 | 无 |
| -m pathname offset | 指定到镜像新 sbspace 的初始 chunk 的 chunk 的可选路径名和偏移量。另见此表中的 -p pathname 和 -o offset 条目 | |
| -Mo mdoffset | 指示将存储元数据的磁盘分区或设备中的偏移量(千字节) | 限制: 值可以是 0 到 chunk 大小之间的整数。您不能指定导致元数据空间结束处超过 chunk 结束处的偏移量。 |
| -Ms mdsize | 指定初始 chunk 中分配的元数据区域的大小(千字节) 剩下的是用户数据空间 | 限制:值可以是 0 到 chunk 大小之间的整数 |
| -o offset | 指示为到达新的 sbspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 限制:无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。对具有 2 千字节页大小的系统,最大 chunk 大小是 4 太字节 ,对具有 4 千字节页大小的系统,最大 chunk 大小是 8 太字节 。 |
| -p pathname | 指示 sbspace 初始 chunk 的磁盘分区或未缓冲设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 |
| -s size | 指示新 sbspace 初始 chunk 的大小(千字节) | 限制:无符号整数。大小必须等于或大于 1000 千字节,并且必须是页大小的整倍数。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大 chunk 大小为 2 或 4 太字节。这与平台有关。 |
| -t | 创建用于存储临时智能大对象的临时 sbspace 。您可以指定元数据区域的大小和偏移量 | 限制: 不能镜像临时 sbspace 。您可以指定任何 -Df 选项(LOGGING=ON 选项除外,它不会生效) |
| -Df default list | 列出存储在 sbspace 中智能大对象的缺省规范 | 限制:用逗号分隔标记,如果未提供标记,那么优先使用系统缺省值。在命令行上,该列表必须括在双引号(")中。 |
default list: 指定缺省规范,这些规范影响存储在 sbspace 中的智能大对象的行为。下表描述了标记及其缺省值。
| 标记 | 值 | 缺省值 | 描述 |
|---|---|---|---|
| ACCESSTIME | ON 或 OFF | OFF | 设置为 ON 时,数据库服务器跟踪对存储在 sbspace 中的所有智能大对象的访问时间。 |
| AVG_LO_SIZE | UNIX™: 2 到 2**31 | 8 | 指定存储在 sbspace 中智能大对象的平均大小(千字节) 数据库服务器使用该值计算元数据区域的大小。不要一起指定 AVG_LO_SIZE 和 -Ms 。可以一起指定 AVG_LO_SIZE 和元数据偏移量(-Mo) 。 如果智能大对象的大小超过 2**31,那么指定 2**31。如果智能大对象的大小小于 2 (在 UNIX 上)或小于 4 (在 Windows 中),那么指定 2 或 4 。 如果耗尽 sbspace 中元数据和保留区域中的空间,那么返回错误 131 。要将额外的 chunk 分配给仅由元数据区域构成的 sbspace,请使用 -Ms 选项。 |
| BUFFERING | ON 或 OFF | ON | 指定存储在 sbspace 中智能大对象的缓冲方式 如果设置为 ON ,那么对于智能大对象 I/O 操作,数据库服务器使用共享内存常驻部分中的缓冲池。如果设置为 OFF,那么数据库服务器使用共享内存虚拟部分中的轻量级 I/O 缓冲区(轻量级 I/O 操作)。 BUFFERING = OFF 与 LOCK_MODE = RANGE 不兼容,会产生冲突。 |
| LOCK_MODE | RANGE 或 BLOB | BLOB | 指定存储在 sbspace 中的智能大对象的锁定方式 如果设置为 RANGE ,那么只锁定智能大对象中一定范围内的字节。如果设置为 BLOB ,那么锁定整个智能大对象。 LOCK_MODE = RANGE 与BUFFERING = OFF 不兼容,会产生冲突。 |
| LOGGING | ON 或 OFF | OFF | 指定存储在 sbspace 中的智能大对象的登录状态 如果设置为 ON,那么数据库服务器将更改记录到 sbspace 中的用户数据区域。在打开 sbspace 的日志记录时,对 sbspace 进行 0 级备份。 当关闭日志记录时,显示以下消息:您正在关闭智能大对象日志记录 |
| EXTENT_SIZE | 4 到 2**31 | 无 | 指定创建表时首次分配给存储在 sbspace 中的智能大对象的磁盘空间的大小(千字节) 让系统选择 EXTENT_SIZE 值。为减少智能大对象中 extent 的数量,请使用 mi_lo_specset_estbytes (DataBlade API)或 ifx_lo_specset_estbytes (GBase 8s ESQL/C) 对系统指示智能大对象的大小合计。系统尝试向智能大对象分配单个 extent。 |
| MIN_EXT_SIZE | 2 到 2**31 | UNIX: 2 | 指定分配给每个智能大对象的最小空间量(千字节) 将显示以下信息:正在更改 sbspace 最小 extent 大小:旧值 value1 新值value2 。 |
| NEXT_SIZE | 4 到 2**31 | 无 | 指定当前 sbspace 中初始 extent 已满时,下次分配给智能大对象的磁盘空间 extent 大小(千字节)让系统选择 NEXT_SIZE 值。要减少智能大对象中 extent 的数量,请使用 mi_lo_specset_estbytes 或 ifx_lo_specset_estbytes 对系统指示智能大对象的大小合计。系统尝试向智能大对象分配单个 extent。 |
示例
例1.创建 1000 千字节的临时 sbspace,在 SBSPACETEMP 配置参数中指定临时 sbspace 的名称。重新启动数据库服务器,从而使它可使用临时 sbspace 。 :
onspaces -c -S tempsbsp -t -p ./tempsbsp -o 0 -s 1000
例2.使用以下规范创建 20 兆字节的镜像 sbspace(eg_sbsp):主 chunk 和镜像 chunk 的偏移量为 500 千字节;元数据区域的偏移量为 200 千字节;平均期望智能大对象大小为 32 千字节;将更改记录到 sbspace 的用户数据区域中的智能大对象中。
onspaces -c -S eg_sbsp -p /dev/raw_dev1 -o 500 -s 20000 -m /dev/raw_dev2 500 -Mo 200 -Df "AVG_LO_SIZE=32,LOGGING=ON"
onspaces -c -x: 创建 extspace
使用 onspaces -c -x 选项创建 extspace。
语法:
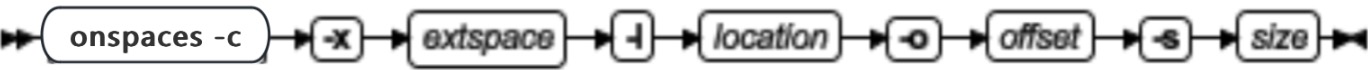
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| - c | 创建 dbspace 、blobspace、 sbspace 或 extspace 最多可以创建 2047 个任意类型的存储空间 | 创建存储空间之后,必须备份该存储空间和 root dbspace。如果所创建的存储空间名称与已删除存储空间的名称相同,那么执行另一个 0 级备份,以确保以后的恢复不混淆新存储空间和旧存储空间。 |
| -l location | 指定 extspace 的位置 存取方法决定该字符串的格式 | 限制:String 。值不得长于 255 字节。 |
| -o offset | 指示为到达新的 blobspace、dbspace 或 sbspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 限制:无符号整数。无符号整数。开始偏移量必须大于等于 0 。 开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大偏移量为 2 或 4 太兆字节,这与平台有关。 |
| -s size | 指示新的 blobspace 或 dbspace 初始 chunk 的大小(千字节) | 限制: 无符号整数。大小必须等于或大于 1000 千字节,并且必须是页大小的整倍数。 开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大 chunk 大小为 2 或 4 太字节。这与平台有关。 |
| -x extspace | 给出要创建的 extspace 的名称 | 限制:Extspace 的名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 |
onspaces -ch: 更改 sbspace 缺省规范
可以使用 onspaces -ch 选项更改 sbspace 缺省规范。使用 onspaces -ch 选项可以更改任何 -Df 标记。数据库服务器将此更改应用于在更改缺省规范之前创建的每个智能大对象。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -ch | 指示要更改的一个或多个 sbspace 缺省规范 | 无 |
| sbspace | 给出要更改其缺省规范的 sbspace 名称 | 语法必须符合 Identifier 段; |
| -Df default list | 列出存储在 sbspace 中的智能大对象的新缺省规范 | 用逗号分隔标记。如果未提供标记,那么优先使用系统缺省值。在命令行上,该列表必须括在双引号(") 中。 |
例如:要关闭在使用 -Df 选项创建 Sbspace中创建的 sbspace 的日志记录,请使用以下命令:
onspaces -ch eg_sbsp -Df "LOGGING=OFF"
在打开 sbspace 的日志记录之后,对 sbspace 进行 0 级备份以创建恢复点。
onspaces -cl: 清除 sbspace 中的游离智能大对象
可以使用 onspaces -cl 选项清除 sbspace 中的游离智能大对象。在正常运行过程中,不应存在任何未使用(游离)的智能大对象。删除智能大对象时,释放空间。如果在删除智能大对象时数据库服务器失败或耗尽系统内存,那么智能大对象可能作为游离对象保留。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -cl | 清除 sbspace 中的游离智能大对象 | 要查找任何游离智能大对象,请在没有用户连接到数据库服务器时使用 oncheck -pS 命令。引用计数为 0 的智能大对象为游离对象。 |
| sbspace | 给出要清除的 sbspace 的名称 | 语法必须符合 Identifier 段; |
示例
以下是 onspaces -cl 命令的一个示例:
onspaces -cl myspace
onspaces -d: 删除 dbspace 、blobspace 或 sbspace 中的 chunk
可以使用 onspaces -d 选项删除 dbspace 、blobspace 或 sbspace 中的 chunk 。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d | 删除 chunk | 当数据库服务器处于在线或静态模式时,您可以删除 dbspace 、临时 dbspace 或 sbspace 中的 chunk。 您只能在数据库服务器处于静态模式时才能删除 blobspace 中的 chunk |
| -f | 删除包含用户数据但不包含元数据的 sbspace chunk 。如果 chunk 包含 sbspace 的元数据,那么必须删除整个 sbspace | 只对 sbspace 使用 -f 选项。如果省略 -f 选项,那么不能删除包含数据的 sbspace 。 |
| -o offset | 指示为到达您正在删除的 dbspace 、blobspace 或 sbspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 限制:无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大偏移量是 4 太字节。 |
| -p pathname | 指示您正在删除的 dbspace 、blobspace 或 sbspace 的初始 chunk 的磁盘分区或未缓冲设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| blobspace | 给出要删除其 chunk 的 blobspace 的名称 | 语法必须符合 Identifier 段; |
| dbspace | 给出要删除其 chunk 的 dbspace 的名称 | 语法必须符合 Identifier 段; |
| sbspace | 给出要删除其 chunk 的 sbspace 的名称 | 语法必须符合 Identifier 段; |
必须指定路径名以指示数据库服务器您正在删除 chunk 。
onspaces -d: 删除空间
可以使用 onspaces -d 选项删除 dbspace 、blobspace 、plogspace 、sbspace 或 extspace 。
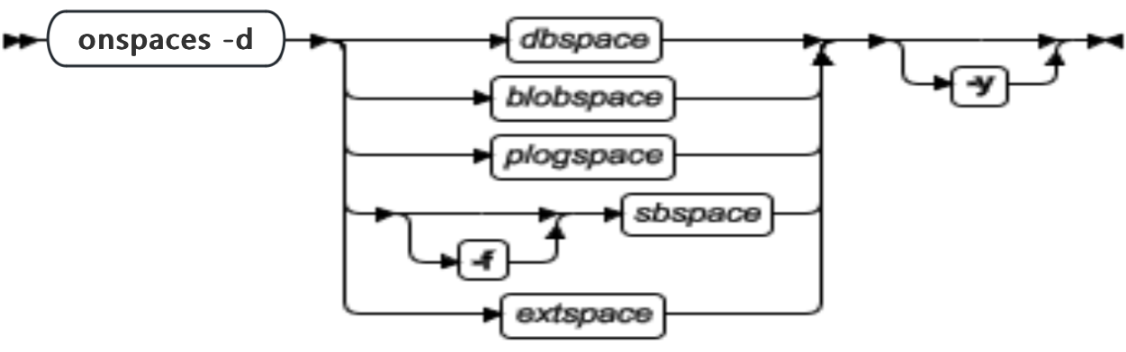
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -d | 指示要删除的存储空间 | 可以在数据库服务器处于在线或静态模式时删除 dbspace 、blobspace 、plogspace 、sbspace 或 extspace。 删除存储空间之后,必须对它进行备份,以确保 sysutils 数据库和保留页时最新的。 执行 oncheck -pe ;来验证当前没有表正向 dbspace 、blobspace 或 sbspace 存储数据 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| -f | 删除包含用户数据和元数据的 sbspace | 必须使用 -f(强制)选项来删除含有数据的 sbspace 。 限制: 仅对 sbspace 使用 -f 选项。 警告: 如果使用 -f 选项,那么数据库服务器中的表可能含有指向已使用该选项删除的智能大对象的死指针 |
| blobspace | 给出要删除的 blobspace 的名称 | 在删除 blobspace 之前,请删除包含引用 blobspace 的 TEXT 或 BYTE 列的所有表 |
| dbspace | 给出要删除的 dbspace 的名称 | 在删除 dbspace 之前,请删除先前在 dbspace 中创建的所有数据库和表 |
| extspace | 给出要删除的 extspace 的名称 | 如果 extspace 与现有表或索引相关联,那么您无法删除它 |
| plogspace | 给出要删除的 plogspace 的名称 | 在删除之前,plogspace 必须为空 |
| sbspace | 给出要删除的 sbspace 的名称 | 在删除 sbspace 之前,请删除包含引用 sbspace 的 BLOB 或 CLOB 列的所有表 |
删除这些存储空间时不要指定路径名。
onspaces -f: 指定 DATASKIP 参数
可以使用 onspaces -f 选项指定 DATASKIP 配置参数的值。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -f | 向数据库服务器指示您想要更改指定 dbspace 或所有 dbspace 的 DATASKIP 缺省值 | DATASKIP 状态中的所有更改都记录在消息日志中 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| dbspace-list | 指定将打开(ON)或关闭(OFF)其 DATASKIP 的一个或多个 dbspace 的名称 | 语法必须符合 Identifier 段; |
| OFF | 关闭 DATASKIP | 如果使用 OFF 时未使用 dbspace-list ,那么对所有分片关闭 DATASKIP 。如果与 dbspace-list 一起使用 OFF ,那么只有指定分片被设置为 DATASKIP 关闭 |
| ON | 打开 DATASKIP | 如果使用 ON 时未使用 dbspace-list ,那么对所有分片打开 DATASKIP 。如果与 dbspace-list 一起使用 ON ,那么只有指定分片被设置为 DATASKIP 打开 |
onspaces -m: 启动镜像
可以使用 onspaces -m 选项启动 dbspace 、blobspace 或 sbspace 的镜像。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -f filename | 指示 chunk 位置信息是在名为 filename 的文件中 | 该文件必须是已存在的已缓冲文件。该路径名必须符合特定于操作系统的路径名规则。 |
| -m | 添加现有 dbspace 、 blobspace 或 sbspace | 镜像 sbspace 中的用户数据 chunk 不需要进行镜像。 镜像 chunk 应在另一个磁盘上,必须一次镜像所有 chunk |
| -m pathname offset | pathname 第二次出现在语法图中,它指示执行镜像的dbspace 、blobspace 或 sbspace 的初始 chunk 的磁盘分区或未缓冲设备。 offset 第二次出现在语法图中,它指示到达新镜像 dbspace 、blobspace 或 sbspace 的镜像 chunk 的偏移量。另见表中的 pathname 和 offset 条目 | 无 |
| -o offset | offset 第一次出现在语法图中,它指示为未到达新镜像 dbspace 、blobspace 或 sbspace 的初始 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 限制: 无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。 最大偏移量为 4 太字节。 |
| -p pathname | pathname 第一次出现在语法图中,它指示您正要镜像的 dbspace 、blobspace 或 sbspace 的初始 chunk 的磁盘分区或未缓冲设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| blobspace | 给出想要镜像的 blobspace 的名称 | 语法必须符合 Identifier 段; |
| dbspace | 给出想要镜像的 dbspace 的名称 | 语法必须符合 Identifier 段; |
| sbspace | 给出想要镜像的 sbspace 的名称 | 语法必须符合 Identifier 段; |
使用文件以 -f 选项指定 chunk 位置信息
可以创建包含 chunk 位置信息的文件。然后,当执行 onspaces 时,使用 -f 选项向数据库服务器指示该信息位于其名称在 filename 中指定的文件。
文件的内容应遵循以下格式,选项用空格隔开,每组主 chunk 和镜像 chunk 都在单独的行上:
primary_chunk_path offset mirror_chunk_path offset
如果正在镜像的 dbspace 包含多个 chunk ,那么必须为要镜像的 dbspace 中的每个主 chunk 指定镜像 chunk 。有关对多 chunk dbspace 启用镜像的示例,
onspaces -r: 停止镜像
可以使用 onspaces -r 选项结束 dbspace 、blobspace 或 sbspace 的镜像。
语法:
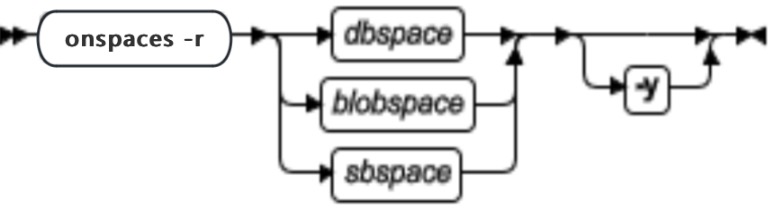
该命令有等同的 SQL 管理 API 命令。
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -r | 向数据库服务器指示现有的 dbspace 、 blobspace 或 sbspace 的镜像应结束 | |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| blobspace | 给出您想要结束镜像的 blobspace 的名称 | 语法必须符合 Identifier 段; |
| dbspace | 给出您想要结束镜像的 dbspace 的名称 | 语法必须符合 Identifier 段; |
| sbspace | 给出您想要结束镜像的 sbspace 的名称 | 语法必须符合 Identifier 段; |
onspaces -ren: 重命名 dbspace 、blobspace 、sbspace 或 extspace
可以使用 onspaces -ren 选项重命名 dbspace 、blobspace 、sbspace 或 extspace 。
语法:
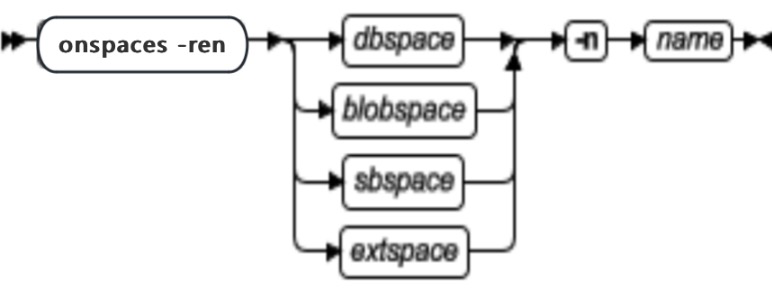
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -ren | 使得数据服务器重命名指定的 dbspace 、blobspace 、sbspace 或 extspace | 限制:当数据处于静态模式时,您可以重命名 dbspace 、blobspace 、sbspace 或 extspace。 |
| -n name | 指定 blobspace 、dbspace 、extspace 或 sbspace 的新名称 | 限制:Dbspace 、blobspace 、sbspace 或 extspace 的名称必须唯一,且不能超过 128 字节。它必须以字母或下划线开始,且必须只包含字母、数字、下划线或 $ 字符。 |
| blobspace | 给出要重命名的 blobspace 的名称 | 语法必须符合 Identifier 段; |
| dbspace | 指定要重命名的 dbspace | 限制: 您不能重命名关键 dbspace ,例如:root dbspace 或包含物理日志的 dbspace 。 其他信息: 如果您对包含在 DATASKIP 列表中的 dbspace 进行重命名,那么请使用 onspaces -f 命令用新的名称更新 DATASKIP 配置参数。 语法必须符合 Identifier 段; |
| extspace | 指定要重命名的 extspace | 语法必须符合 Identifier 段; |
| sbspace | 指定要重命名的 sbspace | 语法必须符合 Identifier 段; |
- 可以在 Enterprise Replication 活动时重命名空间(dbspace、 blobspace 、sbspace 或 extspace )。
- Enterprise Replication 环境中数据库服务器置于静态模式重命名空间时, 连接将断开。在将数据库服务器置于在线模式之后,服务器将会重新同步。
- Enterprise Replication 环境中如果想要在另一台服务器上重命名相同空间,那么必须将该服务器置于静态模式并单独重命名该空间。
- 如果 Enterprise Replication 服务器还参与 High-Availability Data Replication (HAC) ,那么您可以重命名主服务器上的 dbspace ,它将会自动传播到辅助服务器。(辅助服务器不能参与 Enterprise Replication 。)
- 在重命名任何空间(extspace 或临时空间除外)之后,请对重命名的空间和 root dbspace 执行 0 级归档。这将确保您能够将空间恢复到包括重命名 dbspace 操作的状态或者该操作之后的状态。在执行任何其他类型的归档之前,也必须执行该操作。
onspaces -s: 更改镜像 chunk 的状态
使用 onspaces -s 选项来更改在非临界 dbspace 、blobspace 或 sbspace 中的 dbspace 、非主 chunk 的镜像 chunk 的状态。

| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| -D | 指示您要关闭 chunk | 无 |
| -o offset | 指示为到达 chunk 而发生的磁盘分区或设备中的偏移量(千字节) | 限制: U无符号整数。开始偏移量必须大于等于 0 。开始偏移量加 chunk 大小不能超过最大 chunk 大小。该偏移量必须是页大小的倍数。 最大偏移量是 4 太字节。 |
| -O | 指示您要恢复 chunk 并使它在线 | 无 |
| -p pathname | 指示 chunk 的磁盘分区或未缓冲设备 | Chunk 必须是现有的未缓冲设备或已缓冲文件。指定路径名时,可以使用完整路径名或相对路径名。然而,如果使用相对路径名,这必须相对于是初始化数据库服务器时的当前目录的目录。 |
| -s | 指示您想要更改 chunk 的状态 | 限制:只能更改镜像对中的 chunk 或在非临界 dbspace 中的非主 chunk 的状态。 |
| -y | 导致数据库服务器自动对所有提示响应“是” | 无 |
| blobspace | 给出想要更改其状态的 blobspace 的名称 | 语法必须符合 Identifier 段; |
| dbspace | 给出想要更改其状态的 dbspace 的名称 | 语法必须符合 Identifier 段; |
| sbspace | 给出想要更改其状态的 sbspace 的名称 | 语法必须符合 Identifier 段; |
数据库相关信息查询
onstat 语法概览
完整的 onstat 命令语法包括和交互方式和非交互方式,要使 onstat 命令处于交互方式,请使用 -i 选项。交互方式允许您输入多个选项(一个接一个)而不用退出程序。非交互方式不使用 -i 选项。
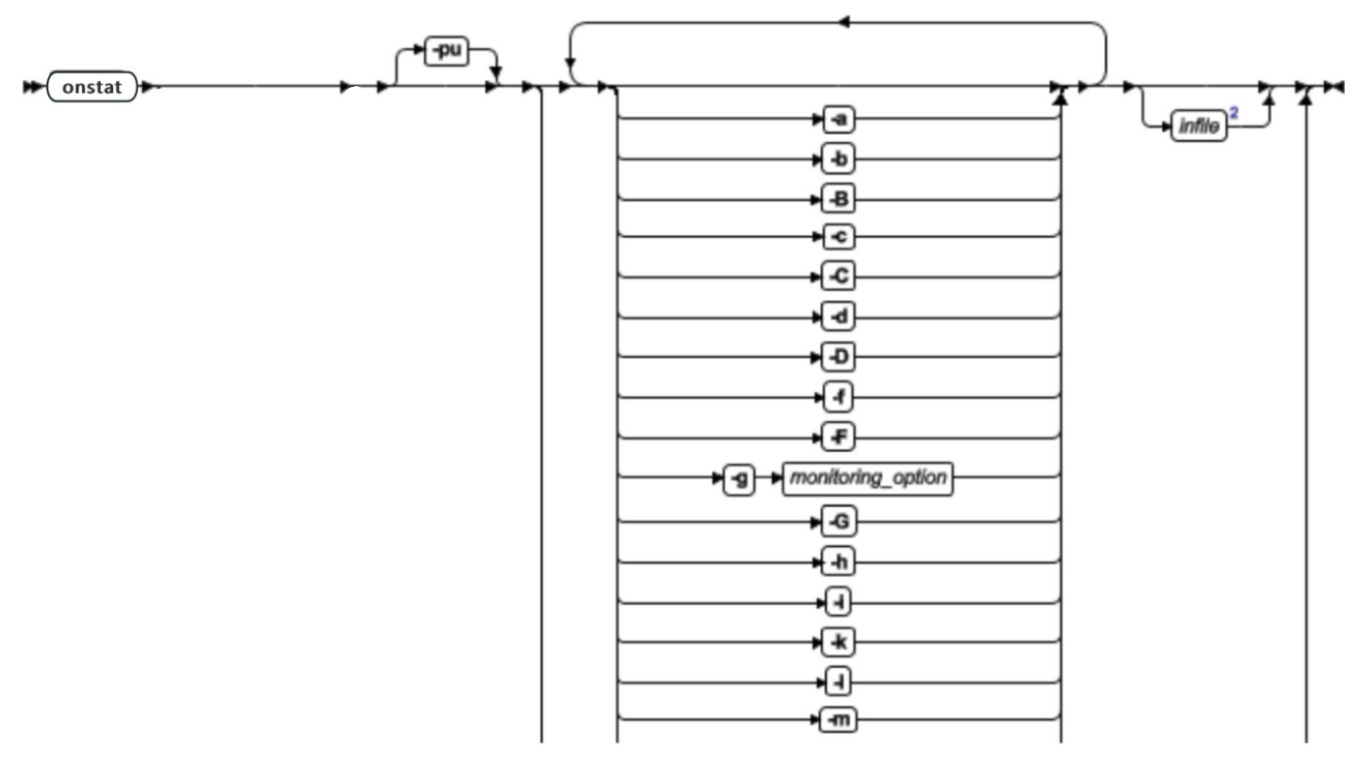
| 元素 | 用途 | 关键注意事项 |
|---|---|---|
| - | 只显示输出头 | 请参阅 onstat - 命令:打印输出头 |
| -- | 显示所有 onstat 选项及其功能的列表 | 请参阅 onstat -- 命令: 打印 onstat 选项和函数 此选项不能与任何其他 onstat 选项组合 |
| -a | 解释为 onstat -cuskbtdlp。以该顺序显示输出 | 请参阅 onstat -a 命令:打印数据库服务器整体状态的信息 |
| -b | 显示有关当前正在使用的缓冲区的信息,包括缓冲池中常驻页的数量 | 请参阅 onstat -b 命令:打印正在使用的缓冲区信息 |
| -B | 获得有关所有数据库服务器缓冲区(而不仅仅是当前正在使用的缓冲区)的信息 | 请参阅 onstat -B 命令:打印已使用的缓冲区信息 |
| -c | 显示 ONCONFIG 文件: ● $GBASEDBTDIR/conf/oncofig 对于 UNIX | 请参阅 onstat -c 命令:打印 ONCONFIG 文件内容 |
| -C | 打印 B-tree 扫描程序信息 | 请参阅 onstat -C 命令:打印 B–tree 扫描程序信息 |
| -d | 显示每个存储空间中的 chunk 的信息 | 请参阅 onstat -d 命令:打印 chunk 信息 |
| -D | 显示每个 dbspace 中前 50 个 chunk 的页读取和页写入信息 | 请参阅 onstat -D 命令:打印页读取和页写入信息 |
| -f | 列出当前受 DATASKIP 功能影响的 dbspace | 请参阅 onstat -f 命令:打印受 dataskip 影响的 dbspace 信息 |
| -F | 显示将页清仓到磁盘上每种类型的写操作的计数 | 请参阅 onstat -F 命令:打印计数 |
| -g option | 打印监视选项 | 请参阅 onstat -g 监视选项 |
| -G | 打印全局事务 ID | 请参阅 onstat -G 命令:打印 TP/XA 事务信息 |
| -h | 提供有关缓冲区头散列链的信 | 请参阅 onstat -h 命令:打印缓冲区头哈希链信息 |
| -i | 使 onstat 命令成为交互方式 | 请参阅 onstat -i 命令: 开始 交互方式 |
| -k | 显示关于活动锁的信息 | 请参阅 onstat -k 命令:打印活动的锁信息 |
| -l | 显示有关物理日志和逻辑日志的信息,包括页地址 | 请参阅 onstat -l 命令:打印物理和逻辑日志信息 |
| -m | 显示数据库服务器消息日志中最新的 20 行 | 此选项的输出列出消息日志文件和完整路径名和 20 个文件条目。一个日期和时间头分隔每天的条目。时间戳记放在每天中单个条目的开始处。消息日志的名称由 ONCONFIG 文件中的 MSGPATH 指定。 请参阅 onstat -m 命令:打印最近的系统消息日志信息 |
| -o | 将共享内存段的副本保存到 outfile | 请参阅 onstat -o 命令:输出共享内存内容 |
| -p | 显示概要文件计数 | 请参阅 onstat -p 命令:打印概要文件计数 |
| -P | 显示所有分区的分区号和属于该分区的缓冲池页的拆离 | 请参阅 onstat -P 命令:打印分区信息 |
| -pu | 如果使用不带任何选项的 onstat 选项,那么该命令被解释为 onstat -pu(-p 选项和 -u 选项)。显示概要计数并打印用户活动的概要文件 | 请参阅 onstat -p 命令:打印概要文件计数 和 onstat -u 命令:打印用户活动概要文件 |
| -r seconds | 在每次执行之间等待指定的 seconds 秒之后重复伴随的 onstat 选项 | 请参阅 onstat -r 命令:重复打印选择的统计信息 |
| -R | 显示关于 LRU 队列、FLRU 队列和 MLRU 队列的详细信息 | 请参阅 onstat -R 命令:打印 LRU 、FLRU 和 MLRU 队列信息 |
| -s | 显示一般锁存器信息 | 请参阅 onstat -s 命令:打印锁存器信息 |
| -t | 显示活动 tblspace 的 tblspace 信息(包括驻留状态) | 请参阅 onstat -t 和 onstat -T 命令:打印 tblspace 信息 |
| -T | 显示所有 tblspace 的 tblspace 信息 | 请参阅 onstat -t 和 onstat -T 命令:打印 tblspace 信息 |
| -u | 打印用户活动的概要文件 | 请参阅 onstat -u 命令:打印用户活动概要文件 |
| -V | 显示软件版本号和序列号。该选项不能与其他任何 onstat 选项组合 | |
| -version | 显示了构件版本、主机、操作系统、编号以及 GLS 版本。该选项不能与其他任何 onstat 选项组合 | |
| -x | 显示有关事务的信息 | 请参阅 onstat -x 命令:打印数据库服务器事务信息 |
| -X | 获取关于正在共享和等待缓冲区的线程的确切信息 | 请参阅 onstat -X 命令:打印线程信息 |
| -z | 将概要文件计数设置为 0 | 请参阅 onstat -z 命令:清除统计信息 |
| infile | 指定 onstat 命令作为所请求的源读取的文件 | 该文件必须包含先前存储的您使用 onstat -o 命令创建的共享内存段。 有关如何使用 onstat -o 创建infile 的说明,请参阅 onstat -o 命令:输出共享内存内容。 有关在资源文件中运行 onstat 的信息,请参阅 在共享内存转储文件中运行 onstat 命令 |
onstat 命令:等同于 onstat -pu 命令
如果调用没有任何选项的 onstat ,那么此命令解释为 onstat -pu( -p 选项和 -u 选项)。
语法:

onstat - 命令:打印输出头
所有 onstat 输出都包含一个头。onstat - 命令仅显示输出头,该命令返回的值指示数据库服务器方式。
语法:

头具有以下格式:
Your evaluation license will expire on 2025-07-31 00\:00\:00 --数据库license 到期时间
On-Line -- Up 2 days 15:44:08 -- 1420932 Kbytes --数据库状态 --数据库服务器运行时长 --数据库服务器共享内存
onstat -- 命令:打印 onstat 选项和函数
使用 onstat -- 命令显示所有 onstat 选项及其功能的列表。此选项是唯一不能与任何其他标志组合的选项标记。
语法:

在共享内存转储文件中运行 onstat 命令
您可以对共享内存转储文件运行 onstat 命令。可以通过使用 onstat -o 命令显式生成共享内存转储。如果将 DUMPSHMEM 配置参数设置为 1 或 2 ,那么在声明失败时自动创建转储文件。
语法:

当使用命令行时,转储文件必须以最终参数的形式输入。以下示例打印有关名为 onstat.out 的文件中包含的共享内存转储信息,而不是尝试连接到正在运行的服务器的共享内存。
onstat -g ath onstat.out
有关如何使用 onstat -o 创建内存转储文件的说明,请参阅onstat -o 命令:输出共享内存内容。
在共享内存转储文件上交互地运行 onstat 命令
对转储文件使用 onstat -i (交互方式)运行而不是 onstat 命令。交互方式可以节省时间,这是因为它只对文件读取一次。在命令行方式,每条命令都读取文件。
以下示例读取共享内存转储文件并进入交互方式。可以在正常的交互方式中对转储执行其他 onstat 命令。
onstat -i source_file
有关交互方式的信息,请参阅 onstat -i 命令: 开始 交互方式 。
在没有创建缓冲池的共享内存转储文件中运行 onstat 命令
当您在没有创建缓冲池的共享内存转储文件(使用 onstat -o nobuffs 创建或将 DUMPSHMEM 配置参数设置为 2)中运行 onstat 命令时,它将会产生不同的输出:
- 如果在没有创建缓存池的转储文件中运行 onstat -B ,那么输出将会在 memaddr 、nslots 和 pgflgs 列显示 0。
- 如果在没有创建缓存池的转储文件中运行 onstat -g seg ,那么输出将会显示原始的没有缓存驻留段大小。
- 如果在没有缓冲池的共享转储文件中运行 onstat -P ,那么它的输出为:
Nobuffs dumpfile -- this information is not available
onstat -a 命令:打印数据库服务器整体状态的信息
可以使用 onstat -a 命令显示有关数据库服务器状态的信息。该命令不仅显示有关所有 onstat 选项的信息,还显示用于初始故障排除的那些选项的信息。
语法:

onstat -b 命令:打印正在使用的缓冲区信息
可以使用 onstat -b 选项显示有关当前正在使用的缓冲区的信息,包括缓冲池中常驻页的总数。可用缓冲区的最大数量以 ONCONFIG 文件中 BUFFERPOOL 配置参数的 buffers 字段进行指定。
语法:
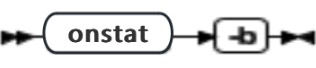
输出样本
以下是 onstat -b 命令的输出样本。有关该输出的描述,请参阅 onstat -B 命令:打印已使用的缓冲区信息。onstat -b 命令还提供有关已修改缓冲区的数量、缓冲池中常驻页的总数。可用缓冲区的总数、可用哈希桶的数目以及以字节表示的缓冲区大小(页大小)的摘要信息:123 modified, 23 resident, 2000 total, 2048 hash buckets, 2048 buffer size.

