磁盘、内存和进程管理
虚拟处理器和线程
这些主题描述虚拟处理器,说明线程如何在虚拟处理器中运行,并说明数据库服务器如何使用虚拟处理器和线程来提高性能。
虚拟处理器
数据库服务器进程都被称为虚拟处理器,因为它们作用的方式类似于计算机中 CPU 作用的方式。如同 CPU 运行多个操作系统进程为多个用户提供服务一样,数据库服务器虚拟处理器运行多个线程来为多个 SQL 客户机应用程序服务。
虚拟处理器是操作系统调度处理的进程。
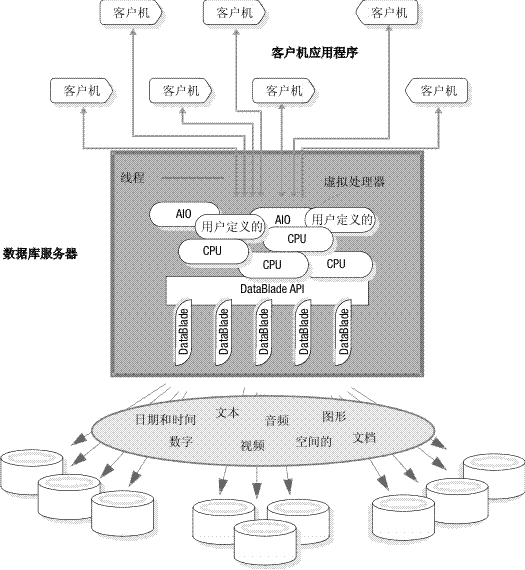
下图说明了客户机应用程序与虚拟处理器之间的关系。少量的虚拟处理器可以为大量的客户机应用程序或查询提供服务。
图: 虚拟处理器

线程
线程是虚拟处理器的一个任务,如同虚拟处理器是 CPU 的一个任务一样。虚拟处理器是操作系统调度在 CPU 上执行的任务;数据库服务器线程是虚拟处理器调度进行内部处理的任务。线程有时称为轻量级进程,因为它们类似进程,但是对操作系统的要求更少。
数据库服务器虚拟处理器是多线程的,因为它们运行多个并发线程。
线程的性质如下所示。
| 操作系统 | 操作 |
|---|---|
| UNIX™ | 线程是虚拟处理器为处理而内部调度的任务。 |
在这些主题中,对线程的所有引用都是指数据库服务器创建、调度和删除的线程。
虚拟处理器代表 SQL 客户机应用程序运行线程(会话线程),并运行线程以满足内部需求(内部线程)。在大多数情况下,对于客户机应用程序的每个连接,数据库服务器都运行一个会话线程。另外,数据库服务器运行内部线程以完成数据库 I/O、日志记录 I/O、页面清除和管理任务。
用户线程是为来自客户机应用程序的请求提供服务的数据库服务器线程。用户线程包括会话线程(称为 sqlexec 线程),这些线程是数据库服务器为了向客户机应用程序提供服务而运行的主线程。
用户线程还包括为来自 onmode 实用程序的请求提供服务的线程、用于恢复的线程、B 型树扫描程序线程以及页清除程序线程。
要显示活动用户线程,请使用 onstat -u。
虚拟处理器的类型
每一类虚拟处理器都专用于处理某些类型的线程。
下表显示虚拟处理器的类以及它们执行的处理的类型。
您配置的每个类的虚拟处理器数量取决于物理处理器 (CPU)、硬件内存和使用中数据库应用程序的可用性。
表 1. 虚拟处理器类
| 虚拟处理器类 | 分类 | 用途 |
|---|---|---|
| ADM | 管理 | 执行管理功能。 |
| ADT | 审计 | 执行审计功能。 |
| AIO | 磁盘 I/O | 执行非日志记录磁盘 I/O。如果使用了 KAIO,那么 AIO 虚拟处理器将对格式化的磁盘空间执行 I/O。 |
| BTS | Basic Text Search | 运行 Basic Text Search 索引操作和查询。 |
| CPU | 中央处理 | 运行所有会话线程以及一些系统线程。 运行可用时的内核异步 I/O (KAIO) 的线程。 可以根据配置运行单个轮询线程。 |
| CSM | 通信支持模块 | 执行通信支持服务操作。 |
| dwavp | 数据仓储 | 在连接到 GBase 8s Warehouse Accelerator 的数据库服务器上,对 GBase 8s Warehouse Accelerator 运行管理功能和过程。 |
| 加密 | 加密 | 调用加密或解密功能时被数据库服务器使用。 |
| IDSXMLVP | XML 发布 | 运行 XML 发布函数。 |
| Java™ VP (JVP) | Java UDR | 运行 Java UDR。 包含 Java 虚拟机 (JVM)。 |
| LIO | 磁盘 I/O | 如果逻辑日志文件(内部类)位于格式化的磁盘空间,那么写入这些逻辑日志文件。 |
| MQ | MQ 消息传递 | 执行 MQ 消息传递事务。 |
| MSC | 其他 | 为需要很大堆栈的系统调用的请求提供服务。 |
| OPT (UNIX™) | Optical | 执行对光盘的 I/O。 |
| PIO | 磁盘 I/O | 如果物理日志文件(内部类)位于格式化的磁盘空间,那么写入该物理日志文件。 |
| SHM | 网络 | 执行共享内存通信。 |
| SOC | 网络 | 使用套接字执行网络通信。 |
| TLI | 网络 | 使用传输层接口 (TLI) 执行网络通信。 |
| WFSVP | Web 要素服务 | 运行 Web 要素服务例程。 |
| 类名 | 用户定义的 | 以线程安全方式运行用户定义的例程,以便在例程失败时数据库服务器不受影响。 用 VPCLASS 配置参数指定。 必须指定类名。 |
下图说明了数据库服务器的主要组件以及可扩展性。
图: 数据库服务器
虚拟处理器的优势
与为单台客户机应用程序提供服务的数据库服务器进程相比,数据库服务器虚拟处理器的动态多线程性质将提供下列优势:
- 虚拟处理器可以共享处理。
- 虚拟处理器将保存内存和资源。
- 虚拟处理器可以执行并行处理。
- 当数据库服务器正在运行时,您可以启动其他的虚拟处理器并终止活动的 CPU 虚拟处理器。
- 您可以将虚拟处理器绑定到 CPU。
以下主题将描述这些优势。
共享处理
同一类的虚拟处理器具有相同的代码并且共享对内存中的数据和处理队列的访问。类中任何的虚拟处理器都可以运行任何属于该类的线程。
通常,数据库服务器会尝试将线程保持在同一个虚拟处理器上运行,因为将它移动到不同的虚拟处理器可能需要来自处理器内存的数据在总线上传送。然而,当线程正等待运行时,数据库服务器可以将线程迁移至另一个虚拟处理器,因为平衡处理负载的好处要大于在传送数据时花费的开销。
一类虚拟处理器中的共享处理是自动发生的并且对数据库用户是透明的。
节省内存和资源
相较于一个客户机进程对应一个服务器进程的体系结构,数据库服务器能够用少量的服务器进程处理大量客户机。对于每台客户机,数据库服务器是通过运行线程而不是进程来实现这点的。
因为线程共享分配给虚拟处理器的资源,所以多线程允许对操作系统资源进行更有效的使用。虚拟处理器运行的所有线程对虚拟处理器内存、通信端口和文件具有相同的访问权。虚拟处理器会按线程协调对资源的访问。但是,每个单独的进程都有一组不同的资源,并且在多个进程需要访问相同资源时,操作系统必须对访问进行协调。
通常,虚拟处理器从一个线程切换至另一个线程比操作系统从一个进程切换至另一个进程更快。当操作系统在两个进程间切换时,它必须使一个进程停止在处理器上运行,保存其当前的处理状态(或上下文),然后启动另一个进程。两个进程都必须进入然后退出操作系统内核,并且可能需要替换部分物理内存的内容。但是,线程会共享相同的虚拟内存和文件描述符。在虚拟处理器从一个线程切换到另一个线程时,就相当于从一个执行路径切换到另一个执行路径。虚拟处理器是一个进程,该进程在 CPU 上持续运行而不会中断。有关虚拟处理器如何从一个线程切换到另一个线程的描述,请参阅上下文切换。
并行处理
在以下情况中,CPU 类的虚拟处理器可以为单台客户机以并行方式运行多个会话线程:
- 索引构建
- 排序
- 恢复
- 扫描
- 连接
- 聚集
- 分组
- 用户定义的例程 (UDR) 执行
下图说明了并行处理。当客户机启动索引构建、排序或逻辑恢复时,数据库服务器将使用尽可能多的计算机资源创建多个线程以并行处理任务。当一个线程正在等待 I/O,另一个线程可能正在工作。
图: 并行处理

在在线模式下添加和删除虚拟处理器
可以添加虚拟处理器以满足数据库服务器运行时对服务的日益增长的需求。例如,如果类的虚拟处理器变成了计算绑定或 I/O 绑定(意思是可以处理 CPU 工作或 I/O 请求的虚拟处理器的当前数量满足不了处理 CPU 工作或 I/O 请求数日益累积的需求),那么您可以为该类启动额外的虚拟处理器来进一步分布处理装入。
可以在数据库服务器运行时为这些类中的任何一个添加虚拟处理器。
当数据库服务器正在运行时,您可以删除 CPU 的虚拟处理器或用户定义类。
将虚拟处理器绑定到 CPU
可使用某些多处理器系统将进程绑定到特定 CPU。此功能称为处理器专用。
在数据库服务器支持处理器专用的多处理器计算机上,您可以将 CPU 虚拟处理器绑定到该计算机中特定的 CPU。当您将 CPU 虚拟处理器绑定到 CPU 时,虚拟处理器将互斥运行在该 CPU 上。此操作将提高虚拟处理器的性能,因为它减少了操作系统必须在进程间进行的切换量。将 CPU 虚拟处理器绑定到特定的 CPU 还可以使您隔离计算机上特定处理器的数据库工作,以将剩余的处理器释放给其他的工作。仅 CPU 虚拟处理器可以绑定到 CPU。
虚拟处理器如何为线程提供服务
在给定的时间中,虚拟处理器只可运行一个线程。虚拟处理器通过在多个线程之间切换来并发地为这些线程提供服务。虚拟处理器运行线程直到其中止。当一个线程中止时,虚拟处理器将切换到下一个已准备好运行的线程。虚拟处理器将继续此过程,并且最后在原始的线程准备好继续时返回到该线程。有些线程完成了它们的工作,虚拟处理器会启动新线程来处理新的工作。由于虚拟处理器持续在线程之间切换,它可以使得 CPU 持续处理。发生处理时的速度使虚拟处理器看上去就像同时在处理多个任务,而实际上也的确如此。
运行多个并发线程需要调度和同步以防一个线程干扰另一个线程的工作。虚拟处理器可以使用下列结构和方法协调多个线程的并发处理:
- 控制结构
- 上下文切换
- 堆栈
- 队列
- 互斥
这些主题描述虚拟处理器如何使用这些结构和方法。
控制结构
当客户机连接到数据库服务器时,数据库服务器创建会话结构(称为会话控制块)以保存有关连接和用户的信息。会话在客户机连接到数据库服务器时开始并在连接终止时结束。
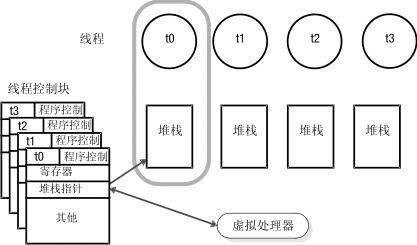
接下来,数据库服务器将创建线程结构(该线程结构被称为会话的线程控制块 (TCB)),并启动主线程(sqlexec)来处理客户机请求。当线程中止,即当它暂停并允许另一个线程运行时,虚拟处理器将保存有关线程控制块中线程状态的信息。此信息包括系统注册的进程内容、程序计数器(下一个要执行的指令的地址)以及堆栈指针。此信息组成线程的内容。
在大多数情况下,数据库服务器将在每个会话中运行一个主线程。然而,在它执行并行处理的情况下,它将为单台客户机创建多个会话线程以及多个相应的线程控制块。
上下文切换
通过上下文切换,虚拟处理器将从运行一个线程切换到运行另一个线程。当固定的时间量(时间片)期满时,数据库服务器不会像操作系统对进程那样预占一个正在运行的线程。 而是,线程会在下列点中的一个点上让步:
- 代码中预先确定的点
- 当线程在满足某个条件前不再可以执行时
当完成任务所需的处理量会引起其他线程等待一段长度过长的时间时,线程在预先确定的点中止。用于这些长时间运行的任务的代码包括处理中的策略点上对让步函数的调用。当线程执行这些任务之一时,它会在遇到让步函数调用时让步。然后,就绪队列中的其他线程将有机会运行。当下一次轮到原来的线程时,该线程将在对让步函数进行调用后立即重新在点上执行代码。对中止函数的预先确定的调用将允许数据库服务器在对性能最有利的点上中断线程。
当线程无法再继续它的任务时,它也会中止直到出现某种条件。例如,当线程等待磁盘 I/O 完成时、当等待来自客户机的数据时或当等待一个锁定或其他资源时,线程中止。
当一个线程中止时,虚拟处理器在线程控制块中保存其上下文。 然后,虚拟处理器将从一队就绪的线程中选择要运行的新线程、从该新线程的线程控制块中装入该新线程的上下文,然后在程序计数器中的新地址处开始执行。下图说明了虚拟处理器如何完成上下文切换。
图: 上下文切换:虚拟处理器如何从一个线程切换到另一个线程

堆栈
数据库服务器将在共享内存的虚拟部分中分配一个区域以便为线程所执行的函数存储非共享数据。此区域称为堆栈。
堆栈使虚拟处理器能够保护线程中非共享数据免遭并发执行相同代码的其他线程的覆盖。例如,如果几台客户机应用程序并发地执行 SELECT 语句,那么每台客户机的会话线程将在代码中执行许多同样的函数。如果线程没有专用堆栈,那么一个线程可能会覆盖属于函数中另一个线程的本地数据。
当虚拟处理器切换到新的线程时,它会为该线程从线程控制块中装入堆栈指针。堆栈指针将存储堆栈的开始地址。 然后,虚拟处理器可以将偏移量指定到在堆栈中存取数据的开始地址。该图说明了虚拟处理器如何使用堆栈来为会话线程分离非共享数据。
图: 虚拟处理器为每个用户分离非共享数据
队列
数据库服务器使用三种类型的队列来调度多个并发运行的线程的处理。
相同类的虚拟处理器将共享队列。有些时候,这将使线程能够在需要时从类中的一个虚拟处理器迁移到另一个虚拟处理器。
就绪队列
就绪队列将在当前的(正在运行的)线程中止时容纳已准备好运行的线程。 当一个线程让步时,虚拟处理器将从就绪队列中选取下一个具有适当优先级的线程。在该队列中,虚拟处理器处理在先进先出 (FIFO) 基础上具有相同优先级的线程。
在多处理器计算机上,如果您注意到线程正在一类的虚拟处理器的就绪队列中堆积(表示工作堆积的速度比虚拟处理器可以处理它的速度块),那么您可以启动该类的附加虚拟处理器以分发处理负载。
睡眠队列
睡眠队列将容纳特定的时间中没有工作要做的线程的上下文。使线程在指定的时间段或永久睡眠。
虚拟处理器的管理类 (ADM) 运行系统计时器和特殊的实用程序线程。此类中的虚拟处理器将自动创建并运行。没有配置参数会影响此类虚拟处理器。
ADM 虚拟处理器唤醒已休眠了指定时间段的线程。运行在 ADM 虚拟处理器中的线程以一秒为时间间隔来检查正在休眠的线程。 如果休眠的线程已休眠了指定时间段,那么 ADM 虚拟处理器将其移动到适当的就绪队列。正在睡眠指定时间段的线程也可以显式地由另一个线程唤醒。
永久睡眠的线程会在其有更多的工作要做时被唤醒。例如,当 CPU 虚拟处理器上运行的线程必须访问磁盘时,该线程会发出 I/O 请求,将其自身置于 CPU 虚拟处理器的休眠队列中,然后停止。当 I/O 线程通知 CPU 虚拟处理器 I/O 已经完成时,CPU 虚拟处理器调度原来的线程通过将该线程从休眠队列移动到就绪队列来继续处理。下图说明了数据库服务器线程如何排队执行数据库 I/O。
图: 数据库服务器线程如何排队执行数据库 I/O

等待队列
等待队列保存了必须等待特定事件才能继续运行的线程。例如,等待队列将协调线程对共享数据的访问。当用户线程尝试获取逻辑日志锁存器但发现锁存器由另一个用户所持有时,遭拒绝的线程会将其自身放在逻辑日志等待队列中。当拥有锁的线程准备好释放锁存器时,它会检查等待的线程,如果线程正在等待,它将唤醒等待队列中的下一个线程。
互斥
互斥(互相排斥),又称为锁存器,是数据库服务器用于同步多个线程对共享资源的访问的一种锁存机制。互斥与信号相似,一些操作系统使用后者来控制多个进程对共享数据的访问。然而,互斥比信号允许更高的并行度。
互斥是与共享资源(如缓冲区)关联的变量。线程必须在可以访问资源前获取资源的互斥。其他线程将不能访问该资源直到所有者将其释放。在互斥可用后,线程通过将其状态设置为使用状态而获得互斥。互斥的同步确保一次只有一个线程写入共享内存的区域。
虚拟处理器类
给定类的虚拟处理器只可以运行该类的线程。这些主题将描述每一类虚拟处理器执行的线程类型或处理类型。 还将说明如何确定必须为每一类运行的虚拟处理器的数量。
CPU 虚拟处理器
CPU 虚拟处理器运行所有的会话线程(这些线程处理来自 SQL 客户机应用程序的请求)和某些内部线程。内部线程执行数据库服务器的内部服务。 例如,侦听来自客户机应用程序的连接请求的线程就是一个内部线程。
每个 CPU 虚拟处理器可以具有与之相关联的专用内存高速缓存。每个专用内存高速缓存块由 1 到 32 个内存页组成,每个内存页大小为 4096 个字节。数据库服务器使用专用内存高速缓存来提高对内存块的访问时间。使用 VP_MEMORY_CACHE_KB 配置参数可启用专用内存高速缓存,并指定内存高速缓存的信息。
确定所需 CPU 虚拟处理器数
CPU 虚拟处理器的正确数量是保持繁忙(但并未繁忙到无法跟上进入的请求)的所有 CPU 虚拟处理器的数量。分配的 CPU 虚拟处理器数不得超过计算机中的硬件处理器数。
数据库服务器启动时,除非启用了 SINGLE_CPU_VP 配置参数,否则会自动将 CPU 虚拟处理器的数量增加到数据库服务器计算机上 CPU 处理器数量的一半。但是,可以根据您的系统调整 CPU VP 的数量。
当数据库服务器正在运行时,要评估 CPU 虚拟处理器的性能,请在一组时间周期中以固定的时间间隔重复以下命令:
onstat -g glo
如果将累积的 usercpu 和 syscpu 时间加在一起,将接近测试周期的 100% 实际耗用时间,如果您让一个可用的 CPU 运行它,请添加另一个 CPU 虚拟处理器。
可使用 VPCLASS 配置参数指定以下所有信息:
- 类要最初启动的虚拟处理器数
- 类要运行的最大虚拟处理器数
- CPU 类虚拟处理器的处理器专用
- 禁用优先级迟滞(如果适用)
使用 VPCLASS 配置参数可指定此信息。(如果已从非常旧的版本升级到 GBase 8s 的当前版本,请注意,必须使用 VPCLASS 配置参数,而不能使用已终止的 AFF_SPROC、AFFNPROCS、NOAGE、NUMCPUVPS 和 NUMAIOVPS 配置参数。此外,不能将 VPCLASS 参数与已终止的参数结合使用。例如,如果 onconfig 文件包含 NUMCPUVPS 参数,并且还包含 VPCLASS cpu 参数,那么您将接收到错误消息。)
在多处理器计算机上运行
如果您要在多处理器计算机上运行多个 CPU 虚拟处理器,请将 onconfig 文件中的 MULTIPROCESSOR 参数设置为 1。在将 MULTIPROCESSOR 设置为 1 时,数据库服务器将按适合多处理器计算机的方式执行锁定。有关设置多处理器方式的信息,请参阅《GBase 8s 管理员参考》中有关配置参数的章节。
在单处理器计算机上运行
如果您正在单个处理器计算机上运行数据库服务器,请将 MULTIPROCESSOR 配置参数设置为 0。 要运行只具有一个 CPU 虚拟处理器的数据库服务器,请将 SINGLE_CPU_VP 参数设置为 1。
将 MULTIPROCESSOR 设置为 0 可使数据库服务器绕过多处理器计算机上多个处理器所需的锁定。有关 MULTIPROCESSOR 配置参数的信息,请参阅《GBase 8s 管理员参考》。
将 SINGLE_CPU_VP 设置为 1 允许数据库服务器绕过某些互斥调用,这些互斥调用通常在运行多个 CPU 虚拟处理器时建立。
将 VPCLASS num 设置为 1 并将 SINGLE_CPU_VP 设置为 0 不会减少互斥调用的数量,即使数据库服务器仅启动一个 CPU 虚拟处理器。必须将 SINGLE_CPU_VP 设置为 1 以减少当您运行单个 CPU 虚拟处理器时执行的锁存器的量。
将 SINGLE_CPU_VP 参数设置为 1 会对数据库服务器施加两个重要限制,如下所示:
- 只允许一个 CPU 虚拟处理器。
当数据库服务器是在线模式时,不能添加 CPU 虚拟处理器。
- 不允许任何用户定义的类。(但是,用户仍然可以定义直接运行在 CPU VP 上的例程。)
在在线模式下添加和删除 CPU 虚拟处理器
当数据库服务器是在线模式时,您可以添加或删除 CPU 类虚拟处理器。
阻止优先级迟滞
有些操作系统将在累积处理时间时降低长时间运行的进程的优先级。操作系统的这种功能称为优先级迟滞。优先级迟滞可以导致数据库服务器进程的性能随着时间的流逝而降低。然而,在有些情况下,可使用操作系统禁用此功能并且将长时间运行的进程保持在高优先级中运行。
要确定优先级迟滞是否在您的计算机上可用,请检查在本指南『简介』中描述的安装随附的机器说明文件。
如果可通过操作系统禁用优先级迟滞,那么可以在 VPCLASS 配置参数中为优先级条目指定 noage 来禁用该功能。
处理器亲缘关系
数据库服务器支持将 CPU 虚拟处理器自动绑定到支持处理器亲缘关系的多处理器计算机上的处理器。您的数据库服务器分发手册将包含机器说明文件,该文件包含有关您的数据库服务器是否支持此功能的信息。当您将 CPU 虚拟处理器指定给特定 CPU 时,虚拟处理器只运行在该 CPU 上,但是其他进程也可以运行在该 CPU 上。
使用带有 aff 选项的 VPCLASS 配置参数可在支持它的多处理器计算机上实现处理器专用。
下图说明了处理器亲缘关系的概念。
图: 处理器亲缘关系

