数据类型和表达式
这些主题描述 GBase 8s 支持的数据类型和表达式。
这些基本的语法段可出现在数据定义语言(DDL)和数据操纵语言(DML)语句中,以及在其他类型 SQL 语句中。某些 SPL 语句也可指定数据类型或表达式。您可使用在不同的上下文中的关系型数据库或对象关系型数据库的这些特性,比如,来定义表的模式、来指定例程的签名和参数,或来表示或计算特定的数据值。
段描述的范围
每一段的描述包括下列信息:
- 说明该段的作用的简短介绍
- 展现如何正确地输入段的语法图
- 说明语法图中数据的表,你必须为其替换名称、值或其他特定的信息
- 用法规则,通常包括说明这些规则的示例
如果一段由多个部分组成,则段描述提供关于每一部分的类似的信息。有些描述以对此文档中和其他文档中相关信息的引用来结束。
段描述的使用
每一段描述内的语法图不是孤立的图。更准确地说,它是可包括该段的 SQL 语句(在 SQL 语句 中)或 SPL 语句(在 SPL 语句 中)的语法的子图。
SQL 或 SPL 语法描述可以两种方式引用段描述:
- 在语法图中的 subdiagram reference 可罗列段名称和此文档在该段描述开始处的页。
- 紧跟在语法图之后的表的语法列可罗列段名称以及该段描述起始处的页。
如果语句的语法图包括对段的引用,请转至那个段描述来查看该段的完整语法。
例如,如果您想要写包括 view 名称的 database 和 database server 限定符的 CREATE VIEW 语句,则首先查找 CREATE VIEW 语句 的语法图。图下的表引用 view 的语法的 Database Object Name 段。然后,使用 Database Object Name 段语法来输入有效的 CREATE VIEW 语句,还为该视图指定 database 和 database server 名称。在下例中, CREATE VIEW 语句在 boston 数据库服务器上的 sales 数据库中定义名为 name_only 的视图:
CREATE VIEW sales@boston:name_only AS
SELECT customer_num, fname, lname FROM customer;
除了本章记录的“数据类型”和“表达式”语法段之外,其它语法段 还提供在此文档的语法图中引用的附加的语法段。
数据类型和表达式段
数据类型和表达式段可出现在 SQL 语句中。
数据类型和表达式段可包括下列项:
- 数据类型
- DATETIME 字段限定符
- INTERVAL 字段限定符
- 表达式
- 聚集表达式
- AVG、COUNT、MAX、MIN、SUM、RANGE、STDDEV、VARIANCE 和用户定义的聚集
- 算术表达式
- 二进制(+、-、*、/)运算符、运算符函数和一元(+、-)运算符
- 强制转型表达式
- CAST 函数和 Cast(::)运算符
- 集合子查询
- 列表达式
- 列名称、ROWID 和子串([ ... ])运算符
- CONCAT 函数和串联(||)运算符
- 条件段和条件表达式
- 比较条件:AND、OR、NOT、BETWEEN、IS NULL、LIKE、MATCHES 和关系运算符
- 带有子查询的条件:IN、EXISTS、ALL、ANY 和 SOME 运算符
- 布尔 UDF
- CASE 表达式
- ISNULL 函数
- NVL 函数
- DECODE 函数
- 常量表达式:CURRENT、SYSDATE、TODAY、DBSERVERNAME、SITENAME、UNITS、CURRENT_USER 和 USER
- 文字值
- 文字集合
- 文字 DATETIME
- 文字 INTERVAL
- 精确数值
- 文字 Row
- 引用的字符串
- 构造函数表达式
- 集合构造函数
- ROW 构造函数表达式
- 代数函数:ABS、MOD、POW、POWER® ROOT、ROUND、SQRT 和 TRUNC 函数
- CARDINALITY 函数
- DBINFO 函数
- 加密和解密函数:DECRYPT_BINARY、DECRYPT_CHAR、ENCRYPT_AES、ENCRYPT_TDES 和 GETHINT 函数
- 指数和对数函数:EXP、LOGN 和 LOG10 函数
- HEX 函数
- 层级查询运算符和函数:CONNECT_BY_ROOT、PRIOR 和 SQL_CONNECT_BY_PATH
- IFX_ALLOW_NEWLINE 函数
- 长度函数:CHARACTER_LENGTH、CHAR_LENGTH、LENGTH 和 OCTET_LENGTH 函数
- 序列运算符:CURRVAL、NEXTVAL
- 智能大对象函数:FILETOBLOB、FILETOCLOB、LOCOPY 和 LOTOFILE 函数
- 字符串操纵函数:LPAD、RPAD、TRIM、REPLACE、SUBSTR、SUBSTRING、INITCAP、LOWER 和 UPPER 函数
- 时间函数:DATE、DAY、EXTEND、MDY、MONTH、TO_CHAR、GBase_TO_DATE、TO_DATE、WEEKDAY 和 YEAR 函数
- 触发器类型布尔运算符:DELETING、INSERTING、SELECTING 和 UPDATING
- 三角函数:ACOS、ASIN、ATAN、ATAN2、COS、SIN 和 TAN 函数
- 汉字转拼音函数:GetHzFullPY、GetHzPYCAP和 GetHzFullPYsubstr 函数
- SYS_GUID 函数
- 列转行函数:WM_CONCAT、WM_CONCAT_TEXT 函数
- 用户定义的函数
- 语句-本地变量表达式
您还可使用主变量或 SPL 变量作为表达式。要获取带有页引用的字母列表,请参阅 表达式的列表。
集合子查询
您可使用“集合子查询”来从子查询的结果创建 MULTISET 集合。此语法是对 SQL 的 ANSI/ISO 标准的扩展。
语法
集合子查询

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| singleton_select | 返回正好一行的子查询 | 子查询不可重复 SELECT 关键字,也不可包括 ORDER BY 子句 | SELECT 语句 |
| subquery | 嵌入的查询 | 不可包含 ORDER BY 子句 | SELECT 语句 |
用法
MULTISET 和 SELECT ITEM 关键字有下列重要意义:
- MULTISET 指定可包括重复值的元素,但没有特定元素的顺序的集合。
- SELECT ITEM 仅支持 projection 列表中的一个表达式。您不可在单个子查询中重复 SELECT 关键字。
您可在下列上下文中使用集合子查询:
- SELECT 语句的 Projection 子句和 WHERE 子句
- INSERT 语句的 VALUES 子句
- UPDATE 语句的 SET 子句
- 在您可使用集合表达式的任何地方(即,计算得到单个集合的任何表达式)
- 作为传递给用户定义的例程的一个参数
下列限制适用于集合子查询:
- Projection 子句不可包含重复的列(字段)名称。
- 它不可包含表名称的别名。(但它可使用列(字段)名称的别名,如下列一些示例中那样。)
- 它是只读的。
- 不可打开它两次。
- 它不可包含 NULL 值。
- 它不可包含尝试在子查询内搜索的语法。
集合子查询返回未命名的 ROW 数据类型的多重集。此 ROW 类型的字段是子查询的 projection 列表中的元素。下列示例访问表和这些语句定义的 ROW 类型:
CREATE ROW TYPE rt1 (a INT);
CREATE ROW TYPE rt2 (x int, y rt1);
CREATE TABLE tab1 (col1 rt1, col2 rt2);
CREATE TABLE tab2 OF TYPE rt1;
CREATE TABLE tab3 (a ROW(x INT));
下列结合子查询的示例返回罗列在该子查询右边的 MULTISET 集合。
| 集合子查询 | 结果集合 |
|---|---|
| MULTISET (SELECT * FROM tab1)... | MULTISET(ROW(col1 rt1, col2 rt2)) |
| MULTISET (SELECT col2.y FROM tab1)... | MULTISET(ROW(y rt1)) |
| MULTISET (SELECT * FROM tab2)... | MULTISET(ROW(a int)) |
| MULTISET(SELECT p FROM tab2 p)... | MULTISET(ROW(p rt1)) |
| MULTISET (SELECT * FROM tab3)... | MULTISET(ROW(a ROW(x int))) |
下列是另一个集合子查询:
SELECT f(MULTISET(SELECT * FROM tab1 WHERE tab1.x = t.y))
FROM t WHERE t.name = 'john doe';
下列集合子查询包括 UNION 运算符:
SELECT f(MULTISET(SELECT id FROM tab1
UNION
SELECT id FROM tab2 WHERE tab2.id2 = tab3.id3)) FROM tab3;
FROM 子句中的表表达式
GBase 8s 支持在 SELECT 查询和子查询的 FROM 子句中表表达式的 ANSI/ISO 标准语法,替代 GBase 8s 扩展集合子查询语法。在 10.00 和更早的版本中需要关键字 TABLE 和 MULTISET。支持对 SQL 的 ANSI/ISO 标准的这些扩展,但在 SELECT 语句的 FROM 子句中不再需要集合子查询。
下列两个查询返回相同的结果集,但仅第二个查询符合 ANSI/ISO 标准:
SELECT * FROM TABLE(MULTISET(SELECT col1 FROM tab1
WHERE col1 = 100))
AS vtab(c1),
(SELECT col1 FROM tab1 WHERE col1 = 10) AS vtab1(vc1) ORDER BY c1;
SELECT * FROM (SELECT col1 FROM tab1 WHERE col1 = 100) AS vtab(c1),
(SELECT col1 FROM tab1 WHERE col1 = 10) AS vtab1(vc1)
ORDER BY c1;
相同的 SELECT 语句可为集合子查询组合 GBase 8s 扩展与 ANSI/ISO 语法二者的实例:
SELECT * FROM (select col1 FROM tab1 WHERE col1 = 100) AS vtab(c1),
TABLE(MULTISET(SELECT col1 FROM tab1 WHERE col1 = 10)) AS vtab1(vc1)
ORDER BY c1;
集合子查询必须通过两种格式的圆括号定界,但紧跟在 TABLE 关键字之后并括在 MULTISET 集合子查询规范的圆括号(( ))的外部集是对 ANSI/ISO 语法的扩展。此 ANSI/ISO 语法仅在 SELECT 语句的 FROM 子句中是有效的。在任何其他上下文中,您不可省略来自集合子查询规范的这些关键字和圆括号。
FROM 子句中的集合子查询不可包括相关的表引用,也不可包括 LATERAL 关键字。
条件
使用条件来测试数据是否满足某些限定条件。在语法图中您看到对条件的引用的任何地方,请使用此段。
语法
条件
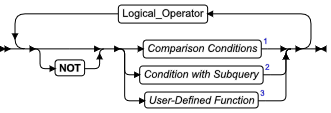
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| Logical_Operator | 组合两个条件 | 有效的选项是 OR ( = logical union) 或 AND ( = logical intersection) | 带有 AND 或 OR 的条件 |
用法
条件是搜索标准,通过逻辑运算符 AND 或 OR 可选地连接起来。可将条件划分为下列几类:
- 比较条件(也称为过滤器或布尔表达式)
- 带有子查询的条件
- 用户定义的函数(仅限于 GBase 8s )
条件可包含聚集函数,仅当它用在 SELECT 语句的 HAVING 子句中,或在子查询的 HAVING 子句中。
在 DELETE、SELECT 或 UPDATE 语句的 WHERE 子句中的条件中不可出现聚集函数,除非下列二者都是 TRUE:
- 起源于父查询的相关列上的聚集。
- WHERE 子句出现在 HAVING 子句内的子查询中。
在 GBase 8s 中,在下列上下文中,用户定义的函数作为条件是无效的:
- 在 SELECT 语句的 HAVING 子句中
- 在检查约束的定义中
在下列上下文中,SPL 例程作为条件是无效的:
- 在检查约束的定义中
- 在 SELECT 语句的 ON 子句中
- 在 DELETE、SELECT 或 UPDATE 语句的 WHERE 子句中
在下列上下文中,外部的例程作为条件是无效的:
- 在检查约束的定义中
- 在 SELECT 语句的 ON 子句中
- 在 DELETE、SELECT 或 UPDATE 语句的 WHERE 子句中
- 在 CREATE TRIGGER 的 WHEN 子句中
- 在 SPL 的 IF、CASE 或 WHILE 语句中
比较条件(布尔表达式)
比较表达式常被称为布尔表达式,因为它们返回 TRUE 或 FALSE 结果。
六种布尔运算符可指定比较条件:
- 关系运算符
- [NOT] BETWEEN … AND 运算符
- [NOT] IN 运算符
- IS [NOT] NULL 运算符
- 触发器类型运算符
- [NOT] LIKE 或 MATCHES 运算符
在此图中总结它们的语法并在后面的部分说明。
比较条件
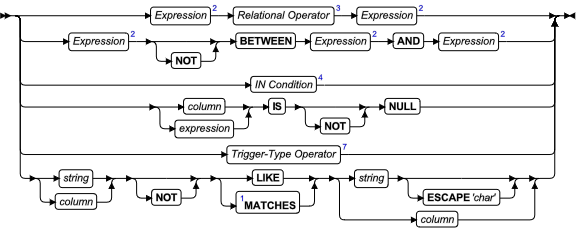
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 在括起来的字符串中要作为转义字符的 ASCII 字符。单引号(')和双引号(" )作为 char 是无效的。 | 请参阅 ESCAPE 与 LIKE 一起使用 和 ESCAPE 与 MATCHES 一起使用 | 引用字符串 |
| column | 列名称(或 ROW 类型列的字段),以其数据值与 NULL、与 string 或与另一 column 做比较 | 可通过标识符、同义词或表或视图的别名来限定。 | 请参阅 列名称 |
| expression | 返回单个值的 SQL 表达式 | 必须返回单个值 | 表达式 |
| string | 通过单引号(')或双引号(" )定界的字符串 | 两个定界符必须是相同的 | 请参阅 引用字符串 |
下列部分描述比较条件的不同类型:
- 关系运算符条件
- BETWEEN 条件
- IN 条件
- IS NULL 和 IS NOT NULL 条件
- LIKE 和 MATCHES 条件。
要获取在 SELECT 语句的上下文中比较条件的讨论,请参阅 在 WHERE 子句中使用条件。
比较条件中的字面 DATE 或 DATETIME 值应为年份指定 4 为数字。当您指定 4 位字符年份时,DBCENTURY 环境变量对结果不起作用。当您指定 2 位数字年份时,DBCENTURY 可影响数据库服务器解释比较条件的方式,这可能产生您不希望的结果。要获取更多关于 DBCENTURY 的信息,请参阅 《GBase 8s SQL 指南:参考》。
列名称
Column Name 段可为比较条件中的一个元素。列的名称(或 ROW 数据类型的列内一个或多个字段)不是比较的主体,但数据库服务器使用此 SQL 标识符来访问数据库表或视图中指定列的或行字段的数据值。
列名称
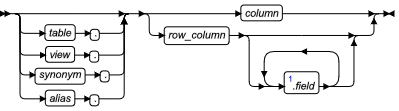
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| alias | 表或视图的临时的替换名称 | 必须在 SELECT 语句的 FROM 子句中定义 | 标识符 |
| column | 列的名称 | 在指定的表中必须存在 | 标识符 |
| field | 在 ROW 类型列中要比较的字段 | 必须是 row-column name 或 field name(对于嵌套的行)的组件 | 标识符 |
| row_column | 类型 ROW 的列 | 必须是现有的命名的 ROW 类型或未命名的 ROW 类型 | 标识符 |
| synonym、table、view | 同义词、表或视图的名称 | synonym 和它指向的表或视图必须在数据库中存在 | 标识符 |
要获取更多关于在这些条件中 column 名称的含义的信息,请参阅 IS NULL 和 IS NOT NULL 条件 和 LIKE 和 MATCHES 条件。
条件中的引号
当您将列表达式与任何比较条件中的常量表达式做比较时,请遵守下列规则:
- 如果该列有数值数据类型,则请不要在引号之间括起常量表达式。
- 如果该列有字符数据类型,则请在引号之间括起常量表达式。
- 如果该列有时间数据类型,则请在引号之间括起常量表达式。
否则,您可能得不到期望的结果。
下列示例展示在比较条件中引号的正确用法。在此,ship_instruct 列有字符数据类型,order_date 列有日期数据类型,而 ship_weight 列有数值数据类型。
SELECT * FROM orders
WHERE ship_instruct = 'express'
AND order_date > '05/01/98'
AND ship_weight < 30;
关系运算符条件
关系运算符定量地比较两个表达式。
要获取受到支持的关系运算符及其描述的列表,请参阅 关系运算符。
下列示例展示一些关系运算符条件:
city[1,3] = 'San'
o.order_date > '6/12/98'
WEEKDAY(paid_date) = WEEKDAY(CURRENT- (31 UNITS DAY))
YEAR(ship_date) < YEAR (TODAY)
quantity <= 3
customer_num <> 105
customer_num != 105
关系运算符条件中的运算对象不可有 UNKNOWN 或 NULL 值。如果 condition 内的表达式有 UNKNOWN 值,则由于它引用未初始化的变量,数据库服务器会产生异常。
NULL 值的条件测试
如果 condition 内的任何表达式求值为 NULL,则 condition 不可为真,除非您正在使用 IS NULL 运算符显式地进行测试。例如,如果 paid_date 列有 NULL 值,则下列查询都不可检索那一行:
SELECT customer_num, order_date FROM orders
WHERE paid_date = '';
SELECT customer_num, order_date FROM orders
WHERE NOT (paid_date !='');
您必须使用 IS NULL 运算符来测试 NULL 值,如下一示例所示。
SELECT customer_num, order_date FROM orders
WHERE paid_date IS NULL;
在 IS NULL 和 IS NOT NULL 条件 中描述 IS NULL 运算符及其逻辑反、IS NOT NULL 运算符。
BETWEEN 条件
使用 BETWEEN 条件来测试数字表达式、字符表达式或时间表达式的值是否在指定的范围内。
BETWEEN 条件
![]()
用法
NULL 值不可满足该条件。定义的范围可求值为 NULL 的表达式也不可满足。
BETWEEN 条件中的三个表达式必须满足这些限制:
- 所有三个表达式都必须求值为相互可比的数值、时间或字符数据类型。
- 紧跟在 BETWEEN 关键字之后的表达式的值必须小于跟在 AND 关键字之后的表达式的值。
BETWEEN 条件中的数值和时间表达式
对于数值表达式,小于意味着在数轴的左边。
对于 DATE 和 DATETIME 表达式,小于意味着时间较早。
对于 INTERVAL 表达式,小于意味着更短的时间跨度。
BETWEEN 条件中的字符表达式
对于 CHAR、VARCHAR 和 LVARCHAR 表达式,小于意味着在代码集顺序之前。
对于 NCHAR 和 NVARCHAR 表达式,小于 意味着在本地化的排序顺序之前,如果存在一个的话;否则小于意味着在代码集合顺序之前。
如果该语言环境定义了排序顺序的话,则将基于语言环境的排序顺序用于 NCHAR 和 NVARCHAR 表达式。因此,对于 NCHAR 和 NVARCHAR 表达式,小于意味着在基于语言环境的排序顺序之前。要获取更多关于基于语言环境的排序顺序以及 NCHAR 和 NVARCHAR 数据类型的信息,请参阅 GBase 8s GLS 用户指南。
要获取关于在有 NLCASE INSENSITIVE 属性的数据库中带有 NCHAR 和 NVARCHAR 运算对象的关系运算符表达式如何不同于在区分大小写的数据库中它们的行为的信息,请参阅主题 在区分大小写的数据库中的 NCHAR 和 NVARCHAR 表达式。
BETWEEN 条件中的 NOT 关键字
对于要为 TRUE 的 BETWEEN 条件,依赖于您是否包括 NOT 关键字。
- 如果您省略 NOT 关键字,则仅当 BETWEEN 关键字左边的表达式的值在 BETWEEN 关键字右边的两个表达式的包括范围之中时,BETWEEN 条件才为 TRUE。
- 如果 NOT 关键字在 BETWEEN 关键字的紧前边,则仅当 BETWEEN 关键字左边的表达式的值不在 BETWEEN 关键字的右边的两个表达式的值的包括范围之中时,BETWEEN 条件才为 TRUE。
否则,BETWEEN 条件为 FALSE。
BETWEEN 条件的示例
下列示例说明 BETWEEN 条件:
order_date BETWEEN '6/1/97' and '9/7/97'
zipcode NOT BETWEEN '94100' and '94199'
EXTEND(call_dtime, DAY TO DAY) BETWEEN
(CURRENT - INTERVAL(7) DAY TO DAY) AND CURRENT
lead_time BETWEEN INTERVAL (1) DAY TO DAY
AND INTERVAL (4) DAY TO DAY
unit_price BETWEEN loprice AND hiprice
IN 条件
当项列表中包括该关键字左边的表达式时,满足 IN 条件。
IN 条件
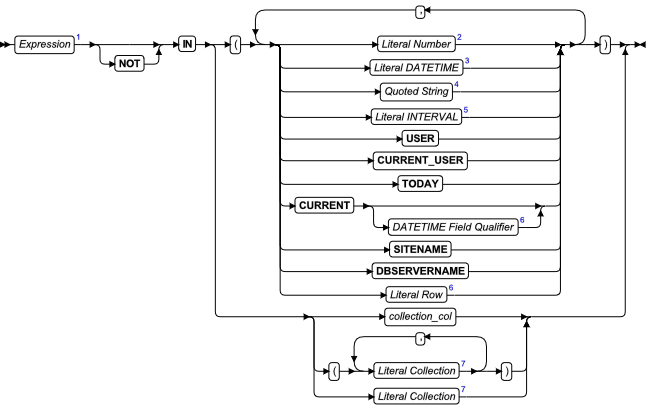
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| collection_col | 在 IN 条件中使用的集合列的名称 | 该列必须在指定的表中存在 | 标识符 |
如果您指定 NOT 运算符,则当该表达式不在项的列表中时,该 IN 条件为 TRUE。NULL 值不满足 IN 条件。
下列示例展示一些 IN 条件:
WHERE state IN ('CA', 'WA', 'OR')
WHERE manu_code IN ('HRO', 'HSK')
WHERE user_id NOT IN (USER)
WHERE order_date NOT IN (TODAY)
在 GBase 8s ESQL/C 中,在执行时刻对内建的 TODAY 函数求值。当打开游标或当执行查询时,对内建的 CURRENT 函数求值,如果它是单个 SELECT 语句的话。
内建的 USER 函数区分大小写;例如,它将 minnie 与 Minnie 解释为不同的值。
使用带有集合数据类型的 IN 运算符
您可使用 IN 运算符来确定集合中是否包含某个元素。
集合可为简单的集合或嵌套的集合。(在嵌套的集合类型中,集合的元素类型也是集合类型。)当您使用 IN 来搜索集合中的元素时,IN 左边或右边的表达式不可包含 BYTE 或 TEXT 数据类型。
假设您创建包含两个集合列的下列表:
CREATE TABLE tab_coll
(
set_num SET(INT NOT NULL),
list_name LIST(SET(CHAR(10) NOT NULL) NOT NULL)
);
下列语句片段展示您可能对 tab_coll 表的集合列上的搜索条件使用 IN 运算符的方式:
WHERE 5 IN set_num
WHERE 5.0::INT IN set_num
WHERE "5" NOT IN set_num
WHERE set_num IN ("SET{1,2,3}", "SET{7,8,9}")
WHERE "SET{'john', 'sally', 'bill'}" IN list_name
WHERE list_name IN ("LIST{""SET{'bill','usha'}"",
""SET{'ann' 'moshi'}""}",
"LIST{""SET{'bob','ramesh'}"",
""SET{'bomani' 'ann'}""}")
通常,当您在集合数据类型上使用 IN 运算符时,数据库服务器检查 IN 运算符左边的值是否是 IN 运算符右边值的集合中的一个元素。
IN 多列
in关键字可以以多列作为联合元素进行布尔结果判断,常用在where子句、join on子句、having子句后使用。
语法:
(columnname1,columnname2...) [NOT] IN(dataset|subquery)
参数说明:
-
columnname1:表中列。
-
dataset:数据集合。最多可以支持10000个数据集合。
-
subquery:子查询,可以是简单子查询、相关子查询、union子查询。
用法及限制:
-
ORACLE模式下运行。
-
字符集集合中会自动移除空格,如 (a,b) in ((1,’a’),(2,’b’))。
-
在查询时,包含exists 的in多列相关子查会改写为join优化。
-
in多列中重复的常量会进行去除重复优化。
-
表关联时,关联条件中有or会消除or合并为in的优化。
-
对 in常量和in子查询进行了索引优化。只有在in左侧全为列表达式,且第一个列表达式有索引的时候可以使用索引,即:(a,b) in () 当a列有索引时,且a,b全为列会使用索引优化。
-
支持in左右元素使用绑定变量(a,?) in ((?,’a’),(?,?))。
-
支持in左右元素使用函数,例如:(to_date(a),to_number(b)) in ((to_date(‘2024-06-01’),1))。
-
支持join on后的多列in跨表使用,例如:t1 join t2 on (t1.a,t2.b) in ()。
-
支持in左右元素使用投影列(today, b) in ((today,1))。
-
in谓词左侧不支持多列子查询,报错。
-
不支持group by函数后使用多列 in 子查询, (单列in也不支持),会报错。
-
不支持text、bytes类型、集合类型、ROW类型。
-
in多列不支持集合类型。
功能用例:
SQL> create table t1(c1 int,c2 int);
Table created.
SQL> insert into t1 values(1,2);
1 row(s) inserted.
SQL> insert into t1 values(1,3);
1 row(s) inserted.
例1:in多列与子查询连用
> select * from t1 where (c1,c2) in (select c1,c2 from t1) ;
C1 C2
1 2
1 3
2 row(s) retrieved.
例2:in使用多列过滤
> select * from t1 where (c1,c2) in ((1,2));
C1 C2
1 2
1 row(s) retrieved.
IS NULL 和 IS NOT NULL 条件
如果紧接在 IS 关键字之前的术语指定下列未定义的值之一,则满足该 IS NULL 条件:
- 包含空值的 column 的名称。
- 求值为空的 expression。
反之,如果您使用 IS NOT NULL 运算符,则当 column 包含一个非空的值时,或当紧接在 IS NOT NULL 关键字之前的 expression 求值不为空时,满足该条件。
假设您希望在可包含 NULL 值的列上执行算术计算。您可创建表、将值插入到表内,然后为了数据计算执行一使用将空值转换为 0 的通用的 CASE 表达式的查询:
CREATE TABLE employee (emp_id INT, savings_in_401k INT, total_salary INT);
INSERT INTO employee VALUES(1, 5000, 40000);
INSERT INTO employee VALUES(2, 0, 40000);
INSERT INTO employee VALUES(3, NULL, 100000);
SELECT emp_id, savings_in_401k AS employer_match FROM employee WHERE
CASE WHEN(savings_in_401k IS NULL) THEN 0
ELSE savings_in_401k END * 0.06 > 0;
此示例展示通过使用 CASE 表达式中的 IS NULL,您可为不可计算的条目提供值,因为空不是有效的数值。
如果该列包含空值,或如果该表达式由于包含一个或多个空值而不可求值,则满足 IS NULL 条件。如果您使用 IS NOT NULL 运算符,则当运算对象是不为空的列值,或是求值不为空的表达式时,满足该条件。
触发器类型的布尔运算符
GBase 8s 的触发器类型的布尔运算符可在运行时测试当前正在执行的触发器活动是否是通过 DML 事件的指定的类型触发了的。这些运算符不使用操作对象。
触发器类型的布尔运算符

如果当前正在执行的触发器的触发事件是对应于操作符的名称的 DML 操作,则这些操作符返回 TRUE ('t'),否则它们返回 FALSE ('f')。在 IF 语句中,在 CASE 表达式中,以及在布尔条件为有效的 SPL 触发器例程内的其他上下文中,这些操作符是有效的。
例如,在下列语句片断中,仅当通过 INSERT 事件激活的当前正在执行的触发器时,才执行第一个 THEN 子句中的 LET 语句,且仅当通过 DELETE 事件激活了该触发器时,才执行第二个 THEN 子句中的 LET 语句:
IF (INSERTING = 't') THEN
LET square = NEW.X * NEW.X
ELIF (DELETING = 't') THEN
LET square = 0
仅在表上触发器或(对于 DELETING、INSERTING 和 UPDATING运算符)在视图上 INSTEAD OF 触发器的 FOR EACH ROW 触发的活动中调用的触发器 UDR 中,SELECTING、DELETING、INSERTING 和 UPDATING 运算符才是有效的。如果您尝试在任何其他的上下文中使用触发器类型的布尔运算符,则发出错误。
如果通过 MERGE 语句已激活了的 Delete、Insert 或 Update 触发器调用触发器例程,则
- 在 MERGE 正在从目标表删除行时,DELETING 返回 TRUE。
- 在 MERGE 正在将行插入到目标表内时,INSERTING 返回 TRUE。
- 在 MERGE 正在更新目标表的行时,UPDATING 返回 TRUE。
LIKE 和 MATCHES 条件
LIKE 或 MATCHES 条件测试字符串的匹配。
当下列测试为 TRUE时,条件为 TRUE,或满足:
- 左边的列的值与括起来的字符串指定的模式相匹配。您可在字符串中使用通配符。NULL 值不满足该条件。
- 左边的列的值与右边指定的列的模式相匹配。右边的列的值用作该条件中的匹配模式。
如果括起来的字符串包括字面字符,这些字符与 LIKE 或 MATCHES 运算符识别的任何通配符相匹配,则 ESCAPE 子句可定义您可在括起来的字符串中包括的 ASCII 字符。当将左边的列值与括起来的字符串相比较时,将紧跟在转义字符之后的下一字符解释为字面字符,而不解释为通配符,且忽略该转义字符。LIKE 和 MATCHES 运算符识别不同的通配符。要获取更多关于 LIKE 和 MATCHES 转义字符的信息,请参阅 ESCAPE 与 LIKE 一起使用 和 ESCAPE 与 MATCHES 一起使用 主题。
您仅可使用带有括起来的字符串的单引号(')来匹配字面的单引号;您不可使用 ESCAPE 子句。您可使用单引号字符作为与任何其他模式相匹配的转义字符,如果您将它写作 '''' 这样的话。
您在 LIKE 或 MATCHES 条件中指定的列应为简单的字符数据类型,像 CHAR、LVARCHAR、NCHAR、NVARCHAR 或 VARCHAR。例如,您不可在 LIKE 或 MATCHES 条件中指定复合的数据类型,诸如 ROW 类型列。(ROW 类型列是声明为命名的或未命名的 ROW 类型的列。)类似地,数据库服务器不可对使用带有简单大对象或智能大对象列(诸如 CLOB 列)的 LIKE 或 MATCHES 的条件求值;包括此条件的查询失败并报错 -640。
NOT 运算符
当左边的列有一非 NULL 的值,且与括起来的字符串指定的模式不匹配时,NOT 运算符使得该搜索条件成功。
例如,下列条件排除 lname 列中以字符 Baxter 开头的所有行:
WHERE lname NOT LIKE 'Baxter%'
WHERE lname NOT MATCHES 'Baxter*'
LIKE 运算符
LIKE 是用于将列值与另一列值或括起来的字符串相比较的 ANSI/ISO 标准运算符。
LIKE 运算符支持括起来的字符串中的这些通配符。
通配符 作用
% 与零个或多个字符相匹配
_ 与任何单个字符相匹配
除了 % 和 _ 之外,当 DEFAULTESCCHAR 配置参数和 DEFAULTESCCHAR 会话环境变量都未设置时,LIKE 支持第三个通配符:
通配符 作用
\ 移除下一字符的特殊意义(通过指定 % 或 \_ 或 \ 来匹配字面的 % 或 _ 或 \)
使用反斜杠(\)符号作为缺省的转义字符(当未设置 DEFAULTESCCHAR 时) 是对 SQL 的 ANSI/ISO 标准的 GBase 8s 扩展。通过将 DEFAULTESCCHAR 值设置为那个字符,您可指定反斜杠(\)符号或某些其他 ASCII 字符作为缺省的转义字符。要获取更多信息,请参阅 DEFAULTESCCHAR 环境选项。
在符合 ANSI 的数据库中,您仅可使用 LIKE 转义字符来转义百分号(%)、下划线(_)或转义字符自身。
下列条件单独或在更长的字符串中测试字符串 tennis 的 description 列,诸如 tennis ball 或 table tennis paddle:
WHERE description LIKE '%tennis%' ESCAPE '\'
下一个示例测试包含一下划线字符的行的 description。在此,反斜杠(\)转义字符是必要的,因为下划线(_)是通配符。
WHERE description LIKE '%\_%' ESCAPE '\'
LIKE 运算符有一相关联的名为 like( ) 的运算符函数。您可定义 like( ) 函数来处理您自己的用户定MATCHES 运算符
义的数据类型。另请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
MATCHES 运算符是用于将列值与另一列值或括起来的字符串相比较的 GBase 8s 扩展。
MATCHES 运算符支持括起来的字符串中的这些通配符。
通配符 作用
* 与零个或多个字符的任何字符串相匹配
? 与任何单个字符相匹配
[ . . . ] 与包括范围的任何括起来的字符相匹配,如在 [a-z] 中那样。不可转义方括号内的字符。
^ 作为方括号内的第一个字符,与未罗列的任何字符相匹配。因此,[^abc] 与除了 a、b 或 c 之外的任何字符相匹配。
\ 移除下一字符的特殊意义(通过指定 \ 或 \* 或 ?,等等,来与字面的 \ 或任何其他通配符相匹配)
下列条件单独或在更长的字符串内测试字符串 tennis,诸如 tennis ball 或 table tennis paddle:
WHERE description MATCHES '*tennis*'
对于名称 Frank 和 frank,下列条件为 TRUE:
WHERE fname MATCHES '[Ff]rank'
对于以 F 或 f 开头的任何名称,下列条件为 TRUE:
WHERE fname MATCHES '[Ff]*'
对于任何以字母 a、b、c 或 d 结尾的任何名称,下一条件为 TRUE:
WHERE fname MATCHES '*[a-d]'
MATCHES 有一相关联的 matches( ) 运算符函数。您可为您自己的用户定义的数据类型定义 matches( ) 函数。要获取更多信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
如果 DB_LOCALE 或 SET COLLATION 指定支持本地化排序的非缺省的语言环境,且您使用方括号([ . . . ])符号为 MATCHES 运算符指定范围,则数据库服务器使用本地化的排序顺序,而不是代码集顺序,来解释该范围并比较那些有 CHAR、CHARACTER VARYING、LVARCHAR、NCHAR、NVARCHAR 和 VARCHAR 数据类型的值。
通常的规则是,仅可在本地化的排序顺序中比较 NCHAR 和 NVARCHAR 数据类型,此行为是该规则的例外。要获取更多关于包括 MATCHES 或 LIKE 运算符的条件的 GLS 方面的信息,请参阅 GBase 8s GLS 用户指南。
在 NLSCASE INSENSITIVE 数据库中,对 NCHAR 和 NVARCHAR 数据的比较操作不理会大小写的差异,因此数据库服务器将包含相同序列字符的字符串之中的大写变量作为重复处理。作为 MATCH 运算符的运算对象,下列字符串的所有对都返回 TRUE:
'beta' 'Beta' 'BETA' 'bETa' 'betA' 'BetA'
要获取更多信息,请参阅 在 NLSCASE INSENSITIVE 数据库中重复的行 和 在区分大小写的数据库中的 NCHAR 和 NVARCHAR 表达式。
ESCAPE 与 LIKE 一起使用
ESCAPE 子句可指定与缺省的转义字符不同的一个转义字符。通过 DEFAULTESCCHAR 配置参数或 DEFAULTESCCHAR 会话环境选项设置缺省的转义字符。
例如,如果您在 ESCAPE 子句中指定 z,则将包含了 z_ 的括起来的字符串运算对象解释为包括字面的下划线(_)字符,而不将 _ 作为通配符。 类似地,将 z% 解释作为字面的百分号(% ),而不将 % 当做通配符。最后,会将字符串中的字符 zz 解释为单个字面的 z。 下列语句从 customer 表检索行,其中的 company 列包括字面的下划线字符:
SELECT * FROM customer WHERE company LIKE '%z_%' ESCAPE 'z';
您还可使用包含单个字符的主变量。下一语句使用主变量来指定一转义字符:
EXEC SQL BEGIN DECLARE SECTION;
char escp='z';
char fname[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL select fname from customer
into :fname where company like '%z_%' escape :escp;
ESCAPE 与 MATCHES 一起使用
ESCAPE 子句可指定与缺省的转义字符不同的转义字符。通过 DEFAULTESCCHAR 配置参数或 DEFAULTESCCHAR 会话环境选项设置缺省的转义字符。
使用此作为您想要的缺省的转义字符,反斜杠,来在括起来的字符串中包括问号(?)、星号(*)、插入符(^) 或左方括号([)或右方括号(])作为字面的字符,以防止将它们解释为特殊字符。如果您选择使用 z 作为该转义字符,则字符串中的字符 z? 代表字面的问号(?)。类似地,字符 z* 代表字面的星号(*)。最后,字符串中的字符 zz 代表单个字符 z。
下列示例从 customer 表检索行,其中的 company 列的值包括问号(?):
SELECT * FROM customer WHERE company MATCHES '*z?*' ESCAPE 'z';
独立条件
独立条件可为没有显式地罗列在比较条件的语法中的任何表达式。仅当表达式返回 BOOLEAN 值时,它作为条件才是有效的。例如,下列示例返回 BOOLEAN 数据类型的值:
funcname(x)
带有子查询的条件
在条件内包括 SELECT 语句,指定带有子查询的条件。您可在 SELECT、INSERT、DELETE 或 UPDATE 语句中使用子查询来执行下列这样的任务:
- 将表达式与查询的结果作比较。
- 确定查询的结果中是否包括表达式。
- 询问查询是否选择任何行。
带有子查询的条件

子查询可依赖于外部 SELECT 语句正在求值的当前行;在此情况下,该子查询称为相关的子查询。(要获取相关的子查询及其对性能的影响的讨论,请参阅 GBase 8s SQL 教程指南。)
下列部分描述子查询条件及其语法。
- 要获取在 SELECT 语句的上下文中子查询条件的类型的讨论,请参阅 在 WHERE 子句中使用条件。
- 要获取在 INSERT 语句的上下文中子查询条件的类型的讨论,请参阅 SELECT 语句的子集。
- 要获取在 DELETE 语句的上下文中子查询条件的类型的讨论,请参阅 DELETE 的 WHERE 子句中的子查询。
- 要获取在 UPDATE 语句的上下文中子查询条件的类型的讨论,请参阅 UPDATE 的 WHERE 子句中的子查询。
依赖于子查询的上下文,子查询可返回单个值、无值或值集。如果子查询返回值,它必须仅选择单个列。如果子查询简单地检查一行(或多行)是否存在,则它可选择任何数目的行和列。
子查询不可引用 BYTE 或 TEXT 列,也不可包含 ORDER BY 子句。然而,在 FROM 子句中指定表表达式的子查询可包括 ORDER BY 子句。
如果子查询的 FROM 子句指定外部语句在这些子句之一中引用的同一表或视图,则子查询及其外部 DML 语句在同一表对象上操作:
- 在 DELETE 或 SELECT 语句的 FROM 子句中
- 在 INSERT 语句的 INTO 子句中
- 在 UPDATE 语句的“表选项”或“集合派生的表”规范中。
仅在 DELETE 或 UPDATE 语句的 WHERE 子句中,那些返回多行和与括起来的 DML 语句操作的同一表或视图的子查询才是有效的。即使在此上下文中,这样的子查询也返回错误 -360,除非满足所有下列条件:
- 该子查询不引用它的 FROM 列表中的任何列名称,它在 projection 列表中未指定的表中
- 使用带有 Subquery 语法的 Condition 指定该子查询。
- 该子查询内的任何 SPL 例程不可引用正在修改的表。
下列程序片断包括在 UPDATE 和 DELETE 语句中带有子查询的条件的示例:
CREATE TABLE t1 ( a INT, a1 INT)
CREATE TABLE t2 ( b INT, b1 INT) ;
. . .
UPDATE t1 SET a = a + 10 WHERE EXISTS
(SELECT a FROM t1 WHERE a > 1);
UPDATE t1 SET a = a + 10 WHERE a IN
(SELECT a FROM t1, t2 WHERE a > b
AND a IN
(SELECT a FROM t1 WHERE a > 50 ) );
DELETE FROM t1 WHERE EXISTS
(SELECT a FROM t1);
要获取更多关于在 DELETE 语句中的子查询的信息,请参阅 DELETE 的 WHERE 子句中的子查询。
要获取更多关于在 UPDATE 语句中的子查询的信息,请参阅 UPDATE 的 WHERE 子句中的子查询。
IN 子查询
如果表达式的值与来自子查询的一个或多个值相匹配,则 IN 子查询条件为 TRUE。(该子查询必须仅返回一行,但它可返回多个列。)关键字 IN 等同于 =ANY 规范。关键字 NOT IN 等同于 !=ALL 规范。请参阅 ALL、ANY 和 SOME 子查询。
IN 子查询
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| subquery | 内嵌的查询 | 不可包含 FIRST 子句也不可包含 ORDER BY 子句 | SELECT 语句 |
下列 IN 子查询的示例查找不包含 baseball gloves (stock_num = 1)的订单的订单号:
WHERE order_num NOT IN
(SELECT order_num FROM items WHERE stock_num = 1)
由于 IN 子查询测试行的出现,因此子查询结果中的重复的行不影响主查询的结果。因此,子查询中的 UNIQUE 或 DISTINCT 关键字对查询结果不起作用,尽管不测试重复可提升查询性能。
EXISTS 子查询条件
如果子查询返回行,则 EXISTS 子查询条件求值为 TRUE。以 EXISTS 子查询,可返回一个或多个列。该子查询总是包含对主查询中表的列的引用。如果您在不包含 HAVING 子句的 EXISTS 子查询中使用聚集函数,则总会返回至少一行。
EXISTS 子查询
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| subquery | 内嵌的查询 | 不可包含 FIRST 子句也不可包含 ORDER BY 子句 | SELECT 语句 |
下列带有 EXISTS 子查询的 SELECT 语句的示例返回从未被订购(且因此未罗列在 items 表中)的每个项的存货编号和制造商代码。您可在此 SELECT 语句中适当地使用 EXISTS 子查询,因为您使用子查询来测试 items 中的 stock_num 以及 manu_code。
SELECT stock_num, manu_code FROM stock
WHERE NOT EXISTS (SELECT stock_num, manu_code FROM items
WHERE stock.stock_num = items.stock_num AND
stock.manu_code = items.manu_code);
如果您在列名称的位置中的子查询中使用 SELECT *,则前面的示例同样奏效,因为测试整行的存在;不测试特定的列值。
ALL、ANY 和 SOME 子查询
使用 ALL、ANY 和 SOME 关键字来指定何种情况下产生条件 TRUE 或 FALSE。当使用 ALL 关键字时,当使用 ANY 关键字时为 TRUE 的搜索条件可能不为 TRUE,反之亦然。
ALL、ANY、SOME 子查询
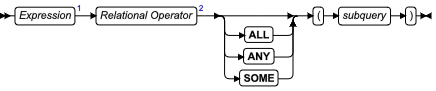
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| subquery | 嵌入的查询 | 不可包含 FIRST 或 ORDER BY 子句 | SELECT 语句 |
使用 ALL 关键字
如果子查询返回的每个值的比较都为 TRUE,则 ALL 关键字指定该搜索条件为 TRUE。如果子查询未返回值,则该条件为 TRUE。
在下列示例中,第一个条件测试是否每一 total_price 都大于订单号 1023 中每个项的总价。第二个条件使用 MAX 聚集函数来产生同样的结果。
total_price > ALL (SELECT total_price FROM items
WHERE order_num = 1023)
total_price > (SELECT MAX(total_price) FROM items
WHERE order_num = 1023)
使用带有 ALL 子查询的 NOT 关键字测试对于子查询返回的至少一个元素是否有一个表达式不为 TRUE。例如,当表达式 total_price 不大于所有被选择的值时,下列条件为 TRUE。也就是说,当 total_price 不大于订单号 1023 中最高的总价时,它为 TRUE。
NOT total_price > ALL (SELECT total_price FROM items
WHERE order_num = 1023)
使用 ANY 或 SOME 关键字
ANY 关键字表示,如果对于至少一个返回值的比较是 TRUE,则搜索条件为 TRUE。如果子查询未返回值,则搜索条件为 FALSE。SOME 关键字是 ANY 的同义词。
当总价大于订单号 1023 中至少一个项的总价时,下列条件为 TRUE。第一个条件使用 ANY 关键字;第二个使用 MIN 聚集函数:
total_price > ANY (SELECT total_price FROM items
WHERE order_num = 1023)
total_price > (SELECT MIN(total_price) FROM items
WHERE order_num = 1023)
使用带有 ANY 子查询的 NOT 关键字测试对于子查询返回的所有元素表达式是否不是 TRUE。例如,当表达式 total_price 不大于任何被选择的值时,下列条件为 TRUE。也就是说,当 total_price 不大于订单号 1023 中的总价时,它是 TRUE。
NOT total_price > ANY (SELECT total_price FROM items
WHERE order_num = 1023)
省略 ANY、ALL 或 SOME 关键字
如果您知道子查询将正好返回一个值,则您可省略子查询中的关键字 ANY、ALL 或 SOME。如果您省略 ANY、ALL 或 SOME 关键字,且该子查询返回多个值,则您收到错误。在下列示例中的子查询仅返回一行,因为它使用聚集函数:
SELECT order_num FROM items
WHERE stock_num = 9 AND quantity =
(SELECT MAX(quantity) FROM items WHERE stock_num = 9);
NOT 运算符
如果您以关键字 NOT 作为条件的开始,则仅当 NOT 限定的条件为 FALSE 时,该测试才是 TRUE。如果 NOT 限定的条件有一 NULL 或一 UNKNOWN 值,则 NOT 运算符无效。
下列真值展示带有 3– 有值的布尔运算对象的 NOT 的作用。在此,T 代表 TRUE 条件,F 代表 FALSE 条件,且问号(?)表示 UNKNOWN 条件。(当运算对象为 NULL 时,可发生 UNKNOWN 值)。

左边的列展示 NOT 运算符的运算对象的值,右边的列展示将 NOT 应用于操作对象之后返回的值。
带有 AND 或 OR 的条件
您可将简单的条件与逻辑运算符 AND 或 OR 组合来形成复合的条件。
下列 SELECT 语句在它们的 WHERE 子句中包含复合的条件的示例:
SELECT customer_num, order_date FROM orders
WHERE paid_date > '1/1/97' OR paid_date IS NULL;
SELECT order_num, total_price FROM items
WHERE total_price > 200.00 AND manu_code LIKE 'H'
SELECT lname, customer_num FROM customer
WHERE zipcode BETWEEN '93500' AND '95700'
OR state NOT IN ('CA', 'WA', 'OR');
下列真值表展示 AND 和 OR 运算符的作用。字母 T 代表 TRUE 条件,F 代表 FALSE 条件,问号(?)代表 UNKNOWN 值。当使用逻辑运算符的表达式的一部分为 NULL 时,可发生 UNKNOWN 值。

在左边的临界值代表第一个操作对象,最上面一行中的值代表第二个操作对象。每一 3x3 矩阵内的值展示将该操作符应用于那些值的操作对象之后所返回的值。
如果布尔表达式球值为 UNKNOWN。则不满足该条件。
请考虑下列 WHERE 子句内的示例:
WHERE ship_charge/ship_weight < 5 AND order_num = 1023
order_num = 1023 的行是 ship_weight 为 NULL 的行。因为 ship_weight 为 NULL,所以 ship_charge/ship_weight 也是 NULL;因此, ship_charge/ship_weight < 5 的真值是 UNKNOWN。因为 order_num = 1023 为 TRUE,因此,AND 表声明整个条件的真值为 UNKNOWN。因此,不选择那行。如果在 AND 的位置使用 OR 作为条件,则该条件会是 TRUE。
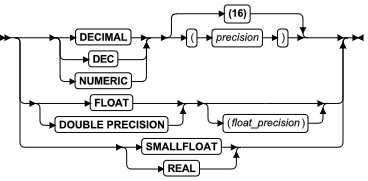
数据类型
“数据类型”段指定列的、集合的组件的、ROW 类型内的字段的、例程参数的、表达式的返回值的或强制转型函数的返回值的数据类型。无论您何时看到对语法图中数据类型的引用时,请使用此段。
语法
数据类型

