dbload 实用程序
dbload 实用程序将数据装入 GBase 8s 产品创建的数据库或表中。它将数据从一个或多个文本文件传送到一个或多个现有表中。
此实用程序支持所有 GBase 8s 版本中的新数据类型。
不能在高可用性集群中的辅助服务器上使用 dbload 实用程序。
当您使用 dbload 实用程序时,可以操纵正在装入的数据文件或访问正在装入的数据库。尽可能使用 LOAD 语句,它比 dbload 要快。
dbload 实用程序给了您极大的灵活性,但它没有其他方法快,并且您必须准备一个命令文件来控制输入。您可将多种格式的数据用于 dbload。
dbload 实用程序与 LOAD 语句相比,有以下优点:
- 您可以使用 dbload 从使用各种格式创建的输入文件中加载数据。dbload 命令文件可以接受来自完全不同的数据库管理系统的数据。。
- 您可以通过将 dbload 指示为读取但忽略x行数据来指定装载起点。
- 您可以指定批处理大小,这样在每插入 x 行之后就提交插入。
- 您可以限制读取的坏行数,超过该数则 dbload 结束。
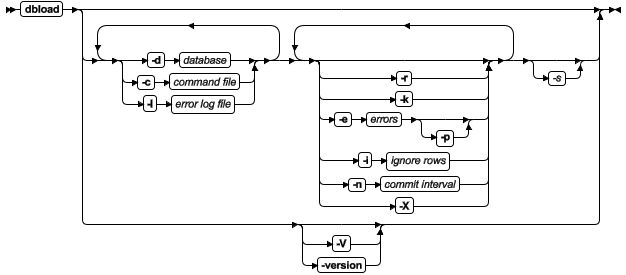
dbload 命令的语法
dbload 命令将数据加载到数据库或表中。
| 元素 | 用途 | 重要注意事项 |
|---|---|---|
| -c command file | 指定 dbload 命令文件的文件名或路径名 | 参考: 有关构建命令文件的信息,请参阅 dbload实用程序的命令文件。 |
| -d database | 指定要接收数据的数据库名称 | 其他信息: 如果希望使用比数据库的简单名称更多的内容,请参阅《GBase 8s SQL 指南:语法》的『数据库名称』一节。 |
| -e errors | 指定终止前 dbload 读取的坏行数。errors 的缺省值为 10。 | 参考: 有关更多信息,请参阅装入操作期间坏行限制。 |
| -i ignore rows | 指定在输入文件中要忽略的行数 | 参考: 有关更多信息,请参阅装入操作期间要忽略的行数。 |
| -k | 指示 dbload 在装入操作期间,对表加排它锁 | 参考: 有关更多信息,请参阅装入操作期间表锁定。 您不能将 -k 选项和 -r 选项一起使用,因为 -r 选项指定在装入操作期间不锁定任何表。 |
| -l error log file | 指定错误日志文件的文件名或路径名 | 如果指定现有文件,那么将覆盖它的内容。如果您指定的文件不存在,dbload 将创建该文件。 其他信息: 错误日志文件存储诊断信息以及 dbload 无法插入到数据库中的任何输入文件行。 |
| -n commit interval | 以行数指定提交间隔 缺省间隔为 100 行。 | 其他信息: 如果您的数据库支持事务,dbload 将在读取并插入指定数量的新行后提交事务。每次提交后会出现一条消息。 参考: 有关事务的信息,请参阅《GBase 8s SQL 指南:教程》。 |
| -p | 如果坏行数超过限制将提示要求指示信息 | 参考: 有关更多信息,请参阅装入操作期间坏行限制。 |
| -r | 阻止 dbload 在装入期间锁定表,这样就在装入期间允许其他用户更新表中的数据 | 其他信息: 有关更多信息,请参阅装入操作期间表锁定。 您不能将 -r 选项和 -k 选项一起使用,因为 -r 选项指定在装入操作期间不锁定任何表,而 -k选项指定对表加排它锁。 |
| -s | 检查命令文件中的语句语法而不插入数据 | 其他信息: 标准输出显示命令文件,并在任何发现错误的位置标识该错误。 |
| -V | 显示软件版本号和序列号 | 无。 |
| -version | 扩展 -V 选项以显示有关构建操作系统、构建号和构建日期的其他信息 | 无。 |
| -X | 识别字符字段中的 HEX 二进制数据 | 无。 |
如果指定了一部分(但不是全部)所需信息,dbload 将提示您提供附加规范。数据库名称、命令文件和错误日志文件都是需要的。如果漏掉了所有这三个选项,将接收到错误消息。
dbload 命令示例
以下命令将dbload命令文件commands中的数据装入stores_demo 数据库:
dbload -d stores_demo -c commands -l errlog
装入操作期间表锁定
dbload -k 选项在装入操作期间会覆盖缺省表锁定方式。-k 选项指示 dbload 以独占模式而非共享方式锁定表。
如果未指定 -k 选项,将以共享方式锁定在命令文件中指定的表。当以共享方式锁定表时,数据库服务器在将行插入表中时仍必须获得行或页上的独占锁。