onstat -B 命令:打印已使用的缓冲区信息
可以使用 onstat -B 选项显示那些不在可用列表中的缓冲区信息。onstat -B 和 onstat -b 显示相同的信息。除了 onstat -b 命令只显示当前被用户线程访问的缓冲区。onstat -B 命令显示不在可用列表中的所有缓冲区。
语法:

输出样本
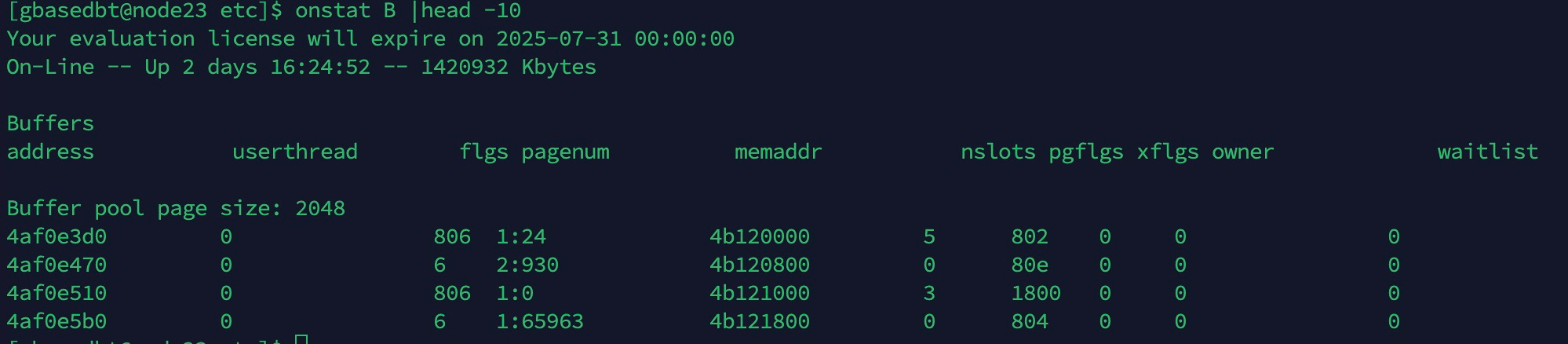
输出描述
| 输出 | 描述 |
|---|---|
| Buffer pool page size | 以字节表示的缓冲池页面大小 |
| address | 是缓冲区表中缓冲区头的地址 |
| userthread | 是访问缓冲区表的最新用户线程的地址。许多用户线程可能正在并发读取同一缓冲区 |
| flgs | 描述缓冲区的标记。 |
| pagenum | 磁盘上的物理页数 |
| memaddr | 缓冲区内存地址 |
| nslots | 页中 slot 表条目的数量,该字段指示存储在该页上的行(或行的一部分)的数量 |
| pgflgs | 页类型 |
| xflgs | 缓冲区标志。0x10共享锁、0x80互斥锁 |
| owner | 设置 xflgs 缓冲区标记的用户线程 |
| waitlist | 正在等待访问该缓冲区的第一个用户线程的地址 |
onstat -c 命令:打印 ONCONFIG 文件内容
使用 onstat -c 命令显示 ONCONFIG 文件内容信息。数据库服务器首先检查是否已为环境变量 ONCONFIG 指定了值。可以在数据库服务器处于任何方式(包括离线)时使用 onstat -c 选项。如果已设置了 ONCONFIG,那么 onstat -c 显示 $GBASEDBTDIR/conf/oncofig 文件的内容。如果未设置,那么缺省情况下,onstat -c 显示 $GBASEDBTDIR/conf/oncofig 的内容。
语法:
onstat -C 命令:打印 B–tree 扫描程序信息
使用 -C 命令显示有关 B-tree 扫描程序子系统和每个 B-tree 扫描程序线程的信息。
语法:
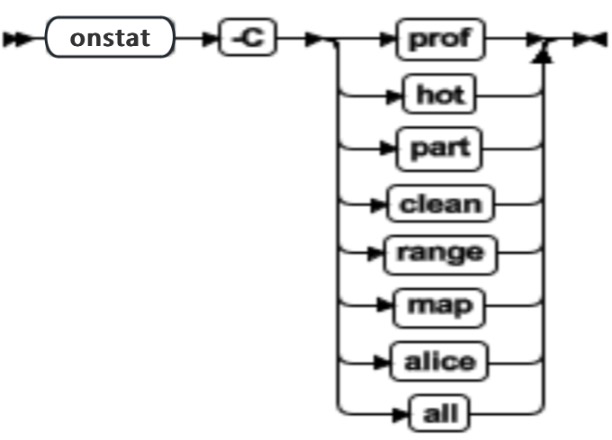
| 选项 | 说明 |
|---|---|
| prof | 打印系统和每个 B-tree 扫描程序线程的概要文件信息。这是缺省选项。 |
| hot | 以要清除的顺序打印 hot 列表索引键 |
| part | 打印具有索引统计信息的所有分区 |
| clean | 打印已清除或需要清除的所有分区的信息 |
| range | 打印通过使用索引范围扫描所节约的页进程数 |
| map | 为 alice 清除方法的每个索引显示了当前的 bitmap |
| alice | 显示了 alice 清除方法选项的效率 |
| all | 打印所有 onstat -C 选项 |
使用 prof 选项示例输出
图: 带 prof 选项的 onstat -C 命令输出
使用 prof 选项输出描述
| 输出 | 描述 |
|---|---|
| Id | BTSCANNER ID |
| Prio | BTSCANNER 当前的优先级 |
| Partnum | 当前正在工作线程的索引分区号 |
| Cmd | 此线程当前正在处理的命令 |
使用 hot 选项示例输出
图: 带有 hot 选项的 onstat -C 命令输出

使用 hot 选项输出的描述
| 输出 | 描述 |
|---|---|
| Partnum | 索引的分区号 |
| Key | 索引键 |
| Hits | Hit 计数器的当前值 |
| * | 指示在 hot 列表持续时,该分区被清除 |
使用 part 选项示例输出
图: onstat -C part 命令输出

使用 part 选项输出描述
Partnum :索引的分区号
Key :索引键
Positions :索引的读取数
Compress :页压缩数
Split :已发生分割的数量
使用 clean 选项示例输出
图: 带有 clean 选项的 onstat -C 命令输出

使用 clean 选项输出描述
Partnum :索引的分区号
Key :索引键
Dirty Hits :Dirty 页被扫描的次数
Clean Time :总耗时,以秒为单位
Pg Examined :被 btscanner 线程审查的页数
Items Del :从该索引移除的项的数量
Pages/Sec :每秒审查的页数
示例输出
图: onstat -C range

输出描述
Partnum: 分区号
Key : 索引键
Low : 范围扫描的下限
High: 索引扫描的上限
Size : 索引的页大小
Saving: 保存相对完整扫描的时间的百分比
输出示例
图: onstat -C map

输出描述
Partnum: 分区号
Key : 索引键
Map: Alice bitmap
输出示例
图: onstat -C alice
输出描述
Partnum: 索引的分区号
Mode: 当前分区的 alice 模式
BM_Sz : 向 bitmap 分配的大小
Used_Pg: 索引的页大小(已使用)
Dirty_Pg: Dirty 页的数量
# I/O: 读取的页数
Found : 在读取中查找到的 dirty 页数量
Eff: Bitmap 的效率
Adj : Alice 效率水平分区不充分并被调节的次数
onstat -d 命令:打印 chunk 信息
使用 onstat -d 命令显示每个存储空间中 chunk 的信息。
语法:
update 选项通过更新共享内存来获得可用页的准确计数。
示例输出
图: onstat -d 命令输出
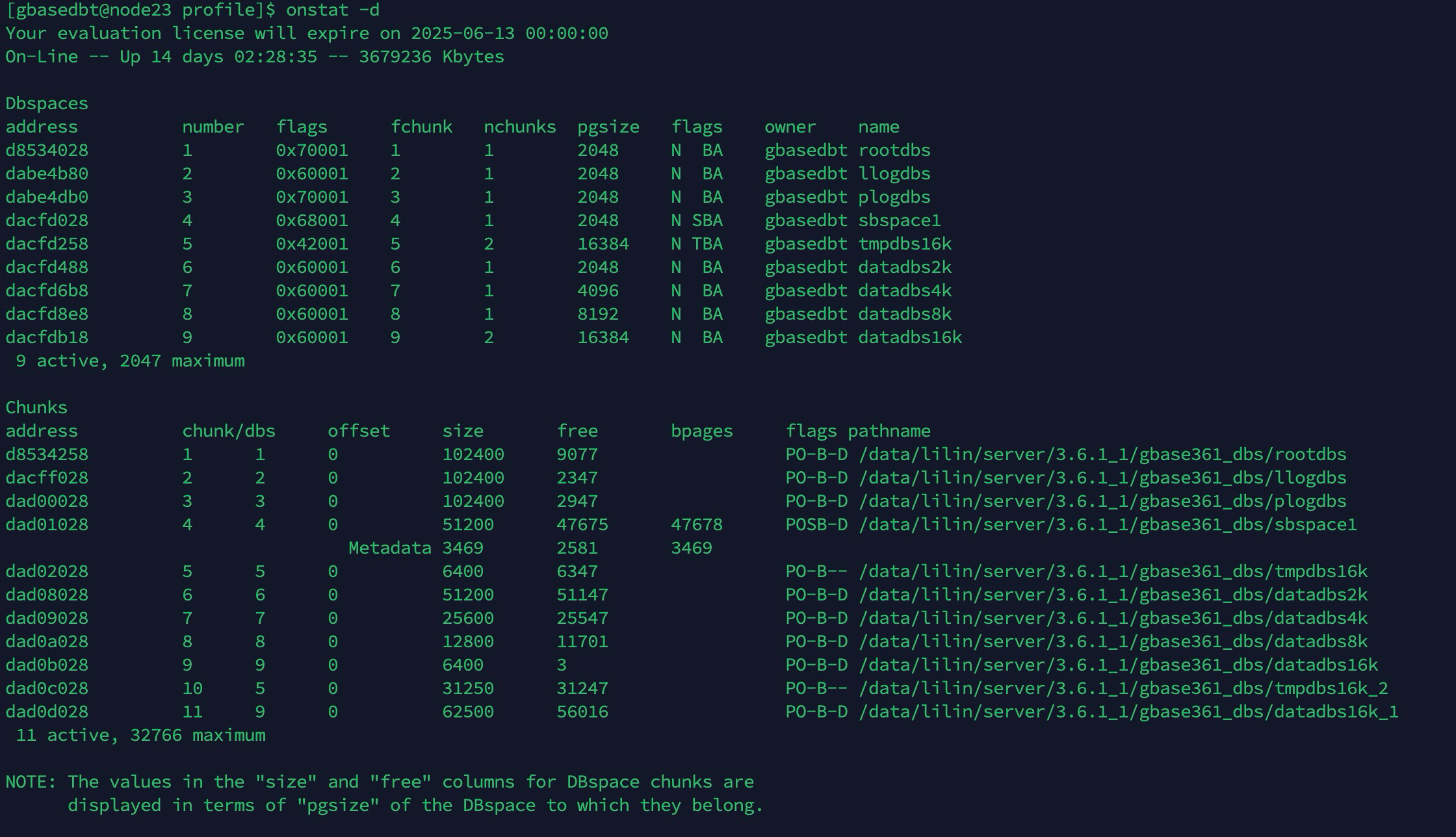
对于 dbspace 的输出描述
该显示的第一部分描述存储空间:
address: 是共享内存空间表中的存储空间地址
number: 是创建时指定的存储空间的唯一 ID
flags: 使用十六进制值描述每个存储空间。可以累积单独的标记以显示 dbspace 的累积属性。下表描述了每个十六进制值:
| 标记值 | 描述 |
|---|---|
| 0x0001 | 允许镜像且 dbspace 是未镜像的 |
| 0x0002 | 允许镜像且 dbspace 是已镜像的 |
| 0x0004 | Dbspace 包含禁用镜像的 chunk |
| 0x0008 | 新镜像的 |
| 0x0010 | Blobspace |
| 0x0200 | 正在恢复空间 |
| 0x0400 | 空间已物理恢复 |
| 0x0800 | 正在恢复逻辑日志 |
| 0x2000 | 临时 dbspace |
| 0x4000 | 正在备份 blobspace |
| 0x8000 | Sbspace |
| 0x10000 | 物理或逻辑日志已更改 |
| 0x20000 | Dbspace 或 chunk 表已更改 |
| 0x040000 | 包含大 chunk 的 blobspace |
| 0x080000 | 在此 dbspace 中的 chunk 已重命名 |
| 0x00100000 | 仅供共享磁盘辅助服务器使用的临时 dbspace 。它是在 SD 辅助服务器中列出 SDS_TEMPDBS 配置参数的其中之一的 sbspace |
| 0x00200000 | SSC 辅助服务器的临时 dbspace 。在共享磁盘辅助服务器上列出了 DBSPACETEMP 配置参数 |
| 0x00400000 | 该 dbspace 已被外部备份 |
| 0x00800000 | Dbspace 正在进行碎片整理 |
| 0x01000000 | Plogspace |
fchunk: 第一个 chunk 的 ID
nchunks: 存储空间中的 chunk 数
pgsize: Dbspace 页的大小 (以字节为单位)
flags: 使用以下字母代码描述每个存储空间:
位置 1:
| 标记 | 描述 |
|---|---|
| M | 已镜像 |
| N | 未镜像 |
位置 2:
| 标记 | 描述 |
|---|---|
| X | 新镜像的 |
| P | 物理恢复的,正在等待逻辑恢复 |
| L | 正在进行逻辑恢复 |
| R | 正在进行恢复 |
| D | 关闭 |
位置 3:
| 标记 | 描述 |
|---|---|
| B | Blobspace |
| P | Plogspace |
| S | Sbspace |
| T | 临时 dbspace |
| U | 临时 sbspace |
| W | 主服务器上的临时 dbspace (该标记仅在 SSC 辅助服务器上显示) |
位置 4:
| 标记 | 描述 |
|---|---|
| B | Dbspace 具有大于 2 GB 的大 chunk |
位置 5:
| 标记 | 描述 |
|---|---|
| A | Dbspace 是自动扩展的,因为 SP_AUTOEXPAND 配置参数禁用并且 dbspace 配置了不为 0 的创建的大小或扩展大小 |
owner: 存储空间的所有者
name: 存储空间的名称
在紧随存储空间列表的行中,active 代表在数据库服务器实例中的存储空间(包括 root dbspace)的当前数量 ,maximum 代表这个数据库服务器实例总的可分配空间。
输出描述 - Chunk
onstat -d 命令输出的第二部分描述 chunk :
address: Chunk 的地址
chk/dbs : Chunk 编号和相关联的空间编号
offset: 页中文件或原始设备的偏移量
size: 以 chunk 所属的 dbspace 页面大小为单位表示的 chunk 的大小
free: 以 chunk 所属的 dbspace 页面大小为单位表示的 chunk 的可用页数量。值为 0 指示 chunk 中的所有空间被分配到表,但不指示表中有多少可用空间。例如:假设创建了具有 200 MB chunk 的 dbspace 并创建了具有 200 MB extent 的表。那么 free 字段的值为 0(指示 chunk 没有可用空间),然而,新的空表有 200 MB 的可用空间。
对于 blobspace ,~符号指示可用 blobpage 的大约数量
对于 sbspace,显示用户数据空间可用页数和用户数据空间总数
bpages: 以 blobpage 为单位的 chunk 的大小。Blobpage 可以比磁盘页大;因此,bpages 值可以小于 size 值。对于 sbspace ,是 sbpage 中 chunk 的大小。
flags: 提供如下的 chunk 状态信息:
位置 1:
| 标记 | 描述 |
|---|---|
| P | 主 |
| M | 镜像 |
位置 2:
| 标记 | 描述 |
|---|---|
| N | 已重命名切实关闭或不一致的 |
| O | 在线 |
| D | 关闭 |
| X | 新镜像的 |
| I | 不一致的 |
位置 3:
| 标记 | 描述 |
|---|---|
| - | Dbspace |
| B | Blobspace |
| S | Sbspace |
位置 4:
| 标记 | 描述 |
|---|---|
| B | Dbspace 具有大于 2 GB 的大 chunk |
位置 5:
| 标记 | 描述 |
|---|---|
| E | 指示该 chunk 是可扩展的 |
| - | 指示该 chunk 是不可扩展的 |
位置 6:
| 标记 | 描述 |
|---|---|
| - | 为此熟的文件 chunk 不启用直接 I/O 选项或并发 I/O 选项 |
| C | 在 AIX® 上,为此熟的文件 chunk 启用并发 I/O 选项 |
| D | 为此熟的文件 chunk 启用直接 I/O 选项 |
pathname : 物理设备的路径名
在紧随 chunk 列表的行中,active 显示活动 chunk(包括 root chunk)的数量,maximum 显示 chunk 的总数。
onstat -D 命令:打印页读取和页写入信息
使用 onstat -D 命令显示每个空间前 50 chunk 的页读取和页写入的信息。
语法:

示例输出
图: onstat -D 命令输出
输出描述
onstat -D 输出在 onstat -d 输出的基础上新增了下面两个属性 。
page Rd: 是已读取页数量
page Wr : 是已写入页的数量
onstat -f 命令:打印受 dataskip 影响的 dbspace 信息
使用 -f 命令列出数据忽略功能当前影响的 dbspace。-f 选项列出用 DATASKIP 配置参数和 onspaces 的 -f 选项设置的 dbspace 。执行 onstat -f 时,数据库服务器显示以下三种输出之一:
- Dataskip 对所有dbspace 都是 OFF 。
- Dataskip 对所有dbspace 都是 ON 。
- Dataskip 对以下 dbspace 都是 ON :
dbspace1 dbspace2...
语法:

onstat -F 命令:打印计数
使用 onstat -F 命令显示将页清仓到磁盘上的每种类型的写操作的计数。
语法:
示例输出
图: onstat -F 命令输出

输出描述
可以如下解释该选项的输出:
Fg Writes: 是已发生前台写入的次数
LRU Writes: 是已发生 LRU 写入的次数
Chunk Writes: 是已发生 chunk 写入的次数
address: 是指定给该页清除程序线程的用户结构的地址
flusher: 是页清除程序号
state:清除活动标识。C - Chunk 写入、**E-**退出、**I-**清除程序处于空闲状态、**L-**LRU 队列
data: 提供与 state 字段相呼应的其他信息,如果 state 为 C ,那么 data 是页清除程序正在将缓冲区写入的 chunk 编号。如果 state 为 L 那么 data 是页清除程序正从其写入的 LRU 队列。data 值显示为十进制,后跟等号,并以十六进制进行重复。
#LRU: 对应于 onstat -g ath 线程 ID 输出
Chunk: 已清除的 chunk 数量
Wakeups: 页清除线程被唤醒的次数
Idle Time: 页清除线程的空闲时间(以秒为单位)
onstat -g 监视选项
onstat -g 命令使用的选项只提供用于支持和调试目的。每个 onstat -g 命令只能包含这些选项中的一个。
onstat -g act 命令:打印活动线程
使用 onstat -g act 命令显示有关活动线程的信息。
语法:
示例输出
以下是 onstat -g act 命令输出的样本。有关输出的描述,请参阅 onstat -g ath 命令:打印所有线程的信息。

onstat -g afr 命令: 打印分配的内存分片
使用 onstat -g afr 命令显示有关指定会话或共享内存池的已分配内存分片。向每个会话分配一个共享池。该命令需要一个额外的参数来指定池名称、会话 ID 或池地址。每个会话都分配了于会话 ID 名称相同的内存池。
语法:
pool_name 是共享内存池的名称。可运行 onstat -g mem 命令标识池的名称。
sessionid 是会话 ID 。可运行 onstat -g ses 命令标识会话 ID。
pool_address 是共享内存池的地址。可运行 onstat -g mem 命令或 onstat -g ses 命令标识池的地址。
示例输出
图: onstat -g afr 命令输出

输出描述
addr (hexadecimal): 池分片的内存地址
size (decimal): 以字节表示的池分片的大小
memid (string): 池分片的内存 ID
fileid (decimal): 仅限内部使用。代码文件标识分配
location (string): 仅限内部使用。分配代码中的行号
onstat -g all 命令:打印诊断信息
使用 onstat -g all 命令收集由 GBase Support 建议的诊断信息。为了能够正常管理,应该只使用带有个别选项的 onstat -g 命令。
语法:
onstat -g aqt 命令:打印数据集和加速查询表的信息
使用 onstat -g aqt 命令来显示有关数据集和向管理的加速查询表(AQT)的信息。AQTs 按照其所属数据集分组。这些组先按照加速程序名称排序,再按数据集名称排序。在数据集组中,AQTs 按以下顺序排序:Fact table tabid (FactTab)、表的数量 (#tab) 和 AQT 名称。
来自字典高速缓存的输出参考了 AQTs 的数据集。输出仅在 AQTs 加载到字典高速缓存中时显示,这种情况通常在对 AQTs 查询匹配时发生。
在数据库尝试对 AQTs 进行匹配查询之前,AQTs 在字典高速缓存中没有任何条目。onstat -g aqt 命令不会在输出中显示任何条目。当在数据库服务器启动时初始化字典高速缓存时,#matched 和 address 列得到新的值。
语法:

示例输出
图: onstat -g aqt 命令输出
AQT Dictionary Cache for database school:
mart: school
accelerator: DWAFINAL
last load: 2011/07/29 07:00:39
AQT name FactTab #tab #matched address
--------------------------------------------------------------------------------
aqt4d11b552-7d41-4b0c-824b-7714b6cb580a 103 1 328 0x4d187e08
aqt61498fab-3617-4c8c-ab40-fd8af4253998 103 2 42 0x4d84a448
aqtbc2da77c-bca8-4ce7-9191-8180a860da34 103 2 768 0x4d187f60
aqt88757e9d-81ee-43b4-87b2-0bf48c98fa55 103 3 15 0x4d84a190
aqta786d0dc-8e95-4de0-a1bd-773aa03a52db 103 3 1475 0x4d84a650
aqt8dd61c80-2c1c-4f0e-8f0c-91babe789f41 103 4 632 0x4d84a908
mart: school2
accelerator: DWAFINAL
last load: 2011/07/29 07:01:04
AQT name FactTab #tab #matched address
--------------------------------------------------------------------------------
aqt56d5aea7-32f4-44e6-8d98-02a7af37630f 103 1 845 0x4d84ac70
aqt03ec4c20-7ba8-4c3a-ae56-4134b005269d 103 2 27 0x4d95c298
aqt4ae7c2fd-5b94-423d-bc49-9ca3f5f38799 103 2 3912 0x4d84adc8
aqt5ed69a75-15e3-45cc-9892-4f5386257895 103 3 83 0x4d95c4a0
aqtdf314aa6-177d-4443-9f6d-f14ba766995a 103 3 37 0x4d95c028
aqt7e36b1f2-4646-4075-ac0b-5fdee475cd7e 103 4 518 0x4d95c758
mart: school3
accelerator: DWAFINAL
last load: 2011/07/29 07:01:50
AQT name FactTab #tab #matched address
--------------------------------------------------------------------------------
aqt92b36a8a-1567-4146-833c-385cd103f5d4 103 1 678 0x4d95cac0
aqt3189bec1-b6c9-417d-b969-92c687ef2e44 103 2 59 0x4d95cc18
aqt8d3b3dc8-59b6-4e34-822b-75b06b99c900 103 2 4487 0x4d90c0d8
aqt5f9c2a05-9131-4738-a929-036fcf77f65c 103 3 71 0x4d90c2e0
aqtee08ed16-6a5c-4478-ac57-fc4f99539c74 103 3 795 0x4d95ce20
aqt04d1c96a-022b-4ed7-938d-caf765bc9926 103 4 367 0x4d90c598
18 entries
输出说明:
onstat -g aqt 命令打印以下信息:
mart: 数据集的名称
accelerator: 加速程序实例名称
last load: 上一次数据集加载的时间戳
AQT name: 系统生成的唯一的 AQT 名称
FactTab: AQT 实际数据表的 tabid
#tab: 属于 AQT 表的数量
#matched: AQT 已发生的查询匹配计数
address: AQT 的内部数据库服务器内存地址
如果对可选 aqt_name 参数使用 AQT 名称,那么该命令打印指定的 AQT 的信息。
图: onstat -g aqt aqt_name 命令输出
AQT: aqt6de1afdd-f10a-45b0-93e9-0c208405fefd
database: iwadb
AQT tabid: 125
Fact table: 111
Number of times matched: 8947
Join structure: alias(tabid)[colno,...] = alias(tabid)[colno,...] {u:unique}
0(111)[1] = 1(110)[1] u
1(110)[2] = 2(109)[1] u
2(109)[5] = 3(101)[1] u
3(101)[3] = 4(100)[1] u
0(111)[2] = 5(106)[1] u
5(106)[2] = 6(103)[1] u
5(106)[3] = 7(104)[1] u
5(106)[4] = 8(105)[1] u
8(105)[3] = 9(101)[1] u
9(101)[3] = 10(100)[1] u
5(106)[5] = 11(102)[1] u
0(111)[2,3] = 15(108)[1,2] u
15(108)[1] = 16(106)[1] u
16(106)[2] = 17(103)[1] u
16(106)[3] = 18(104)[1] u
16(106)[4] = 19(105)[1] u
19(105)[3] = 20(101)[1] u
20(101)[3] = 21(100)[1] u
16(106)[5] = 22(102)[1] u
15(108)[2] = 23(107)[1] u
23(107)[2] = 24(101)[1] u
24(101)[3] = 25(100)[1] u
0(111)[3] = 12(107)[1] u
12(107)[2] = 13(101)[1] u
13(101)[3] = 14(100)[1] u
输出描述
onstat -g aqt aqt_name 命令打印以下信息:
AQT: 系统生成的唯一的 AQT 名称
database: AQT 所属数据库的名称
AQT tabid: 构成数据库服务器中的 systables 系统目录表中的 AQT 条目的 tabid
Fact table AQT 真实表的 tabid
Number of times matched: AQT 已发生的查询匹配计数
onstat -g arc 命令:打印归档状态
使用 onstat -g arc 命令显示每个 dbspace 最后提交归档的信息,也显示正在执行归档的信息。
语法:

示例输出
图: onstat -g arc 命令输出

输出描述 - 正在执行归档
本节的输出代表正在归档的当前的信息。如果系统中没有归档活动,那么不会显示本节的信息。
| 列 | 描述 |
|---|---|
| Number | Dbspace 编号 |
| Name | Dbspace 名称 |
| Q Size | 前映象队列大小。该信息主要为了 GBase 支持 |
| Q Len | 前映象队列长度。该信息主要为了 GBase 支持 |
| Buffer | 前映象缓冲区使用的页数 |
| Partnum | 前映象 bin 分区号 |
| Size | 前映象 bin 的页数 |
| Current-page | 正在执行归档的当前页 |
前映象 bin 是在临时 dbspace 或 root dbspace 中创建的表(如果您没有临时 dbspace)。如果前映象 bin 变小,它可以扩展到其他分区,这样将会看到输出显示同一个 dbspace 具有多个 Partnum 和 Size 字段。
输出描述 - 归档状态
本节输出包含每个 dbspace 发生最后一次备份的信息。
| 列 | 描述 |
|---|---|
| Name | Dbspace 名 |
| Number | Dbspace 编号 |
| Level | 归档级别 |
| Date | 最后一次归档的日期和时间 |
| Log | 用来启动归档的 checkpoint 的唯一 ID (UNIQID) |
| Log-position | 用来启动归档的 checkpoint 的日志位置(LOGPOS) |
onstat -g ath 命令:打印所有线程的信息
使用 onstat -g ath 命令显示有关所有线程的信息。
语法:
示例输出
图: onstat -g ath 命令输出
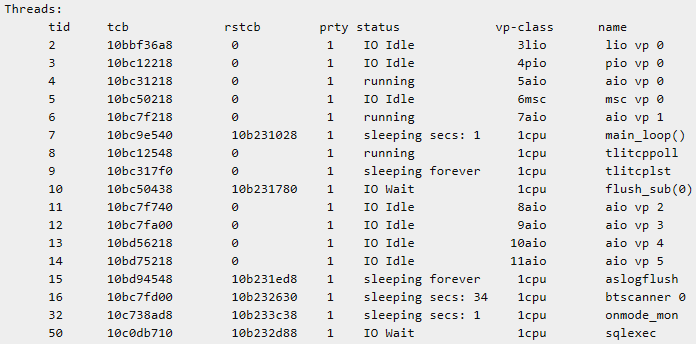
输出描述
tid: 线程 ID
tcb: 线程控制 block 访问地址
rstcb: RSAM 线程控制 block 访问地址
prty: 线程优先级
status: 线程状态
vp-class: 虚拟处理器类
name: 线程名称。对于参与并行存储优化操作的线程,它表示操作的名称和线程编号
- compress.number = 线程正在压缩数据
- repack.number = 线程正在重新打包数据
- uncompress.number = 线程正在解压数据
- update_ipa.number = 线程正在移除就地修改操作
onstat -g bth 和 -g BTH:打印阻塞的和正在等待的线程
使用 onstat -g bth 命令显示阻塞和正在等待线程之间的依赖关系。使用 onstat -g BTH 命令显示阻塞线程的会话和堆信息。
语法:
onstat -g bth 的示例输出
图: onstat -g bth 命令输出
This command attempts to identify any blocking threads.
Highest level blocker(s)
tid name session
48 sqlexec 26
Threads waiting on resources
tid name blocking resource blocker
49 sqlexec MGM 48
13 readahead_0 Condition (ReadAhead) -
50 sqlexec Lock (0x4411e578) 49
51 sqlexec Lock (0x4411e578) 49
52 sqlexec Lock (0x4411e578) 49
53 sqlexec Lock (0x4411e578) 49
57 bf_priosweep() Condition (bp_cond) -
58 scan_1.0 Condition (await_MC1) -
59 scan_1.0 Condition (await_MC1) -
Run 'onstat -g BTH' for more info on blockers.
onstat -g bth 的输出描述
tid: 线程 ID
name: 线程名称
session: 会话 ID
blocking resource: 列出的等待线程的资源类型
blocker: 列出的阻塞线程的线程 ID
onstat -g BTH 的示例输出
Stack for thread: 48 sqlexec
base: 0x00000000461a3000
len: 69632
pc: 0x00000000017b32c3
tos: 0x00000000461b2e30
state: ready
vp: 1
0x00000000017b32c3 (oninit) yield_processor_svp
0x00000000017bca6c (oninit) mt_wait
0x00000000019d4e5c (oninit) net_buf_get
0x00000000019585bf (oninit) recvsocket
0x00000000019d1759 (oninit) tlRecv
0x00000000019ce62d (oninit) slSQIrecv
0x00000000019c43ed (oninit) pfRecv
0x00000000019b2580 (oninit) asfRecv
0x000000000193db2a (oninit) ASF_Call
0x0000000000c855dd (oninit) asf_recv
0x0000000000c8573c (oninit) _iread
0x0000000000c835cc (oninit) _igetint
0x0000000000c72a9e (oninit) sqmain
0x000000000194bb38 (oninit) listen_verify
0x000000000194ab8a (oninit) spawn_thread
0x0000000001817de3 (oninit) th_init_initgls
0x00000000017d3135 (oninit) startup
This command attempts to identify any blocking threads.
Highest level blocker(s)
tid name session
48 sqlexec 26
session effective #RSAM total used dynamic
id user user tty pid hostname threads memory memory explain
26 gbasedbt - 45 31041 mors 2 212992 186568 off
Program : /work3/JC/VIEWS/jc_dct_phase2.view/.s/00055/80003fd351f804d3dbaccess
tid name rstcb flags curstk status
48 sqlexec 448bc5e8 ---P--- 4560 ready-
58 scan_1.0 448bb478 Y------ 896 cond wait await_MC1 -
Memory pools count 2
name class addr totalsize freesize #allocfrag #freefrag
26 V 45fcc040 208896 25616 189 16
26*O0 V 462ad040 4096 808 1 1
name free used name free used
overhead 0 6576 mtmisc 0 72
resident 0 72 scb 0 240
opentable 0 7608 filetable 0 1376
log 0 33072 temprec 0 17744
blob 0 856 keys 0 176
ralloc 0 55344 gentcb 0 2240
ostcb 0 2992 sqscb 0 21280
sql 0 11880 xchg_desc 0 1528
xchg_port 0 1144 xchg_packet 0 440
xchg_group 0 104 xchg_priv 0 336
hashfiletab 0 1144 osenv 0 2520
sqtcb 0 15872 fragman 0 1024
shmblklist 0 416 sqlj 0 72
rsam_seqscan 0 368
sqscb info
scb sqscb optofc pdqpriority optcompind directives
4499c1c0 461c1028 0 100 2 1
Sess SQL Current Iso Lock SQL ISAM F.E.
Id Stmt type Database Lvl Mode ERR ERR Vers Explain
26 SELECT jc CR Not Wait 0 0 9.24 Off
Current statement name : unlcur
Current SQL statement (5) :
select * from systables,syscolumns,sysfragments
Last parsed SQL statement :
select * from systables,syscolumns,sysfragments
onstat -g BTH 的输出描述
tid: 线程 ID
name: 线程名称
session: 会话 ID
该会话信息段包含的信息与 onstat -g ses 命令输出的信息相同。请参阅 onstat -g ses 命令:打印与会话有关的信息。
onstat -g buf 命令:打印缓冲池的概要文件信息
使用 onstat -g buf 命令来显示每个缓冲池的概要文件信息。
语法:

示例输出
onstat -g buf 命令的输出取决于 BUFFERPOOL 配置参数设置是否包含 memory 字段和 buffers 字段而稍有不同。输出将显示 memory 设置。buffers 设置的输出包含 max extends 和 next buffers 字段,代替了 max memory 和 next memory 字段。
图: 对于 memory 设置的 onstat -g buf 输出
Profile
Buffer pool page size: 2048
dskreads pagreads bufreads %cached dskwrits pagwrits bufwrits %cached
1190 1773 661359 99.82 16863 83049 185805 90.92
bufwrits_sinceckpt bufwaits ovbuff flushes
11243 115 0 42
Fg Writes LRU Writes Avg. LRU Time Chunk Writes Total Mem
0 0 nan 10883 32Mb
cache
# extends max memory next memory hit ratio last
0 128Mb 32Mb 90 11:31:17
Bufferpool Segments
id segment size # buffs
0 0x449f0000 32Mb 13025
----------------------------------
Buffer pool page size: 8192
dskreads pagreads bufreads %cached dskwrits pagwrits bufwrits %cached
0 0 11 100.00 4 16 4 0.00
bufwrits_sinceckpt bufwaits ovbuff flushes
0 0 0 1
Fg Writes LRU Writes Avg. LRU Time Chunk Writes Total Mem
0 0 nan 4 128Mb
cache
# extends max memory next memory hit ratio last
0 1280Mb 128Mb 90 11:31:41
Bufferpool Segments
id segment size # buffs
0 0x4928e000 128Mb 14988
----------------------------------
Fast Cache Stats
gets hits %hits puts
246854 244407 99.01 111147
输出描述
Buffer pool page size: 缓冲池中页面的字节数
dskreads: 将页面带入缓冲池的已执行你的磁盘读操作数。每次读操作读取一个或多个页面。
pagreads: 从磁盘读入缓冲池的页面数
bufreads: 从该缓冲池读取的页面内存映象次数
%cached: 为满足高速缓存页面映象的该缓冲池读取的页面百分比(而不是执行磁盘读取)。计算为 (bufreads - dskreads) / bufreads x 100。更高的百分比说明有更好的高速缓存性能。
dskwrits: 将更改的页面从缓冲池写回磁盘所执行的磁盘写入操作数。每次写入操作撰写一个或多个页面。
pagwrits: 从缓冲池写入磁盘的页面数
bufwrits: 写入该缓冲池的页面内存映象次数
%cached: 为满足高速缓存页面映象的该缓冲池写入的页面百分比(而不是执行磁盘写入)。计算为 (bufwrits - dskwrits) / bufwrits x 100 。
bufwrits_sinceckpt: 自上个 checkpiont 后页面内存映象写入该缓冲池的次数
bufwaits: 在该缓冲池内线程必须等待缓冲区内锁的次数。数字越大说明在相同页面上互不兼容的锁的多个线程之间的争用越多。
ovbuff: 为了创建空闲的缓冲区来读取另外一个受请求的页面而将更改了的缓冲区从该缓冲池写入磁盘的次数。如果 ovbuff 值很大,那么可能说明缓冲池还不够大,还不能容纳使用该缓冲池的应用程序所需的工作集,这可能导致性能降级。
flushes: 服务器为缓冲池内所有 dirty 缓冲区执行的大清空的次数。这可能由不同的原因引起,可能是作为 checkpoint 过程的一部分而执行此操作或缓冲池在清洁的缓冲区外运行(无论 LRU 清除活动是否正常)。
Fg Writes: 该缓冲池中访问缓冲区的非 I/O 清空程序线程写入磁盘的已更改缓冲区的数量。这个数字是 ovbuff 字段的超集。除了 ovbuff 字段计数的写入服务页面缺省值的次数,该值也包括为了保持数据库记录和保留页的一致性而执行的操作所做的前台写,其目的是为了保证正确的恢复。
LRU Writes: 由 LRU 清除线程从该缓冲池将更改了的缓冲区写入磁盘的数量。如果缓冲池超过了指定在 lru_max_dirty 字段中 BUFFERPOOL 配置参数值或如果由于缓冲池溢出而发生前台写,那么将激活 LRU 清除程序。
Avg. LRU Time: LRU 清除程序用来清除单个 LRU 链所用的平均时间
Chunk Writes: 由 Chunk 清除操作将已更改的缓冲区写入磁盘的数量。Chunk 清除程序撰写了所有在缓冲池中的某个 chunk 内的已更改的缓冲区。这项操作在需要快速清除大量缓冲区(例如 checkpoint 进程和快速恢复)的各种特殊环境中进行。
Total Mem: 缓冲池的大小
id: 缓冲池段的 ID
segment: 缓冲池段的内部地址
size: 缓冲池段的大小
# buffs: 缓冲池段中缓冲区数
Fast Cache Stats: 快速缓存(减少需要访问缓冲池的时间类型的缓存)的统计信息
gets: 服务器在快速缓存中寻找缓冲区的次数
hits: 服务器发现它正在寻找快速缓存缓冲区的次数
%hits: hits 的百分比 ,即 hits*100/gets
puts: 服务器向快速缓存中插入缓冲区的次数
onstat -g cac 命令:打印有关缓存的信息
使用 onstat -g cac 命令来查看所有缓存或单个缓存的整体和详细信息。
语法:
可以使用不带任何选项的 onstat -g cac 命令查看所有缓存的信息。
使用以下选项来查看特定缓存的信息:
agg: 打印有关聚合缓存的信息
aqt: 打印有关 AQT 字典高速缓存的信息(它与 onstat -g aqt 命令输出一样的信息)。请参阅 onstat -g aqt 命令:打印数据集和加速查询表的信息
am: 打印有关访问方法缓存的信息。可以看到指定访问方法的信息,包括访问方法名称。
cast: 打印有关 cast 缓存的信息
dic: 打印有关数据字典高速缓存的信息。也是打印 onstat -g dic 命令输出的信息。请参阅 onstat -g dic 命令:打印表信息
dsc: 打印有关数据分布式缓存的信息。也是打印 onstat -g dsc 命令输出的信息。请参阅 onstat -g dsc 命令:打印分布式高速缓存信息
ed: 打印有关外部命令缓存的信息
lbacplcy: 打印有关 LBAC 安全政策信息缓存的信息
lbacusrc: 打印有关 LBAC 证书内存缓存的信息
opci: 打印有关操作类实例缓存的信息
prc: 打印有关 UDR 缓存的信息。也是打印 onstat -g prc 命令输出的信息。请参阅 onstat -g prc 命令:打印使用 UDR 或 SPL 例程的会话
prn: 打印有关程序名称缓存的信息
rr: 打印瞬变的二级缓存的信息
ssc: 打印 SQL 语句缓存信息。也是打印 onstat -g ssc 命令输出的信息。请参阅 onstat -g ssc 命令:打印出现的 SQL 语句
ttype: 打印二级瞬变缓存的信息
typei: 打印由其 ID 缓存的扩展类信息。可以看到指定扩展类的信息,包括扩展类 ID。
typen: 打印由其名称缓存的扩展类信息。可以看到指定扩展类的信息,包括扩展类名称。
示例输出
大多数 onstat -g cac 命令的输出包含相似的格式和信息。
以下是一个 onstat -g cac lbacplcy 命令的示例输出:
Security Policy Info Cache:
Number of lists : 31
PLCY_POOLSIZE : 127
Security Policy Info Cache Entries:
list id ref drop hits heap_ptr item
--------------------------------------------------------------
9 2 0 0 0 65f1b8d0 test@gbasesbt: : secpolicyid 2
15 1 0 0 0 65f1b4d0 test@gbasedbt: : secpolicyid 1
Total number of entries : 2
Number of entries in use : 0
输出描述
大多数 onstat -g cac 命令的输出包含以下字段:
Number of lists: 分布式缓存中列表数
configuration parameter name : 一次可以缓存的条目数
list: 分布式缓存哈希链 ID
id: 该缓存条目的唯一 ID
ref: 引用缓存条目的语句数
drop: 当此条目被添加到缓存中后,它是否曾被删除
hits: 该缓存条目被访问的次数
heap_ptr: 用于存储此条目的堆地址
item name : 高速缓存项的名称
Total number of entries: 缓存条目的数量
Number of entries in use: 正在使用的条目数
onstat -g ckp 命令:打印 checkpoint 历史记录和配置建议
可以使用 onstat -g ckp 命令打印 checkpoint 历史记录,显示配置建议(如果检测到次优的配置)。
语法:

示例输出
图: onstat -g ckp 命令输出
![]()


输出描述
Auto Checkpoints: 标示 AUTO_CKPTS 配置参数是 on 或 off
RTO_SERVER_RESTART: 显示 RTO 时间(以秒为单位)。零(0)意味着 RTO 是关闭的
Estimated recovery time ## seconds: 如果数据服务器停止响应,标示评估恢复时间。该值仅在 RTO_SERVER_RESTART 被激活时出现。
Interval: Checkpoint 间隔 ID
Clock Time: Checkpoint 发生的 Clock 时间
Trigger: 事件触发 checkpoint 。 星号(*)表示请求的 checkpoint 是事务阻塞的 checkpoint 。
| 触发器名称 | 描述 |
|---|---|
| Admin | 管理员相关任务。例如: ● 创建、删除或重命名 dbspace ● 添加或删除 chunk ● 添加或删除日志文件 ● 更改物理日志大小和位置 ● 分区上 "shrink" 操作之后 ● 打开或关闭镜像 |
| Backup | 备份相关操作。例如: ● 假备份 ● 启动归档 ● 完整的物理恢复后 |
| CDR | 第一次启动 ER 子系统或在所有复制参与者被移除后,重启 ER 子系统 |
| CKPTINTVL | 当 checkpoint 间隔过期。Checkpoint 间隔是在 onconfig 文件中 CKPTINTVL 参数指定的值 |
| Conv/Rev | 转换复原 checkpoint 。转换检查阶段后磁盘结构实际实际转换前。复原完成之后也将触发 checkpoint 。 |
| HA | 高可用性。例如: ● 新添加到高可用集群的 RHAC 或 SSC 节点 ● 提升为主服务器的辅助服务器 ● 物理日志文件低的辅助服务器 |
| HDR | 高可用性数据复制。例如: ● 更改的服务器方式 ● 安装 HAC 后的启动第一次传输 ● 有潜在的主或辅助服务器上的物理日志溢出 |
| Lightscan | 在分区上关闭观察四周之前 |
| Llog | 逻辑日志资源耗尽 |
| LongTX | 长事务。如果发现长事务未停止,那么会发起 checkpoint 停止该事务。在回滚过程中,如果在长事务终止后 checkpoint 还未准备发生,那么会在回滚阶段发起 checkpoint 。 |
| Misc | 杂项事件。例如:: ● 由于 I/O 错误 dbspace 或 chunk 关闭 ● 在回滚过程中,撤销 chunk 的附加部分时。例如:正在移动 chunk 时。 ● 聚集索引创建的过程中或变更索引为聚集索引时。 |
| Plog | 物理日志具有以下之一的条件: ● 物理日志已满 75% ● 已使用的物理日志量加上脏分区的数量已超出物理日志大小的 90% |
| Restore Pt | 还原点。Checkpoint 在还原点开始和结束。还原点(由转换守护程序使用)是启用的 CONVERSION_GUARD 配置参数,是 RESTORE_POINT_DIR 配置参数指定的临时目录。 |
| Recovery | 在恢复过程中,快速恢复开始时 |
| Reorg | 在在线索引生成开始 |
| RTO | 维护恢复时间目标(RTO)协议。在正常操作时,在系统崩溃后重新启动的时间可能会超过 RTO_SERVER_RESTART 配置参数所设置的值。 |
| Stamp Wrap | Checkpoint 时间戳。如果新的 checkpoint 时间戳出现在最后写入的 checkpoint 之前,那么时间戳在 checkpoint 间间隔先进先出。这样会触发另一个 checkpoint 。 |
| Startup | 数据库服务器启动时。 |
| Uncompress | 在表或分区上发生解压命令。只在表中的 checkpoint 或 没有日志记录的数据库中应用。 |
| User | 用户提交 checkpoint 请求 |
LSN: Checkpoint 记录在逻辑日志中的位置
Total Time: 以秒表示 checkpoint 持续的总时间,从请求开始到 checkpoint 结束
Flush Time: 以秒表示清除缓冲池的时间
Block Time: 由于 checkpoint 被稀缺的必需资源触发而导致事务阻塞的时间(以秒表示)。例如:耗尽物理日志或环绕逻辑日志
# Waits: 由于正在等待 checkpoint 而阻塞的事务的数量
Ckpt Time: 以秒表示所有事务认识到请求的 checkpoint 的时间
Wait Time: 以秒表示该事务已等待 checkpoint 的平均时间
Long Time: 以秒表示事务等待 checkpoint 的最长时间
# Dirty Buffers: 在 checkpoint 期间,刷新到磁盘的 dirty 缓冲区的数量
Dskflu/sec: 每秒刷新的缓冲区数
Physical Log Total Pages: 在 checkpoint 间隔,物理日志记录的总页数
Physical Log Avg/Sec: 在 checkpoint 间隔,物理日志活动的平均率
Logical Log Total Pages: 在 checkpoint 间隔,逻辑日志记录的总页数
Logical Log Avg/Sec: 在 checkpoint 间隔,逻辑日志活动的平均率
Max Plog pages/sec: 在 checkpoint 间隔,物理日志活动的最大速率
Max Llog pages/sec: 在 checkpoint 间隔,逻辑日志活动的最大速率
Max Dskflush Time: 以秒表示缓冲池刷新到磁盘的最长时间
Avg Dskflush pages/sec: 缓冲池刷新到磁盘的平均速率
Avg Dirty pages/sec: 在 checkpoint 之间 dirty 页的平均速率
Blocked Time: 以秒表示自上次数据库服务器启动后最长阻塞时间
如果 GBase 8s 数据服务器检测到一个次优的配置,那么在 checkpoint 历史记录下会出现一个有关性能调整的建议消息。该性能建议也在消息日志中出现。以下是性能建议消息的示例:

onstat -g cfg 命令:打印配置参数的当前值
使用 onstat -g cfg 命令打印配置参数当前值列表。可以使用更多命令选项以打印更多有关配置参数的信息。
语法:
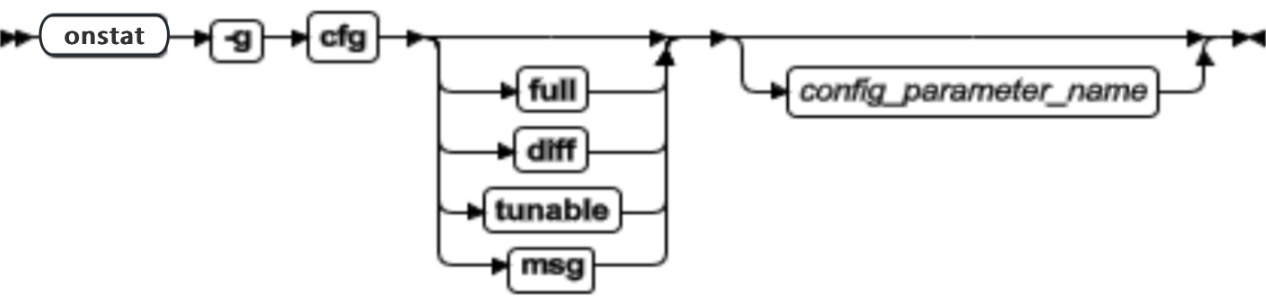
onstat -g cfg 命令具有以下格式:
onstat -g cfg 命令选项:
| 命令 | 描述 |
|---|---|
| onstat -g cfg | 显示配置参数当前值列表 |
| onstat -g cfg config_parameter_name | 只显示指定的配置参数的当前值 |
| onstat -g cfg full | 显示每个配置参数的所有信息,包括当前值、缺省值、 onconfig 文件值和参数描述 |
| onstat -g cfg full config_parameter_name | 显示指定参数的所有信息 |
| onstat -g cfg diff | 显示配置参数当前值不同于其在 onconfig 文件中的永久值的信息 |
| onstat -g cfg tunable | 显示所有可调整参数的缺省值、源值和当前值。星号(*)表示您可以动态调整该配置参数 |
| onstat -g cfg msg | 显示任意消息,例如:与配置参数相关的警告或调整 |
示例输出
以下是 onstat -g cfg 命令显示数据库启动后 DEADLOCK_TIMEOUT 配置参数值被动态更改为 90 的输出样本:
id name type units rsvd tunable
26 DEADLOCK_TIMEOUT INT4 Seconds *
min/max : 0,2147483647
default : 60
onconfig:
current : 90
Description:
Use the DEADLOCK_TIMEOUT configuration parameter to specify the
maximum number of seconds that a database server thread can wait to acquire a lock.
ROOTNAME rootdbs
以下是 onstat -g cfg diff 命令显示 TBLTBLFIRST 和 TBLTBLNEXT 配置参数的缺省值、当前值和其在 onconfig 文件中的值的输出样本:
id name type units rsvd tunable
53 TBLTBLFIRST INT4 KB *
default : 500
onconfig: 0
current : 250
id name type units rsvd tunable
54 TBLTBLNEXT INT4 KB *
default : 100
onconfig: 0
current : 150
以下是显示有关 MSGPATH 配置参数的信息的输出样本。在这里,没有建立该配置参数的缺省值、当前值及其 onconfig 文件:
id name type units rsvd tunable
10 MSGPATH CHAR * *
default :
onconfig: /work2/JC/online.log
current : /work2/JC/online.log
以下是 onstat -g cfg msg 命令显示标识已更改值的配置参数的消息的输出样本:
Configuration Parameters With Messages
name message
TBLTBLFIRST Parameter's user-configured value was adjusted.
TBLTBLNEXT Parameter's user-configured value was adjusted.
BUFFERPOOL Parameter's user-configured value was adjusted.
STACKSIZE Parameter's user-configured value was adjusted.
VPCLASS Parameter's user-configured value was adjusted.
输出描述
name: 配置参数名称
type: 值的数据类型
units: 值表示的单位
rsvd: 标示(带星号)配置参数及其值存储在配置驻留页中
如果没有星号,那么该配置参数及其值不存储在配置驻留页中
tunable: 标示(带星号)此配置参数可以动态调整。例如:使用 onmode -wm 或 -wf 命令,如果没有星号,那么该配置参数不能被动态地修改
min/max: 配置参数的最大值和最小值
default: 建立到服务器中配置参数的缺省值
onconfig: 配置参数值,任和值都在 onconfig.std 文件中
current: 配置参数的当前值,如果动态修改了该值,其当前值是不同的。例如:使用 onmode -wm 命令
Description: 配置参数的描述
message: 标识一个已更改的配置参数值的消息
onstat -g cluster 命令:打印高可用集群信息
可以使用 onstat -g cluster 命令显示有关在高可用集群环境下的服务器的信息。onstat -g cluster 命令合并了 onstat -g dri 、onstat -g sds 和 onstat -g rss 的功能。 onstat -g cluster 命令的输出根据该命令是在主服务器或在其它任一辅助服务器上运行而稍有不同。
语法:

示例输出(主服务器)
以下 onstat -g cluster 命令的示例输出。该示例显示了命令运行在主服务器上的输出。
图: onstat -g cluster 命令输出(自主服务器上运行)

输出描述(主服务器)
Primary server: 分配的主服务器的名称
Current log page: 当前日志页的日志 ID 和页数
Index page logging status: 指示索引页日志记录是否启用或禁用
Index page logging was enabled at: 启用索引页日志记录的日期和时间
Server: 辅助服务器的名称
ACKed Log (log, page): 最后一次应答日志传输的日志 ID 和页数
Applied Log (log, page): 最后一次应用日志传输的日志 ID 和页数
Supports Updates: 显示客户端应用程序是否可以在辅助服务器上执行修改、插入和删除操作(由 UPDATABLE_SECONDARY 配置参数指定)。
Status: 显示辅助服务器的连接状态
示例输出(主服务器,详细输出)
图: onstat -g cluster verbose 命令输出(自主服务器上运行)
以下是 onstat -g cluster verbose 命令的示例输出。该输出显示此命令在主服务器上运行,并带有详细的选项。
Primary Server:serv1
Current Log Page:16,479
Index page logging status: Enabled
Index page logging was enabled at: 2013/12/11 14:05:17
-----------------------------------------------------------
server name: serv3
type: ASYNC (HDR)
control block: 0x4b673018
server status: On
connection status: Connected
Last log page sent (log id, page): 16,479
Last log page acked (log id, page); 16,479
Last log page applied (log id, page); 16,479
Approximate log page backlog: 0
SDS cycle not used
Delayed Apply Not Used
Stop Apply Not Used
Time of last ack: 2013/12/11 14:09:12
Supports Updates: Yes
-----------------------------------------------------------
server name: serv2
type: SYNC (SDS)
control block: 0x4c2de0b8
server status: Active
connection status: Connected
Last log page sent (log id, page): 16,479
Last log page acked (log id, page); 16,479
Last log page applied (log id, page); 16,479
Approximate log page backlog: 0
SDS cycle current: 20 ACKed: 20
Delayed Apply Not Used
Stop Apply Not Used
Time of last ack: 2013/12/11 14:09:13
Supports Updates: Yes
输出描述(主服务器,详细输出)
Primary server : 主服务器名
Current log page : 当前日志页的日志 ID 和页数
Index page logging status : 指示索引页日志记录是否启用或禁用
Index page logging was enabled at : 启用索引页日志记录的日期和时间
Server name : 辅助服务器的名称
type : 显示该辅助服务器的连接是同步(SYNC)还是异步(ASYNC)。也显示辅助服务器的类型:HDR 、SDS 或 RSS
control block : 线程控制 block 的在内存中的地址
server status : 显示辅助服务器的当前状态
connection status : 显示辅助服务器的当前网络连接状态
Last log page sent (log id, page) : 最近一次主服务器发送到辅助服务器的日志页的日志 ID 和页数
Last log page acked (log id, page) : 辅助服务器最近应答的日志页的日志 ID 和页数
Last log page applied (log id, page) : 辅助服务器最近应用的日志页的日志 ID 和页数
Approximate log page backlog : 指示还未被辅助服务器处理的日志页的大概数目
SDS cycle : 指示共享磁盘辅助服务器已确认的周期数和主服务器具有先进的循环次数。由 GBase 支持用于监控主服务器和辅助服务器的协调性。
Delayed Apply : 指示该辅助服务器在应用日志前是否等待特定的时间量(通过 DELAY_APPLY 配置参数指定)
Stop Apply : 指示该辅助服务器是否已停止应用从主服务器接收的日志文件(通过 STOP_APPLY 配置参数指定)
Time of last ack : 最后一次通知日志的日期和时间
Supports Updates : 显示客户端应用程序是否可以在辅助服务器上执行修改、插入和删除操作(由 UPDATABLE_SECONDARY 配置参数指定)
示例输出(辅助服务器)
以下是 onstat -g cluster 命令的输出示例。该示例显示命令在辅助服务器上运行的输出。
图: onstat -g cluster 命令输出(自辅助服务器上运行)
Primary Server:serv1
Index page logging status: Enabled
Index page logging was enabled at: 2010/01/11 14:05:17
Server ACKed Log Applied Log Supports Status
(log, page) (log, page) Updates
serv2 16,479 16,479 Yes SYNC(SDS),Connected,Active
输出描述(辅助服务器)
Primary server : 主服务器的名称
Index page logging status : 指示索引页日志记录是否启用或禁用
Index page logging was enabled at : 启用索引页日志记录的日期和时间
Server : 辅助服务器的名称
ACKed Log (log, page) : 最后一次应答日志传输的日志 ID 和页数
Applied Log (log, page): 最后一次应用日志传输的日志 ID 和页数
Supports Updates : 显示客户端应用程序是否可以在辅助服务器上执行修改、插入和删除操作(由 UPDATABLE_SECONDARY 配置参数指定)
Status : 显示辅助服务器的连接状态
onstat -g cmsm 命令:打印连接管理器的信息
onstat -g cmsm 显示连接连接管理器的连接单元、每个连接管理器服务等级协议(SLA) 处理的连接数、SLA 定义、故障切换顺序规则、故障转移仲裁以及主服务器状态。
使用 connection_manager_name 来显示指定的连接管理器实例的信息。如果没有指定 connection_manager_name ,onstat -g cmsm 显示所有连接数据库服务器的连接管理器的信息。
语法:

示例输出 1:指定的连接管理器的输出
在以下示例中,onstat -g cmsm connection_manager_1 在主服务器的 my_cluster_1 上运行:
Unified Connection Manager: connection_manager_1 Hostname: my_host_1
CLUSTER my_cluster_1 LOCAL
SLA Connections Service/Protocol Rule
oltp_1 35 19910/onsoctcp DBSERVERS=primary
report_1 33 19810/onsoctcp DBSERVERS=(HDR,SDS,RSS)
Failover Arbitrator: Active Arbitrator, Primary is up ORDER=SDS,HDR,RSS PRIORITY=1
该命令显示 connection_manager_1 的输出。connection_manager_1 管理一个 CLUSTER 连接单元,并且是主故障转移仲裁者。
示例输出 2:高可用性集群的输出
在以下示例中,onstat -g cmsm 在主服务器的 my_cluster_2 上运行:
Unified Connection Manager: connection_manager_2 Hostname: my_host_2
CLUSTER my_cluster_2 LOCAL
SLA Connections Service/Protocol Rule
sla_1 1535 19910/onsoctcp DBSERVERS=primary
sla_2 2133 19810/onsoctcp DBSERVERS=(HDR,SDS,RSS)
Failover Arbitrator: Active Arbitrator, Primary is up
ORDER=SDS,HDR,RSS PRIORITY=1
CLUSTER my_cluster_3
SLA Connections Service/Protocol Rule
sla_3 730 19930/onsoctcp DBSERVERS=primary
sla_4 901 19830/onsoctcp DBSERVERS=(HDR,SDS,RSS)
Failover Arbitrator: Active Arbitrator, Primary is up
ORDER=SDS,HDR,RSS PRIORITY=1
Unified Connection Manager: connection_manager_3 Hostname: my_host_3
CLUSTER my_cluster_2 LOCAL
SLA Connections Service/Protocol Rule
sla_5 614 19920/onsoctcp DBSERVERS=primary
sla_6 483 19820/onsoctcp DBSERVERS=(HDR,SDS,RSS)
Failover Arbitrator: Failover is enabled
ORDER=SDS,HDR,RSS PRIORITY=2
CLUSTER my_cluster_3
SLA Connections Service/Protocol Rule
sla_7 678 19940/onsoctcp DBSERVERS=primary
sla_8 270 19840/onsoctcp DBSERVERS=(HDR,SDS,RSS)
Failover Arbitrator: Failover is enabled
ORDER=SDS,HDR,RSS PRIORITY=2
该命令显示连接到主服务集群的两台连接管理器。connection_manager_2 和 connection_manager_3 安装在不同的主机上,并且它们一起管理两个 CLUSTER 连接单元。connection_manager_2 是这些 CLUSTER 连接单元的主故障转移仲裁者。
示例 3:复制设置的输出
在以下示例中,onstat -g cmsm 在复制服务器的 my_replicate_set_1 中运行。
Unified Connection Manager: connection_manager_4 Hostname: my_host_4
REPLSET my_replicate_set_1
SLA Connections Service/Protocol Rule
sla_1 160 19810/onsoctcp DBSERVERS=ANY
Unified Connection Manager: connection_manager_5 Hostname: my_host_5
REPLSET my_replicate_set_1
SLA Connections Service/Protocol Rule
sla_2 240 19820/onsoctcp DBSERVERS=ANY
该命令显示了两台连接到复制服务器的连接管理器。connection_manager_4 和 connection_manager_5 分别安装在不同的主机,并且它们一起管理复制服务器。
示例 4:Grid 的输出
在以下示例中,onstat -g cmsm 在 my_grid_1 的一个节点上运行。
Unified Connection Manager: connection_manager_6 Hostname: my_host_6
GRID my_grid_1
SLA Connections Service/Protocol Rule
sla_1 456 19830/onsoctcp DBSERVERS=(group_name_1,group_name_2) POLICY=FAILURE
Unified Connection Manager: connection_manager_7 Hostname: my_host_7
GRID my_grid_1
SLA Connections Service/Protocol Rule
sla_2 785 19840/onsoctcp DBSERVERS=(group_name_1,group_name_2)POLICY=FAILURE
该命令显示了两台连接到 grid 的连接管理器。它还显示了连接到该节点的两台连接管理器。connection_manager_6 和 connection_manager_7 分别安装在不同的主机,并且它们一起管理 grid 。
示例 5 :服务器集的输出
在以下示例中,onstat -g cmsm 在一个独立服务器的服务器集上运行。
Unified Connection Manager: connection_manager_8 Hostname: my_host_8
SERVERSET server_1,server_2
SLA Connections Service/Protocol Rule
sla_1 63 19810/onsoctcp DBSERVERS=(server_1,server_2) POLICY=ROUNDROBIN
Unified Connection Manager: connection_manager_9 Hostname: my_host_9
SERVERSET server_1,server_2
SLA Connections Service/Protocol Rule
sla_2 63 19810/onsoctcp DBSERVERS=(server_1,server_2) POLICY=ROUNDROBIN
该命令显示了两台连接到此服务器集的连接管理器。connection_manager_8 和 connection_manager_9 分别安装在不同的主机,并且它们一起管理 该服务器集。。
输出描述
onstat -g cmsm 命令的输出包含每个连接管理器的章节。每一节显示连接管理器实例的名称和主机名,之后包含有关连接管理器连接的每个连接单元的子章节。
Unified Connection Manager
连接管理器实例的名称
Hostname: 连接管理器的主机的名称
SLA: 服务等级协议的名称,在连接管理器的配置文件中设置。
Connections: 自从连接管理器启动后,每个 SLA 处理的连接数
Service/Protocol: 与 SLA 相关联的端口号或服务名,随后的是连接协议类型
Rule: SLA 定义
Failover Arbitrator: 指定连接管理器是否是主故障转移仲裁者(如果主服务器是活动的,并且故障转移启用)仅用于显示 CLUSTER 连接单元
ORDER: 指定集群的故障切换顺序。仅用于显示 CLUSTER 连接单元
PRIORITY: 指定连接管理器和集群主服务器的连接优先级。仅用于显示 CLUSTER 连接单元
onstat -g con 命令:打印条件和线程信息
使用 onstat -g con 命令显示有关条件及正在等待这些条件的线程的信息。
语法:
示例输出
图: onstat -g con 命令输出
Conditions with waiters:
cid addr name waiter waittime
271 c63d930 netnorm 1511 6550
输出描述
cid: 条件标识符
addr: 条件控制 block 地址
name: 线程正在等待的条件的名称
waiter: 正在等待条件的线程的 ID
waittime: 以秒表示的线程已经等待此条件的时间
onstat -g cpu: 打印运行时间统计信息
使用 onstat -g cpu 命令显示正在服务器上运行的每个线程的运行时间的统计信息。
语法:
示例输出
图: onstat -g cpu 命令输出
输出描述
tid: 线程 ID
name: 线程名称
vp: 正在运行线程的虚拟处理器的 ID
Last Run: 线程上次运行的时间戳
CPU Time: 直到现在线程运行的时间
#scheds: 线程被安排运行的次数
status: 线程的状态。可能值如下:
- cond wait
- IO Idle
- join wait
- mutex wait
- ready
- sleeping
- terminated
- running
- yield
onstat -g dbc 命令:打印 dbScheduler 和 dbWorker 线程的统计信息
使用 onstat -g dbc 命令显示有关正在运行的调度任务(一些由 dbWorker 处理或计划运行,一些由 dbScheduler 线程处理。)的统计信息。
语法:
示例输出
图: onstat -g dbc 命令输出
Worker Thread(0) 46fa6f10
=====================================
Task: 47430c18
Task Name: mon_config_startup
Task ID: 3
Task Type: STARTUP SENSOR
Last Error
Number -310
Message Table (gbasedbt.mon_onconfig) already exists in database.
Time 09/11/2007 11:41
Task Name mon_config_startup
Task Execution: onconfig_save_diffs
WORKER PROFILE
Total Jobs Executed 10
Sensors Executed 8
Tasks Executed 2
Purge Requests 8
Rows Purged 0
Worker Thread(1) 46fa6f80
=====================================
Task: 4729fc18
Task Name: mon_sysenv
Task ID: 4
Task Type: STARTUP SENSOR
Task Execution: insert into mon_sysenv select 1, env_name, env_value FROM
sysmaster:sysenv
WORKER PROFILE
Total Jobs Executed 3
Sensors Executed 2
Tasks Executed 1
Purge Requests 2
Rows Purged 0
Scheduler Thread 46fa6f80
=====================================
Run Queue
Empty
Run Queue Size 0
Next Task 7
Next Task Waittime 57
输出描述:
Worker Thread: 共享内存中工作线程的地址
Task: 最后执行的任务的名称
Task ID: 来自 sysadmin:ph_task 表中的 tk_id 列有关该任务的任务 ID
Task Type: 任务的类型
Last Error: dbWorker 线程遇到的最后的错误的错误号、错误消息、时间(以秒为单位)和任务名称。它可能来自上一次执行的任务也可能来自几天前执行的任务。
Task Execution: SQL 语句或 SPL 程序或作为部分任务已执行的例程
WORKER PROFILE: dbWorker 线程概要文件数据显示总共执行的工作量、已执行的传感器的数、已执行的任务数和从通过此 dbWorker 线程执行的所有传感器的结果表中已清除的行数。
Scheduler Thread: 共享内存中调度线程的地址
Run Queue: 下一个要调度任务的任务 ID 。如果没有计划任务,那么该值为 Empty
Run Queue Size: 正在等待通过 dbWorker 执行的任务的数量
Next Task: 安排的下一个要执行的任务的任务 ID
Next Task Waittime: 安排的 Next Task 要执行前的秒数
onstat -g defragment 命令:打印磁盘碎片整理的分区 extent
使用 onstat -g defragment 命令显示有关磁盘碎片分区 extent 的活动请求的信息。
语法:

示例输出
图: onstat -g defragment 命令输出

该命令显示有关活动的磁盘碎片请求的信息。如果没有活动的磁盘碎片请求,那么仅返回列标题。
输出描述
id: 磁盘碎片请求的 ID
table name: 正在进行碎片整理的表的全名
tid: 线程 ID
dbsnum: 正在进行碎片整理的 dbspace 的数量
partnum: 正在进行碎片整理的分区的数量
status
- SEARCHING_FOR_EXTENT
- MERGING_EXTENTS
- DEFRAG_COMPLETED
- DEFRAG_FAILED
substatus: 详细的状态号,如果有的话
errnum: 最后一次碎片整理请求返回的错误号
onstat -g dic 命令:打印表信息
使用 onstat -g dic 命令显示共享内存字典中高速缓存的每张表的一行信息。如果指定了表名,那么打印表的内部 SQL 信息。
语法:

示例输出
图: onstat -g dic 命令输出
Dictionary Cache: Number of lists: 31, Maximum list size: 10
list# size refcnt dirty? heapptr table name
--------------------------------------------------------
1 3 1 no 14b5d890 wbe@oninit_shm:gbasedbt.t0010url
1 no 14cbb820 wbe@oninit_shm:gbasedbt.t9051themeval
0 no 14b63c20 wbe@oninit_shm:gbasedbt.t0060hits
2 2 0 no 14b97420 wbe@oninit_shm:gbasedbt.t0120import
1 no 14b6c820 wbe@oninit_shm:gbasedbt.t9110domain
3 3 0 no 14bce020 wbe@oninit_shm:gbasedbt.t0150url
0 no 14d3d820 contact@oninit_shm:gbasedbt.wbtags
0 no 14c87420 wbe@oninit_shm:gbasedbt.wbtags
4 1 0 no 14b7a420 drug@oninit_shm:abcdef.product ..
Total number of dictionary entries: 36
输出描述
list#: 数据字典哈希链 ID
size: 在此哈希列中的条目的数量
refcnt: 当前引用高速缓存条目之一的 SQL 语句的数量
dirty?: 自上次写入磁盘以来条目是否已修改
heapptr: 用于存储此表的堆的地址
table name: 在高速缓存中的表的名称
onstat -g dis 命令:打印数据库服务器信息
使用 onstat -g dis 命令显示数据库服务器及其状态列表和有关每个数据服务器,包括 GBASEDBTDIR 目录位置、sqlhosts 文件以及 ONCONFIG 文件的信息。可以在数据库服务器处于任何方式(包括离线) 时使用该命令。
语法:

示例输出
图: onstat -g dis 命令输出
There are 2 servers found
Server : ol_tuxedo
Server Number : 53
Server Type : IDS
Server Status : Up
Server Version: GBase Database Server Version 12.10.FC4G1TL
Shared Memory : 0xa000000
GBASEDBTDIR : /opt/gbs_server/home
ONCONFIG : #
SQLHOSTS : /opt/gbs_server/data/conf/sqlhosts
Host : avocet
Server : ol_9next
Server Number : 0
Server Type : IDS
Server Status : Down
Server Version:
Shared Memory : 0
GBASEDBTDIR : /local1/engines/gbs_server/home
ONCONFIG :
SQLHOSTS :
Host :
输出描述
Server: 服务器名称
Server Number: 服务器编号
Server Type: 服务器类型
Server Status: Up 表示服务器在线,Down 表示服务器离线
Server Version: 服务器版本
Shared Memory: 共享内存地址的位置
GBASEDBTDIR : 在 UNIX™ 中是 $GBASEDBTDIR 目录的位置
SQLHOSTS: sqlhosts 文件的位置
Host: 服务器的主机名
onstat -g dll 命令:打印动态链接库文件列表
使用 onstat -g dll 命令显示已加载的动态链接库(DLL)文件列表。
语法:
示例输出
该输出显示仅一次每个进程组库文件的名称。该标记标示当服务器启动后,库是否已加载。
图: onstat -g dll 命令输出
addr slot vp baseaddr flags filename
0x4af55310 15 1 0x2a985e3000 PM /finance/jeffzhang/mylib.udr
0x4b6f2310 2 0x2a985e3000
0x4b71b310 3 0x2a985e3000
0x4c09f310 16 1 0x2a985e3000 M /deptxyz/udrs/geodetic.bld
0x4c0c0310 2 0x2a985e3000
0x4c0f1310 3 0x2a985e3000
0x4c112310 17 1 0x7a138e9000 /home/gbasedbt/extend/blade.so
0x4c133310 2 0x3a421e1000
0x4c133310 3 0x3a421e1000
输出描述
addr: DLL 文件的地址
slot: 在库表中的 Slot 编号条目
vp: 虚拟处理器的 ID
baseaddr: 共享库的基地址
flags
- M 标示呼叫 UDR 的线程可从从一个 CPU 虚拟处理器转移到另一个 CPU 虚拟处理器
- P 标示当数据库服务器启动后,该共享库已加载
filename: DLL 文件的名称
onstat -g dmp 命令:打印原内存
使用 onstat -g dmp 命令显示有关在若干个给定的字节的给定的地址处原内存信息。每个地址和长度必须在 onstat -g seg 输出中显示的分配内存的范围之内。指定的地址格式可以是十进制或十六进制。十六进制地址必须以 0x 开头。可以指定该地址为十进制,但是这样做需要在使用它作为命令行参数之前,将 onstat -g seg 显示的内存转换为十进制。
语法:

示例输出
图: onstat -g dmp 命令输出
%onstat -g dmp 0x700000011a19d48 100
address bytes in mem
0700000011a19d48: 07000000 118e0fa8 07000000 11942b40 ........ ......+@
0700000011a19d58: 07000000 10137120 00000000 00000000 ......q ........
0700000011a19d68: 00000000 00000000 00000000 00000000 ........ ........
0700000011a19d78: 07000000 11a19d48 07000000 11a19d48 .......H .......H
0700000011a19d88: 00000000 00000000 00000000 00000000 ........ ........
0700000011a19d98 *
0700000011a19da8: 00000000 ....
输出描述
address: 原内存的内存地址
bytes in mem: 内存内容的十六进制和 ASCII 说明:该命令的输出分为三列:内存地址、以字节表示的内存十六进制值和内存的 ASCII 字节说明。内存中的字节(中间)章节显示了内存位于命令行中指定地址的前 16 个字节。第三列显示了十六进制数据的 ASCII 说明。所有没有等价的 ASCII 字符的十六进制值都会显示成间隔符。显示 ASCII 值是为了使纯文本搜寻更简便。在以上显示的示例输出中,第五行数据显示零并且第六行包含星号。星号标识前一行重复的未知编号,它表示在第四行之后没有更多的数据。
onstat -g dri 命令:打印高可用性数据复制信息
使用 onstat -g dri 命令(单独使用或和 ckpt 或 que 选项一起使用),来打印有关当前服务器中的高可用性数据复制的统计信息。可以使用 onstat -g dri 命令打印有关 HAC 服务器状态和 HRD 相关配置参数信息。
语法:
onstat -g dri 的示例输出和输出描述
图: onstat -g dri 命令输出
Data Replication at 0x4d676028:
Type State Paired server Last DR CKPT (id/pg) Supports Proxy Writes
primary on my_server 4 / 5 NA
DRINTERVAL 5
DRTIMEOUT 30
DRAUTO 3
DRLOSTFOUND /etc/dr.lostfound
DRIDXAUTO 0
ENCRYPT_HDR 0
Backlog 0
Last Send 2013/12/11 16:39:48
Last Receive 2013/12/11 16:39:48
Last Ping 2013/12/11 16:39:44
Last log page applied(log id,page): 4,6
Type: 服务器的当前类型:主服务器、辅助服务器或标准服务器
State: on 或 off
Paired server: 与该服务器配对的主服务器或辅助服务器的名称
Last DR CKPT: 最后 checkpoint ID 和页
Supports Proxy Writes: 显示该服务器是否配置允许辅助服务器更新。Y = 支持辅助服务器更新,N = 不支持辅助服务器更新
DRINTERVAL: onconfig 文件中配置参数的值
DRTIMEOUT: onconfig 文件中配置参数的值
DRAUTO: onconfig 文件中配置参数的值
DRLOSTFOUND: onconfig 文件中配置参数的值
DRIDXAUTO: onconfig 文件中配置参数的值
ENCRYPT_HDR: onconfig 文件中配置参数的值
Backlog: 在 HAC 数据复制缓冲区中还未发送到 HRD 辅助服务器中的日志页数
Last Send: 最后一个消息发送至对等节点的时间
Last Receive: 从对等节点接收的最后一个消息的时间
Last Ping: 上次 ping 的时间
Last log page applied(log id,page): 上次应用日志的日志 ID 和页
onstat -g dri ckpt 的示例输出和输出描述
使用 onstat -g dri ckpt 命令打印在 HAC 服务器中未阻塞的 checkpoint 的信息。
图: onstat -g dri ckpt 命令输出
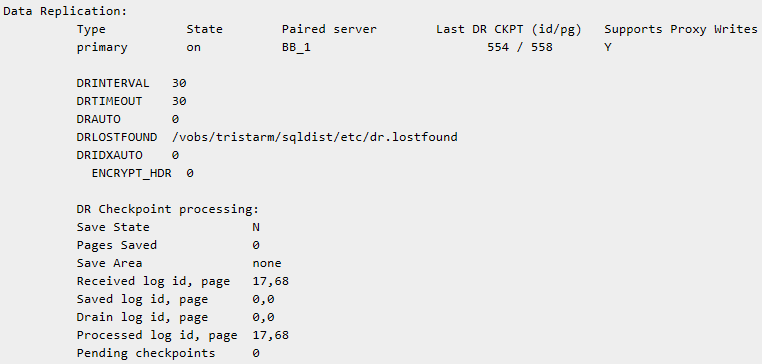
Save State
B (buffering) 服务器正在向暂存区添加日志
D (draining) 服务器正在从暂存区移除日志
N (normal) 服务器正常工作,这意味着没有保存日志
Pages Saved: 显示保存在暂存区还没应用的日志的页数
Save Area: 显示暂存日志文件的位置
Received log id, page: 显示从主服务器接收的最后一个日志的 ID 和页
Processed log id, page: 显示排队等待恢复管道的最后一个日志的 ID 和页
Saved log id, page: 显示存储在暂存区(如果暂存区状态是 B 或 D)的最后一个日志的 ID 和页
Drain log id, page: 显示最后一个从暂存区移除的日志的 ID 和页
Pending checkpoints: 显示暂存的还未应用的 checkpoint 数量
Pending ckpt log id, page: 显示任意暂押的 checkpoint 记录的位置
onstat -g dri que 的示例输出和输出描述
使用 onstat -g dri que 命令打印几乎与 HAC 复制同步相关的信息。
图: onstat -g dri que 命令输出
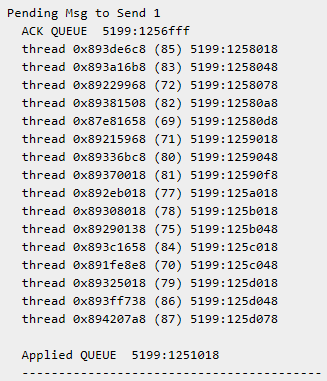
Pending message to send: 在 drprsend 线程的复制缓冲区排队的未处理的数据的数量
ACK QUEUE: 日志唯一值、页编号和最近大多数 GBase_8s paged 的日志的 0xfff 值
thread: 线程控制 block (TCB)的指针,括号中的数字为此线程的 ID,和由该线程执行提交的日志序列号(LSN)
Applied QUEUE: 被 HAC 辅助服务器接收的正在等待认知的提交的 LSN
onstat -g dsc 命令:打印分布式高速缓存信息
使用 onstat -g dsc 命令显示有关分布式高速缓存的信息。
语法
示例输出
图: onstat -g dsc 命令输出
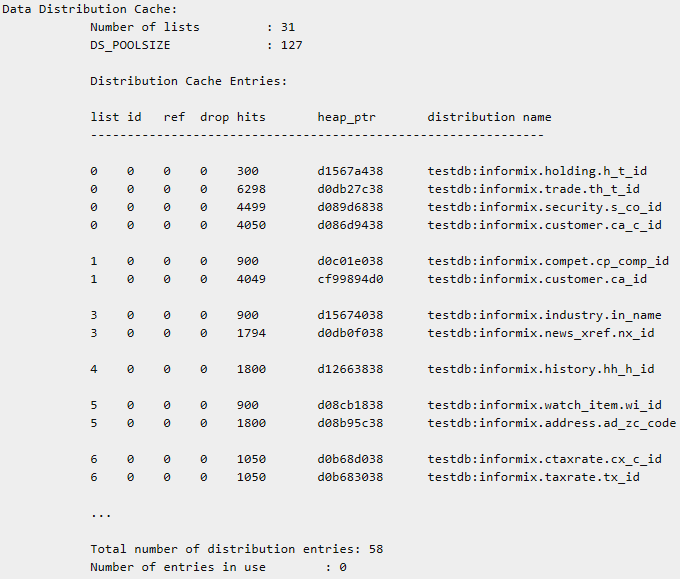
输出描述
Number of lists: 在分布式高速缓存中列表的数量
DS_POOLSIZE: 每次可以高速缓存的条目的数量
list: 分布式高速缓存哈希链 ID
id: 哈希条目编号
ref: 引用高速缓存条目的语句的数量
drop: 此条目添加到高速缓存以来是否被删除
hits: 高速缓存条目的访问次数
heap_ptr: 用于存储此条目的堆地址
distribution name: 在高速缓存中分布式的名称
Total number of distribution entries: 分布式高速缓存中的条目的数量
Number of entries in use: 正在被使用的条目的数量
onstat -g dsk 命令:打印当前正在运行的压缩操作的进度
可以使用 onstat -g dsk 命令打印当前正在运行的压缩操作的进度,例如:压缩、重新打包和收缩。
语法:
示例输出
图: onstat -g dsk 压缩操作命令的输出

图: onstat -g dsk 重新打包操作命令的输出

输出描述
partnum: 表或分片的分区号
OP : 压缩操作,例如:压缩、重新打包或收缩
Pass: 对于重新包装操作,1 标示第一遍读取行,2 标示第二遍读取
Processed Rows : 目前为止该指定操作已处理的行数
Blobs: 操作的简单大对象数
Remaining Rows: 要处理的剩余行数。对于重新打包操作,是当前已过的剩余行数。
Duration Time(s): 自从该操作开始以来的持续的时间
Remaining Time(s): 该操作大概剩余的时间量。对于重新包装操作,是当前已过的剩余时间。
onstat -g env 命令:打印环境变量值
可以使用 onstat -g env 命令显示数据库服务器当前使用的环境变量的值的信息。
语法:
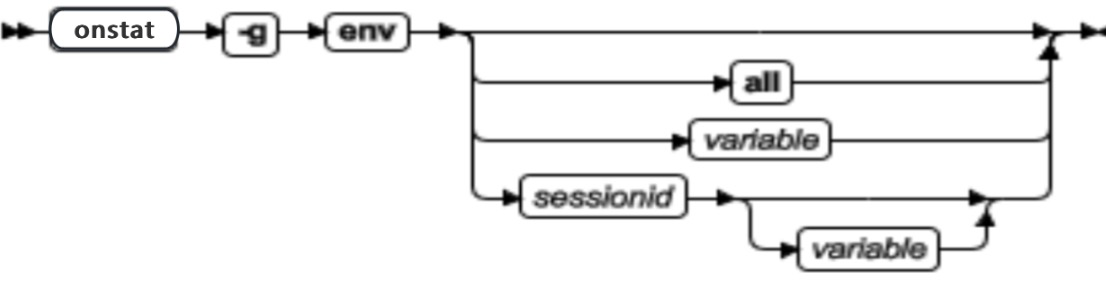
可以指定以下调用之一。
| 命令 | 描述 |
|---|---|
| onstat -g env | 显示数据库服务器启动时变量的设置 不显示还未显式设置的变量 |
| onstat -g env all | 显示由所有会话使用的设置 此显示与 onstat -g env 和 onstat -g envsessionid 的输出相同(对所有当前会话重复) |
| onstat -g env variable | 显示指定变量的缺省值 此 variable 参数使得不必将输出以管道方式运送到 grep (或某些其他命令)中以便在许多可能设置的变量中找到一个变量 |
| onstat -g env sessionid | 显示特定会话使用的设置。该显示包含以下值: ● 会话环境中的设置 ● 由数据库服务器指定,如 onstat -g env 所显示 |
| onstat -g env sessionid variable | 显示指定会话使用的指定变量的值 sessionid 和 variable 参数使得不必将输出以管道方式运送到 grep (或一些其他命令)中以便在许多可能设置的变量中找到一个变量 |
onstat -g env 命令显示变量的当前设置和每次在环境中设置此变量时的值的完整列表。例如:如果 PDQPRIORITY 在 .gbasedbt.rc 文件中设置为 10 ,而在 shell 环境中设置为 55 ,那么 onstat -g env 会显示两个值。
但是,如果使用 onmode -q pdqpriority sessionid 命令更改了 PDQPRIORITY ,那么 onstat -g env 命令不会显示该会话的新值。onstat -g env 命令仅显示环境中设置的变量的值,它不显示会话正在运行时修改的值。
在以下任何情况下,您可能想要显示环境变量的值:
- 数据库服务器示例已运行了几个月,但您无法记起环境变量的设置(例如服务器语言环境设置 SERVER_LOCALE)。
- 您想要显示变量值的完整列表,以标识变量何时在多处进行了设置。
- 在这期间磁盘上的环境文件可能已更改或已丢失。
- 支持工程师想要知道特定环境变量的设置。
示例输出
下图显示了 onstat -g env 命令的输出。
图: onstat -g env 命令输出
Variable Value [values-list]
DBDELIMITER |
DBPATH .
DBPRINT lp -s
DBTEMP /tmp
GBASEDBTSERVER instance
GBASEDBTSQLHOSTS /opt/gbs_server/data/conf/sqlhosts
GBASEDBTTERM terminfo
GBASEDBTDIR /opt/gbs_server/home
[/opt/gbs_server/home]
[/usr/gbasedbt]
IGNORE_UNDERFLOW 1
LANG en_US.UTF-8
LC_COLLATE en_US.UTF-8
LC_CTYPE en_US.UTF-8
LC_MONETARY en_US.UTF-8
LC_NUMERIC en_US.UTF-8
LC_TIME en_US.UTF-8
LKNOTIFY yes
LOCKDOWN no
NODEFDAC no
ONCONFIG onconfig
PATH /opt/gbs_server/home/bin:/bin:/usr/lib64/qt-3.3/bin:/usr/lo cal/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/hom e/gbasedbt/bin
SERVER_LOCALE en_US.819
SHELL /bin/bash
TERM xterm
[xterm]
[dumb]
TERMCAP /etc/termcap
onstat -g ffr 命令:打印空闲分片
可以使用 onstat -g ffr 命令显示有关特定会话或共享内存池的可用分片的信息。
该命令需要附加的参数来指定要显示内存池信息的池的名称或会话 ID 。每个会话都以其名称为会话 ID 分配到内存池中。可以使用 onstat -g mem 命令标示池的名称,使用 onstat -g ses 命令标示会话 ID 。
语法:

示例输出
图: onstat -g ffr aio 命令输出

输出描述
addr (hexadecimal): 池分片的内存地址
size (decimal): 池分片大小,以字节表示
idx (decimal): 供内部使用。可用列表指针数组中的索引
onstat -g glo 命令:打印全局多线程信息
使用 onstat -g glo 命令显示有关多线程的全局信息、每个正在运行的虚拟处理器的信息以及每个虚拟处理器类的计算统计信息。该信息包括有关虚拟处理器 CPU 的使用信息、总会话数和其他多线程全局计数。
语法:
![]()
示例输出
图: onstat -g glo 命令输出
MT global info:
sessions threads vps lngspins time
0 23 14 0 142
sched calls thread switches yield 0 yield n yield forever
total: 85240 70451 16956 868 37319
per sec: 0 0 0 0 0
Virtual processor summary:
class vps usercpu syscpu total
cpu 1 92.12 0.59 92.71
aio 1 0.05 0.08 0.13
lio 1 0.00 0.00 0.00
pio 1 0.00 0.00 0.00
adm 1 0.00 0.01 0.01
soc 4 0.01 0.01 0.02
msc 1 0.00 0.00 0.00
jvp 1 0.00 0.00 0.00
fifo 1 0.00 0.00 0.00
nyevp 1 0.00 0.00 0.00
yevp 1 0.00 0.00 0.00
total 14 92.18 0.69 92.87
Individual virtual processors:
vp pid class usercpu syscpu total Thread Eff
1 26328 cpu 92.12 0.59 92.71 122.65 75%
2 26330 adm 0.00 0.01 0.01 0.00 0%
3 26331 lio 0.00 0.00 0.00 0.00 0%
4 26332 pio 0.00 0.00 0.00 0.00 0%
5 26333 aio 0.05 0.08 0.13 0.28 45%
6 26334 msc 0.00 0.00 0.00 0.19 0%
7 26335 fifo 0.00 0.00 0.00 0.00 0%
8 26336 nyevp 0.00 0.00 0.00 0.00 0%
9 26337 yevp 0.00 0.00 0.00 0.00 0%
10 26338 jvp 0.00 0.00 0.00 0.00 0%
11 26339 soc 0.00 0.00 0.00 NA NA
12 26340 soc 0.00 0.00 0.00 NA NA
13 26341 soc 0.01 0.01 0.02 NA NA
14 26342 soc 0.00 0.00 0.00 NA NA
tot 92.18 0.69 92.87
输出描述
下表解释了示例输出中全局信息章节中的每个列。
表. 虚拟处理器摘要列的描述
| 列名 | 描述 |
|---|---|
| sessions | 会话数 |
| threads | 线程总数 |
| vps | 虚拟处理器的总数 |
| lngspins | 线程不得不 spin 超过 10,000 次以获得资源上的 latch 的次数 |
| time | 生成统计信息的时间。服务器启动时开始统计或通过运行 onstat -z 命令重置统计信息。 |
| sched calls | 排定呼叫的总数 |
| thread switches | 从一个线程到另一个线程切换的总次数 |
| yield | 线程收益率的统计信息(在该线程无法继续它的任务直到发生别的条件时发生) |
下表解释了示例输出中 Virtual Processor Summary 章节中的每个列。
表. Virtual Processor Summary 列的描述
| 列名 | 描述 |
|---|---|
| class | 虚拟处理器的类型 |
| vps | 这个虚拟处理器类的实例的数量 |
| usercpu | 这个虚拟处理器类在 CPU 上运行所花费的总用户时间(秒) |
| syscpu | 这个虚拟处理器类在 CPU 上运行所花费的总系统时间(秒) |
| total | 虚拟处理器类的总 CPU 时间,它是用户时间加上系统时间的总和 |
下表解释了示例输出中 Individual Virtual Processor 章节中的每个列。
表. Individual Virtual Processor 的列描述
| 列名 | 描述 |
|---|---|
| vp | 虚拟处理器编号。 |
| pid | oninit 进程的进程 ID |
| class | 虚拟处理器类 |
| usercpu | 虚拟处理器类在 CPU 上运行的总用户时间(秒) |
| syscpu | 虚拟处理器类在 CPU 上运行的总系统时间(秒) |
| total | 虚拟处理器类的总 CPU 时间,它是用户时间加上系统时间的总和 |
| Thread | 线程在虚拟处理器上运行的总时间 |
| Eff | 效率。总 CPU 时间占线程在虚拟处理器上运行总时间的比率 |
onstat -g his 命令:打印 SQL 跟踪信息
可以使用 onstat -g his 命令显示 sysmaster 数据库中 syssqltrace 表(包括 syssqltrace 、syssqltrace_info 、syssqltrace_hvar 和 syssqltrace_itr)收集的 SQL 跟踪信息。
SQLTRACE 配置参数的 level 设置会影响由 syssqltrace 表存储和显示的 SQL 跟踪信息,并影响 onstat -g his 显示的信息。syssqltrace 表每行描述一条以前执行的 SQL 语句。缺省情况下,只有 DBSA 可以查看来自 onstat -g his 命令的 syssqltrace 信息。然而,当将 UNSECURE_ONSTAT 配置参数设置为 1 时,所有的用户都可以查看该信息。
语法:
示例输出
输出的内容依赖于跟踪的设置。
输出中的 Statement history 部分提供有关正在跟踪的当前设置的信息。

下表是该输出的描述:
| 元素 | 描述 |
|---|---|
| Trace Level | 已跟踪的信息量。可用值为 LOW 、MED 、HIGH 和 OFF |
| Trace Mode | 执行跟踪的类型。Global 参考系统上的所用用户。User 只参考由 SQL 管理 API 函数启用的用户。 |
| Number of traces | 跟踪的 SQL 语句的数量。该值在 onconfig 文件中进行设置,除非 SQL 管理 API 函数动态更改了 ntraces 参数。它的取值范围是 500 到 2147483647 。如果有 100,000 个跟踪缓冲区,每秒组织运行 1000 条 SQL 语句并要跟踪所有的语句,那么这些缓冲区在重写之前将持续 100 秒。 |
| Current Stmt ID | 当前 SQL 语句的 ID 。每条被跟踪的语句都获得一个唯一 ID 。 |
| Trace Buffer size | 每个跟踪缓冲区将获取的数据量(以字节表示)。如果将此大小设置为 2 KB ,但是有一条 12 KB 的 SQL 语句,那么该语句将会截断至少 10 KB 。更多的数据可能会被截断,它依赖于要跟踪的其它的数据。 |
| Duration of buffer | 以秒表示跟踪的数据在当前跟踪缓冲区跨度的时间量。它不是 sqltrace 功能已运行的时间。在上述示例中,Duration of buffer 是 293 秒,它表示跟踪的第一条和最后一条 SQL 语句之间的时间。 |
| Trace Flags | 当前设置的 SQL 跟踪标志 |
| Control Block | 该 SQL 跟踪控制 block 的内存地址 |
每次语句运行后,以下的信息重复显示一次。在该示例中,调用了两个变量。

下表是该输出的描述:
| 元素 | 描述 |
|---|---|
| Database | 数据库名或该数据库的 systables 条目部分的编号 |
| Statement text | 该 SQL 语句的文本。如果该语句时存储过程,那么该语句文本将显示该过程的堆跟踪。如果声明和数字统计大于跟踪缓冲区,那么该语句文本可能会被截断。 |

下表是该输出的描述:
| 元素 | 描述 |
|---|---|
| ID | SQL 迭代器 ID |
| Left | 迭代器左侧输入的 ID |
| Right | 迭代器右侧输入的 ID |
| Est Cost | 本次迭代的估计成本 |
| Est Rows | 本次迭代的估计行数 |
| Num Rows | 本次迭代的实际行数 |
| Partnum | 表编号或索引分区编号 |
| Type | 操作类型 |
如果 SQL 语句包含一个或多个变量,并且您正在跟踪主机变量,那么输出中会显示 Host Variables 小节。

下表是该输出的描述:
| 元素 | 描述 |
|---|---|
| Column 1 | 该语句中变量的位置 |
| Column 2 | 该变量的数据类型 |
| Column 3 | 该变量值 |

下表是该输出的描述:
| 元素 | 描述 |
|---|---|
| Sess_id | 会话 ID |
| User_id | 此操作系统用户 ID |
| Stmt Type | SQL 语句类型 |
| Finish Time | 当天该 SQL 语句结束的时间 |
| Run Time | 虚拟处理器或线程处理该语句所花费的总时间。例如:如果 Finish Time 是 1:15:00 ,Run Time 是 9 分钟并且启动时间不一定是 1:06:00 ,那么可能在并行语句部分调用了多个虚拟处理器或线程。 |
| TX Stamp | 该事务中记录 BEGIN WORK 语句的时间 |
| PDQ | SQL 语句 PDQ 级别 |
输出中 Statement Statistics 部分提供有关该语句的特定信息。
| 元素 | 描述 |
|---|---|
| Page Read | 该 SQL 语句已从磁盘读取的页数 |
| Buffer Read | 该 SQL 语句从缓冲池读取而不是从磁盘读取页的次数 |
| Read % Cache | 应从缓冲池读取页的次数的百分比 |
| Buffer IDX Read | 尚未明确 |
| Page Write | 写入磁盘的页数 |
| Buffer Write | 修改并发送回缓冲池的页数 |
| Write % Cache | 页面写入缓冲池而不是写入磁盘的次数的百分比 |
| Lock Requests | 该语句所需的锁的总数 |
| Lock Waits | 该 SQL 语句等待锁的次数 |
| LK Wait Time (S) | 该语句等待锁的时间(以秒为单位) |
| Log Space | 逻辑日志中该 SQL 语句已使用的存储空间量 |
| Num Sorts | 用于执行语句的排序总数 |
| Disk Sorts | 对于该 SQL 语句,对磁盘执行的排序的次数 |
| Memory Sorts | 对于该 SQL 语句,对内存执行的排序的次数 |
| Total Executions | 该语句已执行的总次数,或者该游标重用的次数 |
| Total Time (S) | 执行该语句的总时间(以秒表示) |
| Avg Time (S) | 执行该语句的平均时间(以秒表示) |
| Max Time (S) | 运行 SQL 语句的总时间(以秒为单位),不包括应用程序使用的任何时间。如果您准备一个查询然后查询 5 次,该查询每次将一个跟踪添加到跟踪缓冲区中。Max Time 是任意执行所花的最长时间 |
| Avg IO Wait | 语句等待 I/O 的时间量,不包括任何异步 I/O |
| I/O Wait Time (S) | 语句等待 I/O 的时间量,不包括任何异步 I/O(以秒为单位) |
| Avg Rows Per Sec | 该语句每秒产生的平均行数 |
| Estimated Cost | 与 SQL 语句关联的查询优化程序的代价 |
| Estimated Rows | 返回的估计行数,由语句的优化程序估计 |
| Actual Rows | 该语句返回的行数 |
| SQL Error | SQL 错误编号 |
| ISAM Error | RSAM 或 ISAM 错误编号 |
| Isolation Level | 该语句运行时使用的隔离级别 |
| SQL Memory | 该 SQL 语句需要的字节数 |
有关 syssqltrace 系统监视接口表的完整结构,请参阅 syssqltrace。
有关 SQLTRACE 配置参数的详细设置信息,请参阅 SQLTRACE 配置参数。
onstat -g ioa 命令:打印合并的 onstat -g 信息
可以使用 onstat -g ioa 命令显示来自 onstat -g iob 、onstat -g iof 、onstat -g ioq 和 onstat -g iov 命令的组合信息。
语法

示例输出
AIO global info:
9 aio classes
9 open files
64 max global files
AIO I/O queues:
q name/id len maxlen totalops dskread dskwrite dskcopy
fifo 0 0 0 0 0 0 0
drda_dbg 0 0 0 0 0 0 0
sqli_dbg 0 0 0 0 0 0 0
adt 0 0 0 0 0 0 0
msc 0 0 1 231 0 0 0
aio 0 0 5 13069 10895 0 0
pio 0 0 1 1580 0 1580 0
lio 0 0 1 37900 0 37900 0
gfd 3 0 87 42115 15806 26309 0
gfd 4 0 4 5 1 4 0
gfd 5 0 12 35 22 13 0
gfd 6 0 11 33 21 12 0
gfd 7 0 1 4 3 1 0
gfd 8 0 1 4 3 1 0
AIO I/O vps:
class/vp/id s io/s totalops dskread dskwrite dskcopy wakeups io/wup errors tempops
fifo 7 0 i 0.0 0 0 0 0 1 0.0 0 0
msc 6 0 i 0.0 231 0 0 0 221 1.0 0 231
aio 5 0 i 0.0 39285 26358 10793 0 37531 1.0 0 5
aio 9 1 i 0.0 5770 3795 1944 0 5926 1.0 0 0
aio 10 2 i 0.0 2308 717 1585 0 1953 1.2 0 0
aio 11 3 i 0.0 1463 166 1295 0 1166 1.3 0 0
aio 12 4 i 0.0 1219 46 1172 0 943 1.3 0 0
aio 13 5 i 0.0 1041 34 1007 0 805 1.3 0 0
aio 15 6 i 0.0 425 2 423 0 438 1.0 0 0
aio 16 7 i 0.0 342 5 337 0 395 0.9 0 0
pio 4 0 i 0.0 1580 0 1580 0 1581 1.0 0 1580
lio 3 0 i 0.0 37900 0 37900 0 29940 1.3 0 37900
AIO global files:
gfd pathname bytes read page reads bytes write page writes io/s
3 ./rootdbs 85456896 41727 207394816 101267 572.9
op type count avg. time
seeks 0 N/A
reads 13975 0.0015
writes 51815 0.0018
kaio_reads 0 N/A
kaio_writes 0 N/A
4 tempsbs.chunk 2048 1 8192 4 113.6
op type count avg. time
seeks 0 N/A
reads 1 0.0131
writes 3 0.0074
kaio_reads 0 N/A
kaio_writes 0 N/A
5 sbs1.chunk 45056 22 26624 13 173.4
op type count avg. time
seeks 0 N/A
reads 22 0.0063
writes 6 0.0038
kaio_reads 0 N/A
kaio_writes 0 N/A
6 sbs2.chunk 43008 21 24576 12 76.1
op type count avg. time
seeks 0 N/A
reads 21 0.0148
writes 6 0.0072
kaio_reads 0 N/A
kaio_writes 0 N/A
7 qhdr.chunk 6144 3 2048 1 550.5
op type count avg. time
seeks 0 N/A
reads 3 0.0019
writes 1 0.0016
kaio_reads 0 N/A
kaio_writes 0 N/A
8 ./dbs1 6144 3 2048 1 403.0
op type count avg. time
seeks 0 N/A
reads 3 0.0027
writes 1 0.0018
kaio_reads 0 N/A
kaio_writes 0 N/A
AIO big buffer usage summary:
class reads writes
pages ops pgs/op holes hl-ops hls/op pages ops pgs/op
fifo 0 0 0.00 0 0 0.00 0 0 0.00
drda_dbg 0 0 0.00 0 0 0.00 0 0 0.00
sqli_dbg 0 0 0.00 0 0 0.00 0 0 0.00
kio 0 0 0.00 0 0 0.00 0 0 0.00
adt 0 0 0.00 0 0 0.00 0 0 0.00
msc 0 0 0.00 0 0 0.00 0 0 0.00
aio 228709 20228 11.31 1005 203 4.95 213272 18556 11.49
pio 0 0 0.00 0 0 0.00 19672 1580 12.45
lio 0 0 0.00 0 0 0.00 55287 37900 1.46
输出描述
有关每个输出列的描述,请分别参阅 onstat -g iob 命令:打印大缓冲区的使用摘要 、onstat -g ioq 命令:打印 I/O 队列信息 和 onstat -g iov 命令:打印 AIO VP 统计信息 命令。
onstat -g iob 命令:打印大缓冲区的使用摘要
使用 onstat -g iob 命令显示大缓冲区的使用摘要。
语法:

示例输出
图: onstat -g iob 命令输出

onstat -g iof 命令:打印 asynchronous I/O 统计信息
使用 onstat -g iof 命令显示按 chunk 或文件的 asynchronous I/O 统计信息。
这个命令与 onstat -D 命令相似,除了 onstat -g iof 也显示非 chunk 文件的信息。它包含临时文件和排序工作文件的信息。
语法:

示例输出
图: onstat -g iof 命令输出

输出描述
gfd: 该 chunk 或文件的全局文件描述符编号
pathname: Chunk 或文件的路径名
bytes read: 已经对 chunk 或文件执行的读取的字节数
page reads: 已经对 chunk 或文件执行的页读取数
bytes write: 已经对 chunk 或文件执行写入的字节数
page writes: 已经对 chunk 或文件执行的页写入数
io/s: 每妙执行的 I/O 操作数,该值代表 chunk 或文件的 I/O 性能
op type: 操作类型
count: 此操作发生的次数
avg time: 操作结束所花的平均时间
onstat -g iog 命令:打印 AIO 全局信息
使用 onstat -g iog 命令显示有关 AIO 的全局信息。
语法:

示例输出
图: onstat -g iog 命令输出

onstat -g ioq 命令:打印 I/O 队列信息
可以使用 onstat -g ioq 命令显示关于由 I/O 队列执行的操作的数量和类型的统计信息。
语法:

如果给定一个 queue_name ,那么只显示具有该名称的队列。如果未给定 queue_name ,那么显示所有队列的信息。
示例输出
图: onstat -g ioq 命令输出
输出描述
q name/id: I/O 队列的名称和编号。名称说明队列的类型。编号用来区分具有相同名称的队列。
以下是可能的队列名称以及每个类型的队列处理的对象的列表:
sqli_dbg
处理 GBase 技术支持的 SQL 接口调试功能的 I/O
fifo
处理 FIFO VPs 的 I/O
adt
处理审计 I/O
msc
处理杂项 I/O
aio
处理 GBase 8s 异步 I/O
kio
处理内核 AIO
pio
处理物理日志记录 I/O
lio
处理逻辑日志记录 I/O
gfd
全局文件描述符 - 为每个主 chunk 和镜像 chunk 分配单独的全局文件描述符。每个 gfd 队列的使用取决于 kaio 是否开启以及关联 chunk 是格式化的还是原始的
len: 在队列中暂挂 I/O 请求的数量
maxlen: 队列中同时存在的 I/O 请求的最大数量
totalops: 队列中已经完成的 I/O 操作的总数
dskread: 队列已完成的读操作的总数
dskwrite: 队列已完成的写操作的总数
dskcopy: 队列已完成的复制操作的总数
onstat -g ipl 命令:打印索引页日志状态信息
可以使用 onstat -g ipl 命令显示索引页日志的状态信息。
语法:
示例输出
图: onstat -g ipl 命令输出
![]()
输出描述
Index page logging status: 索引页日志记录状态:已启用或禁用
Index page logging was enabled at: 启用索引页日志记录的日期和时间
onstat -g iov 命令:打印 AIO VP 统计信息
可以使用 onstat -g iov 命令显示每个虚拟处理器的异步 I/O 统计信息。
语法:
示例输出
图: onstat -g iov 命令输出

输出描述
class: 虚拟处理器类
vp: 虚拟处理器在类中的 ID 编号
s: AIO 虚拟处理器的当前状态
f
派生
i
空闲
s
搜素
b
正忙
o
打开
c
关闭
io/s: 自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器的平均 I/O 速度(以每秒操作数衡量)
totalops: 自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器执行的 I/O 操作总数(以每秒操作数衡量)
dskread: 自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器执行的读操作总数(以每秒操作数衡量)
dskwrite: 自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器执行的写操作总数(以每秒操作数衡量)
dskcopy: 自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器执行的复制操作总数(以每秒操作数衡量)
wakeups: 对于 AIO VPs ,是自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)虚拟处理器处于空闲状态的次数
io/wup: 对于 AIO VPs ,是自数据库服务器启动以来或自 onstat -z 上次运行以来(看着两者哪个发生在后)该虚拟处理器每次唤醒执行的 I/O 操作平均数
errors: KAIO 超出资源的错误总数
tempops (decimal): 仅供内部使用。是用来确定何时添加新 AIO VP 的 I/O 操作计数。它只在 AUTO_AIOVPS 配置参数启用时应用。
onstat -g lap 命令:打印轻量级追加(GBase_8s light append)状态信息
可以使用 onstat -g lap 命令显示有关系统内的轻量级追加的状态信息。
语法:
示例输出
图: onstat -g lap 命令输出

输出描述
Session id (decimal): 执行轻量级追加操作的会话 ID
address (hexadecimal): 轻量级追加缓冲区的地址
cur_ppage (hexadecimal): 当前的物理页面地址
la_npused (decimal): 分配的页面数
la_ndata (decimal): 附加的数据的页面数
la_nrows (decimal): 附加的行数
bufcnt (decimal): 轻量级追加缓冲区数
onstat -g laq 命令:打印辅助服务器队列
使用 onstat -g laq 命令打印有关从主服务器接收的应用日志信息的辅助服务器队列的信息。
在高可用性集群中,主服务器通过网络向一台或多台辅助服务器发送日志记录。每个辅助服务器持续重播来自主服务器的事务日志,以确保数据复制到辅助服务器中。主服务器中的每个 tblspace 被分配到辅助服务器的队列中去接收日志记录。称作 apply thread 的线程,将应用该日志存储到辅助服务器的队列中。这些日志以它们接收时的顺序来应用。
可以使用 onstat -g laq 命令监视该队列在辅助服务器上的性能。如果您怀疑由于辅助服务器上的日志没有及时重播而造成主服务器性能降低,那么可以使用该命令。Avg Depth(平均深度)列标示了上次队列插入操作发生时队列中日志的平均数量
onstat -g laq 命令只在辅助服务器上可用。在主服务器上运行该命令只会返回 onstat 头的输出。
语法:

示例输出
图: onstat -g laq 命令输出
输出描述
Thread: 分配接收日志记录的应用线程的名称
Queue Size: 等待该应用线程的日志记录队列数
Total Queued: 给出的应用线程队列中的日志记录的总数
Avg Depth: 上次队列插入操作发生时队列中日志的平均数量
Secondary Apply Queue: 该辅助应用队列接收来自主服务器的日志缓冲区。显示的值代表分配给接收日志缓冲区记录的缓冲区总数、队列的大小及可用缓冲区数
Log Recovery Queue: 该日志恢复队列接收来自辅助应用队列的输出。日志缓冲区被转换成兼容 ontape 命令的格式。显示的值代表恢复队列中流缓冲区的总数、流缓冲区的大小及可用缓冲区数
Log Page Queue: 该日志页队列接收来自日志恢复队列的输出。ontape 格式被移除并且数据分割成独立的日志页。显示的值代表恢复队列中的日志页的总数、队列的大小以及可用缓冲区数
Log Record Queue: 该日志队列接收来自日志页队列的输出。此日志页被分割成独立的日志记录。显示的值代表恢复队列中的日志记录数、队列的大小以及可用缓冲区数
onstat -g lmm 命令:打印低内存管理信息
使用 onstat -g lmm 命令显示有关自动低内存管理设置及其近期活动。可以使用 LOW_MEMORY_MGR 配置参数来启用自动低内存管理。
语法:
示例输出
图: onstat -g lmm 命令输出
Low Memory Manager
Control Block 0x4cfca220
Memory Limit 300000 KB
Used 149952 KB
Start Threshold 10240 KB
Stop Threshold 10 MB
Idle Time 300 Sec
Internal Task Yes
Task Name 'Low Memory Manager'
Low Mem TID 0x4cfd7178
# Extra Segments 0
Low Memory Manager Tasks
Task Count Last Run
Kill User Sessions 267 04/04/2011.16:57
Kill All Sessions 1 04/04/2011.16:58
Reconfig(reduce) 1 04/04/2011.16:59
Reconfig(restore) 1 04/04/2011.17:59
Last 20 Sessions Killed
Ses ID Username Hostname PID Time
194 sfisher host01 13433 04/04/2011.16:57
201 sfisher host01 13394 04/04/2011.16:57
198 sfisher host01 13419 04/04/2011.16:57
190 sfisher host01 13402 04/04/2011.16:57
199 sfisher host01 13431 04/04/2011.16:57
Total Killed 177
输出描述
Control Block: 自动低内存管理的内部控制结构地址
Memory Limit : 服务器可以附加的内存量
Used: 服务器当前已使用的内存量
Start Threshold: 自动低内存管理的启动阈值
Stop Threshold: 自动低内存管理的停止阈值
Idle Time: 自动低内存管理认为一个会话空闲后的时间量
Internal Task
Yes = 使用 GBase 8s 程序
No = 使用用户自定义程序
Task Name: 用户自定义程序名称
Low Mem TID: 自动低内存管理线程的地址
Task
Kill = 自动运行进程并终止会话
Reconfig(减少) = 自动运行进程并释放 block 未使用的内存
Reconfig(恢复) = 自动运行进程并恢复服务和配置
Count: 执行该任务的次数
Last Run: 最近一次执行任务的日期和时间
Ses ID: 终止的会话的 ID(使用 onmode –z 命令)
Username: 会话所有者的用户名
Hostname: 发起会话的主机的名称
PID: 进程 ID
Time: 会话终止的日期和时间
onstat -g lmx 命令:打印所有锁定的互斥
可以使用 onstat -g lmx 命令显示所有锁定的互斥的信息。
语法:

示例输出
图: onstat -g lmx 命令输出

输出描述
mid: 内部互斥标识符
addr: 锁定的互斥的地址
name: 互斥的名称
holder: 持有这个互斥的线程的 ID ,0 = 在共享模式下持有的读/写互斥
lkcnt: 对于读/写互斥,是线程在共享模式下锁定的此互斥的数量。对于重新锁定互斥,它是此线程持有的互斥被锁定或重新锁定的次数
waiter: 等待这个互斥的线程 ID 的列表
waittime: 此线程已经等待的时间(以秒为单位)
onstat -g lsc 命令:打印活动的轻度扫描(GBase_8s light scan)状态(不推荐使用)
onstat -g lsc 命令已被 onstat -g scn 命令取代。
语法:

onstat -g mem 命令:打印池内存统计信息
可以使用 onstat -g mem 命令显示某个池的内存统计信息。如果运行来自 PER_STMT_EXEC 和 PER_STMT_PREPf 内存持续时间池的分配内存的 SQL 查询,那么 onstat -g mem 命令显示有关 PRP.sessionid.threadid 池和 EXE.sessionid.threadid 池的信息。会话池以会话编号命名。如果未提供参数,那么将显示所有池的信息。
语法:

示例输出
图: onstat -g mem 命令输出
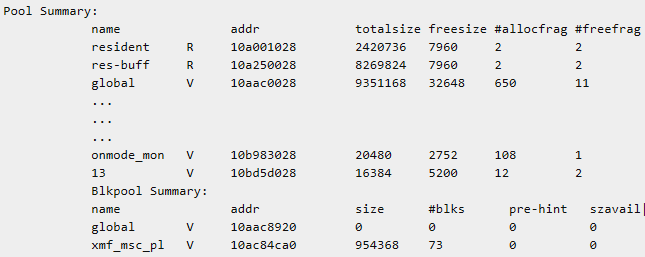
输出描述
Pool Summary
name: 池的名称,在创建池的位置的共享内存段类型
addr: 池内存地址
totalsize: 池大小,以字节表示
freesize: 在池中的可用内存量
#allocfrag: 在池中的已分配的分片
#freefrag: 在池中的可用分片
Blkpool Summary
name: 池的名称,在创建池的位置的共享内存段类型
addr: 池内存地址
size: 池大小,以字节表示
#blks: 池中的 block 数
onstat -g mgm 命令:打印 MGM 资源信息
可以使用 onstat -g mgm 命令显示有关内存分配管理器(MGM)资源信息。
可以使用 onstat -g mgm 命令监视 MGM 如何协调内存使用和扫描线程。此命令读取共享内存结构并提供在命令执行时的精确统计信息。
语法:
onstat -g mgm 输出显示称作 quantum 的内存单位。memory quantum 代表内存单位,如下所示:
memory quantum = DS_TOTAL_MEMORY / DS_MAX_QUERIES
以下算式显示 onstat -g mgm 输出的值的 memory quantum:
memory quantum = 4000 kilobytes / 31
= 129 kilobytes
数据库服务器根据分配内存的需求调整 quantum 的值。因此,onstat -g mgm 命令显示的 quantum 值并非一直精确。
scan thread quantum 总是等于 1。
示例输出
图: onstat -g mgm 命令输出
Memory Grant Manager (MGM)
--------------------------
MAX_PDQPRIORITY: 100
DS_MAX_QUERIES: 31
DS_MAX_SCANS: 1048576
DS_NONPDQ_QUERY_MEM: 128 KB
DS_TOTAL_MEMORY: 4000 KB
Queries: Active Ready Maximum
0 0 31
Memory: Total Free Quantum
(KB) 4000 4000 128
Scans: Total Free Quantum
1048576 1048576 1
Load Control: (Memory) (Scans) (Priority) (Max Queries) (Reinit)
Gate 1 Gate 2 Gate 3 Gate 4 Gate 5
(Queue Length) 0 0 0 0 0
Active Queries: None
Ready Queries: None
Free Resource Average # Minimum #
-------------- --------------- ---------
Memory 0.0 +- 0.0 500
Scans 0.0 +- 0.0 1048576
Queries Average # Maximum # Total #
-------------- --------------- --------- -------
Active 0.0 +- 0.0 0 0
Ready 0.0 +- 0.0 0 0
Resource/Lock Cycle Prevention count: 0
输出描述
输出的第一部分显示 PDQ 配置参数的值。
输出的第二部分描述 MGM 内部控制信息。它包括四组的信息。第一组是 Queries:
Active: 当前正在执行的 PDQ 查询的数量
Ready: 已准备好运行但数据库服务器由于装入控制原因而延迟查询执行的用户查询的数量
Maximum: 数据库服务器允许处于活动状态的查询的最大数量。反映 DS_MAX_QUERIES 配置参数的当前值
下一组是 Memory:
Total: 可由 PDQ 查询使用的可用内存的 KB (DS_TOTAL_MEMORY 指定这个值)
Free: 用于 PDQ 查询的当前未使用的内存的 KB
Quantum: 在 memory quantum 中的内存的 KB
下一组是 Scans:
Total: 由 DS_MAX_SCANS 配置参数指定的扫描线程的总数
Free: 当前可用于决策支持查询的扫描线程的数量
Quantum: 在扫描线程量子中的扫描线程的数量
该部分输出的最后一组描述 MGM Load Control:
Memory: 正在等待内存的查询的数量
Scans: 正在等待扫描的查询的数量
Priority: 正在等待具有更高 PDQ 优先级的查询运行的查询的数量
Max Queries: 正在等待查询 slot 的查询数量
Reinit: 在 onmode -M 或 -Q 命令之后,正等待正在运行的查询完成的查询的数量
输出的下一部分 Active Queries 描述 MGM 活动的和就绪的队列。这部分输出显示在每个入口等待的查询的数量:
Session: 启动查询的会话的会话 ID
Query: 与查询相关联的内部控制 block 的地址
Priority: 分配给查询的 PDQ 优先级
Thread: 向 MGM 注册查询的线程
Memory: 当前分配给查询或为查询保留的内存量(单位是 MGM 页,即 8 KB)
Scans: 有查询当前使用的扫描线程的数量,或者分配给查询的扫描线程的数量
Gate: 查询正在该处等待的入口编号
输出的下一部分 Free Resource 提供 MGM 可用资源的统计信息。这个部分和最后部分的数值反映自系统初始化或自上次 onmode -Q 、-M 或 -S 命令以来的统计信息。这部分输出包含以下信息:
Average: 平均内存量和扫描数量
Minimum: 最小可用内存量和扫描数量
输出的下一部分 Queries 提供关于 MGM 查询的统计信息:
Average: 活动且就绪队列的平均长度
Maximum: 活动且就绪队列的最大长度
Total: 活动且就绪队列的总长度
Resource/Lock Cycle Prevention count: 系统为了避免潜在的死锁而直接激活一个查询的次数。(数据库服务器可以察觉如果没有立即运行查询的话,其队列内一些查询什么时候可能发生死锁情况。)
onstat -g nbm 命令:打印 block 位图
可以使用 onstat -g nbm 命令显示非常驻段的 block 位图。
位图的每个位代表一个 4 KB 的 block。如果 block 正在使用,那么该位设置为 1 。如果 block 是空闲可用的,那么该位设置为 0 。位图以一系列的十六进制数字显示。位从 0 开始编号,从而 block 也从 0 开始编号,所以第一个 block 是 block 0,第二个是 block 1 ,以此类推。
语法:
示例输出
这个示例显示在 0x10CC00000 的虚拟内存段的位图。位图自身是在 0x10CC00290 。这个段的全部 1792 个 block 都可用。除了 block 0 和 block 1023 。
图: onstat -g nbm 命令输出

输出描述
address: 位图的起始地址
size: 位图中的位数。这也是在内存段中的 4 KB block 的数量
used: 在位图中设置为 1 的位的总数。这也是在内存段中的使用中的 4 KB block 的数量
largest free: 如果这个值不是 -1 ,那么它是连续可用位的最大数量。它也是在内存段的最大邻接 block 集合中 4 KB block 的数量 。值 -1 表示还未计算最大可用空间。数据库服务器只在尝试分配从 lastalloc block 开始的 block 集合却没有足够可用空间时计算最大可用空间。一旦在段中分配了另一个 block ,这个值就再次设置为 -1 。
onstat -g nsc 命令:打印当前的共享内存连接信息
可以使用 onstat -g nsc 命令显示有关当前所有连接或特定连接 ID 的共享内存连接的信息。
语法:

如果未提供 client_id ,那么给出关于到数据库服务器的所有当前共享内存连接的信息。如果提供了 client_id ,那么此命令给出具有该 ID 的共享内存连接的更详细的信息。
示例输出
以下是不带有 client_id 的 onstat -g nsc 输出。它显示当前只有一个用户通过共享内存连接到数据库服务器。这个连接的 ID 是 0 。
图: onstat -g nsc 命令输出
![]()
此示例显示使用 client_id 0 运行命令的输出:
图: 带有 client id 的 onstat -g nsc 命令输出
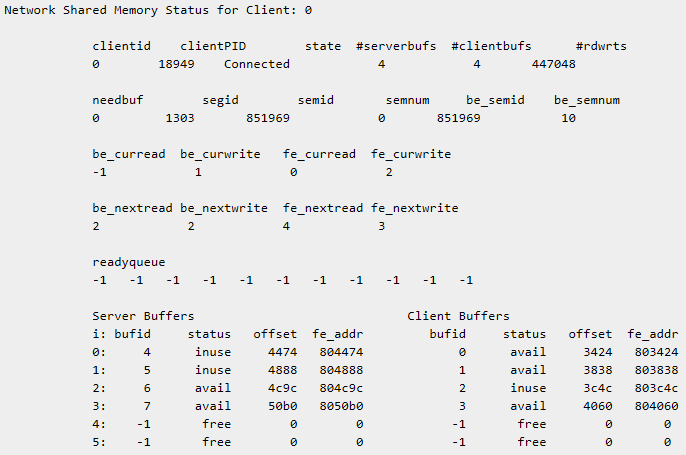
输出描述
clientid: 服务器分配的 ID
clientPID: 客户端进程 ID
state: 连接状态
Connected: 客户端已和服务器建立了连接
Con1:服务器已经成功建立与客户端的连接,但客户端尚未得到通知
Waiting: 服务器正处于与客户机建立连接的过程中
Reject: 服务器已经拒绝客户机连接,通常是由于服务器正在关闭或还未处于在线模式
Closed: 服务器已关闭与客户端的连接。客户端可能还不知道这个情况
Not connected: 服务器正在初始化连接的内部结构
Unknown: 连接已关闭,并且客户端知道这个情况。服务器正在消除内部结构
#serverbufs: 当前分配的数据库服务器缓冲区
#clientbufs: 当前分配的客户端缓冲区
#rdwrts: 自连接创建以来通过这个连接执行的读和写的总数
仅当带 client_id 运行 onstat -g nsc 命令时,以下项才显示在输出中:
needbuf: 标示服务器是否在等待释放某个缓冲区,**0-**False,**1-**True
segid: 共享内存段 ID
semid: 信号量 ID
semnum: 在信号量 ID 中的信号量编号
be_semid: 后端信号量 ID
be_semnum: 在信号量 ID 中的后端信号量编号
be_curread: 正被读取的后端缓冲区的 ID
be_curwrite: 正被写入的后端缓冲区的 ID
fe_curread: 正被读取的前端缓冲区的 ID
fe_currwrite: 正被写入的前端缓冲区的 ID
be_nextread: 要读取的下一个后端缓冲区的 ID
be_nextwrite: 要写入的下一个后端缓冲区的 ID
fe_nextread: 要读取的下一个前端缓冲区的 ID
fe_nextwrite: 要写入的下一个前端缓冲区的 ID
readyqueue: 共享缓冲区标识队列
Buffers
i: 消息缓冲区的内部位置键
bufid: 消息缓冲区 ID
status: 消息缓冲区的状态
offset: 共享内存段中的内存缓冲区的偏移量
fe_addr: 消息缓冲区的前端地址
onstat -g nsd 命令:打印轮询线程共享内存数据
可以使用 onstat -g nsd 命令显示轮询线程的共享内存数据。
语法:
示例输出
图: onstat -g nsd 命令输出
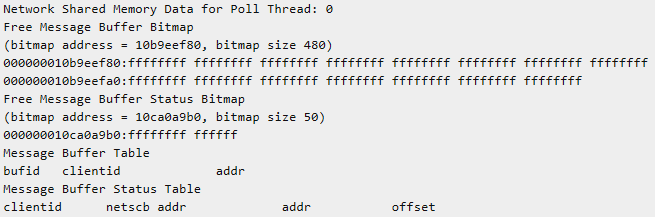
onstat -g nss 命令:打印共享内存网络连接状态
可以使用 onstat -g nss sessionid 命令显示有关共享内存网络连接状态的信息。
语法:

如果未提供 sessionid ,那么会为每个共享内存连接列出一行摘要。
示例输出
图: onstat -g nss 命令输出

输出描述
clientid (decimal): 服务器为查找分配的值
clientPID (decimal): 客户端进程 ID
state (string): 连接的当前状态
- Connected
- Con1
- Waiting
- Reject
- Bedcover
- Closed
- Not connected
- Unknown
#serverbufs (dec): 当前分配的数据库服务器的缓冲区数
#clientbufs (dec): 当前分配的客户端缓冲区数
#rdwrts (dec): 使用中的缓冲区数
onstat -g ntd 命令:打印网络统计信息
可以使用 onstat -g ntd 命令按服务显示网络统计信息。
语法:
示例输出
图: onstat -g ntd 命令输出
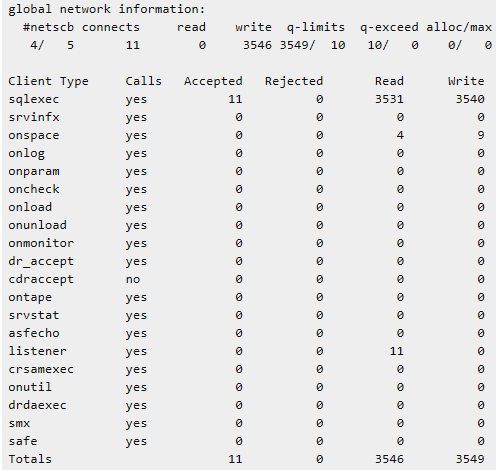
onstat -g ntm 命令:打印网络邮件的统计信息
可以使用 onstat -g ntm 命令打印网络邮件的统计信息。
语法:
示例输出
图: onstat -g ntm 命令输出

onstat -g ntt 命令:打印网络用户的次数
可以使用 onstat -g ntt 命令显示有关网络用户时间的信息。
语法:

示例输出
图: onstat -g ntt 命令输出

onstat -g ntu 命令:打印网络用户统计信息
可以使用 onstat -g ntu 命令显示有关网络用户的统计信息。
语法:
示例输出
图: onstat -g ntu 命令输出

onstat -g opn 命令:打印打开的分区
可以使用 onstat -g opn 命令显示通过线程 ID 打印系统中当前打开的分区(表和索引)的列表。
使用 thread_id 选项来限制指定 ID 的列表。
语法:

示例输出
图: onstat -g opn 命令输出
tid rstcb isfd op_mode op_flags partnum ucount ocount lockmode
38 0x00000000460db7b0 0 0x00000400 0x00000397 0x001000af 2 2 0
38 0x00000000460db7b0 1 0x00000002 0x00000117 0x001000af 2 2 0
38 0x00000000460db7b0 2 0x00000440 0x00000797 0x0010010c 2 0 0
38 0x00000000460db7b0 3 0x00000400 0x00000407 0x0010010a 2 0 0
38 0x00000000460db7b0 4 0x00000400 0x00000407 0x0010010a 2 0 0
38 0x00000000460db7b0 5 0x00000002 0x00000003 0x00100003 2 2 0
38 0x00000000460db7b0 6 0x00000400 0x00000397 0x00100003 2 2 0
38 0x00000000460db7b0 7 0x00000400 0x00000413 0x0010010f 2 0 0
38 0x00000000460db7b0 8 0x00000440 0x00000797 0x0010010c 2 0 0
38 0x00000000460db7b0 9 0x00000402 0x00000403 0x0010010f 2 0 0
38 0x00000000460db7b0 10 0x00000442 0x00000403 0x00100111 1 0 0
38 0x00000000460db7b0 11 0x00000442 0x00000403 0x00100110 1 0 0
38 0x00000000460db7b0 12 0x00000442 0x00000403 0x00100112 1 0 0
38 0x00000000460db7b0 15 0x00000400 0x00004407 0x00000006 1 0 0
38 0x00000000460db7b0 16 0x00000400 0x00000413 0x00100119 1 0 0
36 0x00000000460dbf98 0 0x00000400 0x00000397 0x001000af 2 2 0
36 0x00000000460dbf98 1 0x00000002 0x00000003 0x001000af 2 2 0
36 0x00000000460dbf98 3 0x00000402 0x00000407 0x0010010a 2 0 0
36 0x00000000460dbf98 4 0x00000400 0x00000413 0x0010010a 2 0 0
36 0x00000000460dbf98 6 0x00000442 0x00000797 0x0010010c 1 0 0
37 0x00000000460dc780 0 0x00000400 0x00000397 0x001000af 2 2 0
37 0x00000000460dc780 1 0x00000002 0x00000117 0x001000af 2 2 0
37 0x00000000460dc780 2 0x00000400 0x00000407 0x0010010a 2 0 0
37 0x00000000460dc780 3 0x00000440 0x00000797 0x0010010c 2 0 0
37 0x00000000460dc780 4 0x00000400 0x00000413 0x0010010f 2 0 0
37 0x00000000460dc780 5 0x00000400 0x00000407 0x0010010a 2 0 0
37 0x00000000460dc780 6 0x00000440 0x00000797 0x0010010c 2 0 0
37 0x00000000460dc780 7 0x00000400 0x00000397 0x00100003 2 2 0
37 0x00000000460dc780 8 0x00000002 0x00000003 0x00100003 2 2 0
37 0x00000000460dc780 9 0x00000442 0x00000403 0x00100111 1 0 0
37 0x00000000460dc780 10 0x00000442 0x00000403 0x00100110 1 0 0
37 0x00000000460dc780 11 0x00000402 0x00000403 0x0010010f 2 0 0
37 0x00000000460dc780 12 0x00000400 0x00000413 0x00100119 1 0 0
37 0x00000000460dc780 13 0x00000442 0x00000403 0x00100112 1 0 0
37 0x00000000460dc780 14 0x00000400 0x00004407 0x00000006 1 0 0
输出描述
tid (decimal): 当前访问分区资源(表和索引)的线程 ID
rstcb (hexadecimal): 该线程的 RSAM 线程控制 block 的内存地址
isfd (decimal) : 与打开分区关联的 ISAM 文件描述符
op_mode (hexadecimal) : 使用以下十六进制值组合的分区锁定方式的当前状态:
0x000000 Open for input only
0x000001 Open for output only
0x000002 Open for input and output
0x000004 System catalog
0x000008 No logical logging
0x000010 Open if not already opened for alter
0x000020 Open all fragments data and index
0x000040 Do not allocate a blob descriptor
0x000080 Open for alter
0x000100 Open all data fragments
0x000200 Automatic record lock
0x000400 Manual record lock
0x000800 Exclusive ISAM file lock
0x001000 Ignore dataskip - data cannot be ignored
0x002000 Dropping partition - delay file open
0x004000 Do not drop blobspace blobs when table dropped
(alter fragment)
0x010000 Open table for DDL operations
0x040000 Do not assert fail if this partnum does not exist
0x080000 Include fragments of subtables
0x100000 Table created under supertable
0x400000 Blob in use by CDR
op_flags (hexadecimal) : 分区的当前状态使用以下十六进制值组合:
0x0001 Open data structure is in use
0x0002 Current position exists
0x0004 Current record has been read
0x0008 Duplicate created or read
0x0010 Skip current record on reverse read
0x0020 Shared blob information
0x0040 Partition opened for rollback
0x0080 Stop key has been set
0x0100 No index related read aheads
0x0200 isstart called for current stop key
0x0400 Pseudo-closed
0x0800 Real partition opened for SMI query
0x1000 Read ahead of parent node is done
0x2000 UDR keys loaded
0x4000 Open is for a pseudo table
0x8000 End of file encountered when positioning in table
partnum (hexadecimal) : 已打开资源(表和索引)的分区数
ucount (decimal) : 当前访问该分区的用户线程数
ocount (decimal) : 打开该分区的次数
lockmode (decimal) : 使用以下代码值之一保存锁定类型:
0 No locks
1 Byte lock
2 Intent shared lock
3 Shared lock
4 Shared lock by repeatable read (only on items)
5 Update lock
6 Update lock by repeatable read (only on items)
7 Intent exclusive lock
8 Shared, intent exclusive lock
9 Exclusive lock
10 Exclusive lock by repeatable read (only on items)
11 Inserter's repeatable read test lock
onstat -g osi 命令:打印操作系统的信息
可以使用 onstat -g osi 命令显示您的操作系统和参数的信息,包括共享内存和信号量参数、电脑上当前配置的内存量和未使用的内存量。
示例输出
onstat -g osi 命令也显示电脑上硬件程序的统计信息。
在服务器未在线时使用该命令。
图: onstat -g osi 命令输出
onstat -g pos 命令:打印文件值
可以使用 onstat -g pos 命令显示 $GBASEDBTDIR/etc/.infos.DBSERVERNAME 文件中的值。
语法:
![]()
示例输出
图: onstat -g pos 命令输出
1 2 -32750 shm 32786 5279c803 4ee94000 135364608 V
2 2 19 shm 19 5279c804 56fac000 830087168 V
3 7 0 infos ver/size 3 272
4 1 0 snum 9088 5279c801 44000000 22148 instance
5 4 0 onconfig path #
6 5 0 host localhost.localdomain
7 6 0 oninit ver GBase Database Server Version 12.10.FC4G1TL
8 8 0 sqlhosts path /opt/gbs_server/data/conf/sqlhosts
9 3 2 sema 5111810
10 2 -32752 shm 32784 5279c801 44000000 51986432 R
11 2 17 shm 17 5279c802 47194000 131072000 V
onstat -g ppd 命令:打印分区压缩字典信息
可以使用 onstat –g ppd 命令显示为压缩表和表分片或压缩 B-tree 索引创建的活动压缩字典的信息。可以选择打印特定编号分区或所有打开分区的信息。
onstat –g ppd 命令打印的信息与在 sysmaster 数据库中 syscompdicts_full 表和 syscompdicts 视图显示的信息相同。唯一的区别是 syscompdicts_full 表和 syscompdicts 视图不仅仅只显示活动字典,还显示所有压缩字典的信息。
语法:
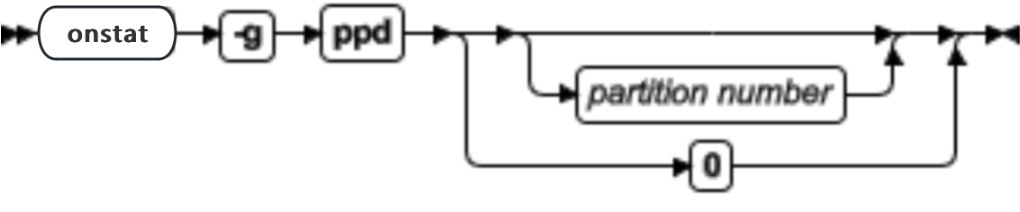
如果指定了分区号,那么 onstat -g ppd 打印该分区的分区概要文件信息。如果指定 0 ,该选项打印所有分区的概要文件信息。
示例输出
图: onstat –g ppd Output

输出描述
partnum: 应用压缩字典的分区号
ColOffset: 压缩分区 blob 列的字节偏移量。-1 表示只有该行是压缩的
DbsNum: 字典驻留的 dbspace 号
CrTS: 显示创建该字典的时间戳
CrLogID: 当创建字典时,创建的逻辑日志的唯一 ID
CrLogPos: 创建字典时,逻辑日志的位置
DrTS: 显示何时清除该字典的时间戳
DrLogID: 当清除字典时,创建的逻辑日志的唯一 ID
DrLogPos: 清除字典时,逻辑日志的位置
onstat -g ppf 命令:打印分区的概要文件
可以使用 onstat -g ppf partition_number 命令显示指定分区号的分区概要文件。
使用 onstat -g ppf 或 onstat -g ppf 0 命令显示所有分区的概要文件。如果 TBLSPACE_STATS 配置参数设置为 0 ,那么 onstat -g ppf 命令显示:Partition profiles disabled。
语法:

示例输出
图: onstat -g ppf 命令输出

输出描述
partnum (hex): 分区号
lkrqs (decimal): 请求分区的锁的数量
lkwts (decimal): 等待分区的锁的数量
dlks (decimal): 分区的死锁数
touts(decimal): 分区的远程死锁超时
isrd (decimal): 分区的读取数
iswrt (decimal): 分区的写入数
isrwt (decimal) : 分区的重写或修改数
isdel (decimal): 分区的删除数
bfrd (decimal): 缓冲区的读取数,以页表示
bfwrt (decimal): 缓冲区的写入数,以页表示
seqsc (decimal): 分区的顺序扫描数
rhitratio (percentage): 磁盘读和缓冲区读的比率
onstat -g pqs 命令:打印所有 SQL 查询的运算符
可以使用 onstat –g pqs 命令显示当前正在运行的 SQL 查询中的使用的运算符的信息。
可以使用该命令对应用程序镜像故障排除、找到该查询所使用的运算符以及每个运算符返回行数及长度。 EXPLAIN 文件包含的信息显示此查询计划的概览,onstat –g pqs 命令显示该查询和查询计划的运行时的操作者。
语法:

可以指定以下之一的调用:
表. 每个 onstat -g pqs 命令调用的描述
| 调用 | 解释 |
|---|---|
| onstat -g pqs | 显示每个会话的一行摘要 |
| onstat -g pqs sessionid | 显示指定会话的信息 |
示例输出
以下示例显示了在不同会话中三个单独的 SQL 语句运行的结果。这些语句是:

图: onstat –g pqs 命令输出

输出描述
addr: 运算符在内存中的地址。可以使用该地址跟踪属于每个 JOINT 运算符的 SCAN 运算符
ses-id: 运行 SQL 语句的会话的 ID
opname: 运算符名称
phase: 已使用的运算符的阶段,例如 OPEN 、NEXT 、CLOSE
rows: 该运算符执行的行数
time: 执行该运算符的时间量。以毫秒显示。 01:20.10 是 1 分钟 20 秒 10 毫秒
in1: 该连接中的第一个运算符(outer)
in2: 该连接中的第二个运算符(inner)
stmt-type: SQL 语句的类型,例如 SELECT 、UPDATE 、DELETE
onstat -g prc 命令:打印使用 UDR 或 SPL 例程的会话
可以使用 onstat -g prc 命令显示当前使用 UDR 或 SPL 例程的会话数。
语法:

示例输出
图: onstat -g prc 命令输出
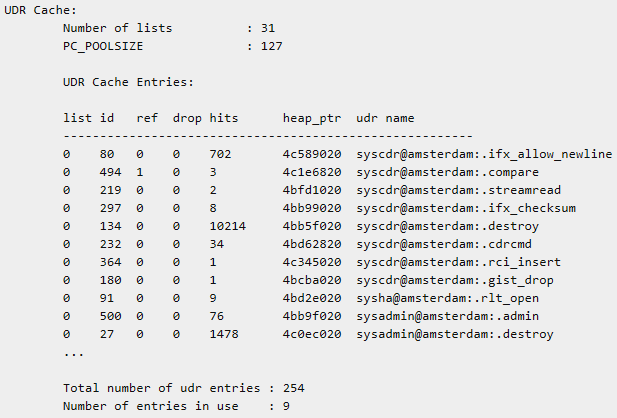
输出描述
**Number of lists:**U DR 高速缓存中的列表数
PC_POOLSIZE: 一次可以高速缓存的条目数
list: UDR 高速缓存哈希链 ID (bucket number)
id: 此例程的唯一 ID
ref: 从高速缓存访问 UDR 或 SPL 例程的会话数
drop: 该例程是否标记已删除
hits: 访问该高速缓存条目的次数
heap_ptr: 用于存储该条目的堆地址
udr_name: 高速缓存中 UDR 或 SPL 例程的名称
Total number of udr entries: 高速缓存中的条目数
Number of entries in use: 正在使用的条目数
onstat -g proxy 命令:打印代理分发器信息
可以使用 onstat -g proxy 命令显示有关代理分发器的信息。onstat -g proxy 命令的输出根据该命令是否在主服务器或辅助服务器上运行而稍有不同。
语法:

| 调用 | 解释 |
|---|---|
| onstat -g proxy | 显示代理分发器信息 |
| onstat -g proxy all | 当在主服务器上运行时,显示有关代理分发器和代理线程的信息。当在辅助服务器上运行时。显示有关所有当前执行更新到辅助服务器的会话的信息 |
| onstat -g proxy proxy_id proxy_transaction_id sequence_number | 该选项只在辅助服务器上可用。显示当前由给出的代理分发器产生的工作的详细信息。proxy_transaction_id 和 sequence_number 是可选的参数。当提供时,第一数字作为 proxy_transaction_id ,第二个数字解释为 sequence_number。如果提供的 proxy_transaction_id 或 sequence_number 不存在,那么该命令的输出与 onstat - 输出一样 |
在主服务器上使用 onstat -g proxy 命令的示例输出
图: onstat -g proxy 命令输出(自主服务器上运行)

输出描述
Secondary Node: 被主服务器所知的辅助服务器名称
Proxy ID: 代理分发器的 ID 。在高可用性集群中代理 ID 是唯一的
Reference Count: 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
Transaction Count: 当前代理分发器正在处理的事务数
Hot Row Total: 代理分发器已处理的热行总数
在辅助服务器上使用 onstat -g proxy 命令的示例输出
图: onstat -g proxy 命令输出(自辅助服务器上运行)

输出描述
Primary Node: 主服务器名
Proxy ID: 代理分发器的 ID 。在高可用性集群中代理 ID 是唯一的
Reference Count: 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
Transaction Count: 当前代理分发器正在处理的事务数
Hot Row Total: 代理分发器已处理的热行总数
在主服务器上使用 onstat -g proxy all 命令的示例输出
图: onstat -g proxy all 命令输出(自主服务器上运行)

输出描述
Secondary Node : 被主服务器所知的辅助服务器名
Proxy ID : 代理分发器的 ID 。在高可用性集群中代理 ID 是唯一的
Reference Count : 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
Transaction Count : 当前代理分发器正在处理的事务数
Hot Row Total : 代理分发器已处理的热行总数
TID : 正在主服务器上运行的代理线程的 ID 。该 ID 是代理分发器创建用于处理来自辅助服务器会话的工作
Flags : 代理线程的标志
Proxy ID : 代表正在运行的代理线程(TID)的代理分发器 ID
Source SessID : 辅助服务器上用户会话的 ID
Proxy TxnID : 当前事务的编号。这些编号对于代理分发器是唯一的
Current Seq : 当前事务中当前操作的顺序号
sqlerrno : 任一 SQL 错误的错误号(或者 0 如果没有错误)
iserrno : 任一 ISAM 或 RSAM 错误的错误号 (或者 0 如果没有错误)
在辅助服务器上使用 onstat -g proxy all 命令的示例输出
图: onstat -g proxy all 命令输出(自辅助服务器上运行)

输出描述
Primary Node : 主服务器名
Proxy ID : 代理分发器的 ID 。在高可用性集群中代理 ID 是唯一的
Reference Count : 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
Transaction Count : 当前代理分发器正在处理的事务数
Hot Row Total : 由代理分发器处理的总行数。热行是辅助服务器上被一个或多个客户端修改过多次的行。当行被多次修改时,如果最近来自不同会话的更新操作不在辅助服务器上重演,辅助服务器会读取之前从主服务器在该行上放置一个更新锁的视图。
Session : 会话 ID
Proxy ID : 代表正在运行的代理线程(TID)的代理分发器 ID
Proxy TID : 正在主服务器上运行的代理线程的 ID 。该 ID 是代理分发器创建用于处理来自辅助服务器会话的工作
Proxy TxnID : 当前事务的编号。这些编号对于代理分发器是唯一的
Current Seq : 当前事务中当前操作的顺序号
Pending Ops : 辅助服务器上还未发送到主服务器的已缓冲的操作数
Reference Count : 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
在辅助服务器上使用 proxy_id 选项的示例输出
该命令只在辅助服务器上才返回信息。
图: onstat -g proxy proxy_id 命令输出(自辅助服务器上运行)

输出描述
Proxy TxnID : 当前的事务的编号。这些编号对于代理分发器是唯一的
Reference Count : 标示当前事务中正在使用该信息的线程数。当计数为 0 时,该事务处理完毕(无论成功或不成功)
Pending Ops : 辅助服务器上还未发送到主服务器的已缓冲的操作数
Proxy SID : 代理会话 ID
在辅助服务器上使用 proxy_id proxy_transaction_id 选项的示例输出
该命令只在辅助服务器上才返回信息。
图: onstat -g proxy_id proxy_transaction_id 命令输出(自辅助服务器上运行)

输出描述
Sequence Number : 操作数
Operation Type : 已执行的操作的类型。可以是:插入、修改、删除和其它
rowid : 应用该操作的行的行 ID
Table Name : 表的全名,修改以适应合理的长度。格式为:database.owner.tablename
sqlerrno : 任一 SQL 错误的错误号(或者 0 如果没有错误)
在辅助服务器上运行 proxy_id proxy_transaction_id sequence_number 选项的示例输出
该命令只在辅助服务器上才返回信息。
输出的字段与 onstat -g proxy_id proxy_transaction_id 命令输出的字段相同。不同的是,onstat -g proxy_id proxy_transaction_id 命令显示该事务的详细信息,onstat -g proxy_id proxy_transaction_id sequence_number 显示所有事务的详细信息。
图: onstat -g proxy_id proxy_transaction_id sequence_number 命令输出(自辅助服务器上运行)
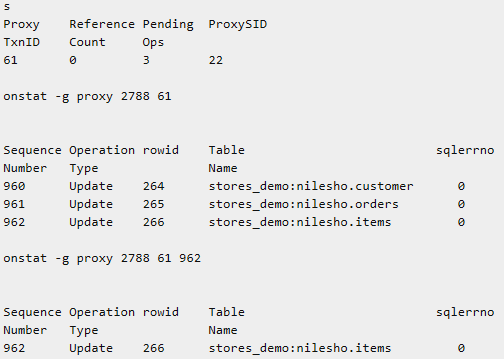
onstat -g qst 命令:打印互斥队列和条件队列的等待选项
可以使用 onstat -g qst 命令显示互斥队列和条件队列(互斥或条件的等待者的队列)的等待统计信息。
QSTATS 配置参数必须设为 1 来启用统计信息的采集。
语法:
示例输出
图: onstat -g qst 命令输出

输出描述
name (string): 等待的互斥或条件资源的名称
nwaits (decimal): 等待此资源的次数
avg_time (decimal): 等待的平均时间(微秒)
max_time (decimal): 等待的最长时间(微秒)
avgq (decimal): 队列的平均长度
maxq (decimal): 队列的最长长度
nservs (decimal): 获取此资源的次数
avg_time (decimal, microsecond): 每次获取资源时挂起的平均时间(微秒)
onstat -g rah 命令:打印预读请求统计信息
可以使用 onstat -g rah 命令显示有关预读请求的信息。
语法:
示例输出
图: onstat -g rah 命令输出
输出描述
Qs: 预读请求队列数
# threads: 预读线程数
# Requests: 预读请求数
# Continued : 持续发生预读请求的次数
# Memory Failures: 由于内存不满足而请求失败的次数
Last Thread Add : 上一次添加预读线程的日期和时间
Way behind: 由于预读的保护进程太落后而删除的页请求列
Partnum: 分区号
Buffer reads: 已读取的缓冲池数和磁盘页数
Disk Reads: 从磁盘读取的页数
Hit Ratio : 分区的缓存命中率
# Reqs: 预读请求数。(该实例有五个输出字段:数据、索引、索引数据、日志页和上次提交的行)
Eff: 预读请求的效率。它是预读操作请求的页数与不需要预读操作的已缓存页数的比率。值位于 0 和 100 之间。数字越大表示该预读效率更高。该实例有五个输出字段:数据、索引、索引数据、日志页和上次提交的行)
Resch: 因为对多片行的更新不完整而要重新安排的最后提交的行的请求数
onstat -g rbm 命令:打印共享内存的 block 映射
可以使用 onstat -g rbm 命令显示共享内存常驻段中可用和已使用的 block 的十六进制位图。
语法:
示例输出
图: onstat -g rbm 命令输出

输出描述
Header
address (hex): 在段内已用/空闲的 block 的内存中起始地址
size (bits): block 位图中的位数;每个位代表一个 block
used (blocks): 位图中已用的 blocks
largest_free (blocks): 可用 block 的最大运行
Data
Bit number (decimal): data (hex): 位数,后面是 32 个字节的数据(十六进制)
onstat -g rea 命令:打印准备就绪的线程
可以使用 onstat -g rea 命令显示当前已就绪的虚拟处理器线程的信息。
语法:

示例输出
图: onstat -g rea 命令输出

onstat -g rss 命令:打印 RHAC 辅助服务器信息
可以使用 onstat -g rss 命令显示有关远程独立辅助服务器的信息。
语法:
onstat -g rss 命令的输出因命令在主服务器上还是 RHAC 辅助服务器上运行而稍有不同。
| 调用 | 解释 |
|---|---|
| onstat -g rss | 显示 RHAC 辅助服务器的简要信息 |
| onstat -g rss verbose | 显示 RHAC 辅助服务器的详细信息 |
| onstat -g rss log | 显示日志信息。该命令只能在主服务器上应用。 |
| onstat -g rss server_name | 显示指定的 RHAC 辅助服务器的信息。该命令只能在主服务器上应用。 |
示例输出(主服务器)
图: onstat -g rss verbose 命令输出,自主服务器上运行
Local server type: Primary
Index page logging status: Enabled
Index page logging was enabled at: 2009/08/31 09:35:22
Number of RSS servers: 1
RSS Server information:
RSS Server control block: 0x5fdd9740
RSS server name: serv3
RSS server status: Active
RSS connection status: Connected
RSS flow control:576/528
Log transmission status: Active
Next log page to send(log id,page): 53,117632
Last log page acked(log id,page): 53,115615
Last log page applied (log id, page); 53,115615
Time of Last Acknowledgment: 2009-08-31.14:14:09
Pending Log Pages to be ACKed: 1984
Approximate Log Page Backlog:97104
Sequence number of next buffer to send: 3676
Sequence number of last buffer acked: 3612
Supports Proxy Writes: Y
输出描述(主服务器)
Local server type: 主或 RHAC(远程独立辅助)服务器类型
Index page logging status: 显示是否启用或禁用主服务器和辅助服务器之间的索引页日志记录
Index page logging was enabled at: 启用索引页日志记录的日期和时间
Number of RSS servers: 连接到主服务器的 RHAC 辅助服务器数
RSS Server control block: RHAC 辅助服务器控制 block
RSS Server name: RHAC 辅助服务器名称
RSS Server status: 显示 RHAC 辅助服务器是否活动
RSS flow control: 逻辑日志页中的数值,代表确定何时启用或禁用流控制
RSS Connection status: RHAC 辅助服务器的连接状态
Log transmission status: 显示日志事务是否激活
Next log page to send (log id, page): 要发送的下一个日志页的日志 ID 和页编号
Last log page acked (log id, page): 应答的上一个日志的日志 ID 和页编号
Last log page applied (log id, page): 最后应用日志的日志 ID 和页编号
Time of Last Acknowledgment: 最后一次应答日志的时间
Pending Log pages to be ACKed: 已发生但还未应答的日志数
Approximate Log Page Backlog: 已发送的日志数和最后逻辑日志数的不同
Sequence number of next buffer to send: 要发送的下一个缓冲区的序号
Sequence number of last buffer acked: 应答的上一个缓冲区的序号
Supports Proxy Writes: 显示该服务器当前是否配置了允许更新辅助服务器。 Y = 支持更新辅助服务器,N = 不支持更新辅助服务器
使用 log 选项的示例输出(主服务器)
图: onstat -g rss log 命令输出,自主服务器上运行
Log Pages Snooped:
RSS Srv From From Tossed
name Cache Disk (LBC full)
cdr_ol_nag_1_c1 1368 1331 0
cdr_ol_nag_1_c2 1357 1342 0
cdr_ol_nag_1_c3 1356 1343 0
使用 log 选项的输出描述(主服务器)
Log Pages Snooped: 每台 RHAC 辅助服务器的统计信息
RSS Srv name: RHAC 辅助服务器名称
From Cache: 来自高速缓存
From Disk: 来自磁盘的日志
Tossed (LBC full): 由于 LBC 变满而抛弃的日志页数
示例输出(RHAC 辅助服务器)
图: onstat -g rss 命令输出,自 RHAC 辅助服务器上运行
Local server type: RSS
Server Status: Active
Source server name: cdr_ol_nag_1
Connection status: Connected
Last log page received(log id,page): 7,877
输出描述(RHAC 辅助服务器)
Local server type: 主或 RSS(远程独立辅助)服务器类型
Server Status: 显示 RHAC 辅助服务器是否活动
Source server name: 主服务器名称
Connection status: RHAC 辅助服务器的连接状态
Last log page received (log id,page): 最近接收到的日志 ID 和页面
使用 verbose 选项的示例输出(RHAC 辅助服务器)
图: onstat -g rss verbose 命令输出,自 RHAC 辅助服务器上运行
RSS Server control block: 0x45a3fe58
Local server type: RSS
Server Status: Active
Source server name: my_server
Connection status: Connected
Last log page received(log id,page): 10,1364
Sequence number of last buffer received: 489
Sequence number of last buffer acked: 489
Delay Apply: Configured (3)
Stop Apply: Not configured.
Delay or Stop Apply control block: 0x45a40ba8
Pending pages: 7
Last page written: (10:1372).
Next page to read: (10:1366).
Delay or Stop Apply thread: Running.
使用 verbose 选项的输出描述(RHAC 辅助服务器)
RSS Server control block: 服务器控制 block
Local server type: 本地服务器的类型
Server Status: RHAC 辅助服务器的状态
Source server name: 在 RHAC 辅助服务器的高可用性集群中的主服务器名称
Connection status: RHAC 辅助服务器和集群的主服务器之间的连接状态
Last log page received (log id,page): RHAC 辅助服务器上一次应答的日志的日志 ID 和页编号
Sequence number of last buffer received: RHAC 辅助服务器接收的上一个缓冲区的序号
Sequence number of last buffer acked: RHAC 辅助服务器应答的上一个缓冲区的序号
Delay Apply: 是否设置了延迟应用。延迟值,以秒表示,用括号括起
Stop Apply: 是否设置了停止应用。停止值,用括号括起,它是 1 或 Unix 时间
Delay or Stop Apply control block: 延迟或停止应用的控制 block
Pending pages: 等待写入日志暂存目录的页数
Last page written: 上一个写入日志暂存目录的日志的日志 ID 和页编号
Next page to read: 下一个要写入日志暂存目录的日志的日志 ID 和页编号
Delay or Stop Apply thread: 延迟应用或停止应用线程的状态
onstat -g rwm 命令:打印读取和写入互斥
可以使用 onstat -g rwm 命令显示读、写和等待互斥线程的信息和这些线程获得的凭单的地址列表。
语法:
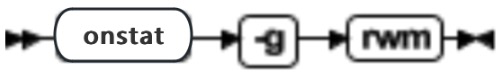
示例输出
图: onstat -g rwm 命令输出
输出描述
tcb : 线程地址列表
Writer : 写线程列表
Readers : 读线程列表
Waiters : 正在等待的线程列表
ticket : 线程获得的凭单的地址
onstat -g sch 命令:打印 VP 信息
可以使用 onstat -g sch 命令显示线程迁移和每个虚拟处理器的信号量操作、自旋和忙等待的数量的信息。
语法:
示例输出
图: onstat -g sch 命令输出
onstat -g scn 命令;打印扫描选项
可以使用 onstat -g scn 命令显示当前扫描的状态和该扫描的信息。
如果您有一个长时间运行的扫描,那么可以使用该命令检查扫描的进程、在扫描结束前确定扫描所需的时间并可以查看该扫描的信息。对于表来说,onstat -g scn 命令的输出标识该扫描是轻度扫描还是缓冲池扫描。
语法:
示例输出
图: onstat -g scn 输出显示表信息

有关运行扫描时索引扫描可用的信息。
图: onstat -g scn 输出显示索引扫描信息

输出描述
descriptor (decimal): 轻度扫描 ID
address (hex): 轻度扫描描述符的内存地址
next_lpage (hex): 要扫描的下一个逻辑页地址
next_ppage (hex): 要扫描的下一个物理页地址
ppage_left (decimal): 当前 extent 中剩余的物理页数
bufcnt: 此次轻度扫描使用的轻度扫描缓冲区数
look_aside: 此次轻度扫描是否要观察周边(Y = yes, N = no)。当线程需要在缓冲池中检查现有页以获得正在被轻度扫描的页的最新图像时,发生观察周边操作
SesID: 会话 ID
Thread: 线程 ID
Partnum: 分区号
Rowid: 当前行 ID
Rows Scan'd: 已扫描的行数
Scan Type: 对于表来说,是以下其中之一:
- Bufferpool
- Light(轻度扫描)
对于索引来说,是以下其中之一:
- key only
- 没有值,如果扫描不是 key only 扫描
Lock Mode: 获得的锁的类型或没有锁:
- Table(表级别锁定)
- Slock(共享锁)
- Ulock(更新锁)
- blank(没有锁)
该列也显示了以下之一的值:
- +Test (扫描测试带有特定锁类型的冲突;没有获得锁)
- +Keep (获取的锁将保持到会话结束而不是事务结束)
Notes® : 该列显示了以下之一的值:
- Look aside
轻度扫描正在观察周边。
轻度扫描直接从磁盘读取页的 block 到大缓冲区,而不是从缓冲区管理器获得每个页。在一些情况下,该进程要求此次轻度扫描检查缓冲池中每个数据页的情况下,来自它的一个大缓冲区的过程;这个过程称为 look aside。如果页在缓冲池中,那么此次轻度扫描会使用副本而不是轻度扫描大缓冲区中的部分。如果页不在缓冲池中,那么此次轻度扫描将会使用从磁盘读取到它的大缓冲区的副本。如果轻度扫描正在观察周边,那么会此次扫描的性能会稍微降低。
在很多情况中,轻度扫描会检测到缓冲池不可能具有新版本的页。在这种情况下,此次轻度扫描将不会检查缓冲池也不会观察周边。
- Forward row lookup
服务器正在对一个具有跨页的表执行轻度扫描。该轻度扫描必须访问和使用缓冲池来得到任何主页上不完整的行的剩余的片段。
Start key: 扫描的起始键
Stop key: 扫描的结束键
Current key: 该扫描中的当前键
Current position: 扫描在索引中的当前位置。例如:页、slot 和偏移量
onstat -g sds 命令:打印 SSC 辅助服务器信息
可以使用 onstat -g sds 命令显示有关共享磁盘辅助服务器的信息。
语法:
onstat -g sds 命令的输出因命令在主服务器上还是 SSC 辅助服务器上运行而稍有不同。
| 调用 | 解释 |
|---|---|
| onstat -g sds | 显示 SSC 辅助服务器的简要信息 |
| onstat -g sds verbose | 显示 SSC 辅助服务器的详细信息 |
| onstat -g sds server_name | 显示指定的 SSC 辅助服务器的信息。当指定 server_name 时,该命令必须从主服务器声明 |
示例输出(主服务器)
图: onstat -g sds 命令输出,自主服务器上运行

输出描述(主服务器)
Local server type: 主或 SSC (共享磁盘辅助)服务器类型
Number of SDS servers: 连接到主服务器的 SSC 辅助服务器数
SDS Srv name: SSC 辅助服务器的名称
SDS Srv status: 显示 SSC 辅助服务器是否活动
Connection status: 显示 SSC 辅助服务器是否连接
Last LPG sent (log id, page): 最近的 LPG 日志 ID 和页
Supports Proxy Writes: 显示该服务器当前是否配置了允许更新辅助服务器。 Y = 支持更新辅助服务器,N = 不支持更新辅助服务器
使用 verbose 选项的示例输出(主服务器)
图: onstat -g sds server_name 命令输出,自主服务器上运行
使用 verbose 选项的输出描述(主服务器)
Number of SDS servers: 与主服务器共享磁盘空间的 SSC 辅助服务器数
Updater node alias name: 主服务器名
SDS server control block: SSC 辅助服务器控制 block
server name: 服务器名
server type: 服务器的类型
server status: 显示该服务器是否被激活
connection status: 主服务器和辅助服务器之间连接的状态
Last log page sent (log id, page): 最近发送的日志页面的日志 ID 和页面
Last log page flushed (log id, page): 最近清空的日志页面的日志 ID 和页面
Last log page acked (log id, pos)): 最近应答的日志页
Last LSN acked (log id, pos): 最近应答的日志序列号
Last log page applied(log id,page): 最近应用的日志的日志 ID 和页编号
Approximate Log Page Backlog: 等待发送的日志数
Current SDS Cycle: 由 GBase 支持内部使用来监视主服务器和 SDS 服务器之间的协调性
Acked SDS Cycle: 由 GBase 支持内部使用来监视主服务器和 SDS 服务器之间的协调性
Sequence number of next buffer to send: 要发送的下一个缓冲区的序号
Sequence number of last buffer acked: 应答的下一个缓冲区的序号
Time of last ack: 上一个日志确认的日期和时间
Supports Proxy Writes: 显示该服务器当前是否配置了允许更新辅助服务器。 Y = 支持更新辅助服务器,N = 不支持更新辅助服务器
Time of last received message: 当前服务器最近一次从另一个服务器接收消息的时间戳
Time of last alternate write: 当前服务器最近一次写入由 SDS_ALTERNATE 配置参数指定的 blobspace 的时间戳
Time of last alternate read: 当前服务器最近一次读取由 SDS_ALTERNATE 配置参数指定的 blobspace 的时间戳
使用 verbose 选项的示例输出 (SSC 辅助服务器)
图: onstat -g sds verbose 命令输出,自 SSC 辅助服务器上运行
使用 verbose 选项的输出描述 (SSC 辅助服务器)
SDS server control block : SSC 辅助服务器控制 block
Local server type : 主或 SSC(共享磁盘辅助)服务器类型
Server status : 显示 SSC 辅助服务器是否活动
Source server name : 主服务器名
Connection status : 显示 SSC 辅助服务器是否已连接
Last log page received (log id, page) : 最近接收的日志页面
Next log page to read (log id,page) : 要读取的下一个日志页的序号
Last LSN acked (log id,pos) : 最近应答的 LSN
Sequence number of last buffer received : 接收的上一个缓冲区的序号
Sequence number of last buffer acked : 应答的上一个缓冲区的序号
Current paging file : 当前 GBase_8s paging 文件的名称
Current paging file size : 当前 GBase_8s paging 文件的大小
Old paging file : 上一个 GBase_8s paging 文件的名称
Old paging file size : 上一个 GBase_8s paging 文件的大小
onstat -g seg 命令:打印共享内存段的统计信息
可以使用 onstat -g seg 命令显示共享内存段的统计信息。
该命令显示附加了多少段以及它们的大小。您可以在转储文件(创建时不包含缓冲池)中运行 onstat -g seg命令。
语法:
示例输出
图: onstat -g seg 命令输出
输出描述
id: 共享内存分段 ID
key: 与共享内存分段 ID 相关联的共享内存键
addr: 共享内存分段地址
size: 共享内存分段大小(字节)
ovhd: 共享内存分段控制信息(开销)大小(字节)
class: 共享内存的类型(B 代表共享内存池、V 代表虚拟、VX 代表虚拟扩展、M 代表消息)
blkused: 已使用内存的 block 数
blkfree: 空闲内存的 block 数
Virtual segment low memory reserve (bytes): 当需要必要活动且服务器限制了可用内存时,供使用的保留内存的大小(以字节表示)(可在 LOW_MEMORY_RESERVE 配置参数中指定保留内存)
Low memory reserve used 0 times and used maximum block size 0 bytes: 服务器使用保留内存的次数和最大的必需内存
onstat -g ses 命令:打印与会话有关的信息
可以使用 onstat -g ses 命令显示会话的信息。
缺省情况下,只有 DBSA 可以查看 onstat -g ses 信息。然而,当 UNSECURE_ONSTAT 配置参数设置为 1 时,所有的用户都可以查看该信息。
语法:

可以指定以下调用之一。
onstat -g ses : 显示每个会话的单行摘要
onstat -g ses sessionid : 显示特定会话的信息
所有会话的示例输出
图: onstat -g ses 命令输出
session #RSAM total used dynamic
id user tty pid hostname threads memory memory explain
24 gbasedbt - 0 - 0 12288 7936 off
23 gbasedbt - 17602 carson 1 57344 48968 off
3 gbasedbt - 0 - 0 12288 9168 off
2 gbasedbt - 0 - 0 12288 7936 off
特定会话的示例输出
图: onstat -g sessessionid 命令输出
session effective #RSAM total used dynamic
id user user tty pid hostname threads memory memory explain
53 gbasedbt - 36 18638 apollo11 1 73728 63048 off
Program :
/usr/gbasedbt/bin/dbaccess
tid name rstcb flags curstk status
77 sqlexec 4636ba20 Y--P--- 4240 cond wait sm_read -
Memory pools count 1
name class addr totalsize freesize #allocfrag #freefrag
53 V 4841d040 73728 10680 84 6
name free used name free used
overhead 0 3288 scb 0 144
opentable 0 2904 filetable 0 592
log 0 16536 temprec 0 2208
gentcb 0 1656 ostcb 0 2920
sqscb 0 21296 sql 0 72
hashfiletab 0 552 osenv 0 2848
sqtcb 0 7640 fragman 0 392
sqscb info
scb sqscb optofc pdqpriority optcompind directives
481b70a0 483e2028 0 0 0 1
Sess SQL Current Iso Lock SQL ISAM F.E.
Id Stmt type Database Lvl Mode ERR ERR Vers Explain
53 - sysmaster CR Not Wait 0 0 9.24 Off
Last parsed SQL statement :
Database 'sysmaster@lx1'
Xadatasources participated in this session :
Xadatasource name RMID Active
xabasicdb@atmol10:sitaramv.xads_t3_i1 6 YES
xabasicdb@atmol10:sitaramv.xads_t2_i1 4 YES
xabasicdb@atmol10:sitaramv.xads_t1_i3 3 YES
xabasicdb@atmol10:sitaramv.xads_t1_i2 2 YES
xabasicdb@atmol10:sitaramv.xads_t1_i1 1 YES
xabasicdb@atmol10:sitaramv.xads_t2_i2 5 NO
DRDA client info
Userid:
Wrkstnname: nemea
Applname: db2jcc_application
Acctng: JCC03510nemea
Programid:
Autocommit:
Packagepath:
输出描述:session 部分
Session id: 会话 ID
user: 启动该会话的用户名
tty: 与此会话的前端关联的 tty
pid: 与此会话的前端关联的进程 ID
hostname: 此会话已连接的主机名
#RSAM threads: 为此会话分配的 RSAM 线程的数量
total memory: 为此会话分配的内存量
used memory: 此会话实际使用的内存量
dynamic explain: 生成会话的 SQL 语句的说明输出(on 或 off)
输出描述:program 部分
显示在您的会话中使用的客户端程序的完整路径。使用客户端程序信息来监视或停止访问数据库。
输出描述:threads 部分
尽管该部分没有标题,但是以下输出显示有关线程的信息。
tid: 线程 ID
name: 线程的名称
rstcb: RSAM 控制 block
flags: 使用以下代码描述线程的状态:
位置 1
B
正在等待缓冲区
C
正在等待 checkpoint
G
正在等待逻辑日志缓冲区写入
L
正在等待锁定
S
正在等待互斥
T
正在等待事务
X
正在等待事务清除
Y
正在等待条件
位置 2
*
此位置中的星号表示线程在事务中遇到 I/O 失败
位置 3
A
归档线程
B
开始工作
P
开始准备或已准备好工作
X
XA 已准备好
C
正在提交或已提交
R
正在异常终止或已异常终止
H
尝试异常终止或尝试回滚
位置 4
P
主线程
位置 5
R
正在读取
X
临界区
位置 6
R
恢复线程
位置 7
M
监视线程
D
守护线程
C
清除程序
F
清空程序
B
B-tree 扫描程序
curstk: 当前堆栈大小
status: 当前线程状态
输出描述: memory pools 头部分
每个会话池重复这些信息。
name: 池名称
class: 池所分配位置的内存类。R 代表常驻、V 代表虚拟、M 代表消息
addr: 池结构的地址
totalsize: 池获得的内存的总的大小,以字节表示
freesize: 在池中的可用字节数量
#allocfrag: 在池中已分配内存分片的数量
#freefrag: 在池中的可用分片数量
输出描述:Memory pools 部分
name: 已经从池中分配内存的组件的名称
free: 释放的字节数量
used: 分配的字节数量
输出描述:sqscb info 部分
scb: 会话控制 block。这是共享内存中主会话结构的地址
sqscb: 会话的 SQL 级别控制 block
optofc: OPTOFC 环境变量或 ONCONFIG 配置文件设置的当前值
pdqpriority: PDQPRIORITY 环境变量或 ONCONFIG 配置文件设置的当前值
optcompind: OPTCOMPIND 环境变量或 ONCONFIG 配置文件设置的当前值
directives: DIRECTIVES 环境变量或 ONCONFIG 配置文件设置的当前值
输出描述:SQL 部分
显示特定会话的 SQL 信息。该部分具有和 onstat -g sql 命令相同的信息。请参阅 onstat -g sql 命令:打印与 SQL 有关的会话信息。
输出描述:Last parsed SQL statement 部分
Last parsed SQL statement 部分具有和 onstat -g sql 命令相同的信息。请参阅 onstat -g sql 命令:打印与 SQL 有关的会话信息。
输出描述:Xadatasources participated in this session 部分
Xadatasources participated in this session 部分显示有关在会话期间可用的 XA 数据源的信息。它们的资源管理器标识,以及它们当前是否是活动的。
Xdatasource name: 参与会话的 XA 数据源
RMID: 对应的 XA 数据源的资源管理器的标识
Active: XA 数据源是否依然是活动的
输出描述:DRDA client info 部分
DRDA client info 显示连接客户端的分布式关系数据库体系结构(DRDA) 的信息。
Userid: 客户端用户的用户 ID
Wrkstnname: 客户端工作站名称
Applname: 客户端应用程序名称,例如:db2jcc_application
Acctng: 来自客户端的审计字符串,例如:JCC03510nemea
Programid: 客户端程序标识( GBase 8s 没有使用)
Autocommit: GBase 8s 数据源缺省的事务自动提交方式
Packagepath: 客户端包装路径( GBase 8s 没有使用)
onstat -g shard 命令:打印有关分片高速缓存的信息
可以使用 onstat -g shard 命令显示有关分片高速缓存的信息。
语法:

示例 1:使用基于散列分片的分片定义的输出
对于本示例,使用以下命令创建一个分片定义:

以下示例显示了当 onstat -g shard 命令在 g_shard_server_A 、g_shard_server_B 、g_shard_server_C 或 g_shard_server_D 上运行的输出。
图: 使用哈希算法将数据分布到多个数据库服务器的分片定义的 onstat -g shard 命令的输出。
GBase 8s Database Server Version 8.8 -- On-Line -- Up 00:00:20 -- 162316 Kbytes
collection_1 database_1:josh.customers_1 key:column_2 HASH:DELETE SHARD OPTIMIZATION:ENABLED
Matching for delete:column_3
g_shard_server_A (65545) mod(ifx_checksum(column_2::LVARCHAR, 0), 4) = 0
g_shard_server_B (65546) mod(ifx_checksum(column_2::LVARCHAR, 0), 4) in (1, -1)
g_shard_server_C (65547) mod(ifx_checksum(column_2::LVARCHAR, 0), 4) in (2, -2)
g_shard_server_D (65548) mod(ifx_checksum(column_2::LVARCHAR, 0), 4) in (3, -3)
示例 1 的输出描述
Sharding definition name: 分片定义的名称。在此示例中该值为 collection_1
Database name: 包含分布在多个分片的集合或表的数据库的名称。在此示例中该值为 database_1
Table owner name: 分布在多个分片的集合或表的所有者名称。在此示例中该值为 josh
Table name: 分布在多个分片的集合或表的名称。在此示例中该值为 customers_1
Shard key: 分片键用于分配行或文档。值可以是表的一个列、文档字段或一个表达式。在此示例中该值为 column_2
Sharding strategy: 确定新行或文档存储在哪个数据库服务器的方法。值可以是 HASH (哈希算法)或 EXPRESSION(表达式)。在此示例中该值为 HASH
Sharding type: 在行或文档复制到目标服务器后指定源服务器的动作。值可以是 DELETE 、KEEP 或 INFORMATIONAL 。 在此示例中该值为 DELETE
Shard optimization: 指定查询是否可以跳过不包含相关数据的分片服务器。值可以是 ENABLED 或 NOT ENABLED 。在此示例中该值为 ENABLED
Version column: 指定 Enterprise Replication 尝试验证源行或源文件没有被更新时使用的列或键。值可以是一列或文档字段。 在此示例中该值为 column_3
Sharding rule: 复制数据到指定的数据库服务器的规则。在上一示例中,g_shard_server_A (服务器编号 65545)基于该规则来发送数据:
mod(ifx_checksum(col2::LVARCHAR,0),4)=0
示例 2:使用基于分片表达式的分片定义的输出
对于本示例,使用以下命令创建一个分片定义:

以下示例显示了运行在 g_shard_server_F 、g_shard_server_G 、g_shard_server_H 或 g_shard_server_I 上的 onstat -g shard 命令的输出。
图: 使用一个表达式将数据分布到多个数据库服务器的分片定义的 onstat -g shard 命令的输出。
GBase 8s Database Server Version 8.8.U -- On-Line -- Up 00:19:07 -- 162316 Kbytes
collection_2 database_2:john.customers_2 key:state EXPRESSION:KEEP SHARD OPTIMIZATION:ENABLED
Matching for delete:version_column
g_shard_server_F (65564) state IN ('AL','MS','GA')
g_shard_server_G (65565) state IN ('TX','OK','NM')
g_shard_server_H (65566) state IN ('NY','NJ')
g_shard_server_I (65567) not ((state IN ('AL','MS','GA')) or (state IN('TX','OK','NM'))
or (state IN ('NY','NJ')))
示例 2 的输出描述
Sharding definition name: 分片定义的名称。在此示例中该值为 collection_2
Database name: 包含分布在多个分片的集合和表的数据库的名称。在此示例中该值为 database_2
Table owner name: 分布在多个分片的集合或表的所有者名称。在此示例中该值为 john
Table name: 分布在多个分片的集合或表的名称。在此示例中该值为 customers_2
Shard key: 分片键用于分配行或文档。值可以是表的一个列、文档字段或一个表达式。在此示例中该值为 state
Sharding strategy: 确定新行或文档存储在哪个数据库服务器的方法。值可以是 HASH (哈希算法)或 EXPRESSION(表达式)。在此示例中该值为 EXPRESSION
Sharding type: 在行或文档复制到目标服务器后指定源服务器的动作。值可以是 DELETE 、KEEP 或 INFORMATIONAL 。 在此示例中该值为 KEEP
Shard optimization: 指定查询是否可以跳过不包含相关数据的分片服务器。值可以是 ENABLED 或 NOT ENABLED 。在此示例中该值为 ENABLED
Version column: 指定 Enterprise Replication 尝试验证源行或源文件没有被更新时使用的列或键。值可以是一列或文档字段。 在此示例中该值为 version_column
Sharding rule: 复制数据到指定的分片的规则。在本示例中 g_shard_server_F(服务器编号为 65564 )基于该规则接收数据:
state in ('AL','MS','GA')
g_shard_server_I(服务器编号为 65567) 基于该规则接收数据:
not ((state in ('AL','MS','GA'))
or (state in ('TX','OK','NM'))
or (state in ('NY','NJ')))
示例 3:使用 BSON 分片键和基于分片表达式的分片定义的输出
对于本示例,使用以下命令创建一个分片定义:

以下示例显示运行在 shard_server_J 、shard_server_K 、shard_server_L 或 shard_server_M 上的 onstat -g shard 命令的输出。
图: 使用 BSON 分片键和表达式将数据分布到多个数据库服务器的分片定义的 onstat -g shard 的命令的输出。
GBase 8s Database Server Version 8.8 -- On-Line -- Up 01:34:01 -- 354721 Kbytes
collection_3 database_3:susan.customers_3 key:bson_value_lvarchar(data,'age')
EXPRESSION:DELETE SHARD OPTIMIZATION:ENABLED
Matching for delete:version
g_shard_server_J (65568) bson_value_lvarchar(data,'age') BETWEEN 0 and 20"
g_shard_server_K (65569) bson_value_lvarchar(data,'age') BETWEEN 21 and 62"
g_shard_server_L (65570) bson_value_lvarchar(data,'age')BETWEEN 63 and 100"
g_shard_server_M (65571) not((bson_value_lvarchar(data,'age') BETWEEN 0 and 20)
or (bson_value_lvarchar(data,'age') BETWEEN 21 and 62) or (bson_value_lvarchar
(data,'age') BETWEEN 63 and 100))
示例 3 的输出描述
Sharding definition name:分片定义的名称。在此示例中的该值为 collection_3
Database name: 包含分布在多个分片的集合或表的数据库的名称。在此示例中该值为 database_3
Table owner name: 分布在多个分片的集合或表的所有者名称。在此示例中该值为 susan
Table name: 分布在多个分片的集合或表的名称。在此示例中该值为 customers_3
Shard key: 分片键用于分配行或文档。值可以是表的一个列、文档字段或一个表达式。在此示例中该值为查询 BSON age 键作为该分片键的表达式 bson_value_lvarchar(data,'age')
Sharding strategy: 确定新行或文档存储在哪个数据库服务器的方法。值可以是 HASH (哈希算法)或 EXPRESSION(表达式)。在此示例中该值为 EXPRESSION
Sharding type: 在行或文档复制到目标服务器后指定源服务器的动作。值可以是 DELETE 、KEEP 或 INFORMATIONAL 。 在此示例中该值为 DELETE
Shard optimization: 指定查询是否可以跳过不包含相关数据的分片服务器。值可以是 ENABLED 或 NOT ENABLED 。在此示例中该值为 ENABLED
Version column: 指定 Enterprise Replication 尝试验证源行或源文件没有被更新时使用的列或键。值可以是一列或文档字段。 在此示例中该值为 version
Sharding rule: 复制数据到指定的分片的规则。在本示例中 g_shard_server_J(服务器编号为 65568)基于该规则接收数据:
bson_value_lvarchar(data,'age') BETWEEN 0 and 20
g_shard_server_M(服务器编号为 65571) 基于该规则接收数据:
not((bson_value_lvarchar(data,'age') BETWEEN 0 and 20)
or (bson_value_lvarchar(data,'age') BETWEEN 21 and 62)
or (bson_value_lvarchar(data,'age') BETWEEN 63 and 100))
onstat -g sle 命令:打印所有休眠的线程
可以使用 onstat -g sle 命令打印所有休眠的线程。
语法:

示例输出
图: onstat -g sle 命令输出
onstat -g smb 命令:打印 sbspace 信息
可以使用 onstat -g smb 命令显示有关 sbspace 的详细信息。
语法:
| 命令 | 解释 |
|---|---|
| onstat -g smb c | 列出 sbspace 中的所有的 chunk |
| onstat -g smb e | 列出所有智能大对象表类型的条目 |
| onstat -g smb e cad | 列出智能大对象 chunk 头表条目 |
| onstat -g smb e fdd | 列出智能大对象文件描述符条目 |
| onstat -g smb e lod | 列出智能大对象头表中的条目 |
| onstat -g smb fdd | 列出智能大对象文件描述符 |
| onstat -g smb h | 列出所有智能大对象表类型头 |
| onstat -g smb h cad | 列出智能大对象 chunk 头表头 |
| onstat -g smb h fdd | 列出智能大对象文件描述符表头 |
| onstat -g smb h lod | 列出智能大对象文头表的表头 |
| onstat -g smb lod | 列出在智能大对象头表中的头和条目 |
| onstat -g smb s | 列出 sbspace 属性(所有者、名称、页大小、-Df 标识设置)Sbspace 创建过程中不初始化值为 0 或 -1 的字段 |
onstat -g smb c 命令的示例输出
使用 onstat -g smb c 命令监视每个 sbspace chunk 中的可用空间量,以及用户数据、元数据和保留区域以页面为单位的大小。onstat -g smb c 命令显示每个 sbspace chunk 的以下信息:
- Chunk 编号和 sbspace 名称
- Chunk 大小和路径名
- 总用户数据页和可用的用户数据页
- 在每个用户数据和元数据区域中的页面的位置和数据
在以下示例中,sbspace 的 chunk 2 具有 2253 个源可用页(orig fr) 2253 个用户页(usr pgs)和 2245 个可用页(free pg)。对于第一个用户数据区域 (Ud1),起始页面偏移量为 53 ,页面数量为 1126。对于元数据区域(Md),起始页的偏移量为1179 ,页面数量为 194。 对于第二个用户数据区域(Ud2),起始页的偏移量为 1373 ,页面数量为 1127 。

onstat -g smb s 命令的输出
onstat -g smb s 命令显示系统中的所有 sbspace 的存储属性:
- sbspace 名称、标志、所有者
- 日志记录状态
- 平均智能大对象大小
- 第一个 extent 大小、下一个 extent 大小和最小 extent 大小
- 最大 I/O 访问时间
- 锁定方式
onstat -g smx 命令:打印多路复用器组信息
可以使用 onstat -g smx 命令显示有关使用 SMX 服务器的多路复用器组信息。
语法:
| 命令 | 解释 |
|---|---|
| onstat -g smx | 显示 SMX 连接的统计信息 |
| onstat -g smx ses | 显示 SMX 会话的统计信息 |
示例输出
图: onstat -g smx 命令输出
SMX connection statistics:
SMX control block: 0x47d5e028
Peer server name: lx1
SMX connection address: 0x47d60d10
Encryption status: Disabled
Total bytes sent: 27055
Total bytes received: 2006989
Total buffers sent: 782
Total buffers received: 7090
Total write calls: 782
Total read calls: 7090
Total retries for write call: 0
Data compression level: 1
Data sent: compressed 40760 bytes by 33%
Data received: compressed 12579324 bytes by 84%
输出描述
SMX control block : SMX 控制 block
Peer server name : 显示同级服务器的名称
SMX connection address : 显示 SMX 连接地址的信息
Encryption status : 显示是否已启用或禁用加密
Total bytes sent : 显示已发送的字节总数
Total bytes received : 显示已接收的字节总数
Total buffers sent : 显示已发送的缓冲区总数
Total buffers received : 显示已接收的缓冲区总数
Total write calls : 显示写入调用的总数
Total read calls : 显示读取调用的总数
Total retries for write call : 显示写入调用的重试总数
Data compression level : 显示由 SMX_COMPRESS 配置参数设置的 SMX 压缩级别
Data sent: compressed x bytes by y% : 显示已发送的数据的已解压的字节数和压缩率
Data received: compressed x bytes by y% : 显示已接收的数据的已解压的字节数和压缩率
示例输出
图: onstat -g smx ses 输出
SMX session statistics:
SMX control block: 0x17c69028
Peer SMX session client reads writes
name address type
delhi_sec 19022050 smx Clone Send 6 183
输出描述
SMX control block: SMX 控制 block
Peer name: 显示同级别的服务器名称
SMX session address: SMX 会话地址
Client type: 显示辅助服务器的类型
reads: 显示会话读取的总数
writes: 显示会话写入的总数
onstat -g spi 命令:打印使用长自旋的自旋锁
可以使用 onstat -g spi 命令显示有关使用长自旋的自旋锁的信息。
语法:

服务器中的许多资源由两个或更多的线程访问。在一些访问(诸如更新共享值)中,服务器必须确保每次只有一个线程在访问该资源。spin lock 是用来为一些资源提供互斥存取的机制。有了这类锁,在第一次尝试时由于另一个线程占用锁而没有成功获取锁的线程重复尝试获取锁,直至成功为止。
自旋锁的成本很低,而且自旋锁通常用于在短期内获取互斥的资源。然而,如果自旋锁被高度使用,那么循环重试机可能会变得更贵。
onstat -g spi 命令对于帮助识别由于高度使用自旋锁而形成的性能瓶颈很有帮助。该选项列出了带有等待的自旋锁,在线程第一次尝试时没有成功为其获取锁而循环重试的自旋锁。
示例输出
图: onstat -g spi 命令输出
输出描述
Num Waits (decimal): 为该自旋锁等待的线程总数
Num Loops (decimal): 在线程成功获取自旋锁前的尝试总数
Avg Loop/Wait (floating point): 用来获取自旋锁的尝试的平均数。以 Num Loops / Num Waits 计算
Name (string): 使用以下代码命名自旋锁:
lockfr: 锁可用列表。lockfr 后的数字是锁可用列表数组中的索引。
lockhash[]: 锁哈希桶。方括号内的字段是该锁哈希桶存储数组的索引
:bhash []: 缓冲区哈希桶。冒号之前的字段是缓冲池的索引;方括号内在 bhash 之后的字段是该缓冲区哈希桶数组的索引
:lru-: LRU latch 。冒号之前的字段是缓冲池的索引;lru- 之后的字段标识缓冲区链对正在被使用
:bf: 缓冲区 latch 。冒号之前的字段是缓冲池的索引;方括号内 bf 后的字段是该缓冲区数组的位置。接下来的两个字段分别是以十六进制表示的缓冲区内存的分区号和页头地址
onstat -g sql 命令:打印与 SQL 有关的会话信息
可以使用 onstat -g sql 命令显示有关会话的 SQL 相关信息。
缺省情况下,只有 DBSA 可以查看 onstat -g sql syssqltrace 信息。然而当 UNSECURE_ONSTAT 配置参数设置为 1 时,所有的用户都可以查看该信息。
语法:

可以指定以下调用之一。
调用
解释
**onstat -g sql:**显示每个会话的单行摘要
**onstat -g sqlsessionid:**显示特定会话的 SQL 信息
不显示加密函数中的加密密码和密码提示参数。下图显示了在 Last parsed SQL statement 字段显示加密密码。
图: onstat -g sql 命令输出

输出描述
Sess id: 会话标识
SQL Stmt type: SQL 语句类型
Current Database: 会话的当前数据库的名称
ISO Lvl: 隔离级别
DR
Dirty 读取
CR
已提交读取
CS
游标锁定
DRU
Dirty 读取,保留更新锁
CRU
已提交读取,保留更新锁
CSU
游标锁定,保留更新锁
LC
已提交读取,最后提交
LCU
已提交读取,最后提交,保留更新锁
RR
可重复的读取
NL
没有事务的数据库
Lock mode
当前会话的锁定方式
SQL Error
当前语句遇到的 SQL 错误号
ISAM Error
当前语句遇到的 ISAM 错误号
F.E. Version
当前客户端程序使用的 SQLI 协议的版本
Explain
SET EXPLAIN 设置
Current Role
当前用户的角色
onstat -g spf 命令:打印已就绪语句的概要文件
可以使用 onstat -g spf 命令显示有关 SQL 查询的当前统计信息。
可以使用该统计信息确定每条语句的成本。
语法:
如果启用了 SQL 跟踪,该信息显示的是由此语句完成的工作的快照并且它可能随着语句继续运行而改变。例如:要监视一条活动的语句中缓冲区读或写的增长率,可以在 2 秒的间隔中发起三个 onstat -g spf 运行。
如果禁用了 SQL 跟踪,那么 "Statistics disabled" 会声明一个警告消息:
示例输出
图: onstat -g spf 命令输出

输出描述
sid: 会话 ID
sdb: 该语句指针的后 8 位数字
tottm: 以秒表示所有语句当前运行的总时间
execs: 已运行完成的语句的当前数量。该值不包含正在运行的语句。
runtm: 以秒表示该语句当前的运行时间
pdq: 当前并发数据库查询(PDQ)优先级别。 PDQ 优先值可以是 0 到 100 之间的任意整数。
scans: 当前已分配的 PDQ 扫描的数量
sorts: 当前已完成排序的数量
bfrd: 当前的缓冲区读取数
pgrd: 当前的页读取数
bfwrt: 当前的缓冲区写入数
pgwrt: 当前的页写入数
lkrqs: 当前的锁请求数
lkwts: 当前的锁等待数
onstat -g src 命令:共享内存中的模式
可以使用 onstat -g src 命令搜索共享内存中的模式。
语法:

示例输出
以下示例显示了 onstat -g srcpattern mask 命令的输出,这里 pattern = 0x123 而 mask = 0xffff 。
图: onstat -g src 命令输出
Search Summary:
addr contents
000000000ad17a50: 01090000 00000000 00000000 00000123 ........ .......#
000000000ad7dec0: 00000001 014e3a0c 00000000 0ade0123 .....N:. .......#
输出描述
addr (hexadecimal): 找到搜索模式的共享内存地址
contents (hexadecimal): 给出地址上的内存内容
onstat -g ssc 命令:打印出现的 SQL 语句
可以使用 onstat -g ssc 命令监视数据库服务器读取高速缓存中的 SQL 语句的次数。
缺省情况下,只有 DBSA 可以查看 onstat -g ssc syssqltrace 信息。然而当 UNSECURE_ONSTAT 配置参数设置为 1 时,所有的用户都可以查看该信息。
语法;
all 选项报告 key-only 高速缓存的条目和完全高速缓存的语句 。如果 hits 列中的值比 STMT_CACHE_HITS 值小,该条目是 key-only 高速缓存条目。
pool 选项报告该 SQL 语句高速缓存的所有内存池的用法。该输出显示内存池的名称、类型、地址和总大小的信息。
示例输出
图: onstat -g ssc 命令输出
Statement Cache Summary:
#lrus currsize maxsize Poolsize #hits nolimit
4 117640 524288 139264 0 1
Statement Cache Entries:
lru hash ref_cnt hits flag heap_ptr database user
----------------------------------------------------------------
0 262 0 7 -F aad8038 sscsi007 admin
INSERT INTO ssc1 ( t1_char , t1_short , t1_key , t1_float , t1_smallfloat
, t1_decimal , t1_serial ) VALUES ( ? , ? , ? , ? , ? , ? , ? )
0 127 0 9 -F b321438 sscsi007 admin
INSERT INTO ssc2 ( t2_char , t2_key , t2_short ) VALUES ( ? , ? , ? )
1 134 0 15 -F aae0c38 sscsi007 admin
SELECT t1_char , t1_short , t1_key , t1_float , t1_smallfloat ,
t1_decimal , t1_serial FROM ssc1 WHERE t1_key = ?
1 143 0 3 -F b322c38 sscsi007 admin
INSERT INTO ssc1 ( t1_char , t1_key , t1_short ) SELECT t2_char , t2_key
+ ? , t2_short FROM ssc2
2 93 0 7 -F aae9838 sscsi007 admin
DELETE FROM ssc1 WHERE t1_key = ?
2 276 0 7 -F aaefc38 sscsi007 admin
SELECT count ( * ) FROM ssc1
2 240 1 7 -F b332838 sscsi007 admin
SELECT COUNT ( * ) FROM ssc1 WHERE t1_char = ? AND t1_key = ? AND
t1_short = ?
3 31 0 7 -F aaec038 sscsi007 admin
SELECT count ( * ) FROM ssc1 WHERE t1_key = ?
3 45 0 1 -F b31e438 sscsi007 admin
DELETE FROM ssc1
3 116 0 0 -F b362038 sscsi007 admin
SELECT COUNT ( * ) FROM ssc1
Total number of entries: 10.
输出描述 - Statement Cache Summary 部分
#lrus : 最近最少使用的队列(LRUS)的次数
currsize : 当前高速缓存的大小
maxsize : 总高速缓存内存量限制
Poolsize : 总的池大小
#hits : 在插入前的命中的数量。这个数量等于 STMT_CACHE_HITS 配置参数的值r
nolimit : STMT_CACHE_NOLIMIT 配置参数的值
输出描述 - Statement Cache Entries 部分
Statement Cache Entries 部分显示已全部插入高速缓存的条目。
lru: 高速缓存条目所属的 lru 队列的索引
hash: 高速缓存条目的哈希值
ref_count: 引用语句的线程的数量
hits: 语句与高速缓存中的语句匹配的次数。匹配可用于 key-only 或完全高速缓存的条目
flag: 高速缓存条目标志;-F 说明语句是完全高速缓存的;-D 说明语句已删除
heap_ptr: 高速缓存条目的内存堆的地址
onstat -g stk 命令:打印线程堆栈
可以使用 onstat -g stk tid 命令显示由线程 ID 指定的线程堆栈。
所有的平台都不支持该选项,并且该选项并非一直精确。
语法:

示例输出
图: onstat -g stk tid 命令输出
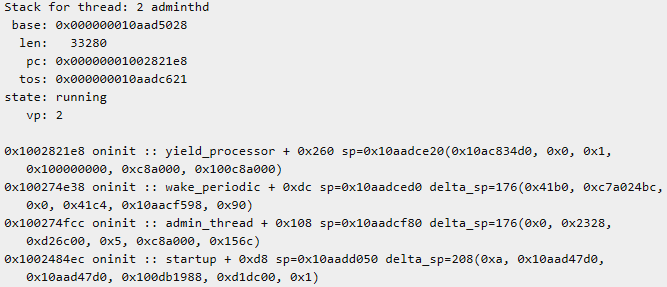
onstat -g stm 命令:打印 SQL 语句的内存使用
可以使用 onstat -g stm 命令显示每个准备好的 SQL 语句所使用的内存。
缺省情况下,只有 DBSA 可以查看 onstat -g stm syssqltrace 信息。然而,当 UNSECURE_ONSTAT 配置参数设置为 1 时,所有的用户都可以查看此信息。
语法:
要只显示一个会话的内存,请在 onstat -g stm 命令中指定会话 ID。
示例输出
图: onstat -g stm 命令输出

输出描述
sdblock : 语句描述符 block 的地址
heapsz : 语句内存堆的大小
statement : 查询文本
onstat -g stq 命令:打印队列信息
可以使用 onstat -g stq 命令显示有关队列的信息。
语法:
要查看特定的会话信息,请指定 session 选项。要查看所有的会话信息,请不要指定 session 选项。
示例输出
图: onstat -g stq 命令输出

输出描述
session : 会话 ID
cnt : 流队列缓冲区的数量
waiters : 正在等待流队列缓冲区的线程数量
onstat -g sts 命令:打印每个线程的堆栈用途
可以使用 onstat -g sts 命令显示有关每个线程的最大和当前堆栈使用的信息。
语法:
示例输出
图: onstat -g sts 命令输出
Stack usage:
TID Total Max Current Thread Name
bytes % bytes %
2 32768 3124 9 3079 9 adminthd
3 32768 2870 8 2871 8 childthd
5 32768 14871 45 2871 8 Cosvr Avail Mgr
6 32768 2870 8 2871 8 dfm_svc
7 131072 3190 2 3191 2 xmf_svc
9 32768 3126 9 3127 9 xtm_svcc
10 32768 3580 10 3335 10 xtm_svcp
11 32768 3238 9 3239 9 cfgmgr_svc
12 32768 6484 19 2871 8 lio vp 0
14 32768 6484 19 2871 8 pio vp 0
16 32768 6484 19 2871 8 aio vp 0
18 131072 10391 7 2871 2 msc vp 0
20 32768 4964 15 2871 8 fifo vp 0
22 32768 4964 15 2871 8 fifo vp 1
24 32768 6028 18 2871 8 aio vp 1
26 32768 5444 16 2951 9 dfmxpl_svc
27 32768 2886 8 2887 8 sch_svc
28 32768 7812 23 5015 15 rqm_svc
29 32768 7140 21 3079 9 sm_poll
30 32768 11828 36 6439 19 sm_listen
31 32768 2870 8 2871 8 sm_discon
32 32768 14487 44 4055 12 main_loop()
33 32768 4272 13 2903 8 flush_sub(0)
34 32768 2902 8 2903 8 flush_sub(1)
35 32768 2870 8 2871 8 btscanner 0
36 32768 3238 9 3239 9 aslogflush
37 32768 3055 9 2887 8 bum_local
38 32768 3238 9 3239 9 bum_rcv
39 32768 4902 14 4903 14 onmode_mon
42 32768 4964 15 2871 8 lio vp 1
44 32768 5136 15 2871 8 pio vp 1
onstat -g sym 命令:打印 oninit 命令的符号表信息
可以使用 onstat -g sym 命令显示 oninit 命令符号表的信息。
语法:

示例输出
图: onstat -g sym 命令输出
以下示例显示了该输出的前几行:

输出描述
onstat -g sym 命令显示 oninit 命令中符号的相对内存地址和名称(函数和变量)。
onstat -g tpf 命令:打印线程概要文件
可以使用 onstat -g tpf 命令显示线程概要文件。
语法:
要打印指定线程的概要文件,请指定 tid 线程 ID 。将 tid 设置为 0 来显示所有线程的概要文件。
示例输出
图: onstat -g tpf 命令输出
onstat -g tpf 945
Thread profiles
tid lkreqs lkw dl to lgrs isrd iswr isrw isdl isct isrb lx bfr bfw lsus lsmx seq
945 1969 0 0 0 6181 1782 2069 13 0 0 0 0 16183 7348 743580 0 6
输出描述
tid : 线程 ID
lkreqs : 锁请求数
lkw : 锁等待数
dl : 死锁数
to : 远程死锁超时
lgrs : 日志记录
isrd : 读取数
iswr : 写入数
isrw : 重新写入数
isdl : 删除数
isct : 提交数
isrb : 回滚数
lx : 长事务
bfr : 缓冲区读取数
bfw : 缓冲区写入数
lsus : 当前使用的日志空间
lsmx : 使用的最大日志空间
seq : 顺序扫描数
onstat -g ufr 命令:打印内存池片分片
可以使用 onstat -g ufr 命令显示当前在特定的内存池中使用的分片列表。
该命令需要一个附加的参数来指定池名或要显示池的会话 ID 。每个会话都会分配一个与其会话 ID 名称相同的内存池。使用 onstat -g mem 命令标识池名,使用 onstat -g ses 命令标识会话 ID 。
语法:
内存池分为很多分片用于不同的用途。使用 onstat -g ufr 命令时,有可能会看到这些分片的列表,显示其各自大小(以字节为单位)和所包含的信息类型。提供的信息大多由 Technical Support 使用以写出其分析报告的问题。
指定池名的示例输出
图: onstat -g ufr global 指定池名的命令输出

指定会话 ID 的示例输出
以下示例显示会话 ID 6 的输出。
图: onstat -g ufr 指定会话 ID 的命令输出
Memory usage for pool name 6:
size memid
3256 overhead
144 scb
2968 ostcb
18896 sqscb
3312 opentable
72 sql
808 filetable
352 fragman
552 hashfiletab
1584 gentcb
12096 log
2960 sqtcb
2928 osenv
720 keys
224 rdahead
16248 temprec
输出描述
size (decimal): 池分片大小(以字节为单位)
memid (string): 池分片的名称
onstat -g vpcache 命令:打印 CPU 虚拟处理器专用内存高速缓存的统计信息
可以使用 onstat -g vpcache 命令显示有关 CPU 虚拟处理器专用内存高速缓存的统计信息。
语法:

示例输出
每个 CPU 虚拟处理器的输出都有相同的格式。以下示例显示了一个 CPU 虚拟处理器的输出。
图: onstat -g vpcache 命令输出
输出描述
vpid: CPU 虚拟处理器的 ID
pid: 操作系统分配的 CPU 虚拟处理器的进程 ID
Blocks held: 4096 字节 block 数是专用内存高速缓存中可用的数量
Hit percentage: 发生请求时 block 可用的时间百分比
Free cache: Block 被释放以供重复使用而不被排出的时间百分比
Current VP total allocations from cache: 从高速缓存获取一个 block 或一组 block 的次数
Total frees: 一个 block 或一组 block 被添加至高速缓存的次数
size: 内存 block 的大小,以 4096 字节 block 为单位
cur blks: 当前已分配的 4096 字节 block 的数量(是 size 的倍数)
tgt blks: 高速缓存被排出之前该高速缓存条目 block 的目标数
alloc: 请求者接收到该大小 block 的次数
miss: 请求内存 block 时没有可用 block 的次数
free: 内存 block 放入高速缓存中的次数
drain: 将到期的 block 强制调出,为其他 block 让出空间的次数
draintime: 上一次内存 block bin 被排出的时间
onstat -g wai 命令:打印等待队列线程队列
可以使用 onstat -g wai 命令显示当前在等待队列中并没有得到执行的系统上的线程列表。输出按线程 ID 排序。
语法:
示例输出
图: onstat -g wai 命令输出
输出描述
tid (decimal): 线程 ID
tcb (hex): 线程控制 block 的内存地址
rstcb (hex): RSAM 线程控制 block 的内存地址
prty (decimal): 线程优先级。较大的数字代表较高的优先级
status (string): 线程的当前状态
vp- (decimal and string): 上次运行线程的 VP 的虚拟处理器整数 ID 与运行线程的 VP 类的名称连接
name (string): 线程名称
onstat -g wmx 命令:使用等待者打印所有互斥
可以使用 onstat -g wmx 命令显示所有有等待对象的互斥。
语法:
示例输出
图: onstat -g wmx 命令输出

输出描述
mid: 内部互斥标识
addr: 已锁定的互斥的地址
name: 互斥名
holder: 持有该互斥的线程的线程 ID 、0 = 在共享方式下持有读/写互斥
lkcnt: 对于读/写互斥,是当前在共享方式下正在锁定的线程数量。对于重新锁定互斥,是持有该互斥的线程锁定或重新锁定该互斥的次数
waiter: 正在等待该互斥的线程的 ID 列表
waittime: 以秒表示线程正在等待的时间量
onstat -g wst 命令:打印线程的等待统计信息
可以使用 onstat -g wst 命令显示系统中线程的等待统计信息。
WSTATS 配置参数必须设置为 1 来启用等待信息收集。有关更多信息。
语法:
示例输出
Version 8.8 -- On-Line -- Up 18:52:59 -- 78856 Kbytes
name tid state n avg(us) max(us)
msc vp 0 5 ready 6 9 17
msc vp 0 5 run 6 1107 2215
msc vp 0 5 IO Idle 5 2985.9s 1496.1s
main_loo 7 IO Wait 55 6496 16725
main_loo 7 yield time 44929 1.2s 343.1s
main_loo 7 ready 44998 206085 343.1s
main_loo 7 run 44985 5 436
...
sqlexec 63 IO Wait 2 1118 2165
sqlexec 63 other cond 6 34237 204142
sqlexec 63 ready 9 7 16
sqlexec 63 run 7 1.1s 7.7s
输出描述
name (string): 线程名称
tid (decimal): 线程 ID
state (string): 说明在此输出行内等待的线程。如果单个线程在多个不同的状态中等待,那么它可能有多行输出。 state 字段能包含的值有:
chkpt cond: 线程等待 checkpoint 条件
cp mutex: 线程等待 checkpoint 互斥可用
deadlock mutex: 线程等待死锁互斥可用
empty Q: 线程等待队列中的空缓冲区
fork: 线程等待子线程运行
full Q: 线程等待队列上的一个完整的缓冲区
IO Idle: I/O 线程空闲
IO Wait: 线程产生,同时等待 I/O 完成
join wait: 线程等待另一个线程退出
lock mutex: 线程等待锁定互斥可用
lockfree mutex: 线程等待锁释放互斥可用
logflush: 发生逻辑日志清空
log mutex: 线程等待逻辑日志互斥可用
logcopy cond: 线程等待逻辑日志复制互斥可用
logio cond: 线程等待逻辑日志条件
lrus mutex: 线程等待缓冲区 LRU 互斥可用
misc: 现场等待杂项理由
other cond: 线程等待内部条件
other mutex: 线程等待内部系统互斥可用
other yield: 线程等待内部原因
OS read: 线程等待操作系统读请求完成
OS write: 线程等待操作系统写请求完成
ready: 线程已准备好运行
run: 线程已运行
sort io: 线程等待排序 I/O 完成
vp mem sync: 线程等待虚拟处理器同步
yield bufwait: 线程产生,同时等待缓冲区可用
yield 0: 线程产生,但立即超时
yield time: 线程产生超时
yield forever: 线程产生并保持这种方式,直到它被唤醒
n (decimal): 在此状态下等待的线程次数
avg(us) (floating point): 每次等待发生的时候,线程在此状态下等待的平均用户时间。时间的单位为微秒,值后的 s 表示以秒为单位计算用户时间。
max(us) (floating point): 等待发生的时候,线程在此状态下等待的最大用户时间。时间的单位为微秒,值后的 s 表示以秒为单位计算用户时间。
onstat -G 命令:打印 TP/XA 事务信息
可以使用 onstat -G 命令显示关于通过 TP/XA 库生成的全局事务的信息。
语法:
示例输出
图: onstat -G 命令输出

对于紧耦合事务,所有的分支将共用在地址列中显示的相同事务地址。
输出描述
address: 事务地址
flags
位置 1 的标志代码(当前事务状态):
A:用户线程已连接到事务
S:TP/XA 已暂挂事务
C:TP/XA 正在等待回滚
位置 2 的标志代码(事务方式):
T:紧耦合方式(MTS)
L:松耦合方式(缺省方式)
位置 3 的标志代码(事务阶段):
B:开始工作
P:准备好用于提交的分布式查询
X:TP/XA 已准备好提交
C:正在提交或已提交
R:正在回滚或已回滚
H:正在尝试回滚或已回滚
位置 4 的标志代码:
X:XA 数据源全局事务
位置 5 的标志代码(事务类型):
G:全局事务
C:分布式查询协调者
S:分布式查询从属者
B:分布式查询协调者和从属者
M:重定向的全局事务
isol: 事务的隔离级别
timeout: 事务锁定超时
fID: 格式 ID
gtl: 全局事务 ID 长度
bql: 分支限定符长度
data: 指定事务的数据
dbpartnum: 启动事务的数据库 ID
onstat -h 命令:打印缓冲区头哈希链信息
可以使用 onstat -h 命令显示有关缓冲区头哈希链(有时称为“哈希桶”)的信息,用于访问每个信息缓冲池中的页。
语法:
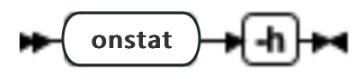
示例输出
输出中显示的信息以链长度的数字柱状图加每个缓冲池的摘要信息显示。输出中的所有数值均为十进制。 哈希链越短,服务器越快能找到请求的缓冲区,因为一般来说,在目标链上查找目标缓冲区所需检查的缓冲区头较少。
在每个缓冲池输出中,最先显示缓冲池页的大小(以字节为单位)。接着显示该缓冲池的柱状图和摘要信息。
图: onstat -h 命令输出

输出描述
Histogram Information on Hash Chains
柱状图信息中有一行用于显示系统中当前存在的每个缓冲区哈希的长度。每一行有两列:
# of chains: 给定长度的哈希链数
of len: 这些链的长度
Summary Information Per Buffer Pool
total chains: 该缓冲池内存在的哈希链数
hashed buffs: 当前哈希到本缓冲池的哈希链中缓冲区头数
total buffs: 该缓冲池中的缓冲区总数
onstat -i 命令: 开始® 交互方式
可以使用 onstat -i 命令将 onstat 命令置于交互方式。
语法:
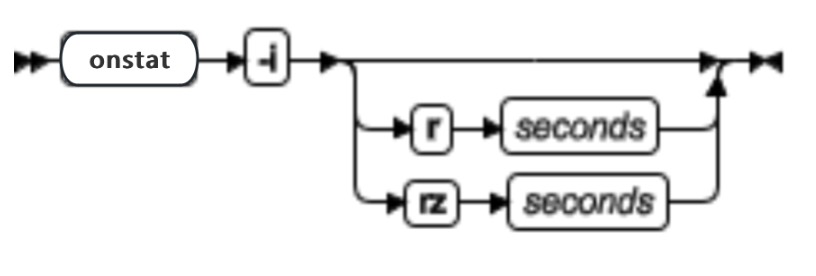
在交互方式中,可以为每个会话输入多个 onstat 选项,但一次只能输入一个。onstat 提示显示并允许您输出选项。
在交互方式中,不要在该选项前加连字符。
其他选项
两个其他选项 onstat r seconds 和 onstat rz seconds 可用于交互方式。onstat r seconds 选项类似于当前的 onstat -r seconds 选项,它重复生成显示。如果管理员在交互方式提示处执行 onstat r seconds ,那么提示更改以反映指定的时间间隔(秒)并重新出现,等待下一命令。在以下示例中,由下一条命令生成的显示每 3 秒重复一次:
onstat> r 3
onstat[3]>
onstat rz seconds 选项使您可以如指定的那样重复下一条命令并在每个执行之间将所有概要文件计数器设置为 0 。
终止交互方式或重复顺序
要终止交互方式,请按 CTRL-d。
要终止重复顺序,请按 CTRL-c。
onstat -k 命令:打印活动的锁信息
可以使用 onstat -k 命令打印活动锁的信息,包括锁表中的该锁的地址。
语法:
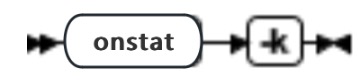
示例输出
可用锁的最大数量由 onconfig 文件中的 LOCKS 配置参数进行指定。
图: onstat -k 命令输出