仅限 UNIX: 要查看 UNIX™ 平台上是否支持处理器亲缘关系,请参阅机器说明文件。
使用 VPCLASS 配置参数设置处理器亲缘关系
要使用 VPCLASS 配置参数设置处理器亲缘关系,可以指定要为其指定虚拟处理器的单个处理器或某一范围的处理器。指定某一范围处理器时,还可以指定范围内的递增值,用于指示将范围中的哪些 CPU 指定给虚拟处理器。例如,可以指定将虚拟处理器分配给范围 0-6 中的每隔一个 CPU,从 CPU 0 开始。
VPCLASS CPU,num=4,aff=(0-6/2)
虚拟处理器分配给 CPU 0、2、4、6。
如果指定 VPCLASS CPU,num=4,aff=(1-10/3),将虚拟处理器分配给范围 1-10 中的每隔两个 CPU,从 CPU 1 开始。虚拟处理器分配给 CPU 1、4、7、10。
指定多个值或范围时,这些值和范围不必是递增的,也无需按照任何特定顺序指定。例如,可以指定 aff=(8,12,7-9,0-6/2)。
数据库服务器将 CPU 虚拟处理器分配给循环模式中的 CPU,从您在 aff 选项中指定的第一个处理器编号开始。如果指定的 CPU 虚拟处理器数多于实际的 CPU 数量,那么数据库服务器继续从首个 CPU 开始分配 CPU 虚拟处理器。例如,假设您指定了以下 VPCLASS 设置:
VPCLASS cpu,num=8,aff=(4-7)
数据库服务器会进行以下分配:
- CPU 虚拟处理器编号 0 到 CPU 4
- CPU 虚拟处理器编号 1 到 CPU 5
- CPU 虚拟处理器编号 2 到 CPU 6
- CPU 虚拟处理器编号 3 到 CPU 7
- CPU 虚拟处理器编号 4 到 CPU 4
- CPU 虚拟处理器编号 5 到 CPU 5
- CPU 虚拟处理器编号 6 到 CPU 6
- CPU 虚拟处理器编号 7 到 CPU 7
有关更多信息,请参阅《GBase 8s 管理员参考》中的 VPCLASS 配置参数。
用户定义的虚拟处理器类
可以定义特殊的虚拟处理器类以运行用户定义的例程。通常可编写用户定义的例程以支持用户定义的数据类型。 如果您不想要用户定义的例程运行在 CPU 类(这是缺省值)中,那么您可以将它指定给虚拟处理器 (VP) 的用户定义类。用户定义的虚拟处理器类还称为扩展虚拟处理器。
这些主题提供了以下有关用户定义的虚拟处理器的信息:
- 何时在用户定义的 VP 而不是 CPU VP 中运行 C 语言 UDR
- 如何将 C 语言 UDR 指定给一个特定的用户定义 VP 类
- 当数据库服务器处于在线模式时,如何添加和删除用户定义的 VP
确定所需的用户定义的虚拟处理器数
可以指定操作系统允许的任意数量的用户定义虚拟处理器。如果运行许多 UDR 或带有 UDR 的并行 PDQ 查询,那么必须配置多个用户定义的虚拟处理器。
用户定义的虚拟处理器
用户定义的虚拟处理器类可保护数据库服务器免遭行为不良的用户定义例程的破坏。行为不良的用户定义的例程至少有以下特征之一:
- 不会为其他线程让出控制权
- 进行分块操作系统调用
- 修改全局 VP 状态
行为良好的 C 语言 UDR 不具有这些特征。 仅在 CPU VP 中运行行为良好的 C 语言 UDR。
在 CPU VP 中执行行为不良的例程会导致对数据库服务器操作的严重干扰,并且可能导致其失败或行为反常。此外,例程本身可能不会产生正确的结果。
要确保安全执行,将任何行为不良的用户定义的例程指定给用户定义的虚拟处理器类。 用户定义的 VP 除去 CPU VP 类上的以下编程限制:
- 需要定期让出处理器
- 需要终止阻塞 I/O 调用
在用户定义的虚拟处理器类中运行的函数无需让出处理器,并且它们可能发出直接的文件系统调用,用于阻止虚拟处理器的进一步处理,直到 I/O 完成。
用户查询的正常处理不受 C 语言 UDR 不良行为的影响,因为这些 UDR 不在 CPU 虚拟处理器中执行。
指定用户定义的虚拟处理器
带有 vpclass 选项的 VPCLASS 参数定义用户定义的 VP 类。还可以指定非让步的用户定义的虚拟处理器。有关更多信息,请参阅指定虚拟处理器类和《GBase 8s 管理员参考》中有关配置参数的主题。
将 UDR 指定给用户定义的虚拟处理器类
SQL CREATE FUNCTION 语句注册用户定义的例程。例如,以下 CREATE FUNCTION 语句注册用户定义的例程 GreaterThanEqual(),并指定对于该例程的调用由名为 UDR 的用户定义的 VP 类执行:
CREATE FUNCTION GreaterThanEqual(ScottishName, ScottishName)
RETURNS boolean
WITH (CLASS = UDR )
EXTERNAL NAME ‘/usr/lib/objects/udrs.so'
LANGUAGE C
要执行该函数,onconfig 文件必须包含定义 UDR 类的 VPCLASS 参数。否则,对 GreaterThanEqual 函数的调用将失败。
CLASS 例程修饰符可为 VP 类指定任何名称。注册 UDR 时,无需有该类名。然而,尝试运行 UDR 且其指定了用于执行的用户定义 VP 类时,此类必须存在并且必须为其指定虚拟处理器。
要配置 UDR 类,请在 onconfig 文件中包含如下类似行。此行将配置带有两个虚拟处理器并且没有优先级迟滞的 UDR 类。
VPCLASS UDR ,num=2,noage
前面的行将 UDR VP 类定义为生成的 VP 类;即该 VP 类允许 C 语言 UDR 生成必须访问 UDR VP 类的其他线程。有关如何使用 VPCLASS 配置参数的更多信息,请参阅 《GBase 8s 管理员参考》。
有关 CREATE FUNCTION 语句的更多信息,请参阅《GBase 8s SQL 指南:语法》。
在在线模式下添加和删除用户定义的虚拟处理器
可以在数据库服务器处于在线状态时添加或删除用户定义的类中的虚拟处理器。
Java 虚拟处理器
Java™ UDR 和 Java 应用程序在专门的虚拟处理器(称为 Java 虚拟处理器 (JVP))上运行。JVP 在其代码中嵌入 Java 虚拟机 (JVM)。JVP 与 CPU VP 具有相同的功能,CPU VP 可以处理所有的 SQL 查询。
可以指定操作系统允许的任意数量的 JVP。如果运行许多 Java 或带有 Java UDR 的并行 PDQ 查询,那么必须配置更多 JVP。
使用带有 jvp 关键字的 VPCLASS 配置参数可配置 JVP。
磁盘 I/O 虚拟处理器
以下虚拟处理器的类执行磁盘 I/O:
- PIO(物理日志 I/O)
- LIO(逻辑日志 I/O)
- AIO(异步 I/O)
- CPU(内核异步 I/O)
除非物理日志文件和逻辑日志文件位于原始磁盘空间中,并且数据库服务器已实现 KAIO,否则 PIO 类将执行所有到物理日志文件的 I/O,而 LIO 类执行所有到逻辑日志文件的 I/O。
在不支持 KAIO 的操作系统上,数据库服务器使用虚拟处理器的 AIO 类来执行与物理或逻辑日志记录不相关的数据库 I/O。
当 KAIO 可用于平台时,数据库服务器使用 CPU 类来执行 KAIO。如果数据库服务器实现 KAIO,那么 KAIO 线程对原始的磁盘空间执行所有的 I/O,包括物理日志和逻辑日志的 I/O。
仅限 UNIX: 要了解您的 UNIX™ 平台是否支持 KAIO,请参阅机器说明文件。
有关非日志记录 I/O 的更多信息,请参阅异步的 I/O。
I/O 优先级
一般来说,数据库服务器通过将不同类型的 I/O 指定给虚拟处理器的不同类,并将优先级指定给非日志记录 I/O 队列来划分磁盘 I/O 的优先级。例如,划分优先级可确保高优先级日志 I/O 绝不会排列在对临时文件进行写操作的后面,该写操作具有低优先级。数据库服务器会对于其执行的不同类型的磁盘 I/O 划分优先级,如下表所示。
表 1. 数据库服务器为磁盘 I/O 划分优先级的方法
| 优先级 | I/O 类型 | VP 类 |
|---|---|---|
| 第 1 级 | 逻辑日志 I/O | CPU 或 LIO |
| 第 2 级 | 物理日志 I/O | CPU 或 PIO |
| 第 3 级 | 数据库 I/O | CPU 或 AIO |
| 第 3 级 | 页清除 I/O | CPU 或 AIO |
| 第 3 级 | 预读取 I/O | CPU 或 AIO |
逻辑日志 I/O
虚拟处理器的 LIO 类对以下情况中的逻辑日志文件执行 I/O:
- 没有实现 KAIO。
- 逻辑日志文件位于熟磁盘空间。
仅当实现了 KAIO 并且逻辑日志文件在原始的磁盘空间中时,数据库服务器才会使用 CPU 虚拟处理器中的 KAIO 线程来对逻辑日志执行 I/O。
逻辑日志文件将存储使数据库服务器能够回滚事务并从系统故障中恢复的数据。对逻辑日志文件的 I/O 是数据库服务器执行的最高优先级的磁盘 I/O。
如果逻辑日志文件存在于非镜像的数据库空间中,那么数据库服务器只运行一个 LIO 虚拟处理器。如果逻辑日志文件存在于镜像的数据库空间中,那么数据库服务器运行两个 LIO 虚拟处理器。此虚拟处理器类没有任何与其关联的参数。
物理日志 I/O
虚拟处理器的 PIO 类对以下情况中的物理日志文件执行 I/O:
- 没有实现 KAIO。
- 物理日志文件存储在已缓冲的文件块中。
仅当实现了 KAIO 并且物理日志文件存在于原始的磁盘空间中时,数据库服务器才会使用 CPU 虚拟处理器中的 KAIO 线程来对物理日志执行 I/O。物理日志文件将存储自上一个检查点以来已更改的数据库空间页的前映像。在恢复开始时,数据库服务器会在处理来自逻辑日志的事务前,使用物理日志文件将前映像复原到自上一个检查点以来已更改的数据库空间页。对物理日志文件的 I/O 是继对逻辑日志文件的 I/O 之后第二高的优先级 I/O。
如果物理日志文件存在于非镜像的数据库空间中,那么数据库服务器只运行一个 PIO 虚拟处理器。 如果物理日志文件存在于镜像的数据库空间中,那么数据库服务器运行两个 PIO 虚拟处理器。此虚拟处理器类没有任何与其关联的参数。
异步的 I/O
数据库服务器异步执行数据库 I/O,这意味着 I/O 将独立于请求 I/O 的线程进行排列和执行。异步地执行 I/O 允许建立请求的线程当 I/O 正在执行时继续工作。
数据库服务器使用以下某个设施异步执行所有的数据库 I/O:
- AIO 虚拟处理器
- 平台(该平台支持 KAIO)上的 KAIO
数据库 I/O 包含 SQL 语句的 I/O、预读 I/O、页清除 I/O 以及检查点 I/O。
内核异步 I/O
当以下条件存在时,数据库服务器使用 KAIO:
- 计算机和操作系统对其支持。
- 已实现性能提高。
- I/O 是对于原始的磁盘空间的。
数据库服务器通过在 COU 虚拟处理器上运行 KAIO 线程来实现 KAIO。KAIO 线程通过建立对操作系统(该操作系统可执行独立于虚拟处理器的 I/O)的系统调用来执行 I/O。KAIO 线程能够对于磁盘 I/O 产生比 AIO 虚拟处理器产生的更好的性能,因为该线程不需要在 CPU 和 AIO 虚拟处理器之间切换。
仅限 UNIX: 当 GBase 8s 具有支持此功能的平台的端口时,GBase 8s 将实现 KAIO。数据库服务器管理员不用配置 KAIO。要查看 KAIO 是否在您的平台上受支持,请参阅机器说明文件。
仅限 Linux: 内核异步 I/O (KAIO) 在缺省情况下启用。 您可以通过在启动服务器的进程环境中指定 KAIOOFF=1 来禁用内核异步 I/O。
在 Linux™ 上,并行 KAIO 请求具有最大数量的系统范围限制。/proc/sys/fs/aio-max-nr 文件包含该值。Linux™ 系统管理员可以增加该值,例如,通过使用该命令:
# echo new_value > /proc/sys/fs/aio-max-nr
所有操作系统进程的已分配请求的当前数量在 /proc/sys/fs/aio-nr 文件中可见。
在缺省情况下,Datebse Server 分配请求的最大数量的一半,并将它们同样分配给已配置 CPU 虚拟处理器的数量。 您可以使用环境变量 KAIOON 来控制分配给每个 CPU 虚拟处理器的请求数量。在启动 GBase 8s 之前,通过将 KAIOON 设置为必需值来执行此操作。
KAIOON 的最小值是 100。如果 Linux 即将耗尽 KAIO 资源,例如当动态地添加许多 CPU 虚拟处理器时,online.log 文件中将打印警告。如果发生了此情况,那么 Linux 系统管理员必须按照上述方式添加 KAIO 资源。
AIO 虚拟处理器
如果平台不支持 KAIO 或如果 I/O 是缓冲区文件块,那么数据库服务器将通过虚拟处理器的 AIO 类执行数据库 I/O。所有的 AIO 虚拟处理器同等服务其类中的所有 I/O 请求。
数据库服务器将根据块的文件名为每个磁盘块指定一个队列(有时称为 gfd 队列)。数据库服务器根据最小化磁头移动算法预订队列中的 I/O 请求。AIO 虚拟处理器为工作在循环法方式下暂挂的队列提供服务。
所有其他的非阻塞 I/O 排列在 AIO 队列中。
使用带有 aio 关键字的 VPCLASS 参数可指定数据库服务器初次启动的 AIO 虚拟处理器的数量。有关 VPCLASS 的信息,请参阅《GBase 8s 管理员参考》中有关配置参数的章节。
当数据库服务器是在线模式时,您可以启动其他的 AIO 虚拟处理器。
当数据库服务器处于在线模式时,您不能删除 AIO 虚拟处理器。
自动增加和降低 AIO 虚拟处理器的数量
当服务器检测到 AIO VP 的处理速度跟不上 I/O 工作负载时,AUTO_AIOVPS 配置参数启用或禁用数据库服务器自动增加 AIO VP 和 flusher 线程的数目。如果您想要手动调整该数值,请禁用此参数。有关设置减少此参数的详细信息,请参阅《GBase 8s 管理员参考》。
所需的 AIO 虚拟处理器数
分配 AIO 虚拟处理器的目的是分配足够的虚拟处理器从而可以保持 I/O 请求队列的长度比较短;即,队列中具有的 I/O 请求要尽可能少。当 gfd 队列总是很短时,它指示对于磁盘设备的 I/O 正在以与产生请求一样快的速度进行处理。
onstat-g ioq 命令显示了有关 I/O 队列的长度和其他统计信息。可以使用此命令为 AIO 虚拟处理器监视 gfd 队列的长度。
一个 AIO 虚拟处理器可能已足够:
- 如果数据库服务器在您的平台上实现内核异步 I/O (KAIO) 并且所有的数据库空 间都是由原始的磁盘空间组成。
- 如果您的文件系统支持用于数据库空间块的页大小的直接 I/O 并且您使用直接 I/O对每个活动的数据库空间分配两个由缓冲区文件块组成的 AIO 虚拟处理器。
- 如果数据库服务器实现 KAIO,但是您正在使用块的某些缓冲区文件
- 如果系统不支持块的 KAIO。
如果 KAIO 不在您的平台上实现,请为数据库服务器经常访问的每个磁盘分配两个 AIO 虚拟处理器。
如果您使用熟文件,并且如果您使用 DIRECT_IO 配置参数启用直接 I/O,那么您可能可以减少 AIO 虚拟处理器的数量。
如果数据库服务器实现了 KAIO 并且使用 DIRECT_IO 配置参数启用了直接 I/O,那么 GBase 8s 将尝试使用 KAIO,这样可能就不需要多个 AIO 虚拟处理器。 但是,即使启用了直接 I/O,如果文件系统不支持直接 I/O 或 KAIO,那么仍必须为组成已缓冲文件块或不使用 KAIO 的每个活动的数据库空间分配两个 AIO 虚拟处理器。
临时数据库空间不使用直接 I/O。如果您拥有临时数据库空间,那么可能需要多个 AIO 虚拟处理器。
分配足够的 AIO 虚拟处理器以满足 I/O 请求的最大值。通常来说,分配过多的 AIO 虚拟处理器不会产生不利影响。
当服务器检测到 AIO 虚拟处理器无法满足 I/O 工作负载时,AUTO_AIOVPS 配置参数可使数据库服务器自动增加 AIO 虚拟处理器和 page-cleaner 线程的数量。
网络虚拟处理器
如客户机/服务器通信中所述,客户机可以下列方式连接到数据库服务器:
- 通过网络连接
- 通过管道
- 通过共享内存
网络连接可以由远程计算机上的客户机建立,或由本地计算机上的客户机通过模拟来自远程计算机的连接(称为本地回送连接)建立。
指定网络连接
通常来说,DBSERVERNAME 和 DBSERVERALIASES 参数定义在 sqlhosts 文件或注册表中具有对应条目的 dbservername。sqlhosts 中的每个 dbservername 都有指定接口/协议组合的 nettype 条目。数据库服务器为每个唯一的 nettype 条目运行一个或多个轮询线程。
NETTYPE 配置参数为接口/协议组合提供可选配置信息。可以将其用于为接口/协议组合指定多个轮询线程,也可用于指定运行轮询线程的虚拟处理器类(CPU 或 NET)。
有关 NETTYPE 配置参数的完整描述,请参阅《GBase 8s 管理员参考》。
在 CPU 或网络虚拟处理器上运行轮询线程
轮询线程可以在 CPU 虚拟处理器或网络虚拟处理器上运行。通常来说,特别在单个处理器计算机上,轮询线程在 CPU 虚拟处理器上的运行更加高效。然而,在具有大量远程客户机的多处理器计算机上,这种情况可能并不成立。
NETTYPE 参数具有名为 vp class 的可选条目,可用于指定 CPU 或 NET 以分别表示 CPU 或网络虚拟处理器类。
如果没有为与 DBSERVERNAME 变量关联的接口/协议组合(轮询线程)指定虚拟处理器类,该类将缺省为 CPU。数据库服务器假设与 DBSERVERNAME 关联的接口/协议组合是效率最高的主接口/协议组合。
对于其他的接口/协议组合,如果没有指定 vp class,那么缺省值将是 NET。
当数据库服务器处于在线模式时,您无法删除正在运行轮询或侦听线程的 CPU 虚拟处理器。
必须仔细区分用于网络连接的轮询线程和用于共享内存连接的轮询线程,后者在每个 CPU 虚拟处理器上只能运行一个。TCP 连接必须仅处于网络虚拟处理器中,并且您必须只有维持响应所需的最少的 TCP 连接数。共享内存连接必须仅处于 CPU 虚拟处理器中,并在每个 CPU 虚拟处理器中运行。
指定联网虚拟处理器数
每个轮询线程需要单独的虚拟处理器,因此当您为接口/协议组合指定轮询线程数量时,您将间接地指定连网虚拟处理器的数量并指定这些处理器将由 NET 类运行。如果您为 vp class 指定 CPU 时,您必须分配一个足够大数量的 CPU 虚拟处理器以运行轮询线程。如果数据库服务器没有使 CPU 虚拟处理器运行 CPU 轮询线程,它将启动指定类的网络虚拟处理器运行轮询线程。
对于大多数系统,每个接口/协议组合有一个轮询线程以及一个虚拟处理器就足够了。对于具有 200 或更多网络用户的系统,运行额外的网络虚拟处理器可能提高吞吐量。在这种情况下,必须进行实验以便确定每个接口/协议组合的最佳虚拟处理器数。
为客户机/服务器连接指定侦听和轮询线程
启动数据库服务器时,oninit 进程将为使用 onconfig 文件中的 DBSERVERNAME 和 DBSERVERALIASES 参数指定的每个 dbservername 启动内部线程,这些线程称为侦听线程。要为这些数据库服务器名条目中的每一个指定侦听端口,请在 sqlhosts 中为其指定 hostname 和 service name 条目的唯一组合。例如,下表中显示的 sqlhosts 文件条目或注册表项将使数据库服务器 soc_ol1 为主机或网络地址 myhost 上的 port1 启动侦听线程。
表 1. 每个侦听端口的侦听线程
| dbservername | nettype | hostname | 服务名 |
|---|---|---|---|
| soc_ol1 | onsoctcp | myhost | port1 |
侦听线程打开端口并请求指定接口/协议组合的轮询线程之一监视客户机请求的端口。轮询线程为正在使用的连接运行于 CPU 虚拟处理器或网络虚拟处理器中。有关轮询线程数的信息,请参阅指定联网虚拟处理器数。
有关如何指定接口/协议组合的轮询线程是在 CPU 虚拟处理器中运行还是在网络虚拟处理器中运行的信息,请参阅在 CPU 或网络虚拟处理器上运行轮询线程以及《GBase 8s 管理员参考》中的 NETTYPE 配置参数。
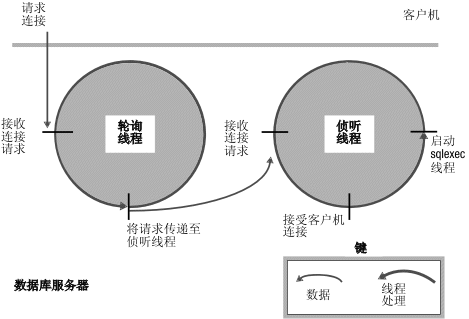
当轮询线程从客户机接收到连接请求,它会将请求传递给该端口的侦听线程。侦听线程将认证用户,建立到数据库服务器的连接,然后启动 sqlexec 线程,该线程是为客户机执行主处理的会话线程。下图说明了侦听线程和轮询线程在建立与客户机应用程序的连接时的角色。
图: 轮询线程和侦听线程在与客户机连接时的角色
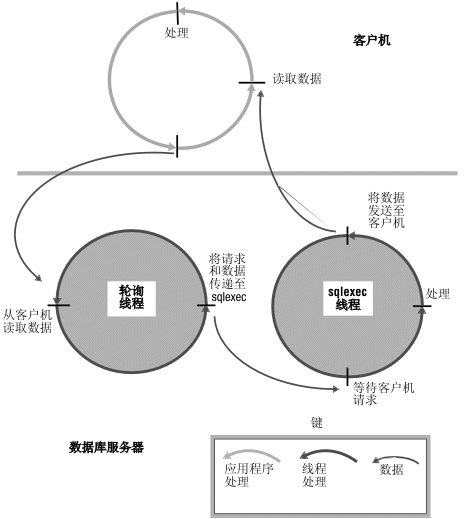
轮询线程等待来自客户机的请求,并将这些请求放在共享内存以便由sqlexec 线程处理。 对于网络连接,轮询线程将消息放在共享内存全局池中的队列中。然后,轮询线程将唤醒客户机的 sqlexec 线程以处理该请求。只要可能,sqlexec 线程都会直接写回客户机而无需轮询线程的帮助。通常,轮询线程从客户机读取数据,然后 sqlexec 线程将数据发送到客户机。
仅限 UNIX: 对于共享内存连接,轮询线程将该消息放在共享内存的通信部分中。
下图说明了轮询线程和 sqlexec 线程在与客户机应用程序通信时执行的基本任务。
图: 轮询线程和 sqlexec 线程在与客户机应用程序通信时的角色
快速轮询
如果操作系统平台支持快速轮询,那么使用 FASTPOLL 配置参数可启用或禁用网络的快速轮询。如果有大量连接,快速轮询会很有用。例如,如果数据库服务器具有 300 多个并行连接,那么可以启用 FASTPOLL 配置参数以获取更好的性能。可通过将 FASTPOLL 配置参数设置为 1 来启用快速轮询。
如果您的操作系统不支持快速轮询,GBase 8s 将忽略 FASTPOLL 配置参数。
多个侦听线程
可以通过使用多个侦听线程来提高连接请求的服务。
如果数据库服务器无法为带有单个端口和相应侦听线程的给定接口/协议组合提供令人满意的连接请求服务,那么可以通过以下方法改进对连接请求的服务:
- 为其他端口添加侦听线程。
- 向同一个端口添加侦听线程(前提是有 onimcsoc 或 onsoctcp 协议)
- 再添加一块网络接口卡。
- 通过使用 SQL 管理 API 或 onmode -P 命令,动态启动、停止或重新启动 SOCTCP 或 TLITCP 网络协议的侦听线程。
如果 onsoctcp 协议的一个端口有多个侦听线程,并且 CPU VP 连接正忙,那么数据库服务器可以接受新连接。
添加侦听线程
启动数据库服务器时,oninit 进程将为具有使用 DBSERVERNAME 和 DBSERVERALIASES 配置参数指定的服务器名称和服务器别名的服务器启动侦听线程。可以为其他端口添加侦听线程。
还可以为 onimcsoc 或 onsoctcp 的一个服务(端口)设置多个侦听线程。
要为附加端口添加侦听线程,您必须首先使用 DBSERVERALIASES 参数来指定每个端口的 dbservername。例如,下图中 DBSERVERALIASES 参数为标识为 soc_ol1 的数据库服务器实例另外定义了两个 dbservername:soc_ol2 和 soc_ol3。
DBSERVERNAME soc_ol1
DBSERVERALIASES soc_ol2,soc_ol3
为数据库服务器定义了其他 dbservername 之后,必须在 sqlhosts 文件或注册表中为每个 dbservername 指定接口/协议组合与端口。每个端口将由 hostname 和 servicename 条目的唯一组合标识。 例如,下表中显示的 sqlhosts 条目会使数据库服务器为 onsoctcp 接口/协议组合启动三个侦听线程,每个定义的端口一个线程。
表 1. 要侦听单个接口/协议组合的多个端口的 sqlhosts 条目
| dbservername | nettype | hostname | 服务名 |
|---|---|---|---|
| soc_ol1 | onsoctcp | myhost | port1 |
| soc_ol2 | onsoctcp | myhost | port2 |
| soc_ol3 | onsoctcp | myhost | port3 |
如果包含了接口/协议组合的 NETTYPE 参数,它将应用于接口/协议组合的所有连接。 换句话说,如果上表中存在 onsoctcp 的 NETTYPE 参数,那么该参数将应用于所有显示的连接。在本例中,数据库服务器为 onsoctcp 接口/协议组合运行一个轮询线程,直到指定了更多的 NETTYPE 参数。有关 sqlhosts 文件中的条目或注册表中的项的更多信息,请参阅连接文件。
为 onimcsoc 或 onsoctcp 协议的一个端口设置多个侦听线程
要为 onimcsoc 或 onsoctcp 协议的一个服务(端口)设置多个侦听线程,请执行以下操作:
- DBSERVERNAME
- - DBSERVERALIASES
- ,
例如:
- 要为 DBSERVERNAME 为 ifx 的服务器启用两个侦听线程,请指定:
DBSERVERNAME ifx-2
- 要为 DBSERVERALIASES 为 ifx_a 和 ifx_b 的服务器启用两个侦听线程,请指定:
DBSERVERALIASES ifx_a-2,ifx_b-2
添加网络接口卡
可以添加网络接口卡来提高性能或将数据库服务器连接到多个网络。
如果主机的网络接口卡无法提供令人满意的连接请求服务,您可能希望提高性能。
要支持多块网络接口卡,您必须在 sqlhosts 中为每块卡指定一个唯一的主机名(网络地址)。
例如,通过使用添加侦听线程中显示的同一个 dbservernames,下表中显示的 sqlhosts 文件条目或注册表项将使数据库服务器为相同接口/协议组合启动三个侦听线程(如添加侦听线程中的条目所执行的操作)。 但是,在此情况下,两个线程要侦听一个接口卡 (myhost1) 上的端口,而第三个线程要侦听第二个接口卡 (myhost2) 上的端口。
表 1. 为 onsoctcp 接口/协议组合的两块网络接口卡提供支持的 sqlhosts 条目示例
| dbservername | nettype | hostname | 服务名 |
|---|---|---|---|
| soc_ol1 | onsoctcp | myhost1 | port1 |
| soc_ol2 | onsoctcp | myhost1 | port2 |
| soc_ol3 | onsoctcp | myhost2 | port1 |
动态启动、停止或重新启动侦听线程
可以为 SOCTCP 或 TLITCP 网络协议动态启动、停止或停止并启动侦听线程,而不必中断现有连接。 例如,您可能希望停止不响应的侦听线程,然后启动新侦听线程,而同时不希望关闭其他正在正常执行的服务器。
侦听线程必须在服务器的 sqlhosts 文件中定义。如有必要,可在启动、停止或重新启动侦听线程之前,修改 sqlhosts 条目。
要动态启动、停止或重新启动侦听线程,请执行以下操作:
- 运行以下某个 onmode -P 命令:
- onmode -P start server_name
- onmode -P stop server_name
- onmode -P restart server_name
- 此外,如果已直接或远程连接到 sysadmin 数据库,那么可运行以下某个命令:
- 带 start listen 自变量的 admin() 或 task() 命令,格式如下
EXECUTE FUNCTION task("start listen", "_server_name_");
- 带 stop listen 自变量的 admin() 或 task() 命令,格式如下
EXECUTE FUNCTION task("stop listen" ,"_server_name_");
- 带 restart listen 自变量的 admin() 或 task() 命令,格式如下
EXECUTE FUNCTION task("restart listen", "_server_name_");
例如,以下任一命令均为名为 ifx_serv2 的服务器启动新侦听线程:
onmode -P start ifx_serv2
EXECUTE FUNCTION task("start listen", "ifx_serv2");
通信支持模块虚拟处理器
虚拟处理器的通信支持模块 (CSM) 类执行通信支持服务和通信支持模块函数。
除非将通信支持模块设置为 GSSCSM 来支持单点登录,否则数据库服务器会启动与 CPU 虚拟处理器启动数量相同的 CSM 虚拟处理器。如果通信支持模块为 GSSCSM,数据库服务器将仅启动一个 CSM 虚拟处理器。
有关通信支持服务的更多信息,请参阅客户机/服务器通信。
加密虚拟处理器
如果没有在 onconfig 配置文件中定义 VPCLASS 参数的 encrypt 选项,那么在首次调用为列级别加密定义的任何加密或解密功能时,数据库服务器将启动一个 ENCRYPT VP。您可以根据需要定义多个 ENCRYPT VP 以缩短启动数据库服务器所需的时间。
使用带有 encrypt 关键字的 VPCLASS 配置参数可配置加密 VP。例如,要添加 5 个 ENCRYPT VP,请如下所示在 onconfig 文件中添加信息:
VPCLASS encrypt,num=5
您可使用 onmode 实用程序修改相同的信息,如下所示:
onmode -p 5 encrypt
有关更多信息,请参阅《GBase 8s 管理员参考》中的配置参数和 onmode 实用程序主题。
光虚拟处理器
虚拟处理器的可选类 (OPT) 仅与 Optical Subsystem 一起使用。如果 STAGEBLOB 配置参数存在,那么 Optical Subsystem 在可选类中启动一个虚拟处理器。
审计虚拟处理器
通过将 onconfig 文件中的 ADTMODE 参数设置为 1 来打开审计方式时,数据库服务器将启动审计类 (ADT) 中的一个虚拟处理器。
综合性虚拟处理器
综合性虚拟处理器将为系统调用的请求(如获取有关当前用户或主机系统名的信息)提供服务,这些系统调用可能需要非常大的堆栈。此虚拟处理器上只可运行一个线程;该线程将通过 128 KB 的堆栈执行。
Basic Text Search 虚拟处理器
要运行 Basic Text Search 查询,需要使用 Basic Text Search 虚拟处理器。
必须先创建 Basic Text Search (BTS) 虚拟处理器,然后才能创建 Basic Text Search 索引并对其运行查询。
创建 Basic Text Search 索引时,会自动添加 Basic Text Search 虚拟处理器。
Basic Text Search 虚拟处理器运行时不会让步;它一次处理一个索引操作。要同时运行多个 Basic Text Search 索引操作和查询,请创建额外的 Basic Text Search 虚拟处理器。
将 VPCLASS 配置参数与 BTS 关键字一起使用以配置 Basic Text Search 虚拟处理器。例如,要添加五个 BTS 虚拟处理器,请将以下行添加到 onconfig,然后重新启动数据库服务器:
VPCLASS bts,num=5
使用 onmode -p 命令可动态添加 BTS 虚拟处理器,例如:
onmode -p 5 bts
MQ 消息传递虚拟处理器
要使用 MQ 消息传递,需要 MQ 虚拟处理器。
必须先创建 MQ 虚拟处理器,然后才能使用 MQ 消息传递。
执行 MQ 消息传递事务时,将自动创建 MQ 虚拟处理器。
MQ 虚拟处理器运行时不带生成器功能,所以一次处理一个操作。要同时执行多个 MQ 消息传递事务,请创建多个 MQ 虚拟处理器。
在 VPCLASS 配置参数中使用 MQ 关键字可配置 MQ 虚拟处理器。例如,要添加五个 MQ 虚拟处理器,请将以下行添加到 onconfig,然后重新启动数据库服务器:
VPCLASS mq,noyield,num=5
有关 VPCLASS 配置参数的更多信息,请参阅《GBase 8s 管理员参考》。有关 MQ 消息传递的更多信息,请参阅《GBase 8s Database Extensions 用户指南》。
Web 要素服务虚拟处理器
要为地理空间数据使用 Web 要素服务,需要 Web 要素服务虚拟处理器。
必须先创建 WFS 虚拟处理器,然后才能使用 WFS。
运行 WFS 例程时,将自动创建 WFS 虚拟处理器。
WFS 虚拟处理器运行时不带生成器功能,所以一次处理一个操作。要同时运行多个 WFS 例程,请创建多个 WFS 虚拟处理器。
在 VPCLASS 配置参数中使用 WFSVP 关键字可配置 WFS 虚拟处理器。例如,要添加五个 WFS 虚拟处理器,请将以下行添加到 onconfig,然后重新启动数据库服务器:
VPCLASS wfsvp,noyield,num=5
有关 VPCLASS 配置参数的更多信息,请参阅《GBase 8s 管理员参考》。有关 WFS 的更多信息,请参阅《GBase 8s Database Extensions 用户指南》。
XML 虚拟处理器
要执行 XML 发布,需要 XML 虚拟处理器。
必须先创建 XML 虚拟处理器,然后才能执行 XML 发布。
运行 XML 函数时,将自动创建 XML 虚拟处理器。
XML 虚拟处理器一次只能运行一个 XML 函数。要同时运行多个 XML 函数,请创建多个 XML 虚拟处理器。
在 VPCLASS 配置参数中使用 IDSXMLVP 关键字可配置 XML 虚拟处理器。例如,要添加五个 XML 虚拟处理器,请将以下行添加到 onconfig,然后重新启动数据库服务器:
VPCLASS idsxmlvp,num=5
使用 onmode -p 命令可动态添加 XML 虚拟处理器,例如:
onmode -p 5 idsxmlvp
有关 VPCLASS 配置参数和 onmode 实用程序的更多信息,请参阅《GBase 8s 管理员参考》。有关 XML 发布的更多信息,请参阅《GBase 8s Database Extensions 用户指南》。
管理虚拟处理器
这些主题将描述如何设置会影响数据库服务器虚拟处理器的配置参数,以及如何启动和停止虚拟处理器。
有关虚拟处理器类的描述以及有关必须为每个类指定多少虚拟处理器的建议,请参阅虚拟处理器和线程。
设置虚拟处理器配置参数
以 root 或 gbasedbt 用户身份,使用文本编辑器为数据库服务器虚拟处理器设置配置参数。
要实现对配置参数所做的任何更改,您必须关闭并重新启动数据库服务器。有关更多信息,请参阅设置共享内存。
使用文本编辑器设置虚拟处理器参数
您可以随时使用文本编辑器程序来设置 ONCONFIG 参数。可以使用编辑器定位希望更改的参数,输入新的值,然后重新将文件写入磁盘。
下表列出了用于配置虚拟处理器的 ONCONFIG 参数。有关这些参数如何影响虚拟处理器的更多信息,请参阅虚拟处理器类。
表 1. 用于配置虚拟处理器的配置参数
| 参数 | 子参数 | 用途 |
|---|---|---|
| MULTIPROCESSOR | 指定在多处理器计算机上运行 | |
| NETTYPE | 指定网络协议线程(和虚拟处理器)的参数 | |
| SINGLE_CPU_VP | 指定运行单个 CPU 虚拟处理器 | |
| VPCLASS | adm kio shm adt lio soc aio msc str cpu ntk tli encrypt opt jvp pio | 指定虚拟处理器的预定义类名。例如,jvp 指定的是 Java™ 虚拟处理器 (JVP)。 |
| VPCLASS | num=number | 指定数据库服务器启动的指定类的虚拟处理器数 |
| VPCLASS | max=number | 指定类所允许的最大虚拟处理器数 |
| VPCLASS | noage | 指定禁用迟滞优先级 |
| VPCLASS | aff = ( processor_number, start_range- end_range, start_range - end_range / increment ) | 指定 CPU 的虚拟处理器指定情况(如果处理器亲缘关系可用) |
| VPCLASS | user_defined | 指定用户定义的虚拟处理器 |
| VPCLASS | noyield | 指定非中止虚拟处理器 |
| VP_MEMORY_ CACHE_KB | 加速对内存块的存取。 |
指定虚拟处理器类
使用 VPCLASS 配置参数可指定虚拟处理器 (VP) 的类、创建用户定义的虚拟处理器,以及指定如下选项:服务器启动的 VP 数、允许用于类的最大 VP 数,以及处理器亲缘关系可用时为 CPU 指定的 VP 数。
可以指定最大长度为 128 字节的 VPCLASS 名称。VPCLASS 名称必须以字母或下划线开头且必须包含字母、数字、下划线或 $ 字符。
禁用优先级迟滞 (UNIX)
使用带有 noage 选项的 VPCLASS 参数可禁用允许该功能的平台上的进程优先级迟滞。
有关 UNIX™ 上这些数据库服务器参数的推荐值,请参阅机器说明文件。
启动和停止虚拟处理器
当您启动数据库服务器时,oninit 实用程序将启动您已直接和间接指定了数量和类型的虚拟处理器。主要通过 ONCONFIG 参数配置虚拟处理器,并且对于网络虚拟处理器,那么通过 sqlhosts 文件或注册表中的参数来配置。有关虚拟处理器类的描述,请参阅虚拟处理器类。
可以使用数据库服务器来启动最多 1000 个虚拟处理器。
当数据库服务器处于在线模式后,如果需要,您可以启动其他虚拟处理器以提高性能。有关更多信息,请参阅在在线模式下添加虚拟处理器。
当数据库服务器处于在线模式,那么您可以删除 CPU 和用户定义类的虚拟处理器。有关更多信息,请参阅删除 CPU 和用户定义的虚拟处理器。
要终止数据库服务器并且从而终止所有的虚拟处理器,请使用 onmode -k 命令。有关使用 onmode -k 的更多信息,请参阅《GBase 8s 管理员参考》。
在在线模式下添加虚拟处理器
当数据库服务器处于在线模式时,您可以启动以下类的其他虚拟处理器:CPU、AIO、PIO、LIO、SHM、STR、TLI、SOC、JVP 和用户定义。数据库服务器自动为 LIO 和 PIO 类的每一个类启动一个虚拟处理器,除非使用了镜像,如果使用了镜像,那么数据库服务器将启动两个虚拟处理器。
可以使用 onmode 实用程序的 -p 选项启动这些额外的虚拟处理器。
可以使用 onmode 实用程序的 -p 选项启动这些额外的虚拟处理器。
还可以启动用户定义类的附加虚拟处理器来运行用户定义的例程。有关用户定义的虚拟处理器的更多信息,请参阅将 UDR 指定给用户定义的虚拟处理器类。
在在线模式下使用 onmode 添加虚拟处理器
使用 onmode 命令的 -p 选项可在数据库服务器处于在线模式时添加虚拟处理器。用正数指定希望添加的虚拟处理器数。作为选择,您可以在虚拟处理器数前加上一个加号 (+)。在这个数字后面,请以小写字母指定虚拟处理器的类。例如,以下两个命令中任意一个都可启动 AIO 类中的其他四个虚拟处理器:
onmode -p 4 aio
onmode -p +4 aio
onmode 实用程序将立即启动附加的虚拟处理器。
一次只可以将虚拟处理器添加到一个类。要为另一个类添加虚拟处理器,您必须再次运行 onmode。
添加网络虚拟处理器
添加网络虚拟处理器时,可添加轮询线程,其中每个轮询线程都需要其自已的虚拟处理器才能运行。
如果尝试在数据库服务器处于在线模式时为协议添加轮询线程,并且在 NETTYPE 配置参数中指定轮询线程在 CPU 类中运行,那么在没有 CPU 虚拟处理器可用于运行新轮询线程时,数据库服务器不会启动新轮询线程。
在以下示例中,轮询线程总共处理 240 个连接:
NETTYPE ipcshm,4,60,CPU # Configure poll thread(s) for nettype
对于 ipcshm,轮询线程的数量对应于内存段的数量。例如,如果 NETTYPE 设置为 3,100 并且您只想要一个轮询线程,那么请将该轮询线程设置为 1,300。
删除 CPU 和用户定义的虚拟处理器
当数据库服务器处于在线模式中,那么您可以使用 onmode 实用程序的 -p 选项来删除或终止 CPU 或用户定义类的虚拟处理器。
删除 CPU 虚拟处理器
紧跟 onmode 命令之后,请指定一个负数,该数值是您想要删除的虚拟处理器的数量,然后以小写字母指定 CPU 类。例如,以下命令删除两个 CPU 虚拟处理器:
% onmode -p -2 cpu
如果您尝试删除一个正在运行轮询线程的 CPU 虚拟处理器,那么您将接收以下消息:
onmode: failed when trying to change the number of cpu virtual processor by -_number_.
有关更多信息,请参阅在 CPU 或网络虚拟处理器上运行轮询线程。
删除用户定义的虚拟处理器
在 onmode 命令的后面,请指定一个负数(该数字是您希望删除的虚拟处理器的数量),然后以小写字母指定用户定义的类。例如,以下命令将删除类 usr 的两个虚拟处理器:
onmode -p -2 usr
有关如何创建用户定义的虚拟处理器类以及如何将用户定义的例程指定给该类,请参阅用户定义的虚拟处理器类。
监视虚拟处理器
监视虚拟处理器以确定为数据库服务器配置的虚拟处理器数对于当前活动程度是否最佳。
有关 onstat -g 命令输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
使用命令行实用程序监视虚拟处理器
可以使用以下 onstat -g 选项来监视虚拟处理器:
- onstat -g ath 命令
- onstat -g glo 命令
- onstat -g ioq 命令
- onstat -g rea 命令
onstat -g ath 命令
onstat -g ath 命令显示了有关系统线程和虚拟处理器类的信息。
onstat -g glo 命令
使用 onstat -g glo 命令可显示有关当前正在运行的每个虚拟处理器的信息,以及有关每个虚拟处理器类的累积统计信息。有关 onstat -g glo 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
onstat -g ioq 命令
使用 onstat -g ioq 选项可确定是否必须分配更多虚拟处理器。命令 onstat -g ioq 显示有关 I/O 队列的长度和其他统计信息。
如果 I/O 队列的长度不断增加,那么 I/O 请求的累积速度将超过 AIO 虚拟处理器处理请求的速度。如果 I/O 队列的长度继续显示 I/O 请求不断累积,那么考虑添加 AIO 虚拟处理器。
有关 onstat -g ioq 输出的示例,请参阅《GBase 8s 管理员参考》中的信息。
onstat -g rea 命令
使用 onstat -g rea 选项监视就绪的队列中的线程数。如果在就绪队列中虚拟处理器类(例如,CPU 类)的线程数量不断增加,那么可能需要将更多此类虚拟处理器添加到配置中。
有关 onstat -g rea 输出的示例,请参阅《GBase 8s 管理员参考》中的信息。
使用 SMI 表监视虚拟处理器
查询 sysvpprof 表以获得有关当前正在运行的虚拟处理器的信息。此表包含以下各列。
| 列 | 描述 |
|---|---|
| vpid | 虚拟处理器的标识号 |
| class | 虚拟处理器类 |
| usercpu | 用户 CPU 已用分钟数 |
| syscpu | 系统 CPU 已用分钟数 |
共享内存
这些主题描述了数据库服务器共享内存的内容、确定共享内存区域大小的因素,以及数据移入和移出共享内存的方式。有关如何更改确定共享内存分配的数据库服务器配置参数的信息,请参阅管理共享内存。
共享内存
共享内存是允许数据库服务器线程和进程通过共享对内存池的访问权来共享数据的一种操作系统功能。数据库服务器将共享内存用于以下用途:
- 要减少内存使用和磁盘 I/O
- 执行进程间的高速通信
共享内存使数据库服务器能够减少总体内存使用量,因为参与进程(在此情况下即虚拟处理器)不需要保留共享内存中数据的专用副本。
共享内存将减少磁盘 I/O,因为缓冲区(作为公共池受管)将在整个数据库服务器范围内清空,而不是为每个进程清空。而且,虚拟处理器可以经常避免从磁盘读取数据,因为数据已经作为较早读取操作的结果存在于共享内存中了。减少磁盘 I/O 将减少执行时间。
共享内存提供最快的进程间通信方法,因为它以内存传送的速度处理读写消息。
共享内存使用
数据库服务器将共享内存用于以下用途:
- 使虚拟处理器和实用工具能够共享数据
- 为使用 IPC 通信的本地客户机应用程序提供快速通信通道
下图说明了共享内存方案。
图: 数据库服务器使用共享内存的方式
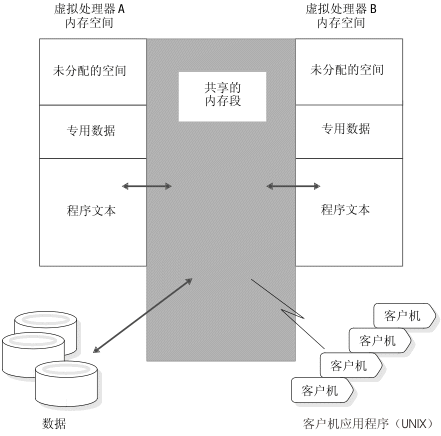
共享内存分配
数据库服务器将创建共享内存的以下部分:
- 常驻部分
- 虚拟部分
- IPC通信或消息部分
如果 sqlhosts 文件指定了共享内存通信,那么数据库服务器将为通信部分分配内存。
- 虚拟扩展部分
数据库服务器根据需要将操作系统段添加到共享内存的虚拟部分和虚拟扩展部分。
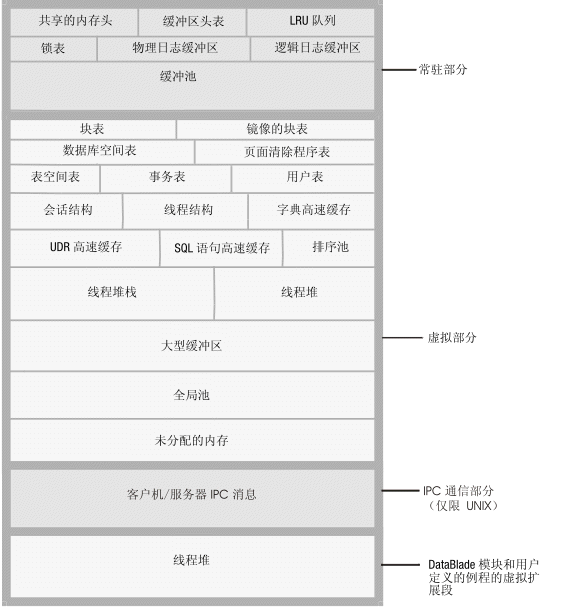
有关平台的共享内存设置的更多信息,请参阅机器说明。下图显示了共享内存各部分的内容。
所有的数据库服务器虚拟处理器都可以访问相同的共享内存段。每个虚拟处理器通过保留其自身对共享内存资源(如缓冲区、锁定和锁存器)的指针集来管理其工作。在将数据库服务器从脱机方式转换到静态、管理或在线模式时,虚拟处理器将连接共享内存。数据库服务器将使用锁定和锁存器来管理多个线程对共享内存资源的并发访问。
图: 数据库服务器共享内存的内容
共享内存大小
数据库服务器共享内存的每个部分都由一个或多个操作系统内存段组成,每个内存段分成一系列大小为 4 KB 的块,并由位图进行管理。
onstat 实用程序输出的标题行包含数据库服务器共享内存的大小(以 KB 表示)。您还可以使用 onstat -g seg 监视数据库服务器为共享内存的每一部分分配多少内存。有关如何使用 onstat 的信息,请参阅《GBase 8s 管理员参考》。
可以在 onconfig 文件中设置 SHMTOTAL 参数来限制数据库服务器可以在计算机或节点上安排的内存开销量。SHMTOTAL 参数指定数据库服务器可用于所有内存分配的共享内存总量。 然而,如果数据库服务器需要的内存量大于 SHMTOTAL 中设置的量,那么某些操作可能会失败。如果发生这种情况,数据库服务器会在消息日志中显示以下消息:
size of resident + virtual segments _x_ + _y_ > _z_
total allowed by configuration parameter SHMTOTAL
此外,数据库服务器会将错误消息返回到已启动违规操作的应用程序中。例如,如果数据库服务器在尝试执行操作(例如,索引构建或散列连接)时需要的内存量大于在 SHMTOTAL 中指定的内存量,那么该服务器将向应用程序返回类似于以下某条消息的错误消息:
-567 Cannot write sorted rows.
-116 ISAM error: cannot allocate memory.
数据库服务器在发送了这些消息后会回滚任何由违规查询执行的部分结果。
内部操作(例如页清除程序或检查点活动)也会导致数据库服务器超过 SHMTOTAL 的上限。当发生这种情况时,数据库服务器会向消息日志发送一条消息: 例如,假设数据库服务器试图为页清除程序活动分配附加的内存但失败了。结果,数据库服务器会向消息日志发送类似于以下消息的信息:
17:19:13 Assert Failed: WARNING! No memory available for page cleaners
17:19:13 Who: Thread(11, flush_sub(0), 9a8444, 1)
17:19:13 Results: Database server may be unable to complete a checkpoint
17:19:13 Action: Make more virtual memory available to database server
17:19:13 See Also: /tmp/af.c4
在数据库服务器通知您分配附加的内存失败后,该服务器会回滚导致其超过 SHMTOTAL 限制的事务。一经回滚,操作就不会再因为内存不足而失败,数据库服务器将继续如平常一样处理事务。
超过 SHMTOTAL 时要执行的操作
当数据库服务器需要的内存量大于 SHMTOTAL 所允许的值时,将出现瞬时状态,这可能是因突发超过正常处理负载的活动所引起。只有导致数据库服务器暂时耗尽内存的操作才会暂时失败。其他操作继续以正常方式处理。
如果有消息定期指示数据库服务器需要的内存量大于 SHMTOTAL 所允许的值,那么表示您没有正确配置数据库服务器。减小 BUFFERPOOL 配置参数中的 DS_TOTAL_MEMORY 值或 buffers 值是一种可能的解决方案;增加 SHMTOTAL 的值是另一种解决方案。
连接到共享内存的进程
以下进程将连接到数据库服务器共享内存:
- 通过共享内存通信部分 (ipcshm) 与数据库服务器通信的客户机应用程序进程
- 数据库服务器虚拟处理器
- 数据库服务器实用程序
客户机如何连接到通信部分 (UNIX™)
通过共享内存 (nettype ipcshm) 与数据库服务器通信的客户机应用程序进程透明地连接到共享内存的通信部分。自动编译到应用程序的系统库函数使其能够连接到共享内存的通信部分。有关指定共享内存连接的信息,请参阅客户机/服务器通信和网络虚拟处理器。
如果没有设置 GBASEDBTSHMBASE 环境变量,那么客户机应用程序将连接到特定于平台的地址的通信部分。如果客户机应用程序连接到其他共享内存段(不是数据库服务器共享内存),那么用户可以将 GBASEDBTSHMBASE 环境变量设置为指定连接数据库服务器共享内存通信段所在的地址。当您指定处理共享内存通信段所在的地址时,可以防止数据库服务器与应用程序使用的其他共享内存段发生冲突。有关如何设置 GBASEDBTSHMBASE 环境变量的信息,请参阅《GBase 8s SQL 指南:参考》。
实用程序如何连接到共享内存
数据库服务器实用程序(如 onstat、onmode 和 ontape)通过以下文件之一连接到共享内存。
| 操作系统 | 文件 |
|---|---|
| UNIX™ | $GBASEDBTDIR/etc/.infos.servername |
变量 servername 是 onconfig 文件中 DBSERVERNAME 参数的值。实用程序从 GBASEDBTSERVER 环境变量中获得文件名的 servername 部分。
oninit 进程在启动数据库服务器时读取 onconfig 文件并创建文件 .infos.servername。该文件将在数据库服务器终止时除去。
虚拟处理器如何连接到共享内存
数据库服务器虚拟处理器在安装期间连接共享内存。在此过程中,数据库服务器必须满足以下两个要求:
- 确保所有虚拟处理器可以定位和访问相同的共享内存段
- 确保共享内存段位于同一台计算机上但与指定给其他数据库服务器实例(如果 有)的共享内存段不同的物理内存位置
数据库服务器使用两个配置参数(SERVERNUM 和 SHMBASE)以满足这些要求。
当虚拟处理器连接到共享内存时,它会执行以下主要步骤:
- 从 onconfig 文件访问 SERVERNUM 参数
- 使用 SERVERNUM 可计算共享内存键值
- 使用共享内存键值请求共享内存段
操作系统返回第一个共享内存段的共享内存标识。
- 引导操作系统将第一个共享内存段连接到其位于 SHMBASE 的进程空间
- 若需要,连接附加共享内存段以与第一个段邻接
获取共享内存段的键值
SERVERNUM 配置参数和 shmkey 的值(内部计算的数字)确定每个共享内存段的唯一键值。
要查看共享内存段的键值,请运行 onstat -g seg 命令。
当虚拟处理器请求操作系统连接第一个共享内存段时,它将提供唯一的键值来标识该段。作为回应,操作系统传回与键值相关联的共享内存段标识。使用此标识,虚拟处理器将请求操作系统将共享内存段连接到虚拟处理器地址空间。
指定连接第一个共享内存段的位置
onconfig 文件中的 SHMBASE 参数指定每个虚拟处理器连接第一个(或基本)共享内存段所在的虚拟地址。每个虚拟处理器在同一个虚拟地址上连接第一个共享内存段。此种情况使相同数据库服务器实例中的所有虚拟处理器都能够引用共享内存中的相同位置,而无需计算共享内存的地址。数据库服务器实例的所有共享内存地址都是 SHMBASE 的相对地址。
不更改 SHMBASE 的值。
SHMBASE 的值易受以下原因影响:
- SHMBASE 的特定值取决于平台以及处理器是 32 位还是 64 位的。SHMBASE 的值不是任意数,它将在虚拟处理器动态获取附加的内存空间时保证共享内存段的安全。
- 不同的操作系统在不同的虚拟地址上接纳附加的内存。有些体系结构扩展虚拟处理器数据段的最高虚拟地址以便接纳下一个段。在此情况下,数据段可能会发展成共享内存段。
- 某些版本的 UNIX™ 需要用户将虚拟地址的 SHMBASE 参数指定为零。零地址会通知 UNIX 内核其挑选连接共享内存段所在的最佳地址。然而,并不是所有 UNIX 体系结构都支持此选项。而且,在一些系统中,内核所做的选择可能不是最好的选择。
连接附加共享内存段
每个虚拟处理器必须连接到数据库服务器已经获取的总共享内存量。在虚拟处理器连接了每个共享内存段后,它将计算已经连接的共享内存数量以及剩余的共享内存数量。数据库服务器通过将共享内存头写入第一个共享内存段促进此进程。虚拟处理器可以深入到头的十六字节获取以下数据:
- 此数据库服务器的共享内存的总大小
- 每个共享内存段的大小
要连接附加共享内存段,虚拟处理器将从操作系统中请求这些段,很多地方就像它请求第一个段一样。然而,对于附加段,虚拟处理器对 shmkey 的先前值加 1。 虚拟处理器将引导操作系统连接位于从以下计算获得的地址的段:
SHMBASE +(seg_size x 已连接的段数)
虚拟处理器将重复此过程直到它获得总共享内存量。
假设初始的键值是 (SERVERNUM * 65536) + shmkey,那么数据库服务器在可以请求由同一台计算机上另一数据库服务器实例使用的共享内存键值前,最多请求 65,536 个共享内存段。
定义共享内存下边界地址
如果操作系统使用参数来定义共享内存的下边界地址,并且该参数未正确设置,那么会使共享内存段无法连续地连接。
下图说明了该问题。如果下边界地址小于上一个段的结束地址加上当前段的大小,那么操作系统将在上一个段的结束位置外的点上连接当前段。此操作将在两个段之间创建间隔。由于共享内存必须连接到虚拟处理器以使其看上去就像连续的内存,所以此间隔将产生问题。 数据库服务器将在这种情况发生时接收到错误。
要更正该问题,请检查指定下边界地址的操作系统内核参数,或者重新将内核配置成允许更大的共享内存段。
图: 共享内存下边界地址概述

常驻共享内存段
操作系统在运行在系统上的进程间切换时通常将各部分内存的内容与磁盘交换。然而,当一部分内存指定为常驻时,它不会与磁盘交换。使频繁访问的数据常驻在内存中可以提高性能,因为这样就可以减少访问该数据所需的磁盘 I/O 操作的数目。
数据库服务器请求操作系统在以下两个条件存在时将这些虚拟部分保持在物理内存中:
- 操作系统支持共享内存驻留。
- onconfig 文件中的 RESIDENT 参数已设置为 -1 或大于 0 的值。
当考虑是否将 RESIDENT 参数设置为 -1 时,应该考虑所有应用程序对共享内存的使用。为使用 GBase 8s 数据库服务器而锁定所有共享内存会对同一台计算机上的其他应用程序(如果有)的性能产生不利的影响。
有关 RESIDENT 配置参数的更多信息,请参阅《GBase 8s 管理员参考》。
共享内存的常驻部分
数据库服务器共享内存的常驻部分存储了下列数据结构,这些数据结构的大小在数据库服务器运行时不会更改:
- 共享内存头
- 缓冲池
- 逻辑日志缓冲区
- 物理日志缓冲区
- 锁表
共享内存头
共享内存头包含有关共享内存中所有其他结构的描述,包括内部表和缓冲池。
共享内存头还包含指向这些结构的位置的指针。当虚拟处理器首次连接到共享内存时,它会读取共享内存头中的地址信息以便引导到所有其他结构。
共享内存头的大小大约有 200 KB,但该大小会根据计算机平台而发生变化。您不能调整该头大小。
共享内存缓冲池
共享内存常驻部分中的缓冲池包含存储从磁盘读取的数据库空间页的缓冲区。缓冲池包含对共享内存的常驻部分的最大分配。
下图说明了共享内存头和缓冲池。
图: 共享内存缓冲池

使用 BUFFERPOOL 配置参数可指定有关缓冲池的信息,包括缓冲池中缓冲区的数量。要分配适当的缓冲区数,对于每个用户至少要启动 4 个缓冲区。对于 500 个以上的用户,最少要求 2000 个缓冲区。缓冲区数目过少会严重影响性能,因此必须监视数据库服务器并调节缓冲区数的值以确定可接受的值。如果非缺省页大小的缓冲池不存在,那么数据库服务器将自动创建大页缓冲区。
如果您正在创建非缺省页大小的数据库空间,那么该数据库空间必须具有对应的缓冲池。例如,如果创建页大小为 6 KB 的数据库空间,那么必须创建大小为 6 KB 的缓冲池。
自动 LRU(最近最少使用)调节可影响所有缓冲池并调整 BUFFERPOOL 配置参数中的 lru_min_dirty 和 lru_max_dirty 值。
有关设置 BUFFERPOOL 配置参数的更多信息,请参阅《GBase 8s 管理员参考》。
缓冲区状态通过缓冲区表跟踪。在共享内存中,缓冲区将组织到 FIFO/LRU 缓冲区队列中。缓冲区获取是通过使用锁存器(称为互斥)和锁访问信息来管理的。
缓冲区溢出至虚拟部分
由于 64 位寻址中的最大缓冲区数可以大到 231-1,所以共享内存的常驻部分可能不能在一个大的缓冲池中容纳所有这些缓冲区。在此情况下,数据库服务器共享内存的虚拟部分可能会容纳这些缓冲区中的一些。
缓冲区大小
每个缓冲区就是一个数据库服务器页的大小。
通常,数据库服务器以整页单位(缓冲区大小)来执行 I/O。从大缓冲区、BLOB 空间缓冲区或轻量级 I/O 缓冲区执行的 I/O 是例外。(请参阅大缓冲区和创建 BLOB 页缓冲区)
onstat -b 命令将显示有关缓冲区的信息。有关 onstat 的信息,请参阅《GBase 8s 管理员参考》。
逻辑日志缓冲区
数据库服务器将使用逻辑日志来存储自上次数据库空间备份以来对数据库服务器所作更改的记录。 逻辑日志存储代表数据库服务器工作的逻辑单元的记录。逻辑日志包含以下五种类型日志记录(此外还有很多其他类型):
- 用于所有数据库的 SQL 数据定义语句
- 用于通过日志记录创建的数据库的 SQL 数据操作语句
- 对数据库的日志记录状态所作更改的记录
- 检查点记录
- 对配置所作更改的记录
数据库服务器一次只使用逻辑日志缓冲区中的一个。此缓冲区是当前的逻辑日志缓冲区。在数据库服务器将当前的逻辑日志缓冲区清空到磁盘之前,它将使第二个逻辑日志缓冲区成为当前的缓冲区以便其可以在第一个缓冲区清空时继续写入。如果第二个逻辑日志缓冲区在第一个缓冲区完成清空前充满,那么第三个逻辑日志缓冲区将成为当前的缓冲区。下图说明了此过程。
图: 逻辑日志缓冲区及其与磁盘上的逻辑日志文件的关系
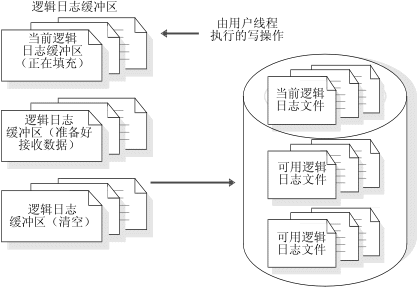
有关数据库服务器如何清空逻辑日志缓冲区的描述,请参阅清空逻辑日志缓冲区。
LOGBUFF 配置参数指定逻辑日志缓冲区的大小。如果存储的记录大于缓冲区的大小(例如,数据库空间中的 TEXT 或 BYTE 数据),那么小缓冲区可能会产生问题。逻辑日志缓冲区大小的推荐值是 64 KB。无论何时该设置小于推荐值,数据库服务器都将在服务器启动时建议另一个值。有关可指定给此配置参数的可能的值,请参阅《GBase 8s 管理员参考》。
有关 TEXT 和 BYTE 数据对共享内存缓冲区的影响的信息,请参阅缓冲区大对象数据。
物理日志缓冲区
数据库服务器使用物理日志缓冲区来容纳一些经过修改的数据库空间页的前映像。物理日志和逻辑日志记录中的前映像使数据库服务器能够在系统故障后将一致性复原到其数据库。
物理日志缓冲区实际上是两个缓冲区。双缓冲允许数据库服务器进程在其他缓冲区正清空到磁盘上的物理日志时写入活动物理日志缓冲区。有关数据库服务器如何清空物理日志缓冲区的描述,请参阅清空物理日志缓冲区。有关监视物理日志文件的信息,请参阅监视物理和逻辑日志记录活动。
onconfig 文件中的 PHYSBUFF 参数指定物理日志缓冲区的大小。一次写入物理日志缓冲区正好写满一页。如果物理日志缓冲区的指定大小不能按页大小均匀分隔,数据库服务器会将该大小向下四舍五入到可按页大小平均分隔的最近的值。虽然有些操作要求缓冲区即刻清空,但通常数据库服务器将在缓冲区充满时才将缓冲区清空到磁盘上的物理日志文件。因此,缓冲区的大小将确定数据库服务器必须每隔多少时间将缓冲区清空到磁盘一次。
物理日志缓冲区大小的缺省值为 512 KB。如果您决定使用更小的值,数据库服务器将显示一条消息,指示这样可能会无法达到最佳性能。使用小于 512 KB 的物理日志缓冲区只会影响性能,而不会影响事务完整性。
有关此配置参数的更多信息,请参阅《GBase 8s 管理员参考》。
高可用性数据复制缓冲区
数据复制要求两个数据库服务器实例(一个主实例和一个辅助实例)分别运行在两个计算机上。如果为数据库服务器实现数据复制,那么主数据库服务器首先将逻辑日志记录保存在数据复制缓冲区中,然后再将这些记录发送到辅助数据库服务器。数据复制缓冲区的大小总是和逻辑日志缓冲区的大小相同。有关逻辑日志缓冲区的大小的信息,请参阅上一主题逻辑日志缓冲区。有关如何使用数据复制缓冲区的更多信息,请参阅数据复制的工作原理。
锁表
锁将在用户线程在锁表中写入条目时创建。锁表是可用锁的池。单个事务可以拥有多个锁。有关锁定和与锁定相关联的 SQL 语句的说明,请参阅《GBase 8s SQL 指南:教程》。
存储在锁表中的以下信息描述锁:
- 拥有定的事务的地址
- 锁定的类型(互斥、更新、共享、字节或意向)
- 已锁定的页或行标识
- 放置锁定的表空间
- 有关已锁定字节(智能大对象的字节范围)的信息:
- 智能大对象标识
- 智能大对象中已锁定字节开始处的偏移量
- 已锁定的字节数(从偏移处开始)
要指定锁定表的初始大小,请设置 LOCKS 配置参数。
如果会话分配的锁定数超过 LOCKS 配置参数中指定的值,那么数据库服务器会将锁定表的大小加倍,最多可达 15 倍。数据库服务器通过尝试在每次增加时使锁定表翻倍来增加锁定表的大小。但是,每次增加期间增加的量不得超过最大值。对于 32 位平台,每次最大可增加 100,000 个锁定。因此,32 位平台允许的最大锁定总数为 8,000,000(启动锁定的最大数目)+ 99(动态锁定表扩展的最大数目)x 100,000(每个锁定表扩展添加的最大锁定数目)。对于 64 位平台,每次最大可增加 1,000,000 个锁定。因此,允许的最大锁定总数为 500,000,000(启动锁定的最大数目)+ 99(动态锁定表扩展的最大数目)x 1,000,000(每个锁定表扩展添加的最大锁定数目)。
可使用 DEF_TABLE_LOCKMODE 配置参数为新表的页或行设置锁定方式。
这些锁定能够使会话在已落实或回滚了并发事务之后再读取数据。对于使用事务日志记录创建的数据库,可使用 onconfig 文件中的 USELASTCOMMITTED 配置参数来指定数据库服务器是否使用上次落实的数据版本。上次落实的数据版本是任何更新发生之前存在的数据版本。使用 USELASTCOMMITTED 配置参数设置的值会覆盖在 SQL 语句 SET ISOLATION TO COMMITTED READ 中指定的隔离级别。有关使用 USELASTCOMMITTED 配置参数的更多信息,请参阅《GBase 8s 管理员参考》中有关配置参数的主题。
共享内存的虚拟部分
共享内存的虚拟部分可以由数据库服务器扩展并且可以由操作系统分页到磁盘。当数据库服务器执行时,它可以自动按需将附加的操作系统段连接到虚拟部分。
管理共享内存的虚拟部分
数据库服务器使用内存池跟踪类型和大小类似的内存分配。在池中保留相关的内存分配将减少内存分段存储。它还使数据库服务器能够一次释放大块的内存,与释放组成池的每个块相对。
所有的会话都有一个或多个内存池。当数据库服务器需要内存时,它会先查看指定的池。如果池中可用的内存不足以满足请求,那么数据库服务器将从系统池添加内存。如果数据库服务器不能在系统池中找到足够的内存,那么它会动态地给虚拟部分分配更多的段。
数据库服务器通过已链接的列表跟踪可用空间的池,为自己的每个子系统(会话池、堆栈、堆、控制块、系统目录、SPL 例程高速缓存、SQL 语句高速缓存、排序池和消息缓冲区)分配虚拟共享内存。当数据库服务器分配内存的部分时,它将首先在池的可用列表中搜索大小足够的段。如果服务器未找到段,那么会将新的块从虚拟部分带入池中。如果释放了内存,那么被释放内存将作为可用段返回到池中并留在其中,直到池被删除。例如,当数据库服务器启动了客户机应用程序会话时,它将为会话池分配内存。当会话终止时,数据库服务器会将已分配的内存作为可用段返回。
共享内存虚拟部分的大小
使用配置参数可指定共享内存虚拟部分的初始大小、以后要添加的段的大小以及可用于 PDQ 查询的内存量。
要指定虚拟共享内存部分的初始大小,请设置 SHMVIRTSIZE 配置参数。要指定以后添加到虚拟共享内存的段的大小,请设置 SHMADD 和 EXTSHMADD 配置参数。
要指定 PDQ 查询可用的内存量,请设置 DS_TOTAL_MEMORY 参数。
如果要增加可用于非 PDQ 查询的内存量,并且 PDQ 优先级设置为 0(零),那么可以通过以下任一方式更改该内存量:
- 设置 DS_NONPDQ_QUERY_MEM 配置参数
- 运行 onmode -wm 或 onmode -wf 命令
例如,如果使用 onmode 实用程序,请按以下示例所示指定值:
onmode -wf DS_NONPDQ_QUERY_MEM=500
DS_NONPDQ_QUERY_MEM 的最小值为 128 KB。支持的最大值为 DS_TOTAL_MEMORY 值的25%。
共享内存虚拟部分的组件
共享内存的虚拟部分存储以下数据:
- 内部表
- 大缓冲区
- 会话数据
- 线程数据(堆栈和堆)
- 数据分发高速缓存
- 字典高速缓存
- SPL 例程高速缓存
- SQL 语句高速缓存
- 排序池
- 全局池
共享内存内部表
数据库服务器共享内存包含跟踪共享内存资源的七个内部表。共享内存的内部表如下所示:
- 缓冲区表
- 块表
- 数据库空间表
- 页清除程序表
- 表空间表
- 事务表
- 用户表
缓冲区表
缓冲区表将跟踪共享内存池中单个缓冲区的地址和状态。当使用缓冲区时,该缓冲区将包含来自磁盘的数据或索引页的映像。有关磁盘页的用途和内容的更多信息,请参阅页。
缓冲区表中的每个缓冲区都包含以下缓冲区管理所需的控制信息:
缓冲区状态
缓冲区状态可以描述为空的、未修改的或已修改的。 未修改的缓冲区包含数据,但可以覆盖这些数据。 已修改的(脏)缓冲区包含必须在可以覆盖前写入磁盘的数据。
当前®锁定访问级别
缓冲区将根据用户线程正在执行的操作类型接收锁定访问级别。数据库服务器支持两种缓冲区锁定访问级别:共享和互斥。
等待缓冲区的线程
每个缓冲区头都保留一系列正在等待缓冲区的线程以及每个处于等待状态的线程所要求的锁访问级别。
每个数据库服务器缓冲区在缓冲区表中都有一个条目。
有关数据库服务器缓冲区的信息,请参阅共享内存的常驻部分。有关如何监视缓冲区的信息,请参阅监视缓冲区。
数据库服务器根据已分配的缓冲区数确定缓冲区表散列表中的条目数。散列值的最大数是小于 buffers 值的 2 的最大幂数,它是在某个 BUFFERPOOL 配置参数字段中指定的。
块表
块表将跟踪数据库服务器中的所有块。如果已启用了镜像,那么还会在启动共享内存时创建相应的镜像块表。镜像块表跟踪所有镜像块。
共享内存中的块表包含了使数据库服务器能够在磁盘上找到块的信息。这些信息包括数据库空间中初始块的编号以及下一个块的编号。标志也描述了块的状态:是镜像块还是主块;是脱机、在线还是恢复方式;以及此块是否是 BLOB 空间的一部分。
块表中的最大条目数可能受操作系统所允许的每个进程的最大文件描述符数的限制。通常可以使用操作系统内核配置参数指定每个进程的文件描述符数。
数据库空间表
数据库空间表跟踪数据库服务器中的存储器空间。数据库空间表信息包含有关每个数据库空间的以下信息:
- 数据库空间编号
- 数据库空间名称和所有者
- 数据库空间的镜像状态(已镜像或未镜像)
- 创建数据库空间的日期和时间
如果存储空间是 BLOB 空间,那么标志将指示该 BLOB 空间所在的介质:是磁性介质还是可移动介质。如果存储空间是个智能大对象空间,那么它将包含跟踪智能大对象的元数据以及包含用户数据的大连续块的页的内部表。
如果存储空间是个 BLOB 空间,那么标志将指示 BLOB 空间所在的介质:是磁性的、可移动的还是光学的介质。如果存储空间是个智能大对象空间,那么它将包含跟踪智能大对象的元数据以及包含用户数据的大连续块的页的内部表。
页清除程序表
页清除程序表将跟踪每个页清除程序线程的状态和位置。页清除程序线程数由 onconfig 文件中的 CLEANERS 配置参数指定。要获得有关应指定多少页清除程序线程的建议,请参阅《GBase 8s 管理员参考》中有关配置参数的章节。
不管 onconfig 文件中 CLEANERS 参数指定的页清除程序线程数是多少,页清除程序表始终包含 128 个条目。
有关监视页清除程序线程活动的信息,请参阅《GBase 8s 管理员参考》中有关 onstat -F 选项的信息。
表空间表
表空间表跟踪数据库服务器实例中的所有活动的表空间。活动的表空间是当前由数据库会话使用的表空间。每个活动的表空间占表空间表中的一个条目。活动的表空间包括数据库表、临时表以及内部控制表(如系统目录表)。每个表空间表条目都包含有关表空间的头信息,表空间名以及指向磁盘上数据库空间中的表空间 tblspace 的指针。(共享内存的活动表空间表与表空间 tblspace 不同。)有关监视表空间的信息,请参阅监视表空间和扩展数据块。
数据库服务器将为每个数据库空间管理一个表空间。
事务表
事务表将跟踪数据库服务器中的所有事务。
从事务表派生的跟踪信息在 onstat -x 显示中显示。
数据库服务器将根据当前的事务数自动增加事务表中的条目数(最多 32,767 个)。
有关事务和用于事务的 SQL 语句的更多信息,请参阅《GBase 8s SQL 指南:教程》、《GBase 8s SQL 指南:参考》和《GBase 8s SQL 指南:语法》。
仅限 UNIX: 事务表同样明确支持 X/Open 环境。支持 X/Open 环境需要 TP/XA。
用户表
用户表跟踪所有用户线程和系统线程。每个客户机会话根据指定的并行性级别有一个主线程以及零到许多个辅助线程。系统线程包含一个监视和控制检查点的线程、一个处理 onmode 命令的线程、B 型树扫描程序线程以及页清除程序线程。
数据库服务器会按需增加用户表中的条目数。可以用 onstat -u 命令监视用户线程。
大缓冲区
大缓冲区是由多个页组成的单个缓冲区。实际页数将取决于平台。数据库服务器将分配大缓冲区以提高大量读写时的性能。
无论何时数据库服务器向磁盘写入多个物理上相邻的页,它都使用大缓冲区。例如,数据库服务器尝试使用大缓冲区执行一系列顺序读(轻度扫描)或将存储在数据库空间的简单大对象读入共享内存。
用户对大缓冲区没有控制权。如果数据库服务器使用轻度扫描,那么它将从共享内存分配大缓冲区。
会话数据
当客户机应用程序请求连接到数据库服务器时,数据库服务器开始与客户机的会话并在称为会话控制块的共享内存中为该会话创建数据结构。会话控制块存储会话标识、用户标识、客户机进程标识、主机名称以及各种状态标志。
数据库服务器会按需为会话数据分配内存。
线程数据
当客户机连接到数据库服务器时,除了启动会话以外,数据库服务器还会启动主会话线程并在共享内存中为其创建启动控制块。
数据库服务器还代表其自身启动内部线程并为这些线程创建线程控制块。当数据库服务器从运行一个线程切换为运行另一个线程(上下文切换)时,它在线程控制块中保存有关线程的信息(如寄存器内容、程序计数器(下一个指令的地址)以及全局指针)。有关线程控制块以及其使用方法的更多信息,请参阅上下文切换。
数据库服务器会按需为线程控制块分配内存。
堆栈
数据库服务器中的每个线程在共享内存的虚拟部分中都有其自己的堆栈区域。用户线程的堆栈空间大小由 onconfig 文件中的 STACKSIZE 参数指定。堆栈的缺省大小为 32 KB。如有必要,可通过更改 STACKSIZE 的值来更改所有用户线程的堆栈大小。有关设置堆栈大小的信息和警告,请参阅《GBase 8s 管理员参考》中有关配置参数的主题中的 STACKSIZE。
要更改特定会话主线程的堆栈大小,请设置 GBASEDBTSTACKSIZE 环境变量。GBASEDBTSTACKSIZE 的值将覆盖特定用户的 STACKSIZE 的值。有关如何覆盖特定用户的堆栈大小的信息,请参阅《GBase 8s SQL 指南:参考》中有关 GBASEDBTSTACKSIZE 环境变量的描述。
要更加安全地更改堆栈空间的大小,请使用 GBASEDBTSTACKSIZE 环境变量而不要更改配置参数 STACKSIZE。GBASEDBTSTACKSIZE 环境变量只会影响一个用户的堆栈空间,并且该变量不太可能影响最初未测量的新的客户机应用程序。
堆
每个线程有一个堆来容纳其在运行时创建的数据结构。堆将在创建线程时动态分配。线程堆的大小是不可配置的。
数据分发高速缓存
数据库服务器使用在 MEDIUM 或 HIGH 方式下由 UPDATE STATISTICS 语句生成的分布统计信息来确定成本最低的查询计划。当数据库服务器第一次访问有关特定列的分布统计信息时,它将从磁盘上的 sysdistrib 系统目录表中读取分布统计信息并且将这些统计信息存储在数据分发高速缓存中。然后可以读取这些统计信息以便优化访问列的后续查询。
如果这些统计信息有效地从数据分发高速缓存中存储和访问,性能将会提高。可使用 DS_HASHSIZE 和 DS_POOLSIZE 配置参数来配置数据分发高速缓存的大小。
字典高速缓存
当会话执行需要访问系统目录表的 SQL 语句时,数据库服务器将从系统目录表中读取数据。数据库服务器将每个查询的表的目录数据存储在各个结构中,这样数据库服务器在对该表进行子查询期间就能更有效的访问这些结构。这些结构将创建在共享内存的虚拟部分中以供所有会话使用。这些结构构成了字典高速缓存。
可使用 DD_HASHSIZE 和 DD_HASHMAX 配置参数来配置字典高速缓存的大小。
SQL 语句高速缓存
SQL 语句高速缓存将减少查询的内存使用量和准备时间。数据库服务器使用 SQL 语句高速缓存来存储用户执行的已解析和优化的 SQL 语句。当用户执行 SQL 语句高速缓存中存储的语句时,数据库服务器不再对该语句进行解析和优化,从而提高了性能。
排序内存
以下数据库操作可以使用大量的共享内存虚拟部分来将数据排序。
- 涉及连接、分组、聚集和排序操作的决策支持查询
- 索引构建
- SQL 中的 UPDATE STATISTICS 语句
数据库服务器为排序所分配的虚拟共享内存量将取决于要排序的行数、行的大小以及其他因素。
SPL 例程和 UDR 高速缓存
数据库服务器将 SPL 例程转换为可执行格式并将该例程存储在 UDR 高速缓存中,任何会话都可以在其中访问该例程。
当第一次需要会话访问 SPL 例程或其他用户定义的例程时,数据库服务器将从系统目录表中读取定义,并将定义存储到 UDR 高速缓存中。
可使用 PC_HASHSIZE 和 PC_POOLSIZE 配置参数来配置 UDR 高速缓存的大小。
全局池
全局池存储对于数据库服务器是全局的结构。例如,全局池包含消息队列,网络通信的轮询线程在该处存储来自客户机的消息。sqlexec 线程将从全局池中挑选这些消息并处理它们。
共享内存的通信部分 (UNIX™)
如果至少将一个连接配置为 IPC 共享内存连接,那么数据库服务器将为共享内存的 IPC 通信部分分配内存。数据库服务器将在您设置共享内存时执行此分配。通信部分包含本地客户机应用程序的消息缓冲区,这些应用程序使用共享内存与数据库服务器进行通信。
共享内存通信部分的大小大约等于 12 KB 乘以共享内存通信所需的期望连接数 (nettype ipcshm)。如果 nettype ipcshm 不存在,那么期望的连接数将缺省为 50。有关客户机如何连接到共享内存的通信部分的信息,请参阅客户机如何连接到通信部分 (UNIX)。
共享内存的虚拟扩展部分
共享内存的虚拟扩展部分包含附加的虚拟段和虚拟扩展段。
虚拟扩展段包含在用户定义的虚拟处理器中运行的用户定义的例程。
EXTSHMADD 配置参数可设置虚拟扩展段的大小。SHMADD 和 SHMTOTAL 配置参数适用于共享内存的虚拟扩展部分,正如它们也适用于共享内存的其他部分一样。
并行控制
运行在同一个虚拟处理器上和运行在个别虚拟处理器上的数据库服务器线程将共享对共享内存中资源的访问权。当线程写入共享内存时,它将使用称为互斥和锁定的机制来防止其他线程同时写入相同的区域。互斥将给予线程访问共享内存资源的权限。防止其他线程写入缓冲区直到放置锁的线程完成对缓冲区的操作并且释放锁定为止的锁定。
共享内存互斥
数据库服务器在尝试修改共享内存中的数据时使用互斥来协调线程。每个可修改的共享内存资源都与互斥相关联。在线程可以修改共享内存资源之前,它必须先获取与该资源关联的互斥。在线程获取该互斥后,它便可以修改该资源。当修改完成时,线程将释放互斥。
如果线程试图获取互斥并发现该互斥正由另一个线程所持有,那么进入的线程必须等待互斥被释放。
例如,两个线程可以尝试访问块表中的同一个插槽,但只有一个线程可以获取与块表关联的互斥。只有持互斥的线程才可以将其条目写入块表。第二个线程必须等待该互斥被释放,然后才能获取该互斥。
有关监视互斥(也称为锁存器)的信息,请参阅监视共享内存概要文件和锁存器。
共享内存缓冲区锁定
共享内存的主要好处在于数据库服务器线程能够共享对存储在共享内存缓冲池中的磁盘页的访问权。数据库服务器将在通过有关锁定数据缓冲区的策略获得此增长的并行性时保持线程隔离。
缓冲区锁定的类型
数据库服务器使用两种类型的锁定来管理到共享内存缓冲区的访问权:
- 共享锁定
- 互斥锁定
这些锁定类型中的每种类型都将在执行期间强制实施所需级别的线程隔离。
共享锁定
如果多个线程可以访问缓冲区以读取数据但没有一个想要修改数据,那么缓冲区为共享方式或有一个共享锁定。
互斥锁定
如果线程要求对缓冲区进行互斥访问,那么缓冲区为互斥方式或具有互斥锁定。所有访问缓冲区的其他线程请求都放置在等待队列中。当正在执行的线程准备好释放互斥锁定,它将唤醒等待队列中的下一个线程。
数据库服务器线程对共享缓冲区的访问
数据库服务器线程通过一系列队列访问共享缓冲区,并且使用互斥和锁定来同步访问以及保护数据。
FIFO/LRU 队列
缓冲区为高速缓存而容纳数据。数据库服务器使用最近最少使用 (LRU) 队列来替换高速缓存的数据。GBase 8s 还有一个先进先出 (FIFO) 队列。设置 LRU 队列数时,您实际上正在设置 FIFO/LRU 队列数。
使用 BUFFERPOOL 配置参数可指定有关缓冲池的信息,包括要在数据库服务器共享内存已设置时要创建的 LRU 队列数目的信息,还包括控制将共享内存缓冲区清空到磁盘的频率的 lru_min_dirty 和 lru_max_dirty 的值信息。
要提高事务吞吐量,请增加 lru_min_dirty 和 lru_max_dirty 值。然而,请勿更改 lru_min_dirty 和 lru_max_dirty 值之间的差额。
LRU 队列的组成部分
每个 LRU 队列由一对已链接的列表组成,如下所示:
- FLRU(可用的最近最少使用的)列表,它跟踪队列中可用的或未修改的页
- MLRU(已修改的最近最少使用的)列表,它跟踪队列中已修改的页
可用或未修改的页列表称为队列对的 FLRU 队列,而已修改的页列表称为 MLRU 队列。这两个不同的列表使您无需在队列中搜索可用或未修改的页。下图说明了 LRU 队列的结构。
图: LRU 队列