指定 -k 选项时,数据库服务器在整个表上放置排它锁。-k 选项提高了大型装入的性能,因为数据库服务器在装入操作期间插入行时不需要获得行或页上的独占锁。
如果未指定 -r 选项,那么装入期间将锁定在命令文件中指定的表,这样其他用户就不能更新该表中的数据。表锁定减少了装入期间需要的锁数量,但也降低了并发性。如果计划装入大量行,请在非高峰时间使用表锁定并装入。
装入操作期间要忽略的行数
dbload -i 选项指定在 dbload 开始处理数据之前,会在输入文件中忽略的换行符的数目。
例如:如果 dbload 在插入 240 行输入后结束,那么如果将忽略行数设置为 240,您可以从第 241 行再次开始装入。
如果您执行dbload在完成全部数据装入之前,因为某些原因,会话提前结束了,那么 -i 选项非常有用。
如果在输入文件开始包含头信息,那么 -i 选项也会很有用。
装入操作期间坏行限制
dbload -e 选项使您可以指定在 dbload 终止前允许的坏行数。
如果将错误数设置为正整数,那么当 dbload 读取的坏行数达到允许的坏行数 + 1时将终止。如果将错误数设置为 0,那么当 dbload 读取第一个坏行时就将终止。
如果 dbload 超过了坏行限制,并且指定了 -p 选项,dbload 在终止前将提示您输入指令。提示将询问您是想回滚还是想提交自上一事务以后插入的所有行。
如果 dbload 超过了坏行限制,但未指定 -p 选项,dbload 将提交自上一事务以后插入的所有行。
终止 dbload 实用程序
如果按中断键,那么 dbload 将终止并废弃已插入但还没有提交给数据库的任何新行(如果数据库具有事务)。
dbload 实用程序的名称和对象准则
当使用 dbload 实用程序时,您必须遵循指定网络名以及处理简单大对象、索引和定界标识的准则。
表 1. dbload 实用程序的名称和对象准则
| 对象 | 准则 |
|---|---|
| 网络名 | 如果已联网,请在数据库名中包含数据库服务器名和目录路径,以指定另一数据库服务器上的数据库。 |
| 简单大对象 | 只要简单大对象在文本文件中,您就可使用 dbload 实用程序装入简单大对象。 |
| 索引 | 索引的存在将大大影响 dbload 实用程序装入数据的速度。为了获得最佳性能,运行 dbload 之前请删除接收数据的表上任何的索引。您可在 dbload 完成后创建新索引。 |
| 定界标识 | 可将定界标识用于 dbload 实用程序。该实用程序会检测诸如关键字、混合大小写或具有特殊字符的数据库对象,并在它们周围括上双引号。 |
dbload 实用程序的命令文件
使用 dbload 实用程序之前,必须创建一个命令文件,该命令文件将来自一个或多个输入文件的字段映射到您数据库中的一个或多个表的列。
该命令文件只包含 FILE 和 INSERT 语句。每个 FILE 语句命名一个输入数据文件。FILE 语句还定义来自输入文件的已插入到表中的数据字段。每个 INSERT 语句命名一个用来接收数据的表。INSERT 语句还定义 dbload 如何将 FILE 语句中描述的数据放入表列中。
在命令文件中,FILE 语句可以以下面的形式出现:
- 定界符格式
- 字符位置格式
FILE 语句有 4,096 字节的大小限制。
当输入数据行中的每个字段使用相同的定界符且每行都以换行字符结束时,请使用定界符格式的 FILE 语句。此格式是典型的带可变长度字段的数据行。只要数据行符合定界符和换行要求,您也可将定界符格式的 FILE 语句用于长度固定的字段。定界符格式的 FILE 和 INSERT 语句比字符位置格式易于使用。
当无法用定界符来进行标识且必须使用输入行中的字符位置来标识输入数据字段时,请使用字符位置格式的 FILE 语句。例如:使用此形式来指示第一输入数据字段从字符位置 1 开始并继续直到字符位置 20。如果必须将字符串转换为空值,您也可使用此形式。例如:如果输入数据文件使用空格序列来指示空值,那么如果您希望指示 dbload 在出现空格字符串的每个地方替换为空时,您必须使用此形式。
您可在单个命令文件中使用两种形式的 FILE 语句。但为清楚起见,以下部分将两种形式分开描述。
定界符格式的 FILE 和 INSERT 语句
为 dbload 实用程序定义信息的 FILE 和 INSERT 语句会采用定界符格式。
以下 dbload 命令文件的示例演示了 FILE 和 INSERT 语句的简单定界符格式。此示例是基于 stores_demo 数据库的。一条 UNLOAD 语句创建了三个输入数据文件:stock.unl、customer.unl 和 manufact.unl。
