分布式数据
多阶段落实协议
两阶段落实协议确保跨多个数据库服务器统一落实或回滚事务。您可以将 GBase 8s 数据库服务器与 GBase 8s Enterprise Gateway 产品或事务管理器一起使用,以便在非 GBase 8s 数据库中处理数据。跨多个 GBase 8s 数据库服务器的分布式查询支持两阶段落实。
异类落实协议确保对单一事务中的一个或多个 GBase 8s 数据库以及一个非 GBase 8s 数据库的更新可统一落实或回滚。
这些主题包含有关使用两阶段落实协议的信息。 有关从失败的两阶段落实事务手动恢复的信息,请参阅从失败的两阶段落实手动恢复。
这些主题还包含有关使用支持符合 XA 的外部数据源的事务的信息,这些数据源可参与两阶段落实事务。请参阅 GBase 8s 事务对符合 XA 的外部数据源的支持。
事务管理器
事务管理器支持两阶段落实和回滚。例如,如果数据库是 GBase 8s,记帐系统是 Oracle,而汇款系统是 Sybase,那么可以使用事务管理器在不同数据库之间通信。 您还可以使用事务管理器通过使用分布式事务而非 Enterprise Replication 或高可用性数据复制,确保 GBase 8s 或非 GBase 8s 数据库之间的数据一致性。
TP/XA 库(带事务管理器)
全局事务是一种在查询中涉及多个数据库服务器的分布式查询。 全局事务环境具有以下部件:
- 客户机应用程序
- 资源管理器(GBase 8s 数据库服务器)
- 事务管理器(供应商软件)
TP/XA 是一个函数库,使数据库服务器可充当 X/Open DTP 环境中的资源管理器。将 TP/XA 库作为 GBase 8s ESQL/C 的一部分安装可启用第三方事务管理器和数据库服务器之间的通信。X/Open 环境支持大型的高性能 OLTP 应用程序。
当您的数据库具有以下特征时,请使用 TP/XA:
- 数据分发在多供应商数据库中
- 事务包括 GBase 8s 和非 GBase 8s 数据
Microsoft Transaction Server (MTS/XA)
数据库服务器支持 Microsoft™ Transaction Server (MTS/XA) 在 XA 环境中充当事务管理器。 要使用 MTS/XA,请安装 GBase 8s Client Software Development Kit、最新版本的 GBase 8s ODBC Driver 以及 MTS/XA。 有关更多信息,请联系 GBase 8s 技术支持,并参阅 GBase 8s 客户机产品安装指南 和 MTS/XA 文档。
GBase 8s 事务对符合 XA 的外部数据源的支持
GBase 8s 事务管理器 GBase 8s 的主体部分,而不是单独模块,用于识别符合 XA 的外部数据源。这些数据源可参与两阶段落实事务。
对于参与特殊事务事件(例如,准备、落实或回滚)的分布式事务每个符合 XA 的外部数据源,事务管理器都会对其运行支持例程。该交互符合 X/Open 接口标准。
符合 XA 的外部数据源的事务支持(也称为资源管理器)使您能够执行以下操作:
- 创建符合 XA 的外部数据源类型及其实例。
- 创建或修改用户定义的例程 (UDR)、虚拟表接口或虚拟索引接口以启用符合 XA 的数据源来为来自符合 XA 的数据源的外部数据提供数据访问机制。
- 将符合 XA 的外部数据源注册到 GBase 8s。
- 注销符合 XA 的外部数据源。
- 在同一个全局事务中使用多个符合 XA 的外部数据源。
事务与符合 XA 的外部数据源的协调仅在以 GBase 8s 登录的数据库和符合 ANSI 标准的数据库中受支持,因为这些数据库都支持事务。事务与符合 XA 的外部数据源的协调在未登录的数据库中不受支持。
可使用以下 DDL 语句,它们是用于管理 XA 数据源类型和数据源的 SQL 语句的扩展:
| 语句 | 描述 |
|---|---|
| CREATE XADATASOURCE TYPE | 创建符合 XA 的外部数据源类型 |
| CREATE XADATASOURCE | 创建符合 XA 的外部数据源实例 |
| DROP XADATASOURCE | 删除符合 XA 的外部数据源实例 |
| DROP XADATASOURCE TYPE | 删除符合 XA 的外部数据源类型 |
有关这些语句的更多信息,请参阅《GBase 8s SQL 指南:语法》 。
GBase 8s 和符合 XA 的外部数据源之间的交互通过一组用户定义且支持 XA 的例程(例如,xa_open、xa_end、 xa_commit 和 xa_prepare)执行。可在使用 CREATE XADATASOURCE TYPE 语句之前创建这些支持例程。
在创建了符合 XA 的外部数据源之后,可使用 mi_xa_register_xadatasource()(或 ax_reg())和 mi_xa_unregister_xadatasource()(或ax_unreg())函数将该数据源注册到当前事务和注销该数据源。在分布式环境中,必须在本地协调者服务器上注册数据源。注册是瞬态的,持续时间仅仅是该事务的持续时间。
使用以下 onstat 选项可显示有关包含符合 XA 的数据源的事务的信息:
| onstat 选项 | 此命令显示的符合 XA 的数据源信息 |
|---|---|
| onstat -x | 显示有关事务中的 XA 参与者的信息。 |
| onstat -G | 显示有关全局事务中的 XA 参与者的信息。 |
| onstat -g ses session id | 显示会话信息,包括有关参与事务的 XA 数据源的信息。 |
高可用性集群中的 XA
X/Open 分布式事务处理 (DTP) 模型允许高可用性集群中的可更新辅助服务器在分布式事务中充当资源管理器。
任何 XA 全局事务中的参与者有三种:
- 应用程序 (AP):定义事务界限,并指定构成事务分支的操作。
- 资源管理器 (RM):提供对资源(如数据库)的访问。
- 事务管理器 (TM):为事务分支指定标识 (XID),监视事务进度,以及协调事务分支以完成操作和实现故障恢复。
在高可用性集群中,会话可以从集群中的任何服务器创建事务分支或附加到事务分支。例如,可从 server_2 附加已从 server_1 分离的事务分支。应用程序可在不跟踪启动事务的服务器的情况下,使用连接管理器连接到集群。事务管理器也可以使用连接管理器连接到集群,以完成 XA 事务,方法是对松散和紧密耦合的事务均执行落实、回滚或忽视(请参阅松耦合与紧耦合方式)。
所有从辅助服务器启动的全局事务分支都将使用现有代理接口重定向到主服务器。 主服务器启动和维护所有事务分支,并执行与分支关联的所有请求工作。
在可更新辅助服务器上启动了 XA 事务时,主服务器上也将启动相应的 XA 事务。主服务器上的 XA 事务执行 XA 事务的整个生命周期(启动、结束、准备以及落实或回滚)。 辅助服务器上的 XA 事务用于支持未重定向到主服务器的查询。发出对 xa_end() 函数的调用时,系统将释放 XA 事务,并将用户会话从 XA 事务分离。所有 XA 事务请求和 XA 事务内发出的所有写操作都将重定向到主服务器。
以下功能特定于GBase 8s XA 实施:
- 所有 XA 接口请求在可更新的辅助服务器上均可用(请参阅辅助服务器上的数据库更新)。
- 支持从可更新的辅助服务器启动、准备以及落实或回滚 XA 事务。
- 支持 xa_recover() 函数,该函数用于从资源管理器获取已就绪事务分支的列表。
- 支持在高可用性集群服务器中执行 XA 事务分支迁移。集群中的任何服务器均可附加到 XA 事务分支,而不考虑事务分支是否源自该服务器。
- XA 客户机和事务管理器可使用连接管理器连接到任何高可用性集群服务器(请参阅连接管理)。
- 支持将 XA 请求从辅助服务器重定向到主服务器。