用法
下面的部分总结这些数据类型。要获取更多信息,请参阅 《GBase 8s SQL 指南:参考》 中关于数据类型的章节。
内建的数据类型
内建的数据类型是由数据库服务器定义的数据类型。
内建的数据类型
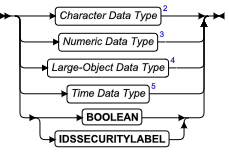
在解释和转换所需的信息和支持函数的意义上讲,这些是“构建在数据库服务器之内”,这些数据类型是数据库服务器软件的一部分,支持 character、numeric、large-object 和 time 内建数据类型的类别。在后面的部分中描述这些。
字符数据类型
字符数据类型使得数据库服务器能够存储文本字符串。
字符数据类型
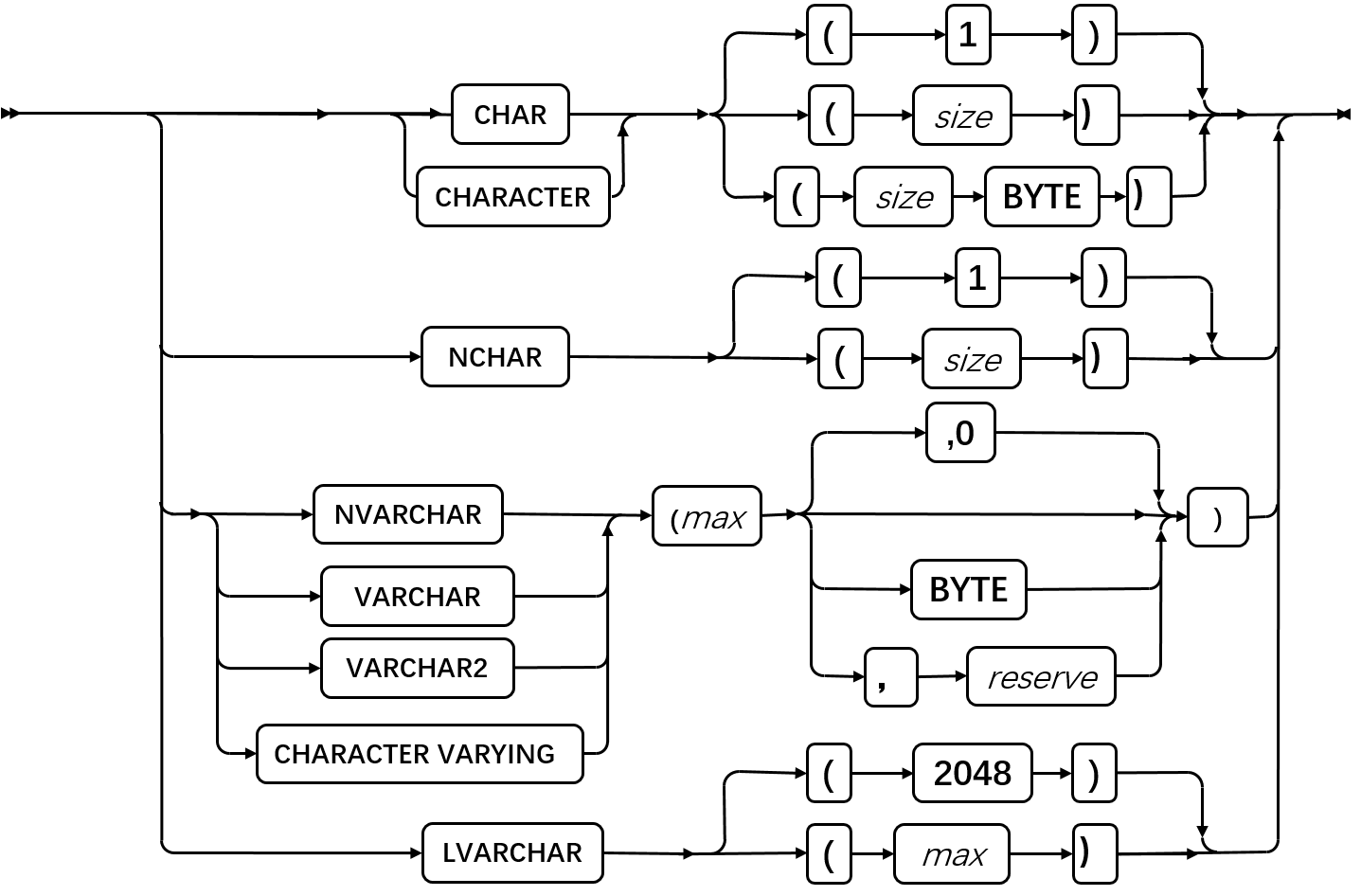
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| max | 以字节计的最大大小。对于 VARCHAR 和 NVARCHAR,这是必需的。LVARCHAR 缺省为 2048 | VARCHAR,VARCHAR2和NVARCHAR: 整数;1 ≤ max ≤ 32,765 LVARCHAR:1 ≤ max ≤ 32,739 | 精确数值 |
| reserve | 保留的字节。缺省为 0。 | 整数;0 ≤ reserve ≤ max | 精确数值 |
| size | 以字节计的大小。缺省为 1。 | 整数;1 ≤ size ≤ 32,767 | 精确数值 |
如果数据类型声明包括空的圆括号,比如 LVARCHAR( ),则数据库服务器发出错误。要声明缺省的长度的 CHAR 或 LVARCHAR 数据类型,简单地省略任何 (size) 或 (max) 规范。 GBase 8s 的 CREATE TABLE 语句接受没有 (max) 也没有 (max, reserve) 规范的 VARCHAR 和 NVARCHAR 列声明,使用 ( 1, 0 ) 作为该列的 (max, reserve) 缺省值。
下表总结内建的字符数据类型。
| 数据类型 | 描述 |
|---|---|
| CHAR | 存储固定长度(最多 32,767 字节)的单字节或多字节文本字符串;支持文本数据的次序中的代码集顺序。缺省的大小为 1 字节。 |
| CHARACTER | CHAR 的同义词 |
| CHARACTER VARYING | VARCHAR 的符合 ANSI 的同义词 |
| LVARCHAR | 存储可变长度(最多 32,739 字节)的单字节或多字节文本字符串。在同一表中其他列的大小可进一步降低此上限。缺省的大小为 2,048 字节。 |
| NCHAR | 存储固定长度(最多 32,767 字节)的单字节或多字节文本字符串;支持文本数据的本地化次序。 |
| NVARCHAR | 存储可变长度(最多 32,765 字节)的单字节或多字节文本字符串;支持文本数据的本地化次序。 |
| VARCHAR/VARCAHR2 | 存储可变长度(最多 32765 字节)的单字节或多字节文本字符串;支持文本数据的代码集顺序次序。 |
单字节和多字节字符和语言环境
所有内建的字符数据类型可支持 DB_LOCALE 设置指定的字符集中的单字节和多字节字符。大多数欧洲和中东语言的语言环境仅支持单字节代码集,但 Unicode 语言环境的 UTF-8 代码集以及一些东亚语言环境的代码(比如中文 GB18030-2000 语言环境)支持多字节逻辑字符。
当启用 SQL_LOGICAL_CHAR 配置参数时,您可指导数据库服务器将内建的字符数据类型的声明中显式的或缺省的大小参数解释为指定可存储的逻辑字符的数目,而不是字节数。这些逻辑的字符语义也适用于其基础类型为内建的字符类型的 DISTINCT 类型,并适用于命名的或未命名的 ROW 数据类型的声明中的内建的字符类型的字段。然而,此特性不支持存储字符字符串的用户定义的数据类型(UDT)。要获取更多关于此特性的信息,请参阅 GBase 8s 管理员参考手册 对 SQL_LOGICAL_CHAR 配置参数的描述。
TEXT 和 CLOB 数据类型也支持单字节或多字节字符数据,但大多数操作字符串的内建的函数不支持 TEXT 也不支持 CLOB 数据。要获取更多信息,请参阅 大对象数据类型。
固定长度或可变长度字符数据类型
数据库服务器支持固定长度和可变长度字符数据的存储。固定长度列需要定义的字节数而不管实际的数据大小。CHAR 数据类型属于固定长度。例如,CHAR(25) 列对于所有值需要 25 字节的存储,因此字符串 "This is a text string" 使用 25 字节的存储。
可变长度列大小可为它的数据占据的字节数。NVARCHAR、VARCHAR、VARCHAR2数据类型是可变长度字符数据类型。例如,VARCHAR(25) 列为列值最多保留 25 字节的存储,但字符串 "This is a text string" 仅使用保留的 25 字节中的 21 字节。VARCHAR 数据类型最多可存储 32765 字节数据。要获取关于 IFX_PAD_VARCHAR 环境变量的信息,其设置控制数据库服务器发送和接收 VARCHAR 和 NVARCHAR 数据值的方式,请参阅 《GBase 8s SQL 指南:参考》。
访问有可变长度列的大型表
对于带有多于一百万行的表,如果查询执行轻扫描,而不是缓冲池扫描,则使用全表扫描或跳跃扫描访问方法的查询更加高效。然而,在包括 NVARCHAR、VARCHAR 或 LVARCHAR 数据类型列,或其基础类型为可变长度列的 DISTINCT 数据类型的列的表上,不支持轻扫描,除非将 BATCHEDREAD_TABLE 配置参数(或 BATCHEDREAD_TABLE 会话环境选项)设置为 1。
在正启用 BATCHEDREAD_TABLE 上轻扫描的依赖还适用于其模式或存储属性包括下列任何情况的表:
- 表压缩
- 任何可变长度数据类型的列
- 占据超过单个存储页的行。
要获取更多关于查询优化器何时选择执行轻扫描的执行路径来访问大型表的信息,请参阅您的 GBase 8s 性能指南。
LVARCHAR 数据类型
GBase 8s 的 LVARCHAR 类型可存储最多 32,739 字节的文本,但如果您在 LVARCHAR 数据类型声明中未指定 size,则缺省的长度为 2,048 字节。LVARCHAR 是内建的 opaque 数据类型。不像大多数内建的 opaque 类型那样,可在分布式查询或其他 DML 操作中的非本地的 GBase 8s 实例的数据库中访问 LVARCHAR 列值,且 LVARCHAR 可为访问本地数据库之外的数据的 UDR 的参数或返回值的数据类型。
GBase 8s 在对 opaque 数据类型的跨服务器 I/O 操作中使用 LVARCHAR 数据类型。在此上下文中,LVARCHAR 数据值的最大大小仅受操作系统的限制。
在包括 LVARCHAR 列的表上不支持查询执行期间的轻扫描,除非将 BATCHEDREAD_TABLE 配置参数(或 BATCHEDREAD_TABLE 会话环境选项)设置为 1。
NCHAR 和 NVARCHAR 数据类型
字符数据类型 NCHAR 和 NVARCHAR 可支持在某些数据库语言环境中次序的本地化顺序。在以 NLSCASE INSENSITIVE 属性创建的数据库中,NCHAR 和 NVARCHAR 列(以及强制转型到这些数据类型的字符串值)可支持区分大小写的查询。
字符数据类型 CHAR、LVARCHAR 和 VARCHAR 支持数据的代码集顺序次序。这是在 DB_LOCALE 环境变量指定的数据库语言环境的代码集内,在其中定义字符的顺序。缺省的(U.S. English)语言环境是为了排序 CHAR、LVARCHAR 和 VARCHAR 字符串值而使用次序的代码集顺序的语言环境的一个示例。
要获取关于 DB_LOCALE、CLIENT_LOCALE 和 SERVER_LOCALE 环境变量的设置(或缺省值)确定为次序使用哪一语言环境的方式的信息,请参阅 GBase 8s GLS 用户指南。
然而,有些语言环境指定不同于代码集顺序的一个次序的顺序。要支持任何次序的特定于语言环境的顺序,您可使用 NCHAR 和 NVARCHAR 数据类型。NCHAR 数据类型是支持本地化次序的固定长度字符数据类型。NVARCHAR 数据类型是可存储最多32,765 字节的文本数据的可变长度字符数据类型,且支持本地化次序。在代码集未定义次序的本地化顺序的语言环境中,比如缺省的语言环境,在 CHAR 与 NCHAR 数据类型之间没有差异,在 VARCHAR 与 NVARCHAR 数据类型之间也没有差异,除了在区分大小写的数据库中之外。
在以 NLSCASE INSENSITIVE 属性创建的数据库中,存储这些数据类型的值恰如将它们加载到数据库内,但在数据处理操作中,包括 NVARCHAR 和 NCHAR 字符串的比较和对照,数据库服务器不理会字母大小写,不考虑大小写对数据值排序。例如,在有次序的列表中,NCHAR 或 NVARCHAR 字符串 "PH" 可能在 "pH" 或 "ph" 之前也可能在之后,在其中将这三个字符串视作重复,依赖于检索这些值的顺序。要获取更多关于在区分大小写的数据库中 NCHAR 或 NVARCHAR 数据处理的信息,请参阅 指定 NLSCASE 区分大小写、在 NLSCASE INSENSITIVE 数据库中重复的行 和 在区分大小写的数据库中的 NCHAR 和 NVARCHAR 表达式。
对于 NCHAR 或 NVARCHAR 值,SQL 的 SET COLLATION 语句可通过指定另一语言环境来覆盖当前会话的本地化的次序顺序。根据当创建索引时生效了的本地化的次序顺序,对 NCHAR 或 NVARCHAR 列上的索引值排序,如果其不同于当前的次序顺序的话。要获取更多关于 SET COLLATION 语句可影响索引、约束、游标、准备好的对象和 SPL 例程的排序行为的方式的信息,请参阅 由数据库对象执行的对照。
如果您在声明 VARCHAR 或 NVARCHAR 列的 CREATE TABLE 或 ALTER TABLE 语句中未指定参数,则新列的缺省的 max 大小为 1 字节,且 reserve 大小为零。
在区分大小写的数据库中的 NCHAR 和 NVARCHAR 表达式
在以 NLSCASE INSENSITIVE 属性创建的数据库中,数据库服务器在 NCHAR 和 NVARCHAR 表达式中相同字母的大写变量与小写变量之间不做区分,不论是否为语言环境定义了本地化的次序顺序。
如果在关系运算符的运算对象之中,或在字符串函数的参数之中,字母大小写变量是唯一的区别,则与在区分大小写的数据库中同一表达式上的同一操作相对比,对字母大小的这种忽略可更改 NCHAR 或 NVARCHAR 表达式上区分大小写的操作返回的值。
例如,假设对于缺省的语言环境中的数据库的表中的记录,NCHAR 列 lname 存储值 McDavid。
在区分大小写的数据库中,布尔表达式 lname > "MCDAVID" 求值为真,因为数据库服务器使用缺省的语言环境的代码集顺序来比较这两个运算对象。虽然两个字符串都是以大写字母 M 开头,但该列值中的下一字符是小写字母 c(ASCII 99 代码点),但括起来的字符串中的下一字符是大写字母 C( ASCII 67 代码点)。由于 99 大于 67,因此,在区分大小写的数据库中,列值大于括起来的字符串。
然而,在不区分大小写的数据库中,同一表达式 lname > "MCDAVID" 求值为假,因为在数据库服务器比较这两个运算对象时,它不管字母大小写变量。两个字符串都有同样序列的同样字符,因此按照这些标准,列值与括起来的字符串是一样的。
在包括 NCHAR 或 NVARCHAR 运算对象的比较过程中,由于有 NLSCASE INSENSITIVE 属性的数据库不管字母的大小写, 因此,在不区分大小写的数据库中,在 NCHAR 或 NVARCHAR 字符串上的操作产生的结果可不同于在区分大小写的数据库中的结果。 区分大小写的数据库在其中的上下文与不区分大小写的数据库在其中的上下文可能使用相同的 SQL 操作来从相同的数据集返回不同的结果,包括这些:
- 排序和次序
- 外键和主键依赖
- 强制唯一的约束
- 集群化的索引
- 访问方式优化器伪指令
- 带有 WHERE 谓词的查询
- 在 projection 子句中带有 UNIQUE 或 DISTINCT 的查询
- 带有 ORDER BY 子句的查询
- 带有 GROUP BY 子句的查询
- 级联的 DELETE 操作
- 表或索引存储分发 BY EXPRESSION
- 表或索引存储分发 BY LIST
- 来自 UPDATE STATISTICS 操作的数据分发。
数值数据类型
数值数据类型使得数据库服务器能够在列中存储诸如整数和实数这样的数。
数值数据类型

数目的值被存储为 exact numeric 数据类型或为 approximate numeric 数据类型。
精确的数值数据类型
精确的数值数据类型存储指定的精度和范围的数值。
精确的数值数据类型
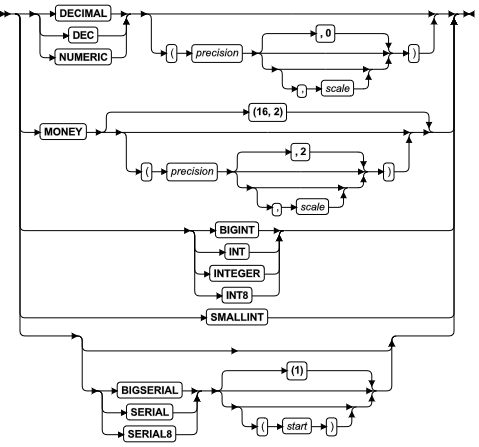
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| precision | 有效数字 | 必须为整数;1 ≤ precision ≤ 32 | 精确数值 |
| scale | 小数部分中的数字 | 必须为整数;1 ≤ scale ≤ precision | 精确数值 |
| start | 整数起始值 | 对于 SERIAL:1 ≤ start ≤ 2,147,483,64; 对于 BIGSERIAL 和 SERIAL8: 1 ≤ start ≤ 9,223,372,036,854,775,807 | 精确数值 |
数据类型的精度是该数据类型存储的数字的数目。范围是小数点分隔符右边的数字的数目。
下表总结可用的精确的数值数据类型。
| 数据类型 | 描述 |
|---|---|
| DEC(p,s) | DECIMAL(p,s) 的同义词 |
| DECIMAL(p,s) | 存储实数的定点小数值,在小数部分中最多 20 位有效数字,或在小数点的左边最多 32 位有效数字。 |
| INT | INTEGER 的同义词 |
| INTEGER | 存储 4 字节整数值。这些值的取值范围可从 -(2^31-1) 至 2^31-1(从 -2,147,483,647 至 2,147,483,647)。 |
| BIGINT 和 INT8 | 存储 8 字节整数值。这些值的取值范围可从 -(2^63-1) 至 2^63-1(从 -9,223,372,036,854,775,807 至 9,223,372,036,854,775,807)。 BIGINT 有比 INT8 更大的存储和处理优势。 |
| MONEY(p,s) | 存储定点货币值。这些值与定点 DECIMAL(p,s) 值有相同的内部数据格式。 |
| NUMERIC(p,s) | DECIMAL(p,s) 的符合 ANSI 的同义词 |
| SERIAL | 存储数据库服务器生成的 4 字节正整数。取值范围从 1 至 2^31-1(即,从 1 至 2,147,483,647)。 |
| BIGSERIAL 和 SERIAL8 | 存储数据库服务器生成的 8 字节正整数。取值范围从 1 至 2^63-1(即,从 1 至 9,223,372,036,854,775,807)。 BIGSERIAL 比 SERIAL8 有更大的存储和处理优势。 |
| SMALLINT | 存储 2 字节的整数值。这些值的取值范围从 -(2^15-1) 至 2^15-1(即,从 -32,767 至 32,767)。 |
DECIMAL(p,s) 数据类型
参数 p 指定精度(数字的总数目),第二个参数(s)指定范围(小数部分中的数字的数目)。如果您仅提供一个参数,则符合 ANSI 的数据库将它解释为定长数值的精度,且缺省的范围为 0。如果您未指定参数,且该数据库符合 ANSI,则在缺省情况下精度为 16 且范围为 0。
如果数据库不符合 ANSI,且您指定的参数少于 2 个,则您声明浮点 DECIMAL,这不是精确的数值数据类型。(另请参阅 近似的数值数据类型 部分。)
DECIMAL(p, s) 值的内部存储方式是,第一个字节代表符号位,以及一个 excess-65 格式的 7 位指数。其他的字节表示尾数作为 base-100 数字。这表示如果 s 是奇数,则 DECIMAL(32, s) 数据类型仅在小数点的右边存储 s-1 个小数数字。
Serial 数据类型
您可声明 SERIAL、BIGSERIAL 或 SERIAL8 数据类型的列。如果用户定义的例程需要变量、参数或返回的数据类型的全数值值,则请指定 INT、BIGINT 或 INT8 作为数据类型,而不是 SERIAL、BIGSERIAL 或 SERIAL8。这些数据类型是整数数据类型,其主要的不同之处在于它们的名称、它们的范围和它们的存储需求。序列数据类型的列不可存储小于 1 的值。表可只有一个 SERIAL 列且只有一个 BIGSERIAL 或 SERIAL8 列。因为通过数据库服务器指定该序列值,因此您不可使用 UPDATE 语句来更改数据库中现有的序列值。
要将显式的值插入到 SERIAL、BIGSERIAL 或 SERIAL8 列内,请指定任何大于零的整数。要获取生成整数值的替代方法的详细信息,请参阅 CREATE SEQUENCE 语句。
仅当您在列上设置唯一索引,SERIAL、BIGSERIAL 或 SERIAL8 列才是唯一的。(该索引还可为主键或唯一约束的形式。)带有唯一索引,序列数据类型列中的值保证是唯一的,但随后的值没有必要是连续的。
近似的数值数据类型
近似的数值数据类型近似地表示数值值。
近似的数值数据类型
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| float_precision | 忽略 float_precision,但这符合 ANSI/ISO。 | 必须为正整数。指定的值没有作用。 | 精确数值 |
| precision | 有效数字。缺省值为 16。 | 整数;1 ≤ precision ≤ 32 | 精确数值 |
对于在算术操作期间容许一定程度舍入的很大和很小的数值,请使用近似的数值数据类型。
下表总结内建的近似的数值数据类型。
| 数据类型 | 描述 |
|---|---|
| DEC(p) | DECIMAL(p) 的同义词 |
| DECIMAL(p) | 存储从 1.0E-130 至 9.99E+126 的近似的范围内的浮点小数值 参数 p 指定精度。如果未指定精度,则缺省值为 16。仅在不符合 ANSI 的数据库中才可用浮点数据类型作为近似的数值类型。 在符合 ANSI 的数据库中,实现 DECIMAL(p) 作为定点 DECIMAL;请参阅 精确的数值数据类型。 |
| DOUBLE PRECISION | FLOAT 的 符合 ANSI 的同义词。当您在数据类型声明中使用此同义词时,float_precision 术语无效。 |
| FLOAT | 存储最多带有 16 位有效数字的双精度浮点数值。为了符合 SQL 的 ANSI/ISO 标准,在数据类型声明中接受 float-precision 参数,但此参数对数据库服务器存储的值的实际精度不起作用。 |
| NUMERIC(p) | DECIMAL(p) 的符合 ANSI 的同义词。在符合 ANSI 的数据库中,这是作为精确的数值类型来实现的,带有指定的精度和范围零,而不是近似的数值(浮点)数据类型。 |
| REAL | SMALLFLOAT 的符合 ANSI 的同义词 |
| SMALLFLOAT | 存储近似地带有 8 位有效数字的单精度浮点数值 |
GBase 8s 数据库服务器的内建的数值数据类型支持实数。它们不直接地存储虚数或复数。
在 GBase 8s 中,您必须为支持可有虚数部分的值的应用创建用户定义的数据类型。
外部 UDR 的不超过九个参数可为 UDR 声明作为 Java™ 语言的 BigDecimal 数据类型的 SQL 的 DECIMAL 数据类型。
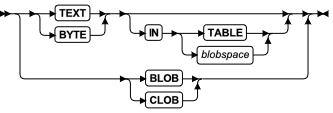
大对象数据类型
大对象数据类型可独立于列存储极大的列值,诸如图片和文档。
大对象数据类型
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| blobspace | 现有的 blobspace 的名称 | 必须存在 | 标识符 |
大对象数据类型可划分为两类:
- 简单大对象:TEXT 和 BYTE
- 智能大对象:CLOB 和 BLOB
简单大对象数据类型
简单大对象数据类型在 blobspace 中存储文本或二进制数据。
这些是简单大对象数据类型:
TEXT 存储最大 2^31^ 字节的文本数据
BYTE 存储最大 231 字节的任何数字化数据
在需要 TEXT 的地方,请不要提供 BYTE 值。没有内建的强制转换支持由 BYTE 到 TEXT 的数据类型转换。
要获取更多关于简单大对象数据类型的信息,请参阅 《GBase 8s SQL 指南:参考》。
要获取关于如何创建 blobspace 的信息,请参阅 GBase 8s 管理员指南。
存储 BYTE 和 TEXT 数据
简单大对象数据类型可在 blobspace 或在表中存储文本或二进制数据。数据库服务器可完整地访问 BYTE 或 TEXT 值。当您指定 BYTE 或 TEXT 数据类型时,您可指定存储它的位置。您可以表存储数据,或在单独的 blobspace 中存储数据。
如果您正在创建有 BYTE 或 TEXT 字段的命名的 ROW 数据类型,则您不可使用 IN 子句来指定单独的存储空间。
下列示例展示如何指定 blobspace 和 dbspace。用户创建 resume 表。数据值存储在 employ dbspace 中。以表存储 vita 列中的数据,但与 photo 列相关联的数据存储在名为 photo_space 的 blobspace 中。
CREATE TABLE resume
(
fname CHAR(15),
lname CHAR(15),
phone CHAR(18),
recd_date DATETIME YEAR TO HOUR,
contact_date DATETIME YEAR TO HOUR,
comments VARCHAR(250, 100),
vita TEXT IN TABLE,
photo BYTE IN photo_space
)
IN employ;
智能大对象数据类型
智能大对象数据类型在 sbspace 中存储文本或二进制数据。
数据库服务器可提供对智能大对象值的随机访问。也就是说,它可访问智能大对象值的任何部分。这些数据类型是可恢复的。下列列表总结 GBase 8s 支持的智能大对象数据类型。
BLOB 存储最多 4 TB(4*240 字节)的二进制数据
CLOB 存储最多 4 TB(4*240 字节)的文本数据
在单个 sbspace 中存储智能大对象。SBSPACENAME 配置参数指定在其中创建智能大对象的系统缺省的 sbspace,除非您指定另一存储区域。要获取关于 CREATE TABLE 语句如何可为 BLOB 或 CLOB 列指定非缺省的存储位置和非缺省的存储特征的信息,请参阅 PUT 子句 的描述。
这两个都是内建的 opaque 数据类型。像大多数 opaque 类型那样,不可通过分布式查询或通过其他 DML 操作在非本地数据库服务器的数据库中访问它们,也不可通过 UDR 从另一数据库服务器的数据库返回它们。然而,要获取关于在本地服务器的其他数据库中访问 BLOB 或 CLOB 值的信息,请参阅 BOOLEAN 和其他内建的 Opaque 数据类型。
智能大对象数据类型是不能并行的。Dynamic Serve 的 PDQ 特性对加载或卸载 BLOB 或 CLOB 值的操作不起作用,对在查询或在其他 DML 操作中处理它们的操作也不起作用。
要获取更多关于智能大对象数据类型的信息,请参阅 《GBase 8s SQL 指南:参考》。
要获取关于如何创建 sbspace 的信息,请参阅您的 GBase 8s 管理员指南。
要获取关于您可用于导入、导出或复制智能大对象的内建的函数的信息,请参阅 智能大对象函数 和 GBase 8s SQL 教程指南。
时间数据类型
时间数据类型存储日历日期、时间点以及时间间隔。
时间数据类型
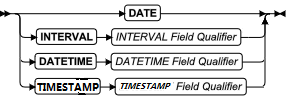
下表总结内建的时间数据类型。
数据类型 描述
DATE 存储日期值作为 Julian 日期,取值范围从公元 1 年 1 月 1 日直至 公元9999 年 12 月 31 日。
DATETIME 存储时间点日期(年、月、日)和每日时间(小时、分、秒和几分之一秒),取值范围从 1 年至 9999 年。也支持这些时间单位的相邻子集。
INTERVAL 存储时间范围,以年数和/或月数的形式,或以更小的时间单位的形式(天数、小时数、分钟数、秒数 和/或几分之一秒),最大的时间单位达到 9 位数值精度,如果这不是 FRACTION 的话。还支持这些时间单位的相邻子集。
TIMESTAMP 存储时间点日期(年、月、日)和每日时间(小时、分、秒和几分之一秒)。
要了解可指定内建的时间数据类型的显示和数据条目格式的 GBase 8s 环境变量之中的优先顺序,请参阅主题 DATE 和 DATETIME 格式规范的优先顺序。
DATETIME 字段限定符
使用 DATETIME Field Qualifier 来指定 DATETIME 列或值中的最大和最小时间单位。无论何时在语法图中查看对 DATETIME Field Qualifier 的引用时,请使用此段。
语法
DATETIME Field Qualifier
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| scale | 几分之一秒。缺省值为 3。 | 整数(1 ≤ scale ≤ 5) | 精确数值 |
用法
此段指定 DATETIME 数据类型的精度和小数位。
作为第一个关键字,指定 DATETIME 列将存储的最大时间单位。在关键字 TO 之后,指定最小的单位作为最后一个关键字。它们可以是同一个关键字。如果不同,那么限定符暗示在第一个和最后一个之间的中间时间单位通过 DATETIME 数据类型记录。
这些关键字可为 DATETIME 列指定下列时间单位。
时间的单位 描述
YEAR 指定年份,取值范围从公元 1 年至 9999 年
MONTH 指定月份,范围为从 1(一月)值 12(十二月)
DAY 指定日期,范围为从 1 至 28、29、30 或 31(根据特定月份)
HOUR 指定小时,范围为从 0(午夜)至 23
MINUTE 指定分钟,范围为从 0 至 59
SECOND 指定秒,范围为从 0 至 59
FRACTION 指定几分之一秒,最多五位小数
缺省的范围为三位数字(千分之一秒)。
与 INTERVAL 限定符不同,DATETIME 限定符不可指定非缺省的精度(当 FRACTION 是该限定符中最小的单位时,FRACTION 除外)。DATETIME 限定符的一些示例如下:
YEAR TO MINUTE MONTH TO MONTH
DAY TO FRACTION(4) MONTH TO DAY
在某些平台上,系统时钟不可支持大于 FRACTION(3) 的精度。
如果第一个关键字表示的时间单位比最后的一个关键字所表示的小,或使用了关键字的复数形式(如 MINUTES),就会产生错误。
对在限定符中不包含 YEAR 的 DATETIME 的值的运算,使用系统时钟日历值来提供所有额外的精度。如果限定符的第一个术语是 DAY,且当前月份少于 31 天,则可能产生意外的结果。
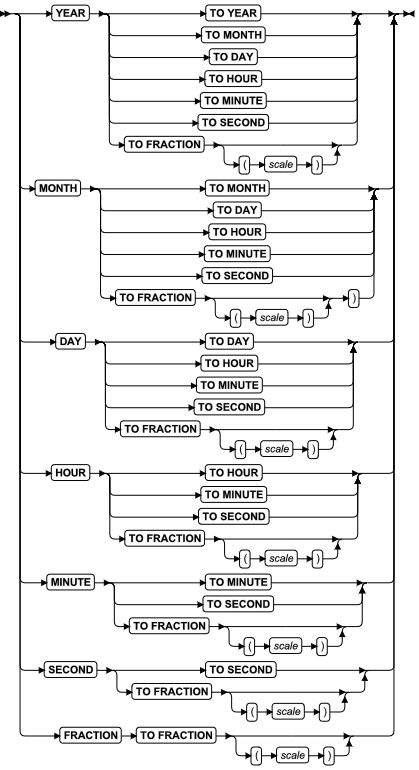
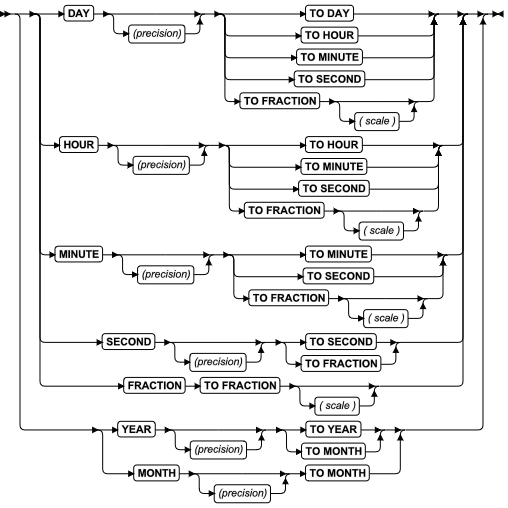
INTERVAL 字段限定符
INTERVAL 字段限定符以时间单位指定 INTERVAL 值的精度。每当您在语法图中看到对 INTERVAL 字段的引用时,请使用 INTERVAL Field Qualifier 段。
语法
INTERVAL 字段限定符
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| scale | FRACTION 字段中数字的个数。缺省值为 3。 | 取值范围必须为从 1 至 5 | 精确数值 |
| precision | INTERVAL 包含的最大时间单位中数字的个数。对于 YEAR,缺省值为 4。对于除 FRACTION 外的其他所有时间单位,缺省值为 2。 | 取值范围必须为从 1 至 9 | 精确数值 |
用法
此段指定 INTERVAL 数据类型的精度和小数位。
指定 largest 时间单位的关键字必须是第一个关键字,而指定 smallest 时间单位的关键字必须跟在 TO 关键字之后。它们可以是同一个关键字。此段与 DATETIME 字段限定符 的语法类似,但有这些例外:
- 如果最大时间单位关键字是 YEAR 或 MONTH,那么最小时间单位关键字不能指定小于 MONTH 的时间单位。
- 可在第一个时间单位后面指定最大为 9 位数字的precision,除非 FRACTION 是第一个时间单位(在此情况下在第一个 FRACTION 关键字之后,没有任何 precision 是有效的,但可在第二个 FRACTION 关键字之后指定多达 5 位数字的 scale)。
由于 year 和 month 不是定长的时间单位,数据库服务器将在限定符中包含 YEAR 或 MONTH 关键字的 INTERVAL 数据类型与限定符小于 MONTH 的时间单位的 INTERVAL 数据类型不兼容。数据库服务器不支持在这两种 INTERVAL 数据类型之间的隐式强制转型。
以下两个示例显示 INTERVAL 数据类型的 YEAR TO MONTH 限定符。第一个示例可以允许最大为 999 年 11 个月的时间间隔,因为它给出了 3 作为 YEAR 字段的精度。第二个示例对 YEAR 字段使用缺省精度,因此可允许最大为 9999 年和 11 个月的时间间隔。
YEAR (3) TO MONTH
YEAR TO MONTH
当需要一个值只指定一种时间单位时,第一个和最后一个限定符是相同的。例如,整年之间的时间间隔可以限定为 YEAR TO YEAR 或 YEAR (5) TO YEAR。用来指定最大 9999 年的时间间隔。
下列示例显示 INTERVAL 字段限定符的几种格式:
YEAR(5) TO MONTH
DAY (5) TO FRACTION(2)
DAY TO DAY
FRACTION TO FRACTION (4)
要获取关于如何指定 INTERVAL 字段限定符以及如何在算术和关系运算中使用 INTERVAL 数据的信息,请参阅相关的参考,INTERVAL 数据类型。
TIMESTAMP 字段限定符
此段指定 TIMESTAMP 数据类型的精度和范围。
TIMESTAMP Field Qualifier 与 DATETIME Field Qualifier 的功能类似。唯一不同的是,其中指定几分之一秒的 FRACTION 时间单位值可以是 1 到 6 范围内的数字,缺省值为 0。
TIMESTAMP WITH TIME ZONE字段限定符
描述一个带时区的 TIMESTAMP 值,其定义是在 TIMESTAMP 类型的后面加上时区信息。时区部分的实质是 INTERVAL HOUR TO MINUTE 类型,取值范围:-12:59 与+14:00 之间。该类型数据输入输出的格式由环境变量NLS_TIMESTAMP_TZ_FORMAT决定,当前会话所在时区由环境变量TIME_ZONE决定。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| fractional_seconds_precision | 可选项,秒的小数部分 | 取值范围是0-5,默认5。 | 数值 |
例如:该类型在创建表、修改表、创建视图及数据的增、删、改、查的场景中应用。
> create table t1(c1 TIMESTAMP WITH TIME ZONE); --表
Table created.
> create view v1 as select c1 from t1; --视图
View created.
> alter table t1 add c2 int;
Table altered.
> alter table t1 drop c1;
Table altered.
> alter table t1 add c1 timestamp with time zone ;
Table altered.
> alter table t1 modify(c1 timestamp); --修改列
Table altered.
> alter session set nls_timestamp_tz_format='yyyy-mm-dd hh24:mi:ss tzh:tzm';
Session altered.
> insert into t1 values('2023-02-10 23\:25\:33 +08:00');--增
1 row created.
> insert into t1 values(timestamp '2023-02-10 23\:25\:33 +08:00');
1 row(s) inserted.
> delete from t1 where c1='2023-02-10 23\:25\:33 +08:00';--删
1 row(s) deleted.
> insert into t1 values(timestamp '2023-02-10 23\:25\:33 +08:00');
1 row(s) inserted.
> update t1 set c1=timestamp'2023-02-10 23\:25\:33 +05:00' where c1=timestamp '2023-02-10 23\:25\:33 +08:00';--改
1 row(s) updated.
> select c1 from t1;
C1 2023-02-10 23\:25\:33 +05:00
1 row(s) retrieved.
说明及限制:
- ORACLE模式下运行。
- 在创建表的时候可定义该类型。
- 支持在该列上进行数据的增删改查。
- 支持在PLSQL、存储过程、函数、包中使用。
- 支持导出/导入(dbimport/dbexport、dbload、load/unload、onload/onunload、dbschema、ontape/onbar)。
- 支持在集群环境(HDR、SDS、ER)中应用。
- 支持开发接口JDBC、ODBC、ESQL/C。
- 支持客户端工具dbaccess。
- 该类型创建索引无效。
- 不支持对改类型进行实时数据抓取(cdc)。
- 不支持对该类型的不同时区数据进行order by排序。
- 在PLSQL、存储过程、函数、包的record类型中不支持声明timestamp with time zone类型。如:type typename is record(c1 timestamp with timezone)
- 在PLSQL、存储过程、函数、包中使用%ROWTYPE,%TYPE时,不支持使用timestamp with time zone类型。
- dbimport\dbexport 导人导出存储过程时,不支持存储过程中有timestamp with time zone 类型的输入输出(in/out)参数。
- timestamp with time zone类型不支持进行minus集合运算。
- timestamp转化为timestamp with time zone类型时结果集有误,没有转为当前时区。
- timestamp with time zone类型不支持在object、嵌套表、变长数组中使用。
- 在gbase模式下运行会引发预期外问题,建议不要使用。
时区类型运算规则
时区类型可以与时间类型、INTERVAL类型、数值类型、时区类型本身做运算,运算规则如下:
时区数据与时间类型运算时
时区数据与时间类型(DATE、TIMESTAMP)数据做运算或者比较时,需要对类型先进行升格,时区数据会按照函数补充规则或者格式化字符串补充规则进行补全。时间类型数据按照下述规则补全。两个类型运算时只支持减法,返回INTERVAL类型数据。
- 缺少年,补充当前年份。
- 缺少月,补充当前月。
- 缺少日,补充01日。
- 缺少小时,补充00时。
- 缺少分钟,补充00分钟。
- 缺少秒钟,补充00.00000秒。
- 缺失时区,补充00:00。
例如:计算2023-06-01 12:12:12 +8:0与2023-05-31之间的时间间隔。
> select timestamp '2023-06-01 12\:12\:12 +8:00' - date '2023-05-31' from dual;
(CONSTANT)
1 12:12:12.00000
1 row(s) retrieved.
用法及限制:
- ORACLE模式下运行。
- 在DATE减TIMESTAMP WITH TIME ZONE时会返回INT类型的数据。
时区数据与INTERVAL类型\数值类型运算时
时区类型与数值运算的本质上是时区类型与时间间隔类型(INTERVAL day)做运算。与时间间隔类型做运算时返回时区类型。支持加减运算。
例如:计算2023-06-01 12:12:12 +8:0加2天之后的结果。
> select timestamp '2023-06-01 12\:12\:12 +8:0' +2 from dual;
(EXPRESSION)
2023-06-03 12\:12\:12.00000 +08:00
1 row(s) retrieved.
> select timestamp '2023-06-01 12\:12\:12 +8:0' + interval '2' day from dual;
(CONSTANT)
2023-06-03 12\:12\:12.00000 +08:00
1 row(s) retrieved.
说明及限制:
- ORACLE模式下运行。
- 当数值是小数时表示小数天。可以通过乘24转换为小时。乘24*60转换为分钟。
时区数据与时区类型
同时区数据会直接运算或者比较,不同时区数据会转成UTC 0时区,再进行比较或运算。运算时只支持减法。获取两个时间之间的间隔。
例如,计算2023-10-2212:12:32+8:00与2023-10-2112:12:32+6:00的时间间隔。
SQL> select timestamp '2023-10-22 12\:12\:32 +8:00' -timestamp '2023-10-21 12\:12\:32 +6:00' from dual;
(CONSTANT)
0.91666666666667
1 row(s) retrieved.
说明及限制:
- ORACLE模式下运行。
- 返回类型为DECIMAL,结果为天。
XMLTYPE数据类型
GBase 8s支持创建xmltype数据类型用于操作xml结构数据。建表时支持创建xmltype类型,插入数据为xml格式。
BOOLEAN 和其他内建的 Opaque 数据类型
GBase 8s 还支持 BOOLEAN 数据类型,这是可存储 true、false 或 NULL 值的内建的 opaque 数据类型。符号 t 表示字面的 BOOLEAN true 值,f 表示字面的 BOOLEAN false 值。
BOOLEAN 是 LVARCHAR 可通过跨服务器分布式查询或通过其他跨服务器分布式 DML 操作返回的唯一内建的 opaque 数据类型。不可通过分布式查询(在远程数据库上通过 INSERT、DELETE 或 UPDATE 操作不修改)检索其他内建的 opaque 数据类型的列值,除非该 DML 操作访问的所有表都在本地的 GBase 8s 实例的数据库中。
类似地,在其他 GBase 8s 实例的数据库上执行分布式操作的 UDR 中,BOOLEAN 和 LVARCHAR 是作为参数或作为返回的该 UDR 的数据类型唯一有效的内建的 opaque 类型,必须在所有参与的数据库中定义该类型。
除了 BOOLEAN 类型之外, GBase 8s 的其他内建的 opaque 数据类型包括 BLOB、CLOB、LVARCHAR、IFX_LO_SPEC、IFX_LO_STAT、INDEXKEYARRAY、POINTER、RTNPARAMTYPES、SELFUNCARGS、STAT、CLIENTBINVAL 和 XID 数据类型。在本地数据库中以及在同一服务器实例的跨数据库分布式操作中,支持这十二个内建的 opaque 类型。在本章的随后部分中讨论这些类型中的前三个。
GBase 8s 还支持内建的 opaque 数据类型 LOLIST、IMPEX、IMPEXBIN 和 SENDRECV。然而,不可通过 DML 操作在远程数据库中访问这些类型,也不通过 UDR 从远程数据库返回,因为这些数据类型没有所需要的支持函数。要获取更多的关于 GBase 8s 在分布式事务中支持的数据类型的信息,请参阅 分布式查询中的数据类型。
IDSSECURITYLABEL 数据类型
GBase 8s 的 IDSSECURITYLABEL 类型在受安全策略保护的表中存储安全标签。仅持有 DBSECADM 角色的用户可创建、修改或删除此数据类型的列。这是内建的 DISTINCT OF VARCHAR(128) 数据类型,但未将它分类作为字符数据类型,因为将它的使用限定在基于标签的访问控制。有安全策略的表可有多个 IDSSECURITYLABEL 列,未与安全策略相关联的表可没有这样的列。
DBSECADM 可使用 GRANT 语句来将特定的安全标签与用户相关联,且 REVOKE 语句可取消用户持有的安全标签。对于给定的安全策略,用户可有多个既支持读访问也支持写访问的标签,或只有一个写访问标签和只有一个读访问标签。对于受安全策略保护,但已将自主访问权限授予了用户的数据,数据库服务器通过将数据的安全标签与用户的安全标签相对比来确定特定的用户可否访问该数据,同时还考虑该用户持有的安全策略规则是否存在任何豁免。
要获取指定 IDSSECURITYLABEL 值的方式的信息,请参阅 安全标签支持函数。
要获取安全策略、安全组件、安全标签以及基于标签的访问控制(LBAC)的其他概念的讨论,请参阅 GBase 8s 安全指南。
二进制数据类型
RAW 数据类型
RAW数据类型用来存储变长二进制数据。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| size | 定义类型大小 | 1到32739的整数 | 精确数值 |
该类型支持创建表(包括普通表及分区表)时被定义。如:
create table raw_t(
c1 int,
c2 varchar(20),
c3 raw(200)
);
Table created.
Elapsed time: 0.001 sec
> insert into raw_t values(1,'1','abcd');
1 row(s) inserted.
支持使用转换函数rawtohex和hextoraw对该类型进行操作,如:
> select rawtohex(c3) rawtohex ,hextoraw(c3) hextoraw from raw_t;
rawtohex ABCD
hextoraw ABCD
1 row(s) retrieved.
说明及限制:
- RAW类型字段中存储字符数据时,必须是一个十六进制数字( 0-9,A-F)。
- RAW类型支持在PLSQL、普通表及分区表等场景中应用。
- RAW类型不支持使用ALTER语句修改。
- RAW类型不支持字符串函数。
- RAW类型字段不支持创建索引。
用户定义的数据类型
用户定义的数据类型是用户为数据库服务器定义的一种数据类型。 GBase 8s 支持两类用户定义的数据类型,即 distinct 数据类型和 opaque 数据类型。这是用户定义的数据类型的声明语法:
用户定义的数据类型

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| distinct_type | 带有与现有的数据类型有相同结构的 distinct 数据类型 | 在数据库中的数据类型名称之中必须是唯一的 | 标识符 |
| opaque_type | opaque 数据类型的名称 | 在数据库中的数据类型名称之中必须是唯一的 | 标识符 |
在本文档中,用户定义的数据类型通常缩写为 UDT。
distinct 数据类型
DISTINCT 数据类型是基于下列数据类型的用户定义的数据类型:
- 内建的类型(包括内建的 opaque 类型)
- 用户定义的 opaque 类型
- 命名的 ROW 类型
- 现有的 DISTINCT 类型。
DISTINCT 类型的基本类型不可为任何下列数据类型:
- 未命名的 ROW 类型
- LIST、MULTISET、SET 或通用的 COLLECTION 类型。
DISTINCT 类型继承存储中它的基本类型的长度和对齐方式。 GBase 8s 自动地在 DISTINCT 类型与它的基本类型之间创建显式的强制转型。要创建 DISTINCT 类型,您必须使用 CREATE DISTINCT TYPE 语句(要获取更多信息,请参阅 CREATE DISTINCT TYPE 语句。)
分布式操作中的 DISTINCT 类型
不可通过分布式查询从同一 GBase 8s 实例的另一数据库检索 DISTINCT 列值(也不可通过 INSERT、DELETE、MERGE 或 UPDATE 跨数据库分布式操作来修改),除非所有下列条件都为真:
- 在下列基本类型之一上定义该 DISTINCT 类型:
- 非 opaque 内建的数据类型
- BOOLEAN 或 LVARCHAR 数据类型
- 在 BOOLEAN 上、在 LVARCHAR 上,或在非 opaque 内建的数据类型上创建的 DISTINCT 类型。
(此条件也递归地适用于 DISTINCT 类型的 DISTINCT 类型,在此,最终的基础类型为 BOOLEAN,或 LVARCHAR,或非 opaque 内建的数据类型。)
- 显式地强制转型为 BOOLEAN、LVARCHAR 或非 opaque 内建的数据类型的 DISTINCT 类型
- DISTINCT 类型,在所有参与的数据库中都正好以同一种方式定义它的层级和它的向内建的类型的显式的强制转型。
对于在分布式操作中的 DISTINCT 数据类型,数据类型层级必须有这些形式中的一种,不随所在的参与的数据库的不同而变化:
上图展示任何 DISTINCT 数据类型的基础类型的一般性逻辑层级。然而,如在上图中那样递归地使用 DISTINCT OF 关键字是无效的 SQL 语法。CREATE DISTINCT TYPE 语句必须为新的 DISTINCT 类型正好指定一个基础类型。要创建 DISTINCT 数据类型的层级,您必须为层级中的每个 DISTINCT 类型发出一个单独的 CREATE DISTINCT TYPE 语句。要了解定义新的 DISTINCT 数据类型的 SQL 语法,请参阅主题 CREATE DISTINCT TYPE 语句。
在受保护的表的行中存储安全标签的 IDSSECURITYLABEL 数据类型是满足此要求的内建的 DISTINCT 类型,因为它的基础类型是内建的 VARCHAR(128) 数据类型。
用户定义的例程可从同一 GBase 8s 实例的另一数据库将 DISTINCT 数据类型返回给本地数据库,仅当所有上述条件都为真,且在所有参与的数据库中定义 UDR 的话。
适用于同一 GBase 8s 实例的跨数据库的分布式操作中的 DISTINCT 数据类型的那些规则,也适用于在不同的 GBase 8s 实例的数据库上的跨服务器分布式操作中的 DISTINCT 数据类型。
要获取关于 GBase 8s 在分布式操作中支持的数据类型的附加信息,请参阅 分布式查询中的数据类型。
Opaque 数据类型
opaque 数据类型是可以与内建的数据类型相同的方式使用的用户定义的数据类型。要创建 opaque 类型,您必须使用 CREATE OPAQUE TYPE 语句。由于 opaque 类型是被封装的,因此您要创建支持函数来访问 opaque 类型的单个组件。该类型的内部存储细节是隐藏的或不透明的。
要获取更多关于如何创建 opaque 数据类型以及它的支持函数的信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
对象类型
详细内容请查看《GBase 8s V8.8 PLSQL 手册》。
嵌套表类型
详细内容请查看《GBase 8s V8.8 PLSQL 手册》。
变长数组类型
详细内容请查看《GBase 8s V8.8 PLSQL 手册》。
复合的数据类型
复合的数据类型是您从内建的类型、opaque 类型、distinct 类型或其他复合的类型创建的 ROW 类型或 COLLECTION 类型。
复合的数据类型

单个复合的数据类型可包括多个组件。当您创建符合的类型时,您定义该复合的类型的组件。然而,不像 opaque 类型那样,不封装复合的类型。您可使用 SQL 来访问复合的数据类型的个别的组件。复合的数据类型的个别的组件称为元素。
GBase 8s 支持下列类别的复合的数据类型:
- ROW 数据类型:命名的 ROW 类型和未命名的 ROW 类型
- COLLECTION 数据类型:SET、MULTISET 和 LIST
COLLECTION 数据类型的元素必须都是同一数据类型。您可使用 SPL 数据类型声明中的关键字 COLLECTION 来指定 untyped 集合变量。在 COLLECTION 数据类型的元素中不支持 NULL 值。
ROW 数据类型的元素可以是不同的数据类型,但对于给定的 ROW 数据类型,从第一个到最后一个元素,数据类型的模式不可变化。在 ROW 数据类型的元素中支持 NULL 值,除非您在数据类型声明中或在约束中另行指定。
ROW 数据类型
这是将一列定义为命名的或未命名的 ROW 类型的语法。
Row 数据类型

未命名 Row 类型

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| data_type | field 的数据类型 | 除了 BYTE 或 TEXT 之外的任何数据类型 | 数据类型 |
| field | row_type 内字段的名称 | 在同一 ROW 类型的字段之中必须是唯一的 | 标识符 |
| row_type | 通过 CREATE ROW TYPE 语句定义的某些 ROW 数据类型 | 在数据库中 ROW 类型必须存在 | 标识符; 数据类型 |
您可将命名的 ROW 类型指定给表、给列或给 SPL 变量。您用来创建 typed 表或用来定义列的命名的 ROW 类型必须已存在。要获取关于如何创建命名的 ROW 数据类型的信息,请参阅 CREATE ROW TYPE 语句。
要在符合 ANSI 的数据库中指定命名的 ROW 数据类型,如果您不是 row_type 的所有者,则您必须以它的 owner 名称来限定 row_type。
通过未命名的 ROW 数据类型结构来标识它,其指定您以它的 ROW 构造函数创建的字段。您可指定一列或一 SPL 变量作为未命名的 ROW 数据类型。要获取为未命名的 ROW 类型指定值的语法,请参阅 ROW 构造函数。
集合数据类型
此图展示定义一列或一 SPL 变量作为集合数据类型的语法。要了解指定集合元素的值的语法,请参阅 集合构造函数。
集合数据类型

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| data_type | 每一集合元素的数据类型 | 可为除了 BIGSERIAL、BYTE、SERIAL、SERIAL8 或 TEXT 之外的任何数据类型 | 数据类型 |
SET 是元素的无序的集合,每一元素都有唯一的值。当您想要存储其元素不包含重复的值且没有相关联的顺序的集合时,请将一列定义为 SET 数据类型。
MULTISET 是可有重复的值的元素的无序的集合。当您想要存储其元素可能不是唯一的且没有与它们相关联的特定顺序时,您可将一列定义为 MULTISET 集合类型。
LIST 是一个可包括重复的元素的元素的有序的集合。与 MULTISET 不同的是,LIST 集合中的每一元素都在该集合中有一有序的位置。当您想要存储其元素可能不是唯一的但有一与它们相关联的特定顺序的集合时,您可将一列定义为 LIST 集合类型。
可在 SPL 数据类型声明中使用关键字 COLLECTION,来指定一 untyped 集合变量。
如果您尝试将一个包括一个或多个重复的值的集合插入到 SET 列内,则 GBase 8s 不发出错误,但忽略重复的值,且只插入唯一的值。
SET 列上 DML 操作中的重复元素
SET 数据类型不允许在同一集合中有重复的元素值。如果您尝试将重复的元素插入到 SET 数据类型内,或将 SET 列或变量更新为包括重复的元素的值,则当执行 INSERT 或 UPDATE 语句时,数据库服务器不发出错误或警告,但在 SET 列或变量中仅存储重复的元素之一。
例如,假如您以 SET 数据类型的列 a 创建表 t3,然后您插入四行,其中一些包括有相同的值的元素:
> CREATE TABLE t3(a SET(INT NOT NULL));
Table created.
> INSERT INTO t3 VALUES( SET{10, 20, 30} );
1 row(s) inserted.
> INSERT INTO t3 VALUES( SET{10, 20, 10});
1 row(s) inserted.
> INSERT INTO t3 VALUES( SET{10, 10, 10});
1 row(s) inserted.
> INSERT INTO t3 VALUES( SET{10,10,10});
1 row(s) inserted.
当您查看插入到列 t3.a 内的那些数据值时,插入的四行不包括重复的元素值:
> SELECT * FROM t3;
a SET{10 ,20 ,30 }
a SET{10 ,20 }
a SET{10 }
a SET{10 }
4 row(s) retrieved.
在此示例中, GBase 8s 静默地从为每一 SET 值指定的 INSERT 语句的 VALUES 子句的元素中舍弃一个实例之外的所有重复的元素。
如果 UPDATE 语句的 SET 子句在同一 SET 值内包括重复的元素,则会发生类似的行为。如果您想要数据库存储可在同一集合内包括重复的元素的无序集,则请声明 MULTISET 数据类型的集合列,而不是 SET 数据类型的。
定义元素类型
元素类型可为除了 TEXT、BYTE、SERIAL、SERIAL8 或 BIGSERIAL 之外的任何数据类型。您可使用集合类型的元素嵌套集合类型。
每个元素必须是同一类型的。例如,如果集合数据类型的元素类型是 INTEGER,则每个元素的类型必须是 INTEGER。
要获取附加的信息,请参阅 集合构造函数。
如果集合的元素类型是未命名的 ROW 类型,则未命名的 ROW 类型不可包含持有未命名的 ROW 类型的字段。也就是说,集合不可包含嵌套的未命名的 ROW 数据类型。
集合的元素不可为 NULL。当您定义一列为集合数据类型时,您必须使用 NOT NULL 关键字来指定该集合的元素不可为 NULL。
对集合数据类型的权限就是数据库列的那些权限。您不可在集合的个别元素上指定权限。
表达式
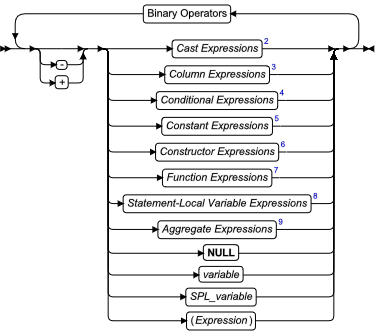
SQL 语句中的数据值必须表示为表达式。表达式是一种规范,其可包括运算符、运算对象和圆括号,数据库服务器可对其求得一个或多个值,或引用某个数据库对象。
表达式可引用数据库的表中已有的值,或从此数据派生的值,但有些表达式(诸如 TODAY、USER 或字面值)可返回独立于数据库的值。您可使用表达式来指定数据操纵语句中的值,定义分片策略和指定其他上下文中的值。只要当您看到语法图中对表达式的引用时,就可使用 Expression 段。
然而,在大多数上下文中,会限定您使用其返回值为某种特定数据类型的表达式,或其数据类型可通过数据库服务器转换为某些需要的数据类型。
要获取在本段中描述的内建的运算符和函数的按字母排序的列表,请参阅 表达式的列表。
表达式语法
二进制运算符