FILE stock.unl DELIMITER '|' 6;
INSERT INTO stock;
FILE customer.unl DELIMITER '|' 10;
INSERT INTO customer;
FILE manufact.unl DELIMITER '|' 3;
INSERT INTO manufact;
定界符格式的语法
定界符格式的语法指定字段定界符、输入文件和每行数据中的字段数。
下图显示了定界符 FILE 语句的语法。

| 元素 | 用途 | 重要注意事项 |
|---|---|---|
| c | 为特定输入文件指定作为字段定界符的字符 | 如果由 c 指定的定界符在输入文件的任何地方以文字字符出现,那么在输入文件中必须在该字符前加上反斜杠 ()。例如:如果 c 的值指定为方括号 ([),那么您必须在输入文件中出现的任何文字方括号之前放置反斜杠。同样,必须在输入文件中出现的任何反斜杠之前放置附加的反斜杠。 |
| filename | 指定输入文件 | 无。 |
| nfields | 指示每个数据行中的字段数 | 无。 |
dbload 实用程序将序列名 f01、f02、f03 等(依此类推)指定给输入文件中的字段。您看不到这些名称,但是如果您在关联的 INSERT 语句中引用这些字段来指定值列表,那么必须使用 f01、f02、f03 格式。有关详细信息,请参阅如何编写定界符格式的 dbload 命令文件。
两个连续的定界符定义了一个空字段。您可紧接在标志每个数据行结束的换行字符前面放置一个定界符。
插入的数据类型对应于显式或缺省列列表。如果数据字段长度与其对应的字符列长度不同,将使数据符合列长度。即,如果插入数据达不到列定义长度将对其填充空格,或如果超过列长度,那么会将其截断。
如果命名的列数少于表中的列数,dbload 将向未命名的列插入表创建指定的缺省值。如果未指定缺省值,dbload 将尝试插入空值。如果这个尝试违反了非空约束或唯一约束,那么插入操作将失败且将返回错误消息。
如果 INSERT 语句省略列名,那么 INSERT 缺省指定语句中指定的表中的每一列。如果 INSERT 语句省略了 VALUES 子句,那么 INSERT 缺省指定先前的 FILE 语句的每个字段。
如果列出的(或由缺省隐含的)字段数不匹配列出的(或由缺省隐含的)值的个数,将导致错误。
dbload INSERT 语句的语法类似于 SQL 中的 INSERT 语句,不同之处在于,在 dbload 中,INSERT 语句无法与 SELECT 语句合并使用。
不要在 dbload 命令文件中使用 INSERT INTO 语句的 CURRENT、TODAY 和 USER 关键字;它们在 dbload 命令文件中不受支持。这些关键字只在 SQL 中受支持。
例如:以下 dbload 命令不受支持:
FILE "testtbl2.unl" DELIMITER '|' 1;
INSERT INTO testtbl (testuser, testtime, testfield)
VALUES ('kae', CURRENT, f01);
首先装入现有数据,然后写 SQL 查询,以使用当前时间、日期或登录用户来插入或更新数据。您可写以下 SQL 语句:
INSERT INTO testtbl (testuser, testtime, testfield)
VALUES ('kae', CURRENT, f01);
CURRENT 关键字返回系统日期和时间。TODAY 关键字返回系统日期。USER 关键字返回登录用户名称。
下图显示了定界符格式的 dbload INSERT 语句的语法。

| 元素 | 用途 | 重要注意事项 |
|---|---|---|
| column | 指定接收新数据的列 | 无。 |
| owner. | 指定表所有者的用户名 | 无。 |
| table | 指定接收新数据的表 | 无。 |
使用此命令文件运行 dbload 的用户必须在命名的表上具有 Insert 特权。
定界符格式的 dbload 命令文件
命令文件必须包含所需的元素,其中包括定界符。
以下示例中的 FILE 语句将 stock.unl 数据行描述为包含六个字段,每个字段以竖条 (|) 作为定界符进行分隔。
FILE stock.unl DELIMITER '|' 6;
INSERT INTO stock;
将 FILE 语句与以下示例中出现在输入文件 stock.unl 中的数据行进行比较。(由于最后的字段后面没有跟定界符,所以如果任何数据行以空字段结束,那么都将导致错误。)