- 支持对 XA 事务执行事务挽救(请参阅在集群故障转移期间完成事务)。
- 如果运行已重定向的 XA 事务的辅助服务器出现故障,将回滚事务。
- 支持在 XA 环境内运行,但位于 XA 事务外的 SQL 事务。
在辅助服务器上运行的 XA 事务有以下限制:
- 不支持从其他用户会话(在相同或不同辅助服务器上)恢复暂挂的全局事务分支。
- 用户会话不能附加到与另一个辅助服务器上的其他用户会话关联的全局事务分支。
- XA 事务与辅助服务器上的其他数据具有相同的限制。请参阅辅助服务器上的数据库更新。
- XA 事务不能在只读辅助服务器上启动。 如果应用程序尝试在只读辅助服务器上创建新的 XA 事务,将收到 XA 错误代码 XAER_RMERR。此外,在只读辅助服务器上运行 xa_prepare()、xa_commit() 或 xa_rollback() 将返回错误代码 XA_NOTA (-4)。
- 只读辅助服务器上支持以下 XA API:
- xa_open()
- xa_close()
如果要将 .NET Framework 用于 Microsoft™ Transaction Server 以管理高可用性集群中的 XA 事务,那么必须使用 TransactionScope 类而非 ServiceConfig 类。TransactionScope 类可用于 .NET Framework 3.5。
松耦合与紧耦合方式
数据库服务器支持松耦合及紧耦合方式的 XA 全局事务:
- 松耦合方式表示不同的数据库服务器可协调事务,但不可共享资源。 来自事务的所有分支的记录分别作为独立事务显示在逻辑日志中。
- 紧耦合方式表示不同的数据库服务器可协调事务并且共享诸如锁定和日志记录这些资源。 来自事务的所有分支的记录作为同一事务显示在逻辑日志中。
BEA Systems 提供的 Tuxedo 事务管理器支持松耦合方式。
两阶段落实协议
两阶段落实协议在执行事务期间发生系统或介质故障的情况下提供自动恢复机制。两阶段落实协议确保所有参与的数据库服务器接收并执行同一操作(落实或回滚事务),而不论是否有本地或网络故障。
如果有任何数据库服务器无法落实它这一部分的事务,那么一定会阻止参与该事务的所有数据库服务器落实各自的工作。
何时使用两阶段落实协议
数据库服务器对任何在多个数据库服务器上修改数据的事务自动使用两阶段落实协议。
例如,假设连接了三台名为australia、italy和 france的数据库服务器,如下图所示。
图: 已连接的数据库服务器
 如果运行以下示例中显示的命令,那么结果是在三台不同的数据库服务器上执行一次更新和两次插入。
如果运行以下示例中显示的命令,那么结果是在三台不同的数据库服务器上执行一次更新和两次插入。
CONNECT TO stores_demo@italy
BEGIN WORK
UPDATE stores_demo:manufact SET manu_code = 'SHM' WHERE manu_name = 'Shimara'
INSERT INTO stores_demo@france:manufact VALUES ('SHM', 'Shimara', '30')
INSERT INTO stores_demo@australia:manufact VALUES ('SHM', 'Shimara', '30')
COMMIT WORK
两阶段落实概念
每个全局事务均有一个协调者和一个或多个参与者,定义如下:
-
协调者可指导全局事务的解决方案。它决定全局事务是必须落实还是必须停止。
两阶段落实协议始终将协调者的角色分配至当前数据库服务器。在单个事务期间,协调者的角色无法更改。 在何时使用两阶段落实协议 中的样本事务中,协调者是 italy。如果您将该示例中的第一行更改为以下语句,那么两阶段落实协议将协调者的角色分配至 france:
CONNECT TO stores_demo@france使用 onstat -x 选项显示分布式事务的协调者。有关更多信息,请参阅监视全局事务。
-
每个参与者指示一个事务分支的执行,事务分支是涉及单个本地数据库的那部分全局事务。全局事务在以下情况中包含几个事务分支:
- 应用程序使用多个进程为全局事务工作
- 多个远程应用程序为同一全局事务工作
在何时使用两阶段落实协议 中,参与者是 france 和 australia。协调者数据库服务器 italy 也起着参与者的作用,因为它也在进行更新。
两阶段落实协议依赖两种通信,消息和逻辑日志记录:
- 消息在协调者和每个参与者之间传递。 来自协调者的消息包括事务标识号和指示信息(如 prepare to commit、commit 或 roll back)。来自每个参与者的消息包括事务状态和所采取操作的报告(如 can commit 或 cannot commit、committed 或 rolled back)。
- 事务的逻辑日志记录保留在磁盘或磁带上以确保即使在参与的数据库服务器(参与者或协调者)上发生故障时的数据完整性和一致性。
有关更多的详细信息,请参阅两阶段落实和逻辑日志记录。
两阶段落实协议的阶段
在两阶段落实事务中,协调者将所有数据修改指示信息(例如,插入)发送至所有参与者。然后,协调者启动两阶段落实协议。两阶段落实协议分两部分,预落实阶段和后决策阶段。
预落实阶段
在预落实阶段期间,协调者和参与者执行以下对话:
协调者
协调者指导每个参与者数据库服务器准备落实事务。
参与者
每个参与者通知协调者它是否可落实其事务分支。
协调者
协调者根据每个参与者的响应来决定落实还是回滚事务。它仅当所有参与者指示它们可以落实各自的事务分支时才决定落实。如果有任何参与者指示它尚未准备好落实其事务分支(或如果它未响应),那么协调者将决定结束全局事务。
后决策阶段
在后决策阶段期间,协调者和参与者执行以下对话:
协调者
协调者将落实记录或回滚记录写入协调者的逻辑日志,然后指示每个参与者数据库服务器落实或回滚事务。
参与者
如果协调者发出落实消息,那么参与者通过将落实记录写入逻辑日志并将消息发送至协调者(确认事务已落实)来落实事务。 如果协调者发出回滚消息,那么参与者回滚事务,但不向协调者发送确认。
协调者
如果协调者发出消息以落实事务,它将在结束全局事务前一直等待以接收来自各参与者的确认。如果协调者发出消息以回滚事务,它将不等待参与者的确认。
两阶段落实协议如何处理故障
两阶段落实协议设计为用可保留所有参与的数据库服务器上的数据完整性的方式来处理系统和介质故障。如果发生故障,两阶段落实协议执行自动恢复。
自动恢复处理的故障类型
以下事件可能导致协调线程或参与者线程终止或挂起,因此需要自动恢复:
- 协调者的系统故障
- 参与者的系统故障
- 网络故障
- 管理员终止协调线程
- 管理员终止参与者线程
管理员在自动恢复中的角色
自动恢复中管理员的唯一角色是在系统或网络故障后将协调者和/或参与者恢复在线。
慢速网络无法触发自动恢复。除非协调者系统发生故障、网络发生故障或管理员终止协调线程,否则此处描述的恢复机制均不会生效。
协调者故障的自动恢复机制
如果协调线程发生故障,各参与者数据库服务器必须决定在其落实或回滚事务之前还是在其回滚事务之后启动自动恢复。此职责是假定结束的优化的一部分。 (请参阅假定结束的优化。)
参与者故障的自动恢复机制
无论何时参与者线程预落实了在两阶段落实协议可完成之前就终止的一项工作,就会发生参与者恢复。参与者恢复的目标是根据协调者作出的决定来完成两阶段落实协议。
根据协调者是决定落实还是回滚全局事务,参与者恢复可由协调者或者参与者驱动。