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| SPL_variable | 在 SPL 例程中,包含语法图展示的某个表达式类型的变量 | 必须符合那个类型的表达式的规则 | 标识符 |
| variable | 包含语法图展示的某个表达式类型的主变量或程序变量 | 必须符合那个类型的表达式的规则 | 名称的特定于语言的规则 |
用法
下表罗列 SQL 表达式的类型,如同在 表达式 的图中标识的那样,且描述每一类型返回的内容。
| 表达式类型 | 描述 |
|---|---|
| 聚集函数 | 从内建的或从用户定义的聚集返回值 |
| 算术运算符 | 支持对一个(一元运算符)或两个(二元运算符)数值运算对象的算术操作 |
| 串联运算符 | 串联两个字符串值 |
| 强制转型运算符 | 从一种数据类型显式强制转型到另一种 |
| 列表达式 | 列值 |
| 条件表达式 | 返回依赖于条件测试的值 |
| 常量表达式 | 在数据操纵(DML)语句中的字面值 |
| 构造函数表达式 | 为复合的数据类型动态地创建值 |
| 函数表达式 | 从内建的或用户定义的函数返回值 |
| 语句-本地的变量表达式 | 在声明了它的 SQL 语句中引用语句-本地的变量(SLV) |
您还可使用主变量或 SPL 变量作为表达式。要获取带有对此章节的页引用的完整列表,请参阅下列 "表达式的列表"。
表达式列表
每一类 SQL 表达式都包括许多个别的表达式。
下表以字母顺序罗列所有 SQL 表达式(以及一些运算符)。此表中的列有下列含义:
- 名称给出每一表达式的名称。
- 描述给出每一表达式的简短描述。
- 语法罗列展示该表达式的语法的页。
- 用法展示描述该表达式的用法的页。
| 名称 | 描述 | 语法 | 用法 |
|---|---|---|---|
| ABS 函数 | 返回数值参数的绝对值 | 代数函数 | ABS 函数 |
| ACOS 函数 | 返回数值参数的反余弦 | 三角函数 | ACOS 函数 |
| ACOSH 函数 | 返回指定的数值输入的双曲正切 | 三角函数 | ACOSH 函数 |
| ADD_MONTHS 函数 | 添加指定的月数 | 时间函数 | ADD_MONTHS 函数 |
| 加法(+)运算符 | 返回两个数值运算对象的和 | 表达式 | 算术运算符 |
| ASCII 函数 | 返回在它的字符串参数中第一个字符的 ASCII 代码点 | 字符串操纵函数 | ASCII 函数 |
| ASIN 函数 | 返回数值参数的反正弦 | 三角函数 | ASIN 函数 |
| ASINH 函数 | 返回指定的数值输入的双曲正弦 | 三角函数 | ASINH 函数 |
| ATAN 函数 | 返回数值参数的反正切 | 三角函数 | ATAN 函数 |
| ATAN2 函数 | 计算极坐标的角度分量 | 三角函数 | ATAN2 函数 |
| ATANH 函数 | 返回指定的数值输入的双曲反正切 | 三角函数 | ATANH 函数 |
| AVG 函数 | 返回一组数值的平均值 | 聚集表达式 | AVG 函数 |
| BITAND | 返回两个参数的位 AND | 位逻辑函数 | BITAND 函数 |
| BITANDNOT | 返回两个参数的位 ANDNOT | 位逻辑函数 | BITANDNOT 函数 |
| BITNOT | 返回两个参数的位 NOT | 位逻辑函数 | BITNOT 函数 |
| BITOR | 返回两个参数的位 OR | 位逻辑函数 | BITOR 函数 |
| BITXOR | 返回两个参数的位 XOR | 位逻辑函数 | BITXOR 函数 |
| CARDINALITY 函数 | 返回集合数据类型(SET、MULTISET 或 LIST)中元素的数目 | CARDINALITY 函数 | CARDINALITY 函数 |
| CASE 表达式 | 返回一个依赖于哪几个条件的测试求值为真的值 | CASE 表达式 | CASE 表达式 |
| CAST 表达式 | 将表达式转换为指定的数据类型 | 强制转型表达式 | 强制转型表达式 |
| 强制转型(::)运算符 | 请参阅“双冒号(::)强制转型运算符” | 强制转型表达式 | 强制转型表达式 |
| CEIL 函数 | 返回大于或等于它的单个参数的最小整数 | 代数函数 | CEIL 函数 |
| CHARACTER_ LENGTH 函数 | 请参阅 CHAR_LENGTH 函数。(在多字节语言环境中,这替代 LENGTH 函数。) | 长度函数 | CHAR_LENGTH 函数 |
| CHAR_LENGTH 函数 | 返回字符串参数中逻辑字符的计数 | 长度函数 | CHAR_LENGTH 函数 |
| CHARINDEX 函数 | 返回子字符串在字符串内的位置 | CHARINDEX 函数 | CHARINDEX 函数 |
| CHR | 从缺省的代码集返回取值范围在 0 至 255 的代码点 | 字符串操纵函数 | CHR 函数 |
| 列表达式 | 来自表的列值 | 列表达式 | 列表达式 |
| CONCAT 运算符函数 | 串联两个表达式的结果 | 字符串操纵函数 | CONCAT 函数 |
| 串联(||)运算符 | 串联两个表达式的结果 | 表达式 | 串联运算符 |
| 常量表达式 | 带有字面的、固定的或可变值的表达式 | 常量表达式 | 常量表达式 |
| COS 函数 | 返回弧度表达式的余弦 | 三角函数 | COS 函数 |
| COSH 函数 | 返回参数的双曲余弦,在此,该参数是以弧度表达的角 | 三角函数 | COSH 函数 |
| COUNT(作为函数集) | 返回频率计数的函数。下面罗列 COUNT 函数的每一形式。 | 聚集表达式 | COUNT 函数概述 |
| COUNT (ALL column) 函数 | 请参阅 COUNT (column) 函数。 | 聚集表达式 | COUNT 列函数 |
| COUNT (column) 函数 | 返回指定的列中非 NULL 值的数目 | 聚集表达式 | COUNT 列函数 |
| COUNT DISTINCT 函数 | 返回指定的列中唯一的非 NULL 值的数目 | 聚集表达式 | COUNT DISTINCT 和 COUNT UNIQUE 函数 |
| COUNT UNIQUE 函数 | 请参阅 COUNT DISTINCT 函数。 | 聚集表达式 | COUNT DISTINCT 和 COUNT UNIQUE 函数 |
| COUNT (*) 函数 | 返回满足查询的一组行的计数 | 聚集表达式 | COUNT(*) 函数 |
| CUME_DIST 函数 | 返回 OLAP 分区中每一行的百分比排名 | OLAP 分等级函数表达式 | CUME_DIST 函数 |
| CURRENT 运算符 | 返回由天的日期和时间构成的 DATETIME 值的当前时间 | 常量表达式 | CURRENT 运算符 |
| CURRENT_ROLE 运算符 | 返回当前启用的用户的角色 | 常量表达式 | CURRENT_ROLE 运算符 |
| CURRENT_USER 运算符 | 返回用户的授权标识符。USER 运算符的同义词。 | 常量表达式 | USER 或 CURRENT_USER 运算符 |
| sequence.CURRVAL | 返回指定的 sequence 的当前值 | 常量表达式 | 使用 CURRVAL |
| DATE 函数 | 将非日期参数转换为 DATE 值 | 时间函数 | DATE 函数 |
| DAY 函数 | 将该月的天数作为整数返回 | 时间函数 | DAY 函数 |
| DBINFO (option) | 检索数据库和会话信息的函数。下面罗列每一 option. | DBINFO 函数 | DBINFO 选项 |
| DBINFO ('bigserial') | 返回最近插入的 BIGSERIAL 值 | DBINFO 函数 | 使用 'serial8' 和 'bigserial' 选项 |
| DBINFO ('cdrsession') | 展示 DML 操作是否为复制的事务的一部分 | DBINFO 函数 | 使用 'cdrsession' 选项 |
| DBINFO ('dbhostname') | 返回客户端引用连接到其上的数据库服务器的主机名称 | DBINFO 函数 | 使用 'dbhostname' 选项 |
| DBINFO ('dbname') | 返回客户端应用连接到其上的数据库的标识符 | DBINFO 函数 | 使用 'dbname' 选项 |
| DBINFO ('dbspace', tblspace_number) | 返回对应于 tblspace number 的 dbspace 的名称 | DBINFO 函数 | 使用 ('dbspace', tblspace_num) 选项 |
| DBINFO ('get_tz' ) | 返回当前会话的时区 | DBINFO 函数 | 使用 'get_tz' 选项 |
| DBINFO ('serial8') | 返回最近插入的 SERIAL8 值 | DBINFO 函数 | 使用 'serial8' 和 'bigserial' 选项 |
| DBINFO ('sessionid') | 返回当前会话的会话 ID | DBINFO 函数 | 使用 'sessionid' 选项 |
| DBINFO ('sqlca.sqlerrd1') | 返回插入到表中的最后的 serial 值 | DBINFO 函数 | 使用 'sqlca.sqlerrd1' 选项 |
| DBINFO ('sqlca.sqlerrd2') | 返回通过 DML 语句和通过 EXECUTE PROCEDURE 和 EXECUTE FUNCTION 语句处理的行的数目 | DBINFO 函数 | 使用 'sqlca.sqlerrd2' 选项 |
| DBINFO ('utc_current') | 返回当前的“世界标准时间”(UTC)值。 | DBINFO 函数 | 使用 'utc_current' 选项 |
| DBINFO ('utc_to_datetime', expression) | 返回指定 UTC 值的整数或列 expression 的 DATETIME 值。 | DBINFO 函数 | 使用 'utc_to_datetime' 选项 |
| DBINFO ('version', parameter) | 通过 parameter 指定的那样,返回客户端应用连接到的数据库服务器的确切版本的全部或一部分。 | DBINFO 函数 | 使用 'version' 选项 |
| DBSERVERNAME 函数 | 返回数据库服务器的名称 | 常量表达式 | DBSERVERNAME 和 SITENAME 运算符 |
| DECODE 函数 | 对一个或多个表达式对求值,并以指定的值表达式比较每一对中的 when 表达式 | DECODE 函数 | DECODE 函数 |
| DECRYPT_ BINARY 函数 | 在处理加密的 BLOB 参数之后,返回明文的 BLOB 数据值 | 加密和解密函数 | DECRYPT_BINARY 函数 |
| DECRYPT_CHAR 函数 | 在处理加密的参数之后,返回明文的字符串或 CLOB | 加密和解密函数 | DECRYPT_CHAR 函数 |
| DEFAULT_ROLE 运算符 | 返回当前用户的缺省的角色 | 常量表达式 | DEFAULT_ROLE 运算符 |
| DEGREES 函数 | 将弧的单位转换为度 | 三角函数 | DEGREES 函数 |
| DELETING 布尔运算符 | 如果触发器事件是 DELETE,则返回 't' | 触发器类型的布尔运算符 | 触发器类型的布尔运算符 |
| DENSERANK 函数 | DENSE_RANK 函数的同义词 | OLAP 分等级函数表达式 | DENSE_RANK 函数 |
| DENSE_RANK 函数 | 将 OLAP 分区中的每一行分等级,等级中没有间隔 | OLAP 分等级函数表达式 | DENSE_RANK 函数 |
| 除法(/)运算符 | 返回两个数值运算对象的商 | 表达式 | 算术运算符 |
| 双冒号(::)强制转型运算符 | 将表达式的值转换为指定的数据类型 | 强制转型表达式 | 强制转型表达式 |
| 双管道( || )串联运算符 | 返回将一个字符串运算对象连接到另一字符串运算对象的字符串 | 表达式 | 串联运算符 |
| ENCRYPT_AES 函数 | 在处理明文字符串、BLOB 或 CLOB 之后,返回加密的字符串 | 加密和解密函数 | ENCRYPT_AES 函数 |
| ENCRYPT_TDES 函数 | 在处理明文字符串、BLOB 或 CLOB 之后,返回加密的字符串 | 加密和解密函数 | ENCRYPT_TDES 函数 |
| EXP 函数 | 返回数值表达式的指数 | 指数和对数函数 | EXP 函数 |
| EXTEND 函数 | 重置 DATETIME 或 DATE 值的精度 | 时间函数 | EXTEND 函数 |
| FILETOBLOB 函数 | 从存储在指定的操作系统文件中的数据,创建 BLOB 值 | 智能大对象函数 | FILETOBLOB 和 FILETOCLOB 函数 |
| FILETOCLOB 函数 | 从存储在指定的操作系统文件中的数据,创建 CLOB 值 | 智能大对象函数 | FILETOBLOB 和 FILETOCLOB 函数 |
| FIRST_VALUE 函数 | 对于每一 OLAP window 分区中的第一个行,返回指定表达式的值 | OLAP 聚集函数表达式 | LAST_VALUE 函数 |
| FLOOR 函数 | 返回小于或等于它的单个参数的最大的整数 | 代数函数 | FLOOR 函数 |
| FORMAT_UNITS 函数 | 返回指定内存或存储的数目和缩写的单位的字符串 | FORMAT_UNITS 函数 | FORMAT_UNITS 函数 |
| GETHINT 函数 | 在处理加密的数据-字符串参数之后,返回明文的提示字符串 | 加密和解密函数 | GETHINT 函数 |
| GREATEST 函数 | 返回值集中的最大值 | 代数函数 | GREATEST 函数 |
| HEX 函数 | 返回 base-10 整数参数的十六进制编码 | HEX 函数 | HEX 函数 |
| 主变量 | 请参阅变量。 | SQL 表达式的语法 | SQL 表达式的语法 |
| IFX_ALLOW_ NEWLINE 函数 | 设置 newline 会话模式,允许或不允许在括起来的字符串中的换行字符 | IFX_ALLOW_NEWLINE 函数 | IFX_ALLOW_NEWLINE 函数 |
| INITCAP 函数 | 将字符串参数转换为其中仅每一词的首字母为大写的字符串 | 大小写转换函数 | INITCAP 函数 |
| INSERTING 布尔运算符 | 如果触发器事件为 INSERT,则返回 't' | 触发器类型的布尔运算符 | 触发器类型的布尔运算符 |
| INSTR 函数 | 返回子字符串在字符串内第 N 次发生的位置 | INSTR 函数 | INSTR 函数 |
| ISNULL 函数 | 返回非 NULL 参数的值,或如果该参数为 NULL 则返回指定的值 | ISNUL 函数 | ISNULL 函数 |
| LAG 函数 | 在 OLAP 分区内的当前行之前,返回在指定的偏移量的行的表达式值 | OLAP 分等级函数表达式 | ids_sqs_1513.html#ids_sqs_1513 |
| LAST_DAY 函数 | 返回它的参数指定的那个月的最后一天的日期 | 时间函数 | LAST_DAY 函数 |
| LAST_VALUE 函数 | 返回 OLAP window 分区中最后一行的指定的表达式的值 | OLAP 聚集函数表达式 | LAST_VALUE 函数 |
| LEAD 函数 | 在 OLAP 分区中当前行之后,返回指定的偏移量的行的表达式值 | OLAP 分等级函数表达式 | ids_sqs_1513.html#ids_sqs_1513 |
| LEAST 函数 | 返回值集中的最小值 | 代数函数 | LEAST 函数 |
| LEFT 函数 | 返回字符串最左边的 N 个字符 | LEFT 函数 | LEFT 函数 |
| LEN 函数 | LENGTH 函数的同义词 | 长度函数 | LENGTH 函数 |
| LENGTH 函数 | 返回字符列中的字节数,不包括拖尾的空格 | 长度函数 | LENGTH 函数 |
| LIST 集合构造函数 | 可包含重复的值的有序的集合的构造函数 | 集合构造函数 | 集合构造函数 |
| 文字 BOOLEAN | BOOLEAN 值的文字表示 | 常量表达式 | 常量表达式 |
| 文字集合 | 代表集合数据类型中的元素 | 常量表达式 | 文字的集合 |
| 文字 DATETIME | 代表 DATETIME 值 | 常量表达式 | 文字的 DATETIME |
| 文字 INTERVAL | 代表 INTERVAL 值 | 常量表达式 | 文字的 INTERVAL |
| 精确数值 | 代表数值 | 常量表达式 | 精确数值 |
| 文字 opaque 类型 | 代表 opaque 数据类型 | 常量表达式 | 常量表达式 |
| 文字 row | 代表 ROW 数据类型中的元素 | 常量表达式 | 文字的 Row |
| LN | 返回数值参数的自然对数 | 指数和对数函数 | LN 函数 |
| LOCOPY 函数 | 创建智能大对象的副本 | 智能大对象函数 | LOCOPY 函数 |
| LOG10 函数 | 返回数值参数的以 10 为底的对数 | 指数和对数函数 | LOG10 函数 |
| LOGN 函数 | 返回数值参数的自然对数 | 指数和对数函数 | LOGN 函数 |
| LOTOFILE 函数 | 将 BLOB 或 CLOB 对象复制到文件 | 智能大对象函数 | LOTOFILE 函数 |
| LOWER 函数 | 将大写字母转换为小写 | 大小写转换函数 | LOWER 函数 |
| LPAD 函数 | 返回由指定数目的填充字符左填充的字符串 | 字符串操纵函数 | LPAD 函数 |
| LTRIM 函数 | 从字符串移除指定的开头填充字符。 | 字符串操纵函数 | LTRIM 函数 |
| MAX 函数 | 返回指定值集中的最大值 | 聚集表达式 | MAX 函数 |
| MDY 函数 | 从整数参数返回 DATE 值 | 时间函数 | MDY 函数 |
| MIN 函数 | 返回指定的值集中的最小值 | 聚集表达式 | MIN 函数 |
| MOD 函数 | 从两个数值参数返回模值(整数除的余值) | 代数函数 | MOD 函数 |
| MONTH 函数 | 从 DATE 或 DATETIME 参数返回月份值 | 时间函数 | MONTH 函数 |
| MONTHS_ BETWEEN 函数 | 返回两个时间参数之间的月份差 | 时间函数 | MONTHS_BETWEEN 函数 |
| 乘法(*)运算符 | 返回两个数值运算对象的乘积 | 表达式 | 算术运算符 |
| MULTISET 集合构造函数 | 可包含重复的值的元素的未排序的集合的构造函数 | 集合构造函数 | 集合构造函数 |
| NEXT_DAY 函数 | 返回同时满足两个条件的最早的日历日期 | 时间函数 | NEXT_DAY 函数 |
| sequence.NEXTVAL | 增加指定的 sequence 的值 | 常量表达式 | 使用 NEXTVAL |
| NTILE 函数 | 将 OLAP 分区中的行划分为近似基数的 N 个分级的类别,称为 tiles | OLAP 分等级函数表达式 | NTILE 函数 |
| NULL 关键字 | 未知的、缺失的或逻辑上未定义的值 | NULL 关键字 | NULL 关键字 |
| NULLIF 函数 | 如果两个值相等,则返回 NULL | NULLIF 函数 | NULLIF 函数 |
| NVL 函数 | 返回非 NULL 参数的值,或如果该参数为 NULL 则返回指定的值 | NVL 函数 | NVL 函数 |
| NVL2 函数 | 当第一个参数不是 NULL 时,返回第二个参数 | NVL2 函数 | NVL2 函数 |
| OCTET_LENGTH 函数 | 返回字符列中的字节数,包括任何结尾的空格 | 长度函数 | OCTET_LENGTH 函数 |
| PERCENT_RANK 函数 | 返回 OLAP window 分区中每一行的等级值,规格化到从 0 至 1 的范围 | OLAP 分等级函数表达式 | PERCENT_RANK 函数 |
| POW 函数 | 将一个基值升高到指定阶数的幂 | 代数函数 | POW 函数 |
| POWER® 函数 | POW 函数的同义词 | 代数函数 | POW 函数 |
| 过程调用表达式 | 请参阅用户定义的函数。 | 用户定义的函数 | 用户定义的函数 |
| 程序变量 | 请参阅变量。 | SQL 表达式的语法 | SQL 表达式的语法 |
| QUARTER 函数 | 返回 DATE 或 DATETIME 值的日历季度 | 时间函数 | QUARTER 函数 |
| 括起来的字符串 | 文字字符串 | 常量表达式 | 引用的字符串 |
| RADIANS 函数 | 将度数的单位转换为弧度 | 三角函数 | RADIANS 函数 |
| RANGE 函数 | 返回指定的值集的范围 | 聚集表达式 | RANGE 函数 |
| RANK | 返回一个序数数目来划分 OLAP window 中每一行的等级 | OLAP 分等级函数表达式 | RANK 函数 |
| RATIOTOREPORT 函数 | RATIO_TO_REPORT 函数的同义词 | OLAP 聚集函数表达式 | RATIO_TO_REPORT 函数 |
| RATIO_TO_REPORT 函数 | 返回同一 OLAP window 分区中每一行值对于所有行合计值的分数比率 | OLAP 聚集函数表达式 | RATIO_TO_REPORT 函数 |
| REPLACE 函数 | 替换源字符串中指定的字符 | 字符串操纵函数 | REPLACE 函数 |
| REVERSE | 颠倒源字符串中字符的顺序 | 字符串操纵函数 | REVERSE 函数 |
| RIGHT 函数 | 从源字符串返回最右边的 N 个字符 | RIGHT 函数 | RIGHT 函数 |
| ROOT 函数 | 返回实数、正值、数值参数的第 N 个根值 | 代数函数 | ROOT 函数 |
| ROUND 函数 | 返回参数的四舍五入的值 | 代数函数 | ROUND 函数 |
| ROW 构造函数 | 命名的 ROW 数据类型的构造函数 | 构造函数表达式 | ROW 构造函数 |
| ROWNUMBER 函数 | ROW_NUMBER 函数的同义词 | OLAP 编号函数表达式 | OLAP 编号函数表达式 |
| ROW_NUMBER 函数 | 返回 OLAP window 分区中每一行的序列整数 | OLAP 编号函数表达式 | OLAP 编号函数表达式 |
| RPAD 函数 | 返回由指定数目的填充字符右填充的字符串 | 字符串操纵函数 | RPAD 函数 |
| RTRIM 函数 | 从字符串移除结尾的空填充字符 | 字符串操纵函数 | RTRIM 函数 |
| SECLABEL_BY_ COMP 函数 | 返回其组件为该参数的安全标签 | 安全标签支持函数 | SECLABEL_BY_COMP 函数 |
| SECLABEL_BY_ NAME 函数 | 返回其标识符为该参数的安全标签 | 安全标签支持函数 | SECLABEL_BY_NAME 函数 |
| SECLABEL_TO_ CHAR 函数 | 返回其字符串格式为该参数的安全标签 | 安全标签支持函数 | SECLABEL_TO_CHAR 函数 |
| SELECTING 布尔运算符 | 如果触发器事件为 SELECT,则返回 't' | 触发器类型的布尔运算符 | 触发器类型的布尔运算符 |
| SET 集合构造函数 | 唯一的元素的未排序集合的构造函数 | 集合构造函数 | 集合构造函数 |
| SIGN 函数 | 返回数值参数的符号的标志 | SIGN 函数 | SIGN 函数 |
| SIN 函数 | 返回弧度参数的正弦 | 三角函数 | SIN 函数 |
| SINH 函数 | 返回弧度参数的双曲正弦 | 三角函数 | SINH 函数 |
| SITENAME 函数 | 请参阅 DBSERVERNAME 函数。 | 常量表达式 | DBSERVERNAME 和 SITENAME 运算符 |
| SLV 表达式 | 其作用域为声明它的 SQL 语句的语句-本地的变量(SLV) | 语句本地的变量声明 | 语句本地的变量表达式 |
| SPACE 函数 | 返回 N 个空字符的字符串 | 字符串操纵函数 | SPACE 函数 |
| SPL 例程表达式 | 请参阅“用户定义的函数” | 用户定义的函数 | 用户定义的函数 |
| SPL 变量 | 存储表达式的 SPL 变量 | SQL 表达式的语法 | SQL 表达式的语法 |
| SQLCODE 函数 | 将 sqlca.sqlcode 值返回到 SPL UDR | SQLCODE 函数(SPL) | SQLCODE 函数(SPL) |
| SQRT 函数 | 返回数值参数的平方根 | 代数函数 | SQRT 函数 |
| STDDEV 函数 | 返回数据集的标准偏差 | 聚集表达式 | STDDEV 函数 |
| SUBSTR 函数 | 返回源字符串的一子字符串 | SUBSTR 函数 | SUBSTR 函数 |
| SUBSTRB 函数 | 返回源字符串的一子字符串 | SUBSTRB 函数 | SUBSTRB 函数 |
| SUBSTRING 函数 | 返回源字符串的一子字符串 | SUBSTRING 函数 | SUBSTRING 函数 |
| SUBSTRING_INDEX 函数 | 返回包括第 N 次出现一定界符的子字符串 | SUBSTRING_INDEX 函数 | SUBSTRING_INDEX 函数 |
| Substring ( [ x, y ] ) 运算符 | 从字符串运算对象返回子字符串 | 列表达式 | 使用子字符串运算符 |
| 减法(-)运算符 | 返回两个数值的差 | 表达式 | 算术运算符 |
| SUM 函数 | 返回指定的值集合总和 | 聚集表达式 | SUM 函数 |
| SYSDATE 运算符 | 从系统时钟返回当前的 DATETIME 值。 | 常量表达式 | SYSDATE 运算符 |
| SYSTIMESTAMP运算符 | 在Oracle模式下,从系统时钟返回当前的 DATETIME 值。 | 常量表达式 | SYSTIMESTAMP 运算符 |
| TAN 函数 | 返回弧度表达式的正切 | 三角函数 | TAN 函数 |
| TANH 函数 | 返回弧度参数的双曲正切 | 三角函数 | TANH 函数 |
| TO_CHAR 函数 | 将时间或数值转换成字符串 | 时间函数 | TO_CHAR 函数 |
| TO_DATE 函数 | 将字符串转换成 DATETIME 值 | 时间函数 | TO_DATE 函数 |
| TO_NUMBER 函数 | 将数值或字符串转换成 DECIMAL 值 | TO_NUMBER 函数 | TO_NUMBER 函数 |
| TODAY 运算符 | 返回当前的系统日期 | 常量表达式 | TODAY 运算符 |
| TRIM 函数 | 从字符串参数删除空填充字符 | 字符串操纵函数 | TRIM 函数 |
| TRUNC 函数 | 返回截断的数值或时间值 | 代数函数 | TRUNC 函数 |
| 一元减号(-) | 指定负数(< 0)值 | 表达式 | 算术运算符 |
| 一元加号(+) | 指定整数(> 0)值。 | 表达式 | 算术运算符 |
| UNITS 运算符 | 将整数转化为 INTERVAL 值 | 常量表达式 | UNITS 运算符 |
| UPDATING 布尔运算符 | 如果触发器事件为 UPDATE,则返回 't' | 触发器类型的布尔运算符 | 触发器类型的布尔运算符 |
| UPPER 函数 | 将小写字母转换为大写 | 大小写转换函数 | UPPER 函数 |
| 用户定义的聚集 | 用户定义的聚集(相对于内建的聚集) | 用户定义的聚集 | 用户定义的聚集 |
| 用户定义的函数 | 用户编写的函数(相对于内建的函数) | 用户定义的函数 | 用户定义的函数 |
| USER 运算符 | 返回当前用户的授权表示法 | 常量表达式 | USER 或 CURRENT_USER 运算符 |
| 变量 | 存储值的主变量或程序变量 | SQL 表达式的语法 | SQL 表达式的语法 |
| VARIANCE 函数 | 返回数值值集的差异 | 聚集表达式 | VARIANCE 函数 |
| WEEKDAY 函数 | 返回代表星期几的整数代码 | 时间函数 | WEEKDAY 函数 |
| Window 聚集函数 | 返回来自 OLAP window 分区的聚集结果 | OLAP window 表达式 | OLAP window 聚集函数 |
| YEAR 函数 | 返回表示年份的 4 位整数 | 时间函数 | YEAR 函数 |
| * 符号 | 请参阅“乘法(*)运算符” | SQL 表达式的语法 | 算术运算符 |
| + 符号 | 请参阅“加法”和“一元加号(+)” | SQL 表达式的语法 | 算术运算符 |
| - 符号 | 请参阅“减法”和“一元减号(-)” | SQL 表达式的语法 | 算术运算符 |
| / 符号 | 请参阅“除法运算符” | SQL 表达式的语法 | 算术运算符 |
| :: 符号 | 请参阅“双冒号(::)强制转型运算符” | 强制转型表达式 | 强制转型表达式 |
| || 符号 | 请参阅“双管道(|| )串联运算符” | SQL 表达式的语法 | 串联运算符 |
| q’转义 | 请参阅“q’转义运算符” | SQL表达式语法 | 字符串运算符 |
| [ first, last ] 符号 | 请参阅“子字符串运算符” | 列表达式 | 使用子字符串运算符 |
下面的部分描述出现在前面表格中的每一表达式的语法和用法。
算术运算符
二元算术运算符可组合返回数值的表达式。
| 算术运算 | 算术运算符 | 运算符函数 | 算术运算 | 算术运算符 | 运算符函数 |
|---|---|---|---|---|---|
| 加法 | + | plus( ) | 乘法 | * | times( ) |
| 减法 | – | minus( ) | 除法 | / | divide( ) |
下列示例使用二元算术运算符:
quantity * total_price
price * 2
COUNT(*) + 2
如果您将 DATETIME 值与一个或多个 INTERVAL 值组合,则所有 INTERVAL 值的字段都出现在 DATETIME 值中;不执行隐式的 EXTEND 功能。此外,您不可使用带有 DAY 至 SECOND 间隔的 YEAR 至 MONTH 间隔。要获取关于二元算术运算符的附加信息,请参阅 《GBase 8s SQL 指南:参考》。
二元算术运算符与运算符函数相关联,如前面的表格所示。以二元运算符连接两个表达式等同于对这些表达式调用相关联的运算符函数。例如, 下列两个语句都选择 total_price 列与 2 的乘积。在第一个语句中,* 运算符隐式地调用 times( ) 函数。
SELECT (total_price * 2) FROM items
WHERE order_num = 1001;
SELECT times(total_price, 2) FROM items
WHERE order_num = 1001;
您不可使用算术运算符来将使用聚集函数的表达式与列表达式组合。
数据库服务器为所有内建的数据类型提供与关系运算符相关联的运算符函数。您可定义这些运算符函数的新版本来处理您自己的用户定义的数据类型。
要获取更多信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
数据库服务器还支持下列一元算术运算符。
| 数值的符号 | 一元算术运算符 | 运算符函数 |
|---|---|---|
| 正 | + | positive( ) |
| 负 | – | negate( ) |
一元算术运算符有前面的表格展示的相关联的运算符函数。您可定义这些函数的新版本来处理您自己的用户定义的数据类型。要获取更多关于此主题的信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
如果参与在算术表达式中的任何值为 NULL,则整个表达式的值为 NULL,如下例所示:
SELECT order_num, ship_charge/ship_weight FROM orders
WHERE order_num = 1023;
如果或 ship_charge 或 ship_weight 为 NULL,则表达式,ship_charge/ship_weight 的返回值也为 NULL。 如果在条件中使用 NULL 表达式 ship_charge/ship_weight,则它的真值不可为 TRUE,且不满足条件(除非该 NULL 表达式是 IS NULL 运算符的一个运算对象)。
位逻辑函数
使用位逻辑函数来执行命名的位运算。
位逻辑函数
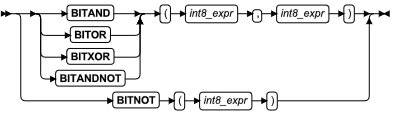
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| int8_expr | 可转化为 INT8 值的数值表达式 | 对于 BITNOT,最大的大小减 1 | 表达式 |
这些函数的参数可为可转换为 INT8 数据类型的任何数值数据类型。
除了带有单个参数的 BITNOT 之外,这些位逻辑函数都有两个可转换为 INT8 值的参数。
如果两个参数都有相同的整数类型,则返回值的数据类型与参数的类型相同。如果两个参数的整数类型不同,则返回值为精度较高的整数类型。例如,如果第一个参数类型为 INT,而第二个参数类型为 INT8,则返回值的类型为 INT8。
如果参数为任何其他数值类型,诸如 DECIMAL、SMALLFLOAT、FLOAT 或 MONEY,或那些类型的某种组合,则返回值数据类型为 DECIMAL(32)。
如果使用主变量,且在准备时刻不知道参数的类型,则假设两个参数都是数据类型 INTEGER,且返回值为 INTEGER。在执行时刻准备之后,如果为主变量提供不同的数据类型值,则 GBase 8s 发出 -9750 错误。要防止发生这样的情况,您可通过使用强制转型来指定主变量数据类型,如下列 ESQL/C 程序片断所示:
sprintf(query1, ",
bitand( ?::int8, ?::int8) from mytab");
EXEC SQL prepare selectq from :query;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor
using :hostvar_int8_input1, :hostvar_int8_input2;
EXEC SQL fetch select_cursor into :var_int8_output;
BITAND 函数
BITAND 函数有两个参数。这些参数可为可转换为 INT8 值的任何数值类型值。
在位运算之前截断小数值。结果是两个参数的 AND。
如果两个参数有相同的整数类型,则返回值的数据类型与参数的类型相同。如果参数有不同的整数类型(例如,INT 和 INT8),则返回带有更高精度的数据类型。如果参数是任何其他数值类型,诸如 DECIMAL、SMALLFLOAT、FLOAT 或 MONEY,或那些类型的某种组合,则返回的数据类型为 DECIMAL(32)。
下列示例展示调用 BITAND 函数的查询:
select task_id, task_status,
decode(bitand(task_status,1), 1, ' Y', ' N') as task_a,
decode(bitand(task_status,2), 2, ' Y', ' N') as task_b,
decode(bitand(task_status,4), 4, ' Y', ' N') as task_c
from tasks;
下表展示此 SELECT 语句的输出。
task_id task_status task_a task_b task_c
100 1 Y N N
101 1 Y N N
102 2 N Y N
103 4 N N Y
104 6 N Y Y
105 3 Y Y N
106 5 Y N Y
107 7 Y Y Y
BITOR 函数
BITOR 函数有两个参数。这些参数可为可转换为 INT8 值的任何数值类型值。
在位运算之前截断小数值。结果是它的两个参数的位 OR。
如果两个参数都有相同的整数类型,则返回值的数据类型与参数的类型相同。如果参数是不同的整数类型(例如,INT 和 INT8),则返回的类型是有较高精度的类型。如果参数是任何其他的数值类型,诸如 DECIMAL、SMALLFLOAT、FLOAT 或 MONEY,或那些类型的某种组合,则返回的数据类型为 DECIMAL(32)
下列示例说明调用 BITOR 函数的查询:
SELECT BITOR(8, 20) AS bitor FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitor
28
BITXOR 函数
BITXOR 函数有两个参数。参数可为可转换为 INT8 值的任何数值类型值。
在位运算之前,截断小数值。结果是它的两个参数的位 XOR。
如果两个参数都有相同的整数类型,则返回值的数据类型与参数的类型相同。如果参数是不同的数据类型(例如,INT 和 INT8),返回的类型是更高精度的类型。如果参数是任何其他的数值类型,诸如 DECIMAL、SMALLFLOAT、FLOAT 或 MONEY,或那些类型的某种组合,则返回的数据类型是 DECIMAL(32)。
下列示例说明调用 BITXOR 函数的查询:
SELECT BITXOR(41, 33) AS bitxor FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitxor
59
此查询调用带有负参数的 BITXOR 函数:
SELECT BITXOR(-20, -41) AS bitxor FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitandnot
16
BITANDNOT 函数
BITANDNOT 函数有两个参数。参数可为可转换为 INT8 值的任何数值类型值。
在位运算之前,截断小数值。结果与两个参数的 BITAND(arg1, BITNOT(arg2)) 相同。
如果两个参数都有相同的整数类型,则返回值的数据类型与参数的类型相同。如果参数是不同的整数类型(例如,INT 和 INT8),则返回的类型是精度更高的类型。如果参数是任何其他的数值类型,诸如 DECIMAL、SMALLFLOAT、FLOAT 或 MONEY,或那些类型的某种组合,则返回的数据类型是 DECIMAL(32)。
下列示例中的查询调用 BITANDNOT 函数:
SELECT BITANDNOT(20,-20) AS bitandnot FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitandnot
16
下列查询为前面的示例中的参数调用等同的 BITAND 和 BITNOT 函数:
select bitand(20, bitnot(-20)) as bitandnot from systables
where tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitandnot
16
BITNOT 函数
BITNOT 函数可取一个小于最大的 INT8 值的任何数值类型值。
在位运算之前,截断小数值。结果是它的参数的位 NOT。
如果参数是 SMALLINT、INT、BIGINT 或 INT8,则返回的数据类型与参数的类型相同。否则返回的数据类型为 DECIMAL(32)。
下列查询调用 BITNOT 函数:
SELECT BITNOT(8) AS bitnot FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitnot
-9
下一查询调用带有负参数的 BITNOT 函数:
SELECT BITNOT(-20) AS bitnot FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
bitnot
19
串联运算符
串联运算符是二元运算符,在 SQL 表达式 的通用图中展示其语法。您可使用串联运算符(||)来串联两个求值为字符数据类型或数值数据类型的两个表达式。这些示例展示一些可能的串联的表达式组合。
- 第一个示例将 zipcode 列串联到 lname 列的前三个字母。
- 第二个示例将后缀 .dbg 串联到名为 file_variable 的主变量的内容。
- 第三个示例将 TODAY 运算符返回的值串联到字符串 Date。
lname[1,3] || zipcode
:file_variable || '.dbg'
'Date:' || TODAY
您不可在下列嵌入式语言语句中使用串联运算符:
- ALLOCATE COLLECTION
- ALLOCATE DESCRIPTOR
- ALLOCATE ROW
- CREATE FUNCTION FROM
- CREATE PROCEDURE FROM
- CREATE ROUTINE FROM
- DEALLOCATE COLLECTION
- DEALLOCATE DESCRIPTOR
- DEALLOCATE ROW DESCRIBE
- DESCRIBE INPUT
- EXECUTE
- FLUSH
- GET DESCRIPTOR
- GET DIAGNOSTICS
- PUT
- SET AUTOFREE
- SET CONNECTION
- SET DESCRIPTOR
- WHENEVER
除非 DECLARE 和 PREPARE 语句另有注明,在下列动态 SQL 语句中,以诸如 GBase 8s ESQL/C 语言这样的外部语言编写的例程不可使用串联运算符:
- CLOSE
- DECLARE
- EXECUTE IMMEDIATE
- FETCH
- FREE
- OPEN
- PREPARE
虽然诸如 cursor_id 规范这样的 DECLARE 语句的输入参数不可为包括串联运算符的表达式,但 GBase 8s ESQL/C 例程可在 DECLARE 语句内的 SELECT、INSERT、EXECUTE FUNCTION 或 EXECUTE PROCEDURE 语句中使用此运算符。
GBase 8s ESQL/C 例程可在 SQL 语句的文本中或在您传递到 PREPARE 语句的语句中使用串联运算符。
在 SPL 例程中,您可在指定传递到 EXECUTE IMMEDIATE 语句或 PREPARE 语句的 SQL 语句的文本的表达式中包括串联运算符,即使该 SPL 例程的调用上下文是一 GBase 8s ESQL/C 例程。
您不可随同用户定义的数据类型、随同复合的或大对象数据类型直接地使用串联运算符,也不可随同非内建的字符或数值数据类型的运算对象使用。在您可将结果传递到串联运算符之前,您必须将 UDT 或其他被支持的数据类型显式地强制转型为内建的字符或数值数据类型。
串联运算的结果的数据类型依赖于运算对象的数据类型以及结果字符串的长度,使用 从 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
串联运算符(||)有相关联的名为 CONCAT 的运算符函数。不可重载 CONCAT 函数。
当您定义基于文本的 UDT 时,您可定义 CONCAT 函数来串联用户定义的数据类型的对象。要获取更多信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
强制转型表达式
您可使用 CAST 和 AS 关键字或双冒号强制转型运算符( :: )来将表达式强制转型为另一数据类型。运算符和这些关键字都调用从表达式的数据类型到指定的目标数据类型的强制转型。
要调用显式的强制转型,您可使用强制转型运算符或 CAST AS 关键字。如果您使用强制转型运算符或 CAST 和 AS 关键字,但未定义显式的或隐式的强制转型来执行两种数据类型之间的转换,则该语句返回错误。
强制转型表达式
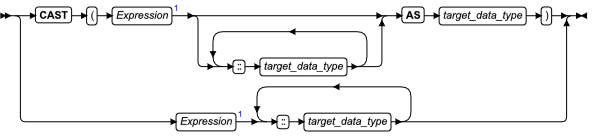
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| target_data_type | 由强制转型返回的数据类型 | 请参阅“对于目标数据类型的规则” | 数据类型 |
对于目标数据类型的规则
下列规则限制强制转型表达式中的目标数据类型:
- 目标数据类型必须为内建的、用户定义的数据类型,或数据库中的命名的 row 类型。
- 目标数据类型不可为未命名的 row 类型或集合类型。
- 在下列情况下,目标数据类型可为 BLOB 数据类型:
- 源表达式(要被强制转型到另一数据类型的表达式)为 BYTE 数据类型。
- 源表达式是用户定义的类型,且用户已定义了从用户定义的类型到 BLOB 类型的强制转型。
- 在这些条件下,目标数据类型可为 CLOB 类型:
- 源表达式是 TEXT 数据类型。
- 源表达式是用户定义的类型,且用户已定义了从用户定义的类型到 CLOB 类型的强制转型。
- 您不可将 BLOB 数据类型强制转型为 BYTE 数据类型。
- 您不可将 CLOB 数据类型强制转型为 TEXT 数据类型。
- 必须存在可将源表达式的数据类型转换为目标数据类型的显式的或隐式的强制转型。
强制转型表达式的示例
下例示例展示将 x 与 y 的总和转化为用户定义的数据类型 user_type 的两种不同方法。这两种方式产生相同的结果。二者都需要存在从由 (x + y) 返回的类型到用户定义的类型的显式的或隐式的强制转型:
CAST ((x + y) AS user_type)
(x + y)::user_type
下列示例展示查找等同于表达式 expr 的整数的两种不同方法。二者都需要存在从数据类型 expr 到 INTEGER 数据类型的隐式的或显式的强制转型:
CAST (expr AS INTEGER)
expr::INTEGER
在下列示例中,用户将 BYTE 列强制转型为 BLOB 类型,并将 BLOB 数据复制到操作系统文件:
SELECT LOTOFILE(mybytecol::blob, 'fname', 'client')
FROM mytab
WHERE pkey = 12345;
在下列示例中,用户将 TEXT 列强制转型为 CLOB 值,然后将同一表中的 CLOB 列更新为从 TEXT 列派生的 CLOB 值:
UPDATE newtab SET myclobcol = mytextcol::clob;
强制转型表达式中的关键字 NULL
强制转型表达式可出现在 projection 列表中,包括形如 NULL**::**datatype 的表达式,在此,datatype 是数据库已知的任何数据类型:
SELECT newtable.col0, null::int FROM newtable;
关键字 NULL 在表达式内有全局的引用作用域。在 SQL 中,关键字 NULL 是访问 NULL 值的唯一语法机制。对于关键字 NULL 的全局作用域的任何重新定义或限制的尝试(例如,声明名为 null 的 SPL 变量),都会禁用涉及 NULL 值的任何强制转型表达式。请确保关键字 NULL 在所有表对象上下文中收到它的全局作用域。
列表达式
列表达式指定数据库中列的数据值,或值的子字符串,或 ROW 类型列内的字段。这是列表达式的语法。
列表达式
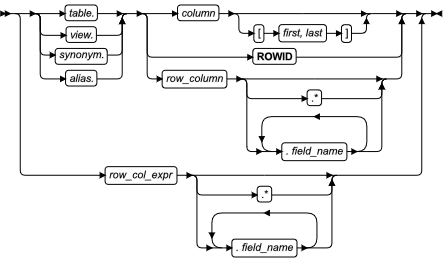
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| alias | 表或视图的临时可替换的名称,在查询的 FROM 子句中声明 | 必须返回字符串。限制依赖于 alias 发生在其中的 SELECT 语句的子句 | 标识符 |
| column | 列的名称 | 限制依赖于 column 发生位置的 SQL 语句 | 标识符 |
| field_name | 在 ROW 列或 ROW 列表达式中 ROW 字段的名称 | 必须为 row-column name 或 row_col_expr 或 field name(对于嵌套的行)指定的行的成员 | 标识符 |
| first、last | 指示 column 内第一个字符和最后一个字符位置的整数 | column 必须为 CHAR、VARCHAR、NCHAR、NVARCHAR、BYTE 或 TEXT 类型,且 0 < first ≤ last | 精确数值 |
| row_col_expr | 返回 ROW 类型值的表达式 | 必须返回 ROW 数据类型 | 表达式 |
| row_column | ROW 类型列的名称 | 必须为命名的 ROW 数据类型或未命名的 ROW 数据类型 | 标识符 |
| synonym、table、view | 包含 column 的表、视图或(表或视图的)同义词 | 同义词以及它指向的表或视图必须存在 | 数据库对象名称,数据库对象名 |
下列示例展示列表达式:
company
items.price
cat_advert [1,15]
每当有必要区分那些有相同的名称但在不同的表中的列时,您必须以表名称或别名限定列。下列展示 SELECT 语句的示例使用来自 customer 和 orders 表的 customer_num。第一个示例将表名称置于列名称之前。第二个示例将表别名置于列名称之前。
SELECT * FROM customer, orders
WHERE customer.customer_num = orders.customer_num;
SELECT * FROM customer c, orders o
WHERE c.customer_num = o.customer_num;
使用点表示法
点表示法(有时称为成员运算符)允许您以为其组件的另一 SQL 标识符限定 SQL 标识符。 您以句号( . )分隔这些标识符。例如,您可以任何下列 SQL 标识符限定列名称:
- 表名称:table_name.column_name
- 视图名称:view_name.column_name
- 同义词名称:syn_name.column_name
这些点表示法的格式称为列 projections。
您还可使用点表示法来直接地访问命名的或未命名的 ROW 列的字段,如下例所示:
row-column name.field name
点表示法的这种使用称为字段 projection。例如,假设您有带有下列定义的名为 rect 的列:
CREATE TABLE rectangles
(
area float,
rect ROW(x int, y int, length float, width float)
);
下列 SELECT 语句使用点表示法来访问 rect 列的字段 length:
SELECT rect.length FROM rectangles WHERE area = 64;
以星号表示法选择 ROW 列的所有字段
如果您想要选择有 ROW 类型的列的所有字段,则您可不使用点表示法指定列名称。例如,您可选择 rect 列的所有字段,如下:
SELECT rect FROM rectangles WHERE area = 64;
您还可使用星号(*)表示法来投影有 ROW 数据类型的列的所有字段。例如,如果您想要使用星号表示法来选择 rect 列的所有字段,您可输入下列语句:
SELECT rect.* FROM rectangles WHERE area = 64;
与分别地指定 rect 列的每一字段相比,星号表示法更容易:
SELECT rect.x, rect.y, rect.length, rect.width
FROM rectangles
WHERE area = 64;
在 SELECT 语句的 projection 列表中,ROW 字段星号表示法是有效的。它可指定 ROW 类型列的所有字段,或 ROW 列表达式返回的数据。
星号表示法不必带有 ROW 类型列,因为您可单独指定列名称来投影它的所有字段。然而,带有 ROW 类型表达式的星号表示法非常有用,诸如返回 ROW 类型值的子查询和用户定义的函数。要获取更多信息,请参阅 使用带有 Row 类型表达式的点表示法。
您仅可在 SELECT 语句的 projection 列表中使用带有 ROW 数据类型的列或表达式的星号表示法。您不可在 SELECT 语句的任何其他子句中使用带有 ROW 类型的列和表达式的星号表示法。
选择嵌套的字段
当定义列的 ROW 类型本身包含其他 ROW 类型时,该列包含嵌套的字段。使用点表示法来访问列内的这些嵌套的字段。
例如,假设 employee 表的 address 列包含字段:street、city、state 和 zip。此外,zip 字段包含嵌套的字段:z_code 和 z_suffix。zip 字段上的查询返回 z_code 和 z_suffix 字段的值。然而,您可指定查询仅返回特定嵌套的字段。下列示例展示如何使用点表示法来构造 SELECT 语句,该语句仅返回 address 列的 z_code 字段的行:
SELECT address.zip.z_code FROM employee;
优先级的规则
数据库服务器使用下列优先级规则来解释点表示法:
- schema name_a . table name_b . column name_c . field name_d
- table name_a . column name_b . field name_c . field name_d
- column name_a . field name_b . field name_c . field name_d
当标识符的含义不明确时,数据库服务器使用优先级规则来确定标识符指定的是哪个数据库对象。请考虑下列两个表:
CREATE TABLE b (c ROW(d INTEGER, e CHAR(2));
CREATE TABLE c (d INTEGER);
在下列 SELECT 语句中,表达式 c.d 引用表 c 的列 d(而不是表 b 中列 c 的字段 d),因为表表达式比列标识符有更高的优先级:
SELECT * FROM b,c WHERE c.d = 10;
要获取更多关于优先级规则以及如何随同 ROW 列使用点表示法的信息,请参阅 GBase 8s SQL 教程指南。
使用带有 Row 类型表达式的点表示法
除了指定 ROW 数据类型的列之外,您还可使用带有任何求值为 ROW 类型的表达式的点表示法。例如,在 INSERT 语句中,您可在返回值的单独行的子查询中使用点表示法。假设您创建名为 row_t 的 ROW 类型:
CREATE ROW TYPE row_t (part_id INT, amt INT);
还假设您创建了基于 row_t ROW 类型的名为 tab1 的 typed 表:
CREATE TABLE tab1 OF TYPE row_t;
还假设您将下列值插入了表 tab1:
INSERT INTO tab1 VALUES (ROW(1,7));
INSERT INTO tab1 VALUES (ROW(2,10));
最后,假设您创建了另一名为 tab2 的表:
CREATE TABLE tab2 (colx INT);
现在,您可使用点表示法来将仅从表 tab1 的 part_id 列的值插入 tab2 表内:
INSERT INTO tab2
VALUES ((SELECT t FROM tab1 t
WHERE part_id = 1).part_id);
当您想要选择 ROW 类型列的所有字段时,星号形式的点表示法不是必须的,因为您可单独指定列名称来选择所有它的字段。然而,当您如在前面示例中那样使用子查询,或当您调用返回 ROW 类型值的用户定义的函数时,点表示法的星号形式可非常有用。
假设名为 new_row 的用户定义的函数返回 ROW 类型值,且您想要调用此函数来将该 ROW 类型值插入表内。星号表示法使得指定将 new_row( ) 函数返回的所有 ROW 类型列插入表内变得非常容易:
INSERT INTO mytab2 SELECT new_row (mycol).\* FROM mytab1;
在分片表达式中不允许引用 ROW 类型列的字段或 ROW 类型表达式。分片表达式是在像 CREATE TABLE、CREATE INDEX 和 ALTER FRAGMENT 那样的 SQL 语句中定义表分片或索引分片的表达式。
使用子字符串运算符
您可在 CHAR、VARCHAR、NCHAR、NVARCHAR、BYTE 和 TEXT 列上使用子字符串运算符来定义列子字符串作为通过该表达式指定的列的一部分。
当一对方括号([ ])括起以逗号分隔的无符号整数,其中 first 整数大于零但不大于 last 整数时,在字符列的标识符之后, GBase 8s 将方括号解释为子字符串运算符。表达式返回列中数据值的从 first 直到 last 字符,在此 first 和 last 定义子字符串。例如,在表达式 cat_advert [6,15] 中,返回值是列 cat_advert 的从第 6 个字符直到第 15 个字符。
在缺省的语言环境中,如果数据值占据至少 15 字节,则此表达式求值为包括该列值的十字节的一子字符串。但在多字节语言环境中,此表达式返回十个连续的逻辑字符的字符串,其存储长度可能超过 10 字节,以第六个逻辑字符开头。要获取关于列子字符串的 GLS 方面的更多信息,请参阅 GBase 8s GLS 用户指南。
在下列示例中,如果 customer 表的 lname 列中的值是 Greenburg,则下列表达式求值为 burg:
lname[6,9]
条件表达式可包括使用子字符串运算符 ( [ first, last ] ) 的列表达式,如下例所示:
SELECT lname FROM customer WHERE phone[5,7] = '356';
此处需要引号来防止数据库服务器将数值过滤器应用到标准值中的数字。
另请参阅 字符串操纵函数 部分,其描述两个可指定 SQL 语句内子字符串表达式的内建的 SQL 函数,SUBSTR( ) 和 SUBSTRING( )。
数据库服务器可使用通过子字符串运算符定义的子字符串作为查询中的索引过滤器。然而,对于由 SUBSTR( ) 或 SUBSTRING( ) 定义的子字符串,或对于其他内建的字符串操纵函数,情况并非如此。
使用 Rowid
在 GBase 8s 中,您可使用与表行相关联的 rowid 列作为该行的一个属性。rowid 列本质上是未分片的表中以及以 WITH ROWIDS 子句创建了的分片的表中的一个隐藏列。对于每一行,rowid 列是唯一的,但它不必是顺序的。然而,推荐您使用主键作为访问方式,而不是利用 rowid 列。
下列示例使用 SELECT 语句中的 ROWID 关键字:
SELECT *, ROWID FROM customer;
SELECT fname, ROWID FROM customer ORDER BY ROWID;
SELECT HEX(rowid) FROM customer WHERE customer_num = 106;
最后的示例展示如何获得您的行的定位的页号(0x 之后的前六位)和槽号(最后两位)。
在包含聚集函数的查询的 Projection 子句的选择列表中,您不可使用 ROWID 关键字。
使用 ROWNUM
ROWNUM 是数据库系统对结果集的编序排列,结果集中第一行的 ROWNUM 值为 1,第二行的 ROWNUM 值为 2 ,依次类推。
可以使用 ROWNUM限制查询返回的总行数,如下所示。
SELECT * FROM customer WHERE ROWNUM < 10;
如果在同一查询连用ROWNUM 和 ORDER BY,则会先根据 ROWNUM 条件取结果集,然后再重新排序,因此,以下语句可能返回与上述示例不同的结果:
SELECT * FROM customer WHERE ROWNUM < 10 ORDER BY fname;
如果想要先排序再应用 ROWNUM 条件,则可以在子查询中嵌入 ORDER BY 子句,而将 ROWNUM 条件放置顶层查询中。例如,以下查询返回按客户编号大小排序的前 10 行结果集。
SELECT * FROM
(SELECT * FROM customer ORDER BY customer_num)
WHERE ROWNUM < 11;
在此示例中,ROWNUM 值是第一层 SELECT 语句的值,因此,它们在子查询已经通过 customer_num 排序后生成。
- ROWNUM 不能使用“> ”条件。
- 建表 CREATE TABLE 不支持定义 ROWNUM 作为列名。例如,create table tab1 ( rownum int),执行报错。
使用智能大对象
SELECT、UPDATE 和 INSERT 语句不直接操纵智能大对象的值。相反,它们使用句柄值(一类指针)来访问 BLOB 或 CLOB 值,如下:
- SELECT 语句返回指向 projection 列表指定的 BLOB 或 CLOB 值的句柄值。SELECT 不返回 projection 列表指定的 BLOB 或 CLOB 列的实际值。相反,它返回指向该列数据的句柄值。
- INSERT 和 UPDATE 语句不将 BLOB 或 CLOB 列的实际数据发送到数据库服务器。相反,它们接受指向此数据的句柄值作为要插入或更新的值。
要访问智能大对象列的数据,您必须使用下列应用编程接口(API)之一:
- 从一 GBase 8s ESQL/C 程序内,使用访问智能大对象的 GBase 8s ESQL/C 库函数。要获取更多信息,请参阅 GBase 8s ESQL/C 程序员手册。
- 从诸如 DataBlade 模块这样的 C 程序内,使用客户端和服务器 API。
您不可在涉及算术运算符的表达式中使用智能大对象列的名称。例如,对智能大对象句柄值的诸如加法或减法这样的运算没有意义。
当您选择智能大对象列时,您可将句柄值赋予任何数目的列:带有相同句柄值的所有列共享该 CLOB 或 BLOB 值。这种存储管理降低 CLOB 或 BLOB 值的磁盘空间量,但当几个列分享同一智能大对象值时,导致下列情况:
- 提高在 CLOB 或 BLOB 列上锁争夺的机会。如果两列共享同一智能大对象值,则该数据库可能被需要访问它的一列锁定。
- 可从多个点更新 CLOB 或 BLOB 值。
要移除这些限制,您可为需要访问它的每一列都创建单独的 BLOB 或 CLOB 数据的副本。您可使用 LOCOPY 函数来创建现有智能大对象的副本。
您还可使用内建的函数 LOTOFILE、FILETOCLOB 和 FILETOBLOB 来访问智能大对象值,如 智能大对象函数 中描述的那样。要获取更多关于 BLOB 和 CLOB 数据类型的信息,请参阅 《GBase 8s SQL 指南:参考》。
条件表达式
条件表达式返回依赖于条件测试的结果的值。此图展示条件表达式的语法。
条件表达式
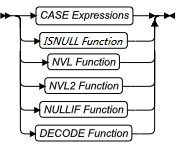
CASE 表达式
CASE 表达式允许诸如 SELECT 语句这样的 SQL 语句返回几个可能的结果之一,依赖于这几个条件中那哪个求值为真。
CASE 表达式有两种形式:通用的 CASE 表达式和线性的 CASE 表达式。
CASE 表达式