1|SMT|baseball gloves|450.00|case|10 gloves/case
2|HRO|baseball|126.00|case|24/case
3|SHK|baseball bat|240.00|case|12/case
示例 INSERT 语句只包含需要的元素。由于省略了列的列表,INSERT 语句默认要将值插入 stock 表中的每个字段中。由于省略了 VALUES 子句,INSERT 语句默认在最新的 FILE 语句中定义了每个字段的输入值。此 INSERT 语句是有效的,因为 stock 表包含六个字段,与 FILE 语句定义的值数量相对应。
以下示例显示了从此 INSERT 语句插入到 stock 中的第一个数据行。
| 字段 | 列 | 值 |
|---|---|---|
| f01 | stock_num | 1 |
| f02 | manu_code | SMT |
| f03 | 描述 | baseball gloves |
| f04 | unit_price | 450.00 |
| f05 | unit | case |
| f06 | unit_descr | 10 gloves/case |
以下示例中的 FILE 和 INSERT 语句演示了更加复杂的 INSERT 语句语法:
FILE stock.unl DELIMITER '|' 6;
INSERT INTO new_stock (col1, col2, col3, col5, col6)
VALUES (f01, f03, f02, f05, 'autographed');
在此示例中,VALUES 子句使用 dbload 自动指定的字段名称。您必须使用字母 f 后跟数字来引用自动指定的字段名称:f01、f02...f10...f100 等等。所有其他格式都是不正确的。
前九个字段必须包含零:f01、f02、...、f09。
用户更改了列名、数据的顺序以及新的 stock 表中 col6 的意义。由于 new_stock 中的第四列 (col4) 未在列列表中进行命名,所以新数据行在 col4 位置包含空值(假定该列允许空值)。如果没有为 col4 指定缺省值,插入值将为空值。
下表显示了从此 INSERT 语句插入到 new_stock 中的第一个数据行。
| 列 | 值 |
|---|---|
| col1 | 1 |
| col2 | baseball gloves |
| col3 | SMT |
| col4 | null |
| col5 | Case |
| col6 | Autographed |
字符位置格式的 FILE 和 INSERT 语句
为 dbload 实用程序定义信息的 FILE 和 INSERT 语句采用字符位置格式。
本主题中的示例基于输入数据文件 cust_loc_data,其包含 customer 表的最后四列(city、state、zipcode 和 phone)。将输入文件中的字段用空格填充以创建数据行,在这些数据行中,数据字段的位置和字符数在所有数据行中都相等。这些字段的定义分别是 CHAR(15)、CHAR(2)、CHAR(5) 和 CHAR(12)。图 1 显示了字符位置以及 cust_loc_data 文件中的五个示例数据行。

以下 dbload 命令文件的示例演示了 FILE 和 INSERT 语句的字符位置格式。示例包含两个新表(cust_address 和 cust_sort)来接收数据。为了此示例的用途,cust_address 包含四列,列的列表省略了第二列。cust_sort 表包含两列。
FILE cust_loc_data
(city 1-15,
state 16-17,
area_cd 23-25 NULL = 'xxx',
phone 23-34 NULL = 'xxx-xxx-xxxx',
zip 18-22,
state_area 16-17 : 23-25);
INSERT INTO cust_address (col1, col3, col4)
VALUES (city, state, zip);
INSERT INTO cust_sort
VALUES (area_cd, zip);
字符位置格式的语法
字符位置格式的语法指定一些信息,其中包括数据行中字符位置范围的开始字符位置和结束字符位置。
下图显示了字符位置 FILE 语句的语法。

| 元素 | 用途 | 重要注意事项 |
|---|---|---|
| -end | 指示数据行中结束字符位置范围的字符位置 | end值前必须有连字符。 |