要在跨服务器事务打开的同时支持下级服务器关闭或重新启动之后的自动恢复,sqlhosts 文件必须为可能启动分布式操作的每个数据库服务器包含一个条目。在自动恢复期间,协调者的名称从逻辑日志恢复,且下级服务器与协调者重新连接以完成该事务。由于协调者总是使用自己的 onconfig 文件的 DBSERVERNAME 配置参数中的名称来向各参与者标识它自己,因此协调者的 DBSERVERNAME 设置必须是参与者都已知的因特网协议连接名称,但是也可使用正确的连接协议,为协调者和下级服务器之间的连接至少定义一个 DBSERVERALIASES 设置。下级服务器必须能够使用协调者的 DBSERVERNAME 设置或 DBSERVERALIASES 设置连接到该协调者。
假定结束的优化
假定结束的优化是描述两阶段落实协议如何处理事务回滚的术语。
回滚是按以下方式处理的。当协调者确定事务必须回滚时,它发送消息给所有的参与者以回滚它们的工作片段。 协调者不会等待该消息的确认,而是继续进行以关闭事务并将其从共享内存中除去。如果参与者尝试确定该事务的状态,即查明事务已落实还是已回滚(例如:在参与者恢复期间)- 它将在共享内存中找不到任何事务状态。参与者必定将此解释为表示事务已回滚。
独立操作
两阶段落实环境中的独立操作是一种独立于两阶段落实协议而发生的操作。独立操作可能与两阶段落实协议指定的操作相对立,也可能不对立。如果操作是与两阶段落实协议相对立,那么操作会导致错误或启发式决策。启发式决策可能导致不一致的数据库,并且需要手动的两阶段落实恢复。手动恢复是非常复杂的管理过程,必须尽量避免。(有关手动恢复过程的说明,请参阅从失败的两阶段落实手动恢复。)
启动独立操作的情境
两阶段落实协议期间的独立操作很少见,但它可能会发生在以下情况中:
- 参与者的工作片段发展成长事务错误并回滚。
- 管理员在协议的后决策阶段使用 onmode -z 停止参与者线程。
- 管理员在协议的后决策阶段使用 onmode -Z 结束参与者事务(工作片段)。
- 在协调者发出落实决策并知道参与者故障之后,管理员使用 onmode -z 或 onmode -Z 结束了协调者数据库服务器上的全局事务。该操作始终会导致错误,尤其是错误 -716。
独立操作的可能结果
如前所述,不是所有的独立操作与两阶段落实协议相对立。独立操作可能会产生以下三种可能的结果:
- 成功完成两阶段落实协议
- 错误状况
- 启发式决策
如果操作不是与两阶段落实协议相对立,那么事务将正常落实或回滚。如果操作过早结束全局事务,会导致错误状况。在协调者上结束全局事务不会被视为启发式决策。如果操作与两阶段落实协议相对立,那么会导致启发式决策。 所有这些情况均在随后各节中进行说明。
允许事务成功完成的独立操作
独立操作不一定需要与两阶段落实协议相对立。例如,如果参与者数据库服务器上的工作片段因为发展成长事务而回滚,并且协调者发出回滚全局事务的决策,那么数据库将保持一致。
导致错误条件的独立操作
如果您(作为协调者数据库服务器管理员)在协调者发出其最终的落实决策后运行 onmode -z(停止协调者线程)或 onmode -Z(停止全局事务),那么将从协调者数据库服务器上的共享内存中除去所有事务的信息。
该操作不会被视为启发式决策,因为它不干扰两阶段协议;它可能是可接受的,或可能干扰了参与者恢复并导致错误。
在所有参与者可以毫无困难地落实事务的任何时候,该操作均是可接受的。在这种情况下,强制结束事务的操作是多余的。仅当协调者准备终止事务时,才会收到您运行了 onmode -Z 的指示。
但实际上,仅当您要尝试加快结束保持打开时间异常长的全局事务时,才可能会考虑在协调者数据库服务器上运行 onmode -z 或 onmode -Z。在这种情况中,问题的来源可能是某些参与者数据库服务器上发生的故障。协调者尚未接收到参与者落实其工作片段的确认,而协调者正在尝试建立与参与者的通信以进行调查。
如果您在协调者正主动尝试重新建立通信的同时运行 onmode -z 或 onmode -Z,那么协调线程会遵循您的指令而终止,但终止之前它会将错误 -716 写入数据库服务器消息日志。该操作被视为错误,这是因为两阶段落实协议被强制中断,使协调者不能确定数据库是否一致。
在协调者数据库服务器上停止全局事务不会被视为启发式决策,但它可能导致不一致的数据库。例如,如果参与者最终恢复在线但在协调者共享内存中找不到全局事务,它将回滚其工作片段,从而导致数据库不一致。
导致启发式决策的独立操作
当以下两个条件都成立时,有些独立操作会发展成启发式决策:
- 参与者数据库服务器已经将 can commit 消息发送到协调者并随后回滚。
- 协调者的决定是落实事务。
当两个条件都成立时,最终结果就是未一致实现的全局事务(由一个或多个数据库服务器落实但由另一数据库服务器回滚)。数据库变得不一致。
以下是两个可能的启发式决策:
- 启发式回滚(在启发式回滚场景中有描述)
- 启发式结束事务(在启发式结束事务场景中有描述)
在发生启发式回滚或结束事务之后,可能必须执行手动恢复,这是一个复杂耗时的过程。必须完全了解启发式决策,以便避免这些问题。在两阶段落实的上下文中运行 onmode -z 或 onmode -Z 务必谨慎。
启发式回滚场景
在启发式回滚中,数据库服务器或管理员回滚已经发送了 can commit 消息的工作片段。
导致启发式回滚的条件
以下两个条件可能导致启发式回滚:
- 逻辑日志填充至 LTXEHWM 配置参数定义的点。(请参阅《GBase 8s 管理员参考》 中有关配置参数的主题。)长事务状况的来源是正代表全局事务执行的工作片段。
- 管理员执行 onmode -z session_id 以停止数据库服务器线程,该线程正在执行代表全局事务而执行的工作片段。
在任一情况中,如果该工作片段已经向其协调者发送了 can commit 消息,那么该操作被视为启发式决策。
条件 1:逻辑日志填充至高水位标志
在两阶段落实中,将阻拦正在等待协调者指令的参与者数据库服务器完成其事务。因为事务保持打开,所以包含与该事务相关联的记录的逻辑日志文件无法释放。结果是逻辑日志由于并发用户的活动而继续填充。
如果当参与者正在等待时,逻辑日志填充至长事务高水位标志的值 (LTXHWM),那么数据库服务器将指导所有拥有长事务的数据库服务器线程开始回滚这些长事务。如果预落实的工作片段就是该违规的长事务,那么数据库服务器启动启发式回滚。也就是说,该数据库服务器在没有协调者的指令或协调者不知道的情况下正在回滚预落实的工作片段。
在两阶段落实中,包含与该工作片段相关联的记录的逻辑日志文件视为打开,直到写入 ENDTRANS 逻辑日志记录。该类型的事务与涉及单个数据库服务器的事务(其中回滚实际关闭事务)不同。
逻辑日志可能继续填充直至达到互斥高水位标志 (LTXEHWM)。如果发生这种情况,所有用户线程暂挂,但当前回滚或当前落实的那些线程除外。在两阶段落实应用场合中,打开的事务使您不能备份逻辑日志文件以及释放逻辑日志中的空间。在这些特殊情况下,逻辑日志可以完全填充。如果发生这种情况,那么参与者数据库服务器关闭,且您必须执行数据复原。
条件 2:系统管理员执行 onmode -z
您(作为管理员)可以决定通过运行 onmode -z 来启动预落实工作片段的启发式回滚。 您可能因为希望释放该工作片段拥有的资源而作出该决策。(如果通过运行 onmode -z 停止参与者线程,那么即便您没有结束事务,也会释放参与者线程拥有的所有锁定和共享内存资源。)
启发式回滚的结果
这些主题描述了在发生启发式回滚时协调者和参与者上所发生的事件,以及此过程如何会导致不一致的数据库:
在发生回滚的参与者数据库服务器上,记录放置在数据库服务器逻辑日志(HEURTX 类型)中。事务拥有的锁和资源得以释放。参与者线程将以下消息写入数据库服务器消息日志,指示发生了长事务状况和回滚:
Transaction Completed Abnormally (rollback):
tx=address flags=0xnn
协调者发出后决策阶段指令以落实事务。
发生启发式回滚的数据库服务器上的参与者线程将错误消息 -699 返回至协调者,如下所示:
-699 Transaction heuristically rolled back.