按最近最少使用的顺序排序的页
当数据库服务器处理对从磁盘读取页的请求时,它必须决定在内存中替换哪个页。 数据库服务器不是随机选择一个页,而是假定最近引用的页比一些时间没有引用的页更有可能在今后得到引用。因此,数据库服务器不会替换最近访问的页,而是替换最近最少访问的页。通过维护按最近最少使用到最近最多使用顺序排序的页,数据库服务器可以方便地在内存中定位最近最少使用的页。
LRU 队列和缓冲池管理
在处理开始之前,所有页缓冲区都是空的,并且每个缓冲区都由某个 FLRU 队列的条目代表。这些缓冲区在 FLRU 队列中是平均分布的。要计算每个队列中的缓冲区的数目,请将缓冲区总数除以 LRU 队列数。缓冲区和 LRU 队列的数目是在 BUFFERPOOL 配置参数中指定的。
当需要用户线程来获取缓冲区时,数据库服务器将随机选择一个 FLRU 队列,并使用列表中最旧的或最近最少使用的条目。如果可以锁存最近最少使用的页,该页将从队列中除去。
如果 FLRU 队列已锁定并且不能锁存结束页,那么数据库服务器将随机选择另一个 FLRU 队列。
如果用户线程正在共享内存中搜索特定的页,那么将从存储在缓冲区表中的控制信息中获取该页的 LRU 队列的位置。
正在执行的线程在完成其工作后将释放缓冲区。如果该页已修改,那么缓冲区将放置在 MLRU 队列的最近最多使用的一端。如果已读取该页但未修改,那么缓冲区将返回到 FLRU 队列的最近最多使用的一端。有关如何监视 LRU 队列的信息,请参阅监视缓冲池活动。
要配置的 LRU 队列数
配置多个 LRU 队列有两个用途:
- 它们将减少用户线程对队列的争用。
- 它们允许多个清除程序清空来自 LRU 队列的页并使脏页的百分比维持在可接受的水平。
根据计算机上提供的 CPU 数目推荐 LRUS 的初始值。如果您的计算机是单处理器的,那么一开始请将 BUFFERPOOL 配置参数中的 lrus 值设置为 4。如果您的计算机是多处理器的,请使用以下公式:
LRUS = max(4, (number_CPU_VPs))
在为 BUFFERPOOL 配置参数中的 lrus 提供了初始值后,请使用 onstat -R 监视 LRU 队列。如果发现脏 LRU 队列的百分比一直超过 lru_max_dirty 的指定值,请增加为 lrus 指定的值以添加更多的 LRU 队列。
例如,假设将 lru_max_dirty 设置为 70,并且一直发现有 75% 的 LRU 队列是脏的。请考虑增加 lrus 的值。如果增加 LRU 队列的数目,就会缩短各个队列的长度,从而减少页清除程序的工作。然而,您必须使用 CLEANERS 配置参数分配足够数量的页清除程序(如下一节中所说明)。保留 lru_max_dirty 和 lru_min_dirty 之间相同的差额。
要分配的清除程序数
通常必须为应用程序经常更新的每个磁盘都配置一个清除程序。但是,除此之外还必须考虑 LRU 队列的长度以及检查点的频率,如以下各段中所说明。
除了 LRU 队列数不够之外,另外一个影响页清除程序数是否跟得上清除的页数的因素是您是否分配了足够的页清除程序线程数。在一些队列 中,脏页的百分比可能超过指定给 lru_max_dirty 的BUFFERPOOL 值,因为没有清除程序可用于清除这些队列。一段时间过后,页清除程序可能实在赶不上了,这时缓冲池将会比您在 lru_max_dirty 中指定的百分比还要脏。
例如,假设 CLEANERS 参数已设置为 8,以及将 LRU 队列数从 8 增加到 12。您不能指望性能会有多大的提升,因为 8 个清除程序现在必须共享清除额外的 4 个队列的工作。如果将 CLEANERS 的数值增加到 12,那么单个清除程序就可以更加有效地清除现在已缩短的队列中的每个队列。
将 CLEANERS 设置得太小会导致出现检查点时性能变差,因为页清除程序必须在检查点期间将所有已修改的页清空到磁盘。如果不配置足够数量的页清除程序,那么检查点会花费更长的时间,导致整体的性能变差。
有关更多信息,请参阅清空缓冲池缓冲区。
已添加到 MLRU 队列的页数
页清除程序线程会定期将 MLRU 队列中已修改的缓冲区清空到磁盘。要指定清除开始的点,请使用 BUFFERPOOL 配置参数指定 lru_max_dirty 的值。
通过指定页清除程序何时开始,lru_max_dirty 值会限制可附加到 MLRU 队列的页缓冲区数。lru_max_dirty 的初始设置是 60.00,因此页清除会在队列所管理的缓冲区的百分之六十被修改时开始。
实际上,页清除程序可以在若干条件下开始,但只有其中一个条件是 MLRU 队列达到 lru_max_dirty 值的情况。有关数据库服务器如何执行缓冲池清空的更多信息,请参阅将数据清空到磁盘。
以下示例显示 lru_max_dirty 的值如何应用于 LRU 队列以指定页清除程序何时开始,从而限制 MLRU 队列中的缓冲区数。
Buffers specified as 8000
lrus specified as 8
lru_max_dirty specified as 60 percent
Page cleaning begins when the number of buffers in the MLRU
queue is equal to lru_max_dirty.
Buffers per lru queue = (8000/8) = 1000
Max buffers in MLRU queue and point at which page cleaning
begins: 1000 x 0.60 = 600
MLRU 清除结束
还可以指定 MLRU 清除可以结束的点。BUFFERPOOL 配置参数中的 lru_min_dirty 值指定 MLRU 队列中缓冲区的可接受百分比。例如,如果将 lru_min_dirty 设置为 50.00,那么当修改了 LRU 队列中 50% 的缓冲区时就不需要清除页了。 实际上,页清除可以根据页清除程序线程的指令继续超过此点。
以下示例显示 lru_min_dirty 的值如何应用于 LRU 队列,以指定 MLRU 队列中缓冲区的可接受百分比以及页清除结束的点。
Buffers specified as 8000
lrus specified as 8
lru_min_dirty specified as 50 percent
The acceptable number of buffers in the MLRU queue and
the point at which page cleaning can end is equal
to lru_min_dirty.
Buffers per LRU queue = (8000/8) = 1000
Acceptable number of buffers in MLRU queue and the point
at which page cleaning can end: 1000 x .50 = 500
可以对 lru_max_dirty 和 lru_min_dirty 值使用十进制。例如,如果把 lru_max_dirty 设置为 1.0333 并且把 lru_min_dirty 设置为 1.0,那么将触发 LRU 在 3,100 脏缓冲区时开始写并在 3,000 脏缓冲区时停止。
有关数据库服务器如何清空缓冲池的更多信息,请参阅将数据清空到磁盘。
预读操作
对于顺序表或索引扫描,可以将数据库服务器配置为在处理当前页的过程中预读多页。数据库服务器将自动预读正在为查询处理的当前页的后面几页,除非禁用自动预读操作。预读使应用程序能够更快地运行,因为它们将花费更少的时间等待磁盘 I/O。
自动预读取在连续扫描数据记录期间请求将页面放入缓冲池高速缓存,这可在服务器检测到查询(包括 OLTP 查询和索引扫描)遇到 I/O 时提高查询的性能。
缺省情况下,数据库服务器将根据查询遇到来自磁盘的 I/O 的时间,自动确定何时发出预读请求以及何时停止。
- 如果查询遇到 I/O,服务器将发出预读请求,以提高查询性能。因为预读请求通过对相对于 CPU 处理速度较慢的 I/O 处理进行补偿,可以极大地提高数据库处理的速度,所以使性能得到提升。
- 如果查询大部分已进行高速缓存,那么服务器将检测到没有执行任何 I/O,因此不会预读。
使用 AUTO_READAHEAD 配置参数可更改查询的自动预读方式或禁用查询的自动预读。您可以:
- 通过运行 onmode -wm 或 onmode -wf 命令,动态更改 AUTO_READAHEAD 配置参数的值。
- 运行 SET ENVIRONMENT AUTO_READAHEAD 语句以更改方式,或启用或禁用会话的自动预读。
顺序数据或索引读取期间,只要数据库服务器检测到有必要执行预读,就会执行预读。
onconfig 文件中的 RA_PAGES 参数指定数据库服务器执行预读时,要从磁盘或索引读取的页数。
RA_THRESHOLD 参数指定内存中导致数据库服务器执行另一个预读的未处理页的数量。例如,如果 RA_PAGES 设置为 10,且 RA_THRESHOLD 为 4,那么数据库服务器将在缓冲区中留有 4 个要处理的页时预读 10 个页。
可以使用 onstat -p 命令来查看数据库服务器读取和写入,并监视需要某个线程等待共享内存锁存器的次数。RA-pgsused 输出字段显示数据库服务器预读使用的页数,并监视数据库服务器对预读的使用。
使用 onstat -g rah 命令可显示有关预读请求的统计信息。
数据库服务器线程对缓存页的访问
数据库服务器使用共享锁定缓存以使多个数据库服务器线程能够在共享内存中同时访问相同的缓冲区。
数据库服务器使用两种类型的缓冲区锁来提供此并发性,而不会在线程隔离时有所损失。 锁定访问的两个类型是共享和互斥。(有关更多信息,请参阅缓冲区锁定的类型。)
将数据清空到磁盘
将缓冲区写入磁盘称为缓冲区清空。当用户线程修改缓冲区中的数据时,它会将缓冲区标为脏。当数据库服务器将缓冲区清空到磁盘时,它随后会将缓冲区标为不脏并允许覆盖缓冲区中的数据。
数据库服务器将清空以下缓冲区:
- 缓冲池(包含在本节中)
- 物理日志缓冲区
请参阅清空物理日志缓冲区。
- 逻辑日志缓冲区
请参阅清空逻辑日志缓冲区。
页清除程序线程缓冲区清空。数据库服务器总是运行至少一个页清除程序线程。如果数据库服务器配置了多个页清除程序线程,那么 LRU 队列将分配到这些页清除程序中以便更有效的清空。有关指定数据库服务器运行多少页清除程序线程的信息,请参阅《GBase 8s 管理员参考》中的 CLEANERS 配置参数。
清空物理日志缓冲区、已修改的共享内存页缓冲区和逻辑日志缓冲区必须依照设计用以保持数据一致性的特定规则与页清除程序活动同步。
清空缓冲池缓冲区
缓冲区的清空由以下任何一种条件启动:
- MLRU 队列中缓冲区数达到 BUFFERPOOL 配置参数中lru_max_dirty 值指定的数目。
- 页清除程序线程无法跟上。换句话说,用户线程必定需要获取缓冲区,但是没有未修改的缓冲区可用。
- 数据库服务器必须执行检查点。(请参阅检查点。)
自动 LRU 调节可影响所有缓冲池并调整 BUFFERPOOL 配置参数中的 lru_min_dirty 和 lru_max_dirty 值。
首先清空前映像
已修改页的前映像在已修改页本身之前清空到磁盘。
实际上,首先清空物理日志缓冲区然后再清空包含已修改的页的缓冲区。因此,即便由于用户线程正在试图获取缓冲区但没有缓冲区可用(前台写入),而必须对共享内存缓冲区页清空时,也只有在页的前映像已写入磁盘后才能将缓冲区页清空。
清空物理日志缓冲区
数据库服务器临时存储物理日志缓冲区中存储一些已修改的磁盘页的前映像。如果前映像已写入物理日志缓冲区但未写入磁盘上的物理日志,那么服务器会在将已修改的页清空到磁盘之前先将物理日志缓冲区清空到磁盘。
数据库服务器总是在将任何数据缓冲区清空到磁盘之前首先将物理日志缓冲区的内容清空到磁盘。
以下事件将导致活动的物理日志缓冲区清空:
- 活动物理日志缓冲区变满。
- 共享内存中的已修改页必须清空,但前映像仍然在活动物理日志缓冲区中。
- 出现检查点。
数据库服务器一次只使用两个物理日志缓冲区中的一个。此缓冲区是活动(或当前)物理日志缓冲区。在数据库服务器将当前物理日志缓冲区清空到磁盘之前,它使其他缓冲区称为当前物理日志缓冲区,以便该服务器可以在清空第一个缓冲区时继续写入。
物理日志缓冲区和物理日志都有助于保持数据在物理上和逻辑上的一致性。有关物理记录、检查点和快速恢复的信息,请参阅物理日志记录、检查点和快速恢复。
同步缓冲区清空
当首先启动共享内存时,所有的缓冲区都是空的。当处理发生时,数据页将从磁盘读入缓冲区,而用户线程则开始修改这些页。
描述清空活动
为了向您提供有关提示缓冲区清空活动的特定条件的信息,数据库服务器定义了三种类型的写入并计算发生每次写入的频率:
- 前台写入
- LRU 写入
- 块写入
要显示数据库服务器保留的写入计数,请如《GBase 8s 管理员参考》中所述使用 onstat -F。
如果实现数据库服务器的镜像,那么数据总是先写入主块。然后写入会在镜像块上重复。 对镜像块的写入次数包含在计数中。有关监视数据库服务器所执行的写入类型的更多信息,请参阅监视缓冲池活动。
前台写入
只要 sqlexec 线程将缓冲区写入磁盘,都称为前台写入。当 sqlexec 线程代表用户在 LRU 队列中搜索但无法找到空的或未修改的缓冲区时将发生前台写入。为了腾出空间,sqlexec 线程将一次清空一个页以容纳要从磁盘读取的数据。(有关更多信息,请参阅 FIFO/LRU 队列。)
如果 sqlexec 线程必须执行缓冲区清空以获取共享内存缓冲区,那么性能会变差。必须避免前台写入。要显示对前台写入次数的计数,请运行 onstat -F。如果发现前台写入定期发生,请调整页清除参数的值。 要么增加页清除程序的数目,要么减少 BUFFERPOOL lru_max_dirty 值。
LRU 写入
与前台写入不同,LRU 写入由页清除程序执行而不是由 sqlexec 线程执行。数据库服务器将 LRU 写入作为后台写入执行,后者通常在脏缓冲区的百分比超过在 BUFFERPOOL 配置参数中为 lru_max_dirty 指定的百分比时发生。
此外,前台写入可触发 LRU 写入。当发生前台写入时,已执行写入的 sqlexec 线程将提醒页清除程序唤醒并清除该线程已为之执行前台写入的 LRU。
在已正确调整的系统中,页清除程序将确保有足够的未修改的缓冲区页可用于存储从磁盘读取的页。因此,执行查询的 sqlexec 线程无需在读入查询所需的磁盘页之前,先将页清空到磁盘。对于不利用前台写入的查询而言,这种情况可以使性能有显著地提高。
由于页清除程序线程执行缓冲区写入比 sqlexec 线程更有效率,因此 LRU 写入比前台写入更受欢迎。要监视写入的两种类型,请使用 onstat -F。
块写入
块写入统称由页清除程序线程在检查点期间执行,或在可能的情况下在共享内存缓冲池中的每个页已修改时执行。块写入(作为已排序的写入执行)是数据库服务器可用的最有效的写入。
在块写入期间,每个页清除程序线程都指定到一个或多个块。每个页清除程序线程在缓冲区头中读取并将一组指针创建到与其特定的块关联的页。(页清除程序对此信息有访问权,因为块编号包含在物理页编号地址中,它是页头的一部分。)此排序将最小化磁盘上的磁头移动(磁盘搜索时间)并在可能的情况下使页清除程序线程能够在写入时使用大缓冲区。
此外,由于用户线程必须等待检查点完成,因此页清除器线程不会与大量线程争用 CPU 时间。结果,页清除程序线程可以通过更少的上下文切换来完成它们的工作。
清空逻辑日志缓冲区
数据库服务器使用共享内存逻辑日志缓冲区作为临时存储器用于存储向数据库服务器页描述修改的记录。这些更改记录将从逻辑日志缓冲区写入磁盘上当前的逻辑日志文件,并最终写入逻辑日志备份介质。有关逻辑日志记录的描述,请参阅逻辑日志。
五个事件导致当前逻辑日志缓冲区清空:
- 当前的逻辑日志缓冲区变满。
- 事务已在带有未缓冲日志记录的数据库中准备或落实。
- 非日志记录数据库会话终止。
- 出现检查点。
- 已修改不需要物理日志中的前映像的页。
以下主题将详细讨论其中每个事件。
事务已在带有未缓冲日志记录的数据库中准备或终止之后
以下日志记录将导致逻辑日志缓冲区在带有未缓冲日志记录的数据库中清空:
- COMMIT
- PREPARE
- XPREPARE
- ENDTRANS
有关已缓冲日志记录和未缓冲日志记录的比较,请参阅 《GBase 8s SQL 指南:语法》 中的 SET LOG 语句。
使用非日志记录数据库或未缓冲日志记录的会话终止时
甚至对于非日志记录数据库,数据库服务器会记录某些改变数据库方式的活动,如创建表或扩展数据块。当数据库服务器终止那些使用未缓冲日志记录或非日志记录数据库的会话时,会清空逻辑日志缓冲区以确保已记录任何日志记录活动。
当出现检查点时
有关在检查点期间所发生事件的详细描述,请参阅检查点。
当已修改不需要物理日志文件中的前映像的页时
当修改了不需要物理日志中的前映像的页时,必须在页清空到磁盘前清空逻辑日志缓冲区。
缓冲区大对象数据
简单大对象(TEXT 或 BYTE 数据)可以存储在数据库空间中也可以存储在 BLOB 空间中。智能大对象(CLOB 或 BLOB 数据)仅存储在智能大对象空间中。数据库服务器使用不同方法来访问每种类型的存储空间。以下主题将描述用于每种类型的缓冲方法。
写入简单大对象
数据库服务器以写入任何其他数据类型时使用的相同方法将简单大对象写入数据库空间中的磁盘页。有关更多信息,请参阅将数据清空到磁盘。
您也可以将简单大对象指定给 BLOB 空间。数据库服务器将简单大对象写入 BLOB 空间(方法与将其他数据写入共享内存缓冲区时的不同),然后将其清空到磁盘。有关 BLOB 空间的描述,请参阅《GBase 8s 管理员参考》 中有关磁盘结构和存储器的章节。
BLOB 页和共享内存
BLOB 空间 BLOB 页存储大量数据。因此,数据库服务器不会经由共享内存缓冲池创建或访问 BLOB 页,并且它不会将 BLOB 空间的 BLOB 页写入逻辑或物理日志。
如果 BLOB 空间数据已通过共享内存池,它可能会通过去除索引页和数据页来降低池的有效性。反之,BLOB 页将在创建时直接写入磁盘。
要减少逻辑日志和物理日志的流量,数据库服务器会使用与写入数据库空间页时不同的方法将 BLOB 页从磁介质写入数据库空间备份磁带以及逻辑日志备份磁带。
由于光学介质的高可靠性,存储在光学介质上的 BLOB 页将不会写入到数据库空间和逻辑日志备份磁带中。
创建简单大对象
当将简单大对象数据写入磁盘时,它所属的行可能尚不存在。 例如,在插入期间,简单大对象会在其他行数据传送之前传送。存储简单大对象后,数据行将与指向其位置的 56 位描述符一同创建。有关如何以物理方式存储简单大对象的描述,请参阅《GBase 8s 管理员参考 》的磁盘存储器和结构章节中有关数据库空间 BLOB 页结构的部分。
创建 BLOB 页缓冲区
要从应用程序进程接收简单大对象数据,数据库服务器会创建一对 BLOB 空间缓冲区(一个用于读一个用于写),大小都是一个 BLOB 空间的 BLOB 页。 确保用户只有一组 BLOB 空间缓冲区,并因此一次只能访问一个简单大对象。
简单大对象数据将以 1 KB 段从客户机应用程序进程传输到数据库服务器。然后数据库服务器开始用 1 KB 块填充 BLOB 空间缓冲区,并尝试一次缓冲两个 BLOB 页。数据库服务器将缓冲两个 BLOB 页以便可以确定何时将转发指针从一个页添加到下一个。当它填充了第一个缓冲区并发现有更多的数据要传送时,它会在向磁盘写入页之前将转发指针添加到下一个页。当不再有数据要传送时,数据库服务器会不带转发指针将最后一页写入到磁盘。
当线程开始将第一个 BLOB 空间缓冲区写入到磁盘时,它尝试根据用户定义的 BLOB 页大小执行 I/O。例如,如果 BLOB 页的大小是 32 KB,那么数据库服务器将尝试以 32,768 字节的增量来读取或写入数据。如果底层硬件(如磁盘控制器)无法在单个操作中传送这些数据量,那么操作系统内核将在内部(以内核方式)循环直到传送完成为止。
BLOB 空间缓冲区会保留到创建它们的缓冲区完成为止。当将简单大对象写入到磁盘时,数据库服务器将取消分配 BLOB 空间缓冲区对。下图说明了将简单大对象写入 BLOB 空间的过程。
图: 将简单大对象写入 BLOB 空间

用自由图页分配和跟踪 BLOB 空间的 BLOB 页。按需创建连接 BLOB 页的链接和指向下一个 BLOB 页段的指针。
操作记录(插入、更新或删除)将写入到逻辑日志缓冲区。
访问智能大对象
数据库服务器通过共享内存缓冲区访问智能大对象,其方法与访问存储在数据库空间中的数据相同。然而,智能大对象的用户数据部分将在比正常缓冲区页更低的优先级上缓冲以防止将更高值的数据清空出缓冲池。缓冲允许对经常访问的智能大对象进行更快的访问。
智能大对象存储在智能大对象空间中。您不能将简单大对象存储在智能大对象空间中,也不能将智能大对象存储在 BLOB 空间中。智能大对象空间由用户数据区域和元数据区域组成。用户数据区域包含智能大对象数据。元数据区域包含有关智能大对象空间内容的信息。
因为智能大对象已通过共享内存缓冲池并且可以记录,所以您必须在分配缓冲区时考虑这些智能大对象。使用 BUFFERPOOL 配置参数分配共享内存缓冲区。通常,尝试分配足够的缓冲区,以便为每个同时打开的智能大对象包含两个智能大对象页。(附加页可用于预读的用途。)
使用 LOGBUFF 配置参数可指定逻辑日志缓冲区的大小。有关设置以下每个配置参数的信息,请参阅《GBase 8s 管理员参考》:
- BUFFERPOOL
- LOGBUFF
已记录的智能大对象的用户数据区域不会通过物理日志,因此无需为智能大对象更改 PHYSBUFF 参数。
有关智能大对象空间结构的更多信息,请参阅《GBase 8s 管理员参考》的磁盘结构和存储器章节中有关智能大对象空间结构的部分。有关创建智能大对象空间的信息,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
64 位平台上的内存使用
通过 64 位寻址,您可以有更大的缓冲池用于减少从磁盘获取数据的 I/O 操作量。因为 64 位平台允许更大的内存地址空间,所以以下与内存相关的配置参数的最大值在 64 位平台上更大:
- BUFFERPOOL
- CLEANERS
- DS_MAX_QUERIES
- DS_TOTAL_MEMORY
- LOCKS
- LRUS
- SHMADD
- SHMVIRTSIZE
每个 64 位平台的机器说明列出了以上配置参数和特定于平台的参数(例如 SHMMAX)的最大值。
管理共享内存
这些主题说明如何执行涉及管理共享内存的以下任务:
- 设置共享内存配置参数
- 设置共享内存
- 为数据库服务器共享内存的常驻部分打开或关闭驻留
- 将段添加到共享内存的虚拟部分
- 为关键活动预留内存
- 在具有内存限制的应用程序中保留目标内存量
- 监视共享内存
这些主题未涵盖 DS_TOTAL_MEMORY 配置参数。此参数将给决策支持查询的内存分配设置上限。
设置操作系统共享内存配置参数
一些操作系统配置参数可以影响数据库服务器使用共享内存。由于参数名会随平台的改变而改变,而且并不是所有的参数都存在于所有平台上,因此不提供参数名。以下列表按功能描述了这些参数:
- 最大操作系统共享内存段大小(用字节或 KB 表示)
- 最小共享内存段大小(用字节表示)
- 最大共享内存标识数
- 共享内存的下边界地址
- 每个进程的最大连接共享内存段数
- 整个系统中最大共享内存量
仅限 UNIX:
- 最大信号标识数
- 最大信号数
- 每个标识的最大信号数
在 UNIX™ 上,机器说明文件包含您可用于配置操作系统资源的推荐值。可以在配置操作系统时使用这些推荐值。有关如何设置这些操作系统参数的信息,请查询操作系统手册。
最大共享内存段大小
当数据库服务器创建所需的共享内存段时,它将尝试获取尽可能大的操作系统段。数据库服务器尝试获取的第一个段大小等于其正在分配的部分(常驻、虚拟或通信)的大小,并四舍五入到 8 KB 的最近倍数。
如果请求的段大小超过允许的最大大小,那么数据库服务器会从操作系统接收到错误。 如果数据库服务器接收到错误,那么它会将请求的大小除以二,然后再试一次。继续尝试获取,直到可以创建 8 KB 倍数的最大段大小为止。然后,数据库服务器将创建与它所需要的一样多的附加段。
最大共享内存标识数 (UNIX™)
共享内存标识会在虚拟处理器尝试连接共享内存时影响数据库服务器的运行。操作系统使用共享内存标识来标识共享内存段。对于大多数操作系统来说,虚拟处理器根据先来先服务的原则接收标识,直到基本上达到为操作系统所定义的限制。有关共享内存标识的更多信息,请参阅虚拟处理器如何连接到共享内存。
您或许能够通过将共享内存标识数乘以最大共享内存段大小来计算操作系统可以分配的最大共享内存量。
信号 (UNIX)
数据库服务器需要一个 UNIX™ 信号用于每个虚拟处理器,一个用于每个通过共享内存(ipcshm 协议)连接到数据库服务器的用户,六个用于数据库服务器实用程序,以及十六个用于其他用途。
设置数据库服务器共享内存配置参数
可以修改影响共享内存的常驻或虚拟部分的配置参数。
可以使用文本编辑器来修改共享内存配置参数。有关这些配置参数的列表,请参阅《GBase 8s 管理员参考》中 onconfig 门户网站:按功能类别排列的配置参数的内容。
在 UNIX™ 上,您必须是 root 或 Gbasedbt 用户才能使用其中任何一种。
设置常驻共享内存的参数
以下列表中包含 onconfig 文件中的参数,这些参数指定了缓冲池和内部表在共享内存的常驻部分中的配置。在对配置参数所做的任何更改生效前,您必须关闭并重新启动数据库服务器。有关配置参数的描述,请参阅《GBase 8s 管理员参考》。
BUFFERPOOL
指定缓冲池的信息,该缓冲池必须给定义给数据库空间使用的每个不同页大小。
LOCKS
指定数据库对象(例如,行、键值、页和表)的初始锁数。
LOGBUFF
指定逻辑日志缓冲区的大小。
PHYSBUFF
指定物理日志缓冲区的大小。
RESIDENT
指定数据库服务器共享内存的常驻部分的驻留。
SERVERNUM
指定本地主机上数据库服务器的唯一标识号。
SHMTOTAL
指定将由数据库服务器使用的总内存量。
设置虚拟共享内存的参数
有多个配置参数影响共享内存的虚拟部分。
以下列表包含用于配置共享内存的虚拟部分的配置参数:
DS_HASHSIZE
数据分发高速缓存中列表的散列存储区数。
DS_POOLSIZE
数据分发高速缓存中的最大条目数。
PC_HASHSIZE
为 UDR 高速缓存和数据库服务器使用的其他高速缓存指定散列存储区数。
PC_POOLSIZE
指定可以存储在 UDR 高速缓存中的 UDR 的数目(SPL 例程和外部例程)。此外,此参数指定了其他数据库服务器高速缓存的大小,如类型名高速缓存和 opclass 高速缓存。
SHMADD
指定动态添加的共享内存段的大小。
SHMNOACCESS
指定不用于连接共享内存的虚拟内存地址范围的列表。使用该参数可避免与其他进程发生冲突。
EXTSHMADD
指定用户定义的例程在用户定义的虚拟处理器中运行时,添加的虚拟扩展段的大小。
SHMTOTAL
指定将由数据库服务器使用的总内存量。
SHMVIRTSIZE
指定共享内存的虚拟部分的初始大小。
STACKSIZE
指定数据库服务器用户线程的堆栈大小。
设置共享内存性能的参数
可以修改用于指定共享内存信息的配置参数。
以下配置参数影响共享内存性能。
AUTO_READAHEAD
为查询指定自动预读方式或禁用自动预读操作。自动预读操作通过在数据库服务器检测到查询遇到 I/O 时发出异步页请求,以帮助提高查询性能。 异步页请求通过将查询处理与从磁盘检索数据并将数据放入缓冲池所需的处理相叠加,从而可以提高查询性能。
CKPTINTVL
如果需要检查点并且 RTO_SERVER_RESTART 配置参数没有设置为打开自动检查点调整,请指定在数据库服务器检查该检查点之前可以耗用的最大秒数。
CLEANERS
指定数据库服务器要运行的页清除程序线程数。
RA_PAGES
指定数据库服务器在执行数据或索引记录的顺序扫描时尝试预读的磁盘页数。
指定数据库服务器在顺序扫描数据或索引记录期间尝试预读的磁盘页数。如果启用了 AUTO_READAHEAD 配置参数,服务器将忽略 RA_PAGES 配置参数中指定的信息。
RA_THRESHOLD
指定未处理的内存页素,这些内存页在读取后导致数据库服务器在磁盘上预读。
使用文本编辑器设置共享内存参数
可以使用文本编辑器设置有关常驻和虚拟共享内存以及共享内存性能的配置参数。 在 onconfig 文件中找到该参数,输入一个或多个新的值,然后重新将文件写入磁盘。更改生效之前,您必须关闭并重新启动数据库服务器。
设置 SQL 语句高速缓存参数
下表显示了可以配置 SQL 语句高速缓存的不同方法。
表 1. 配置 SQL 语句高速缓存
| 配置参数 | 用途 | onmode 命令 |
|---|---|---|
| STMT_CACHE | 打开、启用或禁用内存中的 SQL 语句高速缓存。如果已打开,请指定 SQL 语句高速缓存能否保存已解析和优化的 SQL 语句。 | onmode -e mode |
| STMT_CACHE_HITS | 指定将语句完全插入到 SQL 语句高速缓存之前,命中(引用)该语句的次数。 | onmode -W STMT_CACHE_HITS |
| STMT_CACHE_NOLIMIT | 控制是否在 SQL 语句高速缓存的大小大于 STMT_CACHE_SIZE 值之后将语句插入到该高速缓存中。 | onmode -W STMT_CACHE_NOLIMIT |
| STMT_CACHE_NUMPOOL | 定义 SQL 语句高速缓存的内存池数。 | 无 |
| STMT_CACHE_SIZE | 指定 SQL 语句高速缓存的大小。 | 无 |
使用以下 onstat 选项可监视 SQL 语句高速缓存:
- onstat -g ssc
- onstat -g ssc all
- onstat -g ssc pool
有关这些配置参数、onstat -g 选项以及 onmode 命令的更多信息,请参阅《GBase 8s 管理员参考》。
有关限定和恒等语句的详细信息,请参阅《GBase 8s SQL 指南:语法》。
设置共享内存
要设置共享内存,使数据库服务器脱机然后在线。有关如何使数据库服务器从在线模式转到脱机方式的信息,请参阅从任何方式立即更改到脱机方式。
打开或关闭常驻共享内存的驻留
可以使用以下两种方法中的任何一个为共享内存的常驻部分打开或关闭驻留
- 使用 onmode 实用程序可在数据库服务器处于在线模式时立刻逆转共享内存的状态。
- 更改 onconfig 文件中的 RESIDENT 参数,可在下次设置数据库服务器共享内存时打开或关闭共享内存驻留。
有关共享内存常驻部分的描述,请参阅共享内存的常驻部分。
在在线模式下打开或关闭驻留
要在数据库服务器处于在线模式时打开或关闭驻留,请使用 onmode 实用程序。
要立刻为共享内存的常驻部分打开驻留,请运行以下命令:% onmode -r
要立刻为共享内存的常驻部分关闭驻留,请运行以下命令:% onmode -n
这些命令不会更改 onconfig 文件中 RESIDENT 参数的值。也就是说,这种更改不是永久的,驻留会在您下一次设置共享内存时回复到 RESIDENT 参数所指定的状态。在 UNIX™ 上,您必须是 root 或 gbasedbt用户才能打开或关闭驻留。
重新启动数据库服务器时打开或关闭驻留
可以使用文本编辑器打开或关闭驻留。 要更改驻留的当前状态,请使用文本编辑器定位 RESIDENT 参数。将 RESIDENT 设置为 1 以打开驻留或设置为 0 以关闭常驻,然后重新将文件写入磁盘。更改生效之前,您必须关闭并重新启动数据库服务器。
将段添加到共享内存的虚拟部分
可以使用 onmode 实用程序的 -a 选项将指定大小的段添加到虚拟共享内存。
正常情况下,无需将段添加到虚拟共享内存,因为数据库服务器会按需自动添加段。
如果限制了操作系统段的数目并且初始段大小与所需的数量相比太小,以至于快要超过操作系统对共享内存段的限制,这时使用 onmode 实用程序添加段这一选项将是有用的。
为关键活动保留内存
保留特定量的内存,以供在需要执行关键活动(例如,回滚活动)且数据库服务器可用内存有限时使用。这样可以在执行关键活动期间服务器耗尽可用内存时,防止数据库服务器崩溃。
如果通过将 LOW_MEMORY_RESERVE 配置参数设置为指定值(以千字节为单位)来启用新的 LOW_MEMORY_RESERVE 配置参数,即使用户收到内存不足的错误,也可完成回滚之类的关键活动。如果 LOW_MEMORY_RESERVE 的值为 0,将关闭低内存保留功能。
例如,512 千字节即为合理的保留内存量。 要保留 512 千字节,请指定:
LOW_MEMORY_RESERVE 512
也可使用 onmode -wm 或 onmode -wf 命令来动态调整 LOW_MEMORY_RESERVE 配置参数的值。
使用 onstat -g seg 命令可监视 LOW_MEMORY_RESERVE 的值。查找输出的最后两行,其中包含短语“low memory reserve”。 这两个输出行中的第一行显示保留的内存大小(以字节为单位)。而第二行显示数据库服务器已使用此内存的次数和所需最大内存量。 重新启动服务器时,这两个值都将重置。
配置内存严重过低时的服务器响应
可配置内存严重过低时服务器为继续处理而采取的操作,而不是返回内存不足的错误。根据空闲时间、内存使用量和其他因素指定终止会话的条件,这样目标应用程序可继续处理。配置低内存响应对于存在内存限制的嵌入式应用程序很有用。
要设置自动低内存管理,请执行以下操作:
- 将 LOW_MEMORY_MGR 配置参数设置为 1,从而在数据库服务器启动时启用低内存管理。
- 通过使用带 scheduler lmm enable 自变量的 SQL 管理 API 命令来为要维护的内存量设置阈值参数。
要禁用自动低内存管理,请运行带 scheduler lmm disable 自变量的 SQL 管理 API 命令。
目标内存量的维护方案
本主题中的方案显示在具有内存限制的应用程序中可如何维护目标内存量。
假设您希望指定数据库服务器在可用内存小于或等于 10 MB 时开始运行低内存管理进程,此类进程可停止应用程序并释放内存。假设您还希望指定服务器在可用内存大于或等于 20 MB 时停止运行低内存管理进程:
- 将 LOW_MEMORY_MGR 配置参数设置为 1 并重新启动服务器,或者运行 onmode -wf 命令以更改 LOW_MEMORY_MGR 配置参数的值。
- 运行带 scheduler lmm enable 自变量和低内存参数的 SQL 管理 API 命令,如下所示:
EXECUTE FUNCTION task("scheduler lmm enable",
"LMM START THRESHOLD", "10MB",
"LMM STOP THRESHOLD", "20MB",
"LMM IDLE TIME", "300");
- 运行 onstat -g lmm 命令以显示有关自动低内存管理设置的信息,包括服务器尝试维护的内存量、服务器当前使用的内存量、低内存启动和停止阈值,以及与内存有关的其他统计信息。
也可在 online.log 文件中查看低内存管理信息。
监视共享内存
以下主题描述如何监视共享内存段、共享内存概要文件,以及如何使用特定的共享内存资源(缓冲区、锁存器和锁定)。
可以使用 onstat -o 实用程序捕获数据库服务器共享内存的静态快照用于以后分析和比较。
监视共享内存段
监视共享内存段可确定数据库服务器创建的段的数目和大小。数据库服务器将自动分配共享内存段,因此这些数字会更改。如果数据库服务器正在分配的共享内存段过多,那么您可以增加 SHMVIRTSIZE 配置参数。有关更多信息,请参阅 GBase 8s 管理员参考 中有关配置参数的主题。
onstat -g seg 命令列出了每个共享内存段的信息,包括段的地址和大小,以及可用或正在使用的内存量。有关 onstat -g seg 输出的示例,请参阅 GBase 8s 管理员参考 中有关 onstat 实用程序的信息。
监视共享内存概要文件和锁存器
监视数据库服务器概要文件以分析性能和共享内存资源的用法。
可以获取有关锁存器使用的统计信息以及有关特定锁存器的信息。这些统计信息可用作衡量系统活动的标准。
用于监视共享内存和锁存器的命令行实用程序
您可使用以下命令行实用程序来监视共享内存和锁存器。
onstat -s
使用 onstat -s 命令可获取锁存器信息。
onstat -p
运行 onstat -p 以显示有关数据库服务器活动以及等待锁存器的统计信息(在 lchwaits 字段中)。有关 onstat -p 输出的示例,请参阅*《*GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
SMI 表
查询 sysprofile 表以获取共享内存统计信息。此表包含 onstat -p 输出中可用的所有统计信息,除 ovbuff、usercpu 和 syscpu 统计信息以外。
监视缓冲区
可以同时获取有关缓冲区使用的统计信息以及有关特定缓冲区的信息。统计信息包括已高速缓存到缓冲区的数据写入数的百分比,以及线程需要等待获取缓冲区的次数。已高速缓存的写入数百分比是重要的性能指标。
缓冲区等待数提供了系统并行性的测量方法。
有关特定缓冲区的信息包括线程所包含的共享内存中所有缓冲区的列表。可以使用这些信息来跟踪特定缓冲区的状态。例如,您可以确定另一个线程是否正在等待缓冲区。
用于监视缓冲区的命令行实用程序
可以使用以下命令行实用程序监视缓冲区:
- onstat -p 实用程序
- onstat -B 实用程序
- onstat -b 实用程序
- onstat -X 实用程序
- onstat -R 实用程序
onstat -p 实用程序
运行 onstat -p 可获取有关高速缓存读取数和写入数的统计信息。以下高速缓存统计信息在输出显示的顶行中的四个字段内显示:
- 从共享内存缓冲区读取的次数 (bufreads)
- 已高速缓存的读取数百分比 (%cached)
- 写入共享内存的次数 (bufwrits)
- 已高速缓存的写入数百分比 (%cached)
- 有关通用页的信息(缓冲池中的非标准页)
在输出中,如果发生的读取数或写入数超过 232(取决于平台),那么读取数或写入数可能为负数。
onstat -p 选项还显示了指示会话需要等待缓冲区的次数的统计信息 (bufwaits)。
有关 onstat -p 输出的示例,请参阅《GBase 8s 管理员参考 》中有关 onstat 实用程序的信息。
onstat -B 实用程序
运行 onstat -B 可获取有关不在空闲列表中的所有缓冲区的信息,其中包括:
- 缓冲区的共享内存地址
- 当前持有缓冲区的线程的地址
- 正在等待每个缓冲区的第一个线程的地址
- 有关缓冲池的信息
有关 onstat -B 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
onstat -b 实用程序
运行 onstat -b 可获取以下有关每个缓冲区的信息:
- 当前线程所持有的每个缓冲区的地址
- 缓冲区中所容纳的页的页号
- 缓冲区中所容纳的页类型(例如,数据页、表空间页等等)
- 放置在缓冲区上的锁定的类型(互斥或共享)
- 当前正持有缓冲区的线程的地址
- 正在等待每个缓冲区的第一个线程的地址
- 有关缓冲池的信息
您可以将用户线程的地址与 onstat -u 显示中显示的地址相比较以获取会话标识号。
有关 onstat 显示的字段的更多信息,请参阅《GBase 8s 管理员参考》中的 onstat 实用程序的信息。
onstat -X 实用程序
运行 onstat -X 获取的信息与 onstat -b 同样,此外还可以获取有关所有正在等待缓冲区的线程的完整列表,而不单单是第一个等待的线程。
onstat -R 实用程序
使用 onstat -R 显示有关缓冲池的信息,其中包括有关缓冲区的信息。
SMI 表
查询 sysprofile 表可获取有关已高速缓存的读取数和写入数以及总缓冲区等待数的统计信息。以下是相关行。
dskreads
从磁盘读取的次数
bufreads
从缓冲区读取的次数
dskwrites
写入磁盘的次数
bufwrites
写入缓冲区的次数
buffwts
任何线程必须等待缓冲区的次数
监视缓冲池活动
可以获得与缓冲区可用性相关的统计信息以及有关每个 LRU 队列中缓冲区的信息。
统计信息包括数据库服务器尝试超过最大缓冲区数和磁盘写入数的次数(按导致缓冲区清空的事件分类)。这些统计信息可帮助您确定缓冲区数是否适当。每个 LRU 队列中缓冲区的信息包括队列的长度和该队列中已修改的缓冲区的百分比。
用于获取有关缓冲池活动的信息的命令行实用程序
可以使用 onstat 实用程序获取有关缓冲池活动的信息。还可以运行 Server Administrator 中的 onstat 选项。
有关 onstat 选项的更多信息,请参阅《GBase 8s 管理员参考》 中有关 onstat 实用程序的信息。
onstat -p 实用程序
onstat -p 输出包含指出数据库服务器尝试超过由 BUFFERPOOL 配置参数中的 buffers 值指定的最大共享缓冲区数的统计信息 (ovbuff)。
onstat -F 实用程序
运行 onstat-F 可获取有关已执行写入的计数(按写入类型)。(有关不同写入类型的说明,请参阅描述清空活动。)
onstat-F 命令显示了以下所有写入类型:
- 前台写入
- LRU 写入
- 块写入
onstat-F 命令还列出了以下有关页清除程序的信息:
- 页清除程序编号
- 页清除程序的共享内存地址
- 页清除程序的当前®状态
- 指定了页清除程序的 LRU 队列
有关 onstat -F 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
onstat -R 实用程序
运行 onstat -R 可获得有关每个 LRU 队列中的缓冲区数以及已修改或可用的缓冲区数以及百分比的信息。
有关 onstat -R 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat实用程序的信息。
SMI 表
查询 sysprofile 表可获得有关下列行中所容纳的写入类型的统计信息。
fgwrites
前台写入数
lruwrites
LRU 写入数
chunkwrites
块写入数
服务器故障后删除共享内存段
数据库服务器发生故障之后,必须关闭共享内存段。
此过程必须由具有 GBase 8s 使用经验的 DBA 来执行。请咨询技术支持以获取协助。此过程仅适用于 UNIX™ 系统。
如果 GBase 8s 数据库服务器实例发生故障,请遵循以下过程来删除共享内存段:
-
以用户 gbasedbt 的身份登录。
-
使用 onmode -k 命令使数据库服务器进入脱机方式,然后除去共享内存。
-
如果 onmode -k 命令失败并且服务器未脱机,请运行 onclean -k 命令,或执行以下步骤:
-
使用 onstat -g glo 命令显示多线程运行信息。
-
在上面命令的输出中,找到与 class 列中 cpu 的第一个实例关联的进程标识 (pid)。
例如,在 onstat -g glo 命令的以下输出中的 class 列内,cpu 出现了四次,其 pid 分别为 2599、2603、2604 和 2605:
MT global info:
sessions threads vps lngspins
0 49 14 1
sched calls thread switches yield 0 yield n yield forever
total: 900100 898846 1238 27763 423778
per sec: 327 325 2 12 151
Virtual processor summary:
class vps usercpu syscpu total
cpu 4 0.92 0.10 1.02
aio 4 0.02 0.02 0.04
lio 1 0.00 0.00 0.00
pio 1 0.00 0.00 0.00
adm 1 0.00 0.01 0.01
msc 1 0.00 0.00 0.00
fifo 2 0.00 0.00 0.00
total 14 0.94 0.13 1.07
Individual virtual processors:
vp pid class usercpu syscpu total
1 2599 cpu 0.25 0.06 0.31
2 2602 adm 0.00 0.01 0.01
3 2603 cpu 0.23 0.00 0.23
4 2604 cpu 0.21 0.03 0.24
5 2605 cpu 0.23 0.01 0.24
6 2606 lio 0.00 0.00 0.00
7 2607 pio 0.00 0.00 0.00
8 2608 aio 0.02 0.02 0.04
9 2609 msc 0.00 0.00 0.00
10 2610 fifo 0.00 0.00 0.00
11 2611 fifo 0.00 0.00 0.00
12 2612 aio 0.00 0.00 0.00
13 2613 aio 0.00 0.00 0.00
14 2614 aio 0.00 0.00 0.00
tot 0.94 0.13 1.07 -
使用 kill 命令(按顺序)终止进程标识 2599、2603、2604 和 2605。
-
-
如果尚未除去共享段,请遵循以下步骤:
-
确定服务器编号。
可以通过检查 GBase 8s 实例的 onconfig 文件来找到服务器编号。
-
将服务器编号与 21078 相加。
例如,如果服务器编号为 1,请将 1 与 21078 相加,从而得出 21079。
-
将上一步中的和转换为十六进制。
在上一个示例中,21079 的十六进制数为 5257。
-
在上一步中生成的十六进制值末尾添上 48。
例如,525748。
-
以 root 用户身份运行 ipcs 实用程序,以显示服务器保持打开的共享内存段(如果有)。搜索 key 列以查找 第四步 中得出的数字。
-
除去与 第四步 中得出的数字关联的每个共享内存标识。
-
有关 onclean 实用程序的更多信息,请参阅《GBase 8s 管理员参考》。
有关您系统的正确 ipcm 语法,请查阅操作系统文档。
数据存储
这些主题定义了术语并且对执行管理磁盘空间中描述的任务所必须理解的概念进行了说明。这些主题涵盖以下领域:
- 有关数据库服务器用来存储磁盘上数据的物理和逻辑单元的定义
- 有关如何计算存储数据所需的磁盘空间量的指示信息
- 有关如何安排磁盘空间以及哪里放置数据库和表的准则
- 有关使用外部表的指示信息
请参阅最新的 GBase 8s 发行说明以获取有关与这些主题中说明的与存储单元相关的最大值的补充信息。
物理存储单元和逻辑存储单元
数据库服务器使用物理存储单元分配磁盘空间。与大小会产生变动的逻辑存储单元不同,每个物理单元的大小都是固定或指定的,它们的大小由磁盘体系结构所确定。数据库服务器使用以下物理单元管理磁盘空间:
- 块
- 页面
- 扩展数据块
- BLOB 页
- 智能大对象页
数据库服务器在以下逻辑单元中存储数据:
- 数据库空间
- 临时数据库空间
- BLOB 空间
- 智能大对象空间
- 临时智能大对象空间
- 外部空间
- 数据库
- 表
- 表空间
- 分区
数据库服务器保留了下列存储结构以确保数据的物理和逻辑一致性:
- 逻辑日志
- 物理日志
- 保留页
以下主题描述了数据库服务器所支持的各种数据存储单元以及这些单元间的关系。有关保留页的信息,请参阅《GBase 8s 管理员参考》中有关磁盘结构和存储的主题。
块
块是专用于数据库服务器数据存储的物理磁盘最大单元。
块可以为管理员提供用于分配磁盘空间的特别大的单元。单个块的最大大小是 4 TB。允许的块数为 32,766。
以下存储空间由块组成:
- 数据库空间
- BLOB 空间
- 智能大对象空间
- 临时数据库空间
- 临时智能大对象空间
创建块时,请指定其路径、大小和关联的存储空间名称。
数据库服务器还将块用于镜像。对块制作镜像时,数据库服务器将在块上维护该数据的两个副本。每次执行写入主块的操作后,都会自动向镜像块执行相同的写操作。读操作在两个块之间平均分布。如果主块或镜像块出现故障,发生故障的块会标记为关闭,另一个块会执行所有操作,而不会中断用户对数据的访问。
创建表、索引和其他数据库对象时,会将块空间分配或指定给这些对象。分配的空间并不一定会使用。例如,创建表时,为其分配了空间,但只有在向该表添加数据时才会使用该空间。当数据库空间中的所有块都报告可用页数为 0 时,无法在该数据库空间中创建新的数据库对象。但是,只要现有数据库对象具有未使用的空间,您就可以继续向这些数据库对象添加数据。可以通过使用 onstat -d 命令来监视块。
块的磁盘分配
数据库服务器可以使用常规操作系统文件或原始磁盘设备存储数据。在 UNIX™ 上,只要性能是重要因素时,就必须使用原始磁盘设备存储数据。
GBase 8s 存储空间可位于使用常规操作系统文件的 NFS 安装的文件系统上。
UNIX 上的未缓冲或已缓冲磁盘的访问
可以使用两种方法分配磁盘空间。既可以使用通过操作系统缓冲的文件,也可以使用未缓冲的磁盘存取。
通过操作系统缓冲的文件通常称为熟文件。
未缓冲的磁盘存取也称为原始磁盘空间。
当数据库空间位于原始磁盘设备(也称为字符专用设备)上时,数据库服务器使用未缓冲的磁盘存取。
要创建原始设备,用原始界面配置块设备(硬盘)。该设备提供的存储空间称为原始磁盘空间。原始磁盘空间的块在物理上是连续的。
块的名称是 /dev 目录中字符专用文件的名称。在许多操作系统中,您可以通过文件名的第一个字母(通常是 r)将字符专用文件与块专用文件区别开来。例如,/dev/rsd0f 是与 /dev/sd0f 块专用设备相对应的字符专用设备。
有关更多信息,请参阅在 UNIX 上分配原始磁盘空间。
熟文件是操作系统管理的常规文件。熟文件块和原始磁盘块是同等可靠的。与原始磁盘空间不同,熟文件的逻辑连续块可能在物理上是不连续的。
您可以比原始磁盘空间更方便地分配熟文件。要分配熟文件,必须在任何现有的分区上创建该文件。块的名称是该文件的完整路径名。这些步骤在在 UNIX 上分配熟文件空间中描述。
在对性能要求不是很高的学习环境中,或对于静态数据而言,熟文件会很方便。如果您必须使用 UNIX™ 熟文件,请在那些文件中存储最不频繁存取的数据。将文件存储在最少活动的文件系统中。
对于熟文件块,操作系统将处理来自其自身的缓冲池的所有块 I/O,并确保所有对块的写入都在物理上写入磁盘。
虽然通常必须在 UNIX 上使用原始磁盘设备来获得更好的性能,但如果启用了 DIRECT_IO 配置参数,那么熟文件的性能可接近用于数据库空间块的原始设备的性能。此情况的发生是因为直接 I/O 会绕过文件系统缓冲区的使用。如果有 AIX® 操作系统,那么还可以为 GBase 8s 启用并发 I/O,以便在对使用熟文件的块执行读写时使用直接 IO。
要针对性能确定最佳设备,请对具有用于数据库空间和表布局的两种设备类型的系统执行基准测试。
使用原始磁盘时,无需采取任何特殊的操作来创建大于 2 GB 的块和文件。如果要在熟文件中创建大块,或者如果要将各种数据库导出和导入实用程序用于大文件,那么必须确保正确配置将保存大文件的文件系统。
可扩展块
可扩展块是 GBase 8s 可自动扩展的块,或当应用程序需要额外存储空间时可手动扩展的块。如果具有可扩展块,那么无需添加新块或耗费时间尝试确定哪种存储空间将耗尽空间,以及何时将耗尽空间。
通过配置 GBase 8s 自动添加更多存储空间,可以防止以下情况下可能发生的错误:分区需要更多存储空间,但是在分区所在空间内的任何一个块中都找不到该空间。
可扩展块必须位于非镜像数据库空间或临时数据库空间中。
可使用带 modify space sp_sizes 自变量的 SQL 管理 API 命令来修改可扩展块所在空间的扩展大小和创建大小。
偏移量
系统管理员可以将物理磁盘分成多个分区,这些分区是一个磁盘的不同部分,并且具有不同的路径名。虽然在原始磁盘设备上分配块时必须使用整个磁盘分区,但可以使用偏移量将分区或熟文件进一步分成更小的块。有关更多信息,请参阅磁盘布局准则。
有了对块大小的 4 TB 的限制,您可以通过为每个磁盘驱动器指定单个块来避免对磁盘进行分区。
可以使用偏移量来指示磁盘分区、文件或设备上给定块的位置。例如,假设创建了一个 1000 KB 的块,您希望将其分成两个块,每个块 500 KB。可以用偏移量 0 KB 来标记第一个块的开始,然后用偏移量 500 KB 来标记第二个块的开始。
您可以在创建、添加或从数据库空间、BLOB 空间或智能大对象空间删除块时指定偏移量。
还可能需要指定偏移量来阻止数据库服务器覆盖分区信息。在 UNIX 上分配原始磁盘空间说明了应在何时以及如何指定偏移量。
页
页是数据库服务器用于在 GBase 8s 数据库中读取和写入的物理磁盘存储单元。下图说明了页的概念,在磁盘片中用加深部分表示。
图: 磁盘上的页