| fieldn | 为正使用字符位置范围定义的数据字段指定名称 | 无。 |
| filename | 指定输入文件的名称。 | 无。 |
| null string | 指定dbload必须以空值替代的数据值 | 必须是加引号的字符串。 |
| start | 指示数据行中开始一定范围的字符位置的字符位置。如果您指定 start 而没有指定 end,那么它将代表单个字符。 | 无。 |
您可在数据字段定义或不同字段中重复相同的字符位置。
引用的 null string 的作用域是您定义它的数据字段。您可为每个允许空条目的字段定义显式的空字符串。
插入的数据类型对应于显式或缺省列列表。在数据字段宽度与其对应的字符列不同时,如果列较宽,那么将在插入值中填充空格;如果字段较宽,那么将会截断插入值。
如果命名的列数少于表中的列数,dbload 将插入为未命名的列指定的缺省值。如果未指定缺省值,dbload 将尝试插入空值。如果整个尝试违反了非空约束或唯一约束,插入操作将失败且将返回错误消息。
如果 INSERT 语句省略列名,那么 INSERT 缺省指定语句中指定的表中的每一列。如果 INSERT 语句省略了 VALUES 子句,那么 INSERT 缺省指定先前的 FILE 语句的每个字段。
如果列出的(或由缺省隐含的)列名数不匹配列出的(或由缺省隐含的)值数,将导致错误。
dbload INSERT 语句的语法类似于 SQL 中的 INSERT 语句,不同之处在于,在 dbload 中,INSERT 语句无法与 SELECT 语句合并使用。下图显示了字符位置格式的 dbload INSERT 语句的语法。

| 元素 | 用途 | 重要注意事项 |
|---|---|---|
| column | 指定接收新数据的列 | 无。 |
| owner. | 指定表所有者的用户名 | 无。 |
| table | 指定接收新数据的表 | 无。 |
字符位置格式的语法与定界符格式的语法相同。
使用此命令文件运行 dbload 的用户必须在命名的表上具有 Insert 特权。
字符位置格式的 dbload 命令文件
命令文件必须定义数据字段,并使用字符位置来定义每个字段的长度。
以下示例中的 FILE 语句定义了 cust_loc_data 表数据行中的六个数据字段。
FILE cust_loc_data
(city 1-15,
state 16-17,
area_cd 23-25 NULL = 'xxx',
phone 23-34 NULL = 'xxx-xxx-xxxx',
zip 18-22,
state_area 16-17 : 23-25);
INSERT INTO cust_address (col1, col3, col4)
VALUES (city, state, zip);
语句命名了字段并使用字符位置来定义每个字段的长度。将前面示例中的 FILE 语句与下图中的数据行进行比较。

FILE 语句定义了以下数据字段,它们从样本数据文件中的数据行派生而来。
| 列 | 来自数据行 1 的值 | 来自数据行 2 的值 |
|---|---|---|
| city | Sunnyvale++++++ | Tempe++++++++++ |
| state | CA | AZ |
| area_cd | 408 | null |
| phone | 408-789-8075 | null |
| zip | 94086 | 85253 |
| state_area | CA408 | AZxxx |
为 phone 和 area_cd 字段定义的空字符串在这些列中生成空值,但不影响存储在 state_area 列中的值。
该 INSERT 语句将从 FILE 语句派生而来的字段名和值用作值列表输入。请考虑以下 INSERT 语句:
INSERT INTO cust_address (col1, col3, col4)
VALUES (city, state, zip);
该 INSERT 语句使用样本数据文件中的数据,并且 FILE 语句将以下信息放入 cust_address 表中。
| 列 | 来自数据行 1 的值 | 来自数据行 2 的值 |
|---|---|---|
| col1 | Sunnyvale++++++ | Tempe++++++++++ |
| col2 | null | null |
| col3 | CA | AZ |
| col4 | 94086 | 85253 |
由于没有命名 cust_address 中的第二列 (col2),所以新的数据行将包含空值(假定该列允许空值)。