此时该错误消息不返回至应用程序;它对协调者来说是条内部通知。协调者等待至所有参与者响应该落实指令。 直至所有参与者报告后协调者才能确定数据库一致性。
接下去的步骤取决于发生在其他参与者上的操作。可能有两种情境。
情境 1:协调者发出落实并且所有参与者都报告启发式回滚
协调者收集所有来自参与者的响应。如果每个参与者报告启发式回滚,那么后果是会发生以下事件:
-
协调者将以下消息写入其自己的数据库服务器消息日志:
Transaction heuristically rolled back. -
协调者向所有的参与者发送消息以结束事务。
-
每个参与者都将 ENDTRANS 记录写入其逻辑日志缓冲区中。 (从事务表中除去该事务条目。)
-
协调者将错误 -699 返回至应用程序,如下所示:
-699 Transaction heuristically rolled back. -
在这种情况下,所有数据库保持一致。
情境 2:协调者已发出落实;有一个参与者落实并有一个参与者报告启发式回滚
协调者收集所有来自参与者的响应。如果至少一个参与者报告启发式回滚并且至少一个参与者报告确认落实,那么该结果称为混合事务结果。后果是发生以下事件:
-
协调者将以下消息写入其本身的数据库服务器消息日志:
Mixed transaction result. (pid=nn user=userid)pid 值是协调者过程的用户过程标识号。 user 值是与协调者进程相关联的用户标识。与该消息相关联的是附加消息,这些附加消息列出每个报告了启发式回滚的参与者数据库服务器。附加消息采用以下形式:
Participant database server dbservername heuristically rolled back. -
协调者向每个启发式回滚其工作片段的参与者发送消息,指导各参与者结束事务。
-
每个参与者都将 ENDTRANS 消息写入其逻辑日志缓冲区中。 (从事务表中除去该事务条目。)
-
协调者将 ENDTRANS 消息写入其逻辑日志缓冲区中。 (从共享内存事务表中除去该事务条目。)
-
协调者将错误 -698 返回至应用程序,如下所示:
-698 Inconsistent transaction. Number and names of servers rolled back. -
与该错误消息相关联的是报告了启发式回滚的参与者数据库服务器的列表。如果大量数据库服务器回滚该事务,此列表可能会被截断。完整的列表始终包含在协调者数据库服务器的消息日志中。
在这种情况中,检查每个参与者数据库服务器站点上的逻辑日志并确定您的数据库系统是否一致。(请参阅确定事务是否不一致地实现。)
启发式结束事务场景
启发式结束事务是管理员采取的独立操作,以便回滚工作片段并从事务表中除去所有有关事务的信息。当管理员执行 onmode -Z address 命令时会启动启发式结束事务进程。
每当通过运行 onmode -Z 来启动启发式结束事务,都会除去数据库服务器支持两阶段落实协议及其自动恢复功能所需的关键信息。如果运行 onmode -Z,那么您应负责确定您的联网数据库系统是否一致。
何时执行启发式结束事务
仅在一种很少见的情况下,才必须运行 onmode -Z 选项来启动启发式结束事务。 当已启发式回滚的工作片段保持打开时会发生这种情况,它会使您的逻辑日志文件不能成为可用的文件。结果,逻辑日志将十分接近填满,这很危险。
通常,协调者会在合理时间段内发出其落实或回滚决策。 但是,如果协调者发生故障,不返回在线状态以结束在参与者数据库服务器上启发式回滚的事务,您可能会面临严重的问题。
问题应用场合以如下方式开始:
- 代表全局事务执行工作片段的参与者线程已向协调者发送 can commit 响应。
- 工作片段等待来自协调者的指令。
- 当工作片段正在等待时,逻辑日志填充超过长事务高水位标志。
- 正在等待指令的工作片段是长事务的来源。参与者数据库服务器指导执行线程回滚该工作片段。该操作就是启发式回滚。
- 参与者继续等待协调者指导其结束事务。事务保持打开。逻辑日志继续填充。
如果协调者联系参与者并指导其在合理的时间段内结束事务,那么不会产生任何问题。 如果在参与者数据库服务器上发生启发式回滚并且随后协调者发生故障,致使协调者不能指导参与者结束事务,那么会发生严重问题。
结果,事务保持打开。打开的事务使您不能备份逻辑日志文件以及释放逻辑日志中的空间。当逻辑日志继续填充时,它可能会达到互斥存取长事务高水位标志 (LTXEHWM) 指定的点。如果到达该点,正常的处理将暂挂。在到达高水位标志后的某个时刻,您必须判定打开的事务是否在危及您的逻辑日志。危险就是如果逻辑日志完全填满,那么数据库服务器关闭,并且您必须执行数据复原。
您必须决定是结束事务并保护您的系统不会有填满逻辑日志的可能性(而不考虑所有与运行 onmode -Z 相关联的问题),还是等着查看是否能及时重新建立与协调者的通信,以便在逻辑日志填满前结束事务。
如何使用 onmode -Z
只有在协调者和参与者之间的通信中断时,才会考虑使用 onmode -Z address 命令。为了确保该通信真正中断,在正执行工作片段的线程由于超过 TXTIMEOUT 指定的时间量而终止之前,onmode -Z 命令不会运行。 有关此选项的更多信息,请参阅《GBase 8s 管理员参考》。
address 参数可从 onstat -x 输出中获取。有关 onstat -x 选项的更多信息,请参阅《GBase 8s 管理员参考》。
启发式结束事务时执行的操作
运行 onmode -Z 时,您指示 onmode 实用程序从事务表中除去了位于指定地址的参与者事务条目。
逻辑日志中写入了两条记录以记载该操作。 记录类型为 ROLLBACK 和 ENDTRANS,或如果事务已经启发式回滚,那么仅有类型 ENDTRANS。以下消息写入参与者数据库服务器消息日志:
(time_stamp) Transaction Completed Abnormally (endtx): tx=address flags:0xnn user username tty ttyid
协调者接收来自发生了 onmode -Z 的参与者的错误消息以作为其对 COMMIT 指令的响应。协调者查询参与者数据库服务器,该服务器不再有有关事务的消息。参与者数据库服务器上缺少事务表条目就表明事务已落实。 协调者假设参与者已发送确认消息,但由于某种原因未接收到该消息。因为协调者不知道此参与者的工作片段未落实,所以未生成指示全局事务不一致实现的消息。只有运行 onmode -Z 命令的管理员才会知道实现不一致。
监视全局事务
使用 onstat -x 命令跟踪开放事务并确定它们是否已经启发式回滚。
例如,在输出中,flags 字段中的 H 标志标识启发式回滚,G 标志标识全局事务,L 标志指示松耦合方式,而 T 标志指示紧耦合方式。
curlog 和 logposit 字段提供逻辑日志记录的准确位置。 如果事务未在回滚,那么 curlog 和 logposit 描述最近写入的日志记录。当事务在回滚时,这些字段描述最近“撤销”的日志记录。在事务回滚时,curlog 和 logposit 值会减少。在长事务中,logposit 和beginlg 的值汇聚的速率可帮助您估计回滚将需要的更多时间量。
有关 onstat -x 输出的更多信息及其示例,请参阅《GBase 8s 管理员参考》。
还可以使用 onstat -u 和 onstat -k 命令跟踪事务以及它们保存的锁。有关 onstat -x 显示的字段的描述,请参阅《GBase 8s 管理员参考》。
在辅助服务器上,当启用了故障转移后完成事务(通过设置 FAILOVER_TX_TIMEOUT 配置参数)时,两个全局事务可能有相同的全局事务标识:一个是本地临时全局事务,另一个是属于恢复线程的全局事务。快速区分真正的全局事务与临时事务的方法是,如果真正的事务执行了任何操作,将有一个 B 标志。也可通过使用 onstat -g ath 命令来检查事务的所有者。调用了 xa_end() 函数之后,将删除辅助服务器上的临时全局事务。
以下 onstat 实用程序的示例输出说明了高可用性集群环境中主服务器和辅助服务器上对 XA 事务的支持。onstat -x、onstat -G 和 onstat -ath 命令会单独记录,但是组合的 onstat -xG 命令的输出专门针对全局事务。示例显示了重定向事务的每种状态。
在示例中,所显示的在辅助服务器上运行的全局事务是临时事务。临时事务用于支持在辅助服务器上执行的 SQL 语句(而非重定向到主服务器的事务)。仅当用户线程主动与全局事务分支关联时,才会显示临时事务。
以下示例显示运行 xa_start() 函数之后在辅助服务器上运行的 onstat -xG 命令生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d4190 AT--G 7000000104a7b68 0 - - LC - 0
7000000104d8bd0 ALB-G 7000000104a5aa8 1 180:0x0 180:0x4eb018 DIRTY 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d4190 AT--G COMMIT 0 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