在多数 UNIX™ 平台上,页大小是 2 KB。因为硬件会确定页的大小,所以您不能更改此值。
块包含一定数量的页,如下图所示。页总是完全包含在块中;也就是说,页不能穿过块边界。
图: 块,在逻辑上分成一系列页

有关数据库服务器如何在页中构造数据的信息,请参阅《GBase 8s 管理员参考》中有关磁盘结构和存储的章节
BLOB 页
BLOB 页是数据库服务器用于在 BLOB 空间中存储简单大对象(TEXT 或 BYTE 数据)的磁盘空间分配单元。有关 BLOB 页的描述,请参阅 BLOB 空间。
可将 BLOB 页的大小指定为数据库服务器页大小的倍数。 由于数据库服务器将 BLOB 页分配为连续的空间,所以在与数据大小尽可能接近的 BLOB 页中存储简单大对象将更加有效。下图说明了 BLOB 页的概念,以数据页的倍数(三倍)表示。
图: 磁盘上的 BLOB 页

有关 GBase 8s 如何构造存储在 BLOB 页中的数据的信息,请参阅《GBase 8s 管理员参考》的磁盘结构和存储主题中有关 BLOB 空间 BLOB 页的结构的部分。
就像块中的页一样,一定数量的 BLOB 页可在 BLOB 空间中组成块,如下图所示。BLOB 页总是完全包含在一个块中而不能穿过块的边界。
图: BLOB 空间中的块,在逻辑上分为一系列 BLOB 页

您可以选择在数据库空间中存储简单大对象数据,而不要将其存储在 BLOB 空间中。然而,对于大于两个页的简单大对象,如果在 BLOB 页中存储简单大对象,那么性能将提高。存储在数据库空间中的简单大对象可以共享一个页,但是存储在 BLOB 空间中的简单大对象不可以共享页。
有关如何确定 BLOB 页大小的信息,请参阅确定 BLOB 页大小。
智能大对象页
智能大对象页是数据库服务器用于在智能大对象空间内存储智能大对象的页类型。有关智能大对象空间的描述,请参阅智能大对象空间。与 BLOB 页不同,智能大对象页是不可配置的。智能大对象页的大小与数据库服务器页的相同,在 UNIX™ 上通常是 2 KB。
智能大对象空间中的分配单元是扩展数据块,而 BLOB 空间中的分配单元是 BLOB 页。就像块中的页一样,一定数量的智能大对象扩展数据块可在智能大对象空间中组成块,如下图所示。扩展数据块总是完全包含在一个块中而不能穿过块的边界。
图: 智能大对象空间中的块,在逻辑上分成一系列扩展数据块

智能大对象无法存储在数据库空间或 BLOB 空间。有关更多信息,请参阅智能大对象空间以及《GBase 8s 管理员参考》的磁盘结构和存储章节中有关智能大对象空间结构的部分。
数据库服务器根据一组启发式搜索(如写操作中的字节数)计算智能大对象的数据块大小。
扩展数据块数
当您创建表时,数据库服务器会分配固定数量的空间以包含要存储在该表中的数据。当此空间填满时,数据库服务器必须分配额外的存储空间。数据库服务器用来同时分配初始和后续存储空间的物理存储单元称为扩展数据块。
下图说明了扩展数据块的概念。
图: 由原始磁盘设备上 6 个连续页构成的扩展数据块

扩展数据块包含了为指定的表存储数据的邻接页的集合。(请参阅表。)每个永久数据库表都有两个与其关联的扩展数据块大小。初始扩展数据块大小是在表第一次创建时分配给该表的 KB 数。下一个扩展数据块大小是在初始扩展数据块(以及任何后续的扩展数据块)变满时分配给该表的 KB 数。对于永久表以及用户定义的临时表,下一个扩展数据块大小会在每个扩展数据块之后开始加倍。对于系统创建的临时表,下一个扩展数据块大小会在已添加了 4 个扩展数据块之后开始加倍。
在创建表时,您可以指定初始扩展数据块的大小,以及表增长时要添加的扩展数据块的大小。 还可以修改数据库空间的表中扩展数据块的大小,以及修改新的后续扩展数据块的大小。要指定初始扩展数据块大小和下一个扩展数据块大小,请使用 CREATE TABLE 和 ALTER TABLE 语句。有关更多信息,请参阅《GBase 8s SQL 指南:语法》和 《GBase 8s 管理员参考》中有关磁盘结构的部分。
当创建带有 CLOB 或 BLOB 数据类型列的表时,还应为智能大对象空间定义扩展数据块。有关更多信息,请参阅智能大对象空间的存储特征。
下图显示数据库服务器如何为扩展数据块分配 6 个页:
- 扩展数据块总是完全包含在一个块中;扩展数据块不能穿过块的边界。
- 如果数据库服务器找不到指定给下一个扩展数据块大小的连续磁盘空间,那么它将在数据库空间的下一个块中搜索连续的空间。
图: 扩展数据块的分配过程
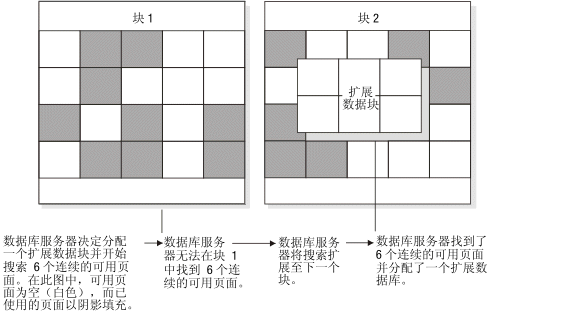
数据库空间
数据库空间是一种可包含 1 到 32766 个块的逻辑单元。放置数据库、表、逻辑日志文件以及数据库空间中的物理日志。
控制简单大对象数据的存储位置
数据库服务器管理员的关键职责是控制数据库服务器存储数据的位置。通过在最快的磁盘驱动器上存储访问频率很高的表或关键数据库空间(根数据库空间、物理日志和逻辑日志),可以提高性能。通过将关键数据存储在单独的物理设备上,您可以确保当包含非关键数据的磁盘中有一个发生故障时,该故障只会影响该磁盘上的数据可用性。
如下图所示,要控制数据库或表的放置,可使用 CREAT DATABASE 或 CREAT TABLE 语句的 IN dbspace 选项。
图: 使用 CREATE TABLE... IN 语句控制表的放置

在数据库空间中创建数据库或表之前,您必须先创建数据库空间。
数据库空间可以包含一个或多个块,如下图所示。您可以在任何时候添加更多的块。监视数据库空间块的填充度以及预期是否有必要向数据库空间分配更多的块,是高优先级的数据库服务器管理员任务。当数据库空间包含多个块时,不能指定数据所在的块。
图: 链接逻辑和物理存储单元的数据库空间
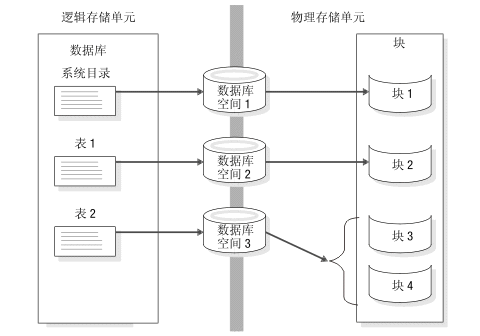
数据库服务器使用数据库空间来存储数据库和表。
创建标准或临时数据库空间时,可指定该数据库空间的页大小。您不能指定BLOB 空间、智能大对象空间或外部空间的页大小。如果不指定页大小,那么根数据库空间的大小将为缺省页大小。有关更多信息,请参阅创建具有非缺省页大小的数据库空间。
创建标准数据库空间时,可在数据库空间中指定表空间 tblspace 的第一个和下一个扩展数据块大小。如果要在必须将表空间 tblspace 扩展数据块放入非主块中时减少表空间 tblspace 扩展数据块的数量并减少这些情况发生的频率,请执行此操作。 有关更多信息,请参阅为表空间 tblspace 指定第一个和下一个扩展数据块大小。
您可以为镜像数据库空间中的每个块建立镜像。一旦数据库服务器分配了镜像块,它会立刻将该镜像块中的所有空间都标记为已满。请参阅监视磁盘使用量。
有关使用 Server Administrator 或 onspaces 执行以下任务的信息,请参阅管理磁盘空间。
- 创建数据库空间
- 向数据库空间添加块
- 重命名数据库空间
- 删除块
- 删除数据库空间、BLOB 空间或智能大对象空间
根数据库空间
根数据库空间是数据库服务器创建的初始数据库空间。根数据库空间是特殊的,因为它包含了保留页和内部表,它们将描述和跟踪所有物理和逻辑存储单元。(有关这些主题的更多信息,请参阅表以及《GBase 8s 管理员参考》中有关磁盘结构和存储的章节。)根数据库空间的初始块及其镜像是唯一在磁盘空间初始化期间创建的块。可在磁盘空间设置后将其他块添加到根数据库空间。
onconfig 配置文件中的以下磁盘配置参数引用根数据库空间的第一个(初始)块:
- ROOTPATH
- ROOTOFFSET
- ROOTNAME
- MIRRORPATH
- MIRROROFFSET
- TBLTBLFIRST
- TBLTBLNEXT
根数据库空间也是由 CREAT DATABASE 语句创建的任何数据库的缺省数据库空间位置。
根数据库空间是由数据库服务器为执行所请求的数据管理而创建的所有临时表的缺省位置。
请参阅根数据库空间的大小以获取有关应为根数据库空间分配多少空间的信息。还可以在设置数据库服务器磁盘空间后将额外的块添加到根数据库空间。
临时数据库空间
临时数据库空间是专门为临时表的存储而保留的数据库空间。您不能为临时数据库空间建立镜像。
数据库服务器不会删除临时数据库空间,除非明确指示应这么做。临时数据库空间是临时的指的只是数据库服务器在其不正常关闭时不保留任何数据库空间内容。
无论何时设置数据库服务器,所有临时数据库空间都将设置。数据库服务器会清除可能从数据库服务器上次关闭后留下的任何表。
数据库服务器不会为临时数据库空间执行逻辑或物理日志记录。由于没有用物理方式记录临时数据库空间,因此只有较少的检查点和 I/O 操作出现,以此提高了性能。
对于标准数据库空间中的临时表,数据库服务器会记录表的创建、扩展数据块的分配以及表的删除。相反,数据库服务器不会记录存储在临时数据库空间中的表。临时数据库空间中禁止使用逻辑日志可减少在逻辑恢复期间要前滚的日志记录数,从而提高关键停机时间内的性能。
使用临时数据库空间存储临时表还会减少存储空间备份的大小,因为数据库服务器不会备份临时数据库空间。
数据库服务器使用临时磁盘空间来存储备份期间被覆盖以及内存中发生查询处理而溢出的之前数据映像。请确保正确设置 DBSPACETEMP 环境变量或参数,以便指定的数据库空间具有足够空间,能满足您的需求。如果指定的数据库空间中空间不足,备份将失败,并且将使用根数据库空间,或者在填满根数据库空间之后,备份将失败。
如果您有多个临时数据库并且在临时表中执行了 SELECT 语句,那么查询结果将以循环顺序插入。
有关如何创建临时数据库空间的详细指示信息,请参阅创建临时数据库空间。
当数据库服务器作为辅助数据库服务器运行时,它需要临时数据库空间存储由只读查询生成的任何内部临时表。
BLOB 空间
BLOB 空间是由一个或多个只存储 TEXT 和 BYTE 数据的块组成的逻辑存储单元。BLOB 空间会以可能的最有效的方法存储 TEXT 和 BYTE 数据。可将与不同的表(请参阅表)关联的 TEXT 和 BYTE 列存储在相同的 BLOB 空间中。
数据库服务器将存储在 BLOB 空间中的数据直接写入磁盘。这些数据不会穿过常驻共享内存。如果穿过常驻共享内存,那么数据卷可能会占用大量缓冲池页,以至于使其他数据和索引页强制退出。由于同样的原因,数据库服务器不会将指定给 BLOB 空间的 TEXT 或 BYTE 对象写入逻辑日志或物理日志。当您备份逻辑日志时,数据库服务器会通过将 BLOB 空间对象从磁盘直接写入到逻辑日志备份带来记录这些 BLOB 空间对象。BLOB 空间对象不会穿过逻辑日志文件。
当您创建 BLOB 空间时,您可将其指定给一个或多个块。 您可以在任何时候添加更多的块。数据库服务器管理员的任务之一是监视块的填充度以及预期是否有必要向 BLOB 空间分配更多的块。有关如何监视块的填充度的指示信息,请参阅监视 BLOB 空间中的简单大对象。有关如何创建 BLOB 空间、向 BLOB 空间添加块或从 BLOB 空间删除块的指示信息,请参阅管理磁盘空间。
有关 BLOB 空间结构的信息,请参阅《GBase 8s 管理员参考》中有关磁盘结构和存储的主题。
智能大对象空间
智能大对象空间是由存储智能大对象的一个或多个块组成的逻辑存储单元。智能大对象由 CLOB(字符大对象)和 BLOB(二进制大对象)数据类型组成。用户定义的数据类型也可以使用智能大对象空间。有关数据类型的更多信息,请参阅《GBase 8s SQL 指南:参考》。
使用智能大对象空间的优势
与 BLOB 空间相比,智能大对象空间有下列优势:
- 类似于标准的 UNIX™ 文件,它们有读取、写入和搜索的属性。
程序员可以使用类似于 UNIX 函数的函数来读取、写入和查找智能大对象。GBase 8s 在GBase 8s ESQL/C 编程界面中提供该智能大对象接口。
- 它们是可以恢复的。
您可以记录对存储在智能大对象空间中的数据进行的所有写入操作。 如果事务期间发生故障,可以落实或回滚更改。
- 它们服从事务隔离方式。
可以锁定粒度级别不同的智能大对象,而锁定持续时间将遵循事务隔离级别的规则。
- 表行中的智能大对象无需在一个语句中检索。
应用程序可以使用GBase 8s ESQL/C 编程接口存储或检索以块计的智能大对象。
智能大对象空间和 Enterprise Replication
当您为 Enterprise Replication 定义复制服务器时,您必须创建智能大对象空间。Enterprise Replication 会将已复制的数据假脱机到智能大对象。在 CDR_QDATA_SBSPACE 配置参数中指定智能大对象空间名称。Enterprise Replication 使用缺省的日志方式,通过这种方式可创建智能大对象空间以用于假脱机行数据。CDR_QDATA_SBSPACE 配置参数接受多个智能大对象空间,最多可达 32 个智能大对象空间。Enterprise Replication 可以支持日志记录和非日志记录智能大对象空间的组合以便存储假脱机行数据。
在定义复制服务器时,可以使 Enterprise Replication 自动从存储池中配置磁盘空间,并设置相应的配置参数。如果 CDR_QDATA_SBSPACE 或 CDR_DBSPACE 配置参数未设置或设置为空,那么 cdr define server 命令将自动创建必需的磁盘空间,并将这些配置参数设置为相应值。
元数据、用户数据和保留区域
与 BLOB 空间和数据库空间一样,当您创建智能大对象空间时,可以为其指定一个或多个块。然而,智能大对象空间的第一个块始终有三个区域:
元数据区域
元数据标识了智能大对象空间的关键方面以及存储在智能大对象空间中的每个智能大对象,并且使数据库服务器能够操纵和恢复其中的智能大对象。
用户数据区域
用户数据是由用户应用程序存储在智能大对象空间中的智能大对象数据。块最多可有两个用户数据区域。
保留区域
当需要更多的空间时,数据库服务器会将保留区域中的空间分配给元数据或用户数据区域。 块最多可有两个保留区域。
当您将块添加到智能大对象空间时,您可以指定块是否包含元数据区域和用户数据区域或者是否要专门为用户数据保留块。您可以在任何时候添加更多的块。如果您正在更新智能大对象,那么原始磁盘上对用户数据的 I/O 将比熟的块文件上的 I/O 快很多。有关如何创建智能大对象空间、向智能大对象空间添加块或从智能大对象空间删除块的指示信息,请参阅管理磁盘空间。
不管数据库的日志记录设置如何,总是记录智能大对象空间元数据。
控制智能大对象数据的存储位置
您可在创建表时指定列的数据类型。对于智能大对象,可以指定 CLOB、BLOB 或用户定义的数据类型。如下图所示,要控制智能大对象的放置,可以使用 CREAT TABLE 语句 PUT 子句中的 IN sbspace 选项。
图: 控制智能大对象的放置

在 PUT 子句中指定智能大对象空间之前,必须首先创建智能大对象空间。有关如何使用 onspaces -c -S 命令创建智能大对象空间的更多信息,请参阅向数据库空间或 BLOB 空间添加块。有关如何在 PUT 子句中指定智能大对象特征的更多信息,请参阅《GBase 8s SQL 指南:语法》 中的 CREAT TABLE 语句。
如果未指定 PUT 子句,那么数据库服务器将在 SBSPACENAME 配置参数中指定的缺省智能大对象空间中存储智能大对象。有关 SBSPACENAME 的更多信息,请参阅《GBase 8s 管理员参考》中的配置参数主题。
智能大对象空间可以包含一个或多个块,如下图所示。当智能大对象空间包含多个块时,不能指定数据所在的块。
您可以在任何时候添加更多的块。监视智能大对象空间块的填充度以及预期是否有必要向智能大对象空间分配更多的块,是高优先级数据库服务器管理员任务。
图: 链接逻辑和物理存储单元的智能大对象空间
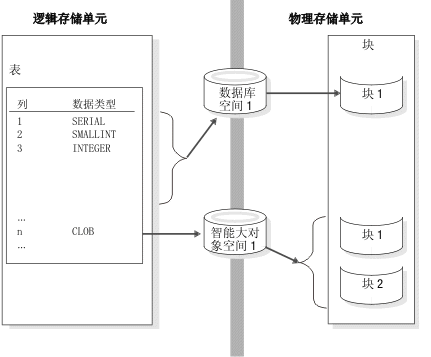
数据库服务器可使用智能大对象空间存储包含智能大对象的表列。数据库服务器使用数据库空间可存储其余的表列。
您可以为智能大对象空间建立镜像以便在介质故障的情况下加速恢复。有关更多信息,请参阅镜像。
有关使用 onspaces 执行以下任务的信息,请参阅管理磁盘空间。
- 创建智能大对象空间
- 向智能大对象空间添加块
- 更改智能大对象的存储特征
- 创建临时智能大对象空间
- 删除智能大对象空间
智能大对象空间的存储特征
作为数据库服务器管理员,您可以使用这些存储特征的系统缺省值,或者可以在用 onspaces -c 创建智能大对象空间时在 -Df 标记中指定这些特征。稍后,您可以使用 onspaces -ch 选项更改这些智能大对象空间特征。该管理员或程序员可以覆盖存储特征的这些缺省值以及单个表的属性。
智能大对象空间的扩展数据块大小
与表中的扩展数据块类似,智能大对象空间中的扩展数据块包含了存储智能大对象数据的邻接页的集合。
智能大对象空间中的分配单元是扩展数据块。数据库服务器根据一组启发式搜索(如写操作中的字节数)计算智能大对象的数据块大小。例如,如果操作请求写入 30 KB,那么数据库服务器会尝试分配一个大小为 30 KB 的扩展数据块。
对于大多数应用程序来说,必须使用数据库服务器为扩展数据块的大小计算的值。
如果您知道智能大对象的大小,您可以使用下列函数之一来设置扩展数据块大小。数据库服务器可将整个智能大对象分配为一个扩展数据块(如果块中存在该大小的扩展数据块):
- GBase 8s ESQL/C ifx_lo_specset_estbytes 函数
有关智能大对象的 GBase 8s ESQL/C 函数的更多信息,请参阅*《*GBase 8s ESQL/C 程序员手册》。
平均智能大对象大小
智能大对象的长度经常会变化。您可以提供智能大对象的平均大小以计算智能大对象空间的空间。可使用 onspaces -c -Df 选项的 AVG_LO_SIZE 标记来指定此平均大小。
要指定元数据区域的大小和位置,请在 onspaces 命令中指定 -Ms 和 -Mo 标志。如果未使用 -Ms 标志,数据库服务器将使用 AVG_LO_SIZE 的值来估计要为元数据区域分配的空间量。有关更多信息,请参阅计算智能大对象空间元数据的大小。
缓冲方式
当您创建智能大对象空间时,缺省的缓冲方式打开,这意味着要在共享内存的常驻部分使用缓冲池。
作为数据库管理员,您可以用 onspaces -c -Df 选项的 BUFFERING 标记来指定缓冲方式。缺省值是“buffering=ON”,这意味着要使用缓冲池。如果您关闭缓冲,数据库服务器将在共享内存的虚拟部分中使用专用缓冲区。
通常,如果对智能大对象的读取和写入操作小于 8 KB,那么创建智能大对象空间时不要指定缓冲方式。如果正读取或写入短的数据块(如 2 KB 或 4 KB),那么保留缺省值“buffering=ON”以便获取更好的性能。
上次访问时间
创建智能大对象空间时,可以指定数据库服务器是否必须保存上次用 onspaces -c -Df 选项的 ACCESSTIME 标记读取或更新的智能大对象的时间。 缺省值为“ACCESSTIME=OFF”。数据库服务器会将此最近访问时间保留在元数据区域中。
锁定方式
创建智能大对象空间时,可以指定数据库服务器是使用 onspaces -c -Df 选项的 LOCK_MODE 标记来锁定整个智能大对象还是智能大对象中一定范围的字节。缺省值为“LOCK_MODE=BLOB”,意味着锁定整个智能大对象。
日志记录
创建智能大对象空间时,可以指定是否为智能大对象启用日志记录。缺省值是不进行日志记录。有关更多信息,请参阅记录智能大对象空间和智能大对象。
当您使用日志记录数据库时,请为智能大对象空间启用日志记录。如果发生故障需要恢复日志,您可以使这些智能大对象与数据库中的其余智能大对象保持一致。
可使用 onspaces -c -Df 选项的 LOGGING 标记来指定日志记录状态。缺省值为“LOGGING=off”。可以用 onspaces -c -Df 选项更改日志记录状态。可以用 SQL 语句 CREATE TABLE 或 ALTER TABLE 中的 PUT 子句覆盖此日志记录状态。有关这些 SQL 语句的更多信息,请参阅《GBase 8s SQL 指南:语法》。
当您为智能大对象空间打开日志记录时,智能大对象将穿过共享内存的常驻部分。虽然应用程序可以检索多个智能大对象,但仍必须考虑可能穿过缓冲池和逻辑日志缓冲区的更大数据大小。有关更多信息,请参阅访问智能大对象。
智能大对象空间特征的继承级别
智能大对象空间特征的四种继承级别是系统、智能大对象空间、列和智能大对象。您可以使用智能大对象空间属性的系统缺省值或覆盖特定智能大对象空间、表中的列或智能大对象的系统缺省值。下图显示了智能大对象的存储特征层次结构。
图: 存储特征层次结构
此图显示您可以用以下方法覆盖系统缺省值:
- 使用 onspaces -c -S 命令的 -Df 标记可覆盖特定智能大对象空间的系统缺省值。
可以稍后用 onspaces -ch 选项更改智能大对象空间的这些智能大对象空间属性。有关 -Df 标记的有效范围的更多信息,请参阅《GBase 8s 管理员参考》中的 onspaces 主题。
- 在 CREAT TABLE 或 ALTER TABLE 语句的 PUT 子句中指定这些属性时,可以覆盖特定列的系统缺省值。
关于智能大对象空间的更多信息
下表列出了有关与使用和管理智能大对象空间相关的各种任务的信息源。
表 1. 查找智能大对象空间任务的信息
| 任务 | 引用 |
|---|---|
| 为智能大对象设置内存配置参数 | 管理共享内存 |
| 了解智能大对象页 | 智能大对象页 |
| 为智能大对象空间指定 I/O 特征 | 智能大对象空间的存储特征中的 onspaces 选项 |
| 为智能大对象空间分配空间 | 创建智能大对象空间 |
| 向智能大对象空间添加块 | 向智能大对象空间添加块 |
| 定义或改变智能大对象的存储特征 | 更改智能大对象的存储特征 《GBase 8s SQL 指南:语法》 中的 CREATE TABLE 或 ALTER TABLE 语句的 PUT 子句 |
| 监视智能大对象空间 | 监视智能大对象空间 |
| 为智能大对象空间设置日志记录 | 记录智能大对象空间和智能大对象 |
| 备份智能大对象空间 | 备份智能大对象空间 |
| 检查智能大对象空间的一致性 | 验证元数据 |
| 了解智能大对象空间的结构 | 《GBase 8s 管理员参考》中有关磁盘结构的主题 |
| 使用智能大对象空间的 onspaces | 《GBase 8s 管理员参考》中有关实用程序的主题 |
| 用 CLOB 或 BLOB 数据类型创建表 | 《GBase 8s SQL 指南:语法》 |
| 访问应用程序中的智能大对象 | 《GBase 8s ESQL/C 程序员手册》 |
临时智能大对象空间
使用临时智能大对象空间可在不用元数据日志记录和用户数据日志记录的情况下存储临时智能大对象。如果您将临时智能大对象存储在标准的智能大对象空间中时,将记录元数据。临时智能大对象空间类似于临时数据库空间。要创建临时智能大对象空间,使用带有 -t 选项的 onspaces -c -S 命令。
您可将临时大对象存储在标准的智能大对象空间或临时的智能大对象空间中。
- 如果在 SBSPACETEMP 参数中指定临时智能大对象空间,那么可在该临时智能大对象空间中存储临时智能大对象。
- 如果在 SBSPACENAME 参数中指定标准智能大对象空间,那么可在该标准智能大对象空间中存储临时和永久智能大对象。
- 如果在 CREATE TEMP TABLE 语句中指定临时智能大对象空间名称,那么可在该临时智能大对象空间中存储临时智能大对象。
- 如果在 CREATE TABLE 语句中指定永久智能大对象空间名称,那么可在该永久智能大对象空间中存储临时智能大对象。
- 如果省略 SBSPACETEMP 和 SBSPACENAME 参数并创建智能大对象,那么可能会显示错误消息 -12053。
- 如果在 SBSPACENAME 参数中指定临时智能大对象空间,那么就不能在该智能大对象空间中存储永久智能大对象。 您可将临时智能大对象存储在该智能大对象空间中。
比较临时和标准智能大对象空间
下表比较了标准和临时智能大对象空间。
表 1. 临时和标准智能大对象空间
| 特征 | 标准智能大对象空间 | 临时智能大对象空间 |
|---|---|---|
| 存储智能大对象 | 是 | 否 |
| 存储临时智能大对象 | 是 | 是 |
| 记录元数据 | 始终记录元数据 | 不记录元数据 |
| 记录用户数据 | 如果 LOGGING=ON,对于临时智能大对象,不记录用户数据;对于永久智能大对象,会记录用户数据 | 不记录用户数据 创建和删除空间,且记录块的添加 |
| 快速恢复 | 是 | 否(智能大对象空间在数据库服务器重新启动时清空) 要设置共享内存而不清除临时智能大对象,请指定 oninit -p。如果保留临时大对象,那么它们的状态是不确定的。 |
| 备份与复原 | 是 | 否 |
| 添加和删除块 | 是 | 是 |
| 配置参数 | SBSPACENAME | SBSPACETEMP |
临时智能大对象
使用临时智能大对象可存储不需要从备份复原或在快速恢复中记录重放的文本或映像数据(CLOB 或 BLOB)。临时智能大对象将在该用户会话中持续,并且比智能大对象更快更新。
除非在 ifx_lo_specset_flags 或 mi_lo_specset_flags 函数中设置了 LO_CREATE_TEMP 标志,否则将以与创建永久智能大对象相同的方式创建临时智能大对象。使用 mi_lo_copy 或 ifx_lo_copy 从临时智能大对象创建永久智能大对象。
只可在临时表中存储指向临时大对象的指针。如果您将它们存储在标准表中并重新引导数据库服务器,那么结果会生成一条错误信息,称大对象不存在。
下表比较了标准和临时智能大对象。
表 1. 临时和标准智能大对象
| 特征 | 智能大对象 | 临时智能大对象 |
|---|---|---|
| 创建标志 | LO_CREATE_LOG 或 LO_CREATE_NOLOG | LO_CREATE_TEMP |
| 回滚 | 是 | 否 |
| 日志记录 | 是,如果打开 | 否 |
| 持续时间 | 永久(直到用户将其删除) | 在用户会话或事务结束时删除 |
| 存储的表类型 | 永久或临时表 | 临时表 |
外部空间
外部空间是与表示外部数据位置的随机字符串关联的逻辑名。外部空间所引用的资源取决于访问其内容的用户定义的访问方法。
例如,数据库用户可能需要对以专有格式编码的二进制文件进行访问。首先,开发者会创建访问方法,它是存取数据的一组例程。这些例程将负责数据库服务器和外部文件之间的所有交互。DBA 然后将添加一个外部空间,该外部空间会将该文件作为其对数据库的目标。DBA 在外部空间中创建了表之后,用户可通过 SQL 语句访问这些专有文件中的数据。要找到这些文件,请使用外部空间信息。
外部空间不必是文件名。例如,它可以是网络位置。存取数据的例程可以用任何方式使用在与外部空间关联的字符串中找到的信息。
数据库
数据库是包含表和索引的逻辑存储单元。 (请参阅表。)每个数据库还包含跟踪有关数据库中许多元素(包括表、索引、SPL 例程和完整性约束)的信息的系统目录。
数据库位于由 CREATE DATABASE 语句指定的数据库空间中。当未在 CREATE DATABASE 语句中明确指定数据库空间时,数据库将位于根数据库空间中。当在 CREAT DATABASE 语句中明确指定了数据库空间时,此数据库空间的位置就是以下表的位置:
- 数据库系统目录表
- 属于该数据库的任何表
下图显示了 stores_demo 数据库中包含的表。
图: stores_demo 数据库