在 CASE 表达式中,您必须包括至少一个 WHEN 子句。随后的 WHEN 子句和 ELSE 子句是可选的。您可在 SQL 语句中您可使用列表达式的任何地方使用通用的或线性的 CASE 表达式(例如,在 SELECT 语句的 Projection 子句中)。
搜索条件中的表达式或结果值表达式可包含子查询,且您可在另一 CASE 表达式中嵌套 CASE 表达式。
当在聚集表达式中出现 CASE 表达式时,您不可使用 CASE 表达式中的聚集函数。
您可指定触发器类型布尔运算符(DELETING、INSERTING、SELECTING 或 UPDATING)作为仅在触发器例程内的 CASE 表达式中的条件。
下列查询片断声明两个聚集列表达式的别名:
SELECT . . .
SUM(orders.ship_weight) as o2,
COUNT(DISTINCT
CASE WHEN orders.backlog MATCHES 'n'
THEN orders.order_num END ) AS o3,
. . .
在此,SUM 的参数为 DECIMAL(8,2) 列值,且 COUNT DISTINCT 聚集以 CASE 表达式作为它的参数。
请不要弄混 CASE 表达式与 SPL 的 CASE 语句,它们支持不同的语法和功能。
CASE 表达式数据类型兼容性
在 CASE 表达式中,所有的结果都应为同一数据类型或可兼容的数据类型。
如果在所有 WHEN ... THEN 分支子句中的结果不是同一数据类型或兼容的数据类型,则发生错误。
下表展示哪些字符数据类型是兼容的,以及为每一组合返回的数据类型。
表 1. 从兼容的字符数据类型返回的数据类型
| 数据类型 | NCHAR (>255) | NCHAR (<=255) | NVARCHAR | CHAR (<=255) | CHAR (>255) | VARCHAR | LVARCHAR (>255) | LVARCHAR (<=255) |
|---|---|---|---|---|---|---|---|---|
| NCHAR (>255) | NCHAR | NCHAR | NCHAR | NCHAR | NCHAR | NCHAR | NCHAR | NCHAR |
| NCHAR (<=255) | NCHAR | NCHAR | NVARCHAR | NCHAR | NCHAR | NVARCHAR | NCHAR | NCHAR |
| NVARCHAR | NCHAR | NVARCHAR | NVARCHAR | NVARCHAR | NCHAR | NVARCHAR | NCHAR | NVARCHAR |
| CHAR (<=255) | NCHAR | NCHAR | NVARCHAR | CHAR | CHAR | VARCHAR | CHAR | CHAR |
| CHAR (>255) | NCHAR | NCHAR | NCHAR | CHAR | CHAR | CHAR | CHAR | CHAR |
| VARCHAR | NCHAR | NVARCHAR | NVARCHAR | VARCHAR | CHAR | VARCHAR | CHAR | VARCHAR |
| LVARCHAR (>255) | NCHAR | NCHAR | NCHAR | CHAR | CHAR | CHAR | LVARCHAR | LVARCHAR |
| LVARCHAR (<=255) | NCHAR | NCHAR | NVARCHAR | CHAR | CHAR | VARCHAR | LVARCHAR | LVARCHAR |
下表展示哪些数值数据类型是兼容的,以及为每一组合返回的数据类型。
表 2. 从可兼容的数值数据类型返回的数据类型
| 数据类型 | INTEGER | SMALLINT | SERIAL | DECIMAL | FLOAT | SMALLFLOAT | MONEY | BIGINT | BIGSERIAL |
|---|---|---|---|---|---|---|---|---|---|
| INTEGER | INTEGER | INTEGER | INTEGER | DECIMAL | DECIMAL | DECIMAL | MONEY | DECIMAL | DECIMAL |
| SMALLINT | INTEGER | SMALLINT | INTEGER | DECIMAL | DECIMAL | DECIMAL | MONEY | DECIMAL | DECIMAL |
| SERIAL | INTEGER | INTEGER | SERIAL | DECIMAL | DECIMAL | DECIMAL | MONEY | DECIMAL | DECIMAL |
| DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | MONEY | DECIMAL | DECIMAL |
| FLOAT | DECIMAL | DECIMAL | DECIMAL | DECIMAL | FLOAT | FLOAT | MONEY | DECIMAL | DECIMAL |
| SMALLFLOAT | DECIMAL | DECIMAL | DECIMAL | DECIMAL | FLOAT | SMALLFLOAT | MONEY | DECIMAL | DECIMAL |
| MONEY | MONEY | MONEY | MONEY | MONEY | MONEY | MONEY | MONEY | MONEY | MONEY |
| BIGINT | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | MONEY | BIGINT | BIGINT |
| BIGSERIAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | DECIMAL | MONEY | BIGINT | BIGSERIAL |
通用的 CASE 表达式
通用的 CASE 表达式测试 WHEN 子句中为真的条件。如果它发现为真的条件,则它返回在 THEN 子句中指定的结果。
通用的 CASE 表达式

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 返回某种数据类型的表达式 | 在 THEN 子句中的 expr 的数据类型必须与在其他 THEN 子句中的表达式的数据类型相兼容 | 表达式 |
数据库服务器以 WHEN 子句在该语句出现的顺序处理它们。如果 WHEN 子句的搜索条件求值为 TRUE,则数据库服务器使用对应的 THEN 表达式的值作为结果,并停止处理该 CASE 表达式。
如果没有 WHEN 条件求值为 TRUE,则数据库服务器使用 ELSE 表达式作为总的结果。如果没有 WHEN 条件求值为 TRUE,且未指定了 ELSE 子句,则返回的 CASE 表达式值为 NULL。您可使用 IS NULL 条件来处理 NULL 结果。要获取更多关于如何处理 NULL 值的信息,请参阅 IS NULL 和 IS NOT NULL 条件。
下一示例展示 Projection 子句中通用的 CASE 表达式。
在此示例中,用户检索每一客户的名称和地址以及基于那个顾客存在的问题的数目而计算出的数值:
SELECT cust_name,
CASE
WHEN number_of_problems = 0
THEN 100
WHEN number_of_problems > 0 AND number_of_problems < 4
THEN number_of_problems * 500
WHEN number_of_problems >= 4 and number_of_problems <= 9
THEN number_of_problems * 400
ELSE
(number_of_problems * 300) + 250
END,
cust_address
FROM custtab
在通用的 CASE 表达式中,所有的结果都应为同一数据类型,或它们应求值为以共同兼容的数据类型。如果在所有 WHEN 子句中的结果不是同一数据类型,或如果它们未求值为相互兼容的类型的值,则发生错误。要获取更多关于返回的数据类型的兼容性的信息,请参阅 CASE 表达式数据类型兼容性。
线性的 CASE 表达式
线性的 CASE 表达式将跟在 CASE 关键字之后的表达式的值与 WHEN 子句中的表达式作比较。
线性的 CASE 表达式

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 返回某种数据类型的值的表达式 | 跟在 WHEN 关键字之后的 expr 的数据类型必须与跟在 CASE 关键字之后的表达式的数据类型相兼容。THEN 子句中的 expr 的数据类型必须与其他 THEN 子句中表达式的数据类型相兼容。 | 表达式 |
数据库服务器对跟在 CASE 关键字之后的表达式求值,然后顺序地处理 WHEN 子句。如果 WHEN 关键字之后的表达式返回的值与跟在 CASE 关键字之后的表达式的一样,则数据库服务器使用跟在 THEN 关键字之后的表达式的值作为该 CASE 表达式的总结果。然后,数据库服务器停止处理该 CASE 表达式。
如果没有 WHEN 表达式返回与跟在 CASE 关键字之后的表达式相同的值,则数据库服务器使用 ELSE 子句的表达式作为该 CASE 表达式的总结果(或,如果未指定了 ELSE 子句,则该 CASE 表达式的返回值为 NULL)。
下一示例展示 SELECT 语句的 Projection 子句的 projection 列表中的线性的 CASE 表达式。对于电影标题表中的每部电影,该查询返回电影的标题、成本和类型。该语句使用 CASE 表达式来派生每部电影的类型:
SELECT title, CASE movie_type
WHEN 1 THEN 'HORROR'
WHEN 2 THEN 'COMEDY'
WHEN 3 THEN 'ROMANCE'
WHEN 4 THEN 'WESTERN'
ELSE 'UNCLASSIFIED'
END,
our_cost FROM movie_titles;
在线性的 CASE 表达式中,WHEN 子句表达式的数据类型必须与跟在 CASE 关键字之后的表示的数据类型相兼容。
ISNULL 函数
ISNULL 表达式返回不同的结果,这取决于于它的第一个参数求值是否为 NULL。
ISNULL 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 expr2 | 返回兼容的数据类型的值的表达式 | 无 | 表达式 |
ISNULL 对 expression1 求值。如果 expression1 不是 NULL,则 ISNULL 返回 expression1 的值。如果 expression1 为 NULL,则 ISNULL 返回 expression2 的值。
表达式 expression1 和 expression2 可为任何数据类型,只要可将它们强制转型为共同的兼容的数据类型。
NVL 函数
NVL 表达式返回不同的结果,这依赖于它的第一个参数求值是否为 NULL。
NVL 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 expr2 | 返回兼容的数据类型的值的表达式 | 不可为主变量或 BYTE 或 TEXT 对象 | 表达式 |
NVL 对 expression1 求值。如果 expression1 不是 NULL,则 NVL 返回 expression1 的值。如果 expression1 为 NULL,则 NVL 返回 expression2 的值。表达式 expression1 和 expression2 可为任何数据类型,只要可将它们强制转型为共同的兼容的数据类型。
假设 employees 表的 addr 列在有些行中有 NULL 值,且用户想要能够为这些行打印标签 Address unknown。 当 addr 列有 NULL 值时,用户输入下列 SELECT 语句来显示标签 Address unknown:
SELECT fname, NVL (addr, 'Address unknown') AS address FROM employees;
NULLIF 函数
NULLIF 表达式返回不同的结果,这依赖于它的两个参数是否相等。
NULLIF 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 expr2 | 返回兼容的数据类型的值的表达式 | 不可为 BYTE 或 TEXT 数据类型 | 表达式 |
NULLIF 对它的两个参数 expr1 和 expr2 求值。
- 如果它们的值相等,则 NULLIF 返回 NULL。
- 如果它们的值不等,则 NULLIF 返回 expr1。
expr1 与 expr2 参数可为存在内建的比较函数的任何数据类型,或可强制转型为有内建的比较函数的相兼容的数据类型的任何两种数据类型。
下列示例使用 NULLIF 函数来将布尔 FALSE 值('f')转换为 NULL 值:
SELECT name, answer, NULLIF(answer, 'f') FROM booktab;
在此,第一个参数是可有真('t')或假('f')值的布尔列表达式,且第二个布尔参数始终为 'f"(表示 FALSE)。对于在 answer 列中有 'f' 的行,通过 NULLIF 函数返回的值会是 NULL(因为当参数相等时,返回 NULL 值)。然而,对于有 't' 作为第一个参数,通过 NULLIF 返回的值总是 't',因为当一个是 't' 而其他的是 'f' 时,两个参数不可相等;当两个值不相等时,返回第一个参数。
IFNULL函数
IFNULL 函数用于判断第一个参数是否为NULL,如果expr1为NULL则返回第二个参数;如果expr1不为NULL,则返回第一个参数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1、expr2 | 需要判断是否为null的字符串 | 支持 字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。不支持布尔类型、大对象类型。 | 表达式 |
例如,判断字符串'a'是否为NULL:
select ifnull('a',null) from dual;
(expression) a
1 row(s) retrieved.
说明及限制:
- expr1和expr2同时为NULL时,返回NULL
IF函数
IF函数用来根据expr1条件的返回结果,取不用的指。如何expr1为真,则返回expr2,否则返回expr3。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 判断条件 | 条件表达式 | 表达式 |
| expr2 | 真值结果 | 支持 字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。不支持布尔类型、大对象类 | 表达式 |
| expr3 | 假值结果 | 支持 字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。不支持布尔类型、大对象类 | 表达式 |
例如,1>2条件为假,取3:
select if(1>2,2,3) from dual;
(EXPRESSION)
3
查询到 1 行。
DECODE 函数
DECODE 表达式类似于 CASE 表达式,它能够根据指定列中找到的值打印不同的结果。
DECODE 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 可对其值和数据类型求值的表达式 | 无 | 表达式 |
| when_expr | 对比值 | when_expr 和expr 的数据类型必须一致、 when_expr 的值不可为 NULL。 | 表达式 |
| then_expr | 对应 when_expr 的返回值 | 与 when_expr 成对出现,多个 then_expr 值可以是不同数据类型。但是: ● 当第一个 then_expr是数值型时,其它then_expr不允许为日期型; ● 当第一个 then_expr是日期型时,其它then_expr不允许为非整数数值型; | 表达式 |
| else_expr | 缺省值 | 可以省略。 | 表达式 |
表达式 expr、when_expr 和 then_expr 是必需的。DECODE 对 expr 求值,并把它和 when_expr 比较。如果 when_expr 的值与 expr 的值相匹配,则 DECODE 返回 then_expr。
表达式 when_expr 和 then_expr 是一个表达式对,并且可以在 DECODE 函数中指定任意数量的表达式对。在所有情况下,DECODE 都把表达式对中的第一个成员和 expr 比较,如果第一个成员和 expr 相匹配,那么就返回第二个成员。
如果没有表达式与 expr 匹配,DECODE 就返回 else_expr。如果没有表达式与 expr 相匹配,并且未指定 else_expr,则 DECODE 返回 NULL。
假设用户要将 students 表的 evaluation 列中的描述性值在输出中的转换为数字值。下表给出了 students 表的内容。
| firstname | evaluation |
|---|---|
| Edward | Great |
| Joe | Not done |
| Mary | Good |
| Jim | Poor |
现在,用户输入带有 DECODE 函数的查询,将 evaluation 列中的描述性值转换为等同的数值:
SELECT firstname, DECODE(evaluation,
'Poor', 0,
'Fair', 25,
'Good', 50,
'Very Good', 75,
'Great', 100,
-1) as grade
FROM students;
此 SELECT 语句的输出如下所示:
firstname evaluation
---------- -----------
Edward 100
Joe -1
Mary 50
Jim 0
可以为参数指定任何数据类型。如果多个 then_expr 值的数据类型不一致,DECODE() 函数返回的结果值的数据类型同第一个 then_expr 值的数据类型相同。
当返回的结果值数据类型与第一个 then_expr 值的数据类型不同时,会自动按照以下规则进行隐式转换:
-
支持数值型、日期型转换为字符型;
-
支持纯数值(科学计数法)字符串转换为数值型;
-
支持日期型字符串转换为日期型;
-
支持整数数值型转换为日期型。
- 整数值范围:[-2147483648,214783647]
- 整数 0 转换为 1899-12-31 00:00:00.00000,数值每增加或减少 1,日期相应增加或减少 1 天。
-
支持数值型字符串转换为日期型
将数值型字符串转换为数值型数据。对于浮点数,截断小数点后面的数字,只保留整数部分,然后按照上一条规则进行处理。
示例 1:返回字符型结果值
SELECT DECODE(1,1,’aa’,2,456,3,’789’,000)from dual;
返回结果为:aa
该语句返回的结果值的数据类型为字符型,与第一个 then_expr 值(‘aa’)的类型一致。
示例 2:返回数值型结果值
SELECT DECODE(400,100,1+2,300,’aa’,66)from dual;
返回结果为:66.0000000000000
该语句最终返回的结果值的数据类型为 decimal 。
示例 3:返回日期型结果值
SELECT DECODE(3,100,today,2,’aa’,3,sysdate,6)from dual;
返回结果为:2018-08-30 16:00:48.00000
SELECT DECODE(4,100,today,2,’aa’,3,sysdate,1)from dual;
返回结果为:1900-01-01 00:00:0.00000
该语句最终返回的结果值的数据类型为日期型,与第一个 then_expr 值(today)的类型一致。并将符合条件的返回值 1 转换为日期1900-01-01 00:00:0.00000。
LNNVL函数
LNNVL函数根据表达式计算结果返回布尔值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| condition | 布尔表达式 | 可以为布尔表达式。condition的计算结果为false或unknown时,返回t,计算结果为true时,返回f。 | 表达式 |
例如,返回布尔表达式1 is null 的结果:
select lnnvl(1 is null) from dual;
(CONSTANT)
t
1 row(s) retrieved.
说明及限制:
- 当condition用来比较char和varchar的相同字符串时,返回结果为t。
- 支持不在where语句中直接在select 后使用该函数。
TEXT_EQUAL函数
TEXT_EQUAL 函数返回n1和n2两个数的比较结果,完全相等返回 1;否则返回 0。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n1,n2 | 需要比较是否相同的大对象 | 数据类型为text类型、clob类型、lvarchar类型,或者可以强转为lvarchar的其他数据类型。不支持布尔类型。 | 表达式 |
例如,比较字符串hello和good是否相同:
select text_equal('hello','good') from dual;
(expression)
0
1 row(s) retrieved.
说明及限制:
- 参数n1和n2同时为空串或空格串时,返回1。
NULL_EQU函数
NULL_EQU 函数返回两个类型相同的值的比较。当 expr1=expr2 或 expr1、expr2 两个值中出现 NULL 时,返回 1 ;反之返回 0 。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 指定需比较的值1 | 数据类型可以为字符数据类型、数值数据类型、日期时间数据类型。 | 表达式 |
| expr2 | 指定需比较的值2 | 数据类型可以为字符数据类型、数值数据类型、日期时间数据类型。 | 表达式 |
例如,比较字符串 aaa 与字符串 bbb 是否相等:
select null_equ('aaa','bbb') from dual;
(expression)|
------------+
0|
BLOB_EQUAL函数
BLOB_EQUAL 函数返回n1和n2两个数的比较结果,完全相等返回 1;否则返回 0。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n1,n2 | 需要比较是否相同的大对象 | 数据类型为blob类型、lvarchar类型,或者可以强转为lvarchar的其他数据类型。不支持布尔类型。 | 表达式 |
例如,比较字符串hello和good是否相同:
select null_equ('aaa','bbb') from dual;
(expression)|
------------+
0|
说明及限制:
- 参数n1和n2同时为空串或空格串时,返回1。
- 该函数本质为调用equal函数计算后返回结果。
常量表达式
返回固定的值的某些表达式称为常量表达式。这些包括读取系统时钟的变量函数运算符,但在字面常量也是有效的上下文中才是有效的。
在这些表达式之中有下列运算符(或系统常量)),在运行时确定其返回的值:
- CURRENT 从系统时钟返回当前的时间和日期。
- CURRENT_ROLE 返回角色的名称(如果有的话),为当前用户启用其权限。
- CURRENT_USER 是 USER 的同义词。
- DEFAULT_ROLE 返回角色的名称(如果有的话),是当前用户的缺省角色。
- DBSERVERNAME 返回当前数据库服务器的名称。
- SITENAME 是 DBSERVERNAME 的同义词。
- SYSDATE 从系统时钟读取 DATETIME 值,像 CURRENT 运算符一样,但有不同的缺省精度。
- TODAY 从系统时钟返回当前的日历日期。
- USER 返回当前用户的登录名称(也称为授权标识符)。
除了这些运算符,术语常量表达式还指括起来的字符串、文字值或带有运算对象的 UNITS 运算符。
常量表达式段有下列语法。
常量表达式
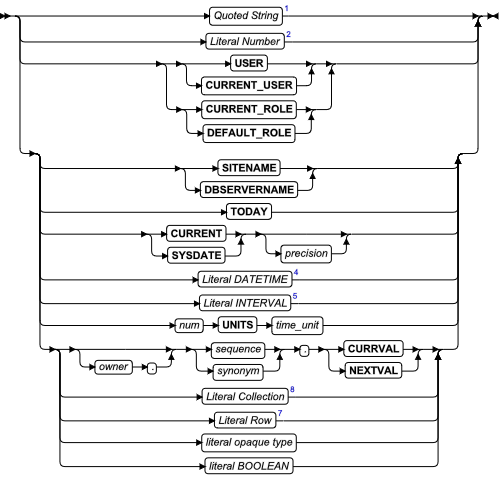
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| literal Boolean | BOOLEAN 值的文字表示 | 必须为 t (TRUE) 或 f (FALSE) | 引用字符串 |
| literal opaque type | opaque 数据类型的值的文字表示 | 必须被 opaque 类型的输入支持函数所识别 | 由 UDT 开发者定义 |
| num | 指定时间单位的数量。请参阅 UNITS 运算符。 | 如果 num 不是整数,则截断小数部分 | 精确数值 |
| owner | 序列的所有者的名称 | 必须拥有序列 | 所有者名称 |
| precision | 返回的 DATETIME 表达式的精度 | 在 Windows™ 系统上,秒的最大范围是 FRACTION(3)。 | DATETIME 字段限定符 |
| sequence | 序列的名称 | 在当前数据库中必须存在 | 标识符 |
| synonym | 序列的名称的同义词 | 在当前数据库中必须存在 | 标识符 |
| time_unit | 指定时间单位的关键字:YEAR、MONTH、DAY、HOUR、MINUTE、SECOND 或 FRACTION | 必须为左边的关键字之一。不区分大小写,但不可括在引号内 | 请参阅 Restrictions 列。 |
引用的字符串
下列示例展示作为表达式的引用的字符串:
SELECT 'The first name is ', fname FROM customer;
INSERT INTO manufact VALUES ('SPS', 'SuperSport');
UPDATE cust_calls SET res_dtime = '2007-1-1 10:45'
WHERE customer_num = 120 AND call_code = 'B';
要获取更多信息,请参阅 引用字符串。
精确数值
精确数值指定数数值。
下列示例展示作为表达式的精确数值:
INSERT INTO items VALUES (4, 35, 52, 'HRO', 12, 4.00);
INSERT INTO acreage VALUES (4, 5.2e4);
SELECT unit_price + 5 FROM stock;
SELECT -1 * balance FROM accounts;
要获取更多信息,请参阅 精确数值。
USER 或 CURRENT_USER 运算符
USER 运算符返回包含正在运行该进程的当前用户的登录名称(也称为授权标识符)的字符串。CURRENT_USER 运算符是 USER 运算符的同义词。
下列语句展示您可以如何使用 USER 运算符:
INSERT INTO cust_calls VALUES
(221,CURRENT,USER,'B','Decimal point off', NULL, NULL);
SELECT * FROM cust_calls WHERE user_id = USER;
UPDATE cust_calls SET user_id = USER WHERE customer_num = 220;
USER 不更改用户 ID 的字母大小写。如果您在表达式中使用 USER 且当前用户为 Robertm,则 USER 运算符返回 Robertm,而不是 robertm 或 ROBERTM。
如果您指定 USER 作为缺省的列值,则 column 必须为类型 CHAR、VARCHAR、NCHAR、NVARCHAR 或 LVARCHAR。
如果您指定 USER 作为列的缺省值,则 column 的大小应不小于 32 字节。如果该列长度太小以至于不能存储缺省值,则在诸如 INSERT 或 ALTER TABLE 这样的操作期间,您会面临出错的风险。
在符合 ANSI 的数据库中,如果您不将 owner 名称括在引号中,则将表所有者的名称存储为大写字母。如果您使用 USER 运算符作为条件的一部分,则您必须确保存储 user 名称的方法与 USER 运算符返回的内容在字母大小写方面相匹配。
CURRENT_ROLE 运算符
CURRENT_ROLE 运算符返回包含正在运行会话的用户的当前启用的角色的名称的字符串。或使用 SET ROLE 语句在会话中显式地设置了此 role ,或当当前用户连接到数据库时,隐式地设置为缺省的角色。如果该用户不持有角色,或如果未授予当前启用的用户角色,则 CURRENT_ROLE 返回 NULL 值。如果尚未授予了用户角色,但已将缺省角色授予了 PUBLIC,且已显式地或隐式地启用了此缺省角色,则 CURRENT_ROLE 返回此缺省角色的名称。
下一语句展示您可以如何使用 CURRENT_ROLE 运算符:
select CURRENT_ROLE FROM systables WHERE tabid = 1;
CURRENT_ROLE 运算符不更改角色的标识符的字母大小写。如果您在表达式中使用 CURRENT_ROLE,且当前角色为 Czarina,则 CURRENT_ROLE 运算符返回 Czarina,而不是 czarina。
如果您指定 CURRENT_ROLE 作为列的缺省值,则该列必须有 CHAR、VARCHAR、LVARCHAR、NCHAR 或 NVARCHAR 数据类型。因为角色的名称是授权标识符,因此如果列长度小于 32 字节,则可能发生截断。
DEFAULT_ROLE 运算符
DEFAULT_ROLE 运算符求值为包含已授予了正在运行会话的用户的缺省角色的名称的字符串。此缺省角色无需当前已经启用,但自从最近的 GRANT DEFAULT ROLE 语句在 TO 子句引用的该用户或 PUBLIC 以来,它必须未被调用。
如果没有为当前用户显式地定义缺省角色,但 PUBLIC 有缺省角色,则 DEFAULT_ROLE 返回 PUBLIC 的缺省角色。
如果用户没有缺省角色,或如果最近将缺省角色显式地授予了该用户,或随后通过 REVOKE DEFAULT ROLE 语句作为 PUBLIC 调用了,则 DEFAULT_ROLE 返回 NULL 值。如果用户尚未被单个地授予了缺省角色,但已将缺省角色授予了 PUBLIC,则 DEFAULT_ROLE 运算符返回此缺省角色的名称。然而,如果当前未为用户也未为 PUBLIC 定义缺省角色,则 DEFAULT_ROLE 返回 NULL。
SET ROLE 语句对 DEFAULT_ROLE 运算符不起作用,但如果 SET ROLE 已激活了某其他角色,或如果 SET ROLE 指定了 NULL 或 NONE 作为用户的当前角色,则用户没必要获得缺省角色的任何访问权限。
下一语句展示您可以如何使用 DEFAULT_ROLE 运算符:
select DEFAULT_ROLE from systables where tabid = 1;
DEFAULT_ROLE 不更改角色的标识符的字母大小写。
如果您指定 DEFAULT_ROLE 作为列的缺省值,则该列必须有 CHAR、VARCHAR、LVARCHAR、NCHAR 或 NVARCHAR 数据类型。由于角色的名称是授权标识符,因此如果列宽小于 32 字节,则可能发生截断。(要了解授权标识符的语法,请参阅 所有者名称。)
DBSERVERNAME 和 SITENAME 运算符
DBSERVERNAME 运算符返回数据库服务器的 SQL 标识符,如同当前数据库所在的 GBase 8s 实例的 ONCONFIG 文件中 DBSERVERNAME 参数所定义的那样,或如同 GBASEDBTSERVER 环境变量中所指定的那样。SITENAME 是 DBSERVERNAME 运算符的关键字同义词。
您可使用 DBSERVERNAME 运算符来指定表的位置,将信息放到表内,或从表抽取信息。您可将 DBSERVERNAME 插入到简单字符字段内或使用它作为列的缺省值。
如果指定 DBSERVERNAME 作为 CREATE TABLE 或 ALTER TABLE 语句中的缺省列值,则该列必须为 CHAR、VARCHAR、LVARCHAR、NCHAR 或 NVARCHAR 数据类型。
如果您指定 DBSERVERNAME 或 SITENAME 作为列的缺省值,则该列的大小应至少为 128 字节长。如果列的长度太小以至于不能存储缺省值,则在 INSERT 和 ALTER TABLE 操作期间,您会面临得到错误消息的风险。
下列示例在 DML 语句中使用 DBSERVERNAME 或 SITENAME。
- 第一个 SELECT 语句返回 customer 表所在的数据库服务器实例的名称。(因为查询不受 WHERE 子句的限制,所以它为表中每行返回相同的 DBSERVERNAME 值。如果您在 projection 子句中包括 DISTINCT 关键字,则数据库仅返回 DBSERVERNAME 一次。)
- 第二个语句将包含当前数据库服务器的名称的行添加到表。
- 第三个语句返回在 host_tab.site_col 列中有当前数据库服务器的名称的所有行。
- 最后的语句将当前数据库服务器的名称更改为其 customer_num 的 SERIAL 值为 120 的行中 customer.company 列的值:
SELECT DBSERVERNAME FROM customer;
INSERT INTO host_tab VALUES ('1', SITENAME);
SELECT * FROM host_tab WHERE site_col = DBSERVERNAME;
UPDATE customer SET company = SITENAME WHERE customer_num = 120;
TODAY 运算符
使用 TODAY 运算符来返回系统日期作为 DATE 数据类型。如果您指定 TODAY 作为缺省的列值,则该列必须为 DATE 列。
下列示例展示您可以在 INSERT、UPDATE 或 SELECT 语句中如何使用 TODAY 运算符:
UPDATE orders (order_date) SET order_date = TODAY WHERE order_num = 1005;
INSERT INTO orders VALUES (0, TODAY, 120, NULL, N, '1AUE217', NULL, NULL, NULL, NULL);
SELECT * FROM orders WHERE ship_date = TODAY;
要获取设置非缺省的时区的代码示例,请参阅 CURRENT 运算符。
CURRENT 运算符
CURRENT 运算符返回带有今日的日期和时间的 DATETIME 值,展示当前时刻。
如果您未指定 DATETIME 限定符,则缺省的限定符为 YEAR TO FRACTION(3)。当数据库服务器从操作系统获取当前时间时,USEOSTIME 配置参数指定它是否使用亚秒精度。要获取更多关于 USEOSTIME 配置参数的信息,请参阅您的 GBase 8s 管理员参考手册。
您可在字面 DATETIME 为有效的任何上下文中使用 CURRENT。(请参阅 文字的 DATETIME)。如果您指定 CURRENT 作为列的缺省值,则它必须为 DATETIME 列且 CURRENT 的限定符必须与列限定符相匹配,如下列示例所示:
CREATE TABLE new_acct (col1 INT, col2 DATETIME YEAR TO DAY
DEFAULT CURRENT YEAR TO DAY);
始终在当前数据库所在的数据库服务器中为 CURRENT 求值。如果当期数据库在远程数据库服务器中,则从远程主机返回值。
SQL 不是过程的语言,且 CURRENT 可能不以在语句中它的位置的词典次序执行。在 SQL 语句的执行中,您不应使用 CURRENT 来标记开始、终止、特定的点。
如果您在单个语句中使用 CURRENT 运算符超过一次,则可能由 CURRENT 的每一实例返回相同的值。您不可依靠 CURRENT 来在它每次执行时返回不同的值。
当指定 CURRENT 的 SQL 语句启动执行时,该返回值基于系统时钟且是固定的。例如,从 EXECUTE FUNCTION(或 EXECUTE PROCEDURE)语句调用的 SPL 函数之内,对 CURRENT 的任何调用都返回当 SPL 函数启动时系统时钟的值。
在 UNIX™ 和 Linux™ 系统上,通过 CURRENT 运算符返回的值的精度由它的 DATETIME 限定符决定,精度范围可从单个时间单位(诸如 MONTH TO MONTH)直到 YEAR TO FRACTION (5)。然而,在 Windows™ 上的系统时钟仅返回亚秒精度。即使您在 DATETIME 限定符中指定 "FRACTION(5)",Windows 上的 CURRENT 运算符也不支持高于 "FRACTION(3)" 的精度。
如果您的平台不提供以亚秒精度的当前时间返回的系统调用,则 CURRENT 为 FRACTION 字段返回零。
在下列示例中,第一个语句使用 WHERE 条件中的 CURRENT。第二个语句使用 CURRENT 作为 DAY 函数的参数。最有的查询选择其 call_dtime 值在从 2007 年初到当前时刻的范围内的行:
DELETE FROM cust_calls WHERE res_dtime < CURRENT YEAR TO MINUTE;
SELECT * FROM orders WHERE DAY(ord_date) < DAY(CURRENT);
SELECT * FROM cust_calls WHERE call_dtime BETWEEN '2007-1-1 00:00:00' AND CURRENT;
要获取更多信息,请参阅 DATETIME 字段限定符。
SYSDATE 运算符
SYSDATE 运算符从系统时钟返回当前的 DATETIME 值。SYSDATE 与 CURRENT 运算符是相同的,除了 SYSDATE 的缺省精度是 YEAR TO FRACTION(5),而 CURRENT 的缺省精度是 YEAR TO FRACTION(3)。
在下列示例中的 SQL 语句使用 SYSDATE 运算符来为数据库的两个 DATETIME 列指定缺省值,并将新行插入到该表内:
CREATE TABLE tab1 (
id SERIAL,
value CHAR(20),
time1 DATETIME YEAR TO FRACTION(5) DEFAULT SYSDATE,
time2 DATETIME YEAR TO SECOND DEFAULT SYSDATE YEAR TO SECOND
);
INSERT INTO tab1 VALUES (0, 'description', SYSDATE, SYSDATE);
下列查询访问在前面的示例中创建了的表:
SELECT SYSDATE AS sysdate, * FROM tab1;
当发出 INSERT 和 SELECT 语句时,结果对日期和时间是灵敏的,但在 2007 年 9 月 23 日该查询可能返回这些值:
sysdate 2007-09-23 21\:30\:23.00000
id 1
value description
time1 2007-09-23 21\:29\:27.00000
time2 2007-09-23 21\:29\:27
下一查询访问同一表,使用 WHERE 子句中的 SYSDATE 作为 DAY 函数的一个参数:
SELECT *, DAY(time1) AS day FROM tab1
WHERE DAY(time1) = DAY(SYSDATE);
在 2007 年 9 月 23 日,该查询可能返回这些值:
id 1
value description
time1 2007-09-23 21\:29\:27.00000
time2 2007-09-23 21\:29\:27
day 23
仅 GBase 8s 支持 SYSDATE。除了它的名称和它的缺省精度之外,在本文档中 CURRENT 运算符的描述也适用于 SYSDATE 运算符。
在 Oracle 模式下使用 SYSDATE 运算符,SYSDATE 的返回精度是 YEAR TO SECOND。
下列示例中的 SQL 语句,在Oracle模式下使用 SYSDATE 运算符返回当前系统时间:
SET ENVIRONMENT SQLMODE 'oracle';
SELECT SYSDATE AS sysdate FROM DUAL;
该查询返回如下值:
SYSDATE 2007-09-23 21\:29\:27
当前版本 Oracle 兼容模式与 GBase 模式在切换过程中,未开启 USEOSTIME,SYSDATE 运算符由于精度取值的差异,Oracle 模式切换至GBase 模式的转换处理如下:
- 切换模式后小于 1 秒内,再次调用 SYSDATE ,返回数值精度为 YEAR TO FRACTION(5),并且读取系统时钟小数秒数值,例如可能返回值 2007-09-23 21:29:27.14871 ;
- 切换模式后大于 1 秒,再次调用 SYSDATE ,返回数值精度为 YEAR TO FRACTION(5),并且仅读取系统时钟至整数秒,例如可能返回值 2007-09-23 21:29:27.00000 。
由于以上转换处理,建议用户在使用 SYSDATE 运算符时,尽量保持在统一模式下。
SYSTIMESTAMP 运算符
在Oracle模式下,SYSTIMESTAMP关键字返回数据库所在系统的系统日期,包括年、月、日、时、分、秒、小数秒,返回类型是DATETIME数据类型。默认输出格式为:DD-MM-YY HH:mm:ss.fffff;
日期时间输出格式可由DBCENTURY环境变量、DBDATE环境变量、DBTIME环境变量、GL_DATE环境变量、GL_DATETIME环境变量决定;
SYSTIMESTAMP关键字可以指定参数n,即SYSTIMESTAMP(n)。参数n指定了小数秒的精度,取值范围为1-5,默认为5。当参数n超出精度范围时,报错:201语法错误。
示例:
CREATE TABLE tab1 (
id SERIAL,
value CHAR(20),
time1 DATETIME YEAR TO FRACTION(5) DEFAULT SYSTIMESTAMP,
time2 DATETIME YEAR TO SECOND DEFAULT SYSTIMESTAMP YEAR TO SECOND
);
INSERT INTO tab1 VALUES (0, 'description', SYSTIMESTAMP, SYSTIMESTAMP);
下列查询访问在前面的示例中创建了的表:
SELECT SYSTIMESTAMP AS SYSTIMESTAMP, * FROM tab1;
当发出 INSERT 和 SELECT 语句时,结果对日期和时间是灵敏的,但在 2023 年 2 月 24 日该查询返回这些值:
SYSTIMESTAMP 2023-02-24 15\:17\:44.125
ID 1
VALUE description
TIME1 2023-02-24 15\:15\:40.659
TIME2 2023-02-24 15\:15\:40
下一查询访问同一表,使用 WHERE 子句中的 SYSTIMESTAMP 作为 DAY 函数的一个参数:
SELECT *, DAY(time1) AS day FROM tab1
WHERE DAY(time1) = DAY(SYSTIMESTAMP);
在 2023 年 2 月 24 日,该查询可能返回这些值:
ID 1
VALUE description
TIME1 2023-02-24 15\:15\:40.659
TIME2 2023-02-24 15\:15\:40
DAY 24
文字的 DATETIME
文字的 DATETIME 指定 DATETIME 数据类型的值,包括它的限定的时间单位。
下列示例展示作为表达式的文字的 DATETIME:
SELECT DATETIME (2007-12-6) YEAR TO DAY FROM customer;
UPDATE cust_calls SET res_dtime = DATETIME (2008-07-07 10:40)
YEAR TO MINUTE
WHERE customer_num = 110
AND call_dtime = DATETIME (2008-07-07 10:24) YEAR TO MINUTE;
SELECT * FROM cust_calls
WHERE call_dtime
= DATETIME (2008-12-25 00\:00\:00) YEAR TO SECOND;
要获取更多信息,请参阅 文字的 DATETIME。
文字的 INTERVAL
文字的 INTERVAL 指定 INTERVAL 数据类型的值,包括它的限定的时间单位。
下列每一示例使用文字的 INTERVAL 作为表达式:
INSERT INTO manufact VALUES ('CAT', 'Catwalk Sports',
INTERVAL (16) DAY TO DAY);
SELECT lead_time + INTERVAL (5) DAY TO DAY FROM manufact;
第二个示例将五天添加到从 manufact 表选择的每一 lead_time 的值。
要获取更多信息,请参阅 文字的 INTERVAL。
UNITS 运算符
UNITS 运算符指定其精度仅包括一个时间单位的 INTERVAL 值。您可在 INTERVAL 或 DATETIME 值中增加或减少一个时间单位的算术表达式中使用 UNITS。
如果 num 运算对象不是整数,则当数据库服务器为该表达式求值时,将它截断到与指定的值相同的(或更接近于零的)完整数。
在下列示例中,第一个 SELECT 语句使用 UNITS 运算符来选择所有增加了五天的 manufacturer.lead_time 值。第二个 SELECT 语句找到放置了超过 30 天的所有呼叫。
如果 WHERE 子句中的表达式返回一大于 99(最大的天数)的值,则查询失败。最后的语句为 ANZE 制造商增加两天的交付时间:
SELECT lead_time + 5 UNITS DAY FROM manufact;
SELECT * FROM cust_calls WHERE (TODAY - call_dtime) > 30 UNITS DAY;
UPDATE manufact SET lead_time = 2 UNITS DAY + lead_time
WHERE manu_code = 'ANZ';
NEXTVAL 和 CURRVAL 运算符
您可在 SQL 语句中使用 NEXTVAL 或 CURRVAL 运算符来访问序列的值。您必须以在同一数据库中存在的序列对象的名称(或同义词)来限定 NEXTVAL 或 CURRVAL,使用格式 sequence .NEXTVAL 或 sequence .CURRVAL。表达式还可通过 owner 名称来限定 sequence,就像在 zelaine.myseq.CURRVAL 中那样。您可指定 sequence 的标识符或有效的同义词,如果存在的话。
在符合 ANSI 的数据库中,如果您不是所有者,则您必须以其所有者的名称(owner.sequence)来限定 sequence 的名称。
要随同序列使用 NEXTVAL 或 CURRVAL,您必须在该序列上有 Select 权限或在数据库上有 DBA 权限。要获取更多关于序列级权限的信息,请参阅 GRANT 语句 语句。
示例
在下列示例中,假设当前没有其他用户正在访问该序列,且用户依顺序执行这些语句。
这些示例基于下列序列对象和表:
CREATE SEQUENCE seq_2
INCREMENT BY 1 START WITH 1
MAXVALUE 30 MINVALUE 0
NOCYCLE CACHE 10 ORDER;
CREATE TABLE tab1 (col1 int, col2 int);
INSERT INTO tab1 VALUES (0, 0);
您可在 INSERT 语句的 Values 子句中使用 NEXTVAL(或 CURRVAL),如下列示例所示:
INSERT INTO tab1 (col1, col2)
VALUES (seq_2.NEXTVAL, seq_2.NEXTVAL);
在前面的示例中,数据库服务器将增加的值(或该序列的第一个值,其为 1)插入到表的 col1 和 col2 列内。
您可在 UPDATE 语句的 SET 子句中使用 NEXTVAL(或 CURRVAL),如下列示例所示:
UPDATE tab1
SET col2 = seq_2.NEXTVAL
WHERE col1 = 1;
在前面的示例中,seq_2 序列的增加的值(其为 2)替代 col2 中 col1 等于 1 的值。
下列示例展示您可如何使用 SELECT 语句的 Projection 子句中的 NEXTVAL 和 CURRVAL:
SELECT seq_2.CURRVAL, seq_2.NEXTVAL FROM tab1;
在前面的示例中,数据库服务器从 CURRVAL 和 NEXTVAL 表达式返回增加的值的两行,3 和 4。对于 tab1 的第一行,数据库服务器为 CURRVAL 和 NEXTVAL 返回增加的值 3;对于 tab1 的第二行,它返回增加的值 4。
使用 NEXTVAL
要首次访问序列,在您可引用 sequence.CURRVAL 之前,你必须引用 sequence.NEXTVAL。第一个对 NEXTVAL 的引用返回该序列的初始值。对 NEXTVAL 的每一后续的引用,都按照定义的 step 来增加该序列的值,并返回该序列的新的增加的值。
在单个 SQL 语句之内,您可对给定的序列仅增加一次。即使您在单个语句之内指定 sequence .NEXTVAL 多次,该序列也仅增加一次,因此,在同一 SQL 语句中 sequence .NEXTVAL 的每次发生都返回相同的值。
除了在同一语句之内多次发生的情况之外,每个 sequence .NEXTVAL 表达式增加该 sequence,不管您随后是提交还是回滚当前事务。
如果您在最终回滚了的事务中指定 sequence .NEXTVAL,则可能跳过某些序列编号。
使用 CURRVAL
任何对 CURRVAL 的引用都返回指定序列的当前值,这是您最后对 NEXTVAL 引用返回的值。在您以 NEXTVAL 创建新值之后,您可继续使用 CURRVAL 来访问那值,不管另一用户是否增加该序列。
如果在 SQL 语句中同时发生 sequence .CURRVAL 和 sequence .NEXTVAL,则该序列仅增加一次。在此情况下,每一 sequence .CURRVAL 和 sequence .NEXTVAL 表达式返回相同的值,不管 sequence .CURRVAL 和 sequence .NEXTVAL 在语句内的顺序。
对序列的并发访问
序列总是生成数据库内的唯一值,即使当多个用户并发地引用同一序列,也觉察不到等待或锁定。当多个用户使用 NEXTVAL 来增加序列时,每一用户生成其他用户不可见的唯一值。
当多个用户并发地增加同一序列时,每一用户看到的值发生差异。例如,一个用户可能从序列生成一系列值,诸如 1、4、6 和 8,而另一用户从同一序列对象并发地生成值 2、3、5 和 7。
对序列运算符的限制
NEXTVAL 和 CURRVAL 仅在 SQL 语句中有效,在 SPL 语句中不是直接有效的。(但可在 SPL 例程中使用使用 NEXTVAL 和 CURRVAL 的 SQL 语句。)下列限制适用于 SQL 语句中的这些运算符:
- 您必须有对序列的 Select 权限。
- 在 CREATE TABLE 或 ALTER TABLE 语句中,您不可在下列上下文中指定 NEXTVAL 或 CURRVAL:
- 在列定义的 Default 子句中
- 在检查约束的定义中。
- 在 SELECT 语句中,您不可在下列上下文中指定 NEXTVAL 或 CURRVAL:
- 当使用 DISTINCT 关键字时,在 projection 列表中
- 在 WHERE、GROUP BY 或 ORDER BY 子句中
- 在子查询中
- 当 UNION 运算符组合 SELECT 语句时。
- 在这些上下文中,你也不可指定 NEXTVAL 或 CURRVAL:
- 在分片表达式中
- 在对另一数据库中的远程序列对象的引用中。
文字的 Row
在 Literal Row 部分中描述命名的或未命名的 ROW 数据类型的值的文字表示的语法。下列示例展示作为表达式的文字的 row:
INSERT INTO employee VALUES
(ROW('103 Baker St', 'San Francisco',
'CA', 94500));
UPDATE rectangles
SET rect = ROW(8, 3, 7, 20)
WHERE area = 140;
EXEC SQL update table(:a_row)
set x=0, y=0, length=10, width=20;
SELECT row_col FROM tab_b
WHERE ROW(17, 'abc') IN (row_col);
要了解求值为 ROW 数据类型的字段值的表达式的语法,请参阅 ROW 构造函数。
文字的集合
GBase 8s 支持内建的或用户定义的数据类型的值的文字表示的表达式。下列示例展示作为表达式的文字的集合:
INSERT INTO tab_a (set_col) VALUES ("SET{6, 9, 3, 12, 4}");
INSERT INTO TABLE(a_set) VALUES (9765);
UPDATE table1 SET set_col = "LIST{3}";
SELECT set_col FROM table1 WHERE SET{17} IN (set_col);
要获取更多信息,请参阅 文字的集合。要了解元素值的语法,请参阅 集合构造函数。
构造函数表达式
构造函数是数据库服务器用来创建特定的数据类型的实例的函数。数据库服务器支持 ROW 构造函数和集合构造函数。
构造函数表达式