请考虑以下 INSERT 语句:
INSERT INTO cust_sort
VALUES (area_cd, zip);
该 INSERT 语句将以下数据行插入 cust_sort 表中。
| 列 | 来自数据行 1 的值 | 来自数据行 2 的值 |
|---|---|---|
| col1 | 408 | null |
| col2 | 94086 | 85253 |
由于没有提供列列表,dbload 从系统目录读取 cust_sort 中所有列的名称。(您不能将数据插入临时表,因为临时表不会进入系统目录。)前面的 FILE 语句的字段名称指定了要装入每列中的值。
dbload装入复杂数据类型的命令文件
您可以创建 dbload 命令文件,将包含复杂数据类型的列装入表。
可将以下数据类型用于 dbload:
- BLOB 或 CLOB
- ROW 类型中的 SET
不可将以下数据类型用于 dbload 实用程序:
- ROW 类型中的 CLOB 或 BLOB
- SET 中的 ROW 类型
所有装载实用程序(dbexport、dbimport、dbload、onload、onunload)都依赖导出和导入功能。如果在写用户定义的数据类型时未定义此功能,那么无法使用这些实用程序。
您可以将 dbload 与命名行类型、未命名行类型、集合类型一起使用。
将 dbload 实用程序用于命名行类型
将命名行类型用于 dbload 实用程序的过程与将其他复杂数据类型用于 dbload 的过程稍有不同,因为命名行类型实际上是用户定义的数据类型。
假定您具有名称为 person 的表,其包含一个带命名行类型的列。再假定 person_t 命名行类型包含六个字段:name、address、city、state、zip 和 bdate。
以下语法显示了如何创建在本示例中使用的命名行类型和表:
CREATE ROW TYPE person_t
(
name VARCHAR(30) NOT NULL,
address VARCHAR(20),
city VARCHAR(20),
state CHAR(2),
zip VARCHAR(9),
bdate DATE
);
CREATE TABLE person of TYPE person_t;
要为命名行类型(或为任何用户定义的数据类型)装入数据
-
使用 UNLOAD 语句将表卸载到输入文件person.unl 。在本示例中,输入文件将命名行类型看成六个单独的字段:
Brown, James|13 First St.|San Francisco|CA|94070|01/04/1940|
Karen Smith|1820 Elm Ave #100|Fremont|CA|94502|01/13/1983| -
使用 dbschema 实用程序捕捉表模式和行类型。必须使用 dbschema -u 选项来获得命名行类型。
dbschema -d stores_demo -u person_t > schema.sql
dbschema -d stores_demo -t person > schema.sql -
使用 DB-Access 在新数据库newdb中重新创建 person 表。
有关详细步骤,请参阅使用 dbschema 输出作为 DB-Access 输入。
-
创建 dbload 命令文件uds_command。此 dbload 命令文件将两行插入新数据库中的 person 表。
FILE person.unl DELIMITER '|' 6;
INSERT INTO person;此 dbload 示例显示了如何将新数据行插入 person 表。该 INSERT 语句和 dbload 命令文件中的行数必须匹配:
FILE person.unl DELIMITER '|' 6;
INSERT INTO person
VALUES ('Jones, Richard', '95 East Ave.',
'Philadelphia', 'PA',
'19115',
'03/15/97'); -
运行 dbload 命令:
dbload -d newdb -c uds_command -l errlog
要找到包含命名行类型的卸载表中的字段数,可计算每个竖条 (|) 定界符之间的字段数。
将 dbload 实用程序用于未命名行类型
您可以将未命名行类型用于 dbload 实用程序,这些类型是使用 ROW 构造函数创建的,并会定义列或字段的类型。
在以下示例中,devtest 表包含两个带未命名行类型的列 s_name 和 s_address。 s_name 列包含三个字段:f_name、m_init 和 l_name。s_address 列包含四个字段:street、city、state 和 zip。