7000000104d8bd0 ALB-G DIRTY 0 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
在辅助服务器上运行的 onstat -g ath 生成的输出:
Threads:
tid tcb rstcb prty status vp-class name
317 7000001500902c8 7000000104a7b68 1 cond wait netnorm 1cpu sqlexec
84 7000001403a7dc0 7000000104a5aa8 3 sleeping secs: 1 5cpu xchg_2.0
在主服务器上运行的 onstat -xG 生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d9e60 ATB-M 7000000104a8bc8 2 180:0x4ea018 180:0x4eb018 COMMIT 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d9e60 AT--M COMMIT 0 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
以上示例中的 M 标志指示全局事务是从辅助服务器启动的。在主服务器上启动的全局事务会显示 G 标志。M 标志仅在主服务器上显示。
onstat -g ath|grep 7000000104a8bc8 命令生成的输出:
196 70000013012d3a8 7000000104a8bc8 1 sleeping secs: 1 4cpu proxyTh
以下示例显示运行 xa_end() 函数之后在辅助服务器上运行 onstat -xG 命令生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d8bd0 ALB-G 7000000104a5aa8 1 180:0x0 180:0x4ee018 DIRTY 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d8bd0 ALB-G DIRTY 0 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
在主服务器上运行 onstat -xG 命令生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d9e60 -TB-M 0 2 180:0x4ea018 180:0x4ee018 COMMIT 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d9e60 -T--M COMMIT -1 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
运行 xa_prepare() 函数之后在辅助服务器上运行 onstat -xG 命令生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d8bd0 ALX-G 7000000104a5aa8 1 180:0x0 180:0x4ef018 DIRTY 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d8bd0 ALX-G DIRTY 0 5067085 15 4 000102030405060708090A0B0C0D0E0F000000
在主服务器上运行 onstat -xG 命令生成的输出:
Transactions
est.
address flags userthread locks begin_logpos current logpos isol rb_time retrys coord
7000000104d9e60 -TX-M 0 2 180:0x4ea018 180:0x4ef018 COMMIT 0:00 0
Global Transaction Identifiers
address flags isol timeout fID gtl bql data
7000000104d9e60 -TX-M COMMIT -1 5067085 15 4 0
两阶段落实协议错误
以下两阶段落实协议错误需要管理员特别加以注意。
错误号 描述
-698
如果您接收到错误 -698,那么说明已发生启发式回滚,并已导致未一致实现的事务。启发式回滚的结果中描述了导致该事件的环境。有关不一致事务如何发展的说明并了解您可用的选项,请参阅这些信息。
-699
如果您接收到错误 -699,那么说明已发生启发式回滚。启发式回滚的结果中描述了导致该事件的环境。有关不一致事务如何发展的说明,请参阅这些信息。
-716
如果您接收到错误 -716,那么说明协调线程已在其发出最后决定后被管理员终止。在导致错误条件的独立操作中描述了该应用场合。
两阶段落实和逻辑日志记录
数据库服务器使用逻辑日志记录实现两阶段落实协议。您可以使用这些逻辑日志记录来检测启发式决策并(如有必要)帮助您执行手动恢复。(请参阅从失败的两阶段落实手动恢复。)
分布式事务中包括以下逻辑日志记录:
- BEGPREP
- PREPARE
- TABLOCKS
- HEURTX
- ENDTRANS
有关这些逻辑日志记录的信息,请参阅《GBase 8s 管理员参考》中有关解释逻辑日志记录的章节。
本节将检查在以下数据库服务器应用场合期间写入的逻辑日志记录的顺序:
事务落实时的逻辑日志记录
下图说明了在生成已落实事务的成功两阶段落实协议期间逻辑日志记录的写入顺序。
图: 已落实事务期间写入的逻辑日志记录
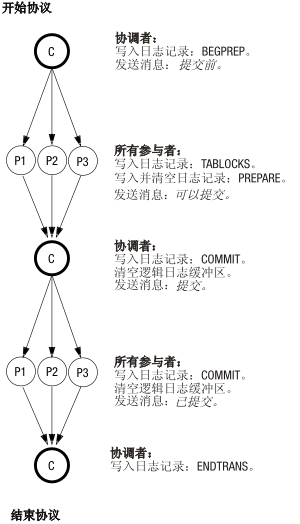
有些逻辑日志记录必须立即从逻辑日志缓冲区清空;对于另外一些记录,清空却不是关键的。
协调者的落实工作记录(COMMIT 记录)包含启动两阶段落实协议所需的所有信息。它还在协调者的主机上发生故障的情况下充当自动恢复的起点。因为该记录对于恢复很关键,所以不允许它保留在逻辑日志缓冲区中。协调者必须立即清空 COMMIT 逻辑日志记录。
上图中的参与者必须立即清空 PREPARE 和 COMMIT 这两条逻辑日志记录。清空 PREPARE 记录可确保快速恢复能在参与者的主机发生故障时,确定此参与者是否为全局事务的一部分。 作为恢复的一部分,参与者可以查询协调者以了解该事务的最终布置。
清空参与者的 COMMIT 记录可确保在参与者的主机发生故障时,参与者具有关于事务的所执行操作的记录。要理解该信息为何至关重要,请考虑在写入 PREPARE 记录之后但在清空 COMMIT 记录之前参与者崩溃的情况。在快速恢复后,PREPARE 记录得以复原,但 COMMIT 记录丢失(因为在发生故障时它位于逻辑日志缓冲区中)。PREPARE 记录的存在将启动对协调者的有关事务的查询。但是,协调者会对该事务一无所知,因为协调者在接收到参与者的确认(已执行落实)后就结束了事务。在这种情况中,参与者将把缺少信息解释为回滚事务的最后指示。两阶段落实协议需要立即清空参与者的 COMMIT 记录,以防止出现此类误解。
启发式回滚期间写入的逻辑日志记录
下图说明了数据库服务器在启发式回滚期间写入逻辑日志记录的顺序。 因为只有在参与者发送了消息说明其可以落实,并且协调者发送了消息去落实之后,才会执行启发式回滚,所以此协议的第一个阶段与图 1 中所示相同。当执行启发式回滚时,会假设回滚是由于参与者 1 (P1) 数据库服务器上发生长事务状况而导致的。最终结果是不一致实现的事务。请参阅启发式回滚场景。
图: 启发式回滚期间写入的逻辑日志记录
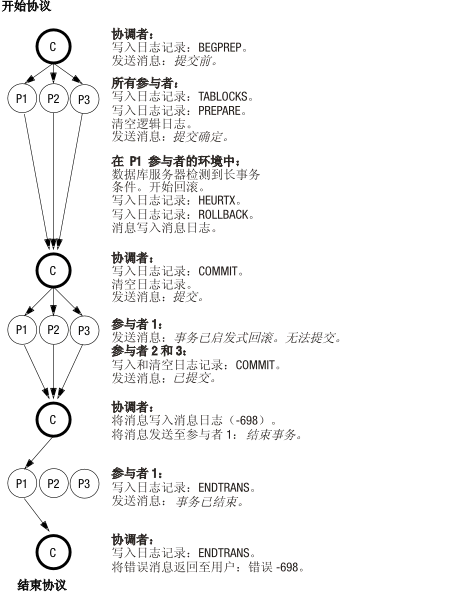
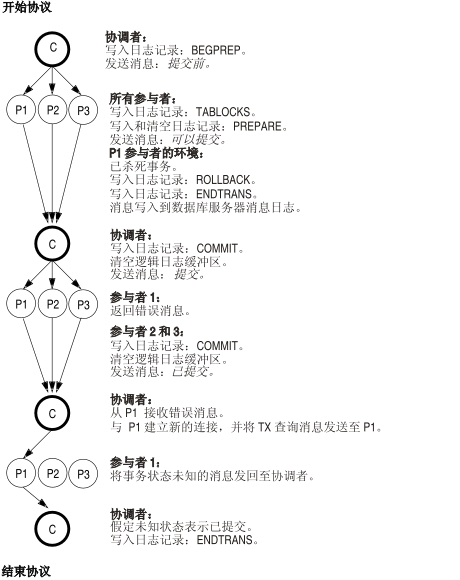
启发式结束事务后写入的逻辑日志记录
下图说明了启发式结束事务期间逻辑日志记录的写入顺序。事件始终是在参与者发送了 can commit 消息后,数据库服务器管理员在参与者数据库服务器上结束事务(请参阅《GBase 8s 管理员参考》中有关 onmode 实用程序的信息)的结果。在下图中,假设已在参与者 1 (P1) 数据库服务器上执行启发式结束事务。结果是未一致实现的事务。 请参阅启发式结束事务场景。
图: 启发式结束事务期间写入的逻辑日志记录
两阶段落实中使用的配置参数
以下两个配置文件参数是特定于分布式环境的:
- DEADLOCK_TIMEOUT
- TXTIMEOUT
虽然两个参数都指定了超时周期,但它们是互相独立的。有关这些配置参数的更多信息,请参阅《GBase 8s 管理员参考》。
DEADLOCK_TIMEOUT 参数的功能
如果强制分布式事务等待共享内存资源的时间超过 DEADLOCK_TIMEOUT 指定的秒数,那么拥有事务的线程会假设存在多服务器死锁。会返回以下错误消息:
-154 ISAM error: deadlock timeout expired - Possible deadlock.