ROW构造函数
您使用 ROW 构造函数来生成 ROW 类型列的值。
假设您创建下列命名的 ROW 类型以及包含命名的 ROW 类型 row_t 和未命名的 ROW 类型的表:
CREATE ROW TYPE row_t ( x INT, y INT);
CREATE TABLE new_tab
(
col1 row_t,
col2 ROW( a CHAR(2), b INT)
);
当您定义列作为命名的 ROW 类型或未命名的 ROW 类型时,您必须使用 ROW 构造函数来生成 ROW 类型列的值。要为命名的 ROW 类型或未命名的 ROW 类型创建值,您必须完成下列步骤:
- 以 ROW 关键字开始该表达式。
- 为每一 ROW 类型的字段指定值。
- 将以逗号分隔的字段值的列表括在圆括号内。
每一字段的值的格式必须与将它指定到的那个 ROW 字段的数据类型相兼容。
您可使用任何类型的表达式作为带有 ROW 构造函数的值,包括文字、函数和变量。下列示例展示使用不同类型的带有 ROW 构造函数的表达式来指定值:
ROW(5, 6.77, 'HMO')
ROW(col1.lname, 45000)
ROW('john davis', TODAY)
ROW(USER, SITENAME)
下列语句使用带有 ROW 构造函数的字面的数值和引用的字符串来将值插入到 new_tab 表的 col1 和 col2 内:
INSERT INTO new_tab
VALUES
(
ROW(32, 65)::row_t,
ROW('CA', 34)
);
当您使用 ROW 构造函数来生成命名的 ROW 类型的值时,您必须显式地将 ROW 强制转型为适当的命名的 ROW 类型。 强制转型有必要生成命名的 ROW 类型的值。要将 ROW 值强制转型为命名的 ROW 类型,您可使用强制转型运算符(:: )或 CAST AS 关键字,如下例所示:
ROW(4,5)::row_t
CAST (ROW(3,4) AS row_t)
您可使用 ROW 构造函数来在 INSERT、UPDATE 和 SELECT 语句中生成 ROW 类型值。在下一示例中,SELECT 语句的 WHERE 子句指定强制转型为类型 person_t 的一个 ROW 类型值:
SELECT * FROM person_tab
WHERE col1 = ROW('charlie','hunter')::person_t;
要获取更多关于在 INSERT 和 UPDATE 语句中使用 ROW 构造函数的信息,请参阅本文档中的 INSERT 和 UPDATE 语句。要获取关于命名的 ROW 类型的信息,请参阅 CREATE ROW TYPE 语句。要获取关于未命名的 ROW 类型,请参阅 《GBase 8s SQL 指南:参考》 中的 ROW 数据类型的讨论。
集合构造函数
使用集合构造函数来为集合列指定值。
集合构造函数

您可在 SELECT 语句的 WHERE 子句中以及 INSERT 语句的 VALUES 子句中使用集合构造函数。您还可将集合构造函数传递给 UDR。
此表区分您可构造的集合的类型。
| 关键字 | 描述 |
|---|---|
| SET | 表明带有下列性质的集合元素: ● 该集合必须包含唯一的值。 ● 元素有与他们相关联的特定的顺序。 |
| MULTISET | 表明带有下列性质的元素的集合: ● 该集合可包含重复的值。 ● 元素没有与他们相关联的特定的顺序。 |
| LIST | 表明带有下列性质的元素的集合: ● 该集合可包含重复的值。 ● 元素有顺序位置。 |
集合的元素类型可为任何内建的或扩展的数据类型。您可随同集合构造函数使用任何类型的表达式,包括文字、函数和变量。
当您使用带有表达式的列表的集合构造函数时,数据库服务器将每一表达式求值为它等同的文字,并使用文字的值来构造该集合。
您可以一系列大括号( { } )指定空集合。
集合的元素不可为 NULL。如果集合元素求值为 NULL 值,则数据库服务器返回错误。
每一表达式的元素类型必须全都是完全相同的数据类型。要实现这一点,将整个集合构造函数表达式强制转型为集合类型,或将个别的元素表达式强制转型为同一类型。如果数据库服务器不可确定集合类型与元素类型是同类的,则集合构造函数返回错误。在主变量的情况下,在客户端声明主变量的元素类型的绑定时刻作出此决定。
当集合的有些元素是 VARCHAR 数据类型但其他的长度不长于 32,765 字节时,可发生对此限制的例外。在此,集合构造函数可将 CHAR(n) 类型指定给所有元素,n 是以字节计的最长的元素的长度。(但是,请参阅 集合数据类型 了解基于此例外的示例,用户通过显式的强制转型为 LVARCHAR 数据类型来避免固定长度的 CHAR 元素。)
集合构造函数的示例
下列示例展示您可以不同的表达式构造集合,如果结果值是同一数据类型的话:
CREATE FUNCTION f (a int) RETURNS int;
RETURN a+1;
END FUNCTION;
CREATE TABLE tab1 (x SET(INT NOT NULL));
INSERT INTO tab1 VALUES
(
SET{10,
1+2+3,
f(10)-f(2),
SQRT(100) +POW(2,3),
(SELECT tabid FROM systables WHERE tabname = 'sysusers'),
'T'::BOOLEAN::INT}
);
SELECT * FROM tab1 WHERE
x=SET{10,
1+2+3,
f(10)-f(2),
SQRT(100) +POW(2,3),
(SELECT tabid FROM systables WHERE tabname = 'sysusers'),
'T'::BOOLEAN::INT}
};
这假设存在从 BOOLEAN 到 INT 的强制转型。(要了解对指定集合值的更限制性的语法,请参阅 文字的集合。)
NULL关键字
在您可指定值的大部分上下文中,NULL 关键字是有效的。然而,它指定的内容没有任何值(或未知的或遗失的值)。
NULL 关键字
![]()
在 SQL 内,关键字 NULL 是访问 NULL 值的唯一语法机制。NULL 不等同于零,也不等同于任何特定的值。在升序的 ORDER BY 操作中,NULL 值排在任何非 NULL 值之前;在降序排序中,NULL 值跟在任何非 NULL 值之后。在 GROUP BY 操作中,所有 NULL 值都组在一起。(如果它们包括遗失的值或未知的值,则这样的分组可能在逻辑上是各种各样的。)
在表达式的语法上下文中,关键字 NULL 是全局的符号,意味着它的引用作用域是全局的。
每种数据类型,不论内建或用户定义的,都可以代表 NULL 值。本版本 GBase 8s支持以下两种形式的 NULL 查询:
- 在投影列表中直接包含 NULL 关键字,无需强制转型。
- 在投影列表中包含 NULL**::**datatype形式的强制转型表达式,其中 datatype 是数据库服务器已知的任何数据类型。
GBase 8s在一般表达式中支持已归类的 NULL 关键字。在某些情境下单独的 NULL 将导致 -201 语法错误。因此,如果 NULL 定义为列名称或过程名称,那么它必须以通过表别名被引用。否则,将返回 -201 语法错误。以下示例和结果可总结该行为:
create table tab1 (a int, null int);
create table tab2 (a int, b int);
表 1. NULL 行为
| 语句 | 结果 |
|---|---|
| select null from tab1 where a = 1 | -201 语法错误 |
| select * from tab1 where null = a | -201 语法错误 |
| select * from tab1 where tab1.null = a | 有效的语法 |
| select * from tab1 where a = null | -201 语法错误 |
| select * from tab2 where a = null | -201 语法错误 |
| select * from tab2 where null = a | -201 语法错误 |
| select * from tab2 where null = a | -201 语法错误 |
| select NULL::int from tab1 | 有效的语法 |
| select NULL from tab1 | 有效的语法 |
| select NULL::int from tab1 | 有效的语法 |
| select 1 + NULL::int from tab1 | 有效的语法 |
| select 1 + NULL::int from tab2 | 有效的语法 |
| select NULL::int + 1 from tab1 | 有效的语法 |
GBase 8s 禁止重新定义 NULL,因为允许这样定义会限制 NULL 关键字的全局作用域。为此,任何限制全局作用域或重新定义关键字 NULL 的作用域的机制都会在语法上禁用涉及 NULL 值的任何强制转型表达式。您必须确保关键字 NULL 的发生在所有表达式上下文中收到它的全局作用域。
例如,请考虑下列 SQL 代码:
CREATE TABLE newtable
(
null int
);
SELECT null, null::int FROM newtable;
CREATE TABLE 语句是有效的,因为列标识符具有限定到表定义的引用的作用域;仅可在表的作用域内访问它们。
然而,在该示例中的 SELECT 语句引起一些语法的多义性。出现在 projection 列表中的标识符 null 引用全局的关键字 NULL 吗?它引用在 CREATE TABLE 语句中声明了的列标识符 null 吗?
- 如果将标识符 null 解释作为列名称,则带有 NULL 关键字的强制转型表达式的全局作用域将会受限。
- 如果将标识符 null 解释作为 NULL 关键字,则 SELECT 语句必须为 null 的发生生成语法错误,因为 NULL 关键字仅可作为强制转型表达式出现在 projection 列表中。
下列形式的 SELECT 语句是有效的,因为以表名称限定 newtable 的 NULL 列:
SELECT newtable.null, null::int FROM newtable;
在有名为 null 的变量的 SPL 例程的上下文中,会出现更多语法的多义性。示例如下:
CREATE FUNCTION nulltest() RETURNING INT;
DEFINE a INT;
DEFINE null INT;
DEFINE b INT;
LET a = 5;
LET null = 7;
LET b = null;
RETURN b;
END FUNCTION;
EXECUTE FUNCTION nulltest();
当在 DB-Access 中执行前面的函数时,在 LET 语句的表达式中,创建标识符 null 作为关键字 NULL。该函数返回 NULL 值,而不是 7。
使用 null 作为 SPL 例程的变量会限制在 SPL 例程体中对 NULL 值的使用。因此,前面的 SPL 代码是无效的,并导致 GBase 8s 返回下列错误:
-947 Declaration of an SPL variable named 'null' conflicts with SQL NULL value.
在 ESQL/C 中,如果有 SELECT 语句会返回 NULL 值的可能性,则您应使用指示符变量。
函数表达式
函数表达式可从内建的 SQL 函数或从用户定义的函数返回一个或多个值,如下图所示。
函数表达式
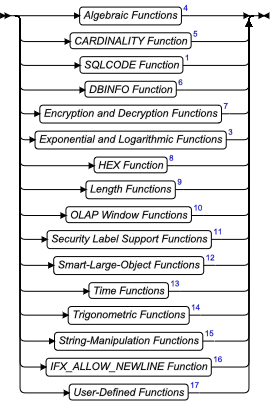
下列示例展示函数表达式:
EXTEND (call_dtime, YEAR TO SECOND)
HEX (LENGTH(123))
MDY (12, 7, 1900 + cur_yr)
TAN (radians)
DATE (365/2)
ABS (-32)
LENGTH ('abc') + LENGTH (pvar)
EXP (3)
HEX (customer_num)
MOD (10,3)
代数函数
代数函数采用一个或多个数值数据类型的参数。除了支持的数值参数之外,CEIL 和 FLOOR 函数还可采用可转换为 DECIMAL 值的字符串参数,且 ROUND 和 TRUNC 函数还可采用 DATE 或 DATETIME 参数。
代数函数
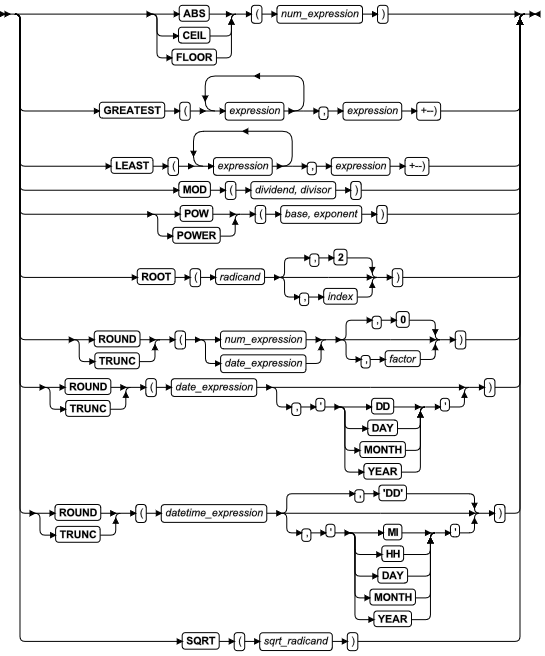
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| base | 要升至 exponent 中指定的幂的值 | 必须返回实数值 | 表达式 |
| date_expression | 求值为(或强制转型为)DATE 值的表达式 | 必须返回 DATE 值 | 表达式 |
| datetime_expression | 求值为(或强制转型为)DATETIME 值的表达式 | 必须返回 DATETIME 值 | 表达式 |
| dividend | 要被 divisor 除的值 | 实数值 | 表达式 |
| divisor | 用来除 dividend 的值 | 非零的实数值 | 表达式 |
| exponent | base 要升到的幂 | 实数值 | 表达式 |
| factor | 在返回的值中以零替换的有效数字位数。默认值为四舍五入的或截断的第一个参数的整数部分。 | 取值范围为 +32 至 -32 的整数。正值或无符号值适用于小数点的右边,负值适用于左边。 | 精确数值 |
| index | 要抽取的根。缺省值为 2。 | 非零的实数值 | 表达式 |
| num_expression | 求值为(或强制转型为)数值值的表达式 | 实数值 | 表达式 |
| radicand | 要返回其根的值 | 实数值 | 表达式 |
| sqrt_radicand | 带有实平方根的数值 | 非负的实数值 | 表达式 |
ABS 函数
ABS 函数返回它的数值参数的绝对值,返回的数据类型与它的参数相同。下列示例中的查询返回所有以现金(+)或作为商店信用卡(-)支付了的 ship_charge 大于 $20 的所有订单。
SELECT order_num, customer_num, ship_charge
FROM orders WHERE ABS(ship_charge) > 20;
CEIL 函数
CEIL 函数将数值表达式,或可转换为 DECIMAL 数据类型的字符串作为它的参数,并返回大于或等于它的单个参数的最小整数的 DECIMAL(32) 表示。
下列查询返回 33 作为大于或等于 CEIL 参数 32.3 的最小整数:
SELECT CEIL(32.3) FROM systables WHERE tabid = 1;
下一示例返回 -32 作为大于或等于 CEIL 参数 -32.3 的最小整数:
SELECT CEIL(-32.3) FROM systables WHERE tabid = 1;
CEILING函数
CEILING 函数返回大于等于 n 的最小整数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 需要求值的数值 | 可以为任意数值类型。 | 表达式 |
例如,返回大于 1.5 的最小整数值:
select ceiling(1.5) from dual;
(expression)|
------------+
2|
FLOOR 函数
FLOOR 函数将数值表达式,或可转换为 DECIMAL 数据类型的字符串作为它的参数,并返回小于或等于它的单个参数的最大整数的 DECIMAL(32) 表示。
下列查询返回 32 作为小于或等于 FLOOR 参数 32.3 的最大整数:
SELECT FLOOR(32.3) FROM systables WHERE tabid = 1;
下一示例返回 -33 作为小于或等于 FLOOR 参数 -32.3 的最大整数:
SELECT FLOOR(-32.3) FROM systables WHERE tabid = 1;
这些示例说明当 FLOOR 和 CEIL 函数有非零小数部分的相同参数时,它们如何提供差值为 1 的上界和下界。对于整数参数,FLOOR 和 CEIL 返回与它们参数相同的 DECIMAL(32) 表示。
GREATEST 函数
GREATEST 函数返回表达式的列表中的最大值。
此函数的参数必须是求值为相兼容的数据类型的以逗号分隔的表达式。
这是 GREATEST 函数的语法:
GREATEST 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 可比较其值的表达式 | 数据类型不可为集合或大对象。 | 表达式 |
这些参数必须是相兼容的数据类型。不支持复合的数据类型,或 BYTE、TEXT、BLOB、CLOB 对象,或基于任何这些数据类型的 DISTINCT 类型的参数。您指定作为 GREATEST 函数的参数的任何用户定义的数据类型必须执行 greaterthan( ) 函数。
如果必要,数据库服务器将指定的 expression 参数转换为返回的值的数据类型。由 expression 的所有运算对象确定此返回数据类型,可兼容性规则与 CASE 表达式一致。
GREATEST 函数的返回值是它的最大参数值。如果一个或多个参数求值为 NULL,则结果为 NULL。如果 GREATEST 是用于比较 DATE 或 DATETIME 值,则返回值是最近的日期。
假设表 T1 包含三列 C1、C2 和 C3,其值为 1、7 和 4。下列查询返回值 7:
SELECT GREATEST (C1, C2, C3) FROM T1;
然而,如果列 C3 有 NULL 值,而不是 4,则同一查询返回 NULL 值。
GREAT函数
GREAT 函数返回char1和char2中最大的值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1、char2 | 需要比较大小的字符或者数值 | 支持字符数据类型、数值数据类型或者可以隐式转换为字符数据类型、数值数据类型的其他数据类型。 | 表达式 |
例如,比较gbase和hello的大小:
select great('gbase','hello') from dual;
(EXPRESSION) hello
1 row(s) retrieved.
例如,比较2+3和2*3的大小:
select great(2+3,2*3) from dual;
(EXPRESSION)
6.000000000000
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
- 返回类型由第一个参数的数据类型决定;如果为数值,返回float类型,如果为字符串,返回lvarchar类型。
- 参数为字符类型时,先比较第一个字符的大小,返回第一个字符大的char,当第一个字符一样大时,往后比较,以此类推。
- 参数char1和char2,一个是空串或空格串,一个为字符串,则返回字符串。
- 参数char1或char2超过lvarchar边界时,做截断处理后返回计算结果。
- 参数char1和char2,char1是空串或空格串,char2为数值,则返回数值。
- 参数char1和char2,char2是空串或空格串,char1为数值,则返回空。
LEAST 函数
LEAST 函数返回一组值中的最小值。
LEAST 函数

参数必须是相兼容的,且每一参数都必须是表达式,表达式的返回值的数据类型不可为复合的类型、BYTES、TEXT、BLOB、CLOB,或基于任何这些类型的用户定义的类型。用户定义的类型必须实现对函数 lessthan() 的支持,以便使用 LEAST 函数。如有必要,将选择的参数转换为结果的数据类型。由所有的运算对象确定结果数据类型,且可兼容性规则与 CASE 表达式保持一致。
该函数的结果是最小的参数值。如果一个或多个参数求值为 NULL,则结果为 NULL。如果 LEAST 用于比较日期,则返回值是最早的日期。
假设表 T1 包含三列 C1、C2 和 C3,取值为 1、7 和 4。查询返回值 1。
SELECT LEAST (C1, C2, C3) FROM T1
如果列 C3 有值 NULL 而不是 4,则同一查询返回 NULL 值。
MOD 函数
MOD 函数以两个实数值运算对象作为参数,并返回第一个参数(被除数)的整数部分除以第二个参数(除数)的整数部分的整数商的余数。返回的值为 INT 数据类型(或对于 INT 范围之外的余数,为 INT8)。丢弃商和余数的任何小数部分。除数 不可为 0。因此,MOD (x,y) 返回 y (modulo x)。请确保收到该结果的任何变量都是可存储返回的值的数据类型。
此示例测试的是当前日期是否在 30 天记账周期之内:
SELECT MOD(TODAY - MDY(1,1,YEAR(TODAY)),30) FROM orders;
POW 函数
POW 函数求得它的第一个数值参数 base 的第二个数据值参数 exponent 的幂。返回的值是 FLOAT 数据类型。
下列示例从 circles 表返回所有行,其中 radius 列值表示小于 1,000 平方单位的面积,使用范围为 4 的 pi 的近似值:
SELECT * FROM circles WHERE (3.1416 * POW(radius,2)) < 1000;
函数标识符 POWER® 是 POW 的同义词。
要使用自然对数的基数 e,请参阅 EXP 函数。
PI函数
PI函数返回常数圆周率π的值。
![]()
例如,查询使用 PI 函数:
select pi() from dual;
(constant) |
-----------------+
3.141592653589793|
ROOT 函数
ROOT 函数从它的第一个数值表达式参数 radicand 抽取正实数根值,返回为 FLOAT 数据类型。
如果您指定第二个数值参数作为 index(不可为零),则返回值的 index 幂等于(在四舍五入误差范围内)radicand 参数。如果仅提供 radicand 参数,则 2 是缺省的 index 值。您不可指定零作为 index 的值。
在下列示例中的第一个 SELECT 语句,使用缺省的 index 值 2,返回文字数值 9 的正平方根。第二个示例返回文字数值 64 的立方根。
SELECT ROOT(9) FROM angles; -- 9 的平方根
SELECT ROOT(64,3) FROM angles; -- 64 的立方根
调用仅带有单个参数的 ROOT 等同于调用 SQRT 函数。
RAND函数
RAND 函数返回一个 0 到 1 之间的随机浮点数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 生成随机数的种子 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。N省略时,系统自动生成随机数种子。 | 表达式 |
例如,生成种子为1 的随机浮点数 :
select rand(1) from dual;
(EXPRESSION)
0.055837056636
1 row(s) retrieved.
说明及限制:
- 参数为NULL时,返回结果为NULL。
SQRT 函数
SQRT 函数返回它的参数的正值平方根,该参数必须为非负的数值表达式。
下列示例为 angles 表的每一行返回 9 的平方根:
SELECT SQRT(9) FROM angles;
SQRT 函数等同于 ROOT(x),ROOT 函数的第二个参数的缺省值 2 指定该指数。
ROUND 函数
ROUND 函数可降低它的第一个数值、MONEY、DATE 或 DATETIME 参数的精度,并返回四舍五入了的值。如果第一个参数不是数值、MONEY 值或时间点,则必须将它强制转型为数值的、MONEY、DATE 或 DATETIME 数据类型。
下图展示 ROUND 和 TRUNC 代数函数的语法,它们支持相同的语法。然而,由于它们的语义不同,它们可从相同的参数列表返回不同的值。 仅 ROUND 可返回大于它的第一个参数的绝对值。
ROUND 和 TRUNC 代数函数
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date_expression | 求值为(或强制转型为)DATE 值的表达式 | 必须返回 DATE 值 | 表达式 |
| datetime_expression | 求值为(或强制转型为)DATETIME 值的表达式 | 必须返回 DATETIME 值 | 表达式 |
| factor | 在返回的值中以零替代的有效数字的数目。缺省的是返回四舍五入的或截断的第一个参数的整数部分。 | 取值范围为 +32 至 -32 的整数。正值或无符号值适用于小数点的右边,而负值适用于左边。 | 精确数值 |
| num_expression | 求值为(或强制转型为)数值值的表达式 | 实数 | 表达式 |
用法
ROUND 函数与 TRUNC 函数相似,其语法如上所示。然而,ROUND 的不同之处在于它如何处理精度之内小于最小有效数字或时间单位的它的第一个参数的任何部分,它的显式的或缺省的第二个参数指定该精度。
- 如果此部分的绝对值等于或大于该精度内最小单位的一半,则那个数字或时间单位的值为由 ROUND 返回的值中增加 1。然而,如果这部分小于一个单位的一半,则丢弃它,仅返回指定的或缺省的精度之内第一个参数的数值或时间单位。
也就是说,如果第一个参数大于零,则
- ROUND 函数舍去在第二个参数的精度之内小于最小有效数字或时间的一半单位的它的第一个参数的任何部分,
- 但向上舍入等于或大于半个单位的第一个参数的任何部分。
例如,ROUND(3.5,0) = 4 且 ROUND(3.4,0) = 3。
但如果第一个参数小于零,则
- ROUND 函数向上舍入在第二个参数的精度之内的小于最小有效数字或时间单位的半个单位的它的第一个参数的任何部分,
- 但舍去等于或大于半个单位的第一个参数的任何部分。
例如,ROUND(-3.5,0) = -4 而 ROUND(-3.4,0) = -3。
- 相反地,TRUNC 函数以零替代数值表达式的小于指定精度的任何数值。对于 DATE 或 DATETIME 表达式,TRUNC 替换小于指定格式字符串的任何时间单位,以 1 替换 month 或 day 时间单位,或以零替换小于 day 的时间单位。
ROUND 函数可接受可选的第二个参数,其指定返回的值的精度。第二个参数的语法和语义依赖于第一个字符是否为数值表达式、DATETIME 表达式或 DATE 表达式。
对数值和 MONEY 值的四舍五入
- 当第一个参数是数值表达式时,返回的值是 DECIMAL,且第二个参数可为取值范围从 -32 至 +32 (包含 -32 和 +32)的整数,指定返回的值的最后有效数字(相对于小数点)的位置。当第一个参数是数值时,如果您省略 factor 规范,则 ROUND 返回舍入到个位或单位位置的第一个参数的整数值。
正的数字值指定舍入到小数点的右边;负的数值值指定舍入到小数点的左边,如 图 1 所示:
图: 负的、零和正的舍入因子的示例

下列示例使用带有列表达式作为它的第一个参数且没有第二个参数的 ROUND 函数,因此,数值表达式被舍入到范围零。此查询返回订单号和其总价(四舍五入到缺省的个位)等于 $124.00 的项的四舍五入的总价。
SELECT order_num , ROUND(total_price) FROM items
WHERE ROUND(total_price) = 124.00;
如果您使用 MONEY 数据类型作为 ROUND 函数的参数,且四舍五入到显式的或缺省的个位,则返回的值以 .00 表示小数部分。下列示例中的 SELECT 语句四舍五入 125.46 和 MONEY 列值。该查询返回 125 和 items 表中每一行的 xxx.00 形式的四舍五入的价格。
SELECT ROUND(125.46), ROUND(total_price) FROM items;
DATE 和 DATETIME 值的四舍五入
- 当 ROUND 的第一个参数为 DATETIME 表达式时,返回的值是 DATETIME YEAR TO MINUTE 数据类型,且第二个参数必须为在返回的值中指定最小有效时间单位的引用的字符串。如果您省略第二个参数,则缺省的格式字符串为 'DD',以四舍五入到 00:00 的小时和分钟指定最近的一天。下列格式字符串作为第二个参数是有效的:
表 1. ROUND 函数的 DATETIME 参数的格式字符串
| 格式字符串 | 对返回的 DATETIME 值的影响 |
|---|---|
| 'YEAR' | 舍入到最近一年之初,以六月 30 日之后的日期舍入到下一年。month、day、hour 和 minute 值舍入为 -01-01 00:00。 |
| 'MONTH' | 舍入到最近一月之初。将 15 日以后的日期舍入到下一月。day、hour 和 minute 值舍入为 01 00:00。 |
| 'DD' | 舍入到最近一天之初(00:00 = midnight)。将中午 12:00 之后的 DATETIME 舍入到下一天。 |
| 'DAY' | 舍入到最近的星期天之初。周三、周四、周五或周六的日期舍入到下一星期天。 |
| 'HH' | 舍入到最近一小时之初。以 minute:second 晚于 29:59 的时间值舍入到下一小时。分钟舍入为零。 |
| 'MI' | 舍入到最近一分钟之初。以 second 晚于 30 的时间值舍入到下一分钟。 |
如果您在初始的 DATETIME 表达式参数之后省略格式字符串规范,则返回的值是将第一个参数舍入到最近一天的值,就如同您已指定了 'DD' 作为格式字符串。
下列示例在 SELECT 语句中使用带有返回 DATETIME YEAR TO FRACTION(5) 值的列表达式的 ROUND 函数。在这些查询中,表 mytab 仅有单个行,且在那行中,mytab.col_dt 的值是 2012-12-07 14:30:12.12300。
下列查询指定 'YEAR' 作为 DATETIME 格式字符串:
SELECT ROUND(col_dt, 'YEAR') FROM mytab;
返回的值为 2013-01-01 00:00。
下一查询与前面的查询相似,但将返回的值强制转型为 DATE 数据类型:
SELECT ROUND(col_dt, 'YEAR')::DATE FROM mytab;
返回的值为 01/01/2013。
此示例指定 'MONTH' 作为 DATETIME 格式字符串:
SELECT ROUND(col_dt, 'MONTH') FROM mytab;
返回的值为 2012-12-01 00:00。
此示例将 DATETIME 表达式舍入到 YEAR TO HOUR 精度:
SELECT ROUND(col_dt, 'HH') FROM mytab;
返回的值为 2012-12-07 15:00。
- 如果第二个参数是在返回的值中指定最小时间单位的引用字符串,则当第一个参数为 DATE 表达式时,返回的值也是 DATE 数据类型。这些是与舍入 DATETIME 值相同的格式字符串,除了 'HH' 和 'MI' 不是有效的 DATE 值之外。对于舍入 DATE 参数,没有缺省的格式字符串。
要返回格式化的 DATE 值,您必须指定下列引用字符串之一作为 ROUND 函数的第二个参数:
表 2. ROUND 函数的 DATE 参数的格式字符串
| 格式字符串 | 对返回的 DATE 值的影响 |
|---|---|
| 'YEAR' | 四舍五入到最近一年之初。一月 30 日之后的日期舍入到下一年。month 和 day 值均舍入为 01。 |
| 'MONTH' | 四舍五入到最近一月之初。15 日之后的日期舍入到下一月。返回的 day 值为 01。 |
| 'DD' | 返回第一个 date_expression 参数的 DATE 值。 |
| 'DAY' | 将该值舍入到最近的星期天。如果第一个参数为星期天,则返回那个日期。周三、周四、周五和周六的日期舍入到下一星期天。 |
当第一个参数为 DATE 数据类型时,如果您未指定格式字符串作为第二个参数,则缺省情况下没有格式字符串生效。不发出错误,但将第一个参数作为求值为整数的数值表达式来处理,而不作为 DATE 值。 GBase 8s 在内部将 DATE 值存储为从 1899 年 12 月 31 日以来的整数计数。对于 21 世纪中的日期,等同于 DATE 值的整数是 5 位整数,取值范围大约在 37,000 与 74,000 之间。
例如,查询 SELECT ROUND(TODAY) FROM systables 不为 DATE 表达式提供格式字符串,且如果在 2012 年 4 月 1 日发出该查询,则返回整数 40999。
如果您应用数值格式规范作为第二个参数,则非负的数值对 DATE 值不起作用,但下列示例将返回值的最后两个数字舍入为零:
SELECT ROUND(TODAY, -2) FROM systables;
在 2012 年 4 月 1 日,上述查询会返回整数值 40900。
在下一天,2012 年 4 月 2 日,同一查询会返回整数值 41000。
对于像 41000 这样的整数格式日期是有用的应用,您可使用 'YEAR'、'MONTH'、'DAY' 或 'DD' 格式字符串作为 ROUND 函数的第二个参数来防止将 DATE 参数处理成 一个数值表达式。在 2012 年 4 月 1 日,下列查询返回 DATE 值 04/01/2012,如果 MDY4/ 是 DBDATE 环境变量设置的话:
SELECT ROUND(TODAY, 'DD') FROM systables WHERE tabid = 1;
在下列示例中,在 2012 年 4 月 3 日(星期二)发出一查询:
SELECT ROUND(TODAY, 'DAY') FROM mytab;
返回的值为 03/31/2012,当前的日期四舍五入到最近的星期天。
如果您正在使用主变量来在动态的 SQL 中存储四舍五入了的时间点值,且在准备时刻不知道第一个参数的数据类型,则 GBase 8s 假设 ROUND 函数的第一个参数是 DATETIME 数据类型,并返回 DATETIME YEAR TO MINUTE 四舍五入的值。在执行时刻,则准备该语句之后,如果为该主变量提供 DATE 值,则发出错误 -9750。要防止发生此错误,您可通过使用强制转型为主变量指定数据类型,如此程序片断中所示。
sprintf(query1, ",
"select round( ?::date, 'DAY') from mytab");
EXEC SQL prepare selectq from :query;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor using :hostvar_date_input;
EXEC SQL fetch select_cursor into :var_date_output;
要了解可为内建的按时间顺序排列的数据类型指定显示和数据条目格式的 GBase 8s 环境变量之中的优先顺序,请参阅主题 DATE 和 DATETIME 格式规范的优先顺序。
TRUNC 函数
通过返回截断的值,TRUNC 函数可降低它的第一个数值的、DATE 或 DATETIME 参数的精度。如果第一个参数既不是数值也不是时间点,则必须将它强制转型为数值、DATE 或 DATETIME 数据类型。
通过返回截断的值,TRUNC 函数可降低它的第一个数值的、DATE 或 DATETIME 参数的精度。如果第一个参数既不是数值也不是时间点,则必须将它强制转型为数值、DATE 或 DATETIME 数据类型。
TRUNC 函数与 ROUND 函数相似,但它截断(而不是舍入到最近的整数)第一个参数中小于它的第二个参数指定的精度之内的最小有效数字或时间单位的任何部分。
- 对于数值表达式,TRUNC 以零替换小于指定精度的任何数字。
- 对于 DATE 或 DATETIME 表达式,TRUNC 替换小于格式规范的任何时间单位,以 1 替换 month 或 day 时间单位,或以 0 替换小于 day 的时间单位。
TRUNC 函数可接受指定返回的值的精度的可选的第二个参数。
- 当第一个参数为数值的表达式时,第二个参数必须为取值范围从 -32 至 +32(包含-32 和 +32)的整数,指定返回的值的最后有效数字(相对于小数点)的位置。当第一个参数为数值时,如果您省略 factor 规范,则 TRUNC 返回截断到个位或单位位置的第一个参数的值。
正的数字值指定截断到小数点的右边;负的数字值指定截断到左边,如下图所示。
图: 负的、零和正的截断因子的示例