应用于数据库的大小限制与它们在数据库空间中的位置相关。要确保数据库中的所有表都创建在特定的物理设备上,只能向该设备指定一个块并创建仅包含该块的数据库空间。将数据库放置在该数据库空间中。当您在指定给特定的物理设备的块中放置数据库时,该数据库的大小不能超过该块的大小。
有关如何列出创建的数据库的指示信息,请参阅显示数据库。
表
在关系数据库系统中,表是一行列标题加上零行或多行数据值。列标题行标识了一个或多个列以及每一列的数据类型。
当创建表时,数据库服务器会为称为扩展数据块的页块中的表分配磁盘空间。(请参阅扩展数据块数。)您可以指定第一个以及任何后续扩展数据块的大小。
可以在创建表(通常用 CREAT TABLE 的 IN dbspace 选项)时,通过命名数据库空间将表放到特定的数据库空间中。不指定数据库空间时,数据库服务器会将该表放置在数据库所在数据库空间中。
您还可以:
- 在多个数据库空间上将表分段。然而,您不能将这些分段放在不同页大小的数据库空间中。所有分段可能都需要有相同的页大小。
您必须为指定哪些表行位于哪些数据库空间的表定义分布方案。
- 如果分段表使用基于表达式的或循环分发方案,请在单个数据库空间内创建分段表的多个分区。
表或表分段完全位于在其中创建它们的数据库空间中。数据库服务器管理员可以使用此事实来限制表的增长,方法是将表放置在数据库空间中然后当数据库空间变满时拒绝向其添加块。
由扩展数据块组成的表可以跨多个块,如下图所示。
图: 跨多个块的表
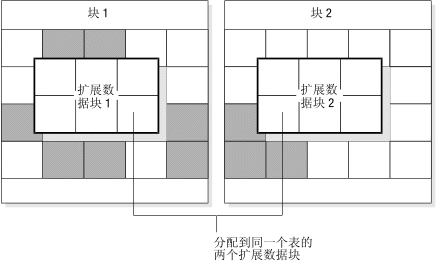
简单大对象位于 BLOB 页中,这些 BLOB 页可以位于带有表的数据页的数据库空间中或位于独立的 BLOB 空间中。
简单大对象位于 BLOB 页中,这些 BLOB 页可以位于带有表的数据页的数据库空间中或位于独立的 BLOB 空间中。使用 Optical Subsystem,您还可以将简单大对象存储在光存储子系统中。
已损坏的表
以下各项可能损坏表:
- 不正确的缓冲区清空
- 用户错误
- 在块顶部安装文件系统或另一个块
- 当更改的范围超出您要求的范围时进行删除或更新
已损坏的索引会导致表看起来已损坏,即使该表实际并未损坏也是如此。
oncheck 命令不能修复大多数已损坏的表。如果某个页已损坏,oncheck 可检测并尝试修理该页,但无法更正该页中的数据。
GBase 8s 的表类型
您可以在 GBase 8s 上的日志记录数据库中创建日志记录或非日志记录表。两种表类型为 STANDARD(日志记录表)和 RAW(非日志记录表)。缺省标准表如同较早版本中创建的没有指定特殊关键字的表一样。您既可以创建 STANDARD 也可以创建 RAW 表,并且可以将表从一个类型更改为另一个类型。
在非日志记录数据库中,STANDARD 和 RAW 表都是非日志记录的。在非日志记录数据库中,STANDARD 和 RAW 表之间的唯一区别在于 RAW 表不支持主键约束、唯一约束、引用约束或回滚。然而,可以为这些表建立索引并进行更新。
下表列出了 GBase 8s 中可用类型表的属性。标志值是 systables 的 flags 列中每种表类型的十六进制值。
表 1. GBase 8s 的表类型
| 特征 | STANDARD | RAW | TEMP |
|---|---|---|---|
| 永久 | 是 | 是 | 否 |
| 已记录 | 是 | 否 | 是 |
| 索引 | 是 | 是 | 是 |
| 约束 | 是 | 无引用约束或唯一约束 允许 NULL 和 NOT NULL 约束 | 是 |
| 回滚 | 是 | 否 | 是 |
| 可复原 | 是 | 是,如果未更新 | 否 |
| 可复原 | 是 | 是,如果未更新 | 否 |
| 可载入 | 是 | 是 | 是 |
| Enterprise Replication 服务器 | 是 | 否 | 否 |
| 高可用性集群中的主服务器 | 是 | 是,不能更改日志记录方式 | 是 |
| 高可用性集群中的辅助服务器 | 是 | 是,但任何操作都不可访问 | 是 |
| 标志值 | 无 | 0x10 | 无 |
标准永久表
STANDARD 表与数据库服务器创建的已记录的数据库中的表相同。STANDARD 表不使用轻量级追加。所有操作都是一条条地记录的,因此 STANDARD 表可以恢复和回滚。可备份与复原 STANDARD 表。日志记录使您能够在执行热复原或时间点复原时应用自上次物理备份起的更新。Enterprise Replication 允许位于 STANDARD 表上。
STANDARD 表是日志记录和非日志记录这两种数据库上的缺省类型。STANDARD 表如果存储在日志记录数据库中,将被记录;如果存储在非日志记录数据库中,将不被记录。
RAW 表
RAW 表是非日志记录的永久表,类似于非日志记录数据库中的表。支持但不记录 RAW 表中行内的更新、插入和删除操作。可在 RAW 表中定义索引,但是不能在 RAW 表中定义唯一约束、主键约束或引用约束。不支持将轻量级追加用于加载 RAW 表,但在 High-Performance Loader (HPL) 操作中和指定 INTO TEMP ... WITH NO LOG 的查询中例外。
无论是存储在日志记录数据库还是非日志记录数据库中,RAW 表都具有相同属性。如果更新了 RAW 表,那么除非在更新之后执行 0 级备份,否则不能可靠复原数据。如果自备份后尚未更新过表,那么可以从上次物理备份复原 RAW 表,但是仅备份逻辑日志并不足以复原 RAW 表。快速恢复可回滚 STANDARD 表上未完成事务,但不会回滚 RAW 表上的未完成事务。
RAW 表适用于初始装入和数据的验证。要装入 RAW 表,可以使用任何装入实用程序,包括 dbexport、DB-Access 的 LOAD 语句或表达式方式下的 HPL。如果在装入 RAW 表时发生错误或故障,那么得到的数据是发生故障时磁盘上的任何数据。
- 不要在事务中使用 RAW 表。在已装入数据后,请首先使用 ALTER TABLE 语句将表更改为 STANDARD 类型并执行 0 级备份,然后再在事务中使用该表。
- 不要在 RAW 或 TEMP 表上使用 Enterprise Replication。
在高可用性集群环境中使用 RAW 表时,有一些限制。因为不记录对 RAW 表所作修改,并且辅助服务器(包括 HAC、RHAC 和 SSC)使用日志记录与主服务器保持同步,所以将限制对 RAW 表执行某些操作:
- 在主服务器上,可以创建、删除和访问 RAW 表;但是,不允许将表方式从未记录更改为已记录,或从已记录更改为未记录。在高可用性集群环境中更改表的方式会生成错误 -19845。
- 在辅助服务器(HAC、SSC 或 RHAC)上,任何操作都不能访问 RAW 表。尝试从 SQL 访问 RAW 表会生成错误 -19846。
Temp 表
Temp 表是临时已记录的表,它们将在用户会话关闭、数据库服务器关闭或故障后重新引导时删除。Temp 表支持索引、约束和回滚。您不能复原、备份或复原 Temp 表。Temp 表支持批量操作(如轻量级追加),快速将行添加到每个表分段的末尾。
表类型的属性
这些主题说明了装入表、快速恢复以及表类型的备份与复原。
将数据装入表
GBase 8s 创建在缺省情况下使用日志记录的 STANDARD 表。数据仓库应用程序可以有需要花费长时间装入的巨型表。装入非日志记录表比装入日志记录表要快。可使用 CREATE RAW TABLE 语句创建 RAW 表或使用 ALTER TABLE 语句在装入 STANDARD 表之前将该表更改为 RAW 表。在装入表后,请对该表运行 UPDATE STATISTICS。
有关使用 ALTER TABLE 将表从日志记录更改为非日志记录的更多信息,请参阅《GBase 8s SQL 指南:语法》。
表类型的快速恢复
下表显示了 GBase 8s 中可用的表类型的快速恢复方案。
表 1. 表类型的快速恢复
| 表类型 | 快速恢复行为 |
|---|---|
| Standard | 快速恢复成功。所有已落实的日志记录将前滚,而所有未完成的事务将回滚。 |
| RAW | 如果自上次修改原始表后已完成检查点,那么所有数据都可恢复。 上一个检查点后的插入、更新和删除将丢失。 RAW 表中未完成的事务将不回滚。 |
备份与复原 RAW 表
下表说明了 GBase 8s 中可用的表类型的备份方案。
表 1. 在 GBase 8s 上备份表
| 表类型 | 是否允许备份? |
|---|---|
| Standard | 是。 |
| Temp | 否。 |
| RAW | 是。如果更新 RAW 表,必须对其进行备份,这样就可以复原其中的所有数据。仅备份逻辑日志是不够的。 |
在装入 RAW 表或将 RAW 表更改为 STANDARD 类型后,必须执行 0 级备份。
下表显示了这些表类型的复原方案。
表 2. 在 GBase 8s 上复原表
| 表类型 | 是否允许复原? |
|---|---|
| Standard | 是。热复原、冷复原和时间点复原都可以起作用。 |
| Temp | 否。 |
| RAW | 复原 RAW 表时,它只包含上次备份时位于磁盘上的数据。由于未记录 RAW 表,因此任何上次备份以来发生的更改都不会复原。 |
备份与复原 RAW 表
下表说明了 GBase 8s 中可用的表类型的备份方案。
表 1. 在 GBase 8s 上备份表
| 表类型 | 是否允许备份? |
|---|---|
| Standard | 是。 |
| Temp | 否。 |
| RAW | 是。如果更新 RAW 表,必须对其进行备份,这样就可以复原其中的所有数据。仅备份逻辑日志是不够的。 |
在装入 RAW 表或将 RAW 表更改为 STANDARD 类型后,必须执行 0 级备份。
下表显示了这些表类型的复原方案。
表 2. 在 GBase 8s 上复原表
| 表类型 | 是否允许复原? |
|---|---|
| Standard | 是。热复原、冷复原和时间点复原都可以起作用。 |
| Temp | 否。 |
| RAW | 复原 RAW 表时,它只包含上次备份时位于磁盘上的数据。由于未记录 RAW 表,因此任何上次备份以来发生的更改都不会复原。 |
临时表
数据库服务器必须为以下两类临时表提供磁盘空间:
- 使用 SQL 语句(例如 CREATE TEMP TABLE. . . 或(使用 Extended Parallel Server)SELECT .... INTO SCRATCH)创建的临时表. .
- 数据库服务器在其处理查询时创建的临时表
请确保您的数据库服务器已为用户创建的和数据库服务器创建的这两种临时表配置了足够的临时空间。对数据库服务器的一些使用需要与永久存储空间一样多的临时存储空间,或更多。
在缺省情况下,数据库服务器会将临时表存储在根数据库空间中。如果您决定不在根数据库空间中存储临时表,那么可以使用 DBSPACETEMP 环境变量或 DBSPACETEMP 配置参数来指定临时表的数据库空间列表。
创建的临时表
可以使用以下任一 SQL 语句创建临时表:
- CREATE TABLE 语句的 TEMP TABLE 选项
- SELECT 语句的 INTO TEMP 子句,例如 SELECT * FROM customer INTO TEMP cust_temp
只有创建了临时表的会话才可以使用该表。 当会话退出时,该表将自动删除。
当您创建临时表时,数据库服务器将使用下列条件:
- 如果用于填充 TEMP 表的查询未产生任何行,那么数据库服务器将创建一个空的且未分段的表。
- 如果查询生成的行未超过 8 KB,那么临时表将只位于一个数据库空间中。
- 如果生成的行超过 8 KB,那么数据库服务器会创建多个分段并使用循环分段存储方案进行填充,除非您为该表指定了分段存储方法和位置。
如果使用 CREATE TEMP 和 SELECT...INTO TEMP SQL 语句并且 DBSPACETEMP 已被设置:
- 列表中的 LOGGING 数据库空间被用来创建指定或暗示 WITH LOG 子句的表。
- 列表中的 NON-LOGGING 临时数据库空间被用来创建指定 WITH NO LOG 子句的表。
当使用了 CREATE TEMP 和 SELECT...INTO TEMP SQL 语句,并且 DBSPACETEMP 还未设置或不包含正确类型的数据库空间时,GBase 8s 会使用数据库的数据库空间来存储临时表。请参阅《GBase 8s SQL 指南:语法》以获取更多信息。
存储用户创建的临时表的位置
如果应用程序允许您指定临时表的位置,那么您可以指定日志记录空间,也可以指定专门为临时表创建的非日志记录空间。
有关创建临时数据库空间的信息,请参阅《GBase 8s 管理员参考》中的 onspaces 主题。
如果未指定临时表的位置,那么数据库服务器会将临时表存储在指定为 DBSPACETEMP 配置参数或环境变量的自变量的某一个空间中。数据库服务器将记住上一个用于临时表的数据库空间的名称。当数据库服务器接收到临时存储空间的另一个请求时,它将使用下一个可用的数据库空间均匀地将 I/O 分布在临时存储空间中。
有关在您未列出作为 DBSPACETEMP 的自变量的任何列表时数据库存储临时表位置的信息,请参阅《GBase 8s 管理员参考》 中 DBSPACETEMP 一节。
当您使用应用程序创建临时表时,您可以使用该临时表直到该应用程序退出或执行下列操作之一为止:
- 关闭创建该表所在的数据库并打开其他数据库服务器中的数据库
- 关闭创建该表所在的数据库
- 显式地删除临时表
数据库服务器创建的临时表
数据库服务器有时会在对数据库运行查询或备份该数据库时创建临时表。
该数据库服务器可能在下列任何情况下创建临时表:
- 包含 GROUP BY 或 ORDER BY 子句的语句
- 使用带有 UNIQUE 或 DISTINCT 关键字的聚集函数的语句
- 使用自动索引或散列连接的 SELECT 语句
- 复杂 CREATE VIEW 语句
- 创建滚动游标的 DECLARE 语句
- 包含相关子查询的语句
- 包含在 IN 或 ANY 子句中发生的子查询的语句
- CREATE INDEX 语句
当启动表创建的进程完成时,数据库服务器会删除其创建的临时表。
如果数据库服务器在没有除去临时表的情况下关闭,那么数据库服务器在下次启动时将除去这些临时表。要启动数据库服务器而不除去临时表,请运行带 -p 选项的 oninit 命令。
应用程序和分析工具可以定义其中派生表包含与基本表连接的多个视图的查询,可能包括数百列。数据库服务器会尝试将视图或派生表折叠放入主查询中。无法折叠的任何此类视图或派生表都会具体化到临时表中。临时表会排除主查询中未引用的所有列。临时表仅使用在 Projection 子句以及父查询的其他子句(包括 WHERE、HAVING、GROUP BY 和 ON 子句)中引用的列进行创建。
通过从系统生成的临时表中排除主查询中未引用的任何列,这一简化模式可以节省存储资源,避免在未使用的列中进行不必要的数据 I/O,从而提高查询性能。
但是,在嵌套查询中,只会检查父查询中来自视图和派生表的投影列,而不会检查高于直接父查询的级别中的投影列。
除了临时表以外,数据库服务器还使用临时磁盘空间来存储发生备份时覆盖的数据记录的前映像,以及用于内存中发生的查询处理中的溢出。确保正确设置了 DBSPACETEMP 环境变量或 DBSPACETEMP 配置参数,以指定具有满足您需求的足够空间的数据库空间。如果指定的数据库空间中空间不足,备份将失败,并且将使用根数据库空间,或者在填满根数据库空间之后,备份将失败。
存储数据库服务器创建的临时表的位置
当数据库服务器创建临时表时,它会将临时表存储在您在 DBSPACETEMP 配置参数或环境变量中指定的某个数据库空间中。环境变量将取代配置参数。
当您未在 DBSPACETEMP 中指定任何临时数据库空间,或指定的临时数据库空间的空间不够时,数据库服务器将根据以下规则在标准数据库空间中创建该表:
- 如果已使用 CREATE TEMP TABLE 创建了临时表,那么数据库服务器会将该表存储在包含该表的数据库的数据库空间中。
- 如果用 SELECT 语句的 INTO TEMP 选项创建临时表,那么数据库服务器在根数据库空间中存储此表。
表空间
数据库服务器管理员有时必须跟踪特定表的磁盘使用。表空间包含分配到给定表或表分段(如果表已分段)的所有磁盘空间。独立表空间包含已分配给关联索引的磁盘空间。
例如,表空间与块的任意特定部分或者甚至是任意特定块都不一致。组成表空间的索引和数据可能散射在您所有块中。然而,表空间代表了专用于特定表的块中空间的方便记帐实体。
表中的最大表空间数
您可以在表中指定最多达 2**20(或 1,048,576)的表空间数。
表和索引表空间
表表空间包含下列类型的页:
- 分配给数据的页
- 分配给索引的页
- 用于在数据库空间中存储 TEXT 或 BYTE 数据的页(不是用于在 BLOB 空间中存储 TEXT 或 BYTE 数据的页)
- 跟踪页在表扩展数据块内使用的位图页
索引表空间包含下列类型的页:
- 分配给索引的页
- 跟踪页在索引扩展数据块内使用的位图页
下表说明了用于构成部分 stores_demo 数据库的三个表的表空间。每个表空间上只有一个表(或表分段)。索引位于独立于关联表的表空间中。BLOB 页代表存储在数据库空间中的 TEXT 或 BYTE 数据。
图: stores_demo 数据库中的样本表空间
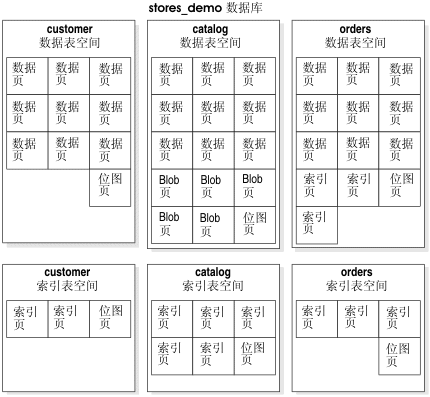
扩展数据块交错
数据库服务器将属于表空间的页分配为扩展数据块。虽然扩展数据块中的页是连续的,但扩展数据块还是可能会分散在表所在整个数据库空间中(甚至在不同的块上)。
下图描绘的情境是:两个非连续扩展数据块属于 table_1 的表空间,而第三个扩展数据块属于 table_2 的表空间。table_2 扩展数据块位于第一个 table_1 扩展数据块和第二个 table_1 扩展数据块之间。当发生这种情况时,扩展数据块会交错。 因为在 table_1 中的顺序访问搜索需要磁盘头在 table_2 扩展数据块中进行搜寻,因此性能会比 table_1 扩展数据块连续时要差。
图: 属于一个数据库空间中两个不同表空间的三个扩展数据块