DEADLOCK_TIMEOUT 的缺省值为 60 秒。调整该值时要小心。如果把该值设置得过低,各个数据库服务器会结束那些非死锁的事务。如果把该值设置得过高,那么多服务器死锁可能会减少并发性。
TXTIMEOUT 参数的功能
TXTIMEOUT 配置参数特定于两阶段落实协议。仅当事务协调者和参与者之间的通信被中断,并且必须重新建立时,才使用该参数。
TXTIMEOUT 参数指定参与者数据库服务器在分布式事务期间等待接收来自协调者数据库服务器的 commit 指令的时间段。如果过了 TXTIMEOUT 指定的时间段,那么参与者数据库服务器会检查事务的状态以确定参与者是否必须启动自动参与者恢复。
TXTIMEOUT 以秒为单位指定。缺省值为 300(5 分钟)。该参数的最佳值将根据您的特定环境和应用程序而变化。修改此参数之前,请阅读两阶段落实协议如何处理故障中的说明。
异类落实协议
术语“异类环境”在用于 GBase 8s 数据库服务器环境中时,是指其中至少有一个数据库服务器不是 GBase 8s 数据库服务器的数据库服务器组。异类落实可确保异类环境中分布式事务的全有或全无的基础。
与两阶段落实协议不同,异类落实协议支持非 GBase 8s 参与者的参与。非 GBase 8s 参与者(称为网关参与者)必须通过 GBase 8s 网关与协调者通信。
当满足了以下条件时,数据库服务器将使用异类落实协议:
- 异类落实已启用。(即,HETERO_COMMIT 配置参数设置为 1。)
- 落实的协调者是 V8.5 版本的 GBase 8s。
- 非 GBase 8s 参与者通过 GBase 8s 网关与 GBase 8s 数据库服务器通信。
- 在单个事务中至多有一个非 GBase 8s 参与者执行更新。
下图说明了此场景。
图: 需要对分布式事务执行异类落实的配置
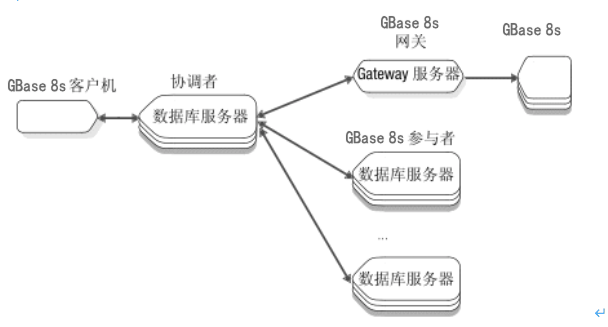
可参与异类落实事务的网关
网关充当 GBase 8s 应用程序(在本例中是数据库服务器)和非 GBase 8s 数据库服务器之间的桥梁。可使用网关将 GBase 8s 应用程序用于访问和修改存储非 GBase 8s 数据库中存储的数据。
下表列出了可参与某事务(数据库服务器在该事务中使用异类落实协议)的网关和相应的数据库服务器。
表 1. 网关和相应的数据库服务器/异类落实事务
| 网关 | 数据库服务器 |
|---|---|
| GBase 8s Enterprise Gateway for EDA/SQL | EDA/SQL |
| GBase 8s Enterprise Gateway Manager | 任何具有 ODBC 连接的数据库服务器 |
启用和禁用异类落实
使用文本编辑器来更改启用或禁用异类落实的 HETERO_COMMIT 配置参数:此更改在关闭并重新启动数据库服务器后生效。
使用文本编辑器来更改启用或禁用异类落实的 HETERO_COMMIT 配置参数:更改的关闭并重新启动数据库服务器后生效。
如果将 HETERO_COMMIT 设置为 1,事务协调者会检查是否有需要使用异类落实的分布式事务。当协调者检测到这类事务,它会自动执行异类落实协议。
如果将 HETERO_COMMIT 设置为 0 或任何非 1 的数字,那么事务协调者将禁用异类落实协议。 下表总结事务协调者为确保分布式事务的完整性而使用哪一协议(异类落实还是两阶段落实)。
| HETERO_COMMIT 设置 | 网关参与者是否已更新 | 数据库服务器协议 |
|---|---|---|
| 已禁用 | 否 | 两阶段落实 |
| 已禁用 | 是 | 两阶段落实 |
| 已启用 | 否 | 两阶段落实 |
| 已启用 | 是 | 异类落实 |
异类落实的工作原理
异类落实协议是标准两阶段落实协议的修改版本。异类落实协议中的后决策阶段与两阶段落实协议的后决策阶段相同。预落实阶段则包含一处轻微修改,并且向异类落实协议添加了称为网关落实阶段的新阶段。
以下主题解释了对预落实阶段和网关落实阶段的修改。有关后决策阶段的详细说明,请参阅后决策阶段。
预落实阶段
协调者指导每个更新参与者(网关参与者除外)准备落实事务。
如果更新满足了所有延迟的约束,那么所有参与者(网关参与者除外)会将指示其可以提交各自的工作片段的消息返回至协调者。
网关落实阶段
如果所有参与者均成功返回了指示其已准备好落实的消息,那么协调者将落实消息发送至网关。接着,网关会将指示网关是否已落实它这部分事务的响应发送至协调者。如果网关落实了事务,协调者会决定落实整个事务。下图说明了此过程。
图: 生成已落实事务的异类落实阶段

如上图所示,如果网关未能落实事务,那么协调者将回滚整个事务。
异类落实优化
当唯一接收更新的参与者是非 GBase 8s 数据库时,数据库服务器将优化异类落实协议。在这种情况下,协调者将在不调用异类落实协议的情况下向所有参与者发送一条落实消息。
失败异类落实的含意
在分布式事务期间,任何时候数据库服务器使用异类落实进行处理,协调者或任意数目的参与者都可能发生故障。数据库服务器用与两阶段落实协议中所使用方法相同的方法来处理这些故障,但某些情况除外。以下主题详细分析了这些特殊情况。
数据库服务器协调者故障
协调者发生故障后数据的一致性取决于异类落实过程中协调者发生故障的时刻。如果协调者在向网关发送落实消息之前发生故障,那么一旦恢复后就停止整个事务,这与两阶段落实的情况相同。
如果协调者在写入落实日志记录之后发生故障,那么一旦恢复后就成功落实整个事务,这与两阶段落实的情况相同。
如果协调者在向网关发送落实消息之后但在写入落实日志记录之前发生故障,那么一旦恢复,事务中的远程 GBase 8s 数据库服务器站点将停止。如果网关接收到落实消息并落实了事务,那么这种情况可能会导致不一致。
下表总结了这些应用场合。
| 数据库服务器协调者发生故障的时间点 | 预期结果 |
|---|---|
| 在协调者写入 PREPARE 日志记录之后,但在网关落实阶段之前 | 维持了数据一致性。 |
| 在协调者向网关发送落实消息之后,但在它接收到答复之前 | 数据有可能不一致。协调者没有指示有可能数据不一致。 |
| 在网关落实阶段之后,但在协调者向逻辑日志写入 COMMIT 记录之前 | 失去数据一致性。协调者没有指示数据不一致。 |
参与者故障
无论何时使用异类协议的分布式事务中的参与者发生故障,协调者都将发送以下错误消息:
-441 Possible inconsistent data at the target DBMS name due to an aborted commit.