下列示例在 SELECT 语句中以返回数值值的列表达式调用 TRUNC 函数。此语句显示订单号以及其总价(截断到缺省的个位小数位置)等于 $124.00 的项的被截断的总价。
SELECT order_num , TRUNC(total_price) FROM items
WHERE TRUNC(total_price) = 124.00;
如果在一个指定个位的 TRUNC 函数调用中,如果 MONEY 数据类型是参数,则在返回的值中小数部分成为 .00。例如,下列 SELECT 语句截断 125.46 和 MONEY 列值。它为 items 表中的每一行返回 125 以及形如 xxx.00 的截断的价格。
SELECT TRUNC(125.46), TRUNC(total_price) FROM items;
- 当 TRUNC 的第一个参数为 DATETIME 表达式时,第二个参数必须为指定返回值中最小有效时间单位的引用的字符串。仅下列格式的字符串是有效的第二个参数:
表 1. TRUNC 函数的 DATETIME 参数的格式字符串
| 格式字符串 | 对返回的值的影响 |
|---|---|
| 'YEAR' | 截断到年初。month、day、hour 和 minute 值截断到 01-01 00:00。 |
| 'MONTH' | 截断到该月的第一天之初。hour 和 minute 值截断到 00:00。 |
| 'DD' | 阶段到同一天之初(00:00 = 午夜)。 |
| 'DAY' | 如果第一个参数是星期天,则返回那天的午夜(00:00)。对于该星期的任何其他天,返回前一个星期天的午夜。 |
| 'HH' | 截断到该小时之初。minute 值截断为零。 |
| 'MI' | 截断到最近的分钟之初。对于所有这些格式字符串,丢弃小于 minute 的时间单位。 |
如果您在初始的 DATETIME 表达式参数之后省略格式字符串规范,则返回的值是将第一个参数截断到天的值,就如同您指定了 'DD' 作为格式字符串一样。
下列示例在 SELECT 语句中以返回 DATETIME YEAR TO FRACTION(5) 值的列表达式调用 TRUNC 函数。在这些示例中,表 mytab 仅有单个行,且在那行中 mytab.col_dt 的值是 2006-12-07 14:30:12.12300。
此查询指定 'YEAR' 作为 DATETIME 格式字符串:
SELECT TRUNC(col_dt, 'YEAR') FROM mytab;
返回的值为 2006-01-01 00:00。
下一查询与前一查询相似,但将截断的值强制转型为 DATE 数据类型:
SELECT TRUNC(col_dt, 'YEAR')::DATE FROM mytab;
返回的值为 01/01/2006。
此示例指定 'MONTH' 作为 DATETIME 格式字符串:
SELECT TRUNC(col_dt, 'MONTH') FROM mytab;
返回的值为 2006-12-01 00:00。
下列示例将 DATETIME 表达式截断到 YEAR TO HOUR 精度:
SELECT TRUNC(col_dt, 'HH') FROM mytab;
返回的值为 2006-12-07 14:00。
- 当第一个参数为 DATE 表达式时,第二个参数通常应为指定返回的值中最小时间单位的引用的字符串。 除了 'HH' 和 'MI' 不是有效的日期之外,这些是与截断 DATETIME 值相同的格式字符串,且对于截断 DATAE 表达式参数,没有缺省的格式字符串。
要返回格式化的 DATE 值,您必须使用下列引用的字符串之一作为 TRUNC 函数的第二个参数:
表 2. TRUNC 函数的 DATE 参数的格式字符串
| 格式字符串 | 代表含义 |
|---|---|
| CC、SCC | 比4位数年份的前两位大1 |
| SYYYY、YYYY、YEAR、SYEAR、YYY、YY、Y | 截断到该年之初。month 和 day 值都为 01。 |
| IYYY、IY、I | 包含日历周的年份,有iso 8601标准定义 |
| Q | 季度(在季度的第二个月的第十六天四舍五入) |
| MONTH、MON、MM、RM | 截断到该月之初。day 值为 01。 |
| WW | 与一年的第一天相同的一天 |
| IW | 与iso 860标准定义的日历周的第一天相同的一天,即星期一 |
| W | 一周的第一天与一个月的第一天相同的一天 |
| DDD、DD、J | 日 |
| DAY、DY、D | 本周开始的第一天 |
| HH、HH12、HH24 | 小时 |
| MI | 分钟 |
当第一个元素为 DATE 数据类型时,如果您未指定格式字符串作为第二个参数,则没有格式字符串作为缺省值生效。不发出错误,但将第一个参数作为求值为整数的数值表达式处理,而不是作为 DATE 值。 GBase 8s 将 DATE 值作为自从 1899 年 12 月 31 日以来的整数天数在内部存储。
例如,查询 SELECT ROUND(TODAY) FROM systables 未为 DATE 表达式提供格式字符串,如果在 2008 年 4 月 1 日提交该查询,则返回整数 39538。
如果您应用数值的格式规范作为第二个参数,则非负的数值对 DATE 值不起作用,但下列示例将返回的值的最后两位数值舍入为零:
SELECT TRUNC(TODAY, -2) FROM systables;
对于类似于 39500 这样的整数日期不适用的应用,请使用 'YEAR'、'MONTH'、'DAY' 或 'DD' 格式字符串作为 TRUNC 函数的第二个参数,来防止将 DATE 表达式作为数值表达式来处理。在 2008 年 4 月 1 日,如果 MDY4/ 是 DBDATE 环境变量的设置,下列查询返回 DATE 值 04/01/2008:
SELECT TRUNC(TODAY, 'DD') FROM systables;
如果您正在使用主变量来在动态的 SQL 中存储截断的时间点值,且在准备时刻不知道第一个参数的数据类型,则 GBase 8s 假设 DATETIME 数据类型是 TRUNC 函数的第一个参数,并返回 DATETIME YEAR TO MINUTE 截断的值。在执行时刻,在准备该语句之后,如果为主变量提供 DATE 值,则发出错误 -9750。要防止发生此错误,您可通过使用强制转型为主变量指定数据类型,如此程序片断中所示:
sprintf(query2, "%s",
"select trunc( ?::date, 'DAY') from mytab");
EXEC SQL prepare selectq from :query2;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor using :hostvar_date_input;
EXEC SQL fetch select_cursor into :var_date_output;
要了解 GBase 8s 环境变量之中的优先顺序,这些环境变量可为内建的按时间排序的数据类型指定显示和数据条目格式,请参阅主题 DATE 和 DATETIME 格式规范的优先顺序.
TRUNC 函数名称是基于英文单词 "truncate",这与在 SQL 的 TRUNCATE 语句中它的含义不同。TRUNC 以另一个更小精度或相同精度的值替代它的第一个参数的值。TRUNCATE 语句从数据库表删除所有行,而不删除表模式。
TRUNCATE函数
TRUNCATE函数返回截取后的值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 需要进行截断的数值 | 支持数值类型或者可以隐式转换成数值类型的其他数据类型。 | 表达式 |
| m | 需要截取的位数 | 支持数值类型或者可以隐式转换成数值类型的其他数据类型。m为负数时,指定截断到小数点左边,m为正数时,指定截断到小数点右边。缺省为0。m为小数时,进行取整。 | 表达式 |
例如,求1234.1234截断两位小数后的结果 :
select truncate(1234.234,2) from dual;
(expression) 1234.23
1 row(s) retrieved.
说明及限制:
- 参数n为NULL或空串时,返回NULL。
- 参数n为数值,m为正数且超过n的小数位数时,返回结果小数位会补0到m位 。
CARDINALITY 函数
CARDINALITY 函数返回集合列(SET、MULTISET、LIST)中元素的数目。
CARDINALITY 函数有下列语法。
CARDINALITY 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| collection_col | 现有的集合列 | 必须声明为集合数据类型 | 标识符 |
| collection_var | 主或程序集合变量 | 必须声明为集合数据类型 | 特定于语言 |
假设 set_col SET 列包含下列值:
{3, 7, 9, 16, 0}
下列 SELECT 语句返回 5 作为 set_col 列中元素的数目:
SELECT CARDINALITY(set_col) FROM table1;
如果集合包含重复的元素,CARDINALITY 为每一个别的元素计数。
SQLCODE 函数(SPL)
SQLCODE 函数不用参数,但将当前 SPL 例程已执行了的最近执行的(不论静态的还是动态的)SQL 语句的 sqlca.sqlcode 值返回到它的调用上下文。仅在游标的上下文中使用 SQLCODE。
SQLCODE
![]()
您可在 SPL 例程内的表达式中使用 SQLCODE 来标识动态游标的状态。在错误处理中以及在诸如确定查询或函数调用是否尚未返回行的上下文中,或当游标已达到了活动集的最后行时,或当 SPL 程序控制应从循环中退出时要标识其他条件,此内建的函数是有用的。
下列 SPL 程序片断说明使用 SQLCODE 来检测 WHILE 循环内游标的活动集的末尾。
CREATE PROCEDURE ...
...
DEFINE myc1 ...
...
PREPARE p FOR "SELECT c1 FROM t1";
DECLARE cur FROM s;
OPEN cur;
FETCH cur INTO myc1;
WHILE (SQLCODE != 100)
FETCH cur INTO myc1;
-- process myc1
...
END WHILE;
END PROCEDURE;
在以 ESQL/C 编写的 UDR 中不需要 SQLCODE,其通过“动态的 SQL”的 GET DIAGNOSTICS 语句以及有其他机制直接访问“SQL 通信区域”(SQLCA)。如果内建的 SQLCODE 函数的调用上下文不在 SPL 例程中,则数据库服务器发出错误。
DBINFO 函数
下图展示 DBINFO 函数的语法。
DBINFO 函数
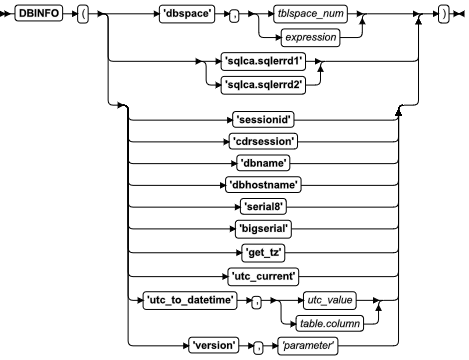
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| column | table 中的列名称 | 在 table 中必须存在 | 标识符 |
| expression | 求值为 tblspace_num 的表达式 | 可包含列名称、SPL 变量、主变量或子查询,但必须返回数值值 | 表达式 |
| parameter | 指定返回 version 字符串的哪一部分的引用的字符串 | 要了解有效的 parameter 值,请参阅 使用 'version' 选项 | 请参阅限制栏。 |
| table | 要显示 dbspace 名称或包含 UTC 值的整数 column 列的表。 | 必须与查询的 FROM 子句中表的名称相匹配 | 标识符 |
| tblspace_num | 表的 tblspace 号(分区号) | 在数据库的 systables 表的 partnum 列中必须存在 | 精确数值 |
| utc_value | 要转换为 DATETIME 等价的 UTC 值 | 必须为数值表达式,求值为从 1970-01-01 00:00:00+00:00 以来的秒数 | 表达式, 精确数值 |
DBINFO 选项
DBINFO 函数实际上是返回关于数据库的不同类型信息的函数集。要调用每一函数,请在 DBINFO 关键字之后指定特定的选项。您可在 SQL 语句之内和 UDR 之内的任何地方使用任何 DBINFO 选项。
下表展示数据库的类别以及 GBase 8s 可通过有效的 DBINFO 选项检索的数据库服务器信息。
- 参数栏展示以圆括号限定的每一有效的 DBINFO 选项的参数列表。
- 返回的信息栏展示参数选项检索的数据库信息的类型。
- 页栏展示您可找到关于参数选项的更多信息的位置。
| 参数 | 返回的信息 | 页 |
|---|---|---|
| ('dbhostname') | 客户端应用连接到的数据库服务器的主机名称 | 使用 'dbhostname' 选项 |
| ('dbname') | 客户端应用连接到的数据库的标识符 | 使用 'dbname' 选项 |
| ('dbspace' tblspace_num) | 与 tblspace 编号相对应的 dbspace 的名称 | 使用 ('dbspace', tblspace_num) 选项 |
| ('get_tz') | 会话的时区,$TZ,如同通过客户端作为字符串指定的那样。 | 使用 'get_tz' 选项 |
| ('serial8') | 插入在表中的最后的 SERIAL8 值 | 使用 'serial8' 和 'bigserial' 选项 |
| ('bigserial') | 插入在表中的最后的 BIGSERIAL 值 | 使用 'serial8' 和 'bigserial' 选项 |
| ('sessionid') | 当前会话的会话 ID 编号 | 使用 'sessionid' 选项 |
| ('cdrsession') | 线程是否正在执行 Enterprise Replication 操作 | 使用 'cdrsession' 选项 |
| ('sqlca.sqlerrd1') | 插入在表中的最后的 SERIAL 值 | 使用 'sqlca.sqlerrd1' 选项 |
| ('sqlca.sqlerrd2') | 通过 SELECT、INSERT、DELETE、UPDATE、EXECUTE PROCEDURE 和 EXECUTE FUNCTION 语句处理的行的数目 | 使用 'sqlca.sqlerrd2' 选项 |
| ('utc_current') | 当开始执行 SQL 语句时,当前的 UTC 时间值(作为一个从 1970-01-01 00:00:00+00:00 以来的秒的整数值)。 | 使用 'utc_current' 选项 |
| ('utc_to_datetime', table.column) | 对应于包含 UTC 时间值(作为一个从 1970-01-01 00:00:00+00:00 以来的秒的整数值)的指定的整数列的 DATETIME 值。 | 使用 'utc_to_datetime' 选项 |
| ('utc_to_datetime', utc_value) | 对应于指定的 UTC 时间值(作为一个从 1970-01-01 00:00:00+00:00 以来的秒的整数值)的 DATETIME 值。 | 使用 'utc_to_datetime' 选项 |
| ('version', 'parameter') | 客户端应用连接到的数据库服务器的类型及其发行版本。(如果 parameter 没有为版本信息指定格式,则调用 DBINFO 失败并报错。) | 使用 'version' 选项 |
使用 ('dbspace', tblspace_num) 选项
'dbspace' 选项返回包含对应于 tblspace 编号的 dbspace 的名称的字符串。您必须提供附加的参数,或 tblspace_num,或求值为 tblspace_num 的表达式。下列示例使用 'dbspace' 选项。首先,它查询 systables 系统目录表来确定表客户的 tblspace_num,然后它执行该函数来确定 dbspace 名称。
SELECT tabname, partnum FROM systables
where tabname = 'customer';
如果查询返回一个分区编号 1048892,则您将那个值插入到第二个参数内来找到包含 customer 表的那个 dbspace,如下例所示:
SELECT DBINFO ('dbspace', 1048892) FROM systables
where tabname = 'customer';
如果您想要知道其 dbspace 名称的表是分片的,则你必须查询 sysfragments 系统目录表来找到每一表分片的 tblspace 编号。然后您必须在单独的 DBINFO 查询中提供每一 tblspace 编号来找到跨分片的表的所有 dbspace。
使用 'sqlca.sqlerrd1' 选项
'sqlca.sqlerrd1' 返回提供插入到表内的最后的 serial 值的单个整数。要确保有效的结果,请紧跟在将带有 serial 值的单个行插入到表内的单 SELECT 语句之后使用此选项。
要获取插入到表内的最后的 SERIAL8 值的值,请使用 DBINFO 的 'serial8' 选项。要获取更多信息,请参阅 使用 'serial8' 和 'bigserial' 选项。
下列示例使用 'sqlca.sqlerrd1' 选项:
EXEC SQL create table fst_tab (ordernum serial, partnum int);
EXEC SQL create table sec_tab (ordernum serial);
EXEC SQL insert into fst_tab VALUES (0,1);
EXEC SQL insert into fst_tab VALUES (0,4);
EXEC SQL insert into fst_tab VALUES (0,6);
EXEC SQL insert into sec_tab values (dbinfo('sqlca.sqlerrd1'));
此示例将包含主键 serial 值的一行插入到 fst_tab 表内,然后使用 DBINFO 函数来将同一 serial 值插入到 sec_tab 表内。DBINFO 函数返回的值是被插入到 fst_tab 内的最后一行的 serial 值。
由于 SQLCA 结构不记录通过触发器插入的 serial 值,因此您不可以 'sqlca.sqlerrd1'、'bigserial' 或 'serial8' 选项调用 DBINFO 函数来返回触发器的活动插入的 serial 值。
要获取更多关于“SQL 通信区域”(SQLCA)数据结构的信息(sqlca.sqlerrd1 在其内是一个字段),请参阅 GBase 8s SQL 教程指南。
使用 'sqlca.sqlerrd2' 选项
'sqlca.sqlerrd2' 选项返回提供 SELECT、INSERT、DELETE、UPDATE、EXECUTE PROCEDURE 和 EXECUTE FUNCTION 语句处理了的行的数目的单个整数。要确保有效的结果,请在 SELECT、EXECUTE PROCEDURE 和 EXECUTE FUNCTION 语句已执行完成之后使用此选项。此外,当您在游标内使用此选项时,要确保有效的结果,请确保在关闭游标之前取回所有行。
下列示例展示 SPL 例程,该例程使用 'sqlca.sqlerrd2' 选项来确定从表删除的行的数目:
CREATE FUNCTION del_rows (pnumb INT)
RETURNING INT;
DEFINE nrows INT;
DELETE FROM fst_tab WHERE part_number = pnumb;
LET nrows = DBINFO('sqlca.sqlerrd2');
RETURN nrows;
END FUNCTION;
要获取更多关于“SQL 通信区域”(SQLCA)数据结构的信息(sqlca.sqlerrd2 在其内是一个字段),请参阅 GBase 8s SQL 教程指南。
使用 'sessionid' 选项
DBINFO 函数的 'sessionid' 选项返回您的当前会话的会话 ID。当客户端应用连接到数据库服务器时,数据库服务器启动与客户端的会话,并为该客户端指定一会话 ID。该会话 ID 用作客户端与数据库服务器之间给定连接的唯一的标识符。
数据库服务器在称为会话控制块的共享内存中的数据结构中存储该会话 ID 的值。给定会话的会话控制块还包括用户 ID、客户端的进程 ID、主机计算机的名称和各种状态标志。
当您指定 'sessionid' 选项时,数据库服务器从会话控制块检索您的当前会话的会话 ID,并将此值作为整数返回给您。sysmaster 数据库中的某些“系统监视接口”(SMI)表包括会话 ID 的列,因此您可使用 DBINFO 函数获取了的会话 ID 来从这些 SMI 表抽取关于您自己的会话的信息。要获取关于会话控制块的更多信息,请参阅 GBase 8s 管理员指南。要获取关于 sysmaster 数据库和 SMI 表的更多信息,请参阅 GBase 8s 管理员参考手册。
在下列示例中,用户在 SELECT 语句中指定 DBINFO 函数来获取当前会话 ID 的值。用户产生针对 systables 系统目录表的查询,并使用 WHERE 子句来将查询结果限定为单个行。
SELECT DBINFO('sessionid') AS my_sessionid
FROM systables
WHERE tabname = 'systables';
在前面的示例中,SELECT 语句针对 systables 系统目录表查询。然而,您可通过针对任何系统目录表或数据库中的用户表进行查询,获取当前会话的会话 ID。 例如,您可输入下列查询来获取您的当前会话的会话 ID:
SELECT DBINFO('sessionid') AS user_sessionid
FROM customer
WHERE customer_num = 101;
您不仅可在 SQL 语句中使用 DBINFO 'sessionid' 选项,还可在 SPL 例程中使用。 下列示例展示返回当前会话 ID 的值的 SPL 函数来调用程序或例程:
CREATE FUNCTION get_sess()
RETURNING INT;
RETURN DBINFO('sessionid');
END FUNCTION;
使用 'cdrsession' 选项
DBINFO() 函数的 'cdrsession' 选项检测是否执行 INSERT、UPDATE 或 DELETE 语句作为复制的事务的一部分。
您可能想要升级触发器、存储过程或用户定义的例程来采取不同的活动,这依赖于是否执行事务作为 Enterprise Replication 的一部分。如果线程执行的数据库操作是 Enterprise Replication apply 或 sync 线程,则 DBINFO() 函数的 'cdrsession' 选项返回 1;否则,该函数返回 0。
下列示例展示使用 'cdrsession' 选项的 SPL 函数,来确定线程是否正在执行 Enterprise Replication 操作:
CREATE FUNCTION iscdr ()
RETURNING int;
DEFINE iscdrthread int;
SELECT DBINFO('cdrsession') into iscdrthread
from systables where tabid = 1;
RETURN iscdrthread;
END FUNCTION
使用 'dbname' 选项
您可使用 'dbname' 选项来检索当前数据库的名称。此选项返回客户端会话当前连接到的数据库的标识符。
在下列示例中,用户在 SELECT 语句中输入 DBINFO 的 'dbname' 选项来检索 DB-Access 连接到的数据库的名称:
SELECT DBINFO('dbname')
FROM systables
WHERE tabid = 1;
下表展示此查询的结果。
(constant)
stores_demo
使用 'dbhostname' 选项
您可使用 'dbhostname' 选项来检索数据库客户端连接到的数据库服务器的主机名称。
此选项检索数据库服务器正运行在其上的计算机的物理计算机名称。
在下列示例中,用户在 SELECT 语句中的 DBINFO 的 'dbhostname' 选项来检索 DB-Access 连接到的数据库服务器的主机名称:
SELECT DBINFO('dbhostname')
FROM systables
WHERE tabid = 1;
下列表格展示此查询的结果。
(constant)
rd_lab1
使用 'version' 选项
您可使用 DBINFO 函数的 'version' 选项来从消息日志检索关于针对客户端应用正在运行的数据库服务器的类型和发布版本的信息。
您必须在 'version' 选项之后包括 'parameter' 规范来表明您想要检索的版本字符串的哪一部分。
如果在 'version' 之后,您指定 'full' 作为 parameter 值,则 DBINFO 返回完整的版本字符串,其与 oninit 实用程序的 -V 选项显示的值相同。 下列表格罗列 DBINFO 的所有有效的 parameter 参数,其可检索关于数据库服务器的版本信息:
- 参数栏展示每一有效的 DBINFO ( 'version', 'parameter') 组合的以圆括号限定的参数列表。
- 返回的版本字符串的部分栏展示每一参数列表返回的版本字符串的哪一部分。
- 返回的值的示例栏展示 Arguments 选项的每一 parameter 值返回的示例。
每一示例返回完整的版本字符串 GBase 8s Version 11.50.UC6 的一部分。
| 参数 | 返回的版本字符串的部分 | 返回的值的示例 |
|---|---|---|
| ('version', 'server-type') | 数据库服务器的类型 | GBase 8s |
| ('version', 'major') | 当前数据库服务器版本的主要版本号 | 11 |
| ('version', 'minor') | 当前数据库服务器版本的次要版本号 | 50 |
| ('version', 'os') | 在版本字符串内的操作系统标识符: T = 32 位 Windows™ 平台 U = 运行在 32 位操作系统上的 UNIX™ 32 位 H = 运行在 64 位操作系统上的 UNIX 32 位 F = 所有 64 位平台 | U |
| ('version', 'level') | 当前数据库服务器版本的临时发布级别 | C6 |
| ('version', 'full') | 会由 oninit -V 返回的完整的版本字符串 | GBase 8s, Version 11.50.UC6 |
不是所有 UNIX 环境都适用前面的表格中操作系统(os)的字长描述。例如,某些 U 版本可运行在 64 位操作系统上。类似地,有些 F 版本可运行在支持 64 位应用的带有 32 位内核的操作系统上。
下列示例展示如何使用 SELECT 语句中的 DBINFO 的 'version' 选项来检索 DB-Access 客户端连接到的数据库服务器的主要版本号:
SELECT DBINFO('version', 'major')
FROM systables
WHERE tabid = 1;
下列表格展示此查询的结果:
(constant)
7
使用 'version_gbase' 选项
DBINFO ('version', parameter)用于返回客户端应用连接到的数据库服务器的确切版本的全部或一部分,本次在保留'version'选项的基础上,增加了'version_gbase'选项。DBINFO ('version_gbase ', parameter)中参数parameter支持:'server-type'、'major'、'minor'、'full'。
| 参数 | 返回的版本字符串的部分 | 返回的值的示例 |
|---|---|---|
| ('version_gbase ', server-type) | 产品名称 | 使用select dbinfo('version_gbase', 'server-type') from sysdual语句进行查询,返回结果格式为:产品名称,示例:GBase8s。 |
| ('version_gbase ', major) | 主要版本号 | 使用select dbinfo('version_gbase', 'major') from sysdual语句进行查询,返回结果格式为:主版本号,示例:V8.8。 |
| ('version_gbase ', minor) | 次要版本号 | 使用select dbinfo('version_gbase', 'minor') from sysdual语句进行查询,系统显示数据库版本号,返回结果格式为:版本级别+_+版本号+专用版本代号及版次+_+迭代序号(送测序号)+补充版本标识+_+6位哈希ID,示例:AEE_3.0.0G5_1P20200918_1fc8fc。 |
| ('version_gbase ', full) | 完整的版本字符串 | 使用select dbinfo('version_gbase', 'full') from sysdual语句进行查询,系统显示数据库版本号,返回结果格式为:产品名称+主版本号+_+版本级别+_+版本号+专用版本代号及版次+_+迭代序号(送测序号)+补充版本标识+_+6位哈希ID,示例:GBase8sV8.8_AEE_3.0.0G5_1P20200918_1fc8fc。 |
使用 'serial8' 和 'bigserial' 选项
'bigserial' 和 'serial8' 选项分别返回指定插入到了表内的最后的 SERIAL8 或 BIGSERIAL 值的单个整数。要确保有效的结果,请紧跟在插入 SERIAL8 或 BIGSERIAL 值的 INSERT 语句之后使用此选项。
要获取被插入到表内的最后 SERIAL 值的值,请使用 DBINFO( ) 的 'sqlca.sqlerrd1' 选项。要获取更多信息,请参阅 使用 'sqlca.sqlerrd1' 选项。
下列示例使用 'serial8' 选项:
EXEC SQL CREATE TABLE fst_tab
(ordernum SERIAL8, partnum INT);
EXEC SQL CREATE TABLE sec_tab (ordernum SERIAL8);
EXEC SQL INSERT INTO fst_tab VALUES (0,1);
EXEC SQL INSERT INTO fst_tab VALUES (0,4);
EXEC SQL INSERT INTO fst_tab VALUES (0,6);
EXEC SQL INSERT INTO sec_tab
SELECT dbinfo('serial8')
FROM fst_tab WHERE partnum = 6;
此示例将包含主键 SERIAL8 值的行插入到 fst_tab 表内,并使用 DBINFO 函数来将相同的 SERIAL8 值插入到 sec_tab 表内。DBINFO 函数返回的值是被插入到 fst_tab 内的最后一行的 SERIAL8 值。在随后行中的子查询包含 WHERE 子句,因此返回单个值。
SQLCA 结构不记录由触发器插入的 serial 值。您不可以 'bigserial' 选项调用 DBINFO 函数来返回由表上的触发器的触发器活动直接地插入了的最近的 BIGSERIAL 值(视图上的 INSTEAD OF 触发器的也不可返回)。出于同样的原因,DBINFO ('serial8') 函数不可返回由表上的触发器插入了的 SERIAL8 值,由视图上的 INSTEAD OF 触发器也不可返回。
使用 'get_tz' 选项
'get_tz' 选项返回展示当前会话的时区的 $TZ 字符串。
下列示例在 stores_demo 数据库的 cust_calls 表的查询中使用 'get_tz' 选项:
EXEC SQL select first call_dtime, dbinfo('get_tz')
from cust_calls where customer_num = 106;
此示例返回会话时区的字符串值以及 customer_num 值为 106 的 cust_calls 表中的第一个 call_dtime 值。
使用 'utc_current' 选项
'utc_current' 选项返回“全球标准时间”(UTC)的当前值,作为展示在 1970-01-01 00:00:00+00:00 与当前 SQL 语句开始执行时刻之间已消耗了的秒数的整数值。
“全球的时间”(UT)从地球的旋转计算持续的秒数。UTC 不是这样,UTC 基于高精度原子时钟使用固定长度的秒数。
由于地球逐渐地减小的旋转速度的变化,在 UTC 中一次又一次地引入闰年跳跃秒数来减少与 UT 时间的差异。在缺省情况下, GBase 8s 忽略在 DATETIME 和 INTERVAL 算术中的跳跃秒数。然而,当采用跳跃秒数的操作系统支持 GBase 8s 时,在操作系统为跳跃秒数调整系统时钟之后,在后续的 DATETIME 和 INTERVAL 操作中反映跳跃秒数。
考虑到数据库服务器的时区,DBINFO 函数的 'utc_to_datetime' 选项将 UTC 秒数返回到服务器会生成的 DATETIME 值,如果 UNIX™ time( ) 系统调用返回了秒参数的值的话。
'utc_to_datetime' 选项将它的最后的参数强制转型为 DATETIME 值,该参数必须是表示“全球标准时间”(UTC)的数值表达式。如果这求值为带有小数部分的数值,则忽略任何小数的秒。
在下列第一个示例中,最后一个参数是表示为字面整数的 UTC 值。在第二个示例中,最后一个参数是指定存储 UTC 值的整数列的列表达式。在两个示例中,DBINFO 都将 UTC 值强制转型为数据库服务器的时区中的 DATETIME 值:
DBINFO ('utc_to_datetime', 1299912999 )
使用 'utc_to_datetime' 选项
DBINFO ('utc_to_datetime', timesheet.utc_checkin )
如果最后一个参数的值是负的,则该函数从较早的 UNIX epoch 返回 DATETIME 值,如下例中所示:
SELECT DBINFO("utc_to_datetime", -2134567890.91234)
FROM 'sysmaster:"gbasedbt".sysdual';
此查询返回 DATETIME 值 1902-05-12 08:28:30。
这些示例时间都假设服务器在特定的时区中。下列查询返回四个 DATETIME 值:
SELECT
DBINFO('utc_to_datetime', -32767) AS min_smallint,
DBINFO('utc_to_datetime', +32767) AS max_smallint,
DBINFO('utc_to_datetime', 1299912999),
DBINFO("utc_to_datetime", -2134567890.91234)
FROM 'sysmaster:"gbasedbt".sysdual';
这些是从 United States Pacific 时区中的服务器返回的 DATETIME 值:
1969-12-31 06\:53\:53 1970-01-01 01\:06\:07
2011-03-11 22\:56\:39 1902-05-12 01\:28\:30
# Server running in TZ=US/Pacific
这些是从 UTC0 时区中的服务器从同一查询返回的 DATETIME 值:
1969-12-31 14\:53\:53 1970-01-01 09\:06\:07
2011-03-12 06\:56\:39 1902-05-12 08\:28\:30
# Server running in TZ=UTC0
第三个 DBINFO 结果中的 DAY 组件对于 United States Pacific 时区与对于 UTC0 时区是不同的,因为这那两个时区之间有 8 小时的偏移量。
对于时间中的点,数据库服务器时区可类似地影响从其他表达式的返回值,诸如 CURRENT、SYSDATE 和 TODAY,其 DATETIME YEAR TO SECOND 或 DATE 表示依赖于服务器的时区。
指数和对数函数
指数和对数函数至少有一个参数,且返回 FLOAT 数据类型。
指数和对数函数有下列语法。
指数和对数函数
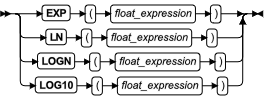
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| float_expression | EXP、LN、LOGN 或 LOG10 函数的一个参数。要了解这些函数中 float_expression 的含义,其参阅后面几页上每一函数的单独的标题。 | 该域是实数集,且范围是正实数集 | 表达式 |
EXP 函数
EXP 函数返回数值表达式的指数。
下列示例为 angles 表的每一行返回 3 的指数:
SELECT EXP(3) FROM angles;
对于此函数,基数始终为 e,自然对数的基数,如下例所示:
e=exp(1)=2.718281828459
当您想要使用自然对数的基数作为基数值时,请使用 EXP 函数。如果您想要指定特定的值来升至特定的幂,其参阅 POW 函数。
LN 函数
LN 函数是 LOGN 函数的别名,返回数值参数的自然对数。此值与指数值相反。
LN 函数
![]()
下列查询为 history 表中的每一行返回 population 的自然对数:
SELECT LN(population) FROM history WHERE country='US' ORDER BY date;
LOG10 函数
LOG10 函数返回以 10 为基数的对数。下列示例为 travel 表的每一行返回距离的以 10 为基数的对数:
SELECT LOG10(distance) + 1 digits FROM travel;
LOGN 函数
LOGN 函数返回数值参数的自然对数。
此返回值与 EXP 函数从同一参数返回的指数值相逆。
下列查询为 history 表的每一行返回 population 的自然对数:
SELECT LOGN(population) FROM history WHERE country='US' ORDER BY date;
NVL2 函数
当第一个参数不为 NULL 时,返回第二个参数。如果第一个参数为 NULL,则返回第三个参数。
NVL2 函数
![]()
NVL2 函数是下列代码的同义词:
CASE WHEN expression IS NOT NULL
THEN result-expression
ELSE else-expression
HEX 函数
HEX 函数返回整数表达式的十六进制编码。
HEX 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| int_expression | 您想要等同的十六进制的表达式 | 必须是文字整数或返回整数的某个其他表达式 | 表达式 |
下一示例显示十六进制格式的 orders 表的列的数据类型和列长度。 对于 MONEY 和 DECIMAL 列,您可从最低的和次低的字节确定精度和范围。对于 VARCHAR 和 NVARCHAR 列,您可从最低的和次低的字节来确定最小空间和最大空间。 要获取更多关于编码的信息的信息,请参阅 《GBase 8s SQL 指南:参考》。
SELECT colname, coltype, HEX(collength)
FROM syscolumns C, systables T
WHERE C.tabid = T.tabid AND T.tabname = 'orders';
下列示例罗列当前数据库中所有表的名称以及十六进制格式的对应的 tblspace 编号。
SELECT tabname, HEX(partnum) FROM systables;
十六进制编号中两个最高有效字节构成 dbspace 编号。它们在 GBase 8s 中的 oncheck 输出中标识该表。
HEX 可在表达式上操作,如下一示例所示:
SELECT HEX(order_num + 1) FROM orders;
DUMP 函数
DUMP 函数返回一个值,其中包含数据类型代码、长度(以字节为单位)和 expr 的内部表示形式。如果省略了return_format,start_position和length参数,则DUMP函数将以十进制表示形式返回整个内部表示形式。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 需要分析的表达式 | 可以为任意字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
| return_format | 决定返回值格式 | 可选参数。默认为10进制。可以是以下任意值: 8:八进制符号 16:十六进制符号 17:单个字符 1008:带字符集名称的八进制符号 1010:带字符集名称的十进制符号 1016:带字符集名称的十六进制符号 1017:带字符集名称的单个字符 | 表达式 |
| start_position | 要返回的内部表示的起始位置 | 可以为数值类型或者可以隐式转换为数值类型的其他数据类型。 | 表达式 |
| length | 要返回的内部表示的长度 | 可选参数。可以为数值类型或者可以隐式转换为数值类型的其他数据类型。 | 表达式 |
例如,输出abc16进制下全部信息:
select DUMP('abc',16,1,3) from dual;
(dump)
Typ=96 Len=3: 61,62,63
1 row(s) retrieved.
说明及限制:
- Len的限制长度为17。
- 第一个参数为longlvarchar类型、text类型、byte类型时,输出len=0。
- 参数length为null或0时,返回整个expression。
长度函数
使用长度函数来确定字符列、字符串或变量的长度,或字符表达式返回的值的长度,或逻辑字符的数目(对于多字节语言环境中的 CHAR_LENGTH)。
长度函数
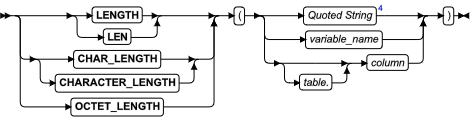
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| column | table 中列的名称 | 必须有字符数据类型 | 标识符 |
| table | 指定的列在其中的表的名称 | 必须存在 | 标识符 |
| variable | 包含字符串的主变量或 SPL 变量 | 必须有字符数据类型 | 请参阅名称的特定于语言的规则。 |
这些函数的每一个都有明确的用途:
- LENGTH
- OCTET_LENGTH
- CHAR_LENGTH(又称为 CHARACTER_LENGTH)
LENGTH 函数
LENGTH 函数返回字符列中的字节数,包括任何末尾的空格。
对于 BYTE 或 TEXT 列,LENGTH 返回全部字节数,包括任何末尾的空格。
在 GBase 8s ESQL/C 中,LENGTH 还可返回字符变量的长度。
下列示例说明 LENGTH 函数的使用:
SELECT customer_num, LENGTH(fname) + LENGTH(lname),
LENGTH('How many bytes is this?')
FROM customer WHERE LENGTH(company) > 10;
另请参阅 GBase 8s GLS 用户指南 中 LENGTH 的讨论。
ORACLE模式下:
LENGTH 函数返回字符串 char 的字符长度,包含所有的尾空格。
 参数说明:
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要计算字符长度的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
例如,zh_CN.utf8字符集下计算一个中文的字符长度:
select length('南') from dual;
(CONSTANT)
1
1 row(s) retrieved.
LEN函数
LEN 函数返回字符列中的字节数,包括任何末尾的空格。
对于 BYTE 或 TEXT 列,LEN 返回全部字节数,包括任何末尾的空格。
在 GBase 8s ESQL/C 中,LEN 还可返回字符变量的长度。
下列示例说明 LEN 函数的使用:
SELECT customer_num, LEN(fname) + LEN(lname),
LEN('How many bytes is this?')
FROM customer WHERE LEN(company) > 10;
说明及限制:
- 在不同字符集下LEN函数返回中文字节长度不同。
LENGTHB函数
LENGTHB 函数返回字符串char的字节长度。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要计算字节长度的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
例如,zh_CN.utf8字符集下计算一个中文的字节长度:
select lengthb('好') from dual;
(CONSTANT)
3
1 row(s) retrieved.
说明及限制:
- 当使用单引号且字符为空时,使用LENGTHB()函数,则返回空字符的个数。
- 在不同字符集下LENGTHB函数返回中文字节长度不同。
- LENGTHB函数计算一个英文字节的长度为1。
- LENGTHB函数长度包含所有的尾随空格。
BIT_LENGTH函数
BIT_LENGTH 函数返回给定字符串的位长度。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 需要计算位长度的字符串 | 可以为字符类型或者可以隐式转换为字符类型的其他数据类型。 | 表达式 |
例如,zn_CN.utf8字符集编码下查看字符串gbase的位长度:
select bit_length('gbase') from dual;
(constant)
40
1 row(s) retrieved.
说明及限制:
- 参数expr为NULL时,返回NULL。
- 如果BIT_LENGTH函数参数类型不是字符类型,BIT_LENGTH() 函数会尝试将参数转为字符串。
- expr边界值为32739个英文字符的长度,超过进行截断。
VSIZE函数
VSIZE函数返回expr的字节数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要计算字节数的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
例如,在utf8字符集下计算字符串Hello 南大通用的字节长度 :
select vsize('Hello 南大通用') from dual;
(CONSTANT)
18
1 row(s) retrieved.
说明及限制:
- 参数expr为NULL时,返回NULL。
- 参数expr为空字符串时,返回0。
- 在不同字符集下vsize函数返回中文字节长度不同。
OCTET_LENGTH 函数
OCTET_LENGTH 返回字符列中的字节数,包括任何末尾的空格。另请参阅 GBase 8s GLS 用户指南。
CHAR_LENGTH 函数
CHAR_LENGTH 函数返回在它的参数中的逻辑字符的数目,该参数可为字符列、字符变量或引用的字符串。还可调用此内建的函数作为 CHARACTER_LENGTH。
在缺省的 U.S. English 语言环境和其他单字节语言环境中,CHAR_LENGTH 的行为正像 LENGTH 函数一样,并返回在它的参数中的字节数。
然而,对于支持各种 Unicode、东亚和其他非缺省的语言环境的多字节代码集,返回值可小于该参数中的字节数。要获取此函数的讨论,请参阅 GBase 8s GLS 用户指南。
安全标签支持函数
安全标签支持函数使得用户能够操纵安全标签。可以三种不同的方式引用安全标签:
- 名称,如在 CREATE SECURITY LABEL 或 RENAME SECURITY LABEL 语句中声明的那样。
- 安全标签的安全策略的每一组件的值的列表。
- IDSSECURITYLABEL 数据类型存储的内部的编码的值。
这些函数可在不同形式的安全标签之间转换。它们通常用于指定 DML 操作的标签,这些操作处理那些由基于标签的访问控制(LBAC)保证安全的数据行。然而,与通过调用该函数的用户的安全凭证已提供的访问相比,在这些操作中,安全标签支持函数不提供针对受保护的数据任何更多的访问。
安全标签支持函数
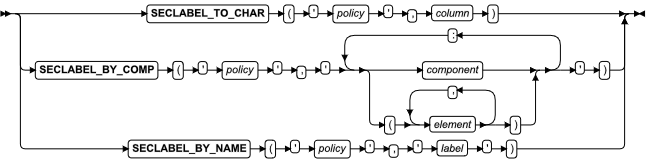
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| column | 类型 IDSSECURITYLABEL 的列 | 必须存在并必须存储 policy 的一个标签 | 标识符 |
| component | policy 的组件的值 | 必须存在且必须为 policy 的一个组件 | 引用字符串 |
| element | component 的值的列表内的值 | 必须存在且必须为 policy 的单个组件的元素 | 引用字符串 |
| label | 该函数返回其值的安全标签的标识符 | 必须存在且必须为 policy 的一个标签 | 引用字符串 |
| policy | 由该函数返回其值的安全标签支持的安全策略 | 必须存在且必须为保证该表安全的安全策略 | 引用字符串 |
这些函数返回指定的安全策略的安全标签。 可在引用受保护的数据库表的 DML 语句内使用它们,但它们还可在其他调用上下文中求值为安全标签。每一这些函数需要不同的参数列表:
- SECLABEL_TO_CHAR 需要安全策略名称以及返回 IDSSECURITYLABEL 对象的表达式,诸如那种数据类型的列的名称。
- SECLABEL_BY_COMP 需要安全策略名称以及该安全标签的个别组件的值。
- SECLABEL_BY_NAME 需要安全策略和安全标签的名称。
SECLABEL_BY_NAME 函数
SECLABEL_BY_NAME 函数使得用户能够通过指定安全标签的名称来直接提供它。
下列 INSERT 语句将一行插入到表 T1 内,该表受到名为 ‘MegaCorp’ 的安全策略的保护。 INSERT 语句的 VALUES 子句为通过使用 SECLABEL_BY_NAME 语句要被插入的行提供安全标签 ‘mylabel’。
INSERT INTO T1 VALUES (SECLABEL_BY_NAME ('MegaCorp', 'mylabel'), 1, 'xyz');
此 SECLABEL_BY_NAME 函数调用的成功并不保证在此示例中 INSERT 操作的成功,因为 MegaCorp 安全策略的 IDSLBACWRITE 规则影响到该用户是否有充足的安全凭证来将标签 mylabel 插入到该行内。
SECLABEL_BY_COMP 函数
SECLABEL_BY_COMP 函数返回 IDSSECURITYLABEL 对象,其为它的内部编码的字符串格式的安全标签。此函数使得用户能够通过指定它的组件值直接地提供安全标签。
如果安全标签组件需要多个值,则可通过将那些值放在圆括号之间来指定这样的多个值,比如 (value_1, value_2, ...)。当特定的安全标签中的组件需要为空时,可通过在左圆括号和右圆括号之间什么都不放来指定它,比如 ()。由于在安全组件的元素之中,空格(ASCII 32)是有效的字符,因此出现在安全标签字符串中的任何空格都作为那个组件的元素值的一部分来处理。
安全标签字符串被限定为最大 32 KB。如果该字符串长度超出此限制,则返回错误。
下列 INSERT 语句将一行插入到表 T1 内,该表受到名为 ‘MegaCorp’ 的安全策略保护,该策略有三个组件:'level'、'compartments' 和 'groups'。在此,用户为由指定 SECLABEL_BY_COMP 函数被插入的行提供安全标签。在此示例中,对于 level 组件,安全标签有值 'VP',对于 compartments 组件,安全标签有值 'Marketing',对于 groups 组件,安全标签有值 'West'。在 SECLABEL_BY_COMP 的参数中,冒号符号分隔这些安全组件元素值,且引号定界安全标签的组件值的列表。
INSERT INTO T1 VALUES (SECLABEL_BY_COMP ('MegaCorp', 'VP:Marketing:West'), 1, 'xyz';
在下一示例中,INSERT 语句在表 T1 中插入一行,该表受到同一 MegaCorp 安全策略的保护,该策略有与前面的示例相同的三个组件:level、compartments 和 groups。用户为通过指定该策略名称要被插入的行提供安全标签,以及安全组件元素的列表作为 SECLABEL_BY_COMP 函数的参数。在此,对于 level 组件,安全标签有值 'Director',对于 compartments 组件,安全标签有值 'HR' 和 'Finance',对于 groups 组件,安全标签有值 'East' 。
INSERT INTO T1 VALUES (SECLABEL_BY_COMP ('MegaCorp', 'Director:(HR,Finance):East'), 1, 'xyz');
下列示例将一行插入到表 T1 内,该表受到 MegaCorp 安全组件的保护,其三个组件为 level、compartments 和 groups。SECLABEL_BY_COMP 函数为要被插入的行指定安全标签。在此示例中,对于 level 组件,安全标签有值 'CEO',对于 compartments 组件,安全标签为空集,对于 groups 组件,安全标签有值 'EntireRegion'。
INSERT INTO T1 VALUES (SECLABEL_BY_COMP ('MegaCorp', 'CEO:():EntireRegion'), 3, 'abc');
如在所有这些示例中那样,SECLABEL_BY_COMP 函数调用的成功不保证 INSERT 语句的成功,因为在数据库服务器允许或拒绝对于插入新行的访问之前,首先要使用 MegaCorp 安全策略的 IDSLBACRWRITE 规则,将用户的安全凭证与保护表 T1 的安全标签进行对比。
SECLABEL_TO_CHAR 函数
SECLABEL_TO_CHAR 函数返回一个安全标签字符串格式的安全标签。
执行此函数的用户的安全凭证可影响该函数的输出。如果用户没有对那个元素的读访问权限,则在输出中不包括安全标签组件的元素。如果用户提供对该数据的读访问的安全凭证,由仅包含那个元素而没有其他元素的安全标签保护数据,则用户有对该元素的访问权限。
对于规则集 IDSLBACRULES,仅类型 TREE 的组件可包含用户没有对元素的子集的读访问权限的元素。对于其他类型组件,如果任何元素阻止读访问,则用户根本不可读该行。因此,仅类型 TREE 的安全组件可有以此方式排除的安全组件元素的子集。
例如,如果用户的安全标签的 TREE 类型组件为 {A},且行安全标签的 TREE 类型组件为 {A, B},则仅返回组件 A,且用户感觉不到在行安全标签中存在 B。然而,如果用户持有 IDSLBACREADTREE 规则上的豁免,则返回的安全组件为 A 和 B。
在下一示例中,MegaCorp 安全策略有名为 mylabel 的安全标签,该标签由其值为 'Director' 的 level 组件,以及带有值 'HR' 和 'Finance' 的 compartments 组件组成。被授予了 ‘mylabel’ 的用户已将带有那个安全标签的一行插入到表 T1 内。在此上下文中,在下列 T1 上的 SELECT 语句中,由 SECLABEL_TO_CHAR 函数返回的安全标签字符串如下。
SELECT SECLABEL_TO_CHAR ('MegaCorp’, C1) FROM T1;
Row returned:
'Director:(HR,Finance)'
由于数据库服务器允许对安全策略名称和安全标签组件的值的读访问,根据 MegaCorp 安全策略的 IDSLBACREAD 规则,此查询的成功说明 SECLABEL_TO_CHAR 函数成功,且该用户的安全凭证是充分的。
限定安全标签字符串的最大大小为 32 KB。如果要被返回的安全标签字符串的长度超出此上限,则发出警告,且返回截断了的 32 KB 字符串。
SIGN 函数
SIGN 函数返回参数的符号的指示符。
SIGN 函数
![]()
如果参数小于零,则返回 -1。如果参数等于零,则返回 0。如果参数大于零,则返回 1。返回的结果始终是这些值之一的整数。
智能大对象函数
智能大对象函数支持 BLOB 和 CLOB 数据类型的对象:
智能大对象函数有下列语法:
智能大对象
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| BLOB_column、CLOB_column | 类型 BLOB 的列;类型 CLOB 的列 | column 数据类型必须为 BLOB 或 CLOB | 标识符 |
| column | table 内 BLOB 或 CLOB 值的副本的列 | 必须有 CLOB 或 BLOB 作为它的数据类型 | 引用字符串 |
| file_destination | 在其上放置或获取智能大对象的系统 | 有效的值仅为字符串 'server' 或 'client' | 引用字符串 |
| pathname | 定位智能大对象的目录路径和 filename | 不超过 256 字节。在 file_destination 系统上必须存在。另请参阅 带逗号的 pathname。 | 引用字符串 |
| table | 包含 BLOB 或 CLOB 值的副本的 column 的表 | 以逗号(不是句号)分隔 'table' 和 'column' 参数 | 引用字符串 |
FILETOBLOB 和 FILETOCLOB 函数
FILETOBLOB 函数为存储在指定的操作系统文件中的数据创建 BLOB 值。类似地,FILETOCLOB 函数为存储在操作系统文件中的数据值创建 CLOB 值。
这些函数从下列参数来确定要使用的操作系统文件:
- pathname 参数标识源文件的目录路径和名称。
- file destination 参数标识此文件所在的计算机,'client' 或 'server':
- 将 file destination 设置为 'client' 来标识客户端计算机作为源文件的位置。pathname 既可是完整路径也可是当前目录的相对路径。
- 将 file destination 设置为 'server' 来标识服务器计算机作为源文件的位置。pathname 必须为完整路径。
table 和 column 参数是可选的:
- 如果您省略 table 和 column,则 FILETOBLOB 函数以系统指定的存储缺省值来创建 BLOB 值,且 FILETOCLOB 函数以系统指定的存储缺省值来创建 CLOB 值。
这些函数从 ONCONFIG 文件或从 sbspace 获取系统特定的存储特征。要获取更多关于系统指定的存储缺省值的信息,请参阅 GBase 8s 管理员指南。
- 如果您指定 table 和 column,则 FILETOBLOB 和 FILETOCLOB 函数为它们创建的 BLOB 或 CLOB 值使用来自指定的列的存储特征。
FILETOBLOB 返回一个指向新的 BLOB 值的句柄值(指针)。类似地,FILETOCLOB 返回一个指向新的 CLOB 值的句柄值。两个参数都不实际地将智能大对象值复制到数据库列内。您必须将 BLOB 或 CLOB 值指定到适当的列。
当 FILETOCLOB 函数将文件从客户端或服务器计算机复制到数据库时,它执行任何可能需要的代码集转换。
下列 INSERT 语句使用 FILETOCLOB 函数来从 smith.rsm 文件中的值创建 CLOB:
INSERT INTO candidate (cand_num, cand_lname, resume)
VALUES (2, 'Smith', FILETOCLOB('smith.rsm', 'client'));
在前面的示例中,FILETOCLOB 函数读取客户端计算机上当前目录中的 smith.rsm 文件,并返回一指向包含此文件中的数据的 CLOB 值的句柄值。由于 FILETOCLOB 函数未指定表和列名称,此新的 CLOB 值有系统指定的存储特征。然后,该 INSERT 语句将此 CLOB 值指定给 candidate 表中的 resume 列。
下列 INSERT 语句使用 FILETOBLOB 函数从本地数据库服务器上的 photos.xxx 文件中的值创建 BLOB 值,并将那个值插入到 rdb 数据库的 election2008 表内,其为本地数据库服务器的另一数据库:
INSERT INTO rdb@:election2008 (cand_pic)
VALUES (FILETOBLOB('C:\tmp\photos.xxx', 'server',
'candidate', 'cand_photo'));
在前面的示例中,FILETOBLOB 函数读取本地数据库服务器上指定的目录中的 photos.xxx 文件,并返回指向此包含文件中的数据的 BLOB 值的句柄值。然后,该 INSERT 语句将此 BLOB 值指定到本地数据库服务器的 rdb 数据库中的 election2008 表中的 cand_pic 列。此新的 BLOB 值有本地数据库中的 candidate 表中的 cand_photo 列的存储特征。
在下列示例中,新的 BLOB 值有 rdb2 数据库中的 election96 表中的 cand_pix 列的存储特征,在此,rdb1 和 rdb2 是本地 GBase 8s 实例的数据库:
INSERT INTO rdb1:election2008 (cand_pic)
VALUES (FILETOBLOB('C:\tmp\photos.xxx', 'server', 'rdb2:election96', 'cand_pix'));
当您以远程数据库和远程数据库服务器的名称限定 FILETOBLOB 或 FILETOCLOB 函数时,pathname 和 file destination 成为对远程数据库服务器的相对值。
当您指定 server 作为文件目的地时,如下例所示,FILETOBLOB 函数在远程数据库服务器上查找源文件(在此情况下,为 photos.xxx):
INSERT INTO rdb@rserv:election (cand_pic)
VALUES (rdb@rserv:FILETOBLOB('C:\tmp\photos.xxx', 'server'));
然而,当您指定 client 为文件目的地时,如下例所示,FILETOBLOB 函数在本地客户端计算机上查找源文件(在此情况下,为 photos.xxx):
INSERT INTO rdb@rserv:election (cand_pic)
VALUES (rdb@rserv:FILETOBLOB('photos.xxx', 'client'));
带逗号的 pathname
如果逗号(,)符号在函数的 pathname 内,则数据库服务器期望该 pathname 有下列格式:
"offset, length,pathname"
对于包含逗号的 pathname,您还必须指定偏移量和长度,如下例所示:
FILETOBLOB("0,-1,/tmp/blob,x","server");
引用的 pathname 字符串中的第一个术语是 offset 0,其指导数据库服务器在该文件的开头开始读。
第二个术语是 length -1,其指导数据库服务器继续读,直到整个文件的结尾为止。
第三个术语是 /tmp/blob,x pathname,指定读哪个文件。(请注意在 x 前面的逗号。)
由于 pathname 包括逗号,因此当调用 FILETOBLOB 时,在此示例中以逗号分隔的 offset 和 length 规范是避免错误所必要的。您不需要为不包括逗号但包括 0、-1 的 pathname 指定 offset 和 length,作为 pathname 字符串的初始字符以避免任何有效的 pathname 的此类错误。
LOTOFILE 函数
LOTOFILE 函数将智能大对象复制到操作系统文件。
第一个参数指定要复制的 BLOB 或 CLOB 列。该函数从下列参数确定要创建什么文件:
- pathname 标识目录路径和源文件名称。
- file destination 标识此文件在其上的计算机,'client' 或 'server':
- 设置 file destination 为 'client' 来标识客户端计算机作为源文件的位置。pathname 可为完整的 pathname 或相对于当前目录的路径。
- 设置 file destination 为 'server' 来标识服务器计算机作为源文件的位置。要求完整的 pathname。
在缺省情况下,LOTOFILE 函数生成这种形式的 filename:
file.hex_id
在此格式中,file 是您在 pathname 中指定的 filename,而 hex_id 是唯一的十六进制智能大对象标识符。智能大对象标识符的最大位数为 17。然而,大多数智能大对象可能有位数较少的标识符。
例如,假设您指定 UNIX™ pathname 值如下:
'/tmp/resume'
如果 CLOB 列有标识符 203b2,则 LOTOFILE 创建文件:
/tmp/resume.203b2
对于另一示例,假设您指定 Windows™ pathname 值如下:
'C:\tmp\resume'
如果 CLOB 列有标识符 203b2,则 LOTOFILE 函数会创建文件:
C:\tmp\resume.203b2
要更改缺省的 filename,您可在 pathname 的 filename 中指定下列通配符:
- 在 filename 中的一个或多个连续的问号(?)可生成唯一的 filename。
LOTOFILE 函数以来自 BLOB 或 CLOB 列的标识符的十六进制数字替换每一问号。
例如,假设您指定 UNIX pathname 值如下:
'/tmp/resume??.txt'
LOTOFILE 函数将十六进制标识符的 2 位数字放到该名称内。如果 CLOB 列有标识符 203b2,则 LOTOFILE 函数会创建文件:
/tmp/resume20.txt
如果您指定多于 17 个问号,则 LOTOFILE 忽略它们。
- filename 末尾的叹号(!)表示 filename 不需要是唯一的。
例如,假设您指定 Windows pathname 值如下:
'C:\tmp\resume.txt!'
LOTOFILE 函数不使用 filename 中的智能大对象标识符,因此它生成下列文件:
C:\tmp\resume.txt
如果您指定的 filename 已存在,则 LOTOFILE 返回错误。
当 LOTOFILE 函数将 CLOB 值从数据库复制到客户端或服务器计算机上的文件时,它执行任何可能需要的代码集转换。
当您以远程数据库和远程数据库服务器的名称限定 LOTOFILE 时,BLOB 或 CLOB 列、pathname 和 file destination 成为对远程数据库服务器的相对值。
当您指定 server 作为文件目的地时,如下一示例中那样,LOTOFILE 函数将智能大对象从远程数据库服务器复制到在远程数据库服务器上指定目录中的源文件:
rdb@rserv:LOTOFILE(blob_col, 'C:\tmp\photo.gif!', 'server')
如果您指定 client 作为文件目的地,如在下例中那样,则 LOTOFILE 函数将智能大对象从远程数据库服务器复制到本地客户端计算机上指定的目录中的源文件:
rdb@rserv:LOTOFILE(clob_col, 'C:\tmp\essay.txt!', 'client')
LOCOPY 函数
LOCOPY 函数创建智能大对象的一个副本。
第一个参数指定要复制的 BLOB 或 CLOB 列。table 和 column 参数是可选的。
- 如果您省略 table 和 column 参数,则 LOCOPY 函数以系统指定的存储缺省值创建智能大对象,并将 BLOB 或 CLOB 列中的数据复制到它之内。
LOCOPY 函数从 ONCONFIG 文件或 sbspace 获取系统特定的存储缺省值。要获取更多关于系统指定的存储缺省值的信息,请参阅 GBase 8s 管理员指南。
- 当您指定 table 和 column 时,LOCOPY 函数为它创建的 BLOB 或 CLOB 值从指定的 column 使用存储特征。
LOCOPY 函数返回指向新的 BLOB 或 CLOB 值的句柄值(一个指针)。此函数不是 实际地将新的智能大对象值存储到数据库中的列内。您必须将该 BLOB 或 CLOB 值指定到适当的列。
下列 GBase 8s ESQL/C 代码片段将 candidate 表的 resume 列中的 CLOB 值复制到 interview 表的 resume 列:
/* Insert a new row in the在 interviews 表中插入新行并
* (从 sqlca.sqlerrd[1])获得结果 SERIAL 值
*/
EXEC SQL insert into interviews (intrv_num, intrv_time)
values (0, '09:30');
intrv_num = sqlca.sqlerrd[1];
/* 以 candidate 编号更新此 interviews 行
* 并从 candidate 表恢复。使用 LOCOPY 来
* 在 candidate 表的 resume 列中
* 创建 CLOB 值的副本。
*/
EXEC SQL update interviews
SET (cand_num, resume) =
(SELECT cand_num,
LOCOPY(resume, 'candidate', 'resume')
FROM candidate
WHERE cand_lname = 'Haven')
WHERE intrv_num = :intrv_num;
在前面的示例中,LOCOPY 函数为 candidate 表中的 CLOB resume 列的副本返回句柄值。由于 LOCOPY 函数指定表和列名称,因此这个新的 CLOB 值有此 resume 列的存储特征。如果您省略表(candidate)和列(resume)名称,则 LOCOPY 函数为新的 CLOB 值使用系统定义的存储缺省值。然后,UPDATE 语句将这个新的 CLOB 值指定到 interviews 表中的 resume 列。
在下列示例中,在本地数据库上执行 LOCOPY 函数并在本地服务器上为 rdb 中的 election2008 表中的 BLOB cand_pic 列的副本返回句柄值,rdb 是本地数据库服务器的另一数据库。然后,INSERT 语句将这个新的 BLOB 值指定到本地的 candidate 表中的 cand_photo 列。
INSERT INTO candidate (cand_photo)
SELECT LOCOPY(cand_pic) FROM rdb:election2008;
当在与分布式查询中原始的 BLOB 或 CLOB 列一样的数据库服务器上执行 LOCOPY 函数时,函数产生 BLOB 或 CLOB 值的两个副本,一个在远程数据库中,另一个在本地数据库中,如下列两个示例所示。
在第一个示例中,在远程 rdb 数据库上执行 LOCOPY 函数,并为远程 election2008 表中的 BLOB cand_pic 列的副本在远程服务器中返回句柄值。然后,INSERT 语句将这个新的 BLOB 值指定到本地 candidate 表中的 cand_photo 列:
INSERT INTO candidate (cand_photo)
SELECT rdb:LOCOPY(cand_pic) FROM rdb:election2008;
在第二个示例中,在本地数据库上执行 LOCOPY 函数,并为本地 candidate 表中的 BLOB cand_photo 列的副本在本地数据库上返回句柄值。然后,该 INSERT 语句将这个新的 BLOB 值指定到远程 rdb 数据库中 election2008 表中的 cand_pic 列:
INSERT INTO rdb:election2008 (cand_pic)
SELECT LOCOPY(cand_photo) FROM candidate;
内建的 LOCOPY 函数的 BLOB 和 CLOB 参数是内建的 opaque 数据类型。这些可为由跨数据库 DML 操作返回的值,或为跨数据库函数调用返回的值,但内建的 opaque 类型不支持跨数据库服务器实例的分布式操作。如果本地数据库与 rdb 数据库是不同的 GBase 8s 实例的数据库,则在前面的两个示例中的 INSERT 语句失败并报错 -999。
时间函数
GBase 8s 的时间函数接受 DATE 或 DATETIME 参数,或 DATE 或 DATETIME 值的字符表示。它们通常返回 DATE 或 DATETIME 值,或将它们从 DATE 或 DATETIME 值抽取的信息转换为字符串或整数。
另请参阅在 代数函数 部分中的 ROUND 和 TRUNC 函数的描述,其可更改 DATE 或 DATETIME 值的精度。
时间函数
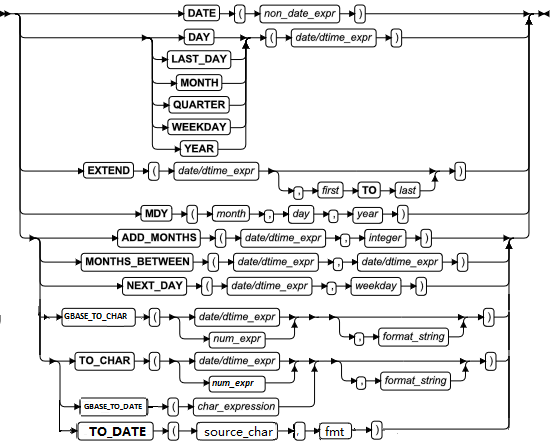
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char_expression | 要被转换为 DATE 或 DATETIME 值的表达式 | 必须为文字、主变量、表达式或字符数据类型的列 | 表达式 |
| date/dtime_expr | 返回 DATE 或 DATETIME 值的表达式 | 可为主变量、表达式、列或常量。 | 表达式 |
| day | 返回该月的天数的表达式 | 必须返回 > 0 但不大于指定的月中天数的整数 | 表达式 |
| first | 结果中的最大时间单位。如果您省略 first 和 last,则缺省的 first 是 YEAR。 | 必须是指定不小于 last 的时间单位的 DATETIME 限定符关键字 | DATETIME 字段限定符 |
| format_string | 包含第一个参数的格式掩码的字符串 | 必须为指定有效的格式的字符数据类型。可为列、主变量、表达式或常量 | 引用字符串 |
| integer | 指定月的整数的表达式 | 必须求值为正的或负的整数 | 表达式 |
| last | 结果中的最小时间单位 | 必须是指定不小于 first 的时间单位的 DATETIME 限定符关键字 | DATETIME 字段限定符 |
| month | 表示月的数值的表达式 | 必须求值为取值范围从 1 至 12(包括1 和 12)的整数 | 表达式 |
| non_date_expr | 表示要被转换为 DATE 数据类型的值的表达式 | 通常是一个表达式,该表达式返回可被转换为 DATE 数据类型的 CHAR、DATETIME 或 INTEGER 值的表达式 | 表达式 |
| num_expr | 求值为实数值的表达式 | 必须返回数值数据类型 | 表达式 |
| weekday | 星期几的缩写名称 | 包含星期几的有效缩写的字符数据类型 | 引用字符串 |
| year | 表示年份的数值表达式 | 必须求值为 4 位整数。您不可使用 2 位缩写。 | 表达式 |
| source_char | 要被转换为 DATETIME 值的源字符串 | 设置为空字符串或NULL时,返回结果为空。 | 引用字符串 |
| fmt | DATETIME 类型的格式化字符串 | 设置为空字符串或NULL时,返回结果为空。 | 引用字符串 |
ADD_MONTHS 函数
ADD_MONTHS 函数采用 DATETIME 或 DATE 表达式作为它的第一个参数,并需要第二个参数指定要添加到第一个参数值上的月数。第二个参数可为正的或负的。
返回的值是基于第二个参数指定的月数,作为 INTERVAL UNITS MONTH 值的第一个参数的 DATE 或 DATETIME 值的总和。
返回的数据类型依赖于第一个参数的数据类型:
- 如果第一个参数求值为 DATE 值,则 ADD_MONTHS 返回 DATE 值。
- 如果第一个参数求值为 DATETIME 值,则 ADD_MONTHS 返回 DATETIME YEAR TO FRACTION(5) 值,对于时间单位小于 day 的,其值与第一个参数中的相同。
如果在第一个参数中的 day 和 month 时间单位指定该月的最后一天,或如果结果月的天数少于第一个参数中的 day,则返回的值为结果月的最后一天。否则,返回的值与第一个参数为该月的同一天。
如果结果月晚于第一个参数中那年的十二月(或对于负的第二个参数,早于一月),则返回的值可在不同的年份中。
下列查询使用列表达式作为参数,在 Projection 子句中调用 ADD_MONTHS 函数两次。在此,列名称表明列数据类型,且 DBDATE 设置为 MDY4/:
SELECT a_serial, b_date, ADD_MONTHS(b_date, a_serial),
c_datetime, ADD_MONTHS(c_datetime, a_serial)
FROM mytab WHERE a_serial = 7;
在此示例中,ADD_MONTHS 返回 DATE 和 DATETIME 值:
a_serial 7
b_date 07/06/2007
(expression) 02/06/2008
c_datetime 2007-10-06 16\:47\:49.00000
(expression) 2008-05-06 16\:47\:49.00000
如果您使用主变量来存储 ADD_MONTHS 的参数,但在准备时刻不知道该参数的数据类型,则 GBase 8s 假设数据类型为 DATETIME YEAR TO FRACTION(5)。如果在运行时刻,在已准备了该语句之后,用户为主变量提供 DATE 值,则数据库服务器发出错误 -9750。要防止此错误,请通过使用强制转型来指定主变量的数据类型,如在此程序片断中所示:
sprintf(query, ","
"select add_months(?::date, 6) from mytab");
EXEC SQL prepare selectq from :query;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor using :hostvar_date_input;
EXEC SQL fetch select_cursor into :var_date_output;
ADD_DAYS函数
ADD_DAYS 函数返回日期 date 加上相应天数 n 后的日期值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需计算的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
| n | 添加至参数 date 的天数 | 可以为任意整数。n 为小数时做取整操作。 | 表达式 |
例如,返回当天日期增加一天的日期值:
select add_days(today,1) from dual;
(EXPRESSION) 2024-03-05 00\:00\:00
1 row(s) retrieved.
说明及限制:
- ADD_DAYS中任意参数为 NULL 或空串时,返回结果为 NULL。
CURDATE函数
CURDATE 函数返回当前日期值。