在以下输出中,最后一行的数字 2 显示的是一个 Enterprise Replication 伪锁:

输出描述
address: 锁表中锁的地址,如果用户线程正在等待该锁,那么锁的地址出现在 onstat -u (用户)输出的 wait 字段中。
wtlist: 是正在等待锁的用户线程(如果有)列表中的第一项
owner: 是正持有锁的线程的共享内存地址
此地址对应于 onstat -u (用户)输出的 address 字段中的地址。当 owner 值显示在括号中时,它代表事务结构的共享内存地址。只有锁是为全局事务而分配时,才会出现这种情况。该地址对应于 onstat -G 的输出的地址字段
lklist: 是刚才列出的所有者所持有的链接列表中的下一个锁
type: 使用以下代码指定锁的类型:
HDR: 头
B: 字节
S: 共享
X: 互斥
I: 意向
U: 更新
IX: 意向—互斥
IS: 意向—共享
SIX: 共享,意向—互斥
tblsnum: 是锁定资源的 tblspace 编号。如果数值小于 10000,那么它表示 Enterprise Replication 伪锁
rowid: 是行标识号
Rowid 提供以下锁的信息:
- 如果 rowid 等于 0 那么该锁为表锁
- 如果 rowid 以两个 0 结束,那么该锁为页锁
- 如果 rowid 为 6 个数字或更少且不以 0 结束,那么该锁很可能是行锁
- 如果 rowid 多于 6 个数字,那么该锁很可能是索引键值锁
key#/bsiz: 是索引键号或对于 VARCHAR 锁的已锁定字节数,如果该字段包含 'K-' ,后跟值,那么是键锁。值标识哪个索引正在被锁定。例如:K-1 表示对表所定义的第一个索引上的锁。
onstat -l 命令:打印物理和逻辑日志信息
可以使用 onstat -l 命令显示有关物理日志、逻辑日志和临时逻辑日志的信息。
语法:
示例输出
图: onstat -l 命令输出
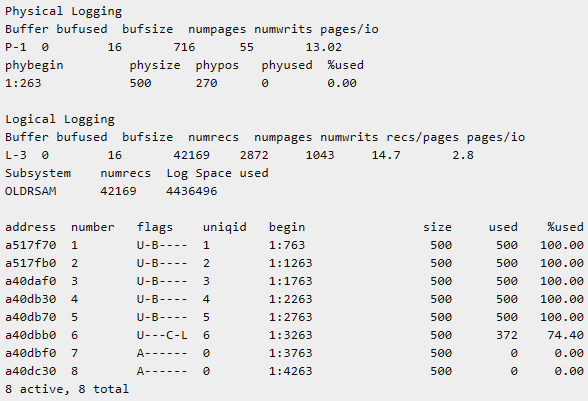
物理日志文件的输出描述
显示的第一部部分描述了物理日志配置:
buffer: 是物理日志缓冲区的数量
bufused: 是已使用的物理日志缓冲区页数
bufsize: 是每个物理日志缓冲区的大小(以页为单位)
numpages: 是写入物理日志的页数
numwrits: 是对磁盘的写入数
pages/io: 计算方法是 numpages/numwrits,该值指示正在缓存的物理日志写入的效率
phybegin: 是日志开始处的物理页号
physize: 是物理日志的大小(以页为单位)
phypos: 是日志中发生下一个日志记录写入的当前数量
phyused: 是日志中已使用页的数量
%used: 是已使用页的百分比
onstat -l 命令输出的第二部分描述逻辑日志配置:
buffer: 是逻辑日志缓冲区数
bufused: 是逻辑日志缓冲区呢已使用的页数
bufsize: 每个逻辑日志缓冲区的大小(以页为单位)
numrecs: 是已写入记录的数量
numpages: 是已写入页的数量
numwrits: 是对逻辑日志的写入数
recs/pages: 计算方法是 numrecs/numpages,您不能影响该值。不同类型的操作生成不同类型(和大小)的记录
pages/io: 计算方法是 numpages/numwrits,可以通过更改逻辑日志缓冲区大小(由 ONCONFIG 文件中的 LOGBUFF 指定)或通过更改数据库的日志记录方式(从已缓冲到未缓冲,反之亦然)来影响此值
以下字段将对每个逻辑日志文件重复:
address: 是日志文件描述符的地址
number: 是逻辑日志文件的日志标识号,日志标识号可能是无序的,因为数据库服务器或管理员都可以直接插入日志文件
flags: 提供每个日志的状态,如下所示:
A: 新添加的(可以使用)
B: 已备份
C: 当前的逻辑日志文件
D: 标记为已删除,要删除日志文件并释放其空间以再利用,那么必须对所有存储空间执行 0 级备份
F: 可用的,可以使用
L: 最新的 checkpoint 记录
U : 已使用的
uniqid: 是日志的唯一 ID 号
begin: 是日志文件的起始页
size: 是日志的大小(以页为单位)
used: 是已使用页数量
%used: 是已使用页的百分比
active: 是活动逻辑日志的数量
total: 是逻辑日志的总数
临时逻辑日志文件的输出描述
数据库服务器在热恢复过程中使用 temporary logical logs ,因为永久日志在那时是不可用的。以下字段将对每个临时逻辑日志文件重复:
address: 是日志文件描述符的地址
number: 是逻辑日志文件的日志标识号
flags: 提供每个日志的状态,如下所示:
B: 已备份
C: 当前的逻辑日志文件
F: 可用的,可以使用
U : 已使用的
uniqid: 是日志的唯一 ID 号
begin: 是日志文件的起始页
size: 是日志的大小(以页为单位)
used: 是已使用页的数量
%used: 是已使用页的百分比
active: 是活动临时逻辑日志的数量
onstat -L 命令:打印可用锁的数量
可以使用 onstat -L 命令打印在锁可用列表上的可用锁的数量。
语法:
示例输出
图: onstat -L 输出
num list head available locks
0 10a143b70 19996
1 101010101 200
3 020202020 300
输出描述
num : 列表编号
list head : 列表的起始地址
available locks : 该列表上的锁的数量
onstat -m 命令:打印最近的系统消息日志信息
可以使用 onstat -m 命令显示系统消息日志中 20 个最新行。
可以在数据库服务器处于任何方式(包括离线)时使用 onstat -m 命令选项。
用法:
示例输出
此选项的输出列出消息日志文件和完整路径名的 20 个文件条目。一个日期和时间头分隔每天的条目。时间戳记放在每天中单个条目的开始处。消息日志由 ONCONFIG 文件中的 MSGPATH 进行指定。
图: onstat -m 命令输出

onstat -o 命令:输出共享内存内容
可以使用 onstat -o 命令将共享内存的内容复制到特定的文件,以便今后分析。如果没有指定输出文件,那么使用当前目录的缺省 onstat.out 文件。
语法:
使用 nobuffs 选项排除来自输出文件中的共享内存常驻段中的缓冲池。这会产生较小的输出文件。
使用 full 选项创建同 GBase 8s 实例的共享内存段大小相同的输出文件。您必须在文件系统上留出足够的空间来处理该输出。
如果您没有指定 nobuffs 或 full 选项,那么输出将会由数据库服务器中的 DUMPSHMEM 配置参数的设置控制:
- 如果 DUMPSHMEM 设置为 0 或 1 ,那么 onstat -o 命令写入一个完整共享内存转储文件。
- 如果 DUMPSHMEM 设置为 2 ,那么 onstat -o 命令写入一个 nobuffs 共享内存转储文件(在驻留段中没有缓冲池)。
通过对此文件运行其他 onstat 命令,您可以从先前保存的共享内存转储中收集信息。使用 onstat -o 命令创建的 outfile 可用作运行其他 onstat 命令的源文件。
onstat -p 命令:打印概要文件计数
可以使用 onstat -p 命令显示自启动数据库服务器以来或自运行 onstat -z 命令以来的概要文件计数的信息。
语法:
示例输出
图: onstat -p 命令输出
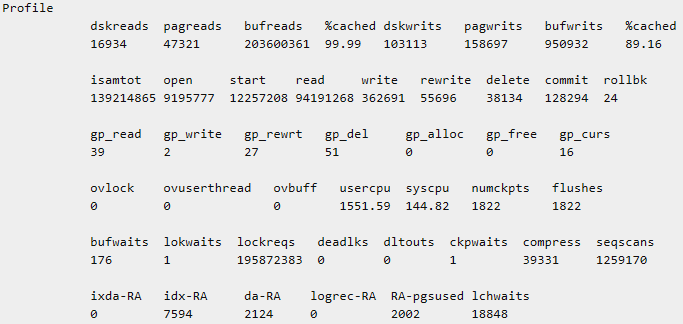
输出描述
输出的第一部分描述读取和写入。
读和写分成三类:从磁盘、从缓冲区以及页数(读取或写入)
第一个 %cached 字段衡量从缓冲区的读取数与从磁盘的读取数之比。第二个 %cached 字段衡量写入缓冲区的数量与写入磁盘的数量之比。
数据库服务器对信息执行缓冲并将其写入磁盘(以页为单位)。出于这个原因,以 dskwrits 显示的磁盘写入数通常小于个别用户执行的写入数:
dskreads: 实际的磁盘读取数
pagreads: 页读取数
bufreads: 共享内存读取数
%cached: 缓冲池中已高速缓存的读取数百分比,如果 bufreads 超过最大 integer (或 long)值,那么其内部表示变成负数,但值显示为 0.0
dskwrits: 对磁盘的物理写入的实际数量,该数字包含对 onstat -l 中所报告的物理和逻辑日志的写入数
pagwrits: 已写入页的数量
bufwrits: 共享内存写入数
%cached: 缓冲池中已高速缓存的写入数百分比
-p 的下一部分显示已执行不同类 ISAM 调用的次数的制表。这些调用发生在操作的最底层,并且不必与 SQL 语句一对一对应执行。单个查询可能产生多个 ISAM 调用。这些统计信息通过数据库服务器产生并且不能用来监视单个数据库上的活动,除非只有一个数据库是活动的或只存在一个数据库
isamtot: 调用总数
open: 当 tblspace 打开时增加
start: 增加索引中的指针
read: 当调用读取函数时增加
write: 当每次写调用时增加
rewrite: 当发生更新时增加
delete: 当删除行时增加
commit: 每次执行 iscommit() 调用时增加,该值与已执行的显式 COMMIT WORK 语句之间不存在一对一的对应关系
rollbk: 当事务回滚时增加
onstat -p 命令输出的下一部分显示有关一般页的信息。一般页管理提供一个 API 让 GBase 8s 来管理数据库服务器缓冲池中的非标准页。下表描述了 onstat -p 命令输出中的 Generic Page Manager 。
gp_read: 一般页读取数
gp_write: 一般页写入数
gp_rewrt: 一般页更新数
gp_del: 一般页删除数
gp_alloc: 一般页分配数
gp_free: 已释放并返回给 tablspace 的一般页数
gp_curs: 用于一般页的游标数
onstat -p 命令输出的下一部分显示了请求资源时没有可用资源的次数:
ovlock: 会话尝试超过锁最大数量的次数
ovuserthread: 用户尝试超过用户线程最大数量的次数
ovbuff: 数据库服务器无法找到可用共享内存缓冲区的次数
当没有可用缓冲区时,数据库服务器将 dirty 缓冲区写入磁盘,然后设法找到可用缓冲区
usercpu: 所有用户线程使用的用户 CPU 时间(以秒为单位)
该条目每 15 秒更新一次
syscpu: 所有用户线程使用的全部系统 CPU 时间(以秒为单位)
该条目每 15 秒更新一次
numckpts: 自引导时间以来的 checkpoint 数
flushes: 缓冲池已清仓到磁盘的次数
onstat -p 命令输出的下一部分包含杂项信息,如下:
bufwaits: 每次用户线程必须等待缓冲区时增加
lokwaits: 每次用户线程必须等待锁时增加
lockreqs: 每次请求锁时增加
deadlks: 死锁次数。
dltouts: 等锁超时次数。
ckpwaits: Checkpoint 等待数
compress: 每次压缩数据页时增加
seqscans: 对每个顺序扫描增加
onstat -p 命令输出的最后一部分包含以下信息:
ixda-RA: 索引页到数据页的预先读取计数
idx-RA: 遍历索引页的预先读取计数
da-RA: 仅数据路径扫描的计数
logrec-RA: 数据库服务器预先读取的日志记录
RA-pgsused: 数据库服务器预先读取所使用的页数
lchwaits: 存储线程需要等待共享存储锁存器的次数
大的锁存器等待数通常是由大量处理活动引起,数据库服务器正在此活动中记录大多数事务
onstat -P 命令:打印分区信息
可以使用 onstat -P 命令显示所有分区的分区号和属于分区的缓冲池中的页。
语法:
有关在没有创建缓冲池的转储文件中上运行 onstat -P 命令的信息,请参阅 在共享内存转储文件中运行 onstat 命令.
示例输出
图: onstat -P 命令输出
输出描述
Buffer pool page size : 以字节表示的缓冲池页面大小
partnum : 分区号
total : 分区总数
btree : 分区中 B-tree 页数
data : 分区中数据页数
other : 分区中其他页数
dirty : 分区中 dirty 页数
onstat -r 命令:重复打印选择的统计信息
可以使用 onstat -r 命令反复在指定的时间间隔打印指定选项的统计信息。
语法:
使用 onstat -r seconds other_options 命令来指定重复其他选项的时间间隔。
使用 onstat -r other_options 命令来让此选项每隔五秒重复一次,这将使其他选项能与 -r 选项连接。如下所示: onstat -rFh 。
onstat -r 命令可以在命令方式和交互方式下使用,并可能对将命令重复输出到受监视系统的资源利用有用。
每隔五秒执行一次 onstat -r 命令的示例输出
图: 命令输出
onstat -r
GBase 8s Database Server Version 8.7.F -- On-Line -- Up 20:05:25 -- 1067288 Kbytes
GBase 8s Database Server Version 8.7.F -- On-Line -- Up 20:05:30 -- 1067288 Kbytes
GBase 8s Database Server Version 8.7.F -- On-Line -- Up 20:05:35 -- 1067288 Kbytes
每个十秒执行 onstat -r 命令的示例输出
图: 命令输出
onstat -r 10
GBase 8s Database Server Version 8.8 -- On-Line -- Up 20:06:58 -- 1067288 Kbytes
GBase 8s Database Server Version 8.8 -- On-Line -- Up 20:07:08 -- 1067288 Kbytes
GBase 8s Database Server Version 8.8 -- On-Line -- Up 20:07:18 -- 1067288 Kbytes
每隔一秒执行带有 -h 选项的 onstat -r 命令的示例输出
图: onstat -r 1 -h 命令输出
onstat -r 1 -h
Buffer pool page size: 2048
buffer hash chain length histogram
# of chains of len
3841 0
3767 1
522 2
62 3
8192 total chains
4351 hashed buffs
5000 total buffs
Buffer pool page size: 2048
buffer hash chain length histogram
# of chains of len
4020 0
3392 1
735 2
43 3
2 4
8192 total chains
4172 hashed buffs
5000 total buffs
每隔五秒执行带有 -Fh 选项的 onstat -r 命令的示例输出
图: onstat -rFh 命令输出
onstat -rFh
Fg Writes LRU Writes Chunk Writes
0 0 21
address flusher state data # LRU Chunk Wakeups Idle Tim
460e6820 0 I 0 0 2 5 9.820
states: Exit Idle Chunk Lru
Buffer pool page size: 2048
buffer hash chain length histogram
# of chains of len
6342 0
1850 1
8192 total chains
1850 hashed buffs
5000 total buffs
Fg Writes LRU Writes Chunk Writes
0 0 21
address flusher state data # LRU Chunk Wakeups Idle Tim
460e6820 0 I 0 0 2 10 22.755
states: Exit Idle Chunk Lru
Buffer pool page size: 2048
buffer hash chain length histogram
# of chains of len
4396 0
3796 1
8192 total chains
3796 hashed buffs
5000 total buffs
onstat -R 命令:打印 LRU 、FLRU 和 MLRU 队列信息
可以使用 onstat -R 命令显示有关 LRU 队列、FLRU 队列和 MLRU 队列的详细信息。对于每个队列, onstat -R 命令显示队列中的缓冲区数和已修改缓冲区的数量和百分比。
语法:
示例输出
图: onstat -R 命令输出
Buffer pool page size: 2048
8 buffer LRU queue pairs priority levels
# f/m pair total % of length LOW HIGH
0 f 375 100.0% 375 375 0
1 m 0.0% 0 0 0
2 f 375 100.0% 375 375 0
3 m 0.0% 0 0 0
4 f 375 100.0% 375 375 0
5 m 0.0% 0 0 0
6 F 375 100.0% 375 375 0
7 m 0.0% 0 0 0
8 f 375 100.0% 375 375 0
9 m 0.0% 0 0 0
10 f 375 100.0% 375 375 0
11 m 0.0% 0 0 0
12 f 375 100.0% 375 375 0
13 m 0.0% 0 0 0
14 f 375 100.0% 375 375 0
15 m 0.0% 0 0 0
0 dirty, 3000 queued, 3000 total, 4096 hash buckets, 2048 buffer size
start clean at 60.000% (of pair total) dirty, or 226 buffs dirty, stop at
50.000%
Buffer pool page size: 8192
4 buffer LRU queue pairs priority levels
# f/m pair total % of length LOW HIGH
0 F 250 100.0% 250 250 0
1 m 0.0% 0 0 0
2 f 250 100.0% 250 250 0
3 m 0.0% 0 0 0
4 f 250 100.0% 250 250 0
5 m 0.0% 0 0 0
6 f 250 100.0% 250 250 0
7 m 0.0% 0 0 0
0 dirty, 1000 queued, 1000 total, 1024 hash buckets, 8192 buffer size
start clean at 60.000% (of pair total) dirty, or 150 buffs dirty, stop at
50.000%
输出描述
Buffer pool page size: 是以字节表示的缓冲池页面大小
#: 显示队列编号,每个 LRU 队列由两个子队列构成:一个 FLRU 队列和一个 MLRU 队列。这样,队列 0 和 1 属于第一个 LRU 队列,队列 2 和 3 属于第二个 LRU 队列,依此类推。
f/m: 标识队列类型,该字段有 4 种可能值:
f: 可用 LRU 队列,在这种上下文中,可用意味着未修改过。尽管 LRU 队列中的几乎所有缓冲区都可用但数据库服务器尝试使用 FLRU 队列而不是 MLRU 队列。( 在数据库服务器可以使用缓冲区之前,已修改缓冲区必须已写入磁盘。)
F: 具有最少元素的可用 LRU,数据库服务器使用该估计确定接下来将未修改(可用)缓冲区置于何处
m: MLRU 队列
M : 清仓程序正在清除的 MLRU 队列
length: 跟踪受测量队列的长度(以缓冲区为单位)
% of : 显示此子队列构成 LRU 队列的百分比,例如:假设一个 LRU 队列具有 50 个缓冲区,其中 30 个缓冲区正在 MLRU 队列中,20 个在 FLRU 队列中。则 % of 列将分别列出 60.00 和 40.00 的百分率
pair total : 提供此 LRU 队列中缓冲区的总数
priority levels: 显示优先级级别: LOW 、MED_LOW 、MED_HIGH 、HIGH
onstat -R 命令也列出优先级级别。
摘要信息在单独的 LRU 队列信息后面。可如下解释摘要信息:
dirty: 是所有 LRU 队列中已修改缓冲区的总数
queued: 是 LRU 队列中缓冲区的总数
total: 是缓冲区的总数
hash buckets: 是哈希桶数
buffer size: 是每个缓冲区的大小
start clean: 是指定的 BUFFERPOOL 配置参数的 lru_max_dirty 字段值
stop at: 是指定的 BUFFERPOOL 配置参数的 lru_min_dirty 字段值
priority downgrades: 是已降级为较低优先级的 LRU 队列的数量
priority upgrades: 是已升级为较高优先级的 LRU 队列的数量
onstat -s 命令:打印锁存器信息
可以使用 onstat -s 命令显示一般锁存器信息,包含锁存器控制的资源。
语法:
示例输出
图: onstat -s 命令输出
![]()
输出描述
name: 使用以下缩写标识锁存器所控制的资源:
archive: 存储空间备份
bf: 缓冲区
bh: 哈希缓冲区
chunks: Chunk 表
ckpt: 检查点
dbspace: Dbspace 表
flushctl: 页清除程序控制
flushr: 页清除程序
locks: Lock 表
loglog: 逻辑日志
LRU: LRU 队列
physb1: 第一个物理日志缓冲区
physb2: 第二个物理日志缓冲区
physlog: 物理日志
pt: Tblspace tblspace
tblsps: Tblspace 表
users: 用户表
address: 是锁存器的地址,如果线程正在等待锁存器,那么该地址显示在 onstat -u (用户)命令输出的 wait 字段
lock: 标示锁存器是否已锁定并设置,标示锁状态的代码(1 或 0)与计算机有关
wait: 标示是否有任何用户线程正在等待锁存器
userthread: 是正在等待锁存器的任何用户线程的共享内存地址,此线程包含线程控制块地址,所有线程都有这些地址。您可以比较该地址与 onstat -u 输出中的用户地址以获得用户进程标识号,要从 tcb 地址中获得 rstcb 地址,请检查 onstat -g ath 命令的输出,它列出了每个用户线程的这两个地址。
onstat -t 和 onstat -T 命令:打印 tblspace 信息
可以使用 onstat -t 命令显示活动 tblspace 的 tblspace 信息。使用 onstat -T 命令显示所有 tblspace 的 tblspace 信息。
onstat -t 命令页列出了活动 tblspace 的数量和 tblspace 的总数。
语法:
示例输出
图: onstat -t 命令输出

输出描述
n: 是打开的 tblspace 的计数器
address: 是共享内存 tblspace 表中的 tblspace 地址
flgs: 使用以下标志位描述标志:
0x00000001
正在初始化分区结构
0x00000002
分区已修改。已修改页未清仓到磁盘中
0x00000004
正在删除分区
0x00000008
分区用于伪表
0x00000010
正在 ADD INDEX 或 DROP INDEX 操作中改变分区
0x00000020
正在 ALTER TABLE 操作中更改分区
0x00000080
当 dbspace 关闭时正在删除分区
0x00000100
当删除表时未删除 blobspace 中的简单大对象
0x00000200
分区更改页计数已更新
0x00000400
页已更改为最新的数据库模式
0x00000800
系统临时表
0x00001000
用户临时表
0x00004000
索引操作在恢复过程中推迟
0x00008000
正在截断分区
0x00010000
分区被部分截断
ucnt: 使用计数,它指示当前正在访问 tblspace 的用户线程数
tblnum: 是以十六进制值表示的 tblspace 编号,等价的整数值显示为 systables 系统目录表中的 partnum 值
physaddr: 是 tblspace 的物理地址(在磁盘上)
npages: 是分配给 tblspace 的页数
nused: 是 tblspace 中已使用页的数量
npdata: 是已使用数据页的数量
nrows: 是已使用数据行的数量
nextns: 是已分配非连续 extent 的数量,该数与已分配下一个 extent 的次数不相等
onstat -u 命令:打印用户活动概要文件
可以使用 onstat -u 命令显示用户活动的概要文件。
语法:
示例输出
图: onstat -u 命令输出
Userthreads
address flags sessid user tty wait tout locks nreads nwrites
a4d8018 ---P--D 1 gbasedbt - 0 0 0 58 4595
a4d8628 ---P--F 0 gbasedbt - 0 0 0 0 2734
a4d8c38 ---P--- 5 gbasedbt - 0 0 0 0 1
a4d9248 ---P--B 6 gbasedbt - 0 0 0 40 0
a4d9858 ---P--D 7 gbasedbt - 0 0 0 0 0
a4d9e68 Y--P--- 21 niraj - a65e5a8 0 1 0 0
6 active, 128 total, 7 maximum concurrent
输出描述
-u 选项对每个用户线程提供以下输出:
address: 在用户表中用户线程的共享内存地址,比较该地址与 -s 选项(锁存器)输出、-b 、-B 和 -X 选项(缓冲区)以及 -k 选项(锁)中显示的地址以了解该线程正在持有或等待什么资源
flags: 提供会话状态。
位置 1 的标志代码:
B:正在等待缓冲区
C :正在等待 checkpoint
G:正在等待对逻辑日志缓冲区的写入
L:正在等待锁
S:正在等待互斥
T:正在等待事务
Y:正在等待条件
X:正在等待事务清除(回滚)
DEFUNCT:该线程已引起严重的断言失败,并已暂挂以允许其他线程继续其工作
位置 2 的标志代码:
*:I/O 故障过程中的事务是活动的
位置 3 的标志代码:
A:Dbspace 备份线程,有关此处显示的其他值,请参阅 -x 选项位置 3 的标志代码。
位置 4 的标志代码:
P:会话主线程
位置 5 的标志代码:
R:正在读取
X:临界段中的线程
位置 6 的标志代码:
R:恢复过程中使用的线程(例如:物理或逻辑恢复)
-:恢复过程中未使用的线程
位置 7 的标记代码:
B:B-tree 清除程序线程
C:已终止正在等待清除的用户线程
D:守护程序线程
F:页清除程序线程
sessid: 会话标识符编号。在操作(例如并行排序和并行索引构建)过程中,会话可能有许多与其相关联的用户线程。出于这一原因,会话标识用来标识每个唯一的会话
user: 用户登录名(从操作系统派生)
tty: 用户正在使用的标准错误(stderr)文件名称(从操作系统派生)
wait: 如果用户线程正在等待特定锁存器、锁、互斥锁或条件,该字段显示该资源的地址。使用该地址映射到 -s (锁存器)或 -k (锁)选项输出中提供的信息。如果等待是用于持久条件的,那么对 onstat -a 输出中的地址运行 grep
tout: 当前等待中的剩余秒数。如果值是 0,那么用户线程不再等待锁存器或锁。如果值是 -1 ,那么用户线程处于不定等待中
locks: 用户线程正持有的锁数,-k 输出应包含持有的每个锁的列表
nreads: 用户线程已执行的磁盘读取数
nwrites: 是用户线程已执行的写调用数。
所有写调用都写入共享内存缓冲区高速缓存
onstat -u 命令输出的最后一行显示自初始化数据库服务器以来已分配的并发用户线程的最大数量。例如:样本 onstat -u 命令输出的最后一行如下:
![]()
该行的最后部分( 17 maximum concurrent)指示自初始化数据库服务器以来并发运行的用户线程的最大数为 17 。
该输出还指示了活动用户的数量和允许用户的最大数。
onstat -x 命令:打印数据库服务器事务信息
可以使用 onstat -x 命令显示在数据库服务器上的事务信息。
语法:
只有在以下情况下事务信息才是必需的:
- X/Open 环境
- 参与分布式查询的数据库服务器
- 数据库服务使用 Microsoft™ Transaction Server (MTS)事务管理器
示例输出
图: onstat -x 命令输出
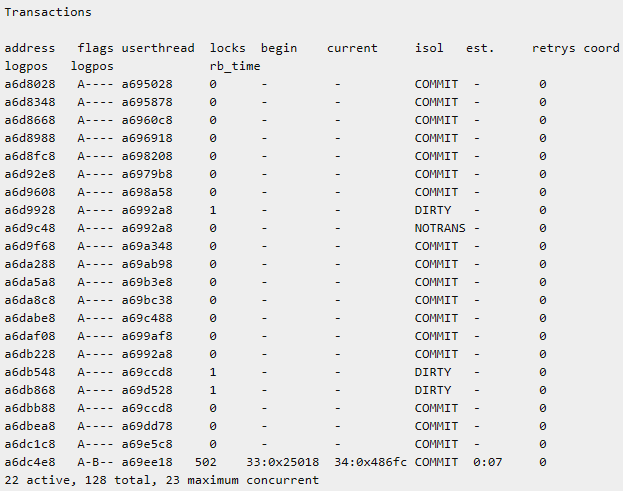
输出描述
可以如下解释 onstat -x 命令输出:
address: 事务结构的共享内存地址
flags:位置 1 的标志代码(当前事务状态):
A:用户线程已连接到事务
S:TP/XA 暂挂的事务
C:TP/XA 正在等待回滚
位置 2 的标志代码(事务方式):
T:紧耦合方式(MTS)
L:松耦合方式(缺省方式)
位置 3 的标志代码(事务阶段):
B:开始工作
P:准备好用于提交的分布式查询
X:准备好用于提交的 TP/XA
C:正在提交或已提交
R:正在回滚或已回滚
H:正在尝试回滚或已回滚
位置 4 的标志代码
X:XA 事务
位置 5 的标志代码 (事务的类型):
G :全局事务
C:分布式查询协调者
S:分布式查询从属者
B:分布式查询协调者和从属者
M:重新定向的全局事务
userthread: 拥有事务的线程(rstcb 地址)
locks: 事务持有的锁数
begin logpos: BEGIN WORK 记录已记录到其中的日志
current logpos: 事务最近写入的日志的当前日志位置 (当事务回滚时,当前日志位置会回退直到它到达起始日志位置。 当到达起始日志位置,回滚结束。)
isol: 隔离级别
est. rb time: 服务器回滚该事务所需的估计时间。随着事务前进,该时间增长。如果事务回滚,那么该时间随着事务的展开而减少
retrys: 启动分布式查询的恢复线程的尝试次数
coord: 从属者正在执行事务时事务协调者的名称
该字段告诉您哪个数据库服务器正在协调两阶段提交
onstat -x 命令输出的最后一行指示 8 是自初始化数据库服务器以来并发事务的最大数。
![]()
确定逻辑日志记录的位置
可以使用 onstat -x 命令确定逻辑日志记录的位置。
curlog 和 logposit 字段提供了逻辑日志记录的确切位置。如果事务不在回滚,curlog 和 logposit 描述最新写入的日志记录的位置。当事务正在回滚时,这些字段描述最新“撤销”的日志记录的位置。随着事务的回滚,curlog 和 logposit 值下降。在长事务中,logposit 和 beginlg 值的聚集率可以帮助您估计回滚还将花费多少时间。
确定全局事务的方式
onstat -x 命令对确定全局事务是以松耦合方式还是以紧耦合方式执行很有用。
onstat -x 命令输出的 flag 列的第二个位置显示全局事务的标志。T 标志指示紧耦合方式,L 标志指示松耦合方式。
- 松耦合方式意味着不同的数据库服务器协调事务但不共享锁。全局事务中的每个分支都具有独立的事务 XID 。在逻辑日志中,所有分支的记录都显示为独立的事务。
- 紧耦合方式意味着不同数据库服务器协调事务并共享诸如锁和日志之类的资源。在全局事务中,访问同一数据库的所有分支共享同一事务 XID 。具有相同 XID 的分支的日志记录显示在同一会话 ID 下面。MTS 使用紧耦合方式。
onstat -X 命令:打印线程信息
可以使用 onstat -X 命令获取关于正在等待缓冲区的线程的确切信息。
对于每个使用中的缓冲区,onstat -X 命令显示一般的缓冲区信息,这些信息也可以使用 onstat -b 或 onstat -B 命令获得。有关更多信息,请参阅 onstat -b 命令:打印正在使用的缓冲区信息 中的 onstat -b 命令。
语法:
示例输出
图: onstat -X 命令输出

输出描述
onstat -X 命令具有 waiter 字段,用以列出所有正在等待缓冲区的用户线程,而 onstat -b 和 onstat -B 命令包含 waitlist 字段,它显示正在等待缓冲区的第一个用户线程的地址。共享缓冲区的最大数量以 ONCONFIG 文件中 BUFFERPOOL 配置参数的 buffers 字段进行指定。
Buffer pool page size: 以字节表示的缓冲池页面大小
address: 缓冲区表中缓冲区头的地址
flags: 指示缓存页当前状态的标志:
0x01 : 已修改数据
0x02: 数据
0x04: LRU
0x08: 错误
0x10: 共享锁
0x20: 正在进行 LRU AIO 写
0x40: 正在进行 Chunk 写
0x10: 互斥锁
0x100: 清除程序已指定到 LRU
0x200: 缓冲区应该避免 bf_check 调用
0x400: 在写页面之前进行日志清空
0x800: 缓冲区已进行缓冲区检查
0x8000: 缓冲区已固定
pagenum: 磁盘上的物理页数
memaddr: 缓冲区内存地址
nslots: 页中 solt 表的条目的数量,该字段指示存储在该页上的行(或行的一部分)的数量
pgflgs: 使用以下值(单独或组合)来描述页类型:
1:数据页
2:Tblspace 页
4:可用列表页
8:Chunk 可用列表页
9:剩余数据页
b:分区常驻 blobpage
c:Blobspace 常驻 blobpage
d:Blob chunk 可用列表位页
e:Blob chunk blob 图页
10:B-tree 节点页
20:B-tree 根节点页
40:B-tree 分支节点页
80:B-tree 叶节点页
100:逻辑日志页
200:逻辑日志的最后一页
400:逻辑日志的同步页
800:物理日志
1000:保留根页
2000:不需要物理日志
8000:带有缺省标志的 B-tree 叶
scount: 显示正在等待缓冲区的线程数
waiter: 列出正在等待缓冲区的所有用户线程的地址
onstat -z 命令:清除统计信息
可以使用 onstat -z 命令清除数据库服务器的统计信息(包括与 Enterprise Replication 相关联的统计信息),并将概要文件计数设置为 0 。
如果使用 onstat -z 命令重置和监视某些字段的计数,那么应了解概要文件计数对于数据库服务器管理的任何数据库中发生的所有活动都是增加的。任何用户都可以重设概要文件计数从而对另一用户正在执行的监视进行干预。
语法:
退出 onstat 命令时的返回码
当您退出 onstat 命令时,该命令会显示一个返回码的设置。
示例
以下是当您退出 onstat 命令时,显示的返回码和消息的几行示例:
GLS failures: -1
Failed to attach shared memory: -1
Failed to attach shared memory when running 'onstat -': 255
All other errors detected by onstat: 1
No errors detected by onstat: 0
Administration mode: 7
返回码值
下表列出了与退出 onstat 命令时显示的返回码相关的服务器方式。
| 值 | 解释 |
|---|---|
| -1 | GLS 本地语言环境初始化失败或 GBase 8s 连接共享内存失败 |
| 0 | 初始化方式 |
| 1 | 静态模式 |
| 2 | 恢复方式 |
| 3 | 备份方式 |
| 4 | 关机方式 |
| 5 | 在线模式 |
| 6 | 中止方式 |
| 7 | 用户方式 |
| 255 | 离线方式 |