此外,数据库服务器还向消息日志发送以下消息:
Data source accessed using gateway name might be in an inconsistent state.
参与者故障并不限于数据库服务器或网关的故障。此外,协调者和网关之间的通信链接的故障被认为是网关故障。如果发生链接故障,那么网关将终止。网关必定会终止,因为它没有保留事务日志,因此无法重新建立与协调者的连接并重新开始事务。由于这种限制,所以存在一些应用场合,在这些应用场合中网关故障可能使数据处于不一致状态。 下表总结了这些应用场合。
| 参与者发生故障的时间点 | 预期结果 |
|---|---|
| 在参与者接收到来自协调者的落实事务消息之后,但在参与者执行落实之前 | 维持了数据一致性。 |
| 在参与者接收到来自协调者的落实事务消息并落实了事务之后,但在参与者回复协调者之前 | 数据不一致。 |
| 在参与者落实事务并向协调者发送回复之后 | 如果在协调者接收到回复之前通信链接发生故障,那么数据不一致。如果协调者接收到回复,那么数据是一致的(前提是协调者在写入 COMMIT 记录之前没有发生故障)。 |
当参与者发生故障时数据库服务器所遵循的恢复过程与两阶段落实中所遵循的过程相同。有关此过程的更多信息,请参阅两阶段落实协议如何处理故障。
异类落实错误消息的解释
当数据库服务器未能使用异类落实来处理分布式事务时,它将返回以下主题中说明的两个错误消息之一。
应用程序尝试更新多个网关参与者
当 HETERO_COMMIT 设置为 1 时,如果您的客户机应用程序尝试在多个网关参与者上更新数据,那么协调者将返回以下错误消息:
-440 Cannot update more than one non-GBase8s DBMS within a transaction.
如果您接收到该错误消息,可重写该违规的应用程序,以使它在单个分布式事务中至多更新一个网关参与者。
尝试使用异类落实来落实分布式事务失败
数据库服务器有可能因为以下一个或多个原因而导致在使用异类协议时未能落实分布式事务:
- 通信错误
- 站点故障
- 网关故障
- 其他未知错误
当发生这类故障时,协调者将返回以下消息:
-441 Possible inconsistent data at the target DBMS name due to an aborted commit.
在数据库服务器发送该消息后,它会回滚所有正在参与事务的更新站点,但网关参与者站点上完成的工作有可能出现异常。 如果故障发生在网关参与者处理落实消息之后,那么网关参与者可能已落实其更新。如果网关参与者落实了更新,您必须手动回滚这些更新。
从失败的两阶段落实手动恢复
分布式事务遵循两阶段落实协议。某些操作的发生独立于两阶段落实协议,就导致事务不一致地实现。(请参阅独立操作。)在这些情况中,可能需要从事务进行手动恢复。
确定是否需要手动恢复
以下主题概述了确定数据库一致性并更正相关情况(如果需要)的过程中的步骤。
以下主题中描述了其中每个步骤。
确定事务是否不一致地实现
首要任务是确定事务是否由于独立操作而不一致地实现。
全局事务过早结束
如果运行了 onmode -z 命令来结束协调者上的全局事务,那么事务可能会不一致地实现。(有关该情况会如何发生的说明,请参阅导致错误条件的独立操作。)您可以通过首先检查数据库服务器消息日志来检查协调者是否有不一致的事务。查找以下错误消息:
-716 Possible inconsistent transaction.
Unknown servers are server-name-list.
该消息列出所有充当参与者的数据库服务器。 检查每个参与者的逻辑日志。如果至少一个参与者执行了落实且一个参与者执行了回滚,那么事务不一致地实现。
启发式结束事务
如果运行了 onmode -Z address 命令来结束某个参与者执行的工作片段,并且协调者决定落实事务,那么事务将不一致地实现。(有关该应用场合的描述,请参阅启发式结束事务场景。)检查每个参与者的逻辑日志。如果至少一个参与者执行了落实且一个参与者执行了回滚,那么事务不一致地实现。
启发式回滚
您可以用以下方法来确定启发式决策所影响的特定数据库服务器参与者,从而回滚事务:
检查应用程序中 COMMIT WORK 语句的返回码。
-
以下消息指示有一个参与者执行了启发式回滚:
-698 Inconsistent transaction. Number and names of servers rolled back. -
检查数据库服务器消息日志文件的消息。
如果由于参与数据库服务器上的启发式决策导致有可能出现数据库不一致,那么协调者的数据库服务器消息日志文件中会出现以下消息:
Mixed transaction result. (pid=nn user=user_id)无论何时返回错误 -698,均会写入该消息。与该消息相关联的是事务回滚所涉及的参与者数据库服务器的列表。这是完整的列表。 如果大量参与者回滚了该事务,那么与 -698 错误消息一起创建的列表可能会被截断。
-
检查每个参与者的逻辑日志。
如果至少一个参与者回滚了其工作片段并且一个参与者落实了其工作片段,那么事务将不正确地实现。
确定分布式数据库是否包含不一致的数据
如果您确定事务是不一致地实现,您必须确定这种情况对您的分布式数据库系统意味着什么。您尤其必须确定数据完整性是否受到影响。
无论何时当一个参与者回滚的工作片段与另一参与者更新的工作片段相关时,不一致实现的事务就造成了问题。不能使用 SQL 定义这些依赖性,因为分布式事务不支持引用多个数据库服务器上数据的约束。仅当数据已在两个独立事务中更新时,该工作片段才是独立的(不存在相关性)。否则,就认为该工作片段是有相关性的。
在您继续之前,请考虑导致该错误的事务。更新的数据段和回滚的数据段是否互相相关?单个事务可能会由于其他原因(而不是维护数据完整性)而包含多次更新。 例如,以下是三种可能的原因:
- 减少的事务开销
- 简化的编码
- 程序员喜好
并验证每个假设已落实事务的数据库服务器实际修改了数据。只读数据库服务器可能会作为已落实事务的参与者而列出。
如果不一致的事务没有导致数据完整性的违例,此时您就可以退出该过程。
获取逻辑日志记录中的信息
要确定数据完整性是否受到不一致实现的全局事务的影响,必须重建全局事务,并确定事务的哪些部分已落实,哪些已回滚。使用 onlog 实用程序获取必要信息。过程如下:
-
在包含 HEURTX 记录的参与者上重建事务。
a. 参与者数据库服务器逻辑日志是您进行信息搜索的开始点。日志中的每条记录均有本地事务标识号 (xid)。获取 HEURTX 记录的 xid。
b. 使用本地 xid 定位所有相关联的日志记录,这些记录作为该工作片段的一部分而回滚。
-
确定哪一数据库服务器是充当全局事务的协调者。
a. 查找参与者上包含相同本地 xid 的 PREPARE 记录。 PREPARE 记录为该参与者标记了两阶段落实协议的起点。
b. 使用 onlog -l 选项获取 PREPARE 记录的详细输出。 该记录包含全局事务标识 (GTRID) 和协调数据库服务器的名称。有关 GTRID 的信息,请参阅获取全局事务标识。
-
从协调者日志获取其他参与者的列表。
a. 检查协调者数据库服务器上的日志记录。 找到 BEGPREP 记录。
b. 检查 BEGPREP 记录的详细输出。 如果该记录中 GTRID 的前 32 字节与参与者的 GTRID 相匹配,那么 BEGPREP 记录是同一全局事务的一部分。请注意,BEGPREP 详细输出的 ASCII 部分中显示的参与者。
-
重建每个参与者上的事务。
a. 在每个参与者数据库服务器上,读取逻辑日志以找到包含与该事务关联的 GTRID 的 PREPARE 记录,并获取该参与者执行的工作片段的本地 xid。
b. 在每个参与者数据库服务器上,使用本地 xid 定位所有与该事务(已落实或已回滚)相关联的逻辑日志记录。
在您遵循该过程之后,您将知道事务的所有参与者是哪些、分配给每个参与者哪些工作片段以及每个工作片段是已回滚还是已落实。根据该信息,您可以确定独立操作是否影响了数据完整性。
获取全局事务标识
当全局事务开始时,它会接收到称为全局事务标识 (GTRID) 的唯一标识号。 GTRID 包含协调者的名称。GTRID 已写入协调者的 BEGPREP 逻辑日志记录以及每个参与者的 PREPARE 逻辑日志记录。
要查看 GTRID,请使用 onlog -l 选项。GTRID 在记录的数据部分中偏移了 20 字节,长为 144 字节。以下示例显示 BEGPREP 记录的 onlog -l 输出。协调者为chrisw。
4a064 188 BEGPREP 4 0 4a038 0 1
000000bc 00000043 00000004 0004a038 .......C .......8
00087ef0 00000002 63687269 73770000 ..~..... chrisw..