例如,返回当天日期:
select curdate() from dual;
(constant) |
-----------------------+
2024-03-01 00\:00\:00.000|
NEW_TIME 函数
NEW_TIME函数将日期从指定时区转换为另一个指定时区并返回结果。
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要转换时区的日期 | 可以为DATETIME类型或者可以强转的日期字符串。 | 表达式 |
| timezone1 | 时区文本 | 可以为文本字符串: AST、ADT:大西洋标准时间或夏令时 BST、BDT:白令标准时间或夏令时 CST、CDT:中央标准时间或夏令时 EST、EDT:东部标准时间或夏令时 GMT:格林威治标准时间 HST、HDT:阿拉斯加-夏威夷标准时间或夏令时。 MST、MDT:山区标准时间或夏令时 NST:纽芬兰标准时间 PST、PDT:太平洋标准时间或夏令时 YST、YDT:育空标准时间或夏令时 | 表达式 |
| timezone2 | 时区文本 | 可以为文本字符串: AST、ADT:大西洋标准时间或夏令时 BST、BDT:白令标准时间或夏令时 CST、CDT:中央标准时间或夏令时 EST、EDT:东部标准时间或夏令时 GMT:格林威治标准时间 HST、HDT:阿拉斯加-夏威夷标准时间或夏令时。 MST、MDT:山区标准时间或夏令时 NST:纽芬兰标准时间 PST、PDT:太平洋标准时间或夏令时 YST、YDT:育空标准时间或夏令时 | 表达式 |
例如,将当前时间从大西洋标准时间或夏令时转换成太平洋标准时间或夏令时:
select new_time(sysdate,'AST','PST') from dual;
(expression) 2024-01-23 10\:41\:09
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,都返回NULL。
DATE 函数
DATE 函数将它的参数转换为 DATE 值。
它的非 DATE 参数可为可转换为 DATE 值的任何表达式,通常是 CHAR、DATETIME 或 INTEGER 值。下列 WHERE 子句指定引用的字符串作为它的 CHAR 参数:
WHERE order_date < DATE('12/31/07')
当 DATE 函数解释一 CHAR 非 DATE 表达式时,它期望此表达式符合任何 DBDATE 环境变量指定的 DATE 格式。例如,假设当您执行下列查询时,DBDATE 设置为 Y2MD/:
SELECT DISTINCT DATE('02/01/2008') FROM ship_info;
此 SELECT 语句生成错误,因为 DATE 函数不可转换此字符串表达式。DATE 函数将该日期字符串的第一部分(02)解释为年份,第二部分(01)为月份。
对于第三部分(2008),当 DATE 函数期望两位的日期(有效的日期值必须介于 01 与 31 之间)时,它遇到了四位数字。因此,它不可转换该值。对于要以 DBDATE 的 Y2MD/ 值成功地执行的 SELECT 语句,该参数需要为 '08/02/01'。要获取关于 DBDATE 的格式的信息,请参阅 《GBase 8s SQL 指南:参考》。
要获取那些可指定 DATE 值的显示和数据条目格式的 GBase 8s 环境变量之中优先级顺序的信息,请参阅主题 DATE 和 DATETIME 格式规范的优先顺序。
当您为非 DATE 表达式指定正的 INTEGER 值时,DATE 函数将此解释为 1899 年 12 月 31 日之后的天数。
如果整数值为负的,则 DATE 函数将该值解释为 1899 年 12 月 31 日之前的天数。下列 WHERE 子句为非 DATE 表达式指定 INTEGER 值:
WHERE order_date < DATE(365)
数据库服务器搜索 order_date 值小于 1900 年 12 月 31 日(其为 12/31/1899 加上 365 天)的行。
DATE_ADD函数
DATE_ADD函数返回一个日期或时间值加上一个时间间隔的时间值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| d | 需要计算的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
| expr | 需要加的时间间隔 | 支持interval类型。interval类型仅支持year to month部分。 | 表达式 |
例如,查看当前日期加十年十个月后的日期:
select date_add(sysdate,interval '10-10' year to month) from dual;
(EXPRESSION) 2035-01-04 14\:18\:13
1 row(s) retrieved.
说明及限制:
- DATE_ADD中任意参数为NULL、空格串或空串时,返回NULL。
DATE_SUB函数
DATE_SUB函数返回一个日期或者时间值减去一个时间间隔的时间值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| d | 需要计算的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
| expr | 需要减的时间间隔 | interval类型。 | 表达式 |
例如,查看当前日期减十年十个月后的日期:
select date_sub(sysdate,interval '10-10' year to month) from dual;
(EXPRESSION) 2013-05-04 17\:26\:44
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
DATE_FORMAT函数
DATE_FORMAT 函数返回以不同的格式显示日期/时间数据。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| d | 需要转换为规定格式的日期 | 可以为DATETIME类型或者可以强转的日期字符串。不支持大对象类型。 | 表达式 |
| format | 需要返回的日期格式 | 可取值为: %a 缩写星期名 %b 缩写月分名 %C 表示为整数(00 至 99)的世纪数值(年份除以 100 并截断为整数) %D 与 %m/%d/%y 格式相同 %e 月的天,数值(0-31) %A 完整的星期名称 %B 完整的月份名称 %d 以整数(01 至 31)表示的该月的日期。在单一位的值之前添零(0)。 %Y 4 位十进制数值的年份 %R 24 小时表示法的时间(等同于 %H:%M 格式,如下面定义的那样) %Fn 秒的小数部分的值,由无符号的整数 n 指定精度。n 的缺省值为 2;n 的范围为 0 ≤ n ≤ 5。此值覆盖在 % 与 F 字符之间指定的任何宽度或精度 %h 与%b格式相同,缩写的月份名称 %H 小时(00-23) %I 2位整数表示的小时(00 至 11) %m 整数表示的月份(01 至 12)。任何单一位值之前添加零(0)。 %M 2 位整数表示的分钟(00 至 59) %S 2 位整数表示的秒(00 至 61)。秒值可达到 61(而不是 59),以允许偶然的跳跃秒或 双跳跃秒。 %T %H:%M:%S 格式的时间 %w 数值表示的星期(0 至 6);0 表示等同于星期日的语言环境。 %y 2 位十进制数值表示的年份。 %p 上午或下午 %r 时间,24-小时(hh:mm:ss) %u 数值表示的星期(0 至 6) | 表达式 |
例如,查看当前日期的缩写星期名 :
select date_format(sysdate,'%a') from dual;
(EXPRESSION)
1 row(s) retrieved.
说明及限制:
- 参数d不支持datetime、date关键字。
IS_DATE函数
ISDATE 函数判断给定表达式是否为有效的日期时间。若判断为有效日期时间,返回 1,反之返回 0。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 需要判断是否为有效日期的表达式 | 不支持大对象类型、布尔类型、集合类型。 | 表达式 |
例如,判断 current 函数返回值是否为日期值:
select isdate(current) from dual;
(expression)|
------------+
1|
DAY 函数
DAY 函数采用 DATE 或 DATETIME 参数,并返回该月的日期作为取值范围从 1 至当前月中天数的一个整数。
下列语句片段调用带有 CURRENT 函数的作为参数的 DAY 函数,比较 order_date 列值与该月的当前日期:
WHERE DAY(order_date) > DAY(CURRENT)
DAYNAME函数
DAYNAME函数返回日期的星期名称。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算星期名称的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年12月12日是星期几:
select dayname('2023-12-12') from dual;
(constant) 星期二
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
DAYOFMONTH函数
DAYOFMONTH 函数返回日期为所在月份的第几天。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算为该月第几天的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年12月12日是12月的第几天:
select dayofmonth('2023-12-12') from dual;
(constant) 12
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
DAYOFWEEK函数
DAYOFWEEK 函数返回日期为所在星期的第几天。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算为该星期第几天的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年12月12日是该周的第几天:
select dayofweek('2023-12-12') from dual;
(constant) 3
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
DAYOFYEAR函数
DAYOFYEAR 函数返回日期为所在年中的第几天。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算为该年第几天的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年12月12日是该年的第几天:
select dayofmonth('2023-12-12') from dual;
(constant) 346
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
DAYS_BETWEEN函数
DAYS_BETWEEN函数返回两个日期之间相差的天数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dt1,dt2 | 需要计算相差天数的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年11月13日和2023年12月12日相差多少天:
SELECT DAYS_BETWEEN('2023-11-13','2023-12-12') from dual;
(constant)
-29
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
FROM_UNIXTIME函数
FROM_UNIXTIME函数返回将自'1970-01-01 00:00:00'的秒数差转成本地会话时区的时间戳类型。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| unixtime | 需要转换成本地会话时区的时间戳类型的秒数 | 支持int类型或者可以隐式转换成int类型的其他数据类型。取值范围为【-2147483647~2147483647】。参数unixtime为小数时,取整后计算返回结果。参数unixtime为负数时,返回'1970-01-01 00:00:00'减去unixtime秒后的时间戳。 | 表达式 |
例如,查看10000秒与'1970-01-01 00:00:00'的秒数差转成本地会话时区的时间戳:
select from_unixtime(10000) from dual;
(EXPRESSION) 1970-01-01 10\:46\:40
1 row(s) retrieved.
说明及限制:
- 参数unixtime为NULL时,返回NULL。
FROM_TZ函数
把一个时间戳和时区数据转化为TIMESTAMP WITH TIME ZONE类型的数据。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| timestamp_expr | 日期格式字符串 | 只支持yyyy-mm-ddhh24:mi:ss.ff格式 | 字符串 |
| timezone_expr | 时区格式字符串 | 只支持tzh:tzm格式 | 字符串 |
例如:将时间戳2000-03-28 08:00:00置于 +3:0时区后的结果。
> SELECT FROM_TZ(TIMESTAMP '2000-03-28 08\:00\:00', '+3:00') FROM DUAL;
(CONSTANT)
2000-03-28 08\:00\:00.00000 +03:00
1 row(s) retrieved.
Elapsed time: 0.001 sec
说明及限制:
- oracle模式下运行
GETDATE函数
GETDATE 函数返回系统的当前时间戳值。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 指定小数秒精度 | 该参数兼容使用,实际无效果。可以为任意数值类型。 | 表达式 |
例如,返回当前系统时间:
select getdate() from dual;
(constant) |
-----------------------+
2024-03-01 09\:49\:22.000|
HOUR函数
HOUR函数返回时间中的小时分量。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| time | 需要返回小时分量的时间 | 支持DATETIME 表达式、可强转的时间字符串。 | 表达式 |
例如,计算当前时间的小时分量:
select hour(sysdate) from dual;
(EXPRESSION)
15
1 row(s) retrieved.
说明及限制:
- 参数time为NULL时,返回NULL。
LOCAL_TIMESTAMP 函数
在数据类型 TIMESTAMP 的值中返回会话时区中的当前日期和时间。
LOCAL_TIMESTAMP 函数
![]()
此函数与 CURRENT_TIMESTAMP 之间的不同在于,LOCALTIMESTAMP 返回 TIMESTAMP 值,而 CURRENT_TIMESTAMP 返回 TIMESTAMP WITH TIME ZONE 值。
MONTH 函数
MONTH 函数返回对应于它的 DATE 或 DATETIME 参数的 month 部分的整数。
像 DAY、YEAR、WEEKDAY 和 QUARTER 内建的时间函数一样,MONTH 函数从作为它的参数的单个 DATE 或 DATETIME 表达式抽取信息。返回值是在日历年中月份序列内 month 的顺序位置。例如,在 9 月 23 日,该函数表达式 MONTH(TODAY) 返回 9。
下列示例返回取值范围从 1 至 12 的一个数值来表示下订单的月份:
SELECT order_num, MONTH(order_date) FROM orders;
LOCALTIME函数
LOCALTIME 函数返回系统当前时间(时分秒)。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 参数可选,用于指定小数秒精度。 | 该参数兼容使用,实际无效果。可以为任意数值类型。 | 表达式 |
例如,返回当前系统时间的时分秒值:
select localtime() from dual;
(constant)
16:10:13
MONTHNAME函数
MONTH_NAME 函数返回日期中月份分量的名称。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算相差天数的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,zh_CN.utf8字符集下查看当前日期的月份分量 :
SELECT MONTHNAME(sysdate) from dual;
(expression) 三月
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
- en_us.819字符集下返回结果为英文,zh_cn.utf8字符集返回结果为中文,zh_CN.GB18030-2000字符集返回结果为阿拉伯数字加月,如1月;
MINUTE函数
MINUTE 函数返回时间中的分钟分量。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| time | 需要返回分钟分量的时间 | 支持DATETIME 表达式、可强转的时间字符串。 | 表达式 |
例如,计算当前时间的分钟分量:
select minute(sysdate) from dual;
(EXPRESSION)
20
1 row(s) retrieved.
说明及限制:
- 参数time为NULL时,返回NULL。
WEEK函数
WEEK 函数返回指定日期属于所在年中的第几周。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date | 需要计算当前为所在年的第几周的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
| mode | 需要设定的周起始规则 | 参数可选。支持int类型或者可以强转为int类型的其他数据类型。取值范围为-2,147,483,647-2,147,483,647。 | 表达式 |
| mode 值 | 周起始 | 返回值范围 | 说明 |
|---|---|---|---|
| 0 | 周日 | 0~53 | 本年第一个周日开始为第 1 周,之前算本年第 0 周 |
| 1 | 周一 | 0~53 | 本年第一个周一之前如果超过 3 天则算第 1 周,否则算第 0 周 |
| 2 | 周日 | 1~53 | 本年第一个周日开始为第 1 周,之前算去年第 5x 周 |
| 3 | 周一 | 1~53 | 本年第一个周一之前如果超过 3 天则算第 1 周,否则算去年第 5x 周;年末不足 4 天算明年第 1 周 |
| 4 | 周日 | 0~53 | 本年第一个周日之前如果超过 3 天则算第 1 周,否则算第 0 周 |
| 5 | 周一 | 0~53 | 本年第一个周一开始为第 1 周,之前算本年第 0 周 |
| 6 | 周日 | 1~53 | 本年第一个周日之前如果超过 3 天则算第 1 周,否则算去年第 5x 周;年末不足 4 天算明年第 1 周 |
| 7 | 周一 | 1~53 | 本年第一个周一开始为第 1 周,之前算去年第 5x 周 |
例如,查看当前日期在mode为7的情况下为今年的第几周:
select week(sysdate,7) from dual;
(CONSTANT)
10
1 row(s) retrieved.
说明及限制:
- 参数date为NULL时,返回NULL。
- 根据mode不同,计算周数的方式不同,结果不同。
WEEKS_BETWEEN函数
WEEKS_BETWEEN函数返回两个日期之间相差的周数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dt1,dt2 | 需要计算相差周数的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年11月13日和2023年12月12日相差多少天:
SELECT WEEKS_BETWEEN('2023-11-13','2024-12-12') from dual;
(constant)
-56
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
SEC_TO_TIME函数
SEC_TO_TIME 函数将秒数换算成时间。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| sec | 需要转换成时间的秒数 | 支持decimal类型或者可以隐式转换成decimal类型的其他数据类型。sec取值范围为【-2147483647~ 2147483647】。sec为小数时,取整后进行计算。sec为负数时,取绝对值进行计算。 | 表达式 |
例如,计算12345秒为多长时间:
select sec_to_time(12345) from dual;
(CONSTANT) 03:25:45
1 row(s) retrieved.
说明及限制:
- 参数sec为NULL时,返回NULL。
SECOND函数
SECOND 函数返回时间中的秒分量。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| time | 需要返回秒分量的时间 | 支持DATETIME 表达式、可强转的时间字符串。 | 表达式 |
例如,计算当前时间的秒分量:
select second(sysdate) from dual;
(EXPRESSION)
24
1 row(s) retrieved.
说明及限制:
- 参数time为NULL时,返回NULL。
TIME_TO_SEC函数
TIME_TO_SEC函数将时间换算成秒。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| d | 需要计算秒数的时间 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。d的取值范围为【0001-1-1 00:00:00~ 9999-12-31 23:59:59】。 | 表达式 |
例如,计算2024-12-12 00:34:21为多少秒:
select time_to_sec( '2024-12-12 00\:34\:21') from dual;
(CONSTANT)
2061
1 row(s) retrieved.
说明及限制:
- 参数d为NULL时,返回NULL。
- 返回值有小数时,进行取整并返回结果。
QUARTER 函数
QUARTER 函数返回一个取值范围从 1 至 4 的整数,对应于包括它的 DATE 或 DATETIME 参数的那个日历年的季度。
例如,一月、二月或三月中的任何日期都返回整数 1。
该参数必须为求值为 DATE 或 DATETIME 数据类型的表达式。
QUARTER 函数表达式的示例
下列函数表达式返回 3,因为八月在一年中的第三个季度中。
QUARTER('2014-08-25')
下列示例返回取值范围可从 1 至 4 的一个数值,来表明下订单时的季度:
SELECT order_num, QUARTER(order_date) FROM orders;
下列查询包括 QUARTER 函数表达式,其参数为 order_date 列和 CURRENT 运算符。WHERE 子句将结果集限定为 order_date 值所在季度早于当前年当前季度的那些行:
SELECT * FROM orders
WHERE (QUARTER(order_date) < QUARTER(CURRENT))
AND YEAR(order_date) = YEAR(CURRENT);
然而,在第一季度期间,此查询不返回行,因为从小于当前季度的季度里,不可有数据。也就是说,没有值为零的季度。
WEEKDAY 函数
WEEKDAY 函数接受 DATE 或 DATETIME 参数,并返回取值范围从 0 至 6 代表星期几的整数。
作为返回值,零(0)代表星期天,一(1)代表星期一,以此类推。
下列查询返回与当前日期相同的星期几支付了的所有订单:
SELECT * FROM orders
WHERE WEEKDAY(paid_date) = WEEKDAY(CURRENT);
YEAR 函数
YEAR 函数采用 DATE 或 DATETIME 参数,并返回表示该年的四位整数。
下列示例罗列了其 ship_date 早于当前年初的订单:
SELECT order_num, customer_num FROM orders
WHERE year(ship_date) < YEAR(TODAY);
类似地,由于 DATE 值是一个简单的日历日期,您不可以一个其 last 限定符小于那个 DAY 的 INTERVAL 值来加上或减去一个 DATE 值。在此情况下,请将 DATE 值转换为 DATETIME 值。
YEARS_BETWEEN函数
YEARS_BETWEEN函数返回两个日期之间相差的年数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dt1,dt2 | 需要计算相差年数的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年11月13日和2024年12月12日相差多少天:
SELECT YEARS_BETWEEN('2023-11-13','2024-12-12') from dual;
(CONSTANT)
-1
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
MONTHS_BETWEEN 函数
MONTHS_BETWEEN 函数接受两个 DATE 或 DATETIME 表达式参数,并返回一个带符号的 DECIMAL 值,该值量化这些参数之间的月数间隔,就好像 month 是时间的单位一样。
此函数需要两个参数,每一参数可为 DATE 表达式或 DATETIME 表达式。
返回的值为 DECIMAL 数据类型,表示两个参数之间的差异,表达为基于 31 天为单位的 DECIMAL 值。如果第一个参数是晚于第二个参数的时间点,则返回的值的符号为正。如果第一个参数早于第二个参数,则返回的值的符号为负。如果两个参数相等,则返回值为零。
如果两个参数的日期都是一个月的同一天,或都是一个月的最后一天,则结果为整数。否则,基于一个月 31 天,来计算结果的小数部分。此小数部分还可包括 hour、minute 和 second 时间单位中的差异,除非两个参数都是 DATE 表达式。
下列查询使用通过 TO_DATE 表达式作为参数返回的两个 DATE 值,调用 Projection 子句中的 MONTHS_BETWEEN 函数。
SELECT MONTHS_BETWEEN(TO_DATE('2-2-2005', '%m-%d-%Y'),
TO_DATE('1-1-2005', '%m-%d-%Y'))
AS lunations FROM systables WHERE tabid = 1;
该查询返回的值表示两个 DATE 参数之间有 32 天的差异,作为 31 天月份的正值:
months
1.03225806451613
下一示例将 DATETIME 列表达式参数返回到 MONTHS_BETWEEN 表达式,以及对于表的两行,它们的以月计算的差异:
SELECT d_datetime, e_datetime,
MONTHS_BETWEEN(d_datetime, e_datetime) AS months_between
FROM mytab1;
d_datetime 2007-11-01 09\:00\:00.00000
e_datetime 2007-12-07 14\:30\:12.12345
months_between -1.2009453405018
d_datetime 2007-12-13 09\:40\:30.00000
e_datetime 2007-11-13 08\:40\:30.00000
months_between 1.00000000000000
在此,第一个 MONTHS_BETWEEN 结果包括以小于天的时间单位计的差异。第二个结果没有小数部分,因为两个参数的 day 时间单位有相同的值。
下一示例中的 MONTHS_BETWEEN 表达式比较 DATE 与 DATETIME 值:
SELECT col_datetime, col_date, MONTHS_BETWEEN(col_datetime, col_date) AS months_between
FROM mytab2;
col_datetime 2008-12-13 08\:40\:30.00000
col_date 11/13/2007
months_between 13.0000000000000
由于两个参数指定该月的同一天,因此结果没有小数部分。
LAST_DAY 函数
LAST_DAY 函数需要一个 DATE 或 DATETIME 表达式作为它的唯一参数。它返回它的参数指定的那个月的最后一天的日期。
此返回的值的数据类型与参数的数据类型相同。返回的值与参数之间的差为那个月剩余的天数。
下列查询返回当前日期的 DATE 表示、当前月中最后一天的日期,以及当前月中最后一天之前的天数(由第二个 DATE 值减去第一个计算):
SELECT TODAY AS today, LAST_DAY(TODAY) AS last,
LAST_DAY(TODAY) - TODAY AS days_left
FROM systables WHERE tabid = 1;
如果在 2008 年 3 月 12 日发出了该查询,以 MDY4/ 作为缺省的语言环境的 DBDATE 设置,则它会返回下列信息:
today last days_left
03/12/2008 03/31/2008 19
在此示例的 SELECT 语句中,在 Projection 子句中 TODAY 运算符与标识符 today 之间没有名称冲突,因为 AS 关键字向 GBase 8s 表明 today 为一显示标签。
如果您使用主变量来存储 LAST_DAY 的参数,但在准备时刻不知道该参数的数据类型,则 GBase 8s 假设该数据类型为 DATETIME YEAR TO FRACTION(5)。如果在运行时刻,在已准备了该语句之后,用户为该主变量提供 DATE 值,则发出错误 -9750。要防止发生此错误,请通过使用强制转型来指定该主变量的数据类型,如在此程序片段中所示:
sprintf(query, ",
"select last_day(?::date) from mytab");
EXEC SQL prepare selectq from :query;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor using :hostvar_date_input;
EXEC SQL fetch select_cursor into :var_date_output;
NEXT_DAY 函数
NEXT_DAY 函数返回晚于它的第一个 DATE 或 DATETIME 参数的最早的日期,并落在它的第二个参数指定的星期几上。第二个参数是三个 ASCII 字符的加引号的字符串,是星期几的英文名称缩写。
NEXT_DAY 函数需要两个参数:
- 求值为早于该返回值的日期的 DATE 或 DATETIME 表达式。
- 至少三个 ASCII 字符的字符串。这三个字母编码为星期几的英文名称缩写。
成功地执行此函数,返回满足两个条件的最早的日历日期:
- 该日期晚于第一个参数指定的日期。
- 该日期落在第二个参数指定的星期几上。
NEXT_DAY 接受下列星期几的缩写字符串:
| 星期 | 缩写 | 星期 | 缩写 |
|---|---|---|---|
| 星期日 | 'SUN' | 星期三 | 'WED' |
| 星期一 | 'MON' | 星期四 | 'THU' |
| 星期二 | 'TUE' | 星期五 | 'FRI' |
| 星期六 | 'SAT' |
忽略跟在这些缩写字符串的第三个字符之后的任何字符。例如,对于第二个参数,'MONDAY' 和 'MONTAG' 都是有效的规范,每一都指定在第一个参数的日期之后的星期一。然而,如果第二个字符串的前三个字符不与上表中星期缩写之一相匹配,比如 'MODNAY', 则 GBase 8s 发出错误。
NEXT_DAY 也接受数字1-7:
| 星期 | 数字 | 星期 | 数字 |
|---|---|---|---|
| 星期日 | 1 | 星期三 | 4 |
| 星期一 | 2 | 星期四 | 5 |
| 星期二 | 3 | 星期五 | 6 |
| 星期六 | 7 |
例如,下列查询包括有效的 NEXT_DAY 表达式:
SELECT ship_date, NEXT_DAY(ship_date, 'SAT') AS next_saturday,
NEXT_DAY(ship_date, 'SAT') - ship_date AS num_days FROM orders;
此查询的结果集可能包括来自 orders 表的下列数据:
ship_date next_saturday num_days
06/01/2006 06/03/2006 2
02/12/2007 02/17/2007 5
05/31/2007 06/02/2007 2
05/23/2007 05/26/2007 3
由 NEXT_DAY 返回的值与第一个参数有相同的数据类型。如果此参数为 DATE 类型,则 NEXT_DAY 返回 DATE 值。如果第一个参数为 DATETIME 类型,则 NEXT_DAY 返回 DATETIME YEAR TO FRACTION(5) 值。
由于在前面示例中的 ship_date 是 DATE 列,所以返回的日期格式化为 DATE 值,而不是 DATETIME 格式。
如果您使用主变量来存储 NEXT_DAY 的参数,但在准备时刻不知道该参数的数据类型,则 GBase 8s 假设该数据类型为 DATETIME YEAR TO FRACTION(5)。如果在运行时刻,在已准备了该语句之后,用户为主变量提供 DATE 值,则发出错误 -9750。要避免这种错误,请使用强制转型来指定该主变量的类型,如此程序片段中所示:
sprintf(query, ", "select next_day(?::date, 'SUN') from mytab");
EXEC SQL prepare selectq from :query;
EXEC SQL declare select_cursor cursor for selectq;
EXEC SQL open select_cursor using :hostvar_date_input;
EXEC SQL fetch select_cursor into :var_date_output;
EXTEND 函数
EXTEND 函数调整 DATETIME 或 DATE 值的精度。
作为它的第一个参数的 DATETIME 或 DATE 表达式不可为 DATE 值的加引号的字符串表示。
如果您未指定 first 和 last 限定符,则缺省的限定符为 YEAR TO FRACTION(3)。
如果表达式包含未通过时间单位限定符指定的字段,则丢弃那些字段。
如果 first 限定符指定比表达式中存在的更大的(即,更多有效位的)时间单位,则以 CURRENT 函数返回的值填充新的字段。如果 last 限定符比表达式中存在的更小的(即,更少有效位的)时间单位,则以常量值填充新的字段。以 1 填充丢失的 MONTH 或 DAY 字段,且以 0 填充丢失的 HOUR 或 FRACTION 字段。
在下列表达式中,EXTEND 调用返回带有 YEAR TO SECOND 表达式的 call_dtime 列值:
EXTEND (call_dtime, YEAR TO SECOND)
您可使用 EXTEND 函数来执行 DATETIME 值与没有相同时间单位限定符的 INTERVAL 值的加法或减法。下一表达式将文字的 DATETIME YEAR TO DAY 值扩展为 YEAR TO MINUTE 精度,因而可从它减去间隔的 YEAR TO MINUTE 值:
EXTEND (DATETIME (2009-8-1) YEAR TO DAY, YEAR TO MINUTE)
- INTERVAL (720) MINUTE (3) TO MINUTE
您可使用 EXTEND 函数来选择性地更新 DATETIME 值中时间单位的子集。在下一示例中的 UPDATE 语句仅更新 DATETIME YEAR TO MINUTE 列中的 hour 和 minute 时间单位值。
UPDATE cust_calls SET call_dtime = call_dtime -
(EXTEND(call_dtime, HOUR TO MINUTE) - DATETIME (11:00)
HOUR TO MINUTE) WHERE customer_num = 106;
从由 EXTEND 返回的 DATETIME HOUR TO MINUTE 值中减去 11:00 生成一个正的或负的 INTERVAL HOUR TO MINUTE 值。从 call_dtime 列中原始的值减去此差异,在 cust_calls.call_dtime 列中将更新的 hour 和 minute 时间单位值强制为 11:00。
MDY 函数
MDY 函数将表示 month、day 和 year 的三个整数表达式作为它的参数,并返回类型 DATE 值。
- 第一个参数表示月份的数值(1 至 12)。
- 第二个参数表示该月的日期的数值(1 至 28、29、30 或 31,与月份相对应)。
- 第三个参数表示 4 位的年份。您不可使用 2 位缩写。
UPDATE 语句中 MDY 函数的示例
下列示例更新 orders 表中的一行,将其采购订单号为 8052 的 paid_date 列值更改为当前月的第一天:
UPDATE orders SET paid_date = MDY(MONTH(TODAY), 1, YEAR(TODAY))
WHERE po_num = '8052';
在此,MDY 函数的第一个和最后一个参数是返回对应于当前的 month 和 year 的整数的时间表达式。第二个参数指定该月的日期为以文字整数。颠倒此示例中前两个参数的顺序,会将 paid_date 更改为当前年的 1 月 13 日之前的某一天,除非同一应用还包括了错误检查代码,标识那个时期过早,不是有效的。
GBASE_TO_CHAR 函数
GBASE_TO_CHAR 函数将一求值为 DATE、DATETIME 或数值值的表达式转换为字符串。
返回的字符串表示第一个参数指定的数据值,使用第二个参数在 format_string 中定义的格式掩码,可包括特殊的格式符号和文字字符。
- 此函数的第一个参数必须为 DATE、DATETIME 或内建的数值数据类型,或可转换为这些数据类型之一的字符串。如果初始的 DATE、DATETIME 或数值参数的值为 NULL,则该函数返回 NULL 值。
- 此函数的第二个参数是指定格式掩码的字符串。哪些特殊的字符适合于格式掩码,主要依赖于 GBASE_TO_CHAR 函数的第一个参数是表示时间点还是数值。
格式化 DATE 和 DATETIME 表达式
format_string 参数不需要隐含与 GBASE_TO_CHAR 函数的第一个参数中的值相同的时间单位。当 format_string 中隐含的精度与第一个参数中的 DATETIME 限定符不同时,GBASE_TO_CHAR 函数扩展 DATETIME 值,就如同它已调用了 EXTEND 函数。
在下列示例中,用户想要将 tab1 表的 begin_date 列转换为字符串。begin_date 列定义为 DATETIME YEAR TO SECOND 数据类型。用户使用带有 GBASE_TO_CHAR函数的 SELECT 语句来执行此转换:
SELECT GBASE_TO_CHAR(begin_date, '%A %B %d, %Y %R') FROM tab1;
此示例的 format_string 中的符号有下列含义。
符号 含义
%A 完整的星期名称,如在语言环境中定义的那样
%B 完整的月份名称,如在语言环境中定义的那样
%d 以整数(01 至 31)表示的该月的日期。在单一位的值之前添零(0)。
%Y 4 位十进制数值的年份
%R 24 小时表示法的时间(等同于 %H:%M 格式,如下面定义的那样)。
在上例中紧跟在 %d 格式规范之后的逗号(,)是文字字符,而不是 GBASE_TO_CHAR 函数的参数的分隔符。第二个参数是引号括起的字符串 '%A %B %d, %Y %R',定义 TO_CHAR 返回的值中表示第一个参数的格式掩码。
将此 format_string 应用于 begin_date 列值,返回此结果:
Wednesday July 25, 2013 18:45
下例中的查询调用 TO_CHAR 来将同一格式字符串应用于 ADD_MONTHS 表达式,并展示该查询的结果:
SELECT ship_date, GBASE_TO_CHAR(ADD_MONTHS(ship_date, 1), '%A %B %d, %Y')
AS survey_date FROM orders;
ship_date 03/12/2013
survey_date Thursday April 12, 2013
在以上的查询输出中,
- 根据 DB_DATE 环境变量设置格式化 ship_date 值,
- 并根据 GBASE_TO_CHAR 函数的 '%A %B %d, %Y %R' 格式字符串参数格式化 survey_date 值。
对于 DATE 或 DATETIME 值,在 GBASE_TO_CHAR 函数的 format_string 参数中附加的有效字符包括下列。
符号 含义
%a 缩写的星期名称,如在语言环境中定义的那样
%b 缩写的月份名称,如在语言环境中定义的那样
%C 表示为整数(00 至 99)的世纪数值(年份除以 100 并截断为整数)
%D 与 %m/%d/%y 格式相同
%e 数值表示的该月的日期(1 至 31)。单一位值之前添加一空格。
%Fn 秒的小数部分的值,由无符号的整数 n 指定精度。n 的缺省值为 2;n 的范围为 0 ≤ n ≤ 5。此值覆盖在 % 与 F 字符之间指定的任何宽度或精度。
%h 与 %b 格式相同:缩写的月份名称,如在语言环境中定义的那样
%H 2 位整数表示的小时(00 至 23)(24 小时时钟)
%I 2 为整数表示的小时(00 至 11)(12 小时时钟)
%m 整数表示的月份(01 至 12)。任何单一位值之前添加零(0)。
%M 2 位整数表示的分钟(00 至 59)
%S 2 位整数表示的秒(00 至 61)。秒值可达到 61(而不是 59),以允许偶然的跳跃秒或双跳跃秒。
%T %H:%M:%S 格式的时间
%w 数值表示的星期(0 至 6);0 表示等同于星期日的语言环境。
%y 2 位十进制数值表示的年份。
例如,假设在 2013 年 8 月 23 日,DB-Access 实用程序发出了下列查询:
SELECT GBASE_TO_CHAR(CURRENT YEAR TO FRACTION(5), "%Y-%m-%d %H:%M:%S.%F")
FROM sysmaster:sysdual;
在此示例中,格式字符串参数以下列文字字符作为 DATETIME 字段值之间的分隔符指定用户格式:
- ASCII 45 ( - ) 连字符分隔年、月和日值
- ASCII 32 ( ) 空格分隔开日期与小时
- ASCII 58 ( : ) 冒号分隔时、分和秒
- ASCII 46 ( . ) 句号分隔秒与秒的小数部分。
这是以指定的 DATETIME 用户格式返回的值:
(expression) 2013-08-23 13\:15\:53.00
当 DATETIME 或 DATE 表达式是第一个参数时,如果您省略 format_string 参数,则 TO_CHAR 函数使用 DBTIME 或 DBDATE 环境变量的设置作为缺省值,来格式化在第一个参数中表示的值。在非缺省的语言环境中,通过诸如 GL_DATETIME 和 GL_DATE 这样的环境变量指定 DATETIME 和 DATE 值的缺省格式。
对于其精度包括 SECOND 和 FRACTION 数据值的 DATETIME 用户格式,连接那些字段,除非在 %S 与 %F 格式伪指令之间显式地定义分隔符字符。在版本 11.70.xC7 以及更早的 GBase 8s 产品中,在缺省情况下, %F 伪指令在 SECOND 与 FRACTION 字段值之间插入了 ASCII 46 字符(.)。然而,在此产品中,%F 伪指令为隐含缺省的分隔符。
要了解那些可为内建的按时间顺序排列的数据类型指定显示和数据条目格式的 GBase 8s 环境变量之中的优先顺序,请参阅主题 DATE 和 DATETIME 格式规范的优先顺序。
格式化数值的和 MONEY 表达式
GBASE_TO_CHAR 函数的 format_string 参数支持与 ESQL 函数使用的相同的数值格式掩码,比如 rfmtdec( )、rfmtdouble( ) 和 rfmtlong( )。 在 GBase 8s ESQL/C 程序员手册 中,是对数值值(当将数值表达式格式化为字符串时)的 GBase 8s 数值格式掩码的详尽描述。以下是数值格式掩码的简短总结描述。
当将数值表达式格式化为字符串时,数值格式掩码指定应用于某数值值的格式。此掩码是下列格式化字符的组合:
符号 含义
* 此字符以星号填充本来为空的显示字段中的任何位置
& 此字符以零填充本来为空的显示字段中的任何位置
# 此字符将开始的零更改为空格。使用此字符来指定字段向左边的最大扩展。
< 此字符对显示字段总的数值进行左调整。它将开始的零更改为 NULL 字符串。
, 此字符表明在值的整数部分按三位一组(从单位位置向左数)分隔的符号。在缺省情况下,此符号为逗号。您可以 DBMONEY 环境变量设置该符号。在格式化了的数值中,仅当该值的整数部分有四位或更多位时才出现此符号。
. 此字符表明将货币值的整数部分与小数部分分隔的符号。在缺省情况下,此符号为句号。您可以 DBMONEY 环境变量设置该符号。在格式字符串中,您仅可有一个句号。
- 此字符为文字字符。当 expr1 小于零时,它作为负号出现。当您将一行中的几个负号(-)分组时,单个负号浮动到它可占据的最右边的位置;它不影响数值及其币种符号。
+ 此字符为文字字符。当 expr1 大于或等于零时,它作为正号出现。当您在将一行中的几个正号分组时,单个加号或减号浮动到它可占据的最右边的位置;它不影响数值及其币种符号。
( 此字符为文字字符。它作为负数值的左边的左圆括号(()出现。它是替换负数的减号的一对会计圆括号之一。当您对一行中的几个分组时,单个左圆括号浮动到它可占据的最右边的位置;它不影响数值及其币种符号。
) 这是替换负值的减号的一对会计圆括号之一。
$ 此字符显示在数值值前面的币种符号。在缺省的语言环境中,币种符号是美元号($)。您可以 DBMONEY 环境变量设置非缺省的币种符号。当您将一行中的几个美元号分组时,单个币种符号浮动到它可占据的最右边的位置;它不影响该数值。
在 GBASE_TO_CHAR 函数返回的格式化的值中,按字面重新产生格式掩码中的任何其他字符。
在下面的三个示例中,GBASE_TO_CHAR 的 d_int 列表达式参数的值为 -12344455。
此查询在 GBASE_TO_CHAR 的调用中未指定格式掩码:
SELECT GBASE_TO_CHAR(d_int) FROM tab_numbers;
下列表格展示此 SELECT 语句的输出。
(expression)
-12344455
下列查询指定货币格式掩码:
SELECT GBASE_TO_CHAR(d_int, "$*********.**") FROM tab_numbers;
下列表格展示此 SELECT 语句的输出。
(expression)
$12344455.00
SELECT GBASE_TO_CHAR(d_int, "-$\*\*\*\*\*\*\*\*\*.\*\*") FROM tab_numbers;
该查询返回 - $12344455.00。
SELECT GBASE_TO_CHAR(12344455,"-$\*\*\*\*\*\*\*\*\*.\*\*") FROM tab_numbers;
下列表格展示此 SELECT 语句的输出。
(constant)
$12344455.00
应用来自格式掩码参数的币种($)符号,但减号(-)不起作用,因为第一个参数的值大于零。
请注意,当 GBASE_TO_CHAR 函数的第一个参数是 DATE 或 DATETIME 表达式时,它是时间表达式,或是可被格式化为 DATE 或 DATETIME 表达式的字符串。然而,当它的第一个参数是数值或货币值时,GBASE_TO_CHAR 返回那个参数的值的字符串形式,但它不返回时间表达式。
TO_CHAR 函数
TO_CHAR 函数将一求值为 DATE、DATETIME 或数值值的表达式转换为字符串。
语法

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date/dtime_expr | 返回 DATE 或 DATETIME、TIMESTAMP、TIMESTAMP WITH TIME ZONE 值的表达式 | 可为主变量、表达式、列或常量。 | 表达式 |
| num_expr | 要转换为字符串的数值型数据 | 可为主变量、表达式、列或常量。 | 表达式 |
| format_string | 指定的格式化字符串 | 为指定有效的格式的字符数据类型。可为列、主变量、表达式或常量。支持省略。 | 引用字符串 |
在下面的示例中,TO_CHAR() 的 numcol 列表达式参数的值为13。
SELECT TO_CHAR(numcol) FROM tab1;
返回结果为:13
TO_CHAR(datetime):转换日期型表达式
TO_CAHR(datetime)将日期类型 DATE、DATETIME、TIMESTAMP 表达式转换为 format_string 参数中指定格式的 VARCHAR 类型值。
对于日期数据类型,TO_CHAR 函数的 format_string 参数有效的日期元素如下:
| 元素 | 含义(范围) |
|---|---|
| / - ,. : | 标点符号在结果中重新复制 |
| YYYY | 4 位的年份 |
| YY | 年份的最后 2 位数字 |
| MM | 月份(01-12) |
| DD | 月中的某一天(01—31) |
| HH、HH12 | 12 小时制(00—12) |
| HH24 | 24 小时制(00—24) |
| MI | 分(00——59) |
| SS | 秒(00—59) |
| FF[n] | 亚秒,n 的取值范围为1—6 |
缺省的转换形式为:YYY-MM-DD HH:MI:SS。
示例
SELECT TO_CHAR(SYSDATE, "YYYYMMDD") FROM DUAL;
返回结果为:20180520
SELECT TO_CHAR(SYSDATE, "YYYY-MM-DD HH24:MI:SS") FROM DUAL;
返回结果为:2018-05-20 14:30:28
SELECT TO_CHAR(SYSDATE, "YYYY/MM/DD HH:MI:SS") FROM DUAL;
返回结果为:2018/05/20 02:30:30
TO_CHAR(number):转换数值型表达式
TO_CAHR(number)将数值型数据num_expr 转换为 format_string 参数指定的格式的字符串。
其用法与 GBASE_TO_CHAR() 函数的转换数值表达式为字符串的用法相同。具体信息,请参见 GBASE_TO_CHAR() 函数。
GBASE_TO_DATE 函数
GBASE_TO_DATE 函数将字符串转换为 DATETIME 值。该函数根据 format_string 第二个参数指定的日期格式,将 char_expression 第一个参数求值为日期,并返回等同的日期。
如果 char_expression 为 NULL,则返回 NULL 值。
GBASE_TO_DATE 函数的任何参数都必须为内建的数据类型。
如果您省略 format_string 参数,则 GBASE_TO_DATE 函数将缺省的 DATETIME 格式应用于该 DATETIME 值。通过 GL_DATETIME 环境变量指定缺省的 DATETIME 格式。
在下列示例中,用户想要将字符串转换为 DATETIME 值,以便以转换了的值来更新 tab1 表的 begin_date 列。begin_date 列定义为 DATETIME YEAR TO SECOND 数据类型。用户使用包含 GBASE_TO_DATE 函数的 UPDATE 语句来实现此结果:
UPDATE tab1
SET begin_date = GBASE_TO_DATE('Wednesday July 25, 2007 18:45','%A %B %d, %Y %R');
在此示例中的 format_string 参数告诉 GBASE_TO_DATE 函数如何格式化 begin_date 列中转化了的字符串。要获取展示在此格式字符串中每一格式符号的作用的表格,请参阅 TO_CHAR 函数。
TO_DATE 函数
TO_DATE 函数将字符串转换为 DATETIME 数据类型。支持转换的字符型数据包括:CHAR、VARCHAR2、NCHAR 或 NVARCHAR2。
TO_DATE 函数有此语法:
TO_DATE 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 要被转换为 DATETIME 类型的源字符串。 | 设置为空字符串或NULL时,返回结果为空 | 引用字符串 |
| fmt | DATETIME 类型的格式化字符串 | 设置为空字符串或NULL时,返回结果为空。 | 引用字符串 |
该函数根据 fmt 第二个参数指定的日期格式,将 source_char 第一个参数求值为日期,并返回等同的日期。
此函数的第一个参数 source_char(源字符串)支持公元、年、月、日、时、分、秒、亚秒等时间格式。通常『年-月-日 时:分:秒』具有的格式如下:
- 年度部分(YYYY):支持1~4位有效数字;
- 月份部分(MM):取值范围为[0,12],0~9支持设置为00~09;
- 日期部分(DD):取值范围为[0,31],0~9支持设置为00~09;
- 小时部分(HH/HH12/HH24):hh/hh12取值范围为[0,12],hh24取值范围为[0,24],0~9均支持设置为00~09;
- 分钟部分(MI):取值范围为[0,59],0~9支持设置为00~09;
- 秒钟部分(SS):取值范围为[0,59],0~9支持设置为00~09。
此函数的第二个参数 fmt(格式化串)设置为:『YYYY-MM-DD HH:MI:SS』,连接字符与源字符串相对应,不区分大小写。使用时,用单(双)引号包围。
在下列示例中,用户输入 SELECT 查询语句,对 TO_DATE 函数进行查询,将字符串转换为 DATETIME 类型。
select to_date(’2017-07-21 13\:33\:24’, ’YYYY-MM-DD HH:MI:SS’);
返回结果为:
2017-07-21 13\:33\:24
如果设置省略参数中对应的元素,则执行结果通过to_char函数展示时包括年、月、日、时、分、秒、亚秒全部信息,显示形式为:年-月-日 时:分:秒.亚秒(2017-07-01 00:00:00.000000)。缺省信息系统自动补齐。缺省‘年’则补齐当前年;缺省‘月’则补齐当前月;缺省‘日’则补齐第一天;缺省‘时’、‘分’、‘秒’则补齐‘00’;缺省‘亚秒’则补齐‘000000’。
例如,在以下示例中,对 TO_DATE 函数进行查询。
select to_date(’07-21’,‘MM-DD’);
返回结果如下:
2017-07-21 00\:00\:00.000000
又如,以下 SQL 语句,对于缺省的‘年、月、日’补齐当前年的当前月的第一天:
select to_date(’13:33’,‘HH:MI’);
返回结果如下:
2017-10-01 13\:33\:00.000000
如果省略 fmt 参数(格式化串),只有当 source_char 参数(源字符串)格式为‘年月日’、‘年月日时分’、‘年月日时分秒’时,TO_DATE 函数执行成功。否则函数执行失败,系统提示错误。
例如,在以下示例中对 TO_DATE 函数进行查询,设置省略 fmt 参数(格式化串)。
select to_date(’2017-07-21 13\:33\:24’);
返回结果如下:
2017-07-21 13\:33\:24.000000
以下语句执行失败。
select to_date(’07-21 13:33:24’);
source_char 参数(源字符串)与 fmt 参数(格式化串)还可以设置为嵌套函数、表达式、字符数据类型列。例如,在以下示例中,将TO_DATE 函数的第二个参数设置为 CAST表达式:
select (to_date(’10-12 23:56:33’, cast(’mm-ddhh12:mi:ss’as char(30))) ;
返回结果如下:
2017-10-12 23\:56\:33.000000
如果 source_char参数(源字符串)与 fmt 参数(格式化串)之间存在连接字符省略的情况,则当源字符串和格式化串省略的位置相同时,TO_DATE 函数执行成功,系统返回正确的结果。例如,
select (to_date(’20110911 23:11:24’,’YYYYMMDD HH:MI:SS ’);
返回结果如下:
2011-09-11 23\:11\:24.000000
而当源字符串的连接字符省略,对应的格式化串中的连字符未省略时,函数执行失败,系统返回错误。例如,以下查询语句执行失败:
select to_date(’201707-21’, ’YYYY-MM-DD HH:MI:SS’);
此外,如果将这两个参数的连接字符设置为数字、字母,TO_DATE 函数会执行失败,系统返回错误。
TO_DAYS函数
TO_DAYS函数返回转换成公元 0 年 1 月 1 日的天数差。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| d | 需要计算天数差的日期 | 支持 DATE 或 DATETIME 表达式、可强转的日期字符串。 | 表达式 |
例如,计算2023年12月12日与公元0年1月1日的天差数:
select to_days('2023-12-12') from dual;
(constant)
739231
1 row(s) retrieved.
说明及限制:
- TO_DAYS中参数为NULL时,返回NULL。
TO_TIMESTAMP函数
TO_TIMESTAMP 函数将字符串转换为 TIMESTAMP 数据类型。支持转换的字符型数据包括:CHAR、VARCHAR、NCHAR 或 NVARCHAR。

该函数根据第二个参数fmt指定的日期格式,将第一个参数source_char求值为TIMESTAMP类型值。
TO_TIMESTAMP函数的使用方法与TO_DATE函数的用法一致。
例如,将字符串转换为TIMESTAMP类型值:
SELECT TO_TIMESTAMP('2021-10-16 13\:33\:24', 'YYYY-MM-DD HH:MI:SS') FROM DUAL;
返回结果为:2021-10-16 13:33:24.00000
TO_TIMESTAMP_TZ 函数
将字符类型(包括CHAR, VARCHAR2, NCHAR, NVARCHAR2 )的数据转化为TIMESTAMP WITH TIME ZONE类型的数据。时区类型的数据会被自动补充,补充规则为:
- 缺少年,补充当前年份。
- 缺少月,补充当前月。
- 缺少日,补充01日。
- 缺少小时,补充00时。
- 缺少分钟,补充00分钟。
- 缺少秒钟,补充00.00000秒。
- 缺失时区,会按照会话所在时区补充。
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| timestamp_tz_expr | 待转化为时区数据的字符串 | 符合日期格式 | 字符串 |
| format_expr | 格式化元素表达式 | 符合时区格式化元素 | 字符串 |
例如:使用以下两种格式转化为TIMESTAMP WITH TIME ZONE的值。
> select to_timestamp_tz('2023-10-23 12\:31\:32','yyyy-mm-dd hh24:mi:ss') from dual;
(CONSTANT)
2023-10-23 12\:31\:32.00000 +08:00
1 row(s) retrieved.
Elapsed time: 0.001 sec
说明及限制:
- oracle模式下运行
CURRENT_DATE函数

返回系统的当前时间。返回类型:datetime year to second。
例如:查看系统当前时间
> select current_date C1 from dual;
C1 2023-12-08 12\:18\:22
1 row(s) retrieved.
CURTIME函数

返回系统的当前时间。返回类型:datetime year to fraction(5)。
例如:查看系统当前时间
> select CURTIME() from dual;
(EXPRESSION)
2024-12-19 16\:02\:06.42832
查询到 1 行。
CURRENT_TIMESTAMP函数

返回系统的当前时间戳。
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 指定小数秒精度 | 必须是整型数值类型[ 0 - 5 ],其他数值范围及浮点类型数均不支持。仅支持常数表达式,不支持科学计数法表示的常,输入参数不能是null | 表达式 |
说明及限制:
- 返回结果相容性数据类型:varchar, char, lvarchar, nchar, nvarchar, character varying, varchar2, datetime year to fraction;
例如:查看系统当前时间戳
> select current_timestamp C1, current_timestamp(3) C2 from dual;
C1 2023-12-04 15\:58\:15.34252
C2 2023-12-04 15\:58\:15.342
1 row(s) retrieved.
CURRENT_TIME函数

返回系统的当前时间。
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 指定小数秒精度 | 必须是整型数值类型[ 0 - 5 ],其他数值范围及浮点类型数均不支持。仅支持常数表达式,不支持科学计数法表示的常,输入参数不能是null | 表达式 |
说明及限制:
- 返回结果相容性数据类型:varchar, char, lvarchar, nchar, nvarchar, character varying, varchar2, datetime year to fraction;
例如:查看系统当前时间
> select current_time() from dual;
(EXPRESSION)
15:53:13.23411
查询到 1 行。
NOW函数
返回系统的当前时间。

说明及限制:
- 返回结果相容性数据类型:varchar, char, lvarchar, nchar, nvarchar, character varying, varchar2, datetime year to fraction;
例如:查看系统当前时间
> select now() from dual;
(EXPRESSION)
15:53:13.23411
查询到 1 行。
EXTRACT (datetime)函数
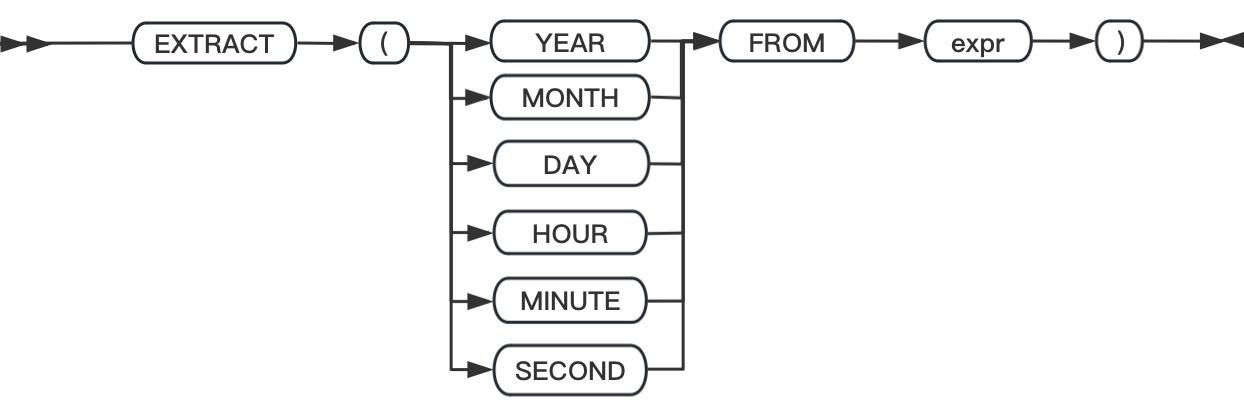
用来提取或者返回日期时间类型中指定的元素。结果返回DECIMAL类型。
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | DATETIME类型表达式 | 支持DATETIME类型或者可隐士转化为DATETIME类型的表达式 | 表达式 |
例如:提取日期中的年月。
> select EXTRACT(year from date '2023-10-22') c1 from dual;
C1 2023
> select EXTRACT(month from date '2023-10-22') c1 from dual;
C1 10
1 row(s) retrieved.
LOCALTIMESTAMP函数