表分段存储和数据存储
分段存储功能将赋予您对数据库存储数据的位置的额外控制。您不但可以指定单个表和索引的位置,而且可以指定表和索引分段的位置(这些分段是位于不同存储空间的表或索引的不同部分)。您可以将下列存储空间分段:
- 数据库空间
- 智能大对象空间
通常您在最初创建表时将表分段。CREATE TABLE 语句将采用以下某种表格:
CREATE TABLE tablename ... FRAGMENT BY ROUND ROBIN IN dbspace1, dbspace2, dbspace3;
CREATE TABLE tablename ...FRAGMENT BY EXPRESSION
<Expression 1> in dbspace1,
<Expression 2> in dbspace2,
<Expression 3> in dbspace3;
FRAGMENT BY ROUND ROBIN 和 FRAGMENT BY EXPRESSION 关键字指的是两种不同的分布方案。两个语句都将分段与数据库空间关联。
对表进行分段时,还可在相同的数据库空间内为表创建多个分区,如此示例中所示:
CREATE TABLE tb1(a int)
FRAGMENT BY EXPRESSION
PARTITION part1 (a >=0 AND a < 5) in dbs1,
PARTITION part2 (a >=5 AND a < 10) in dbs1
...
;
下图说明了分段在指定数据位置中的角色。
图: 链接逻辑单元(包括表分段)和物理存储单元的数据库空间
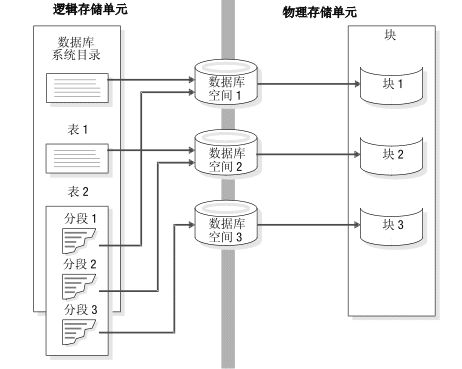
有关空间和分区的信息,请参阅管理磁盘空间。
存储数据所需的磁盘空间量
要确定需要多少磁盘空间,请遵循以下步骤:
- 计算需要多少根数据库空间。
- 估计要分配给所有数据库服务器数据库的总磁盘空间量,包括用于开销和增长的空间。
以下主题说明了这些步骤。
根数据库空间的大小
可以计算根数据库空间的大小,此空间存储了描述数据库服务器的信息。
要计算根数据库空间的大小,请考虑下列存储结构:
- 物理日志(最小 200 KB)
- 逻辑日志文件(最小 200 KB)
- 临时表
- 数据
- 系统数据库(sysmaster、sysutils、syscdr、sysuuid)以及系统目录(大小随版本的不同而变化)
- 保留页 (~24 KB)
- 表空间 tblspace(最小 100 到 200 KB)
- 额外空间
此估计值是初始化数据库服务器之前根数据库空间的大小。根数据库空间的大小取决于您是计划在根数据库空间还是在其他数据库空间中存储物理日志、逻辑日志和临时表。根数据库空间必须足够大以便在磁盘初始化期间进行最小大小配置。
使用小日志大小(例如,三个 1000 KB 的日志文件或总日志大小为 3000 KB)设置系统。在设置完成后,请创建新的数据库空间、移动逻辑日志文件并调整其大小、删除根数据库空间中的原始日志。然后将物理日志移至另一个数据库空间。此过程可最大限度降低日志在根数据库空间中的影响,原因是:
- 移动这些日志后,根数据库空间中不会有大量空间保留不用。
- 日志不会与根数据库空间在相同磁盘上争用空间和 I/O。
有关如何移动日志的详细信息,请参阅将逻辑日志文件移至另一个数据库空间和更改物理日志的位置和大小。
如果在服务器已初始化后,需要将根数据库空间设置得更大,可以向根数据库空间添加新块。此外,可以通过使用自动空间管理来扩展根数据库空间中的块。
物理日志和逻辑日志
存储在 ONCONFIG 参数 PHYSFILE 中的值定义了在最初创建数据库服务器时物理日志的大小。在使用 oninit -i 命令初始化磁盘空间并使数据库服务器进入在线模式后,请使用 onparams 实用程序更改物理日志的位置和大小。有关估算物理日志的建议包含在物理日志的大小和位置中。
要计算逻辑日志文件的大小,请将 ONCONFIG 参数 LOGSIZE 的值乘以逻辑日志文件数。有关估算逻辑日志的建议,请参阅估计日志文件的大小和数量。
临时表
分析最终用户应用程序以估计数据库服务器可能要求临时表具备的磁盘空间量。尝试估计这些语句中有多少将会并发运行。已返还的行和列所占据的空间将提供估计所需的空间量的良好基础。
数据库服务器在热复原期间创建的最大的临时表与逻辑日志的大小相等。您可以通过增加所有逻辑日志文件的大小来计算逻辑日志的大小。
您还必须分析最终用户应用程序以估计数据库服务器可能需要用于显式临时表的磁盘空间量。
关键数据
不要将数据库和表存储在根数据库空间中。为包含关键数据(如物理日志和逻辑日志)的根数据库空间和其他数据库空间建立镜像。估计需要为存储在根数据库空间中的表分配的磁盘空间量(如果有)。
额外空间
允许系统数据库的根数据库空间中的额外空间增长以便获得扩展保留页和充足的可用空间。扩展保留页数取决于数据库服务器中的主要块、镜像块、逻辑日志文件和存储空间的数目。
数据库所需空间量
数据库服务器数据存储需要的附加磁盘空间量取决于用户的需求,以及开销和增长。用户运行的每个应用程序都有不同的存储需要。 以下列表提出了一些您可以用来计算要分配的磁盘空间(根数据库空间除外)量的步骤:
- 决定必须存储多少数据库和表。计算每个数据库和表所需的空间量。
- 计算每个表的增长率并为每个表指定一些磁盘空间量以适应增长。
- 决定希望监视哪些数据库和表。
存储池
GBase 8s 的每个实例都具有存储池。 存储池中包含有关以下对象的信息:服务器可在必要时用于自动扩展现有数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间的目录、熟文件和原始设备。
如果存储空间低于 SP_THRESHOLD 配置参数中定义的阈值,GBase 8s 可自动运行空间扩充任务,方法是扩展空间中的现有块或添加新块。
使用 SQL 管理 API 可以执行以下操作:
- 添加、删除或修改用于描述存储池中的一个目录、熟文件或原始设备的条目。必要时,服务器可使用指定的目录、熟文件或原始设备来向现有存储空间自动添加空间。
- 通过以下方法控制存储池条目的使用方式:修改与扩充存储空间相关的两个不同的数据库空间大小,即扩展大小和创建大小。
- 将块标记为可扩展或不可扩展。
- 不希望 GBase 8s 自动扩充空间时,立即扩充空间大小。
- 立即按指定的最小量扩展块的大小。
- 通过存储池中的条目创建存储空间或块
- 将空的空间从已删除的存储空间或块返还给存储池
sysadmin 数据库中的 storagepool 表包含有关 GBase 8s 实例的存储池中所有条目的信息。
磁盘布局准则
有效磁盘布局具有以下典型目标:
- 限制磁盘头的移动
- 减少磁盘争用
- 平衡负载
- 最大化可用性
您必须在设计磁盘布局时对这些目标作一些折中。例如,将系统目录表、逻辑日志和物理日志分开可以帮助减少对这些资源的争用。然而,此操作也会增加必须执行系统复原的机率。
数据库空间和块准则
本主题列出了磁盘布局的一些常规策略,这些策略不需要有关特定数据库特征的任何信息:
- 将磁盘分区与块关联并为根数据库空间分配至少一个附加块。
已经分区的磁盘可能需要使用偏移量。 有关详细信息,请参阅在 UNIX 上分配原始磁盘空间。
有了块的 4 太字节的最大大小的限制,您可以通过为每个磁盘驱动器指定块来避免进行分区。
- 为关键数据库空间(根数据库空间、包含逻辑日志和逻辑日志文件的数据库空间)建立镜像。还可为使用率高的数据库和表建立镜像。
可以在数据库空间级别上指定镜像。对于所有属于数据库空间的块来说,镜像可以打开也可以关闭。在不同的磁盘上定位主要和镜像数据库空间。理论上,不同的控制器将处理不同的磁盘。
- 在多个磁盘上分布临时表并将文件排序。
要为临时表和排序文件定义数个数据库空间,可使用 onspaces -t。 当在不同的磁盘上放置这些数据库空间并将它们列在 DBSPACETEMP 配置参数中时,可以展开与临时表相关联的 I/O 并在多个磁盘上对文件进行排序。有关使用 DBSPACETEMP 配置参数或环境变量的信息,请参阅《GBase 8s 管理员参考》中有关配置参数的章节。
- 将物理日志保留在根数据库空间中,而将逻辑日志从根数据库空间移出。然而,如果您计划将系统目录存储在根数据库空间中,请将物理日志移至另一个数据库空间。
有关日志存储的位置的建议,请参阅指定物理日志的位置和逻辑日志文件的位置。另请参阅将逻辑日志文件移至另一个数据库空间和更改物理日志的位置和大小。
- 要提高备份与复原的性能,请执行以下操作:
- 将系统目录与它们跟踪的数据集群起来。
- 如果使用 ON-Bar 对高速磁带机执行并行备份,请将这些数据库存储在多个小数据库空间中。
有关附加的性能建议,请参阅《GBase 8s 备份与复原指南》。
表位置准则
本主题将列出用于优化磁盘布局的一些策略,前提是数据库中存在有关表的某些特征。您可以使用表分段存储通过更高程度的控制来实现这些策略中的许多策略:
- 隔离独立磁盘上使用率高的表。
要在其自身的磁盘设备上隔离使用率高的表,请将该设备指定给一个块,然后将同一个块指定给数据库空间。最后,将使用频繁的表放置在刚使用 CREAT TABLE 的 IN dbspace 选项创建的数据库空间中。
要显示对每个块的 I/O 操作级别,请运行 onstat -g iof 选项。
- 将使用率高的表在多个磁盘上分段。
- 将有关的表在数据库空间中分组。
如果包含数据库空间的设备发生故障,该数据库空间中的所有表都是不可访问的。然而,其他数据库空间中的表将仍然可以访问。尽管在包含关键信息的数据库空间发生故障时必须执行冷复原,然而如果只是非关键的数据库空间发生故障,那么只须执行热复原即可。
- 将使用率高的表放置在磁盘的中间分区上。
- 优化表扩展数据块的大小。
有关 onstat 选项的信息,请参阅《GBase 8s 管理员参考》。
样本磁盘布局
当开始组织磁盘空间时,数据库服务器管理员通常会想到下列目标中的一个或多个目标:
- 高性能
- 高可用性
- 简单和频繁的备份与复原
满足这些目标中的任何一个都需要折中。例如,将系统配置成高性能通常会导致数据的可用性降低。下列各节提供了一个示例,该示例中数据库服务器管理员必须在磁盘资源有限的情况下作出磁盘布局的选择。下节描述两种不同的磁盘布局解决方案。第一个解决方案代表性能优化,而第二个解决方案代表可用性和复原优化。
样本磁盘布局的设置是使用 stores_demo 数据库的结构(但不是卷)的虚构的体育用品数据库。 在此示例中,数据库服务器被配置成处理大约 350 个用户和 3 千兆字节的数据。磁盘空间的资源显示在下表中。
| 磁盘驱动器 | 驱动器大小 | 高性能 |
|---|---|---|
| 磁盘 1 | 2.5 千兆字节 | 否 |
| 磁盘 2 | 3 千兆字节 | 是 |
| 磁盘 3 | 2 千兆字节 | 是 |
| 磁盘 4 | 1.5 千兆字节 | 否 |
数据库包含两个大表:cust_calls 和 items。假设这两个表都包含多于 1,000,000 个行。cust_calls 表提供了客户致电经销商的所有通话记录。items 表包含经销商已发货的每张订单的行式项目。
数据库包含两个使用率高的表:items 和 orders。这两个表都要经受来自整个国家或地区的用户的持续访问。
其余的表是低容量表,数据库服务器将使用这些表查询数据,如:邮政编码或制造商。
| 表名 | 最大大小 | 访问率 |
|---|---|---|
| cust_calls | 2.5 千兆字节 | 低 |
| items | 0.5 千兆字节 | 高 |
| orders | 50 兆字节 | 高 |
| customers | 50 兆字节 | 低 |
| stock | 50 兆字节 | 低 |
| catalog | 50 兆字节 | 低 |
| manufact | 50 兆字节 | 低 |
| state | 50 兆字节 | 低 |
| call_type | 50 兆字节 | 低 |
性能优先级最高时的样本布局
下图显示了一种针对性能优化的磁盘布局。此磁盘布局使用下列策略提高性能:
- 将逻辑日志从 rootdbs 数据库空间迁移到独立磁盘上的数据库空间
此策略将逻辑日志与物理日志分开,从而减少了对根数据库空间的争用。
- 在独立磁盘上的数据库空间中经历最高使用率的两个表的位置
这些磁盘既不存储逻辑日志也不存储物理日志。理论上,可以将 items 和 orders 表分别存储在不同的高性能磁盘上。然而,在当前的方案中,此策略无法使用,因为需要其中一个高性能磁盘来存储超大的 cust_calls 表(其他两个磁盘对于此任务来说过小)。
图: 针对性能优化的磁盘布局
可用性优先级最高时的样本布局
上一种磁盘布局的缺点在于如果磁盘 1 或磁盘 2 发生故障,那么整个数据库服务器将停止运行直到您将这些磁盘上的数据库空间从备份中复原为止。换句话说,该磁盘布局对于可用性来说是不适合的。
下图中显示了一种可以针对可用性优化并涉及镜像的备用磁盘布局。此布局将所有关键数据空间(系统目录表、物理日志和逻辑日志)镜像到单独的磁盘。理论上,可以将逻辑日志和物理日志分开(与上一种布局一样),并且将每个磁盘镜像到其自身的镜像磁盘上。然而,在此方案中,所需的磁盘数不存在;因此逻辑日志和物理日志都位于根数据库空间中。
图: 针对可用性优化的磁盘布局
逻辑卷管理器
可以使用逻辑卷管理器 (LVM) 实用程序通过用户定义的逻辑卷来管理磁盘空间。
许多计算机制造商提供带专有 LVM 的计算机。可使用数据库服务器在由大多数专有 LVM 管理的磁盘上存储和检索数据。本节的剩余部分将对逻辑卷管理器的优势和劣势进行说明。
大多数 LVM 可管理多个千兆字节的磁盘空间。 数据库服务器块限制到 4 TB 大小,且此大小只能在正被分配的块偏移量为零时获取。因此,必须限制所有要分配为块的卷的大小(每个块 4 TB)。
由于可使用 LVM 将磁盘驱动器分区成多个卷,因此可以控制将数据放置在给定磁盘的哪个位置。可以通过定义由磁盘驱动器的最中间的柱面组成的卷并在该卷种放置使用率高的表来提高性能。(从技术上讲,您不能将表直接放置在卷中。您必须先将块分配为卷,然后将块指定到数据库空间,最后将表放置在该数据库空间中。有关更多信息,请参阅控制简单大对象数据的存储位置。
如果选择使用大磁盘驱动器,那么可以将块指定给一个驱动器并且不必将该磁盘分区。
还可以通过使用逻辑卷管理器定义在多个磁盘上展开的卷并随后将表放置到该卷中来提高性能。
许多逻辑卷管理器还允许标准操作系统格式实用程序所不允许的灵活性程度。其中一个特征是能够在您定义了逻辑卷后重新将其定位。这样,与操作系统格式实用程序相比,初次获取磁盘空间布局就不那么重要了。
LVM 经常提供操作系统级别的镜像工具。有关更多信息,请参阅 镜像备用方法。
管理磁盘空间
可以使用多个实用程序和工具来管理数据库服务器控制的磁盘空间和数据。
这些主题假设您熟悉数据存储中包含的术语和概念。
您可使用以下实用程序来管理存储空间:
- onspaces 实用程序命令
有关使用 SQL 管理 API 命令(而不是一些 onspaces 命令)的信息,请参阅使用 SQL 管理 API 执行远程管理和《GBase 8s 管理员参考》。
可以生成 SQL 管理 API 或 onspaces 命令,用于再现文件中存在的存储空间、块和日志。使用 dbschema 实用程序可执行此操作。
分配磁盘空间
本节说明如何分配数据库服务器的磁盘空间。请在分配磁盘空间之前阅读下列章节:
- UNIX 上的未缓冲或已缓冲磁盘的访问
- 存储数据所需的磁盘空间量
- 磁盘布局准则
在您可以创建存储空间或块、或对现有存储空间制作镜像之前,必须为块文件分配磁盘空间。您可以为数据库服务器磁盘空间分配空文件或部分原始磁盘。
**仅限 UNIX:**在 UNIX™ 上,如果分配原始磁盘空间,必须使用 UNIX ™ ln 命令来创建字符专用设备名称和另一个文件名之间的链接。有关此主题的更多信息,请参阅创建到原始设备的符号链接 (UNIX)。
将 UNIX 文件及其固有操作系统接口用于数据库服务器磁盘空间称为使用熟空间。
您可以在磁盘和控制器上平衡块。在单个磁盘上放置多个块可提高吞吐量。
指定偏移量
当您将磁盘空间块分配至数据库服务器时,为达到以下两个目的之一,请指定偏移量:
- 防止数据库服务器覆盖分区信息
- 在分区、磁盘设备或熟文件上定义多个块
偏移量的最大值为 4 太字节。
许多计算机系统和一些磁盘驱动器的制造商会将有关物理磁盘驱动器的信息保存在驱动器本身中。此信息有时称为卷目录 (VTOC) 或磁盘标签。VTOC 通常存储在驱动器的第一个磁道上。备用扇区及坏扇区映射表(又称为重指向表)也可能存储在第一个磁道上。
如果计划从磁盘起始处分配分区,那么可能需要使用偏移量来防止数据库服务器覆盖操作系统所需的关键信息。有关所需的精确偏移量,请参阅磁盘驱动器手册。
如果您正运行数据库服务器的两个或两个以上实例,那么要非常小心,不要定义重叠的块。重叠的块会导致数据库服务器用不相关的重叠块中数据覆盖另一个块中的数据。此覆盖实际上会删除重叠数据。
为根数据库空间的初始块指定偏移量
对于根数据库空间的初始块及其镜像(如果镜像存在),分别用 ROOTOFFSET 和 MIRROROFFSET 参数指定偏移量。有关更多信息,请参阅《GBase 8s 管理员参考》中有关配置参数的主题。
为附加块指定偏移量
要为数据库服务器空间的附加块指定偏移量,必须在为数据库服务器分配空间时将偏移量作为参数而提供。有关更多信息,请参阅创建使用缺省页大小的数据库空间。
使用偏移量创建多个块
通过指定偏移量以及分配小于可用总空间的块,您可从磁盘分区、磁盘设备或文件中创建多个块。偏移量指定块的开始位置。数据库服务器通过将块大小增加至偏移量来确定块的最后字节的位置。
对于第一个块,分配任何初始偏移量(如有需要)并将大小指定为少于分配磁盘空间总大小的数量。对于每个附加块,请指定偏移量以包含所有先前分配的块并加上初始偏移量,然后分配少于或等于分配中剩余的空间量大小。
在 UNIX 上分配熟文件空间
以下过程显示了在 UNIX™ 上为名为 usr/data/my_chunk 的熟文件分配磁盘空间的示例。
要分配熟文件空间,请执行以下操作:
- 以用户 gbasedbt 身份登录:su gbasedbt
- 将目录切换至将熟空间将位于的目录:cd /usr/data
- 通过将 null 连接至数据库服务器要用于磁盘空间的文件名来创建块:cat /dev/null > my_chunk
- 将文件许可权设置为 660 (rw-rw----):chmod 660 my_chunk
- 必须将组和文件所有者均设置到 gbasedbt:
ls -l my_chunk -rw-rw----
1 gbasedbt gbasedbt
0 Oct 12 13:43 my_chunk - 使用 onspaces 创建存储空间或块。
有关如何使用已分配的文件来创建存储空间的信息,请参阅创建使用缺省页大小的数据库空间、创建 BLOB 空间和创建智能大对象空间。
在 UNIX 上分配原始磁盘空间
要分配原始空间,您必须具有专用于未加工空间的可用磁盘分区。要创建原始磁盘空间,您可以将磁盘重新分区或卸载现有文件系统。在卸载设备之前请备份所有文件。
分配原始磁盘空间
- 创建并安装原始设备。 有关如何在 UNIX™ 上分配原始磁盘空间的特定指示信息,请参阅您的操作系统文档和 UNIX 上的未缓冲或已缓冲磁盘的访问。
- 将字符专用设备的所有权和许可权更改到 gbasedbt。 字符专用设备的文件名通常以字母 r 开头。有关过程,请参阅在 UNIX 上分配熟文件空间中的步骤4 和步骤5。
- 验证指定特征的设备的操作系统许可权是否为 crw-rw----。
- 使用 UNIX 链接命令 ln -s 创建字符专用设备名称和另一个文件名之间的符号链接。 有关详细信息,请参阅创建到原始设备的符号链接 (UNIX)。
在您创建数据库服务器用于磁盘空间的原始设备之后,请不要在您为数据库服务器磁盘空间分配的同一原始设备上创建文件系统。并且,也不要将同一原始设备用作您为数据库服务器磁盘空间分配的交换空间。
创建到原始设备的符号链接 (UNIX)
使用符号链接来分配标准设备名称并指向设备。要在字符专用设备名和另一个文件名之间创建链接,请使用 UNIX™ 链接命令(通常为 ln)。要验证设备和链接是否都存在,请在设备目录下运行 UNIX 命令 ls -l(DBS 上的 ls -lg)。以下示例显示原始设备的链接。如果您的操作系统不支持符号链接,那么硬链接也可起作用。
ln -s /dev/rxy0h /dev/my_root # orig_device link to symbolic_name
ln -s /dev/rxy0a /dev/raw_dev2
ls -l
crw-rw--- /dev/rxy0h
crw-rw--- /dev/rxy0a
lrwxrwxrwx /dev/my_root@->/dev/rxy0h
lrwxrwxrwx /dev/raw_dev2@->/dev/rxy0a
为何使用符号链接?如果是在原始设备上创建块,但该设备发生了故障,那么直到替换该原始设备并使用相同路径名之后才能从备份复原。在上次备份时可访问的所有块在您执行复原时均必须为可访问的。
符号链接简化了磁盘故障的恢复,并使您可迅速替换块所处的磁盘。您可以用其他设备替换故障设备,将新设备路径名链接至先前为故障设备创建的同一文件名,然后复原数据。无需等待原始设备修复。
指定存储空间和块的名称
块名称与存储空间名称遵循相同的规则。 如下所示,为存储空间或块指定明确的路径名:
- 如果要在 UNIX™ 上使用原始磁盘,那么必须使用已链接的路径名。(请参阅创建到原始设备的符号链接 (UNIX)。)
- 如果要为数据库服务器磁盘空间使用文件,那么路径名为完整的路径和文件名。
在您创建存储空间或添加块时请使用这些命名规则。文件名必须具有以下特征:
- 唯一,且不超过 128 字节
- 以字母或下划线开头
- 仅包含字母、数字、下划线或 $ 字符
除非名称用引号括起,否则名称不区分大小写。在缺省情况下,数据库服务器将该名称中的大写字符转换为小写。如果希望在名称中使用大写,请用引号将其括起,并将 DELIMIDENT 环境变量设置为 ON。
指定块的最大大小
在大多数平台上,最大块大小为 4 TB;但在其他平台上,最大块大小为 8 TB。
要确定平台所支持的块大小,请参阅机器说明文件。
指定块和存储空间的最大数量
您可在数据库服务器系统上指定存储空间的最大块数为 32,766 以及最大存储空间数为 32,766。
存储空间可以是数据库空间、BLOB 空间和智能大对象空间的任何组合。
考虑到对数据库服务器实例大小的所做的所有限制,实例的最大大小为 8 拍字节。
更改物理模式后备份
您必须对根数据库空间和修改过的存储空间执行 0 级备份,从而确保您可在执行以下操作时复原数据:
- 添加或删除镜像
- 删除逻辑日志文件
- 更改物理日志的大小或位置
- 更改您的存储管理器配置
- 添加、移动或删除数据库空间、BLOB 空间或智能大对象空间
- 对数据库空间、BLOB 空间或智能大对象空间添加、移动或删除块
添加新的逻辑日志时,不再需要为使用新逻辑日志而对根数据库空间和修改过的数据库空间执行 0 级备份。但必须执行 0 级备份以防止 1 级和 2 级备份失败。
您必须对修改过的存储空间执行 0 级备份,以确保执行以下操作时在转换到日志记录表类型之前可以复原未记录的数据:
- 当您将非日志记录数据库转换为日志记录数据库。
- 当您将 RAW 表转换为标准表
监视存储空间
您可以监视存储空间状态,并配置当存储空间变满时如何给予通知。
当存储空间或分区变满时,会通过联机消息日志文件显示消息。
您可以通过 STORAGE_FULL_ALARM 配置参数配置当存储空间变满时要触发的警报。 您可以指定发送警报的频率和要发送警报的最低严重性级别。 缺省情况下,警报时间间隔是 600 秒,警报严重性级别为 3。有关 STORAGE_FULL_ALARM 配置参数和事件警报的更多信息,请参阅《GBase 8s 管理员参考》。
如果高可用性集群中的主服务器遇到了空间不足的情况,并且启用了 STORAGE_FULL_ALARM 配置参数,那么将触发事件警报,并在主服务器上返回错误状态,但是不会在任何辅助服务器上返回错误状态。这是预期的行为,因为主服务器遇到空间不足情况时,不会再将日志记录从主服务器发送到辅助服务器。在这种情况下,辅助服务器永远不会超过其存储限制,因此不会触发事件警报或返回错误状态。
您可以使用 GBase 8s 调度程序设置自动监视存储空间状态这一任务。 任务的属性定义调度程序收集的信息,并指定任务运行的频率。例如,可以将任务定义为一周五天、每隔一小时监视存储空间。有关更多信息,请参阅调度程序和创建任务。
管理数据库空间
这部分包含有关创建具有和不具有缺省页大小的标准和临时数据库空间的信息,创建数据库空间时在数据库空间中为表空间 tblspace 指定第一个和下一个扩展数据块大小的信息,以及向数据库空间或 BLOB 空间添加块的信息。
有关监视数据库空间的信息,请参阅监视存储空间。
创建使用缺省页大小的数据库空间
可以使用 onspaces 创建标准数据库空间和临时数据库空间。
有关创建具有非缺省页大小的数据库空间的信息,请参阅创建具有非缺省页大小的数据库空间。
任何新添加的数据库空间及其镜像(如果存在一个镜像)立即可用。如果您使用镜像,那么可在创建数据库空间时对其制作镜像。镜像可立即生效。
要使用 onspaces 创建标准数据库空间:
-
在 UNIX™ 上,您必须以用户 gbasedbt 或 root 身份登录来创建数据库空间。
-
请确保数据库服务器处于在线、管理员或静态模式中。
-
按分配磁盘空间中所述,为数据库空间分配磁盘空间。
-
要创建数据库空间,请使用 onspaces -c -d 选项。
KB 是 -s size 和 -o offset 选项的缺省单位。 要将 KB 转换为 MB,可将该单位数量乘以 1024(例如,10 MB = 10 * 1024 KB)。
如果要创建具有非缺省页大小的数据库空间,请参阅创建具有非缺省页大小的数据库空间以获取有关附加 onspaces 选项的信息。
-
如果不想为数据库空间中的表空间 tblspace 指定第一个和下一个扩展数据块大小,请转至 6。
如果想要为数据库空间中的表空间 tblspace 指定第一个和下一个扩展数据块大小,表空间为表空间 tblspace 指定第一个和下一个扩展数据块大小中的其他信息。
-
在创建数据库空间之后,必须对根数据库空间和新数据库空间执行 0 级备份。
以下示例显示了如何在 UNIX 上使用原始磁盘空间创建 10 MB 镜像数据库空间 dbspce1,对主块和镜像块的偏移量均为 5000 KB。
onspaces -c -d dbspce1 -p /dev/raw_dev1 -o 5000 -s 10240 -m /dev/raw_dev2 5000
有关使用 onspaces 创建数据库空间的更多信息,请参阅数据库空间和《GBase 8s 管理员参考》中有关 onspaces 的信息。
为表空间 tblspace 指定第一个和下一个扩展数据块大小
如果要减少表空间 tblspace 扩展数据块数,并降低发生必须将表空间 tblspace 扩展数据块放入非主块的情况的频率,可以指定第一个和下一个扩展数据块大小。 (主块为数据库空间中的初始块。)
可选择性地指定第一个扩展数据块大小、下一个扩展数据块大小,以及第一个和/或下一个扩展数据块大小。如果不为表空间 tblspace 指定第一个或下一个扩展数据块大小,那么 GBase 8s 将使用现有的缺省扩展数据块大小。
可使用 TBLTBLFIRST 和 TBLTBLNEXT 配置参数为表空间 tblspace指定第一个或下一个扩展数据块大小,该表空间位于在初始化服务器时创建的根数据库空间中。
可使用 onspaces 实用程序为非根数据库表空间中的表空间 tblspace 指定第一个和下一个扩展数据块大小。
创建数据库空间时,可以仅指定第一个和下一个扩展数据块大小。创建数据库空间后,不能改变第一个和下一个扩展数据块大小的规范。另外,您还不能指定临时数据库空间、智能大对象空间、BLOB 空间或外部空间的扩展数据块大小。创建数据库空间之后,您将无法改变第一个和下一个扩展数据块大小的规格。
要指定第一个和下一个扩展数据块大小,请执行以下操作:
-
确定在表空间 tblspace 中所需的总页数。
页数等于表数 + 拆离索引数 + 可能位于数据库空间中的表分段数 + 表空间 tblspace 的一个页面。
-
计算页数所需的 KB 数。
此数字将取决于系统上的一个页面的 KB 数。
-
通过考虑在创建数据库空间期间分配的表空间 tblspace 的所有扩展数据块的重要性,以及是否必须连续分配这些扩展数据块来确定系统上的空间管理需求。
其中,最重要的就是第一个扩展数据块大小必须更大。如果不是很在意辅助块中存在不连 续扩展数据块,那么第一个和下一个扩展数据块大小可以小一些。
-
如下所示,指定扩展数据块大小:
- 如果空间需求适用于根数据库空间,那么在 TBLTBLFIRST 配置参数中指定第一个扩展数据块大小并在 TBLTBLNEXT 配置参数中指定下一个扩展数据块大小。 然后初始化数据库服务器实例。
- 如果空间需求适用于非根数据库空间,那么通过使用 onspaces实用程序在命令行上指示第一个和下一个扩展数据块大小从而创建数据库空间。
扩展数据块大小必须以 KB 计,并且必须是页大小的倍数。指定第一个和下一个扩展数据块大小时,请遵循以下指南:
| 扩展数据块的类型 | 最小大小 | 最大大小 |
|---|---|---|
| 非根数据库空间中的第一个扩展数据块 | 相当于 50 页(以 KB 指定)。这是系统缺省值。 例如,对于 2 KB 页面系统,最小长度为 100。 | 初始块的大小,减去任何系统对象(如保留页、数据库表空间,以及物理和逻辑日志)所需的空间。 |
| 根数据库空间中的第一个扩展数据块 | 相当于 250 页(以 KB 指定)。这是系统缺省值。 | 初始块的大小,减去任何系统对象(如保留页、数据库表空间,以及物理和逻辑日志)所需的空间。 |
| 下一个扩展数据块 | 为系统上磁盘页大小的 4 倍。 在任何类型的数据库空间上,缺省值均为 50 页。 | 最大块大小减去 3 页。 |
可使用以下 onspaces 实用程序和**-ef** 和 -en 选项为非根数据库表空间中的表空间 tblspace 指定第一个和下一个扩展数据块大小:
- 第一个扩展数据块大小:-ef size_in_kbytes
- 下一个扩展数据块大小:-en size_in_kbytes
例如,可以指定:
onspaces -c -d dbspace1 -p /usr/data/dbspace1 -o 0 -s 1000000 -e 2000 -n 1000
可使用 Gcheck -pt 和 oncheck -pT显示表空间 tblspace 的第一个和下一个扩展数据块大小。
如果正在使用数据复制并且在主数据库服务器上创建了数据库空间,那么第一个和下一个扩展数据块大小将通过 ADDCHK 日志记录传递到辅助数据库服务器。
有关 onspaces 实用程序、oncheck 命令以及为表空间 tblspace 指定第一个和下一个扩展数据块大小的更多信息,请参阅《GBase 8s 管理员参考》。
创建具有非缺省页大小的数据库空间
如果需要的密钥长度比缺省页大小可提供的更长,那么可以指定标准或临时数据库空间的页大小。
根数据库空间为缺省页大小。如果要指定页大小,该大小必须为缺省页大小的整数倍,且不能超过 16 KB。
对于具有足够存储空间的系统,较大页大小的性能优势包括:
- 减少 B 型树索引的深度(甚至对于较小的索引键)。
- 减少检查点时间(通常出现在使用较大页大小时)。
其他的性能优势还体现在您可以:
- 将当前跨多个页(大小为缺省页大小)的长行分组到同一页上。
- 定义临时表的不同页大小,这样临时表具有单独的缓冲池。
使用 BUFFERPOOL 配置参数可创建与数据库空间的页大小相对应的缓冲池。(您可能想要执行此操作来实现一种“专用缓冲池”。)
一个表可在一个数据库空间中,而该表的索引可在另一个数据库空间中。这些分区的页大小可以不同。
如果想要为数据库空间指定页大小,请指向以下任务:
-
请运行 onmode -BC 2命令来启用大块方式。
缺省情况下,首次初始化或重新启动 GBase 8s 时,将启动 GBase 8s,并启用大块方式。有关 onmode 实用程序的信息,请参阅《GBase 8s 管理员参考》。
-
创建对应于数据库空间页大小的缓冲池。可使用 onparams 实用程序或 BUFFERPOOL 配置参数。必须在创建数据库空间之前执行此操作。
如果创建的数据库空间其页大小没有对应的缓冲池,那么 GBase 8s 将使用在 onconfig 配置文件中定义的缺省参数自动创建缓冲池。
无法使多个缓冲池具体相同的页大小。
-
创建数据库空间时,定义数据库空间的页大小。可使用 onspaces 实用程序。有关更多信息,请参阅定义页大小。
例如,如果创建页大小为 6 KB 的数据库空间,那么必须创建大小为 6 KB 的缓冲池。如果没有为新的缓冲池指定页大小,那么 GBase 8s会将操作系统缺省页大小(在大多数 UNIX™ 平台上为 2 KB)用作缓冲池的缺省页大小。
如果使用非缺省页大小,可能需要增大物理日志的大小。如果对非缺省页执行许多更新,那么可能需要将物理日志大小增大 150% 到 200%。要调整物理日志,可能需要进行一些试验。可根据物理日志触发器检查点的填充频率来按需调整物理日志的大小。
为非缺省页大小创建缓冲池
创建缓冲池时,可使用 BUFFERPOOL 配置参数或 onparams 实用程序来指定有关缓冲区的信息(包括其大小)、指定缓冲池中 LRUS 的数量、指定缓冲池中缓冲区的数量,以及的 lru_min_dirty 和 lru_max_dirty值。
使用 BUFFERPOOL 配置参数指定此信息。
BUFFERPOOL 配置参数由 onconfig.std 文件中的两行组成。
在 UNIX™ 系统上,这些行是:
BUFFERPOOL default,buffers=10000,lrus=8,lru_min_dirty=50.00,lru_max_dirty=60.50
BUFFERPOOL size=2K,buffers=50000,lrus=8,lru_min_dirty=50,lru_max_dirty=60
第一行指定了使用的缺省值,这些值是当您创建的数据库空间的页大小没有对应在启动数据库服务器时创建的缓冲池时被使用的。缺省行之后的以下行指定了缓冲池的数据库服务器缺省值。 这些值以数据库服务器的缺省页大小为依据。
使用 onspaces 实用程序添加具有不同页大小的数据库空间时,或者使用 onparams 实用程序添加新的缓冲池时,将向 onconfig 文件的 BUFFERPOOL 配置参数添加一个新行。每个缓冲池的页大小必须为您操作系统缺省页大小的倍数。以下示例显示了添加到 onconfig 文件中的第三个 BUFFERPOOL 行:
BUFFERPOOL default,buffers=10000,lrus=8,lru_min_dirty=50.00,lru_max_dirty=60.50
BUFFERPOOL size=2K,buffers=50000,lrus=8,lru_min_dirty=50,lru_max_dirty=60
BUFFERPOOL size=6K,buffers=3000,lrus=8,lru_min_dirty=50,lru_max_dirty=60
BUFFERPOOL 行中的字段不区分大小写,所以您可以指定 lrus、Lrus 或 LRUS)。这些字段可按任何顺序显示。
如果没有为新的缓冲池指定页大小,那么 GBase 8s会将操作系统缺省页大小用作缓冲池的缺省页大小。
如果 buffers 的值为零 (0),或者在 BUFFERPOOL 配置参数中缺少 buffers 的值,那么 GBase 8s 不会创建指定页大小的缓冲池。
使用BUFFERPOOL 配置参数输入的信息将取代先前使用不推荐的参数指定的任何信息。有关不推荐的参数的更多信息,请参阅附录,其中包含《GBase 8s 管理员参考》中已终止的配置参数的信息。
下表为您使用 BUFFERPOOL 配置参数或 onparams 实用程序指定的值提供了说明。
| 字段 | 解释 | 值范围 |
|---|---|---|
| size | 指定页面中后跟后缀 K 的 KB 数。 | 大小可在 2K 或 4K 至 16 K 之间变化。2K 为缺省值。 |
| buffers | 指定页大小缓冲区的数量。 这是数据库服务器用户线程代表客户机应用程序用于磁盘 I/O 的共享内存缓冲区的最大数目。数据库服务器所需的缓冲区数取决于应用程序。 例如,如果数据库服务器用了 90% 的时间访问了 15% 的应用程序数据,那么必须分配足够的缓冲区以保留该 15% 的数据。增加缓冲区数量可提高系统性能。 缓冲区空间所需的物理内存百分比取决于计算机上可用的内存量,以及用于其他应用程序的内存量。对于具有大量可用物理内存(4 千兆字节或以上)的系统,缓冲区空间可达到物理内存的 90%。对于可用物理内存量较小的系统,缓冲区空间的范围可以为物理内存的 20% 到 25%。 必须在设置缓冲区空间 (buffers *system_page_size) 后计算所有其他的共享内存参数。 | 对于 UNIX 上的 32 位平台 ● 页大小等于 2048 字节:100 到 1,843,200 个缓冲区 (1843200 = 1800 * 1024) ● 页大小等于 4096 字节:100 到 921,600 个缓冲区 (921,600 = ((1800 * 1024)/4096) * 2048 ) 对于 64 位平台:100 到 231-1 个缓冲区(对于 64 位平台的实际值,请参阅发行说明。Solaris 上缓冲区的最 大数为 536,870,912。) |
| lrus | 在共享内存缓冲池中为页大小指定 LRU(最近最少使用的)队列的数目。可调整 LRUS、lru_min_dirty 和lru_max_dirty 值以控制共享内存缓冲区每隔多少时间清空到磁盘一次。 将 LRUS 设置得过高可能导致页清除程序活动过多。 | 1 到 128 |
| lru_min_dirty | 指定已修改的页占 LRU 队列的百分比,达到该百分比时页清除将不再是必需的。在某些情况下,页清除程序可能会超出该点继续清除。 用于清空检查点之间缓冲池的 LRU 值对于检查点性能不是特别重要。 lru_min_dirty 值通常仅对于维持足够数量的干净页以供替换而言是必要的。通过设置 LRU 清空参数以将 lru_min_dirty 设置为 70 来启动。 有关更多信息,请参阅用于清空检查点之间缓冲池的 LRU 值。 | 0 到 100(允许小数值) 如果超过值的范围指定参数,那么缺省值将被设置为 50.00%。 |
| lru_max_dirty | 指定已修改页占 LRU 队列的百分比,达到该百分比时将清除队列。 用于清空检查点之间缓冲池的 LRU 值对于检查点性能不是特别重要。lru_max_dirty 值通常仅在维持足够数量的干净页以供替换时才显得必要。通过设置 LRU 清空参数以将 lru_max_dirty 设置为 80 来启动。 有关更多信息,请参阅用于清空检查点之间缓冲池的 LRU 值。 | 0 到 100(允许小数值) 如果超过值的范围指定参数,那么缺省值将被设置为60.00%。 |
如果数据库服务器处于在线、静态或管理员方式,那么您还可以使用 onparams 实用程序添加不同大小的新缓冲池。使用 onparams 实用程序时,指定的信息将自动传输到 onconfig 文件的,并且会使用 BUFFERPOOL 关键字指定新值。不能通过编辑onconfig.std 文件更改值。
当您使用 onparams 实用程序时,请如下指定信息:
onparams -b -g <size of buffer page in Kbytes> -n <number of buffers>
-r <number of LRUs> -x <max dirty (fractional value allowed)>
-m <minimum dirty (fractional value allowed)>
例如:
onparams -b -g 6 -n 3000 -r 2 -x 2.0 -m 1.0
这添加了 3000 个大小为 6K 字节的缓冲区,每个缓冲区都具体 2 个 LRUS 并且lru_max_dirty 被设置为 2%,而且lru_min_dirty 被设置为 1%。
有关 onparams 实用程序的更多信息,请参阅《GBase 8s 管理员参考》。
将 PHYSBUFF 配置参数至少设置为 128 KB。如果数据库服务器已配置为使用 RTO_SERVER_RESTART,请将 PHYSBUFF 配置参数至少设置为 512 KB。将 PHYSBUFF 设置为较低的值可能会影响事务性能以及/或者导致服务器初始化期间出现性能警告。
LG_ADDBPOOL 日志记录和 sysbufpool 系统目录表包含有关每个缓冲池的信息。
当数据库服务器正在运行时添加的缓冲池将会进入虚拟内存而不是常驻内存中。根据正在使用的内存的可用性,仅在启动时在 onconfig 文件中指定的那些缓冲池条目会进入常驻内存。
调整现有缓冲池大小
如果必须调整现有缓冲池的大小,必须关闭数据库服务器。然后在 onconfig 文件中更改缓冲池的大小。
删除现有缓冲池
如果必须删除现有缓冲池,必须关闭数据库服务器。然后在 onconfig 文件中删除缓冲池。
定义页大小
可以使用 onspaces -k 选项以定义页大小。
如下所示设置页大小(以 KB 为单位):
onspaces -c -d DBspace [-t] [-k pagesize] -p path -o offset -s size [-m path offset]
根数据库空间为缺省页大小。
如果指定页大小,页大小必须是缺省页大小的倍数,且不能超过 16 KB。
通过使用直接 I/O 提高熟文件数据库空间的性能
在 UNIX™ 系统上,可通过使用直接 I/O 提高用于数据库空间块的熟文件的性能。
直接 I/O 必须可用并且文件系统必须支持用于数据库空间块的页大小的直接 I/O。
可以使用 GBase 8s 将原始设备或熟文件用于数据库空间块。通常,熟文件会较慢,因为存在文件系统提供的额外开销和缓存。直接 I/O 绕过文件系统缓冲区的使用,因此对磁盘的读写效率更高。使用 DIRECT_IO 配置参数指定直接 I/O。如果文件系统支持用于数据库空间块的页大小的直接 I/O 并使用直接 I/O,那么熟文件的性能可能接近用于数据库空间块的原始设备的性能。
要通过使用直接 I/O 提高熟文件数据库空间的性能,请执行以下操作:
- 验证您是否具有直接 I/O 且文件系统是否对用于数据库空间块的页大小支持直接 I/O。
- 通过将 DIRECT_IO 配置参数设置为 1 启用直接 I/O。
如果有 AIX® 操作系统,那么还可以为 GBase 8s 启用并行 I/O,以在对使用熟文件的块执行读写时将其与直接 IO 一起使用。
将多个指定分段存储在单个数据库空间
对于使用基于表达式的分布方案或循环分布方案的分段表,可以创建可位于单个数据库空间中的指定分段。
对于使用基于表达式、时间间隔、列表或循环法的分布方案的分段表,可以创建可位于单个数据库空间中的指定分段。
将多个表或索引段存储到一个数据库空间中时的查询性能要优于将每个段存储到不同数据库空间中时的查询性能,并且简化了数据库空间的管理。
假设您要使用基于表达式的分布方案创建分段表,该分布方案中的每个表达式都会指定放置在特定分段中的数据集。您可决定使用某个数据库空间中某个月的 数据以及其他的 11 个数据库空间中的 11 个月的数据分割表中的数据。然而,如果要对所有年度数据仅使用一个数据库空间,那么可以创建指定分段,使每个月的数据存储在一个数据库空间中。
如果创建具有指定分段的分段表,sysfragments 系统目录中每行的分区列中都会包含分段名称。如果创建没有指定分段的分段表,那么数据库空间的名称位于分区列中。sysfragments 目录中的标志列告诉您分段存储方案中是否具有指定分段。
可以创建具有指定分段的表和索引,并且可以使用 PARTITION 关键字和分段名称创建、删除和修改指定分段。
要创建具有指定分段的分段表,请如以下示例中所示使用 SQL 语法:
CREATE TABLE tb1(a int)
FRAGMENT BY EXPRESSION
PARTITION part1 (a >=0 AND a < 5) IN dbspace1,
PARTITION part2 (a >=5 AND a < 10) IN dbspace1
...
;
如果创建的表或索引分段包含指定分段,那么在使用 ALTER FRAGMENT 语句时必须使用包含指定分段名称的语法,如以下示例中所示:
ALTER FRAGMENT ON TABLE tb1 INIT FRAGMENT BY EXPRESSION
PARTITION part_1 (a >=0 AND a < 5) IN dbspace1,
PARTITION part_2 (a >=5 AND a < 10) IN dbspace1;
ALTER FRAGMENT ON INDEX ind1 INIT FRAGMENT BY EXPRESSION
PARTITION part_1 (a >=0 AND a < 5) IN dbspace1,
PARTITION part_2 (a >=5 AND a < 10) IN dbspace1;
按此示例中所示,可使用 PARTITION BY EXPRESSION 子句替代 CREATE TABLE、CREATE INDEX 和 ALTER FRAGMENT ON INDEX 语句中的 FRAGMENT BY EXPRESSION 子句:
ALTER FRAGMENT ON INDEX idx1 INIT PARTITION BY EXPRESSION
PARTITION part1 (a <= 10) IN idxdbspc1,
PARTITION part2 (a <= 20) IN idxdbspc1,
PARTITION part3 (a <= 30) IN idxdbspc1;
使用 ALTER FRAGMENT 语法将不具有指定分段的分段表和索引更改为具有指定分段的表和索引。以下语法显示了如何可将具有多个数据库空间的分段表转换为具有指定分段的分段表:
CREATE TABLE t1 (c1 int) FRAGMENT BY EXPRESSION
(c1=10) IN dbs1,
(c1=20) IN dbs2;
ALTER FRAGMENT ON TABLE t1 MODIFY dbs2 TO PARTITION part_3 (c1=20)
IN dbs1
以下语法显示了如何可将分段索引转换为包含指定分段的索引:
CREATE TABLE t1 (c1 int) FRAGMENT BY EXPRESSION
(c1=10) IN dbs1, (c1=20) IN dbs2, (c1=30) IN dbs3
CREATE INDEX ind1 ON t1 (c1) FRAGMENT BY EXPRESSION
(c1=10) IN dbs1, (c1=20) IN dbs2, (c1=30) IN dbs3
ALTER FRAGMENT ON INDEX ind1 INIT FRAGMENT BY EXPRESSION
PARTITION part_1 (c1=10) IN dbs1, PARTITION part_2 (c1=20) IN dbs1,
PARTITION part_3 (c1=30) IN dbs1,
请参阅《GBase 8s SQL 指南:语法》以获取更多的语法详细信息,包括 GRANT FRAGMENT 和 REVOKE FRAGMENT 语句中有关指定分段的信息以及有关使用 ALTER FRAGMENT 语句的 DROP、DETACH 和 MODIFY 子句的详细信息。
创建临时数据库空间
要指定分配临时文件的位置,请创建临时数据库空间。
要定义临时数据库空间,请执行以下操作:
-
使用带 -c -d -t 选项的 onspaces 实用程序。
有关更多信息,请参阅创建使用缺省页大小的数据库空间。
-
使用 DBSPACETEMP 环境变量或配置参数可指定数据库服务器可用于临时存储器的数据库空间。
DBSPACETEMP 配置参数可包含非缺省页大小的数据库空间。虽然可在 DBSPACETEMP 的参数列表中包含页大小不同的各个数据库空间,但数据库服务器只会使用页大小和所列出的第一个数据库空间的页大小相同的数据库空间。
有关 DBSPACETEMP 的更多信息,请参阅 GBase 8s 管理员参考 中有关配置参数的主题。
-
如果创建了多个临时数据库空间,那么这些数据库空间必须位于不同磁盘上以优化 I/O。
如果要创建临时数据库空间,那么必须通过设置 DBSPACETEMP 配置参数和/或 DBSPACETEMP 环境变量让数据库服务器知道存在新创建的临时数据库空间。数据库服务器直至您采取以下两个步骤之后才开始使用临时数据库空间:
- 设置 DBSPACETEMP 配置参数和/或 DBSPACETEMP 环境变量。
- 重新启动数据库服务器。
以下示例显示了如何创建名为 temp_space 的 5 MB 临时数据库空间,偏移量为 5000 KB:
onspaces -c -t -d temp_space -p /dev/raw_dev1 -o 5000 -s 5120
有关更多信息,请参阅临时数据库空间。
磁盘空间不足时应执行的操作
当您正在创建的数据库空间的初始块是熟文件(在 UNIX™ 上)时,数据库服务器会验证磁盘空间是否足够用于该初始块。如果块大小大于磁盘上的可用空间,将显示消息且不会创建任何数据库空间。但是,未除去数据库服务器为初始块创建的熟文件。它的大小表示在您创建数据库空间之前文件系统上剩余的空间。 除去该文件以回收该空间。
向数据库空间或 BLOB 空间添加块
当数据库空间、BLOB 空间或智能大对象空间将满或需要更多磁盘空间时添加块。
重要: 新添加的块及其相关联的镜像(如果存在一个镜像)立即可用。如果您正向已镜像的存储空间添加块,那么必须还添加镜像块。
要使用 onspaces 添加块,请执行以下操作:
-
在 UNIX™ 上,必须以用户 gbasedbt 或 root 身份登录来添加块。
-
请确保数据库服务器处于在线、管理员或静态模式,或快速恢复方式的清除阶段。
-
按分配磁盘空间中所述,为块分配磁盘空间。
-
要添加块,请使用 onspaces 的 -a 选项。
如果存储空间已镜像,那么必须为主块和镜像块都指定路径名。
如果指定了不正确的路径名、偏移量或大小,那么数据库服务器不会创建块,并且会显示错误消息。另见磁盘空间不足时应执行的操作。
-
在创建块之后,必须对根数据库空间和包含该块的数据库空间、BLOB 空间或智能大对象空间执行 0 级备份。
以下示例将 10 兆字节的镜像块添加至 blobsp3。对主块和镜像块都指定了 200 KB 的偏移量。如果您不添加镜像块,那么可省略 -m 选项。
onspaces -a blobsp3 -p /dev/raw_dev1 -o 200 -s 10240 -m /dev/raw_dev2 200
下一个示例以 5200 KB 的偏移量向数据库空间 dbspc3 添加 5 MB 的原始磁盘空间块。
onspaces -a dbspc3 \\.\e: -o 5200 -s 5120
还可以定义当应用程序需要更多存储空间时,GBase 8s 可用于自动扩展块大小的信息。如果有可扩展块,那么无需添加新块或耗费时间来尝试确定哪种存储空间(数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 BLOB 空间)将耗尽空间,以及何时将耗尽空间。
当启用 CHUNK_OVERLAP_PROTECTION 配置参数时,数据库服务器将确保新块不会与其他块重叠。如果服务器发现块重叠,新块添加操作将失败。
重命名数据库空间
如果您是用户 gbasedbt 或者具有 DBA 特权,并且数据库服务器处于静态模式(不是其他方式),那么可使用 onspaces 实用程序来重命名数据库空间。
要重命名数据库空间,请使用以下 onspaces 实用程序命令:
onspaces -ren old_dbspace_name -n new_dbspace_name
可重命名标准数据库空间和所有其他空间,包括 BLOB 空间、智能 BLOB 空间、临时空间和外部空间。然而,您无法重命名任何关键数据库空间,比如根数据库空间或包含物理日志的数据库空间。
可重命名数据库空间和智能大对象空间:
- 启用了 Enterprise Replication 时
- 启动数据复制时,在主数据库服务器上
无法在辅助数据库服务器上或者当辅助数据库服务器为 Enterprise Replication 配置的一部分时重命名数据库空间和智能大对象空间
重命名数据库空间操作仅更改数据库空间名称;它不会重新组织数据。
重命名数据库空间命名更新所有存储该名称位置处的数据库空间名称。这包含磁盘上 的保留页、系统目录、ONCONFIG 配置文件和内存内数据结构。
重命名数据库空间后,对重命名的根数据库空间和根数据库空间执行 0 级归档。有关信息,请参阅《GBase 8s 备份与复原指南》。
重命名数据库空间之后可能需要执行的其他操作
如果重命名数据库空间,必须重新写入和重新编译引用旧数据库空间名称的所有存储过程代码。 例如,如果您的存储过程包含 ALTER FRAGMENT 关键字并引用了数据库空间名称,那么必须重新写入和重新编译该存储过程。
如果您重命名在 DATASKIP 配置参数中指定的数据库空间,那么您必须在重命名数据库空间后手动更新 DATASKIP 配置参数。
管理 BLOB 空间
本节说明如何创建 BLOB 空间和确定 BLOB 页大小。数据库服务器将 TEXT 和 BYTE 数据存储在数据库空间或 BLOB 空间中,但 BLOB 空间更有效率。有关添加块的信息,请参阅向数据库空间或 BLOB 空间添加块。
有关监视 BLOB 空间的信息,请参阅监视存储空间
创建 BLOB 空间
可以使用 onspaces 创建 BLOB 空间。
创建 BLOB 空间之前:
- 按分配磁盘空间中所述,为 BLOB 空间分配磁盘空间。
- 确定对您环境最佳的 BLOB 页大小。
有关指示信息,请参阅确定 BLOB 页大小。
指定最多为 128 个字节的 BLOB 空间名称。该名称必须是唯一的,并且必须以字母或下划线开头。您可以在名称中使用字母、数字、下划线和 $ 字符。
如果数据库服务器启用了镜像,那么您可在创建 BLOB 空间时对其制作镜像。镜像可立即生效。
要使用 onspaces 创建 BLOB 空间,请执行以下操作:
-
要在 UNIX™ 上创建 BLOB 空间,您必须以用户 gbasedbt 或 root 身份登录。
-
请确保数据库服务器处于在线、管理员或静态模式,或快速恢复方式的清除阶段。
-
要添加 BLOB 空间,请使用 onspaces -c -b 选项。
- 为 BLOB 空间指定明确的路径名。如果已对 BLOB 空间制作镜像,那么必须为主块和镜像块都指定路径名和大小。
- 使用 -o 选项为 BLOB 空间指定偏移量。
- 使用 -s 选项指定 BLOB 空间块的大小(以 KB 计)。
- 使用 -g 选项根据每个 BLOB 页的磁盘页数指定 BLOB 页大小。
请参阅确定 BLOB 页大小。例如,如果数据库服务器实例的磁盘页大小为 2 KB,而您需要大小为 10 KB 的 BLOB 页,那么在该字段中输入 5。
如果指定了不正确的路径名、偏移量或大小,那么数据库服务器不会创建 BLOB 空间,并且会显示错误消息。另见磁盘空间不足时应执行的操作。
-
在创建 BLOB 空间之后,必须对根数据库空间和新 BLOB 空间执行 0 级备份。
以下示例显示了如何在数据库服务器页大小为 2 KB 时,创建 BLOB 页大小为 10 KB 的 10 MB 镜像 BLOB 空间 blobsp3。为主块和镜像块指定偏移量 200 KB。BLOB 空间从 UNIX 上的原始磁盘空间创建。
onspaces -c -b blobsp3 -g 5 -p /dev/raw_dev1 -o 200 -s 10240 -m /dev/raw_dev2 200
有关使用 onspaces 创建 BLOB 空间的参考信息,请参阅 GBase 8s 管理员参考 中有关 onspaces 实用程序的信息。
准备 BLOB 空间以存储 TEXT 和 BYTE 数据
新创建的 BLOB 空间不能立即用于存储 TEXT 或 BYTE 数据。BLOB 空间日志记录和恢复需要在不同的逻辑日志文件中创建用于创建 BLOB 空间的语句,以及用于将 TEXT 和 BYTE 数据插入该 BLOB 空间的语句。对所有的 BLOB 空间均是如此要求,而无论数据库的日志记录状态。要满足该要求,请在创建 BLOB 空间后切换至下一逻辑日志文件。(有关指示信息,请参阅备份日志文件以释放 BLOB 页。)
确定 BLOB 页大小
在创建 BLOB 空间时,将最常出现的简单大对象的大小用作 BLOB 页的大小。换言之,选择浪费最少空间量的 BLOB 页大小。
如果一个表具有多个 TEXT 或 BYTE 列,并且各个对象的大小并不接近,请将每个列存储在不同的 BLOB 空间中,且每个列都用适当大小的 BLOB 页来存储。
确定数据库服务器页大小
在您指定 BLOB 页大小时,请根据数据库服务器基页大小来指定。
可以使用以下方法之一来确定您系统的数据库服务器页大小:
- 运行 onstat -b 实用程序以显示系统页大小,在输出的最后一行中显示其为缓冲区大小。
- 要查看 PAGE_PZERO 保留页的内容,请运行 oncheck -pr 实用程序。
获取 BLOB 空间存储统计信息
要帮助确定每个 BLOB 空间的最佳 BLOB 页大小,请使用以下数据库服务器实用程序命令:
- oncheck -pe
- oncheck -pB
oncheck -pe 命令提供有关存储在 BLOB 空间中的对象的背景信息:
- 有关每个有数据存储在 BLOB 空间块中的表的完整的所有权信息(显示为 database:owner.table)
- 每个表用于存储与其相关联的 TEXT 和 BYTE 数据的总页数
- BLOB 空间中总的可用页数和总的开销页数
oncheck -pB 命令列出以下有关每个表或数据库的信息:
- 表或数据库在每个 BLOB 空间中使用的 BLOB 页数
- 作为表或数据库的一部分而存储的每个简单大对象所用的 BLOB 页的平均填充度
管理智能大对象空间
本节描述如何创建标准的或临时的智能大对象空间、监视元数据或用户数据区域、向智能大对象空间添加块以及更改智能大对象的存储特征。
有关监视智能大对象空间的信息,请参阅监视存储空间。
创建智能大对象空间
使用 onspaces 实用程序创建智能大对象空间。
使用 onspaces 实用程序创建智能大对象空间。
要使用 onspaces 创建智能大对象空间,请执行以下操作:
- 要在 UNIX™ 上创建智能大对象空间,必须以用户 gbasedbt 或 root 身份登录。
- 请确保数据库服务器处于在线、管理员或静态模式,或者处于快速恢复方式的清除阶段。
- 使用 onspaces -c -S 选项创建智能大对象空间。
- 使用 -p 选项指定路径名、使用 -o 选项指定偏移量,以及使用 -s 选项指定智能大对象空间大小。
- 如果要对智能大对象空间制作镜像,请使用 -m 选项指定镜像路径和偏移量。
- 如果您希望使用智能大对象空间的缺省存储特征,那么省略 -Df 选项。如果您希望指定不同的存储特征,请使用 -Df 选项。有关更多信息,请参阅智能大对象空间的存储特征。
- 智能大对象空间中的第一个块必须具有元数据区域。您可以为智能大对象空间指定元数据区域,或让数据库服务器计算元数据区域的大小。有关更多信息,请参阅计算智能大对象空间元数据的大小。
- 在创建智能大对象空间之后,必须对根数据库空间和新智能大对象空间执行 0 级备份。
- 要在该智能大对象空间中开始存储智能大对象,请在 SBSPACENAME 配置参数中指定空间名称。
- 使用 onstat -d、onstat -g smb s 以及 oncheck -cs、-cS、-ps 或 -pS 来显示有关智能大对象空间的信息。
有关更多信息,请参阅监视智能大对象空间。
这显示了如何创建 20 兆字节的镜像智能大对象空间 sbsp4。为主块和镜像块均指定 500 KB 的偏移量,还指定偏移量为 200 KB 且大小为 150 KB 的元数据。AVG_LO_SIZE -Df 标记指定 32 KB 的智能大对象平均期望大小。
onspaces -c -S sbsp4 -p /dev/rawdev1 -o 500 -s 20480 -m /dev/rawdev2 500
-Ms 150 -Mo 200 -Df "AVG_LO_SIZE=32"
有关创建智能大对象空间和智能大对象缺省选项的信息,请参阅《GBase 8s 管理员参考》 中有关 onspaces 实用程序的信息。
计算智能大对象空间元数据的大小
智能大对象空间的第一个块必须有元数据区域。 在向智能大对象空间添加智能大对象和块时,元数据区域会增大。另外,数据库服务器保留 40% 的用户区域,在元数据区域空间耗尽的情况下使用。
为智能大对象空间正确估算元数据区域以确保智能大对象空间不会耗尽元数据空间,这一点很重要。您可以使用以下方法之一:
- 让数据库服务器为新智能大对象空间块计算元数据区域的大小。
- 明确指定元数据区域的大小。
向智能大对象空间添加块
可以将块添加到智能大对象空间或临时智能大对象空间。
您可以为块指定元数据区域、让数据库服务器计算元数据区域或者将块仅用于用户数据。
要使用 onspaces 将块添加到智能大对象空间,请执行以下操作:
- 请确保数据库服务器处于在线、管理员或静态模式,或者处于快速恢复方式的清除阶段。
- 使用 onspaces -a 选项创建智能大对象空间块。
- 使用 -p 选项指定路径名、使用 -o 选项指定偏移量,以及使用 -s 选项指定块大小。
- 如果您希望对块制作镜像,请使用 -m 选项指定镜像路径和偏移量。
- 要指定元数据空间的大小和偏移量,请使用 -Mo 和 -Ms 选项。
数据库服务器在新块上分配指定量的元数据区域。 - 要让数据库服务器为新块计算元数据大小,那么省略 -Mo 和 -Ms 选项。
数据库服务器按用户数据区域大小划分智能大对象的估计平均大小。 - 要将块仅用于用户数据,请指定 -U 选项。
如果您使用 -U 选项,那么数据库服务器不会在该块中分配元数据空间。取而代之,智能大对象空间使用一个其他块中的元数据区域。
- 在将块添加到智能大对象空间后,数据库服务器将编写 CHRESERV 和 CHKADJUP 日志记录。
- 对根数据库空间和智能大对象空间执行 0 级备份。
- 使用 onstat -d 和 oncheck -pe 可监视智能大对象空间块中的可用空间量。
此示例向 sbsp4 添加 10 兆字节的镜像块。 对主块和镜像块都指定了 200 KB 的偏移量。如果您不添加镜像块,那么可省略 -m 选项。-U 选项指定新块仅包含用户数据。
onspaces -a sbsp4 -p /dev/rawdev1 -o 200 -s 10240 -m /dev/rawdev2 200 -U
还可以定义当应用程序需要更多存储空间时,GBase 8s 可用于自动扩展块大小的信息。如果有可扩展块,那么无需添加新块或耗费时间来尝试确定哪种存储空间(数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 BLOB 空间)将耗尽空间,以及何时将耗尽空间。
当启用 CHUNK_OVERLAP_PROTECTION 配置参数时,数据库服务器将确保新块不会与其他块重叠。如果服务器发现块重叠,新块添加操作将失败。
更改智能大对象的存储特征
使用 onspaces -ch 命令为智能大对象空间更改以下缺省存储特征:
- 扩展数据块大小
- 平均智能大对象大小
- 缓冲方式
- 上次访问时间
- 锁定方式
- 日志记录
创建临时智能大对象空间
有关确定智能大对象存储位置的背景信息和规则,请参阅临时智能大对象空间。您可将临时智能大对象存储在标准的或临时的智能大对象空间中。可以在临时智能大对象空间中添加或删除块。
要创建具有临时智能大对象的临时智能大对象空间,请执行以下操作:
-
为临时智能大对象空间分配空间。
有关详细信息,请参阅分配磁盘空间。
有关 SBSPACETEMP 的信息,请参阅《GBase 8s 管理员参考》中有关配置参数的主题。
-
如以下示例所示,创建临时智能大对象空间:
onspaces -c -S tempsbsp -t -p ./tempsbsp -o 0 -s 1000 -
您可任意指定以下 onspaces 选项:
-
指定元数据区域和偏移量(-Ms 和 -Mo)。
-
指定存储特征 (-Df)。
无法为临时智能大对象空间打开日志记录。
-
-
将 SBSPACETEMP 配置参数设置为缺省临时智能大对象空间存储区域的名称。
重新启动数据库服务器。
-
使用 onstat -d 显示临时智能大对象空间。
有关 onstat -d 输出示例的信息,请参阅《GBase 8s 管理员参考》中的 onstat 实用程序。
-
在创建临时智能大对象时指定 LO_CREATE_TEMP 标志。
使用 GBase 8s ESQL/C:
ifx_lo_specset_flags(lo_spec,LO_CREATE_TEMP);
有关创建智能大对象的信息,请参阅《GBase 8s ESQL/C 程序员手册》。
自动空间管理
可将服务器配置为需要更多空间时,自动添加更多存储空间。这样就可以更有效地使用空间,并确保在必要时分配空间,同时减少空间不足错误,以及减少手动监视空间和确定哪些存储空间将耗尽可用空间与何时耗尽空间所需的时间。将服务器配置为自动添加空间时,也可手动扩充空间或扩展块。
服务器扩展存储空间(数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间)时,服务器可向该存储空间添加块。如果存储空间是非镜像的数据库空间或临时数据库空间,服务器还可以扩展该存储空间中的块。
自动空间管理适用于参与 Enterprise Replication 的服务器或集群。要通过 Enterprise Replication 域传播 CDR_QDATA_SBSPACE 和 CDR_DBSPACE 配置参数,请使用 cdr define 命令。
要对空间的自动和手动管理进行配置,请运行 SQL 管理 API 命令来执行以下任务:
- 在存储池中创建、修改和删除一个或多个条目。存储池中包含 GBase 8s 用于扩展存储空间的可用原始设备、熟文件和目录的条目。
- 将块标记为可扩展。
- 修改存储空间的创建和扩展大小(可选)。
- 更改自动添加更多空间的阈值和等待时间(可选)。
- 配置“监视低存储量”任务的频率(可选)。
如果存储池中包含条目,也可运行 SQL 管理 API 命令来执行以下操作:
- 不希望等待运行自动扩充空间的任务时,手动扩充存储空间或扩展块。