00000000 00000000 00000000 00087eeb ........ ......~.
00006b16 00000000 00000000 00000000 ..k..... ........
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000000 00000000 00000000
00000000 00000001 6a756469 74685f73 ........ judith_s
6f630000 736f6374 63700000 oc..soct cp..
协调者上的 BEGPREP 记录与参与者(这些参与者是同一全局事务的一部分)上的 PREPARE 记录的 GTRID 的前 32 字节相同。例如,将以下示例中 PREPARE 记录的 GTRID 与上一个示例中 BEGPREP 记录的 GTRID 相比较。
c7064 184 PREPARE 4 0 c7038 chrisw
000000b8 00000044 00000004 000c7038 .......D ......p8
00005cd6 00000002 63687269 73770000 ...... chrisw..
00000000 00000000 00000069 00087eeb ........ ...i..~.
00006b16 00000000 00000010 00ba5a10 ..k..... ......Z.
00000002 00ba3a0c 00000006 00000000 ......:. ........
00ba5a10 00ba5a1c 00000000 00000000 ..Z...Z. ........
00ba3a0e 00254554 00ba2090 00000001 ..:..%ET .. .....
00000000 00ab8148 0005fd70 00ab8148 .......H ...p...H
0005fe34 0000003c 00000000 00000000 ...4...< ........
00000000 00ab80cc 00000000 00ab80c4 ........ ........
00ba002f 63687269 73770000 00120018 .../chrisw......
00120018 00ba0000 ........
确定是否需要执行操作来更正情况
如果不一致的事务创建了不一致的数据库,那么您可以有以下三个选项:
- 让联网数据库保持处于不一致状态。
- 除去落实事务之处受到的事务影响,从而回滚整个事务。
- 在回滚事务之处重新应用事务的影响,从而落实事务。
如果事务未严重影响数据库数据,那么您可以让数据库保持处于不一致状态。如果正在执行事务的应用程序可以继续按原状执行,并且您得出的决定是通过除去影响或重新应用事务来将数据库返回至一致状态的成本(时间与工作量方面的成本)过高,您就可能会遇到这种情况。
无需立即作出此决定。您可以使用以下段落中描述的方法来确定事务在更新哪些数据以及哪些记录受到影响。
当您作决定时,请考虑到没有自动过程或实用程序可以执行已落实事务的回滚或可以落实已回滚事务的一部分。以下段落描述如何浏览数据库服务器消息日志和逻辑日志以找到受影响的记录。如果不具备详细的应用程序知识,那么仅凭消息不足以确定所发生的事件。根据您的应用程序和系统的知识,您必须确定是回滚还是落实事务。您还必须对执行回滚或落实的补偿事务进行编程。
手动恢复的示例
本实例说明了手动恢复所涉及的工作。 以下 SQL 语句由用户nhowe 执行。 返回了错误 -698。
dbaccess
CREATE DATABASE tmp WITH LOG;
CREATE TABLE t (a int);
CLOSE DATABASE;
CREATE DATABASE tmp@apex WITH LOG;
CREATE TABLE t (a int);
CLOSE DATABASE;
DATABASE tmp;
BEGIN WORK;
INSERT INTO t VALUES (2);
INSERT INTO tmp@apex:t VALUES (2);
COMMIT WORK;
### return code -698
以下摘要引用自当前数据库服务器上的逻辑日志:
addr len type xid id link
.....
17018 16 CKPOINT 0 0 13018 0
18018 20 BEGIN 2 1 0 08/27/91 10:56:57
3482 nhowe
1802c 32 HINSERT 2 0 18018 1000018 102
4
1804c 40 CKPOINT 0 0 17018 1
begin xid id addr user
1 2 1 1802c nhowe
19018 72 BEGPREP 2 0 1802c 6d69 1
19060 16 COMMIT 2 0 19018 08/27/91 11:01:38
1a018 16 ENDTRANS 2 0 19060 580543
以下摘要引用自数据库服务器 apex 上的逻辑日志:
addr len type xid id link
.....
16018 20 BEGIN 2 1 0 08/27/91
10:57:07 3483 pault
1602c 32 HINSERT 2 0 16018 1000018 102
4
1604c 68 PREPARE 2 0 1602c eh
17018 16 HEURTX 2 0 1604c 1
17028 12 CLR 2 0 1602c
17034 16 ROLLBACK 2 0 17018 08/27/91 11:01:22
17044 40 CKPOINT 0 0 15018 1
begin xid id addr user
1 2 1 17034 --------
18018 16 ENDTRANS 2 0 17034 8806c3
....
首先您要尝试将当前数据库服务器日志中的事务与 apex 数据库服务器日志中的事务相匹配。BEGPREP 和 PREPARE 日志记录均包含 GTRID。您可以通过使用 onlog -l 以及查看 BEGPREP 和 PREPARE 日志记录的数据部分来抽取 GTRID。GTRID 在数据部分中偏移了 22 字节,长为 68 字节。更为简单但是准确度较低的方法是查看 COMMIT 或 ROLLBACK 记录的时间。 虽然由于将落实(或回滚)消息从协调者传输至参与者所用时间而导致稍有延迟,但这两个时间必须很接近。(第二个方法缺乏准确度,因为虽然来自同一协调者的并发事务很可能不在同一时间落实,但并发事务是可以在同一时间落实的。)
更正该样本情况
- 查找所有已更新的记录。
- 使用 onlog 和记录类型表来识别记录类型(插入、删除、更新)。
- 使用每个记录的 onlog -l 输出以获取本地 xid、表空间数和行标识。
- 通过将表空间数与systables 系统目录表的 partnum 列中的值相比较,从而将表空间数映射到表名。
- 运用您的应用程序知识来确定需要哪一操作来更正该情况。
在本示例中,不同日志中 COMMIT 和 ROLLBACK 记录上的时间戳记很接近。没有其他活动事务造成另一并发的落实或回滚的可能性。在这种情况下,当前数据库服务器上落实了已分配行标识 102(十六进制)或 258(十进制)的插入 (HINSERT)。 因此,补偿事务如下:
DELETE FROM t WHERE rowid = 258