CREATE TABLE devtest
(
s_name ROW(f_name varchar(20), m_init char(1), l_name varchar(20)
not null),
s_address ROW(street varchar(20), city varchar(20), state char(20),
zip varchar(9)
);
来自 devtest 表的数据卸载到 devtest.unl 文件。每个数据行包含两个定界字段,每个未命名行类型一个。ROW 构造函数放在每个未命名行类型之前,如下:
ROW('Jim','K','Johnson')|ROW('10 Grove St.','Eldorado','CA','94108')|
ROW('Maria','E','Martinez')|ROW('2387 West Wilton
Ave.','Hershey','PA','17033')|
此 dbload 示例显示了如何将包含未命名行类型的数据插入 devtest 表。在每个未命名行类型两边放上双引号,否则插入无法工作。
FILE devtest.unl DELIMITER '|' 2;
INSERT INTO devtest (s_name, s_address)
VALUES ("row('Stephen', 'M', 'Wu')",
"row('1200 Grand Ave.', 'Richmond', 'OR', '97200')");
将 dbload 实用程序用于集合数据类型
您可以将集合数据类型(例如 SET、LIST 和 MULTISET)用于 dbload 实用程序。
SET 数据类型示例:
SET 数据类型是存储唯一元素的无序集合类型。SET 数据类型中的元素个数可以变化,但不允许空值。
以下语句创建了一个表,在该表中,children 列定义为 SET:
CREATE TABLE employee
(
name char(30),
address char(40),
children SET (varchar(30) NOT NULL)
);
来自 employee 表的数据卸载到 employee.unl 文件。每个数据行包含四个定界的字段。 第一个集合包含三个元素(Karen、Lauren 和 Andrea),然而第二个集合包含四个元素。SET 构造函数放在每个 SET 数据行之前。
Muriel|5555 SW Merry
Sailing Dr.|02/06/1926|SET{'Karen','Lauren','Andrea'}|
Larry|1234 Indian Lane|07/31/1927|SET{'Martha',
'Melissa','Craig','Larry'}|
此 dbload 示例显示了如何将包含 SET 数据类型的数据插入新数据库中的 employee 表中。在每个 SET 数据类型两边放上双引号,否则插入无法工作。
FILE employee.unl DELIMITER '|' 4;
INSERT INTO employee
VALUES ('Marvin', '10734 Pardee', '06/17/27',
"SET{'Joe', 'Ann'}");
LIST 数据类型示例:
LIST 数据类型是存储有序的非唯一元素的集合类型;也就是说,它允许元素值重复。
以下语句创建了一个表,在该表中,month_sales 列定义为 LIST:
CREATE TABLE sales_person
(
name CHAR(30),
month_sales LIST(MONEY NOT NULL)
);
来自 sales_person 表的数据卸载到 sales.unl 文件。每个数据行包含两个定界的字段,如下:
Jane Doe|LIST{'4.00','20.45','000.99'}|
Big Earner|LIST{'0000.00','00000.00','999.99'}|
此 dbload 示例显示了如何将包含 LIST 数据类型的数据插入新数据库中的 sales_person 表中。在每个 LIST 数据类型两边使用双引号,否则插入操作无法进行。
FILE sales_person.unl DELIMITER '|' 2;
INSERT INTO sales_person
VALUES ('Jenny Chow', "{587900, 600000}");
您可以用类似的方式装入多个集合。