- 通过存储池条目手动创建存储空间,并将空存储空间中的空间返还给存储池。
如果不希望服务器自动扩充空间,可将 SP_AUTOEXPAND 配置参数设置为 0,以禁用块的自动创建或扩展。也可指定某个块不可扩展。
在某些情况下,将数据库服务器配置为自动扩展现有存储空间后,该服务器可能不会自动扩展 DBSPACETEMP 配置参数中列出的临时数据库空间。如果使用临时数据库空间的操作(例如,索引构建或排序)耗尽空间,那么您将收到“空间不足”错误。
要解决此问题,必须手动向临时数据库空间添加块或者使用更大的临时数据库空间。
创建和管理存储池条目
可在存储池中添加、修改或删除条目(存储池是 GBase 8s 可在必要时用于自动向现有存储空间添加空间的可用原始设备、熟文件或目录的集合)。
存储池中的每一个条目都包含有关以下对象的信息:GBase 8s 实例可在必要时用于自动扩展现有数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间的目录、熟文件或原始设备。
创建存储池条目
要创建存储池条目,请运行带 storagepool add 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool add", "path", "begin_offset",
"total_size", "chunk size", "priority");
指定以下信息:
- 需要更多存储空间时服务器可使用的文件、目录或设备的路径。
- GBase 8s 可开始分配空间的设备的偏移量(以 KB 计)。
- 此条目中 GBase 8s 可用的总空间。服务器可从该空间量中分配多个块。
- 可从设备、文件或目录分配的块的最小大小(以 KB 计)。可创建的最小块为 1000 K。因此,可指定的最小块大小为 1000 K。
- 优先级数字,从 1 到 3(1 = 高;2 = 中;3 = 低)。服务器会尝试先从高优先级的条目分配空间,然后再从较低优先级的条目分配空间。
存储池大小和偏移量的缺省单位为 KB。但也可以按照以下示例中显示的任意方式指定信息:
- "100000"
- "100000 K"
- "100 MB"
- "100 GB"
- "100 TB"
修改存储池条目
要修改存储池条目,请运行带 storagepool modify 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool modify", "storage_pool_entry_id",
"new_total_size", "new_chunk size", "new_priority");
删除存储池条目
要删除存储池条目,请运行带 storagepool delete 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool delete", "_storage_pool_entry_id_");
要删除所有存储池条目,请运行带 storagepool purge all 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool purge all");
要删除已满的所有存储池条目,请运行带 storagepool purge full 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool purge full");
要删除有错的存储池条目,请运行带 storagepool purge errors 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("storagepool purge errors");
示例
以下命令添加开始偏移量为 0,总大小为 0,初始块大小为 20 兆字节且具有高优先级的目录,名称为 /region2/dbspaces。在该示例中,对于目录而言,只能接受偏移量为 0 和总大小为 0 这两个条目。
EXECUTE FUNCTION task("storagepool add", "/region2/dbspaces", "0", "0", "20000", "1");
以下命令将存储池中第 8 个条目的总大小、块大小和优先级更改为 10 千兆字节、10 兆字节和中优先级。
EXECUTE FUNCTION task("storagepool modify", "8", "10 GB", "10000", "2");
以下命令删除条目标识为 7 的存储池条目:
EXECUTE FUNCTION task("storagepool delete", "7");
将块标记为可扩展或不可扩展
将块标记为可扩展,可以对块启用自动或手动扩展。将该标记更改为不可扩展,则可以防止自动或手动扩展块。
如果块标记为不可扩展:
- 块中只有少量或没有可用空间时,服务器不能自动扩展块。(但是,如果存储池中包含条目,那么服务器可通过向存储空间添加另一个块来扩展存储空间。)
- 不能手动扩展块的大小。
先决条件: 可扩展块必须位于未镜像数据库空间或临时数据库空间中。
要将块标记为可扩展,请执行以下操作:
运行带 modify chunk extendable 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("modify chunk extendable", "chunk number");
要将块标记为不可扩展,请执行以下操作:
运行带 modify chunk extendable off 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("modify chunk extendable off", "_chunk number_");
以下命令指定可扩展第 12 个块:
EXECUTE FUNCTION task("modify chunk extendable", "12");
修改存储空间的创建或扩展大小
通过以下方法可以控制存储池条目的使用方式:修改与扩充存储空间相关的两个不同的数据库空间大小,即创建大小和扩展大小。
要修改存储空间的创建或扩展大小,请执行以下操作:
运行带 modify space sp_sizes 自变量的 admin() 或 task() 函数,如下所示:
EXECUTE FUNCTION task("modify space sp_sizes", "space_name",
"new_create_size", "new_extend_size");
对于:
- new_create_size,请指定在指定的数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中创建新块时,服务器可使用的最小大小。
- new_extend_size,请指定在指定的未镜像数据库空间或临时数据库空间中扩展块时,服务器可使用的最小大小。
使用数字(KB 数)或百分比(占总空间的百分比)指定大小。
以下命令将名为 dbspace3 的空间的创建大小和扩展大小分别设置为 60 兆字节和 10 兆字节:
EXECUTE FUNCTION task("modify space sp_sizes", "dbspace3", "60000", "10000");
以下命令将名为 logdbs 的空间的创建大小和扩展大小分别设置为 20% 和 1.5%:
EXECUTE FUNCTION task("modify space sp_sizes", "logdbs", "20", "1.5");
更改自动添加更多空间的阈值和等待时间
当存储空间已满时,GBase 8s 可以通过自动扩展或添加块来应对空间不足的情况,而您也可以配置服务器以在存储空间变满之前扩展或添加块。
为此,可为数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中的最小可用 KB 量指定一个阈值。
定义的阈值用于触发扩充空间的任务。
也可使用 SP_WAITTIME 配置参数指定返回空间不足错误之前,线程等待空间扩充的最大秒数。
要更改阈值和等待时间,请执行以下操作:
- 将 SP_THRESHOLD 配置参数中指定的阈值的值从 0(已禁用)更改为非零值。指定 1 到 50 的百分数或指定 1000 到块的最大大小(以 KB 计)。
- 更改 SP_WAITTIME 配置参数的值,该配置参数指定返回空间不足错误之前,线程等待空间扩展的最大秒数。
配置监视低存储任务的频率
可更改 mon_low_storage 任务的频率,该任务定期扫描数据库空间列表,以查找低于 SP_THRESHOLD 配置参数指示的阈值的空间。 如果该任务找到了低于该阈值的空间,将尝试扩充找到的空间,方法是扩展可扩展块,或使用存储池来添加块。
mon_low_storage 任务的缺省频率为每小时一次,但也可以配置该任务,以增加或减小运行频率
先决条件:在 SP_THRESHOLD 配置参数中,为数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中的最小可用 KB 量指定一个值。
要将 mon_low_storage 任务配置为以更高或更低频率运行,请执行以下操作:
运行以下 SQL 语句,其中 minutes 是两次运行之间的分钟数:
DATABASE sysadmin;
UPDATE ph_task set tk_frequency = INTERVAL (minutes)
MINUTE TO MINUTE WHERE tk_name = “mon_low_storage”;
例如,要将任务配置为每 10 分钟运行一次,请运行以下 SQL 语句:
DATABASE sysadmin;
UPDATE ph_task set tk_frequency = INTERVAL (10) MINUTE TO MINUTE
WHERE tk_name = “mon_low_storage”;
手动扩充空间或扩展可扩展块
必要时可手动扩充空间或扩展块,而无需等待 GBase 8s 自动扩充空间或扩展块。
先决条件:
- 只能扩展位于未镜像数据库空间或临时数据库空间中的块。
- 块必须先标记为可扩展,然后才能扩展。 否则,必须运行带 modify chunk extendable 自变量的 admin() 或 task() 函数来指定该块可扩展。
- 如果不能通过扩展块来扩充空间,那么存储池中必须包含服务器可用于创建新块的活动条目。
要立即增加存储空间:
执行以下任一项操作:
- 通过运行带 modify space expand 自变量的 admin() 或 task() 函数手动扩充空间,如下所示:
EXECUTE FUNCTION task("modify space expand", "_space_name_", "_size_");
例如,以下命令将编号为 8 的空间扩展 1 千兆字节:
EXECUTE FUNCTION task("modify space expand", "8", "1000000");
服务器通过扩展空间中的块或添加新块来扩充空间。服务器可能对请求的大小向上取整,具体取决于存储空间的页大小以及扩展期间任何存储池条目所使用的已配置块大小。
- 通过运行带 modify chunk extend 自变量的 admin() 或 task() 函数手动扩展块,如下所示:
EXECUTE FUNCTION task("modify chunk extend", "_chunk_number_", "_extend_amount_");
例如,以下命令将编号为 12 的块扩展 5000 KB:
EXECUTE FUNCTION task("modify chunk extend", "12", "5000");
服务器可能对请求的大小向上取整,具体取决于存储空间的页大小。
对自动添加更多空间的最低程度配置和测试的示例
此示例显示可如何最低程度地配置和测试自动添加更多空间。可通过创建数据库空间、填充空间、向 GBase 8s 存储池添加条目和将表装入空间来执行此操作。空间填满之后,GBase 8s 将自动扩展该空间。
要最低程度地配置和测试自动添加更多空间,请执行以下操作:
-
创建数据库空间。
例如,创建名为 expandable_dbs 的数据库空间,并将名为 /my_directory/my_chunk 的熟文件的前 10000 KB 分配给初始块,如下所示:
onspaces -c -d expandable_dbs -p /my_directory/my_chunk -o 0 -s 10000 -
填充数据库空间。
例如,在不装入数据行的情况下填充数据库空间。实际操作是创建表,然后为第一个扩展数据块分配一大组邻接的可用页,如下所示:
CREATE TABLE large_tab (col1 int) IN expandable_dbs EXTENT SIZE 10000000;可通过使用 onstat -d 命令来监视块中的可用页。如果数据库空间已满,那么在尝试创建数据并将其装入到另一个新表时,将收到空间不足的错误。
-
向 GBase 8s 存储池添加条目。
例如,将 $GBASEDBTDIR/tmp 目录添加到存储池,如下所示:
DATABASE sysadmin;
EXECUTE FUNCTION task("storagepool add", "$GBASEDBTDIR/tmp",
"0", "0", "10000", "2"); -
在 SP_THRESHOLD 配置参数中,设置 GBase 8s 自动运行任务以扩充空间之前,存储空间中可包含的最小可用 KB 量的阈值。
-
创建新表并将其装入数据库。
现在,如果存储空间变满,不会再收到空间不足的错误,而是由 GBase 8s 自动在 $GBASEDBTDIR/tmp 文件中创建熟文件,并使用这个新的熟文件向 expandable_dbs 数据库添加块。继续填充此块时,服务器将自动对其进行扩展。向数据库空间添加新块之前,如果可能,服务器将始终扩展块。
-
减小存储空间中的可用空间,以测试 SP_THRESHOLD 配置参数中的值。
在数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中分配足够的页面,以减少可用空间,使其低于 SP_THRESHOLD 指示的阈值。但是,请勿填满该空间。
下次运行 mon_low_storage 任务时,您会发现该空间将自动扩展。
-
创建空间不足的条件。
在数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中分配所有页。然后尝试分配更多页。必须确保此分配成功,并且确保不会收到空间不足的错误。
GBase 8s 每次扩展或添加块以及将新块标记为可扩展时,都会向日志中写入消息。
运行 onstat -d 命令可显示实例中的所有块。查找可扩展块,这种块带有 E 标志。该命令输出会显示服务器自动扩充了空间,方法是添加了新块或扩展了现有块的大小。
自动添加更多空间的配置示例
此示例显示可通过以下方法对自动添加更多空间进行充分配置:更改某些配置参数的设置,更改用于监视低存储的任务的频率,以及指定可扩展空间和块的信息。
要配置为自动添加更多存储空间:
-
向存储池添加条目。
例如,将 $GBASEDBTDIR/tmp 目录添加到存储池,如下所示:
DATABASE sysadmin;
EXECUTE FUNCTION task("storagepool add", "$GBASEDBTDIR/tmp",
"0", "0", "10000", "2"); -
将未镜像数据库空间和临时数据库空间中的某些块标记为可扩展,以便将来必要时,服务器可扩展这些块。
例如,指定第 12 个块可扩展:
EXECUTE FUNCTION task("modify chunk extendable", "12");也可将可扩展块的标记更改为不可扩展。 例如,指定编号为 10 的块不可扩展:
EXECUTE FUNCTION task("modify chunk extendable off", "10"); -
在 SP_THRESHOLD 配置参数中,设置 GBase 8s 自动运行任务以扩充空间之前,存储空间中可包含的最小可用 KB 量的阈值。指定以下任一项:
- 1 到 50 的百分比值。
- 1000 到块最大大小的值(以 KB 计)
如果单个存储空间的填充程度超过了您定义的此阈值,并且该填充程度持续到下次运行空间监视任务 (mon_low_storage) 为止,那么服务器将通过扩展可扩展块或通过使用存储池添加块来尝试扩充该空间。
例如,假设 SP_THRESHOLD 值为 5.5,服务器将该值视为 5.5%。如果某个空间中的可用页很少,可用空间百分比降到 5.5% 以下,并且这种低水平持续到下次运行 mon_low_storage 任务为止,那么该任务将尝试扩展此空间。如果 SP_THRESHOLD 设置为 50000,并且某个空间的可用空间低于 50000 KB,那么下次运行 mon_low_storage 时将扩展该空间。
-
**可选:**更改 mon_low_storage 任务的运行频率。该任务定期扫描数据库空间列表,以查找低于 SP_THRESHOLD 配置参数指示的阈值的空间。
例如,要将任务配置为每 10 分钟运行一次,请运行以下 SQL 语句:
DATABASE sysadmin;
UPDATE ph_task set tk_frequency = INTERVAL (10) MINUTE TO MINUTE
WHERE tk_name = “mon_low_storage”; -
可选: 更改 SP_WAITTIME 配置参数的值,该配置参数指定返回空间不足错误之前,线程等待空间扩展的最大秒数。
-
可选: 更改与扩展存储空间相关的两种大小:
- 扩展大小,这是扩展数据库空间或临时数据库空间中的块时使用的最小大小。
- 创建大小,这是在不属于镜像空间的数据库空间、临时数据库空间、智能大对象空间、临时智能大对象空间或 Blob 空间中创建新块时使用的最小大小。
例如,以下命令将编号为 3 的空间的创建大小和扩展大小分别设置为 60 兆字节和 10 兆字节:
EXECUTE FUNCTION task("modify dbspace sp_sizes",
"3", "60000", "10000");
对存储空间的自动扩充进行了配置之后,也可在必要时手动扩充空间或扩展空间中的块。
删除块
使用 onspaces 或 Server Administrator 从数据库空间删除块。
在删除块之前,请使用下表作为指导方针,确保数据库服务器处于正确方式。
| 块类型 | 在线模式下的数据库服务器 | 管理员模式或静态模式下的数据库服务器 | 脱机方式下的数据库服务器 |
|---|---|---|---|
| 数据库空间块 | 是 | 是 | 否 |
| 临时数据库空间块 | 是 | 是 | 否 |
| BLOB 空间块 | 否 | 是 | 否 |
| 智能大对象空间或临时智能大对象空间块 | 是 | 是 | 否 |
验证块是否为空
要用这些实用程序之一从数据库空间成功删除块,块不能包含任何数据。开销页以外的所有页都必须得到释放。
如果有任何页保持分配给未开销的实体,那么实用程序会返回以下错误:块不为空。
此外,当数据库空间由两个或更多的块组成并且附加块不包含用户数据时,如果这些附加块包含表空间 tblspace,那么它们无法被删除。
如果接收到块不为空消息,必须通过运行 oncheck -pe 列出扩展数据块内容,从而确定哪些表或其他实体仍在占用块中的空间。
通常,在您删除拥有这些页的表时就会除去这些页。然后重新输入实用程序命令。
使用 onspaces 从数据库空间删除块
以下示例在 UNIX™ 上从 dbsp3 删除块。 指定了 300 KB 的偏移量。
onspaces -d dbsp3 -p /dev/raw_dev1 -o 300
您不能用以上示例中的语法来删除数据库空间的初始块。取而代之,您必须删除数据库空间。使用 onstat -d 的 fchunk 列来确定数据库空间的初始块。有关 onstat 的更多信息,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
有关使用 onspaces 从数据库空间删除块的信息,请参阅《GBase 8s 管理员参考》。
从 BLOB 空间删除块
从 BLOB 空间删除块的过程与使用 onspaces 从数据库空间删除块中所述的从数据库空间删除块的过程相同,但是数据库服务器必须处于静态模式或管理员模式。除了这一条件,还必须将任何出现对数据库空间的引用之处替换为您的 BLOB 空间名称。
使用 onspaces 从智能大对象空间删除块
以下示例在 UNIX™ 上从 sbsp3 删除块。 指定了 300 KB 的偏移量。当从智能大对象空间或临时智能大对象空间删除块时,数据库服务器必须处于在线管理员模式或静态模式。
onspaces -d sbsp3 -p /dev/raw_dev1 -o 300
您不能用以上示例中的语法来删除智能大对象空间的初始块。取而代之,您必须删除智能大对象空间。使用 onstat -d 的 fchunk 列来确定哪个块是智能大对象空间的初始块。
-f(强制)选项
您可以使用 onspaces 的 -f 选项来删除其中未分配元数据的智能大对象空间块。 如果该块包含智能大对象空间的元数据,那么必须删除整个智能大对象空间。使用 onstat -d 的块部分来确定哪些智能大对象空间块包含元数据。
onspaces -d sbsp3 -f
如果您强制删除智能大对象空间,那么可能为表和智能大对象空间之间造成一致性方面的问题。
删除不带任何指针的智能大对象
每个智能大对象均有引用计数,即智能大对象的指针数。当引用计数大于 0 时,数据库服务器假定智能大对象正在使用中,就不会予以删除。
而引用计数为 0 的智能大对象很少会保留下来。您可使用 onspaces -cl 命令删除所有引用计数为 0 的智能大对象(如果它未被任何应用程序打开)。
有关使用 onspaces -cl 的信息,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
删除存储空间
使用 onspaces 可删除数据库空间、临时数据库空间、BLOB 空间、智能大对象空间、临时智能大对象空间或外部空间。
在 UNIX™ 上,您必须以 root 或 gbasedbt身份登录来删除存储空间。
仅当数据库服务器处于在线、管理员或静态模式时,才能删除存储空间。
删除存储空间的准备工作
在删除数据库空间之前,您必须首先删除所有先前在数据库空间创建的数据库和表。您不能删除根数据库空间。
在删除 BLOB 空间之前,必须删除具有引用了该 BLOB 空间的 TEXT 或 BYTE 列的所有表。
运行 oncheck -pe 以验证没有表或日志文件位于数据库空间或 BLOB 空间中。
在删除某个智能大对象空间之前,必须删除具有引用了该智能大对象空间中存储对象的 CLOB 或 BLOB 列的所有表。对于智能大对象空间,无需删除指向智能大对象空间的列,但这些列必须为空;也就是说,所有智能大对象必须取消分配至智能大对象空间。
如果您在发生轻量级追加的数据库空间中删除表,这些轻量级追加可能会比您所期望的要慢。该问题的症状就是物理日志记录活动。如果轻量级追加比您所期望的要慢,请确保在轻量级追加之前或在轻量级追加期间没有从数据库空间中删除表。如果您已删除了表,请在执行轻量级追加之前用 onmode -c 强制执行检查点。
删除块或数据库空间将触发阻塞检查点,这会强制所有数据库更新等待所有缓冲池清空到磁盘之后才执行。此更新阻塞在阻塞检查点期间所用时间可能比非阻塞检查点期间所用时间长得多,特别是缓冲池很大的情况下。
删除镜像存储空间
如果您删除已镜像的存储空间,那么镜像空间也被删除。
如果您希望仅删除存储空间镜像,请关闭镜像。(请参阅结束镜像过程。)该操作删除数据库空间、BLOB 空间或智能大对象空间镜像,并释放块以作其他用途。
使用 onspaces 删除存储空间
要使用 onspaces 删除存储空间,请按以下示例说明,使用 -d 选项。
以下示例删除名为 dbspce5 的数据库空间及其镜像。
onspaces -d dbspce5
以下示例删除名为 blobsp3 的数据库空间及其镜像。
onspaces -d blobsp3
如果您希望删除包含数据的智能大对象空间,那么将 -d 选项与 -f 选项一起使用。如果省略 -f 选项,您就无法删除包含数据的智能大对象空间。此示例删除称为 sbspc4 的智能大对象空间及其镜像。
onspaces -d sbspc4 -f
如果您使用 -f 选项,数据库服务器中的表可能包含指向已删除的智能大对象的无效指针。
有关使用 onspaces 删除存储空间的信息,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
删除存储空间后备份
如果您创建了名称与已删除存储空间相同的存储空间,请执行 0 级备份,以确保以后的存储不会将新存储空间与旧存储空间相混淆。有关更多信息,请参阅《GBase 8s 备份与复原指南》。
在删除数据库空间、BLOB 空间或智能大对象空间之后,新释放的块可用于重新分配至其他数据库空间、BLOB 空间或智能大对象空间。但是,在重新分配新释放的块之前,必须对根数据库空间和修改过的存储空间执行 0 级备份。如果未执行该备份,但随后必须执行复原,那么复原可能失败,因为备份保留页不是最新的。
从存储池创建空间或块
如果存储池中包含条目,可从存储池中的可用空间创建存储空间或块。
先决条件: 存储池中必须包含条目(目录、熟文件或原始设备)。
要从存储池创建存储空间或块,请执行以下操作:
运行带以下自变量之一的 admin() 或 task() 函数从存储池创建空间。命令中所用元素取决于要创建的空间类型。
- EXECUTE FUNCTION task("create dbspace from storagepool", "space_name", "size", "page_size", "mirroring_flag", "first_extent", "next_extent");
- EXECUTE FUNCTION task("create tempdbspace from storagepool", "space_name", "size", "page_size");
- EXECUTE FUNCTION task("create blobspace from storagepool", "space_name", "size", "page_size", "mirroring_flag",);
- EXECUTE FUNCTION task("create sbspace from storagepool", "space_name", "size", "log_flag", "mirroring_flag",);
- EXECUTE FUNCTION task("create tempsbspace from storagepool", "space_name", "size",);
- EXECUTE FUNCTION task("create chunk from storagepool", "space_name", "size",);
示例
以下命令创建名为 blobspace1 的镜像 Blob 空间。新 Blob 空间的大小为 100 千兆字节,Blob 页大小为 100 页。
EXECUTE FUNCTION task("create blobspace from storagepool", "blobspace1", "100 GB", "100", "1");
以下命令向名为 logdbs 的数据库空间添加块。新块的大小为 200 兆字节。
EXECUTE FUNCTION task("create chunk from storagepool", "logdbs", "200 MB");
将空的空间返还给存储池
可将空块或空存储空间中的空间返还给存储池。
要将空的块、数据库空间、临时数据库空间、Blob 空间、智能大对象空间或临时智能大对象空间中的存储空间返还给存储池,请执行以下操作:
运行带以下自变量之一的 admin() 或 task() 函数将空间返还给存储池。命令中所用元素取决于要删除的对象类型。
- EXECUTE FUNCTION task("drop chunk to storagepool", "space_name", "chunk_path", "chunk_offset")
- EXECUTE FUNCTION task("drop dbspace to storagepool", "space_name");
- EXECUTE FUNCTION task("drop tempdbspace to storagepool", "space_name");
- EXECUTE FUNCTION task("drop blobspace to storagepool", "space_name");
- EXECUTE FUNCTION task("drop sbspace to storagepool", "space_name");
- EXECUTE FUNCTION task("drop tempsbspace to storagepool", "space_name");
示例
以下命令删除名为 blob4 的空 Blob 空间,并将释放的所有空间添加到存储池。
EXECUTE FUNCTION task("drop blobspace to storagepool", "blob4");
以下命令删除名为 health 的数据库空间中的空块,并将释放的所有空间添加到存储池。
EXECUTE FUNCTION task("drop chunk to storagepool", "health",
"/health/rawdisk23", "100 KB");
管理外部空间
外部空间不需要分配磁盘空间。 使用 onspaces 实用程序创建和删除外部空间。 有关外部空间的更多信息,请参阅外部空间。
创建外部空间
用 onspaces 实用程序创建外部空间。 但是首先必须具有有效数据源和用来访问该数据源的有效访问方法。虽然您可以创建不带有效访问方法或有效数据源的外部空间,但是从该外部空间检索数据的任何尝试都将生成错误。
要用 onspaces 创建外部空间,请按以下示例说明,使用 -c 选项。以下示例显示了如何创建与 UNIX™ 密码文件相关联的外部空间 pass_space。
onspaces -c -x pass_space -l /etc/passwd
指定最多为 128 字节的外部空间名称。该名称必须是唯一的,并以字母或下划线开始。您可以在名称中使用字母、数字、下划线和 $ 字符。
以上示例假设您编写了提供正确访问文件 passwd 的函数的例程,并假设文件本身已存在。在创建了外部空间之后,就必须使用适当的命令以允许访问文件 passwd 中的数据。有关用户定义的访问方法的更多信息,请参阅*《GBase 8s虚拟表接口程序员指南》*。
有关使用 onspaces 创建外部空间的参考信息,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
删除外部空间
要使用 onspaces 删除外部空间,请按以下示例说明使用 -d 选项。外部空间如果不与现有表或索引相关联,就无法删除。
以下示例删除名为 pass_space 的外部空间。
onspaces -d pass_space
跳过不可访问的分段
分段存储的一个好处是可以在 I/O 操作期间跳过不可用的表分段。例如,即使当分段位于当前由于磁盘故障而脱机的块上时,查询也可继续。发生这种情况时,磁盘故障仅影响分段表中的部分数据。相较而言,如果未分段的表位于故障磁盘上,它们可能会变得完全不可访问。
如下所示控制此功能:
- 由数据库服务器管理员使用 DATASKIP 配置参数
- 由各个应用程序使用 SET DATASKIP 语句
DATASKIP 配置参数
可将 DATASKIP 参数设置为 OFF、ALL 或 ON dbspace_list。OFF 表示数据库服务器不跳过任何分段。如果分段不可用,查询将返回错误。ALL 指示跳过所有不可用的分段。ON dbspace_list 指示数据库服务器跳过任何位于指定数据库空间中的分段。
onspaces 的数据跳过功能
使用 onspaces 实用程序的 dataskip 功能来指定要跳过的数据库空间(当这些数据库空间不可用时)。 例如,以下命令设置 DATASKIP 参数,使数据库服务器跳过 dbspace1 和 dbspace3 中的分段,但不跳过 dbspace2 中的分段:
onspaces -f ON dbspace1 dbspace3
有关此 onspaces 选项的完整语法,请参阅《GBase 8s 管理员参考》中有关 onspaces 实用程序的信息。
使用 onstat 检查数据跳过状态
使用 onstat 实用程序列出当前受 dataskip 功能影响的数据库空间。-f 选项同时列出使用 DATASKIP 配置参数以及使用 onspaces 实用程序的 -f 选项设置的数据库空间。
运行 onstat -f 时,您会收到消息,通知您 DATASKIP 配置参数是对所有数据库空间设置为 on、对所有数据库空间设置为 off,还是对特定数据库空间设置为 on。
SQL 语句 SET DATASKIP
应用程序可以使用 SQL 语句 SET DATASKIP 来控制在某个分段不可用时是否跳过该分段。 应用程序必须仅在有限情况下包含此语句,因为它会使查询根据底层分段的可用性而返回不同结果。与配置参数 DATASKIP 类似,SET DATASKIP 语句接受那些向数据库服务器指示要跳过哪些分段的数据库空间列表。例如,假设某应用程序的编程人员将以下语句包含在应用程序的开始:
SET DATASKIP ON dbspace1, dbspace5
该语句使数据库服务器在以下两个条件都满足时就跳过 dbspace1 或 dbspace5:
- 应用程序尝试访问这两个数据库空间之一。
- 数据库服务器发现这两个数据库空间之一不可用。
如果数据库服务器发现 dbspace1 和 dbspace5 均不可用,它会跳过这两个数据库空间。
数据库服务器管理员可使用 SET DATASKIP 语句的 DEFAULT 设置来控制数据跳过功能。假设应用程序开发者将以下语句包含在应用程序中:
SET DATASKIP DEFAULT
如果在此 SQL 语句之后紧接着运行查询,那么数据库服务器会检查配置参数 DATASKIP 的值。数据库服务器管理员可鼓励用户使用此设置,以便指定当数据库服务器管理员注意到一个或多个数据库空间不可用时,要立即跳过的数据库空间。
数据跳过功能对事务的影响
如果打开 dataskip 功能,那么 SELECT 语句将始终执行。另外,如果表由循环分段且至少有一个分段在线,那么 INSERT 语句将始终成功执行。但是,当写入数据库的操作可能会影响数据库的完整性时,数据库服务器不会完成这类操作。以下操作失败:
- 当数据库服务器无法消除脱机的分段时,为所有的 UPDATE 和 DELETE 操作
如果数据库服务器可以消除脱机的分段,那么更新或删除操作成功,但结果与 DATASKIP 设置无关。
- 当相应分段脱机时,根据基于表达式的分布方案对已分段的表的 INSERT 操作
- 当约束包含脱机的分段中的数据时,任何包含参阅约束检查的操作
例如,如果应用程序删除具有子行的行,那么子行必须是可用的,以便删除。
- 当所提到的索引位于脱机的块中时,任何影响索引值的操作(例如,对已建立索引的列的更新)
确定何时使用数据跳过
要少用该功能且使用时要谨慎,因为该结果始终是不可靠的。可考虑在以下情况中使用该功能:
- 您可以接受事务完整性受影响。
- 您可以确定事务完整性未受影响。
后一任务可能很难且很耗时。
确定何时跳过选定的分段
在某种情况下,您可能希望数据库服务器跳过某些分段而不是其他分段。这通常会发生在以下情况中:
- 因为分段对查询结果没有重要作用,所以可以跳过这些分段。
- 某些分段脱机,并且您断定跳过这些分段并返回有限数量的数据将比取消查询要好。
当要跳过分段时,请使用 ON dbspace-list 设置来指定包含数据库服务器必须跳过的分段的数据库空间列表。
确定何时跳过所有分段
将 DATASKIP 配置参数设置为 ALL 将使数据库服务器跳过所有不可用的分段。请谨慎使用此选项。如果数据库空间变得不可用,那么在执行前未发出 SET DATASKIP OFF 语句的应用程序启动的所有查询均可能发生错误。
监视分段存储使用
数据库管理员可能会发现分段存储的以下方面对监视是有用的:
- 分段上的数据分发
- 分段上的 I/O 请求均衡
- 包含分段的块的状态
管理员可以监视表分段上的数据分发。如果分段存储的目标是提高管理响应时间,那么数据要均匀分布在分段上是很重要的。要监视分段存储磁盘使用,您必须监视数据库服务器表空间,因为分段的磁盘存储单位是表空间。(有关如何监视分段表的数据分发的信息,请参阅监视表空间和扩展数据块。)
管理员必须监视包含在分段中的数据的 I/O 请求队列。当 I/O 队列变得不平衡时,管理员必须使用 DBA 来调整分段存储策略。(有关如何监视块使用的说明,包括如何监视每个块的 I/O 队列,请参阅监视块。)
管理员必须为可用性而监视分段,并在包含一个或多个分段的数据库空间发生故障时采取适当的步骤。有关如何确定块是否脱机,请参阅监视块。
显示数据库
可以显示通过 SMI 表创建的数据库。
SMI 表
查询 sysdatabases 表以显示对应于数据库服务器管理的每个数据库的行。 有关此表中的列的描述,请参阅《GBase 8s 管理员参考》中有关 sysmaster 数据库的主题中的 sysdatabases 信息。
监视磁盘使用量
这些主题描述跟踪各种数据库服务器存储单元所使用磁盘空间的方法。
有关本节中提及的内部数据库服务器存储单元的背景信息,请参阅《GBase 8s 管理员参考》 中有关磁盘结构和存储的章节。
监视块
可以监视块,获取以下信息:
- 块大小
- 可用页数
- 块中的表
可以使用这些信息跟踪块所使用的磁盘空间、监视块 I/O 活动以及检查是否有分段存储。
onstat -d 实用程序
onstat -d 实用程序列出所有数据库空间、BLOB 空间和智能大对象空间以及以下有关这些空间中的块的信息。
- 块地址
- 块号及相关联的数据库空间号
- 设备中的偏移量(以页计)
- 块大小(以页计)
- 块中的可用页数
- 物理设备的路径名
如果您在带有 BLOB 空间块的某实例上发出 onstat -d 命令,那么所显示的可用页数是过时的。在 free 值之前的波浪号 (~) 指示该数值是大约值。在备份其中执行了删除的逻辑日志且释放 BLOB 页之后,onstat -d 命令才会将 BLOB 页注册为可用页。因此,如果删除了 25 个简单大对象并立即运行 onstat -d,onstat 输出中将不会包含新释放的空间。
要获取 BLOB 空间块中准确的可用 BLOB 页数,可发出 onstat -d update 命令。有关详细信息,请参阅 onstat -d update 选项。
在 onstat -d update 输出中,块部分的标志列提供以下信息:
- 块是主块还是镜像块
- 块是在线、脱机、正在恢复还是新块
有关 onstat -d 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
在关闭镜像之后以及镜像可活动之前,必须对根数据库空间和修改过的数据库空间执行 0 级备份。
onstat -d update 选项
onstat -d update 选项显示与 onstat -d 所显示信息相同的信息以及每个 BLOB 空间块的准确的可用 BLOB 页数。
onstat -D 选项
onstat -D 选项显示与 onstat -d 所显示信息相同的信息,另外还显示从块中读取的页数(在页读取字段中)。
使用 onstat -g iof 命令监视块 I/O 活动
可以使用 onstat -g iof 命令监视分段表的不同分段上的 I/O 请求的分布。
onstat -g iof 命令显示:
- 从每个块的读取次数和向每个块写入的次数。
- 单个操作中断的 I/0(按服务级别)
- 操作类型
- 操作发生的次数
- 完成操作所用平均时间
如果某个块具有数量与之不成比例的 I/O 活动,那么该块可能会成为系统的瓶颈。
有关 onstat -g iof 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
oncheck -pr 命令
数据库服务器将块信息存储在保留页 PAGE_1PCHUNK 和 PAGE_2PCHUNK 中。
要列出保留页的内容,请运行 oncheck -pr。以下示例显示 oncheck -pr 的样本输出。此输出基本上与 onstat -d 的输出相同;但如果块信息自上一个检查点之后更改过,那么 oncheck -pr 输出中不会包含这些更改。
Validating PAGE_1DBSP & PAGE_2DBSP...
Using dbspace page PAGE_2DBSP.
DBspace number 1
DBspace name rootdbs
Flags 0x20001 No mirror chunks
Number of chunks 2
First chunk 1
Date/Time created 07/28/2008 14:46:55
Partition table page number 14
Logical Log Unique Id 0
Logical Log Position 0
Oldest Logical Log Unique Id 0
Last Logical Log Unique Id 0
Dbspace archive status No archives have occurred
.
Validating PAGE_1PCHUNK & PAGE_2PCHUNK...
Using primary chunk page PAGE_2PCHUNK.
Chunk number 1
Flags 0x40 Chunk is online
Chunk path /home/server/root_chunk
Chunk offset 0 (p)
Chunk size 75000 (p)
Number of free pages 40502
DBSpace number 1
oncheck -pe 命令
要获取块中信息的物理布局,请运行 oncheck -pe。将列出数据库空间、BLOB 空间和智能大对象空间。以下示例显示 oncheck -pe 的样本输出。
显示以下信息:
- 数据库空间的名称、所有者和创建日期
- 块大小(以页计)、已用页数和可用页数
- 块中所有表的列表,包含初始页数和页中的表长度
按顺序列出块中的表。该输出对于确定块分段存储是有用的。如果数据库服务器无法在块中分配扩展数据块(尽管有足够的可用页数),那么该块可能会被错误地分段。
DBSpace Usage Report: rootdbs Owner: GBase 8s Created: 08/08/2006
Chunk Pathname Size Used Free
1 /home/server/root_chunk 75000 19420 55580
Description Offset Size
------------------------------------------- --------------------------
RESERVED PAGES 0 12
CHUNK FREELIST PAGE 12 1
rootdbs:'gbasedbt'.TBLSpace 13 250
PHYSICAL LOG 263 1000
FREE 1263 1500
LOGICAL LOG: Log file 2 2763 1500
LOGICAL LOG: Log file 3 4263 1500
...
sysmaster:'gbasedbt'.sysdatabases 10263 4
sysmaster:'gbasedbt'.systables 10267 8
...
Chunk Pathname Size Used Free
2 /home/server/dbspace1 5000 53 4947
Description Offset Size
------------------------------------------- ---------------------------------
RESERVED PAGES 0 2
CHUNK FREELIST PAGE 2 1
dbspace1:'gbasedbt'.TBLSpace 3 50
FREE 53 4947
Server Administrator
SMI 表
查询 syschunks 表以获取块状态。以下是相关列。
chknum
数据库空间中的块数
dbsnum
数据库空间数
chksize
总的块大小(以页为单位)
nfree
可用页数
is_offline
块是否脱机
is_recovering
块是否正在恢复
mis_offline
镜像块是否脱机
镜像块是否正在恢复
syschkio 表包含以下列。
pagesread
从块中读取的页数
pageswritten
向块中写入的页数
监视表空间和扩展数据块
监视 tblspaces 和扩展数据块按数据库、表或表分段确定磁盘使用。 当您正使用表分段存储并希望确保表数据和表索引数据适当分布在分段上之时,监视表的磁盘使用就特别重要。
运行 oncheck -pt 以获取扩展数据块信息。oncheck -pT 选项返回所有来自 oncheck -pt 选项的信息以及有关页和索引使用的其他信息。
SMI 表
查询 systabnames 表以获取有关每个表空间的信息。systabnames 表包含指示相应表、数据库和每个表空间所有者的列。
查询 sysextents 表以获取有关每个扩展数据块的信息。sysextents 表包含指示扩展数据块所属的数据库和表的列,以及扩展数据块的物理地址和大小的列。
监视 BLOB 空间中的简单大对象
监视 BLOB 空间以确定可用空间以及 BLOB 页大小是否为最佳大小。
onstat -O 选项
onstat -O 选项显示有关登台区域 BLOB 空间和 Optical Subsystem 内存高速缓存的信息。所显示的总计随会话而逐一累计。仅当运行 onstat -z 时,数据库服务器才会将总计重置为 0。
有关 onstat -O 输出的示例,请参阅《GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
显示的第一部分描述以下系统高速缓存总计信息。
列
描述
size
在 OPCACHEMAX 配置参数中指定的大小
alloc
数据库服务器分配给高速缓存的 1 KB 大小的块数
avail
未使用的 alloc 部分(以 KB 计)
number
数据库服务器成功放入高速缓存而未溢出的简单大对象数目
kbytes
数据库服务器放入高速缓存而未溢出的简单大对象的 KB 数
number
数据库服务器写入登台区域 BLOB 空间的简单大对象数目
kbytes
数据库服务器写入登台区域 BLOB 空间的简单大对象的 KB 数
虽然 size 输出指示了在配置参数 OPCACHEMAX 中指定的内存量,但是数据库服务器直至需要时才会将内存分配至 OPCACHEMAX。因此,alloc 输出仅反映已处理的最大简单大对象的 1 KB 大小的块数。当 alloc 和 avail 输出相等时,高速缓存为空。
显示的第二部分描述以下用户高速缓存总计信息。
列
描述
SID
用户的会话标识
user
客户机的用户标识
size
在 GBASEDBTOPCACHE 环境变量中指定的大小(如果已设置)
如果您未设置 GBASEDBTOPCACHE 环境变量,那么数据库服务器使用您在配置参数 OPCACHEMAX 中指定的大小。
number
数据库服务器放入高速缓存而未溢出的简单大对象数目
kbytes
数据库服务器放入高速缓存而未溢出的简单大对象的 KB 数
number
数据库服务器写入登台区域 BLOB 空间的简单大对象数目
kbytes
数据库服务器写入登台区域 BLOB 空间的简单大对象的大小(以 KB 计)
使用 oncheck -pB 确定 BLOB 页填充度
oncheck -pB 命令显示描述 Blob 页平均充满度的统计信息。如果您发现大量简单大对象的统计信息中显示的充满度百分比很低,那么更改 Blob 空间中的 Blob 页的大小会提高数据库服务器的性能。
使用数据库名称或表名作为参数运行 oncheck -pB。以下示例检索存储在 stores_demo 数据库的 sriram.catalog 表中的所有简单大对象的存储信息:
oncheck -pB stores_demo:sriram.catalog
使用 oncheck -pe 监视 BLOB 空间使用情况
oncheck -pe 命令提供了有关 BLOB 空间使用情况的信息:
- 存储 TEXT 和 BYTE 数据的表名(按块)
- 所使用的磁盘页(非 BLOB 页)数(按表)
- 剩余的可用磁盘页数(按块)
- 所用的开销页数(按块)
以下示例显示样本 oncheck -pe 输出。
BLOBSpace Usage Report: fstblob Owner: GBase 8s Created: 03/01/08
Chunk: 3 /home/server/blob_chunk Size Used Free
4000 304 3696
Disk usage for Chunk 3 Total Pages
----------------------------------------------------- ----------------------
OVERHEAD 8
stores_demo:chrisw.catalog 296
FREE 3696
使用 oncheck -pT 监视数据库空间中的简单大对象
使用 oncheck -pT 可监视数据库空间来确定 TEXT 和 BYTE 数据使用的数据库空间的页数。
此命令采用数据库名称或表名作为参数。对于数据库中的每个表,或对于特定表,数据库服务器显示常规表空间报告。
常规报告之后是扩展数据块中页使用的详细分类(按页类型)。请参阅 Type 列以获取有关 TEXT 和 BYTE 数据的信息。
数据库服务器可以将一个以上的简单大对象存储在同一 BLOB 页上。因此,可对表空间中存储 TEXT 或 BYTE 数据的页数计数,但无法估计表中简单大对象的数目。
以下示例显示样本输出。
TBLSpace Usage Report for mydemo:chrisw.catalog
Type Pages Empty Semi-Full Full Very-Full
---------------- ------------- ---------- ---------- ---------- ----------- Free 7
Bit-Map 1
Index 2
Data (Home) 9
Data (Remainder) 0 0 0 0 0
Tblspace BLOBs 5 0 0 1 4
-------------
Total Pages 24
Unused Space Summary
Unused data bytes in Home pages 3564
Unused data bytes in Remainder pages 0
Unused bytes in Tblspace Blob pages 1430
Index Usage Report for index 111_16 on mydemo:chrisw.catalog
Average Average
Level Total No. Keys Free Bytes
-------- -------- ----------- --------------
1 1 74 1058
-------- -------- ----------- --------------
Total 1 74 1058
Index Usage Report for index 111_18 on mydemo:chrisw.catalog
Average Average
Level Total No. Keys Free Bytes
-------- -------- ----------- --------------
1 1 74 984
-------- -------- ----------- --------------
Total 1 74 984
监视智能大对象空间
要在智能大对象空间中监视的最重要的区域之一是元数据页使用。在创建智能大对象空间时,您指定元数据区域的大小。而且,每次向智能大对象空间添加块时,您可以指定要添加至块的元数据空间。
如果您尝试插入新的智能大对象,但没有可用的元数据空间,就会接收到一个错误。管理员必须监视元数据空间可用性以防止此情况发生。
使用以下命令监视智能大对象空间。
| 命令 | 描述 |
|---|---|
| onstat -g smb s | 显示系统中所有智能大对象空间的存储属性: ● 智能大对象空间名称、标志、所有者 ● 日志记录状态 ● 平均智能大对象大小 ● 第一个扩展数据块大小、下一个扩展数据块大小和最小扩展数据块大小 ● 最大 I/O 存取时间 ● 锁定方式 |
| onstat -g smb c | 显示以下有关每个智能大对象空间的信息: ● 块数和智能大对象空间名称 ● 块大小和路径名 ● 用户数据页和可用用户数据页的总数 ● 每个用户数据和元数据区域中的页的位置和数量 |
| oncheck -ce oncheck -pe | 显示以下有关智能大对象空间使用的信息: ● 存储智能大对象数据的表名(按块) ● 所使用的磁盘页(非智能大对象页)数(按表) ● 剩余的可用用户数据页数(按块) ● 剩余的保留用户数据页数(按块) ● 所使用的元数据页数(按块) 输出提供以下总计: ● 所有用户数据区域和元数据区域的已用页的总数。系统向用户数据区域和元数据区域的总计添加了 53 页以用于保留区域。 ● 在元数据区域中剩余的可用页数 ● 在所有用户数据区域中剩余的可用页数 |
| onstat -d | 显示以下有关每个智能大对象空间中的块的信息: ● 在元数据区域和在用户数据区域中的每个智能大对象空间块中的可用智能大对象页数 ● 在元数据区域和在用户数据区域中的每个智能大对象空间块中的总智能大对象页数 |
| oncheck -cs oncheck -ps | 验证并显示有关智能大对象空间的元数据区域的信息。 |
| oncheck -cS | 显示有关智能大对象空间的智能大对象扩展数据块和用户数据区域的信息。 |
| oncheck -pS | 显示有关智能大对象空间的智能大对象扩展数据块、用户数据区域和元数据区域的信息。 |
onstat -d 选项
使用 onstat -d 选项显示以下有关每个智能大对象空间中块的信息:
- 在元数据区域和在用户数据区域中的每个智能大对象空间块中的可用智能大对象页数
- 在元数据区域和在用户数据区域中的每个智能大对象空间块中的总智能大对象页数
有关 onstat -d 输出的示例,请参阅*《*GBase 8s 管理员参考》中有关 onstat 实用程序的信息。
要查明已使用空间的总量,请运行 oncheck -pe 命令。有关更多信息,请参阅 oncheck -ce 和 oncheck -pe 选项。
在备份执行删除的逻辑登录且释放智能大对象页之后,onstat -d 命令才会将智能大对象页注册为可用页。因此,如果删除了 25 个智能大对象并立即运行 onstat -d,onstat 输出中将不会包含新释放的空间。
oncheck -ce 和 oncheck -pe 选项
运行 oncheck -ce 可显示用户数据区域中每个智能大对象空间块的大小、已使用空间的总量和可用空间量。oncheck -pe 选项显示与 oncheck -ce 所显示信息相同的信息,另外还显示块使用的详细列表。首先列出数据库空间,然后列出智能大对象空间。-pe 输出提供以下有关智能大对象空间使用的信息:
- 存储智能大对象数据的表名(按块)
- 所使用的磁盘页(非智能大对象页)数(按表)
- 剩余的可用用户数据页数(按块)
- 所使用的元数据页数(按块)
输出提供以下总计:
- 用户数据区域、元数据区域和保留区域的已用页的总数。
系统向用户数据区域和元数据区域的总计添加了额外的 53 页以用于保留区域。
- 在元数据区域中剩余的可用页数
- 在用户数据区域中剩余的可用页数
oncheck -pe 选项以数据库服务器页的形式提供了有关智能大对象空间的使用情况的信息,而非智能大对象页的形式。
以下示例显示样本输出。在该示例中,智能大对象空间 s9_sbspc 的已用总页数为 214、元数据区域中的可用页数为 60 以及用户数据区域的可用页数为 726。
Chunk Pathname Size Used Free
2 /ix/ids9.2/./s9_sbspc 1000 940 60
Description Offset Size
-------------------------------------------------- ---------- ----------
RESERVED PAGES 0 2
CHUNK FREELIST PAGE 2 1
s9_sbspc:'gbasedbt'.TBLSpace 3 50
SBLOBSpace LO [2,2,1] 53 8
SBLOBSpace LO [2,2,2] 61 1
...
SBLOBSpace LO [2,2,79] 168 1
SBLOBSpace FREE USER DATA 169 305
s9_sbspc:'gbasedbt'.sbspace_desc 474 4
s9_sbspc:'gbasedbt'.chunk_adjunc 478 4
s9_sbspc:'gbasedbt'.LO_hdr_partn 482 8
s9_sbspc:'gbasedbt'.LO_ud_free 490 5
s9_sbspc:'gbasedbt'.LO_hdr_partn 495 24
FREE 519 60
SBLOBSpace FREE USER DATA 579 421
Total Used: 214
Total SBLOBSpace FREE META DATA: 60
Total SBLOBSpace FREE USER DATA: 726
Chunk Pathname Size Used Free
2 /ix/ids9.2/./s9_sbspc 1000 940 60
Description Offset Size
-------------------------------------------------- ---------- ----------
RESERVED PAGES 0 2
CHUNK FREELIST PAGE 2 1
s9_sbspc:'gbasedbt'.TBLSpace 3 50
SBLOBSpace LO [2,2,1] 53 8
SBLOBSpace LO [2,2,2] 61 1
...
SBLOBSpace LO [2,2,79] 168 1
SBLOBSpace FREE USER DATA 169 305
s9_sbspc:'gbasedbt'.sbspace_desc 474 4
s9_sbspc:'gbasedbt'.chunk_adjunc 478 4
s9_sbspc:'gbasedbt'.LO_hdr_partn 482 8
s9_sbspc:'gbasedbt'.LO_ud_free 490 5
s9_sbspc:'gbasedbt'.LO_hdr_partn 495 24
FREE 519 60
SBLOBSpace FREE USER DATA 579 421
Total Used: 214
Total SBLOBSpace FREE META DATA: 60
Total SBLOBSpace FREE USER DATA: 726
可以将 CHECK EXTENTS 用作与 oncheck -ce 等同的 SQL 管理 API 命令。有关使用 SQL API 命令的信息,请参阅使用 SQL 管理 API 执行远程管理和《GBase 8s 管理员参考》。
oncheck -cs 选项
oncheck -cs 和 oncheck -Cs 选项验证智能大对象空间的元数据区域。下面显示了 s9_sbspc 的 -cs 输出的一个示例。如果不在命令行上指定智能大对象空间名称,那么oncheck 会检查和显示所有智能大对象空间的元数据。
使用 oncheck -cs 输出来查看在元数据区域中留下的空间量。如果该区域已满,那么为元数据区域分配另一具有足够空间的块。要查明元数据区域中的已用页数,可将 Used 列中的数值进行总计。 要查明元数据区域中的可用页数,可将 Free 列中的数值进行总计。
例如,根据下图中显示的字段值,s9_sbspc 的元数据区域中的已用总页数为 33 个 2 KB 大小的页(或 66 KB)。元数据区域包含的可用总页数为 62(或 124 KB)。
Validating space 's9_sbspc' ...
SBLOBspace Metadata Partition Partnum Used Free
s9_sbspc:'gbasedbt'.TBLSpace 0x200001 6 44
s9_sbspc:'gbasedbt'.sbspace_desc 0x200002 2 2
s9_sbspc:'gbasedbt'.chunk_adjunc 0x200003 2 2
s9_sbspc:'gbasedbt'.LO_hdr_partn 0x200004 21 11
s9_sbspc:'gbasedbt'.LO_ud_free 0x200005 2 3
oncheck -ps 选项
oncheck -ps 选项验证并显示有关智能大对象空间分区中元数据区域的信息。下面显示了 s9_sbspc 的 -ps 输出的一个示例。如果您未在命令行中指定智能大对象空间名称,那么 oncheck 验证并显示所有存储空间的表空间信息。
要监视可用元数据空间量,请运行以下命令:
oncheck -ps spacename
-ps 输出包含有关元数据区域中的锁定粒度、partnum、已分配和已使用的页数、扩展数据块大小以及行数。使用 oncheck -ps 输出来查看在元数据区域中留下的空间量。如果该区域已满,那么为元数据区域分配另一具有足够空间的块。
如果您为包含存储了智能大对象的表的数据库空间运行 oncheck -ps,那么可查明表中的行数。
Validating space 's9_sbspc' ...
TBLSpace Report for
TBLspace Flags 2801 Page Locking
TBLspace use 4 bit bit-maps
Permanent System TBLspace
Partition partnum 0x200001
Number of rows 92
Number of special columns 0
Number of keys 0
Number of extents 1
Current serial value 1
First extent size 50
Next extent size 50
Number of pages allocated 50
Number of pages used 6
Number of data pages 0
Number of rows 0
Partition lockid 2097153
Optical Cluster Partnum -1
Current SERIAL8 value 1
Current REFID value 1
Created Thu May 24 14:14:33 2007
监视元数据和用户数据区域
数据库服务器保留 40% 的用户数据区域作为保留区域。数据库服务器将该保留空间用于元数据或用户数据。元数据区域在向该智能大对象空间添加智能大对象时被耗尽。当数据库服务器耗尽元数据或用户数据空间时,它会将一块保留空间移至相应区域。
当所有的保留区域均用尽时,即使用户数据区域包含可用空间,数据库服务器也无法移动空间至元数据区域。
-
当您将智能大对象添加到智能大对象空间时,请使用 oncheck -pe 或 onstat -g smb c 监视元数据区域、用户数据区域和保留区域中的空间。
有关示例,请参阅 oncheck -ce 和 oncheck -pe 选项。
数据库服务器打印有关从保留区域分配至元数据区域的页数消息。
-
在智能大对象空间耗尽元数据和保留区域中空间之前向智能大对象空间添加另一个块。
有关更多信息,请参阅向智能大对象空间添加块。
-
数据库服务器在将空间从保留区域移至元数据或用户数据区域时编写 FREE_RE 和 CHKADJUP 日志记录。
有关更多信息,请参阅计算智能大对象空间元数据的大小。
存储优化
数据压缩和合并方法可将数据所用磁盘空间降到最低。
下表描述可用于减小数据所用磁盘空间量的方法。
表 1. 存储优化方法
| 存储优化方法 | 用途 | 何时使用 |
|---|---|---|
| 压缩数据 | 压缩表或分段行中的数据,从而减小所需磁盘空间量 压缩数据之后,还可以合并表或分段中剩余的可用空间,并将这些可用空间返还给数据库空间。 | 希望减少表中的数据大小时 |
| 重新打包数据 | 合并表和分段中的可用空间 | 压缩数据之后,或希望单独合并表或分段中的可用空间时 |
| 收缩数据 | 将可用空间返还给数据库空间 | 压缩或重新打包数据之后,或希望单独将可用空间返还给数据库空间时 |
| 为表扩展数据块取消分段 | 使邻接的合并扩展数据块中的数据行靠得更紧密 | 经常更新的表在多个非邻接扩展数据块之间变得分散时 |
可自动执行以上任意一个或所有方法。
可在 SQL 管理 API 函数进行编程来执行这些方法。
自动优化数据存储
可通过更新 auto_crsd 调度程序任务,为表和扩展数据块配置自动压缩、收缩、重新打包和取消分段。
必须以用户 gbasedbt 或其他授权用户身份连接 sysadmin 数据库。
要启用和配置自动存储优化,请执行以下操作:
-
通过在 ph_task 表上使用 UPDATE 语句将 tk_enable 列的值设置为 T,从而启用 auto_crsd 调度程序任务。例如,以下语句启用 auto_crsd 任务:
UPDATE ph_task
SET tk_enable = 'T'
WHERE tk_name = 'auto_crsd'; -
可选:通过在 ph_threshold 表上使用 UPDATE 语句来将阈值的 value 列设置为 F,从而禁用单个操作:
- AUTOCOMPRESS_ENABLED:控制压缩
- AUTOREPACK_ENABLED:控制重新打包
- AUTOSHRINK_ENABLED:控制收缩
- AUTODEFRAG_ENABLED:控制取消分段
例如,以下语句只禁用 auto_crsd 任务的取消分段存储操作:
UPDATE ph_threshold
SET value = 'F'
WHERE name = 'AUTODEFRAG_ENABLED'; -
可选:通过在 ph_threshold 表上使用 UPDATE 语句来更改阈值的 value 列的值,从而更改单个操作的阈值:
- AUTOCOMPRESS_ROWS:压缩的阈值是未压缩行数。缺省阈值为 10 000 行。在未压缩行数超过 10 000 时,将压缩表。
- AUTOREPACK_SPACE:重新打包的阈值为非邻接空间的百分比。缺省值为 90%。在表占用的空间中 90% 以上的空间非连续时,将重新打包该表。
- AUTOSHRINK_UNUSED:表或分段的收缩阈值是已分配的未用空间的百分比。缺省值为 50%。在 50% 以上的已分配空间未被使用时,将收缩表或分段。
- AUTODEFRAG_EXTENTS:表或分段扩展数据块的取消分段阈值是扩展数据块的数量。缺省值为 100。在扩展数据块的数量超过 100 时,将对表或分段执行取消分段操作。
例如,以下语句将压缩阈值更改为 5000 行:
UPDATE ph_threshold
SET value = '5000'
WHERE name = 'AUTOCOMPRESS_ROWS';
或者,除了运行已调度的自动压缩任务之外,还可以通过 SQL 管理 API create dictionary 命令或初始 compress 命令来启用自动压缩。对表或表分段运行 SQL 管理 API create dictionary 命令或初始 compress 命令时,将启用后续数据装入(包含 2000 行或更多行数据)的自动压缩。
您还可以使用 CREATE TABLE 语句的 COMPRESSED 选项来支持在将数据装入表或表分段时对大量行内数据执行自动压缩。CREATE TABLE 语句的 COMPRESSED 选项不支持对数据库空间或索引中的简单大对象执行自动压缩。
对分区取消分段
可以通过对分区取消分段以将非邻接的扩展数据块合并,从而提高性能。
随着时间推移,经常更新的表可能变为分段表,从而当服务器每次访问表时,导致性能下降。对表取消分段可使数据行更紧密的集合在一起,并避免分区标题页溢出问题。对索引取消分段会让条目更集中,这会提高存取表信息的速度。
要确定表、索引或分区有多少扩展数据块,可运行 oncheck -pt and pT 命令。
要为表、索引或分区取消分段,请运行带 defragment 自变量或 defragment partnum 自变量的 SQL 管理 API task() 或 admin() 函数,并指定要取消分段的表名、索引或分区号。
限制和注意事项
对分区取消分段之前,请查看以下重要注意事项:
- 提交取消分段请求之后,无法停止该请求。
- 不能为以下对象取消分段:
- 伪表,如虚拟表接口 (VTI) 表
- 包含虚拟索引接口 (VII) 索引的表
- 包含 B 型树函数索引的表
- 临时表
- 排序文件
- 光盘 BLOB 文件
- 不得对要取消分段的表或分区发出冲突操作。必须先完成第一个操作,再启动第二个操作。如果第一个操作仍在运行,对第二个操作的请求将返回错误。以下列表中包含冲突操作示例:
- 一个分区一次只能运行一个取消分段请求。
- 一个数据库空间一次只能运行一个取消分段请求。
- 如果表或分区上正在运行 DROP TABLE 或 ALTER FRAGMENT 之类的 DDL 语句,那么不能为表取消分段。
- 不能为正在截断的表取消分段。
- 不能为正在压缩或解压缩的表取消分段。
- 不能为正在运行在线索引构建的表取消分段。
- 不能为设置了互斥存取的表取消分段。
如果完成取消分段请求时发生问题,将向联机日志文件发送错误消息。
数据压缩
可以压缩和解压缩表与分段中的行数据和/或数据库空间中的简单大对象。可以压缩表与表分段中的数据,以减少占用的磁盘空间量。还可以合并表或分段中的可用空间,然后将这些可用空间返还给数据库空间。 压缩数据之前,可估计可以节省的磁盘空间量。
压缩数据、整合数据以及返还可用空间具有以下益处:
- 显著节省磁盘存储空间
- 减少压缩的分段的磁盘使用量
- 显著节省逻辑日志使用量,这样在完成压缩操作后可节省额外空间并可以防止高吞吐量 OLTP 的瓶颈。
- 页面读取更少,因为更多行可以置于一个页面中
- 缓冲池更小,因为更多数据置于同一大小的池中
- I/O 活动减少,因为:
- 与未压缩行相比,更多压缩行置于一个页面中
- 压缩行的插入、更新和删除操作的日志记录更小
- 可以压缩按时间分段数据的不常访问的较旧分段,而让频繁访问的更多近期数据处于未压缩的格式
- 可以释放表不再需要的空间
- 备份与复原更快
I/O 绑定表(例如,高速缓存命中率低的表)非常适合压缩。在 OLTP 环境中,压缩 I/O 绑定表可以提高性能。
但是,如果应用程序运行时具有很高的缓冲区高速缓存命中率,并且高性能比空间使用量更重要,那么可能不希望压缩数据,因为压缩可能会稍微降低性能。
查询可以访问压缩表中的数据。
由于与未压缩数据相比,压缩的数据占用更少页面且每页中有更多行,所以查询优化器可能在压缩后选择不同的计划。
如果使用 Enterprise Replication (ER),那么压缩一个复制服务器上的数据不会影响其他任何复制服务器上的数据。
如果使用高可用性数据复制 (HAC),源表中的压缩数据在目标表中也处于压缩状态。不能在 HAC 辅助服务器、RS 辅助服务器或 SD 辅助服务器上执行压缩操作,因为 HAC 目标服务器必须具有与源服务器相同的数据和物理布局。
不能使用 onload 和 onunload 实用程序将压缩后的数据从一个数据库移至另一个数据库。在使用 onload 和 onunload 实用程序之前,您必须将压缩表和分段中的数据解压缩。
可通过运行包含带有压缩参数的 SQL 管理 API 命令的 SQL 语句来执行这些操作。 对表或表分段运行 SQL 管理 API create dictionary 命令或初始 compress 命令时,将启用后续数据装入(包含 2000 行或更多行数据)的自动压缩。
在 GBase 8s V8.8 中,必须运行启用压缩的 SQL 管理 API 命令才可以对表或分段进行压缩。 如果启用了压缩,那么必须遵循以下 GBase 8s 还原过程,以更改回没有数据压缩功能的服务器版本,并且必须解压缩或删除任何压缩表和分段。
取代压缩的主要方法是购买更多物理存储器。取代减少 IO 绑定工作负载内的瓶颈的主要方法是购买更多物理内存,以便扩展缓冲池。
可压缩的数据
可以压缩行中的数据以及数据库空间中的简单大对象。但是,您可能并不希望压缩可压缩的所有类型的数据。
具有经常重复的长模式的表或表分段数据非常适合压缩。特定类型的数据(如文本)可能比其他类型的数据(如数字数据)更适合压缩,因为文本之类的数据类型可能包含更长、更频繁重复的模式。
但是,不能仅根据数据类型来预测压缩率。例如:
- 不同语言或字符集的文本的压缩率可能不同,即使文本存储在 CHAR 或 VARCHAR 列中也是如此。
- 大部分由零构成的数字数据压缩率可能很高,而可变数字数据较多则压缩率可能不高。
- 具有大量空格的数据压缩率较高
- 已使用其他某种算法压缩的数据和已加密的数据的压缩率可能不高。例如,行中的图像和声音采样可能已经压缩,因此再次压缩这些数据不会再额外节省任何空间。
GBase 8s 可压缩任意数据类型的组合,因为它将所有数据视为未结构化的字节序列来压缩。因此,服务器可以压缩跨多个列的模式,如城市、州和邮政编码的组合。(服务器对字节序列的解压缩顺序与数据压缩之前存在的顺序相同。)
可以压缩:
- 数据行的内容,包括跨多页的行的任何剩余片段,以及包含在逻辑日志记录中的行的映像。
- 数据库空间中的简单大对象(例如,XML 文件、PDF 文件或其他包含文本的文档)
压缩仅应用于数据行的内容,包括跨多页的行的剩余片段,以及包含在逻辑日志记录中的行的映像。
不能压缩的数据
不能压缩某些类型的表和分段中的行数据。不能压缩索引中的数据,也不能压缩某些类型的表和分段中的数据。
不能压缩以下对象的行中的数据:
- sysmaster、sysutils、sysuser、syscdr 和 syscdcv1 数据库中的表或分段
- 目录
- 临时表
- 虚拟表接口表
- 表空间 tblspace(这些是隐藏分段,每个数据库空间一个隐藏分段。每个表包含有关数据库空间内所有分段的元数据。)
- 内部分区表
- 字典表,每个数据库空间一个字典表(这些表包含该数据库空间内已压缩的分段或表的压缩字典,以及有关这些字典的元数据。)
- 索引
- 在其中正在执行在线索引构建的表
也不能压缩 BLOB 空间中的简单大对象。
不会将压缩应用于索引数据、存储在行外的 LOB 数据,或其他任何形式的非行数据。
加密的数据、已经通过其他算法压缩的数据,以及没有长重复模式的数据压缩效果不佳或不压缩。 请尽量不要将包含压缩效果不佳的数据的列放在具有常用模式的列之间,以防止跨列模式的可能损坏。
如果存储 XML 数据时将第一部分放在行中,将其余部分放在该行外,那么压缩将仅应用于存储在行中的数据。
仅当压缩行的映像小于未压缩映像时,GBase 8s 才会压缩行的映像。即便压缩后的行仅比其未压缩映像稍小,但节省的少量空间也可以让服务器在页中放入更多行。
压缩估算
压缩表或表分段之前,可估算压缩数据后将可节约的空间量。显示的比率根据行数据的样本估算。实际节约的空间比率可能稍有不同。
GBase 8s 通过以下方法估算压缩率:对行数据随机采样(使用与字典构建相同的采样算法),然后计算以下项的大小总和:
- 未压缩行映像
- 使用新压缩字典(由估算压缩命令临时创建的压缩字典)得到的压缩行映像
- 使用存在的现有字典得到的压缩行映像(如果没有现有字典,该值将与未压缩行映像的大小之和相同。)
获得的空间实际节约比率可能由于以下原因而有所差异:
- 发生了较小的采样错误。
- 估算是基于行的原始压缩能力。
例如,服务器通常尝试将整个行放入一页中。因此,如果每个未压缩行几乎填满一整页,并且压缩率低于 50%,那么每个压缩行仍将填满大半页,而即使在压缩之后,服务器仍倾向于将每行放在单独的一页上。在这种情况下,尽管估算的压缩率可能为 45%,实际节约的空间则可能为 0%。
每个未压缩行填充页的一半稍多。每个未压缩行将占用一整页,因为两个整行的总大小已超出一页。 例如,估算的压缩率可能为 5%,但是该压缩率可能刚够将每个行收缩到小于半页。所以,压缩之后,两行可放入一页,实际节约的空间可能为 50%。
实际获得的压缩可能与估算不一样,因为 GBase 8s 在一页中存储的行数不能超过 255。所以小行或大页会减少压缩可获得的节约总量。 例如,如果压缩前一页中有 200 行,无论压缩后行有多小,最大有效压缩率均接近 20%,因为压缩后一页中只能有 255 行。
如果使用的页面大于最小页大小,那么可通过切换到更小的页来增加实现的压缩空间节约量,从而:
- 不再达到 255 行的限制。
- 如果仍然达到了该限制,页中的未使用空间将更少。
如果压缩操作包含重新打包操作、收缩操作或重新打包并收缩操作,那么可节约更多(或更少)空间。仅当一页中的压缩行数超过了未压缩行数,重新打包操作才能节约更多空间。如果重新打包操作释放出空间,那么收缩操作可以在数据库空间级别节约空间。
压缩数据和存储优化的图示
本主题中的图示显示使用分段中大部分空间的未压缩数据、压缩数据时创建的可用空间、执行重新打包操作之后移动到分段末尾的可用空间,以及执行收缩操作之后留在分段中的数据。
图: 压缩和存储优化处理期间分段中的数据
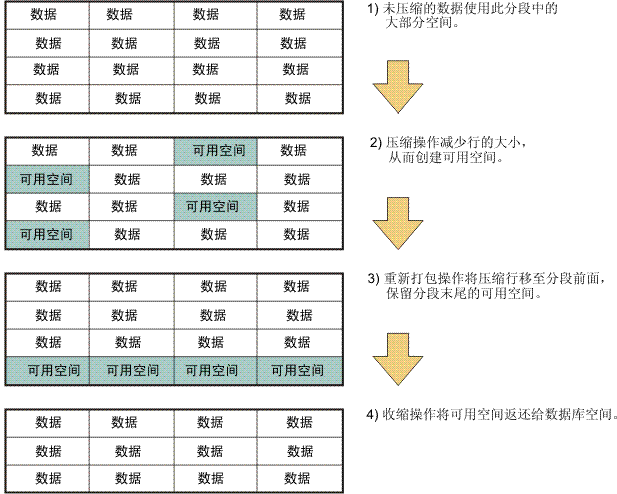
压缩和解压缩数据
此方案显示如何运行 SQL 管理 API 命令来管理压缩和存储优化。
在该方案中,用户 mario 所有的数据库 music 内有一个表 rock。
先决条件:
-
表的每个分段中必须至少有 2000 行,而不仅是整个表总共只有 2000 行。
-
您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
-
如果希望运行的任何工作负载(包括但不限于压缩操作)耗用日志文件的速度超过每 30 秒一个文件,那么必须将日志配置为比当前大小更大。
-
如果希望运行的任何工作负载(包括但不限于这些压缩操作)耗用日志文件的速度超过每 30 秒一个文件,请将日志配置为比当前大小更大。compress、repack、repack_offline、uncompress 和 uncompress_offline 操作可能会耗用大量日志。
-
如果在使用 GBase 8s,必须先启用压缩,才能压缩数据。要启用压缩,请运行以下命令:
EXECUTE FUNCTION task("enable compression");无需启用压缩,即可使用 estimate_compression 自变量估算压缩数据可节约的空间量。如果要使用 shrink、repack 或 repack_offline自变量在不压缩任何行数据的情况下从表中释放空间,也无需启用压缩。
要同时压缩行数据以及数据库空间中的简单大对象:
要压缩和解压缩行数据,请执行以下操作:
-
不确定是否要压缩 rock 表,那么可以运行以下命令来检查压缩该表可节约的空间量:
EXECUTE FUNCTION task("table estimate_compression", "rock", "music", mario");复审生成的报告,其中指示可为 rock 表当前使用的空间节约 75%。您决定压缩表。
-
压缩数据之前,希望创建压缩字典,其中包含 GBase 8s 用于压缩 rock 表中的数据的信息。运行以下命令
EXECUTE FUNCTION task("table create_dictionary", "rock", "music", "mario");如果不作为单独的步骤来创建压缩字典,GBase 8s 将在您压缩数据时自动创建字典。
-
您决定要压缩 rock 表中的数据以及数据库空间中的简单大对象,合并这些数据,然后将可用空间返还给数据库空间。 可以运行以下命令:
EXECUTE FUNCTION task("table compress repack shrink", "rock", "music", "mario");如果决定仅压缩行数据或仅压缩数据库空间中的简单大对象,请通过将 rows 或 blobs 插入到单词 compress 之后或字符串 compress repack shrink 之后来调整命令。例如:
-
要仅压缩行数据,请指定:
EXECUTE FUNCTION task("table compress rows","rock","music","mario"); -
要仅压缩行数据,然后重新打包和收缩数据,请指定:
EXECUTE FUNCTION task("table compress repack shrink rows","rock","music","mario"); -
要仅压缩数据库空间中的简单大对象,请指定:
EXECUTE FUNCTION task("table compress blobs","rock","music","mario");
压缩现有行和简单大对象之后,GBase 8s 会合并表末尾留下的可用空间,然后从表中除去这些可用空间,从而将该空间返还给数据库空间。
如果简单大对象或行 /* 在压缩后并不会变小,那么数据库服务器不会对其进行压缩。
-
-
现在假设必须解压缩数据。可以运行以下命令:
EXECUTE FUNCTION task("table uncompress", "rock", "music", "mario"); -
您希望除去压缩字典。
-
验证 Enterprise Replication 是否不需要该字典。
如果 Enterprise Replication 确实需要这些已解压缩或已删除的表和分段的压缩字典,请勿除去这些字典。
-
归档其中包含带有压缩字典的表或分段的数据库空间。
-
运行以下命令:
EXECUTE FUNCTION task("table purge_dictionary", "rock", "music", "mario");
-
按照压缩和解压缩行中数据以及数据库空间中简单大对象的相同方式来压缩和解压缩表分段中的数据以及数据库空间中的简单大对象,但是不同之处在于,运行的命令具有以下格式:
EXECUTE FUNCTION task("fragment compression_arguments", "partnum_list");
如果要在不执行压缩或重新压缩的情况下合并可用空间或返还可用空间,可运行一个命令,指示服务器重新打包、收缩或重新打包并收缩。
启用压缩
在 GBase 8s V8.8 中,必须先运行用于启用压缩的 SQL 管理 API admin() 或 task()命令,才能对实例中的表或表分段执行首次压缩或解压缩操作。
在 GBase 8s V8.8 中,压缩将自动启用。
您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
但是,在启用压缩之前,可以估算压缩率、合并可用空间(重新打包)和将可用空间返还给表或分段(收缩)。
要启用压缩,请执行以下操作:
运行带 enable compression 自变量的 admin() 或 task() 函数。
例如,指定:
EXECUTE FUNCTION task(“enable compression”);
启用压缩之后,可创建压缩字典,或者也可以压缩表的行或者分段表的特定分段或所有分段的行。
估算压缩率
如果压缩表或者分段表的特定分段或所有分段,可估算可节约的空间百分比。该命令将显示可用于确定是否要压缩或重新压缩行数据的信息。
先决条件:您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
用于估算压缩率的命令总是同时估算新压缩率和当前压缩率。
有关压缩率和估算的一般信息,请参阅压缩率和压缩估算。
要估算压缩的优点,请执行以下操作:
运行带 estimate_compression 自变量的 admin() 或 task() 函数。
例如,为表使用以下语法:
EXECUTE FUNCTION task(“table estimate_compression", “table_name”, “database_name”, “owner_name”);
对于分段,请使用以下语法:
EXECUTE FUNCTION task(“fragment estimate_compression”“partnum_list”);
以下示例显示了这样的一个命令:指示 GBase 8s 估算所有者为“wong”的“store123”数据库内名为“cash_transaction”的表的压缩优点。
EXECUTE FUNCTION task("table estimate_compression", "cash_transaction", "store123", "wong");
估算压缩操作显示可实现的估算压缩率、当前压缩率、对获得或失去的百分比的估算、每个分段的分区号,以及表的全名,包括数据库、所有者和表名。如果表未压缩,那么当前比率为 0.0%。
在以下示例中,已经压缩了第一个分段。未压缩第二个分段。如果重新压缩第一个分段,可以节约的空间会增加 0.4%。如果压缩第二个分段,可以增加 75.7%。
est curr change partnum coloff table
-------- ------------ ----------- --------------- -------- -------------------------------------
75.7% 75.3% +0.4 0x00200003 -1 store3:wg.cash_transaction
75.7% 0.0% +75.7 0x00300002 -1 store3:wg.cash_transaction
est curr change partnum table
--------- -------- -------- ------------------ ----------------------------------------------
75.7% 75.3% +0.4 0x00200003 store123:wong.cash_transaction
75.7% 0.0% +75.7 0x00300002 store123:wong.cash_transaction
表和分段的压缩估算输出看起来几乎相同,不同之处在于表的输出始终显示表中的所有分段,而分段的输出仅显示指定分段的信息。
创建压缩字典
可根据现有行创建压缩字典,以供 GBase 8s 压缩表或表分段中的数据时使用。创建字典之后,GBase 8s 将使用该字典来压缩新插入或更新的行。
如果没有压缩字典,您也可以在运行压缩命令时创建。这两个命令的唯一差别是压缩命令还将压缩表或分段中的现有数据。
如果数据已装入表中,并且您要创建字典以用于在装入数据时压缩新数据,那么可以为该表创建压缩字典。
该表或分段必须至少包含 2000 行数据,然后数据库服务器才能创建压缩字典。如果创建字典时,表或分段没有足够的数据用于字典,那么该表或分段将设置为自动压缩。然后,在该表或分段中装入了足够的数据后,数据库服务器将自动创建该字典。
有关压缩字典的一般信息,请参阅压缩字典。
先决条件:
- 您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
- 如果要为分段创建压缩字典,分段中必须至少包含 2,000 行。如果要为表创建压缩字典,该表的每个分段必须至少包含 2,000 行。
要创建压缩字典,请执行以下操作:
运行带 table create_dictionary 或 fragment create_dictionary 自变量的 admin() 或 task() 函数。
例如:
-
为表指定信息,如下所示:
EXECUTE FUNCTION task(“table create_dictionary”, “table_name”,“database_name”, “owner_name”);必须指定表名。数据库和所有者名称可选。如果不指定数据库或所有者名称,GBase 8s 将使用当前数据库和所有者名称。
-
为分段指定信息,如下所示:
EXECUTE FUNCTION task(“fragment create_dictionary”, partnum_list”);partnum_list 列出了分区号,以空格分隔。
以下示例显示了这样的一个命令:指示 GBase 8s 为所有者为“shakar”的“music”数据库内名为“classical”的表创建压缩字典。
EXECUTE FUNCTION task("table create_dictionary","classical","music","shakar");
要在创建压缩字典之后压缩现有表或分段行中的数据,必须运行压缩命令。
只有在解压缩表或分段之后,才能删除压缩字典。
合并表中的可用空间
压缩表或分段时,可以合并(重新打包)表和分段中的可用空间,或单独合并可用空间,而不进行压缩。
可以使用 repack 或 repack_offline 自变量,以在线或脱机方式执行重新打包操作。repack_offline 操作与 repack 操作相同,但当 GBase 8s 在表或分段上持有互斥锁定期间执行操作时例外。 此操作在完成之前,会阻止对数据的所有其他访问。
如果执行 repack 操作时在表或分段中进行了轻量级追加,那么 repack 操作不会在表或分段的末尾完成空间合并。repack 操作无法完成的原因是,在已执行了 repack 操作的位置中添加了新的扩展数据块,因此空间无法返还给数据库空间。要完成 repack 进程,必须在完成轻量级追加活动之后,再运行一次 repack 操作。第二次运行的 repack 操作将在第一次 repack 操作工作的基础上构建。
完成 repack_offline 操作之前删除或禁用索引可以缩短服务器完成此操作所用时间量。之后,可以重新创建或重新启用索引,最好是利用 PDQ。先删除或禁用索引,再重新创建或启用索引,要比不这样做而直接完成 repack_offline 操作的速度更快。
先决条件:
- 您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
- 如果希望运行的任何工作负载(包括但不限于 repack 或 repack_offline 操作)耗用日志文件的速度超过每 30 秒一个文件,请将日志配置为比当前大小更大。
要合并表中的可用空间,请执行以下操作:
-
运行使用 table repack、table repack_offline、fragment repack 或 fragment repack_offline 命令自变量的 admin() 或 task() 函数。
例如,为表指定:
EXECUTE FUNCTION task(“table repack”, “_table_name_”,“_database_name_”, “_owner_name_”);必须指定表名。数据库和所有者名称可选。 如果不指定数据库或所有者名称,GBase 8s 将使用当前数据库和所有者名称。
例如,为分段指定:
EXECUTE FUNCTION task(“fragment repack*offline”, “\_partnum_list*”);partnum_list 是属于同一个表的分区号的空格分隔列表。
-
(可选)扩展自变量以在以下任意组合中包含 compress 和 shrink:
- compress repack
- compress repack shrink
- repack shrink
以下示例显示了这样的一个命令:指示 GBase 8s 合并所有者为“bob”的一个“music”数据库中名称为“opera”的表中的可用空间。
EXECUTE FUNCTION task("table repack","opera","music","bob");
以下示例显示了这样的一个命令:指示 GBase 8s 以脱机方式合并所有者为“bob”的一个“music”数据库中名称为“folk”的表中的可用空间。
EXECUTE FUNCTION task("table repack_offline","folk","music","janna");
以下示例显示这样的一个命令:指示 GBase 8s 合并可用空间,并将空间返还给数据库空间中分区号为 14680071 的分段。
EXECUTE FUNCTION task("fragment repack shrink", "14680071");
可以取消使用 compress 自变量的命令,例如在 DB-Access 中输入 CTRL-C。之前中断命令之后,可重新发出带 repack 或 repack_offline 自变量的命令。(压缩和重新打包操作将记录,但是在较小的部分中运行。)
将可用空间返还给数据库空间
压缩、重新打包或压缩并重新打包表或分段时,可将可用空间返还给数据库空间(收缩空间);也可在不压缩或重新打包的情况下单独返还可用空间。 返还可用空间将减小分段或表的总大小。
可在不影响表的分配策略的情况下,安全收缩整个表。例如,如果有一个分段表,一周的每一天都有一个分段,并且还有许多预分配的分段供将来使用,那么可在不影响该分配策略的情况下收缩该表。如果该表为空,GBase 8s 将把该表收缩为创建该表时指定的初始扩展数据块大小。
启动收缩操作时,GBase 8s 将缩小扩展数据块,如下所示:
- 将除第一个扩展数据块之外的其他所有扩展数据块尽量缩小。
- 如果整个表都在第一个扩展数据块中(例如,因为该表是空表),GBase 8s 将不把第一个扩展数据块收缩为小于使用 CREATE TABLE 语句创建该表时指定的扩展数据块大小。
可以使用 ALTER TABLE 语句的 MODIFY EXTENT SIZE 子句来减小当前扩展数据块大小。执行此操作之后,可重新运行收缩操作,以便将第一个扩展数据块收缩为新扩展数据块大小。
先决条件:您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
要将可用空间返还给数据库空间:
-
运行带 table shrink 或 fragment shrink 自变量的 admin() 或 task() 函数。
例如,为表指定:
EXECUTE FUNCTION admin("table shrink", "table_name", "database_name", "owner_name");必须指定表名。数据库和所有者名称可选。 如果不指定数据库或所有者名称,GBase 8s 将使用当前数据库和所有者名称。
例如,为分段指定:
EXECUTE FUNCTION task(“fragment shrink”, “partnum_list”);partnum_list 是属于同一个表的分区号的空格分隔列表。
-
可以选择扩展自变量以在以下任意组合中包含 compress 和 repack:
- compress repack shrink
- compress shrink
- repack shrink
以下示例显示了这样的一个命令:指示 GBase 8s 收缩所有者为“bob”的“music”数据库内名为“opera”的表。
EXECUTE FUNCTION task("table shrink","opera","music","bob");
以下示例显示了这样的一个命令:指示 GBase 8s 重新打包和收缩分区号为 14680071 的分段。
EXECUTE FUNCTION task("fragment repack shrink," "14680071");
解压缩数据
可解压缩之前压缩的表和分段。解压缩表或分段将停用对新的插入和更新操作的压缩、解压缩所有已压缩的行、停用压缩字典,并对不再适合其原始页面的行分配新页面。
可使用 uncompress 或 uncompress_offline 自变量,以在线或脱机方式解压缩。 脱机解压缩操作与解压缩的操作相同,不同之处是该操作在执行时对分段保持互斥锁定,以便在完成操作之前,避免其他对分段数据进行的所有访问。
完成脱机解压缩操作之前删除或禁用索引可以减少服务器完成此操作需要的时间量。之后,可以重新创建或重新启用索引,最好是利用 PDQ。先删除或禁用索引,再重新创建或启用,这种做法比不这样做而直接完成脱机重新打包或脱机解压缩操作的速度更快。
先决条件:
- 您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
- 必须压缩表或分段。
- 如果希望运行的任何工作负载(包括但不限于 uncompress 或 uncompress_offline 操作)耗用日志文件的速度超过每 30 秒一个文件,请将日志配置为比当前大小更大。
要解压缩表或分段中的数据,请执行以下操作:
运行带 table uncompress、table uncompress_offline、fragment uncompress 或 fragment uncompress_offline 命令自变量的 admin() 或 task() 函数。
为表指定信息,如下所示:
EXECUTE FUNCTION task(“table uncompress”, “table_name”,“database_name”, “owner_name”);
或
EXECUTE FUNCTION admin(“table uncompress_offline”, “table_name”, “database_name”, “owner_name”);
必须指定表名。数据库和所有者名称可选。如果不指定数据库或所有者名称,GBase 8s 将使用当前数据库和所有者名称。
为分段指定信息,如下所示:
EXECUTE FUNCTION task(“fragment uncompress”, “partnum_list”);
或
EXECUTE FUNCTION task(“fragment uncompress_offline”, “partnum_list”);
示例
以下示例显示了这样的一个命令:指示 GBase 8s 解压缩所有者为“mario”的“music”数据库内名为“rock”的表。
EXECUTE FUNCTION task("table uncompress","rock","music","mario");
以下示例显示了这样的一个命令:指示 GBase 8s 以脱机方式解压缩分区号为 14680071 的分段。
EXECUTE FUNCTION task("fragment uncompress_offline," "14680071");
如果已解压缩表,GBase 8s 将把该表的字典标记为不活动。GBase 8s 不会删除字典,因为 Enterprise Replication 函数会将字典用于较旧的日志。可删除不再需要的字典。
您可以取消带 uncompress 自变量的命令,如在 DB-Access 中按 CTRL-C。
之前中断命令之后,可重新发出带 uncompress 和 uncompress_offline 自变量的命令。(压缩、重新打包和解压缩操作将记录,但是在较小的部分中运行。)
删除压缩字典
可删除特定表或分段的不活动压缩字典,删除所有不活动压缩字典,或删除达到指定日期的所有不活动压缩字典。删除为表和分段创建的任何压缩字典之前,必须解压缩表和分段,以使字典处于不活动状态。
请勿除去 Enterprise Replication 需要的压缩字典。
不能删除为索引创建的压缩字典。删除索引时,数据库服务器会除去这些压缩字典。
先决条件:
- 您必须可以连接到 sysadmin 数据库(缺省情况下只有用户 gbasedbt 可连接),并且必须是 DBSA。
- 删除关联字典之前,请解压缩或删除表或分段。只能删除压缩表或分段不再使用的压缩字典。
- 确保 Enterprise Replication 函数未将压缩字典用于较旧的日志。
- 归档包含具有压缩字典的表或分段的任何数据库空间,即使表或分段中的数据已解压缩并且字典不再处于活动状态。
要删除不再需要的一个或多个压缩字典,请执行以下操作:
运行带以下自变量的 admin() 或 task() 函数:
- table purge_dictionary 或 fragment purge_dictionary 命令自变量,用于删除特定的不活动字典。
- compression purge_dictionary 命令自变量,用于删除所有字典。
- compression purge_dictionary 命令自变量和日期,用于删除该日期及之前创建的所有字典。
任何可根据您的语言环境转换为 DATE 数据类型格式的日期均可使用。 例如,可以指定 01/31/2012、01/31/12 或 Jan 31, 2012。
示例 1:运行以下命令可除去所有者为“arlette”的“music”数据库中表“latin”的不活动字典。
EXECUTE FUNCTION task(“table purge_dictionary”, “latin”, “music”,”arlette”);
示例 2:运行以下命令可除去 2011 年 3 月 8 日及之前创建的所有字典:
EXECUTE FUNCTION task(“compression purge_dictionary”, "03/08/11");
压缩表时,数据库服务器会创建一个内部分区用于保存压缩字典。解压缩表和清除字典时,数据库服务器会除去该字典。 但是,内部分区不会除去。如果为保存字典而创建的内部分区位于第二个块上,那么可能会有一个块只包含内部分区。 如果发生此情况,将无法删除该块。可以备份数据库空间,然后将其删除。
移动压缩数据
可使用 High-Performance Loader (HPL) 或其他任何 GBase 8s 实用程序(onunload 和 onload 实用程序除外)来移动压缩数据。
不能使用 onunload 和 onload 实用程序将压缩后的数据从一个数据库移动到另一个。在使用 onunload 和 onload 实用程序之前,您必须将压缩表和分段中的数据解压缩。
dbexport 实用程序用于解压缩压缩的数据。因此,如果数据库包含带有压缩数据的表或分段,那么必须在使用 dbimport 实用程序导入数据之后重新启用压缩和重新压缩。
dbexport 实用程序用于解压缩压缩的数据。因此,如果数据库包含带有压缩数据的表或分段,那么必须在使用 dbimport 实用程序导入数据之后重新压缩。
B 型树索引压缩和存储优化
可以压缩拆离的 B 型树索引。您还可以合并索引中的可用空间,然后可将索引末尾的可用空间返还给数据库空间。压缩数据之前,可估计可以节省的磁盘空间量。
压缩索引、合并数据并返还可用空间会带来以下益处:
- 可将更多数据放入缓冲区高速缓存
- 释放内存用于其他用途
使用 CREATE INDEX 命令创建新索引时,可以对其进行压缩。
可以压缩位于分段或非分段表上的现有拆离 B 型树索引。使用 SQL 管理 API 命令来压缩现有索引。
您不能压缩以下类型的索引:
- 不是 B 型树索引的索引
- 连接的 B 型树索引
- 虚拟 B 型树索引
- 键数少于 2000(这是可压缩索引需要的最小键数)的索引
先决条件:要能够进行压缩,索引必须至少有 2000 个键。
压缩操作仅压缩索引的叶子(底层)。
不能将已压缩的索引解压缩。如果不再需要已压缩的索引,可以删除该索引,然后将其重新创建为未压缩的索引。
压缩率
压缩率取决于压缩的数据。GBase 8s 使用的压缩算法是基于字典的算法,该算法对找到的最常用的数据模式执行操作,方法是在构建该字典时采样的数据中按长度加权。
如果典型数据分发与创建字典时采样的数据存在偏差,压缩率可能降低。
最大压缩率可能为 90%。这是因为任何顺序的字节的最大可能压缩率是通过以下方法得出的:将每组 15 个字节替换为一个 12 位的符号数,从而生成占原始映像大小 10% 的压缩映像。但是,并不容易获得 90% 的压缩率,因为 GBase 8s 会向每个压缩映像添加一个字节的元数据。
压缩字典
对于每个压缩分段和每个压缩的非分段表,都存在一个单独的压缩字典。对于每个压缩分段、每个压缩的非分段表、数据库空间中的每个压缩简单大对象和每个压缩索引分区,都存在一个单独的压缩字典。每个压缩字典是由分段或表数据中经常出现的模式和替换这些模式的符号数构成的库。
压缩字典是使用从至少包含 2,000 行的分段或非分段表随机采样的数据构建的。如果分段或表中包含的行数不足 2,000,那么 GBase 8s 不会构建压缩字典。
压缩字典最多可存储 3,840 个模式,每个模式的长度可以为 2 到 15 个字节。(超过 7 个字节的模式将减少字典可包含的模式的总数。)这些模式中的每一个都通过压缩行中的 12 位符号数来表示。要进行压缩,输入行映像中的一系列字节必须精确匹配字典中的某个完整模式。如果行与字典匹配的模式不足,那么可能无法压缩,因为不完全匹配的输入行中的每个字节在压缩映像中都将替换为 12 位(1.5 个字节)。
GBase 8s 尝试捕获最佳的可压缩模式(模式频率乘以长度)。数据通过以下方法压缩:将出现的模式替换为字典中的相应符号数,并将出现的不匹配任何模式的字节替换为特别保留的符号数。
数据库空间中表或分段的所有字典都存储在该数据库空间中一个隐藏的字典表内。sysmaster 数据库中的 syscompdicts_full 表和 syscompdicts 视图提供有关压缩字典的信息。
通常需要大约 100 KB 的空间来存储压缩分段或表的压缩字典。因此,太小的表不适合压缩,因为可能无法通过压缩行来收回足够抵销压缩字典存储花费的空间。
此外,GBase 8s 不能将单个行压缩到长度小于 4 个字节。这是因为服务器必须留出一些空间,以免行映像稍后增长到超过了页面可容纳的程度。因此,不得尝试压缩带有包含 4 个或更少字节的行的分段或非分段表。
可查看的压缩信息
可以使用 GBase 8s 实用程序、sysmaster 数据库表和 sysmaster 视图来显示压缩统计信息、有关压缩字典的信息,以及压缩字典。
表 1. 用于显示压缩信息的实用程序、sysmaster 表和视图
| 实用程序、表或视图 | 描述 |
|---|---|
| oncheck -pT 选项 | 在输出的“Compressed Data Summary”部分中显示有关任何压缩项的统计信息。如果未压缩任何项,那么输出中不会显示“Compressed Data Summary”部分。 例如,对于行数据,oncheck -pT 显示表或表分段中任何压缩行的数量,以及压缩的表或表分段行的百分比。 |
| onlog -c 选项 | 使用压缩字典来扩展压缩的数据,并显示压缩日志记录的未压缩内容。 |
| onstat –g dsk 选项 | 显示有关当前运行的压缩操作的进度的信息。 |
| onstat -g ppd 选项 | 显示有关当前打开的压缩分段(也称为分区)存在的活动压缩字典的信息。此选项显示的信息与 sysmaster 数据库中的 syscompdicts 视图显示的信息相同。 |
| sysmaster 数据库中的 syscompdicts_full 表 | 显示有关压缩字典和压缩字典二进制对象的元数据。 只有用户 gbasedbt 可访问此表。 |
| sysmaster 数据库中的 syscompdicts 视图 | 与 syscompdicts_full 表显示的信息相同,不过出于安全性原因,其中不包含 dict_dictionary 列,该列中包含压缩字典二进制对象。 |
可以使用 UNLOAD 语句,将压缩字典从 syscompdicts_full 表卸载到压缩字典文件,如下所示:
UNLOAD TO 'compression_dictionary_file'
SELECT * FROM sysmaster:syscompdicts_full;
有关 onlog 实用程序、onstat -g dsk 选项、onstat -g ppd 选项、oncheck -pT 选项、syscompdicts_full 表和 syscompdicts 视图的更多信息,请参阅《GBase 8s 管理员参考》。
将数据装入表
您可以按以下方法将数据 装入现有的表中。
| 装入数据的方法 | TEXT 或 BYTE 数据 | CLOB 或 BLOB 数据 | 引用 |
|---|---|---|---|
| DB-Access LOAD 语句 | 是 | 是 | 《GBase 8s SQL 指南:语法》中的 LOAD 语句 |
| dbload 实用程序 | 是 | 是 | |
| dbimport 实用程序 | 是 | 是 | |
| GBase 8s ESQL/C 程序 | 是 | 是 | 《GBase 8s ESQL/C 程序员手册》 |
| 使用 EXTERNAL 源表插入 MERGE | 是 | 是 | 《GBase 8s SQL 指南:语法》 |
| onload 实用程序 | 否 | 否 | |
| onpladm 实用程序 | 是,精致方式 | 是,精致方式 |
重要: 数据库服务器在数据已装入数据库后,不包含任何压缩 TEXT 和 BYTE 数据的机制。
使用外部表移动数据
可使用外部表装入和卸载数据库数据。
您可以发出一系列用于执行以下功能的 SQL 语句:
- 将运作数据高效传输到其他系统或从其他系统传入
- 以 GBase 8s 内部数据格式跨平台传输数据文件
- 使用数据库服务器在定界 ASCII、固定 ASCII 与 GBase 8s 内部(原始)表示法之间转换数据
- 使用 SQL INSERT 和 SELECT 语句来指定数据库表中新列的数据映射
- 提供并行标准 INSERT 操作,即可在不删除索引的情况下装入数据
- 使用命名管道来支持在存储设备中装入和卸载数据,这些存储设备包括磁带机和直接网络连接
- 维护运行期间的装入和卸载统计信息的记录
- 执行快速(高速)和高级(数据检查)传输
可使用 DB-Access 发出 SQL 语句,或将其嵌入 ESQL/C 程序中。
外部表
外部表是不受 GBase 8s 数据库服务器管理的数据文件。外部表的定义包括数据格式化类型、外部数据描述字段和全局参数。
为了将外部数据映射到内部数据,数据库服务器将外部数据视为外部表。将外部数据视为表是一种很有用的方法,可用于将数据移入或移出数据库,并指定数据库的转换。
数据库服务器运行装入任务时,将从外部源读取数据,并执行创建行所需的转换,然后将行插入表中。数据库服务器将错误写入拒绝文件。
如果不能转换外部表中的数据,可指定数据库服务器将记录写入拒绝文件,并且包含失败的原因。为此,请在 CREATE EXTERNAL TABLE 语句中指定 REJECTFILE 关键字。
数据库服务器提供了若干不同的转换机制,这些转换机制在数据库服务器内部执行,从而在执行转换任务期间提供最大性能。数据库服务器优化固定格式和定界格式的 ASCII 与 GBase 8s 数据表示法之间的数据转换。
要执行定制转换,可创建一个过滤器程序,用于将转换后的数据写入命名管道。数据库服务器然后以一种常用格式从命名管道读取其输入。
定义外部表
要定义外部表,需要使用 SQL 语句来描述数据文件,定义表,然后指定要装入或卸载的数据。
要设置装入和卸载任务,需要发出以下一系列 SQL 语句:
- CREATE EXTERNAL TABLE,用于描述要装入或卸载的数据文件
- CREATE TABLE,用于定义要装入的表
- INSERT...SELECT,用于执行装入和卸载
以下步骤概述装入过程:
-
CREATE EXTERNAL TABLE 语句描述各个外部文件的位置和外部数据的格式,其位置可以是磁盘或来自管道(磁带机或直接网络连接)。以下示例描述的是 CREATE EXTERNAL TABLE 语句:
CREATE EXTERNAL TABLE emp_ext
( name CHAR(18) EXTERNAL CHAR(18),
hiredate DATE EXTERNAL CHAR(10),
address VARCHAR(40) EXTERNAL CHAR(40),
empno INTEGER EXTERNAL CHAR(6) )
USING (
FORMAT 'FIXED',
DATAFILES
("DISK:/work2/mydir/emp.fix")
); -
CREATE TABLE 语句定义要装入的表。以下样本 CREATE TABLE 语句定义 employee 表:
CREATE TABLE employee
FRAGMENT BY ROUND ROBIN IN dbspaces; -
INSERT...SELECT 语句用于映射外部数据与数据库表之间的移动。 以下样本 INSERT 语句从外部表装入 employee 表:
INSERT INTO employee SELECT * FROM emp_ext
如果指定多个 INSERT...SELECT 语句来卸载数据,那么每个后续 INSERT 语句将覆盖数据文件。 请对数据文件使用绝对路径。
将数据装入数据库时,SELECT 子句的 FROM 表部分是 CREATE EXTERNAL 语句定义的外部表。将数据卸载到外部文件时,SELECT 子句控制从数据库检索数据。
与 TEMP 表不同,外部表在删除之前会在目录中保留定义。创建外部表时,可保存数据的外部描述,以便复用。将表卸载为 GBase 8s 内部数据表示法后,此操作特别有用,因为稍后可使用相同的外部表描述来重新装入这些数据。
外部表定义中包含定义外部数据文件中的数据所需的全部信息,如下所示:
-
外部数据中的字段的描述。
-
DATAFILES 子句。
该子句指定:
- 数据文件是位于磁盘上还是命名管道上。
- 文件的路径名。
-
FORMAT 子句。
该子句指定外部数据文件中的数据格式化类型。数据库服务器转换若干数据格式的外部数据,这些格式包括定界和固定 ASCII,以及 GBase 8s 内部格式。
- 影响数据格式的任何全局参数。
如果将外部表直接映射到定界格式的内部数据库表中,可使用 CREATE EXTERNAL TABLE 语句定义列,并添加子句 SAMEAS 内部表,而无需显式枚举列。
将列映射到其他列
如果数据文件应该让字段按照其他顺序排列(例如,empno、name、address、hiredate),可使用 INSERT 语句映射列。首先创建包含列的表,而这些列的排列顺序是其在外部文件中发现时的排列顺序。
CREATE EXTERNAL TABLE emp_ext
(
f01 INTEGER,
f02 CHAR(18),
f03 VARCHAR(40),
f04 DATE
)
USING (
DATAFILES ("DISK:/work2/mydir/emp.dat"),
REJECTFILE "/work2/mydir/emp.rej"
);
INSERT INTO employee (empno, name, address, hiredate)
SELECT * FROM emp_ext;
通过这种方法将对插入列进行映射,以匹配外部表的字段顺序。
另一种对列进行重新排序的方法是使用 SELECT 子句来匹配数据库表的顺序。
INSERT INTO employee
SELECT f02, f04, f03, f01 FROM emp_ext;
从命名管道装入数据和将数据卸载到命名管道
可使用命名管道(也称为先进先出,FIFO)数据文件,来从非标准设备(如磁带机)装入和卸载到非标准设备。
与普通的操作系统文件不同,命名管道没有 2 GB 大小限制。操作系统打开并检查命名管道的文件末尾,其方法与普通文件不同。
使用命名管道装入数据
可使用命名管道从外部表装入数据。
要使用命名管道从外部表装入数据,请执行以下步骤:
-
在 SQL 中 CREATE EXTERNAL TABLE 语句的 DATAFILES 子句内,指定命名管道。
-
创建在 DATAFILES 子句中指定的命名管道。
使用操作系统命令创建命名管道。
使用带 -p 选项的 mknod UNIX™ 命令创建命名管道。要避免在 UNIX 上出现妨碍管道打开的问题,请为管道读程序和管道写程序启动单独的 UNIX 进程,或使用 O_NDELAY 标志集来打开管道。
-
使用读取命名管道的程序打开命名管道。
-
执行 SQL 中的 INSERT 语句。
INSERT INTO employee SELECT * FROM emp_ext;
如果在执行 INSERT 语句之前不创建和打开命名管道,INSERT 将成功执行,但是不装入任何行。
FIFO 虚拟处理器
数据库服务器使用 FIFO 虚拟处理器 (VP) 来读写命名管道上的外部表。
缺省 FIFO 虚拟处理器数为 1。
数据库服务器为您在 CREATE EXTERNAL TABLE 语句的 DATAFILES 子句中指定的每个命名管道使用一个 FIFO VP。例如,假设您使用以下 SQL 语句定义外部表:
CREATE EXTERNAL TABLE ext_items
SAMEAS items
USING (
DATAFILES("PIPE:/tmp/pipe1",
"PIPE:/tmp/pipe2",
"PIPE:/tmp/pipe3"
));
如果对 FIFO VP 使用缺省值 1,数据库在读取完 pipe1 中的所有数据之前不会从 pipe2 读取,在读取完 pipe2 中的所有数据之前不会从 pipe3 读取。
使用命名管道卸载数据
可使用命名管道将数据从数据库卸载到外部表。
要使用命名管道将数据卸载到外部表,请执行以下步骤:
-
在 SQL 的 CREATE EXTERNAL TABLE 语句或 SELECT INTO EXTERNAL 语句的 DATAFILES 子句中,指定命名管道。
DATAFILES ("PIPE:/usr/local/TAPE") -
创建在 DATAFILES 子句中指定的命名管道。使用操作系统命令创建命名管道。
-
使用写入命名管道的程序打开命名管道。
-
将数据卸载到命名管道。
CREATE EXTERNAL TABLE emp_ext
( name CHAR(18) EXTERNAL CHAR(20),
hiredate DATE EXTERNAL CHAR(10),
address VARCHAR(40) EXTERNAL CHAR(40),
empno INTEGER EXTERNAL CHAR(6) )
USING (
FORMAT 'FIXED',
DATAFILES
("PIPE:/usr/local/TAPE")
);
INSERT INTO emp_ext SELECT * FROM employee;
如果在执行 SELECT 或 INSERT 语句之前不创建和打开命名管道,卸载将失败,并生成 ENXIO 错误消息(没有这样的设备或地址)。
使用 PIPE 选项将数据从一个实例复制到另一个
可使用命名管道将数据从一个 GBase 8s 实例复制到另一个,而无需将数据写入中间文件。
可使用命名管道将数据从一个 GBase 8s 实例卸载,然后装入另一个实例,而无需将数据写入中间文件。也可使用命名管道将数据从一个表复制到同一个 GBase 8s 实例上的另一个表。 在以下示例中,数据将从一个实例上的源表复制到第二个实例上的目标表。
必须首先根据所用硬件平台使用以下命令之一创建命名管道。在本示例中,命名管道称为 pipe1。
% mkfifo /work/pipe1
% mknod /work/pipe1
执行以下步骤,将数据从源实例上的表复制到同一台计算机上目标实例中的表。
-
在源实例上创建源表。在本示例中,源表称为 source_data_table:
CREATE TABLE source_data_table
(
empid CHAR(5),
empname VARCHAR(40),
empaddr VARCHAR(100)
); -
在源实例上创建外部表。在本示例中,外部表称为 ext_table:
CREATE EXTERNAL TABLE ext_table
(
empid CHAR(5),
empname VARCHAR(40),
empaddr VARCHAR(100)
)
USING
(DATAFILES
(
'PIPE:/work/pipe1'
)
); -
在目标实例上创建目标表。在本示例中,目标表称为 destin_data_table:
CREATE TABLE destin_data_table
(
empid CHAR(5),
empname VARCHAR(40),
empaddr VARCHAR(100)
); -
在目标实例上创建外部表。在本示例中,外部表称为 ext_table:
CREATE EXTERNAL TABLE ext_table
(
empid CHAR(5),
empname VARCHAR(40),
empaddr VARCHAR(100)
)
USING
(DATAFILES
(
'PIPE:/work/pipe1_1'
)
); -
从 UNIX™ shell 运行以下命令。该命令将数据从 /work/pipe1 重定向到 /work/pipe1_1
cat /work/pipe1 > /work/pipe1_1 -
在目标实例上运行以下命令,以将数据从命名管道定向到目标表:
INSERT INTO destin_data_table SELECT * FROM ext_table; -
在源实例上运行以下命令,以将数据假脱机到命名管道:
INSERT INTO ext_table SELECT * FROM source_data_table;
可使用多个管道,方法是在 DATAFILES 子句中插入多个 PIPE 语句,并为每个语句创建一个命名管道。
监视装入或卸载操作
可监视外部表的装入或卸载操作的状态。
您可能希望在以下情况监视装入或卸载操作:
- 如果希望经常装入和卸载同一个表,以构建数据集市或数据仓库,那么监视作业的进度可估算类似作业的时间,供将来使用。
- 如果从命名管道装入或卸载,那么监视 I/O 队列可确定是否有足够数量的 FIFO 虚拟处理器。
监视常用装入和卸载操作
可使用 onstat -g iof 命令查找要查看的文件中的全局文件描述符 (gfd)。然后使用 onstat -g sql 命令来监视装入和卸载操作。
以下示例显示了样本 onstat -g iof 命令输出。
AIO global files:
Gfd path name bytes read page reads bytes write page writes io/s
3 rootdbs 1918976 937 145061888 70831 36.5
op type count avg. time
seeks 0 N/A
reads 937 0.0010
writes 4088 0.0335
kaio_reads 0 N/A
kaio_writes 0 N/A
要确定装入或卸载操作是否可使用并行执行,请在执行 INSERT 语句之前执行 SET EXPLAIN ON 语句。SET EXPLAIN 输出显示以下计数:
- 优化器为 INSERT 语句选择的并行 SQL 运算符的数量
- 每个 SQL 运算符要处理的行数
要监视装入操作,请运行 onstat -g sql 来获取会话标识。
监视 FIFO 虚拟处理器
可使用 onstat 命令监视 FIFO VP 的有效使用。
可使用 onstat -g ioq 选项显示正在等待执行 I/O 请求的每个 FIFO 队列的长度。以下示例显示样本输出。
AIO I/O queues:
q name/id len maxlen totalops dskread dskwrite dskcopy
fifo 0 0 0 0 0 0 0
adt 0 0 0 0 0 0 0
msc 0 0 1 153 0 0 0
aio 0 0 9 3499 1013 77 0
pio 0 0 2 3 0 2 0
lio 0 0 2 2159 0 2158 0
gfd 3 0 16 39860 38 39822 0
gfd 4 0 16 39854 32 39822 0
gfd 5 0 1 2 2 0 0
gfd 6 0 1 2 2 0 0
...
gfd 19 0 1 2 2 0 0
以上示例中样本输出内的 q name 字段显示了队列的类型,如 fifo 表示 FIFO VP,或 aio 表示 AIO VP。 如果 q name 字段显示 gfd 或 gfdwq,说明这是其全局文件描述符与输出的 id 字段匹配的文件的队列。磁盘文件在一个队列中同时包含读写请求。每个磁盘文件在 onstat -g ioq 输出中显示一行。 管道有单独的读写队列。每个管道在输出中显示两行:gfd 针对读请求,gfdwq 针对写请求。
len 或 maxlen 字段的值最高为 4(对于装入)或 4 * number_of_writer_threads(对于卸载)。xuwrite 运算符控制写程序线程的数量。
请使用 totalops 字段中的值,而不是 len 或 maxlen 字段中的值,监视对文件或管道执行的读或写请求的数量。totalops 字段表示从该文件中读取了 34 KB 的数据,或将 34 KB 的数据写入了该文件。如果 totalops 不增加,说明已停止对文件或管道执行读或写操作(因为 FIFO VP 正忙)。
要提高性能,请使用 onmode -p 命令增加更多 FIFO VP。FIFO VP 的缺省数量为 1。在该样本输出中,FIFO 队列内不包含任何数据。例如,如果通常定义两个以上的管道来装入或卸载,请使用以下样本 onmode 命令增加 FIFO VP 的数量:
onmode -p +2 FIFO
也可以使用 onmode -p 命令除去 FIFO VP。 但是,不能将 FIFO VP 的数量设置为低于 1。
有关更多信息,请参阅《GBase 8s 管理员参考》。
高可用性集群环境中的外部表
可按照几乎与主服务器上使用的相同方式,在辅助服务器上使用外部表。
可在主服务器和辅助服务器上执行以下操作:
-
将数据从数据库表卸载到外部表:
INSERT INTO external_table SELECT * FROM base_table WHERE ... -
将数据从外部表装入到数据库表:
INSERT INTO base_table SELECT * FROM external_table WHERE ...
在 SDS、RHAC 或 HAC 辅助服务器上装入数据的速度比在主服务器上装入数据的速度慢。
辅助服务器上不支持 CREATE EXTERNAL TABLE 语句和 SELECT ... INTO EXTERNAL ... 语句。
将数据从数据库表卸载到外部表时,将在辅助服务器上创建数据文件,但是不会在主服务器上创建。在辅助服务器上创建的外部表数据文件不会自动传输到主服务器,反之在主服务器上创建的外部表数据文件也不会自动传输到辅助服务器。
在主服务器上创建外部表时,仅外部表的模式会复制到辅助服务器,而不会复制数据文件。
要在主服务器与辅助服务器之间同步外部表,可以将外部表文件从主服务器复制到辅助服务器,或使用以下步骤:
-
在主服务器上:
-
使用与外部表相同的模式创建临时表。
-
填充临时表:
INSERT INTO dummy_table SELECT * FROM external_table
-
-
在辅助服务器上:
使用以下命令填充外部表:
INSERT INTO external_table SELECT * FROM dummy_table
外部表的系统目录条目
可查询系统目录表,以确定外部表的状态。
每次创建外部表时,GBase 8s 都会更新 sysexternal 和 sysextdfiles 系统目录表。指定外部格式类型 (fmttype) FIXED 时,将更新 sysextcols 系统目录表。
表 1. 外部表系统目录条目
| 表名 | 描述 |
|---|---|
| sysexternal | 存储有关每个外部表的信息。 |
| sysextdfiles | 存储有关外部表数据文件的信息 |
| sysextcols | 存储有关类型为 FIXED 的外部表的信息 |
请参阅《GBase 8s SQL 指南:参考》以获取更多信息。
创建外部表时,将在 systables 系统目录中插入行;但是,除非在创建外部表时指定了 NUMROWS 子句,否则 nrows(行数)和 npused(所用数据页数)列可能无法精确反映外部表所用行数和数据页数。
创建外部表时如果没有为 NUMROWS 子句指定值,GBase 8s 就无法确定外部表中的行数,因为数据位于数据库外的数据文件中。GBase 8s 通过插入较大值 (MAXINT – 1) 来更新 systables 系统目录中的 nrows 列,并根据 nrows 的值计算所用数据页数。优化器稍后将使用 npused 和 nrows 中存储的值来确定最有效的执行计划。尽管无需精确指定 NUMROWS 子句,但是指定得越准确,nrows 和 npused 的值就越准确。
使用外部表时的性能注意事项
如果要使用 SQL 命令处理 ASCII 文件中的数据,或将数据从外部数据文件装入 RAW 数据库表,您可以使用外部表。
将信息装入数据库的方法有几种,包括:
- LOAD FROM ... INSERT INTO... DB-Access 命令
- dbimport 实用程序
- High-Performance Loader 实用程序
- 外部表
High Performance Loader 实用程序可在将外部数据装入到带索引的数据库表时提供最佳性能。
外部表可在将数据装入到不带索引的 RAW 表时提供最佳性能。
装入数据前锁定外部表将提高装入性能
管理外部表装入和卸载操作产生的错误
可管理外部表装入和卸载操作期间发生的错误。
这些主题描述如何使用拒绝文件和错误消息来管理错误,以及如何恢复已装入到数据库的数据。
拒绝文件
装入期间具有转换错误的行将写入执行转换的服务器上的拒绝文件中。
CREATE EXTERNAL TABLE 语句中的 REJECTFILE 关键字用于确定指定给拒绝文件的名称。
可不使用拒绝文件,而是使用 CREATE EXTERNAL TABLE 语句中的 MAXERRORS 关键字来指定数据库服务器停止装入数据之前允许的错误数。(如果不设置 MAXERRORS 关键字,数据库将无视错误数,处理所有数据。)
数据库服务器将在开始执行装入时除去拒绝文件(如果有)。仅当装入期间发生错误时,才会重新创建和写入拒绝文件。
拒绝文件条目是包含以逗号分隔的以下字段的单行:
file name, record, reason-code, field-name: bad-line
file name
输入文件的名称
record
输入文件中的记录号,在该文件中检测到错误
reason-code
错误的描述
field-name
外部字段名称(行中的第一个错误即在此处出现)或
bad-line
坏行本身(仅对于定界或固定 ASCII 文件)
装入操作以 ASCII 格式写入 file name、record、field-name 和 reason-code。
bad-line 信息由输入文件的类型决定:
- 对于定界文件或固定文本文件,整个坏行将直接复制到拒绝文件中。但是如果定界格式表具有 TEXT 或 BYTE 列,那么拒绝文件中将不包含任何坏数据。装入操作将仅为每个拒绝的行生成一个标题。
- 对于 GBase 8s 内部数据文件,坏行不会放入拒绝文件中,因为您无法编辑文件中的二进制表示。但是,拒绝文件中仍然会报告 file name、record、reason-code 和 field-name,这样您可以隔离该问题。
以下类型的错误可能导致行被拒绝。
CONSTRAINT constraint name
违反了该约束。
CONVERT_ERR
有字段遇到转换错误。
MISSING_DELIMITER
找不到定界符。
MISSING_RECORDEND
找不到记录结尾。
NOT NULL
field-name 中找到了空值。
ROW_TOO_LONG
输入记录长度超过了 64 KB。
输入记录长度超过了 2 GB。
外部表错误消息
与外部表有关的大多数错误消息都在范围 -26151 到 -26199 之间。
其他消息为 -615、-999、-23852 和 -23855。在这些消息中,n macro 和 r macro 指从替换字符 %r(first..last) 生成的值。有关错误消息列表使用 finderr 实用程序。有关违例表错误消息的信息,请参阅《GBase 8s 管理员参考*》*。
外部表的表类型可恢复性
装入数据时,数据库服务器将检查表的可恢复性级别。
- 如果表类型为 RAW,数据库服务器可使用轻量级追加(快速)方式装入数据和处理检查约束。如果装入期间数据库服务器崩溃,将不回滚装入的数据,而表可能保持未知状态。
- 如果表类型为 STATIC,那么数据库服务器根本不能装入数据。
- 只有高级方式支持数据可恢复性。高级方式使用记录的常规插入。要在快速方式装入失败之后恢复数据,请还原为最近的 0 级备份。对于此级别的可恢复性,表类型必须为 STANDARD。
有关复原表类型的信息,请参阅《GBase 8s 备份与复原指南》。