返回系统的当前时间戳。返回类型datetime year to fraction(n),默认是datetime year to fraction(5)。
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | 指定小数秒精度 | 必须是整型数值类型[ 0 - 5 ],其他数值范围及浮点类型数均不支持。仅支持常数表达式,不支持科学计数法表示的常数,输入参数不能是null | 表达式 |
说明及限制:
- 返回结果相容性数据类型:varchar, char, lvarchar, nchar, nvarchar, character varying, varchar2, datetime year to fraction;
例如:查看系统当前时间戳
> select localtimestamp C1, localtimestamp(3) C2 from dual;
C1 2023-12-04 16\:52\:15.44252
C2 2023-12-04 16\:52\:15.442
1 row(s) retrieved.
TO_NUMBER 函数
TO_NUMBER 函数可将表示数值值的数值或字符表达式转换为 DECIMAL 数据类型。
TO_NUMBER 函数有此语法:
TO_NUMBER 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char_expression | 要被转换为 DECIMAL 值的表达式 | 必须为文字、主变量、表达式或字符数据类型的列 | 表达式 |
| num_expression | 求值为实数值的表达式 | 必须返回数值的数据类型 | 表达式 |
TO_NUMBER 函数将它的参数转换为 DECIMAL 数据类型。该参数可为数值或数值表达式的字符串表示。
下列示例检索 TO_NUMBER 函数从 MONEY 值的文字表示返回的 DECIMAL 值:
SELECT TO_NUMBER('$100.00') from mytab;
下表展示此 SELECT 语句的输出。
(expression)
100.000000000000
在此示例中,从 '$100.00' 字符串舍弃币种符号。
在大多数上下文中不需要 TO_NUMBER 函数,因为在缺省情况下, GBase 8s 将包括小数点的数值(以及以有小数点的文字数值为格式的引用字符串)转换为 DECIMAL 数据类型。然而,当您正在迁移那些原本为其他数据库服务器编写的 SQL 应用时,如果该应用调用返回 DECIMAL 值的此名称的函数,则此函数有用。
三角函数
内建的三角函数计算直角三角形的边的长度的比率。DEGREES 和 RADIANS 这两个支持函数可分别将角度值的单位从弧度转换为角度,以及从角度转换为弧度。
内建的三角函数有下列语法。
三角函数
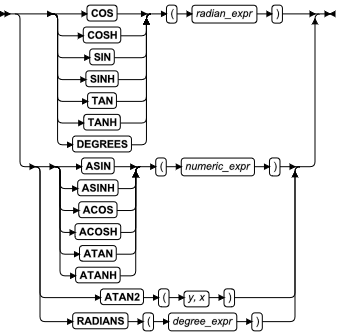
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| degree_expr | 表示角度的数值的表达式 | 必须返回可被转换为 DECIMAL 类型的值 | 表达式 |
| numeric_expr | 作为 ASIN、ACOS、ATAN、ASINH、ACOSH 或 ATANH 函数的参数的表达式 | 必须返回在 -1 与 1 之间(包括 -1 和 1)的值 | 表达式 |
| radian_expr | 表示弧度的数值的表达式 | 必须返回数值值 | 表达式 |
| x | 在直角坐标对 (x, y) 中表示 x 坐标的表达式 | 必须返回数值值 | 表达式 |
| y | 在直角坐标对 (x, y) 中表示 y 坐标的表达式 | 必须返回数值值 | 表达式 |
后面的部分描述每一这些内建的三角函数。
COS 函数
COS 函数返回弧度表达式的余切。
下列示例返回 anglestbl 表中角度列的值的余弦。在此示例中传递到 COS 函数的表达式将角度转换为弧度。
SELECT COS(degrees*180/3.1416) FROM anglestbl;
COSH 函数
COSH 函数返回所需要的参数的双曲余弦,在此,该参数是以弧度表示的角度。
COSH 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| radian_expr | 求值为以弧度的单位计的角度的表达式 | 必须为数值数据类型 | 表达式 |
下列示例返回 anglestbl 表的角度列中的值的双曲余弦。传递到 COSH 函数的表达式将角度转换为弧度。
SELECT COSH(degrees*180/3.1416) FROM anglestbl;
COT函数
COT 函数返回弧度表达式的余切,返回 DECIMAL 类型。
![]()
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 计算余切值的数值 | 可以是任意数值类型。 | 表达式 |
例如,查询使用 COT 函数:
select cot(1) from dual;
(constant) |
-------------------+
0.64209261593433065|
SIN 函数
SIN 函数返回您指定作为它的弧度表达式参数的角的正弦。
下列查询返回 anglestbl 表的 radians 列的每一行中值的正弦:
SELECT SIN(radians) FROM anglestbl;
SINH 函数
SINH 函数返回参数的双曲正弦,在此,该参数是以弧度表示的角。
SINH 函数
![]()
下列示例返回 anglestbl 表的角度列中值的双曲正弦。传递到 SINH 函数的表达式将角度转换为弧度。
SELECT SINH(degrees*180/3.1416) FROM anglestbl;
TAN 函数
TAN 函数返回它的弧度表达式参数的正切的值。
此示例返回 anglestbl 表的 radians 列中的值的正切:
SELECT TAN(radians) FROM anglestbl;
TANH 函数
TANH 函数返回参数的双曲正切,该参数是以弧度表示的角。
TANH 函数
![]()
下列示例返回 anglestbl 表的角度列中值的双曲正切。传递给 TANH 函数的表达式将角度转换弧度。
SELECT TANH(degrees*180/3.1416) FROM anglestbl;
ACOS 函数
ACOS 函数返回数值表达式的反余弦。
下列示例返回弧度值(-0.73)的反余弦:
SELECT ACOS(-0.73) FROM anglestbl;
ACOSH 函数
ACOSH 函数返回指定的数值输入的双曲反余弦。
ACOSH 函数
![]()
ASIN 函数
ASIN 函数返回数值表达式参数的反正弦。
下列示例返回弧度值(-0.73)的反正弦:
SELECT ASIN(-0.73) FROM anglestbl;
ASINH 函数
ASINH 函数返回指定的数值输入的反双曲正弦。
ASINH 函数
![]()
ATAN 函数
ATAN 函数返回数值表达式的反正切。
下列示例返回弧度值(-0.73)的反正切:
SELECT ATAN(-0.73) FROM anglestbl;
ATANH 函数
ATANH 函数返回指定的数值输入的反双曲正切。
ATANH 函数
![]()
ATAN2 函数
ATAN2 函数计算与 (x, y) 相关的极坐标 (r, q) 的角度分量。
下列示例将 angles 与直角坐标 (4, 5) 的 q 相比较:
WHERE angles > ATAN2(4,5) --确定 (4,5) 的 q 并
--与 angles 对比
您可使用下列示例所示的表达式来确定径向坐标 r 的长度:
SQRT(POW(x,2) + POW(y,2)) --确定 (x,y) 的 r
您可使用下列示例所示的表达式来确定直角坐标 (4,5) 的径向坐标 r 的长度:
SQRT(POW(4,2) + POW(5,2)) --确定 (4,5) 的 r
DEGREES 函数
使用 DEGREES 函数来将表示弧度数值的表达式或主变量的值转换为等同的角度值。
作为此函数的唯一参数的 radian_expression 或主变量必须为数值数据类型(或可转换为数值的非数值数据类型),数据库服务器以弧度的单位求值该参数,并转换为角度的单位。
返回值为类型 DECIMAL (32, 255) 的数值。
在下列两个示例中,DEGREES 的参数求值为 6 弧度,且返回值为 343.774677078494 角度:
EXECUTE FUNCTION DEGREES (6);
EXECUTE FUNCTION DEGREES ("6");
DEGREES 函数根据下列公式将弧度转换为角度:
(number of radians) * (180/pi) = (number of degrees)
在此,pi 代表圆的周长对它的直径的比率。使用超越数值 pi 作为有理数的除数进行算术计算的结果往往包括舍入错误。
RADIANS 函数
使用 RADIANS 函数来将表示角度值的表达式或主变量转换为等同的弧度值。
返回值为类型 DECIMAL (32, 255) 的数值。
作为此函数的唯一参数的 degree_expression 必须有数值数据类型(或可转换为数值的非数值数据类型),数据库服务器以角度的单位求值该参数,并转换为弧度的单位:
EXECUTE FUNCTION RADIANS (100);
EXECUTE FUNCTION RADIANS ("100");
在上述两个示例中,RADIANS 参数求值为 100 度,且返回值为 1.745328251994 弧度。您可使用 RADIANS 函数表达式作为 COS、SIN 或 TAN 函数的参数,来返回那个角各自的三角值:
COS(RADIANS (100))
SIN(RADIANS ("100"))
TAN(RADIANS (100))
RADIANS 函数根据下列公式将角度转换为弧度:
(number of degrees) * (pi/180) = (number of radians)
在此,pi 代表圆的周长对它的直径的比率。使用超越数值 pi 作为有理数的除数进行算术计算的结果往往包括舍入错误。
数字函数
VAR_POP
返回输入值的方差,返回值类型为decimal。计算公式为(SUM(expr2) - SUM(expr)2 / COUNT(expr)) / COUNT(expr)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。参数为包含列的表达式且值包含null时,null所在的行不纳入计算。参数为null函数返回值为空。 | 表达式 |
VAR_SAMP
返回一组数据的样本方差,返回值类型为decimal。计算公式为(SUM(expr - (SUM(expr) / COUNT(expr)))2) / (COUNT(expr) - 1) 。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。参数为包含列的表达式且值包含null时,null所在的行不纳入计算。参数为null函数返回值为空。 | 表达式 |
STDDEV_POP
返回输入值的总体标准差,返回值类型为decimal。计算公式为VAR_POP函数值的算术平方根。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。参数为包含列的表达式且值包含null时,null所在的行不纳入计算。参数为null,函数返回值为空。 | 表达式 |
STDDEV_SAMP
累积样本标准差并返回样本方差的平方根,返回值类型为decimal。计算公式为VAR_SAMP函数的算术平方根。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。参数为包含列的表达式且值包含null时,null所在的行不纳入计算。参数为null,函数返回值为空。 | 表达式 |
COVAR_POP
返回一组数对的总体协方差,返回值类型为decimal。计算公式为(SUM(expr1 * expr2) - SUM(expr2) * SUM(expr1) / n) / n。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。任何一个参数,值包含null时,null所在的行不纳入计算。两个参数同时为null,函数返回值为空。 | 表达式 |
| n | 表达式 | 指expr1,expr2两个表达式值中同时不为null的记录数。 | 表达式 |
COVAR_SAMP
返回一组数对的样本协方差,函数返回值类型为decimal。计算公式为(SUM(expr1 * expr2) - SUM(expr1) * SUM(expr2) / n) / (n-1)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 参数为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。任何一个参数,值包含null时,null所在的行不纳入计算。两个参数同时为null,函数返回值为空。 | 表达式 |
| n | 表达式 | 指expr1,expr2两个表达式值中同时不为null的记录数。 | 表达式 |
CORR
返回一组数对的相关系数,函数返回值类型为decimal。计算公式为COVAR_POP(expr1, expr2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2))。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 表达式 | 为数值型或能通过隐式类型转换为数值型的表达式,其他数据类型报错。任何一个参数,值包含null时,null所在的行不纳入计算。两个参数同时为null,函数返回值为空。 | 表达式 |
ISNUMERIC函数
ISNUMERIC函数判断给定表达式是否为有效的数值,是返回 1,否则返回 0 。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 需要判断是否为有效数值的表达式 | 不支持大对象类型、布尔类型、集合类型。 | 表达式 |
例如,判断Π是否为数值:
select isnumeric(pi) from dual;
(CONSTANT)
1
1 row(s) retrieved.
字符串操纵函数
字符串操纵函数对字符串执行各种操作。
在下图中标识字符串操纵函数:
字符串操纵函数
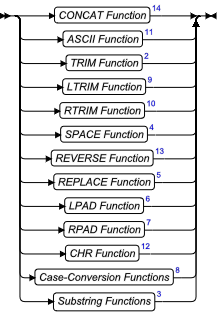
后面的部分描述每一内建的字符串操纵函数。
CONCAT 函数
CONCAT 函数接受两个表达式作为参数,并返回将由它的第二个参数返回的值的字符串表示追加到由它的第一个参数返回的值的字符串表示之后的单个字符串。
CONCAT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr_1、expr_2 | 要将它们的值的字符串表示串联的表达式 | 不可返回复合的、用户定义的或大对象类型。如果是主变量,则它必须有足够的长度来存储组合字符串的结果。 | 表达式 |
CONCAT 函数的每一参数可求值为字符、数值或时间数据类型。如果某个或两个被串联的参数为空,则该函数返回 NULL 值。
与 GBase 8s 的其他内建的字符串操纵函数不一样,不可重载 CONCAT 函数。
CONCAT 是串联(||)运算符的运算符函数。对于给定的表达式参数对,CONCAT 返回的字符串与从同一表达式为运算对象的运算符返回的字符串相同。要获取关于串联操作,以及对您在其中调用 CONCAT 函数的 SQL 和动态 SQL 语句的限制的附加信息,请参阅 串联运算符。
来自 CONCAT 和字符串函数的返回类型
从成功的 CONCAT 函数调用(或从串联(||)操作符,或对于确定他们的返回类型所遵循的规则与 CONCAT 相同的其他内建的字符串操纵函数)的返回值的数据类型依赖于参数的数据类型以及结果字符串的长度。在确定返回类型时,两个参数的顺序的意义不大。
对于来自串联多个数据类型指定的值的串联操作的返回类型, GBase 8s 应用下列规则:
- 如果其中一个类型为“国家语言支持”(也就是 NCHAR 和 NVARCHAR):
- 返回类型为 NVARCHAR。
- 如果其中一个参数为 VARCHAR 或数值类型,则
- 返回类型为VARCHAR。
- 然而,在某些在本地执行远程例程的跨服务器操作中,可发生针对这些规则的例外,且在将串联表达式的返回值发送到远程数据库服务器之前,在本地对它求值。对于不支持在分布式事务中的 LVARCHAR 数据类型的远程服务器,如果发送 LVARCHAR 类型返回错误,则作为 CHAR 数据类型发送串联的结果。
在下列表格中,各行罗列 CONCAT 函数的第一个参数的有效的数据类型,各列罗列第二个参数的类型。每一行与列交叉处的单元展示可能的一个或多个返回类型。标明其他的行和列表示求值为非字符类型的参数,诸如数值或像 DECIMAL 或 DATE 一样的时间数据类型。
表 1. 来自两个参数上的操作的返回类型
| NCHAR | NVARCHAR | CHAR | VARCHAR | LVARCHAR | 其他 | |
|---|---|---|---|---|---|---|
| NCHAR | nchar | nvarchar 或 nchar | nchar | nvarchar 或 nchar | nvarchar 或 nchar | nvarchar 或 nchar |
| NVARCHAR | nvarchar 或 nchar | nvarchar 或 nchar | nvarchar 或 nchar | nvarchar 或 nchar | nvarchar 或 nchar | nvarchar 或 nchar |
| CHAR | nchar | nvarchar 或 nchar | char | varchar 或 lvarchar | lvarchar | varchar 或 lvarchar |
| VARCHAR | nvarchar 或 nchar | nvarchar 或 nchar | varchar 或 lvarchar | varchar 或 lvarchar | lvarchar | varchar 或 lvarchar |
| LVARCHAR | nvarchar 或 nchar | nvarchar 或 nchar | lvarchar | lvarchar | lvarchar | lvarchar |
| 其他 | nvarchar 或 nchar | nvarchar 或 nchar | varchar 或 lvarchar | varchar 或 lvarchar | lvarchar | varchar 或 lvarchar |
对于 CONCAT 之外的其他字符串操纵函数,DATE、DATETIME 或 MONEY 数据类型的参数往往返回 NVARCHAR 或 NCHAR 值,这依赖于结果字符串的长度。
此表格是对称的,因为参数的顺序对返回数据类型没有影响。对于内建的字符串操纵函数或运算符,用户定义的数据类型、大对象类型、复合的类型和其他扩展的数据类型不是有效的参数。
此表格还描述使用串联(||)运算符的表达式的返回数据类型。
对于返回类型提升,下列字符串操纵函数支持与 CONCAT 相同的规则:
- LPAD
- RPAD
- REPLACE
- SUBSTR
- SUBSTRING
- TRIM
- LTRIM
- RTRIM
下列表格总结 GBase 8s 如何基于参数类型,来确定来自这些字符串操纵函数的返回类型:
表 2. 支持返回类型提升的字符串操纵函数
| 函数 | 如何确定函数的返回类型 |
|---|---|
| CONCAT、 || | 返回类型基于两个参数。请参考 表 1。 |
| SUBSTR、SUBSTRING | 返回类型与 source string 类型相同。如果 source string 为主变量,则依赖于结果的长度,返回类型为 NVARCHAR 或 NCHAR。 |
| TRIM、LTRIM、RTRIM | 返回类型依赖于源类型和返回的长度: ● NVARCHAR 返回 NVARCHAR ● VARCHAR 返回 VARCHAR ● CHAR 返回 VARCHAR(如果 length <= 255 字节的话) ● CHAR 返回 LVARCHAR(如果 length > 255 字节的话) ● NCHAR 返回 NVARCHAR(如果 length <= 255 字节的话) ● NCHAR 返回 LVARCHAR(如果 length > 255 字节的话) ● LVARCHAR 返回 LVARCHAR |
| LPAD、RPAD | 返回类型基于 source_string 和 pad_string 参数。如果未指定 pad_string,则返回类型基于 source_string 的数据类型。 |
| REPLACE | 返回类型基于 source_string 和 old_string 参数(以及基于 new_string 参数,如果指定了的话)。如果任何参数为主变量,则返回类型为 NCHAR。 |
| ENCRYPT_AES、ENCRYPT_TDES、DECRYPT_BINARY、DECRYPT_CHAR | 对于不是 BLOB 或 CLOB 变量的参数,返回类型基于 data 和 encrypted_data 参数的数据类型。请参考 表 1。 |
在 NLSCASE INSENSITIVE 数据库中的数据类型提升
在有 NLSCASE INSENSITIVE 属性的数据库中,数据库服务器丢弃 NCHAR 和 NVARCHAR 值的大写字母。通过执行隐式的强制转型来在其中避免函数或运算符溢出错误的表达式,可产生与区分大小写的数据库会返回的结果不同的结果,如果该表达式求值为 NCHAR 或 NVARCHAR 数据类型的话。
当数据库服务器在其上支持数据类型提升的字符串函数或字符串运算符返回一值,对于该表达式的缺省的 VARCHAR 或 NVARCHAR 数据类型会产生溢出错误时,数据库服务器在返回值上执行隐式的强制转型,如同主题 来自 CONCAT 和字符串函数的返回类型 的第一张表格表明的那样:
- 如果没有参数或运算对象是 NCHAR 或 NVARCHAR 数据类型,则表达式求值为 CHAR、LVARCHAR 或 VARCHAR 数据类型。
- 如果任何参数或运算对象是 NCHAR 或 NVARCHAR 数据类型,则表达式求值为 NCHAR 或 NVARCHAR 数据类型。
在有 NLSCASE INSENSITIVE 属性的数据库中,对 CHAR、LVARCHAR 或 VARCHAR 数据类型的操作是区分大小写的,但对 NCHAR 或 NVARCHAR 数据类型的操作不区分大小写。数据类型提升还从包括 CHAR、LVARCHAR 或 VARCHAR 分量的表达式的求值产生不区分大小写的结果(而不是区分大小写),如果同一表达式还包括 NCHAR 或 NVARCHAR 字符串的话。
下列示例说明在 NLSCASE INSENSITIVE 数据库中的此行为,其中的表 t1 有五个字符列,对应五种内建的字符数据类型。该表存储三行,其中的每一列存储 3 个字母字符串的同一字母大小写变量:
CREATE DATABASE db NLSCASE INSENSITIVE;
CREATE TABLE t1 (
c1 NCHAR(20),
c2 NVARCHAR(20),
c3 CHAR((20),
c4 VARCHAR(20),
c5 LVARCHAR(20)) ;
INSERT INTO t1 values ('gbase', 'gbase', 'gbase', 'gbase', 'gbase');
INSERT INTO t1 values ('Gbase', 'Gbase', 'Gbase', 'Gbase', 'Gbase');
INSERT INTO t1 values ('GBASE', 'GBASE', 'GBASE', 'GBASE', 'GBASE');
下列查询使用其字母均为小写的文字字符串的相等谓词,从 NCHAR 列检索值:
SELECT c1 FROM t1 WHERE c1 = 'gbase';
由于在此数据库中 NCHAR 值不区分大小写,因此该查询从每一行返回列 c1 值:
c1
gbase
Gbase
GBASE
下列对同一表的查询从 WHERE 子句将其强制转型为 NCHAR 值的 CHAR 列 c3,返回相同的不区分大小写的结果:
SELECT c1 FROM t1 WHERE c3 = 'gbase'::NCHAR(10);
在强制转型之后,c3 值不区分大小写,因此,c3 中的每行都与字符串 'gbase' 相匹配,且对于 c1 中的每行,WHERE 条件都为真:
c1
gbase
Gbase
GBASE
如同在前面的示例中那样,在相同的序列中出现相同的字母的字符串之中,由于不区分大小写的操作丢弃字母大小写的差异,因此在有 NLSCASE INSENSITIVE 属性的数据库中,请留意避免将不区分大小写的规则应用到您期望区分大小写的操作的数据类型提升上下文。
另请参阅 在 NLSCASE INSENSITIVE 数据库中重复的行 部分。
在分布式事务中的返回字符串类型
在访问同一 GBase 8s 实例的不同数据库中的表的跨数据库分布式查询中,通过来自 CONCAT 函数的返回类型部分描述的 CONCAT(以及通过遵循相同的返回类型提升的其他内建的字符串操纵函数)返回相同的类型。
在跨服务器的分布式查询中也返回相同的类型。
对于的 GBase 8s 的所有版本,如果返回的字符串的长度超出 23 KB,则发出错误 -881。
ASCII 函数
ASCII 函数基于在 ASCII 字符集中它的代码点,返回字符串中第一个字符的十进制表示。
ASCII 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char_expr | 求值为字符数据类型的表达式 | 必须为类型 CHAR、LVARCHAR、NCHAR、NVARCHAR 或 VARCHAR | 标识符 |
ASCII 函数采用任何字符数据类型的单个参数。它基于参数的第一个字符返回一个整数值,对应于在 ASCII 字符集内那个字符的代码点的十进制表示。
如果参数为 NULL,或如果参数为空串,则 ASCII 函数返回 NULL 值。
下列查询返回大写 H 的 ASCII 值:
SELECT ASCII("HELLO") FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
(constant)
72
下列查询返回小写 h 的 ASCII 值:
SELECT ASCII("hello") FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的输出。
(constant)
104
下列查询从空字符串参数返回 ASCII 输出:
SELECT ASCII("") FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的 NULL 输出。
(constant)
下列查询返回从 NULL 参数的 ASCII 输出:
SELECT ASCII(NULL) FROM systables WHERE tabid = 1;
下列表格展示此 SELECT 语句的 NULL 输出。
(constant)
ASCII 函数将此参数解释为 NULL 表达式,而不是为以大写 N 开头的值。
要获取 ASCII 字符集中代码点的数值值的表格,请参阅 U.S. English 数据的排序顺序。
TRIM 函数
TRIM 函数从字符串移除指定的开头或末尾的填充字符。(另请参阅 LTRIM 和 RTRIM 函数的描述,这两个函数提供类似的功能,但支持不同的语法。)
TRIM 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| pad_char | 求值为单个字符或 NULL 的表达式。缺省值为空格(= ASCII 32)。 | 必须为字符表达式 | 表达式 |
| source_expression | 字符表达式,包括字符列名,或对另一 TRIM 函数的调用 | 不可为 DISTINCT 数据类型 | 表达式 |
TRIM 函数返回一个与它的 source_expression 参数相同的字符串,除了删除由 LEADING、TRAILING 或 BOTH 关键字指定的开头或末尾填充字符之外。如果未指定修正限定符(LEADING、TRAILING 或 BOTH),则缺省值为 BOTH。如果未指定 pad_char,则缺省值为单个空格(ASCII 32 字符),并从返回的值删除由限定的关键字指定的开头的或末尾的空格。
如果 pad_char 或 source_expression 求值为 NULL,则 TRIM 函数的结果为 NULL。
返回的值的数据类型依赖于 source_expression 参数:
- 如果参数长于 255 字节,则返回的值为 LVARCHAR 类型。
- 如果参数有 255 字节或更少,则返回的值的数据类型依赖于参数的数据类型:
- 如果参数是 CHAR 或 VARCHAR 类型,则返回 VARCHAR 值。
- 如果参数是 NCHAR 或 NVARCHAR 类型,则返回 NVARCHAR 值。
- 如果参数是 LVARCHAR 类型,则返回 LVARCHAR 值。
下列示例展示 TRIM 函数的一些一般使用:
SELECT TRIM (c1) FROM tab;
SELECT TRIM (TRAILING '#' FROM c1) FROM tab;
SELECT TRIM (LEADING FROM c1) FROM tab;
UPDATE c1='xyz' FROM tab WHERE LENGTH(TRIM(c1))=5;
SELECT c1, TRIM(LEADING '#' FROM TRIM(TRAILING '%' FROM
'###abc%%%')) FROM tab;
在动态 SQL 中,当您随同在 Projection 子句中调用 TRIM 函数的 SELECT 语句来使用 DESCRIBE 语句时,对于在 GBase 8s ESQL/C 源文件的 sqltypes.h 头文件中定义的 SQL 数据类型常量,DESCRIBE 返回的修正的列的数据类型依赖于 source_expression 的数据类型。要获取关于 GBase 8s ESQL/C 中 TRIM 函数在 GLS 方面的更多信息,请参阅 GBase 8s GLS 用户指南。
固定的字符列
可在定长字符列上指定 TRIM 函数。如果字符串的长度未完全地填满,则以空格填充未使用的字符。 图 1 展示对于列条目 '##A2T##' 的此概念,在此,定义该列为 CHAR(10)。
图: 在定长字符列的列条目

如果您想要从该列修整掉井号(#)pad_char,则需要考虑填充的空格以及实际的字符。
例如,如果您指定关键字 BOTH,则修整操作的结果为 A2T##,因为 TRIM 函数与跟在字符串之后的修整的空格不匹配。在此情况下,仅修整在其他字符之前的那些井号(#)。图 2 跟着的 SELECT 语句显示结果。
SELECT TRIM(LEADING '#' FROM col1) FROM taba;
图: TRIM 操作的结果

此 SELECT 语句移除所有出现的井号(#):
SELECT TRIM(BOTH '#' FROM TRIM(TRAILING ' ' FROM col1)) FROM taba;
LTRIM 函数
LTRIM 函数从字符串移除指定的开头填充字符。
LTRIM 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| pad_string | 指定一个或多个要从 source_string 删除的字符的表达式 | 必须为字符表达式 | 表达式 |
| source_string | 指定要从其删除 pad_string 中的字符的字符串的表达式 | 不删除不在 pad_string 中任何字符右边的填充字符 | 表达式 |
LTRIM 函数的第一个参数必须为要从其删除开头填充字符的字符表达式。可选的第二个参数是求值为填充字符的字符串的字符表达式。如果未提供第二个参数,则仅将空字符作为填充字符。
LTRIM 函数的返回数据类型是基于它的 source_string 参数的,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
返回的值包含 source_string 的子字符串,但已移除了第一个非填充字符左边的任何开头填充字符。如果使用主变量,则返回 LVARCHAR 数据类型。
LTRIM 函数从左边扫描 source_string 的副本,删除出现在 pad_string 中的任何开头字符。如果未指定 pad_string 参数,则仅从返回的值删除开头空格。当遇到第一个非填充字符时,该函数返回它的结果字符串并终止。
在下列示例中,pad_string 为 'Hello':
SELECT LTRIM('Hellohello world!', 'Hello') FROM mytab;
下列表格展示此 SELECT 语句的输出。
(constant)
hello world!
在此,删除了 source_string 的前五个字符,因为它们与 pad_string 中的字符相匹配,但在该函数遇到了小写字母 h 字符之后终止,其保留了它右边的末尾 'ello' 填充字符。
RTRIM 函数
RTRIM 函数从字符串移除指定的末尾填充字符。
RTRIM 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| pad_string | 指定要从 source_string 删除的一个或多个字符的表达式 | 必须为字符表达式 | 表达式 |
| source_string | 指定从其删除 pad_string 中的字符的字符串的表达式 | 不删除不在 pad_string 中的任何字符左边的填充字符 | 表达式 |
RTRIM 函数的第一个参数必须为从其删除末尾填充字符的字符表达式。可选的第二个参数是求值为填充字符的字符串的字符串表达式。如果未提供第二个参数,则仅将空字符作为填充字符。
LTRIM 函数的返回数据类型是基于它的 source_string 参数的,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
返回的值包含 source_string 的子字符串,但已从其移除了第一个非填充字符右边的任何末尾填充字符。如果使用主变量,则返回 LVARCHAR 数据类型。
RTRIM 函数从右边扫描 source_string 的副本,删除出现在 pad_string 中的任何末尾字符。如果未指定 pad_string 参数,则仅从返回的值删除末尾空格。当遇到第一个非填充字符时,该函数返回它的结果字符串并终止。
在下列示例中,pad_string 为 'theend!*#?':
SELECT RTRIM('good night... *!#?theend ', ' theend!*#?') AS closing FROM mytab;
下列表格展示此 SELECT 语句的输出。
(constant)
good night...
在此,删除了 source_string 的最后十五个字符,因为它们与 pad_string 中的字符相匹配,但该函数在遇到了句号(.)字符之后终止了,保留了左边的开头的 'thn' 填充字符。
SPACE 函数
SPACE 函数创建指定的空格数量的字符串。返回的字符串值的最大长度可为 32,739 空字符。
该函数有此语法:
SPACE 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 求值为非负整数 < 256 的表达式 | 必须为表达式、常量、列或内建的整数类型的主变量,或可转化为整数的表达式 | 表达式 |
SPACE 函数的参数必须为内建的数据类型。
SPACE 函数返回指定数目的空(ASCII 32)字符的 LVARCHAR 字符串。
如果参数求值为 NULL 值,或为小于 1 的数值,则此函数返回 NULL 值,而不是空串。
在下列示例中,SPACE 函数返回单个字符的空字符串:
SELECT SPACE(1) FROM tabula_rasa;
下列表格展示来自此 SELECT 语句的输出,其为单个空字符:
(constant)
REVERSE 函数
REVERSE 函数接受字符表达式作为它的参数,并返回同样长度的字符串,但颠倒每个逻辑字符的顺序位置。
这是 REVERSE 函数的语法:
REVERSE 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_string | 求值为字符串的表达式 | 必须为表达式、常量、列或可转换为字符类型的类型的主变量 | 表达式 |
REVERSE 函数的参数不可有用户定义的数据类型。内建的 CHAR、LVARCHAR、NCHAR、NVARCHAR 和 VARCHAR 类型是有效的。
REVERSE 函数返回与它的 source_string 参数相同的数据类型。
如果您指定作为参数的表达式求值为 NULL,则返回值为 NULL。
对于求值为 N 字符的字符串的参数,在 source_string 中每一字符的顺序位置 p 在返回的字符串中成为 (N + 1 - p)。这颠倒了 source_string 中字符序列的原始顺序,因此,返回值以 source_string 中的最后一个字符开头,并以 source_string 的第一个字符结尾。
例如,函数表达式 REVERSE('Mood') 从加引号的字符串参数返回字符串 dooM。在单字节和多字节代码集中,仅颠倒顺序的位置,而不颠倒字母本身。在上述的函数表达式中,'d' 不成为 'b',且多字节代码集(例如,utf8 或 GB2312-80)中的每一逻辑字符作为单一的逻辑单位换位。
如果参数求值为单个字符或空的 source_string,则返回值与 source_string 相同,如同 REVERSE 函数未起作用一样。对于包括多个字符的字符串,仅当 source_string 是回文时,此等式才为真。对于 MOD(N,2) = 1 的字符串,顺序位置为 (N+1)/2 的字符在 source_string 中和在返回的字符串中都处于相同的中间位置。
在下列示例中,REVERSE 函数颠倒一个引号括起的字符串参数:
SELECT REVERSE('Able was I ere I saw Elba.') FROM Mirror_Table;
下列表格展示此 SELECT 语句的输出。
(constant)
.ablE was I ere I saw elbA
REPLACE 函数
REPLACE 函数以不同的字符替换源字符串内指定的字符。
REPLACE 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| new_string | 替换字符串中 old_string 的单个或多个字符 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
| old_string | 要被 new_string 替换的 source_string 中的一个或多个字符 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
| source_string | REPLACE 函数的字符串参数 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
REPLACE 函数的任何参数都必须为内建的数据类型。
REPLACE 函数返回 source_string 的副本,以 new_string 替换其中的每个 old_string。如果您省略 new_string 选项,则从返回字符串中略去每个 old_string。
返回数据类型是source_string 参数的数据类型。如果返回值的长度超过 2048 字节,则会截断超长的字符,保存截断后的结果。
在下列示例中,REPLACE 函数以 t 替换源字符串中的每个 xz:
SELECT REPLACE('Mighxzy xzime', 'xz', 't') FROM mytable;
下列表格展示此 SELECT 语句的输出。
(constant)
Mighty time
LPAD 函数
LPAD 函数返回 source_string 的一个副本,左填充达到由 length 指定的总字节数。
LPAD 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| length | 指定在返回的字符串中总的字节数的整数值 | 必须为表达式、常量、列或可转换为整数数据类型的数据类型的主变量 | 精确数值 |
| pad_string | 指定一个或多个填充字符的字符串 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
| source_string | 作为 LPAD 函数的输入的字符串 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
LPAD 函数的任何参数都必须为内建的数据类型。
pad_string 参数指定要被用于填充源字符串的一个或多个字符。填充字符的序列出现的次数与使得返回字符串达到 length 指定的存储长度的必要次数相同。
如果 pad_string 中的填充字符的序列太长,以至于不适应 length,则截断它。如果您未指定 pad_string,则缺省值为单个空(ASCII 32)字符。
返回数据类型是基于这三个参数的,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
在下列示例中,用户指定要将源字符串左填充达到总长度 16 字节。用户还指定填充字符是由连字符和下划线(-_)组成的序列。
SELECT LPAD('Here we are', 16, '-_') FROM mytable;
下列表格展示此 SELECT 的输出。
(constant)
-_-_-Here we are
RPAD 函数
RPAD 函数返回 source_string 的一个副本,右填充达到 length 参数指定的总字节数。
RPAD 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| length | 返回值中的总字节数 | 必须为表达式、常量、列或返回整数的主变量 | 精确数值 |
| pad_string | 指定一个或多个填充字符的字符串 | 必须为表达式、常量、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
| source_string | 作为 RPAD 函数的输入的字符串 | 同 pad_string | 表达式 |
RPAD 函数的任何参数都必须为内建的数据类型。
pad_string 参数指定要用来填充源字符串的一个或多个填充字符。
填充字符的序列出现的次数与使得返回字符串达到 length 指定的长度所必要的次数相同。如果 pad_string 中的填充字符的序列太长,以至于不适应 length,则截断它。如果您省略 pad_string 参数,则缺省的值为单个空格(ASCII 32)字符。
返回数据类型是基于 source_string 和 pad_string 参数的,如果都指定了的话。如果主变量是源,则返回值为 NVARCHAR 或 NCHAR,根据返回的字符串的长度来确定,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
即使 RPAD 函数已将空字符追加到数据值之后,DB-Access 的 UNLOAD 特性也截断 CHAR 或 NCHAR 列中的末尾空格。您必须显式地将 CHAR 或 NCHAR 值强制转型为 VARCHAR、LVARCHAR 或 NVARCHAR 数据类型,如果您需要 UNLOAD 保留 RPAD 返回的值中的末尾空字符或不可打印的字符的话。
在下列示例中,用户指定将源字符串右填充到总长度 18 字符。用户还指定要使用的填充字符是由问号和叹号(?!)组成的序列
SELECT RPAD('Where are you', 18, '?!') FROM mytable;
下列表格展示此 SELECT 语句的输出。
(constant)
Where are you?!?!?
CHR 函数
此函数接受无符号整数参数,并返回单个逻辑字符。
CHR 函数有此语法:
CHR 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 求值为小于 256 的非负的整数的表达式 | 必须为取值范围从 0 至 255(含 0 和 255)的整数 | 表达式 |
返回值的数据类型为 VARCHAR(1)。
参数可为 SMALLINT、INTEGER、SERIAL、INT8、SERIAL8、BIGINT 或 BIGSERIAL。参数必须求值为整数,取值范围从 0 至 255。
如果参数为取值范围从 0 至 127 的整数,则返回值为对应的单字节 ASCII 代码点。要获取对应于 ASCII 代码点从 0 至 127 的字符的列表,请参阅 U.S. English 数据的排序顺序。
如果参数是取值范围从 128 至 255 的整数,则返回值为缺省的代码集中对应的 2 字节代码点。
- 在 UNIX™ 平台上,缺省的代码集为 ISO8859-1。
- 在 Windows™ 平台上,缺省的代码集为 Microsoft™ 1252。
CHAR函数
CHAR 函数返回整数n对应的逻辑字符。别名CHR.。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| n | ASCII编码 | 当参数n为0~127时,按ascii码表返回对应值。 | 表达式 |
例如,查看ASCII码为33的字符是什么:
select char(33) from dual;
(EXPRESSION)
!
1 row(s) retrieved.
说明及限制:
- 参数为NULL时,返回结果为NULL。
- 当 CHAR函数的参数包含小数部分时,进行向下取整,并输出结果。
UNHEX函数
UNHEX 函数返回将十六进制格式的字符串转化为原来的格式字符串。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要转换成格式字符串的16进制数据 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。 | 表达式 |
例如,查看16进制为7e的字符是什么:
SELECT unhex('7e') from dual;
(constant) ~
1 row(s) retrieved.
说明及限制:
- 16进制数据需要按字符串处理,用单引号或双引号括起来。
- 当参数char为00~7f时,按ascii码表返回对应字符。
- 参数char为空字符串或NULL时,返回NULL。
BINTOCHAR函数
BINTOCHAR 函数将16进制数值 binary 转换为ascii码对应的字符 。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| binary | 需要转换为ascii码对应的字符的16进制数 | 参数binary为数值或字符串,都按16进制处理返回ascii码对应的字符。参数binary为数值时,从后往前每两位一读,计算后返回结果 | 表达式 |
例如,查看E4BABA的对应字符:
select bintochar('E4BABA') from dual;
(constant) 人
1 row(s) retrieved.
说明及限制:
- 参数为NULL时,返回NULL。
CONVERT函数
CONVERT 函数返回将字符串从一个字符集转换成另一个字符集并输出。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| c1 | 需要转换字符集的字符串 | 支持字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
| set1 | 需要将参数c1转换为的字符集名称 | 可以为文本或者包含字符集名称的列。兼容ORACLE中的US7ASCII,WE8ISO8859P1,zhs16cgb231280和zhs16gbk字符集。 | 表达式 |
| set2 | 数据库中存储c1的字符集名称 | 可以为文本或者包含字符集名称的列。缺省为数据库字符集。兼容ORACLE中的US7ASCII,WE8ISO8859P1,zhs16cgb231280和zhs16gbk字符集。 | 表达式 |
例如,将字符串'Ä Ê Í Õ Ø A B C D E '从'WE8ISO8859P1'字符集转换到'US7ASCII'字符集:
SELECT CONVERT('Ä Ê Í Õ Ø A B C D E ', 'US7ASCII', 'WE8ISO8859P1') FROM DUAL;
(CONSTANT) A B C D E
1 row(s) retrieved.
说明及限制:
- 一般要求源串字符集与数据库服务器所在操作系统的字符集一致,否则转换结果会跟源串字符集与数据库服务器所在操作系统的字符集一致时不一样。
NLSSORT函数(当前版本暂不支持)
NLSSORT函数返回对自然语言排序的编码。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| str1 | 需要排序的字符串 | 支持字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。不支持大对象类型、布尔类型。 | 表达式 |
| str2 | 排序规则 | 可选参数。缺省时按默认字符集二进制编码排序。SCHINESE_PINYIN_M 表示按中文拼音排序;SCHINESE_STROKE_M 表示按中文笔画排序;SCHINESE_RADICAL_M 表示按中文部首排序。 | 表达式 |
例如,将中文字符串‘啊’、‘不’、‘才’、‘的’按二进制编码排序:
create table createTable0001_t1(c1 varchar(100));
insert into createTable0001_t1 values('啊');
insert into createTable0001_t1 values('不');
insert into createTable0001_t1 values('才');
insert into createTable0001_t1 values('的');
SELECT * FROM CREATETABLE0001_T1 ORDER BY NLSSORT(C1);
C1 不
C1 啊
C1 才
C1 的
4 row(s) retrieved.
STRPOSDEC函数
STRPOSDEC 函数返回字符串 char 中指定位置 pos 上的字节值减一后的字符串。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要计算的字符串 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。不支持大对象类型、集合类型、布尔类型。 | 表达式 |
| pos | 指定char中值减1的字符位置 | 参数可选。缺省为字符串最后一个字节。支持int类型。当pos所指的位置为空时,则保持不变。取值范围为1到字符串的长度。pos为小数时,进行四舍五入后返回结果。 | 表达式 |
例如,查看字符串abc第三个位置字节值减1后的字符串:
select strposdec('abc',3) from dual;
(CONSTANT) abb
1 row(s) retrieved.
说明及限制:
- 参数char或pos为NULL或pos为空串时,返回NULL。
- 不同字符集下由于编码不同返回结果不同。
- 当参数char为varchar类型时超过32739,会进行截断并输出结果。
STRPOSINC函数
STRPOSDEC 函数返回字符串 char 中指定位置 pos 上的字节值加一后的字符串。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要计算的字符串 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。不支持大对象类型、集合类型、布尔类型。 | 表达式 |
| pos | 指定char中值加1的字符位置 | 参数可选。缺省为字符串最后一个字节。支持int类型。当pos所指的位置为空时,则保持不变。取值范围为1到字符串的长度。pos为小数时,进行四舍五入后返回结果。 | 表达式 |
例如,查看字符串abc第三个位置字节值加1后的字符串:
select strposinc('abc',3) from dual;
(CONSTANT) abd
1 row(s) retrieved.
说明及限制:
- 参数char或pos为NULL或pos为空串时,返回NULL。
- 不同字符集下由于编码不同返回结果不同。
- 当参数char为varchar类型时超过32739,会进行截断并输出结果。
UNISTR函数
UNISTR 函数将解析为字符数据的文本或表达式作为其参数,并以地区字符集返回它。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| string | 需要转换成本地字符的字符串 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。不支持大对象类型、集合类型、布尔类型。 | 表达式 |
例如,查看 \5357\5927\901A\7528的本地编码:
select unistr('\5357\5927\901A\7528') from dual;
(CONSTANT) 南大通用
1 row(s) retrieved.
说明及限制:
- 参数为NULL时,返回NULL。
- string为数字、日期、字符串类型时,返回它本身。
- UNISTR函数仅支持在utf8字符集下使用,其他字符集下可能会出现转换乱码 。
- 当参数string为varchar类型时超过32739,会进行截断并输出结果。
CONCAT_WS函数
CONCAT_WS 函数顺序联结多个字符串成为一个字符串,并用 delim 分割。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| delim | 分隔符 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。 | 表达式 |
| char | 需要联结的字符串 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。不支持大对象类型。 | 表达式 |
例如,联结字符串’hello’,’gbase’,’good’,用@符合分隔:
select concat_ws('@','hello','gbase','good') from dual;
(CONSTANT)
hello@gbase@good
1 row(s) retrieved.
说明及限制:
- 如果只有delim和其他一个字符串,返回结果为该字符串。
- 返回的联结字符串最长为32767。
DIFFERENCE函数
DIFFERENCE函数比较两个字符串的 SOUNDEX 值差异, 返回两个SOUNDEX 值串同一位置出现相同字符的个数。

DIFFERENCE 函数比较两个字符串的 SOUNDEX 值差异, 返回两个SOUNDEX 值串同一位置出现相同字符的个数。
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1、char2 | 需要比较SOUNDEX值差异的字符串 | 支持字符类型或者可以隐式转换成字符类型的其他数据类型。不支持大对象类型、集合类型、布尔类型。 | 表达式 |
例如,比较字符串hello和good间的soundex值差异:
select difference('hello','good') from dual;
(CONSTANT)
2
1 row(s) retrieved.
说明及限制:
- 参数char1和char2为数值类型时,返回结果为0。
- 参数char1和char2为null和字符串或数值类型时,返回结果为0。
- 参数char1和char2为特殊字符时,返回结果为0。
大小写转换函数
大小写转换函数执行对字母字符的大小写转换。在缺省的语言环境中,这些函数仅可修改范围为 A - Z 以及 a - z 内的 ASCII 字符,这使得您能够在您的查询中执行区分大小写的搜索并能够指定输出的格式。
大小写转换函数是 UPPER、LOWER 和 INITCAP。下图展示这些大小写转换函数的语法。
大小写转换函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 返回字符串的表达式 | 必须为内建的字符类型。如果是主变量,则它的长度必须足够存储转换的字符串。 | 表达式 |
expression 必须返回字符数据类型。当指定列表达式时,由数据库服务器返回的列数据类型为 expression 的数据类型。例如,如果输入类型为 CHAR,则输出类型也为 CHAR。
这些函数的参数必须为内建的数据类型。
在所有语言环境中,以大小写转换函数从列的描述返回的字节长度是源字符串的输入字节长度。如果您使用带有多字节 expression 参数的大小写转换函数,则转换可能增加或减少该字符串的长度。如果结果字符串的字节长度超过 expression 的字节长度,则数据库服务器截断结果字符串来适应 expression 的字节长度。
仅转换在语言环境文件中指定为 ALPHA 类的字符,且仅当语言环境识别大小写的结构时才会发生。
如果 expression 求值为 NULL,则大小写转换函数的结果也是 NULL。
在下列实例中,数据库服务器将大小写转换函数处理为 SPL 例程:
- 如果它没有参数
- 如果它有一个参数,且那个参数是命名的参数
- 如果它有多个参数
- 如果它出现在 Projection 列表中,以主变量作为参数
如果未遇到前面的列表中的情况,则数据库服务器将大小写转换函数处理为系统函数。
下列示例在相同的查询中使用所有大小写转换函数来为同一值指定多种输出格式:
Input value:
SAN Jose
Query:
SELECT City, LOWER(City), LOWER("City"),
UPPER (City), INITCAP(City)
FROM Weather;
Query output:
SAN Jose san jose city SAN JOSE San Jose
UPPER 函数
UPPER 函数接受一个表达式参数,并返回其中的表达式中的每个小写字母字符都被对应的大写字母字符替换的字符串。
下列示例使用 UPPER 函数来对带有 Curran 姓氏的所有员工执行 lname 列上的区分大小写搜索:
SELECT title, INITCAP(fname), INITCAP(lname) FROM employees
WHERE UPPER (lname) = "CURRAN"
由于在 projection 列表中指定 INITCAP 函数,因此数据库服务器返回混合大小写格式的结果。例如,一个相匹配的行的输出可能为:accountant James Curran.
UCASE函数
UCASE 函数返回其中的表达式中的每个小写字母字符都被对应的大写字母字符替换的字符串。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 需要转大写的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,返回 abc 转换大写的对应字符串:
select ucase('abc') from dual;
(expression)|
------------+
ABC |
LOWER 函数
LOWER 函数接受一个表达式参数,并返回其中表达式中的每个大写字母字符都被对应的小写字母字符替换的字符串。
下列示例展示如何使用 LOWER 函数来在 City 列上执行区分大小写的搜索。此语句指导数据库服务器以混合大小写格式 San Jose 替换词语 san jose 的任何实例(即,任何变化形式)。
UPDATE Weather SET City = "San Jose"
WHERE LOWER (City) = "san jose";
LCASE函数
LCASE 函数返回其中的表达式中的每个大写字母字符都被对应的小写字母字符替换的字符串。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 需要转小写的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,返回 ABC 转换小写的对应字符串:
select lcase('ABC') from dual;
(expression)|
------------+
abc |
INITCAP 函数
INITCAP 函数返回表达式的一个副本,其中表达式中每个词都以大写字母开头。使用这个函数,词语在任何字符而不是字母之后开始。因此,除了空格,诸如逗号、句号、冒号等等这样的符号引出新的词语。
要获取 INITCAP 函数的示例,请参阅 UPPER 函数。
NLSCASE INSENSITIVE 数据库中的大小写转换函数
指定了 UPPER 和 LOWER 大小写转换函数来支持在区分大小写的数据库中的区分大小写查询。在有 NLSCASE INSENSITIVE 属性的数据库中不经常需要他们,因为无需调用这些函数,NCHAR 和 NVARCHAR 数据类型就支持区分大小写的查询。您可在 NLSCASE INSENSITIVE 数据库中调用大小写转换函数,它们对 CHAR、LVARCHAR 和 VARCHAR 数据类型的影响与在区分大小写的数据库中相同。
在以 NLSCASE INSENSITIVE 选项创建的数据库中,数据库服务器不理会 NCHAR 和 NVARCHAR 值的字母大小写。调用大小写转换函数的表达式可返回的结果可与区分大小写的数据库会返回的不同,如果该表达式引用 NCHAR 或 NVARCHAR 对象,或如果数据库服务器以显式的或隐式的强制转型将该表达式求值为 NCHAR 或 NVARCHAR 数据类型的话。
当在带有 NLSCASE INSENSITIVE 属性的数据库中使用 UPPER、LOWER 或 INITCAP 函数对字符串表达式求值时,数据库服务器调用该函数,并对它的返回值应用数据类型提升规则,在主题 来自 CONCAT 和字符串函数的返回类型 中总结该规则。
- 如果该表达式求值为 CHAR、LVARCHAR 或 VARCHAR 数据类型,则数据库服务器可使用区分大小写的操作中的结果,如果那些操作不涉及 NCHAR 或 NVARCHAR 对象的话。
- 在执行了 UPPER、LOWER 或 INITCAP 函数之后,如果该表达式求值为 NCHAR 或 NVARCHAR 值,则在使用来自该表达式的此返回值的后续操作中,不理会在此结果中的字母的大小写。
下列示例说明在 NLSCASE INSENSITIVE 数据库中的此行为,其中表 t1 有这五个内建的字符数据类型的字符列。该表存储三行,其中每一列存储 3 个字母字符串的相同大小写的形式:
CREATE DATABASE db NLSCASE INSENSITIVE;
CREATE TABLE t1 (
c1 NCHAR(20),
c2 NVARCHAR(20),
c4 VARCHAR(20),
c5 LVARCHAR(20)) ;
INSERT INTO t1 values ('gbase', 'gbase', 'gbase', 'gbase', 'gbase');
INSERT INTO t1 values ('Gbase', 'Gbase', 'Gbase', 'Gbase', 'Gbase');
INSERT INTO t1 values ('GBASE', 'GBASE', 'GBASE', 'GBASE', 'GBASE');
在下列示例中,数据库服务器将 UPPER 函数应用到 NCHAR 列 c1,然后对于 'GBASE' 字符串常量相匹配的列中返回的所有值应用区分大小写的规则。
SELECT c1 FROM t1 WHERE UPPER(c1) = ‘GBASE’;
由于在此数据库中 NCHAR 值时不区分大小写的,因此该查询从表中的每行返回列 c1 值,由于在每一行中字母的序列与字符串常量相匹配,使用忽略该列值的字母大小写的不区分大小写的规则:
c1
gbase
Gbase
GBASE
在相同的表上,通过对同一查询的下列修改,也会返回相同的结果集(即’gbase’、'Gbase' 和 ' GBASE '):
- 如果 projection 子句指定了任何其他列,而不是 c1,因为每行存储相同的值,且对于此数据库中字符串 'GBASE' 的所有大小写变化形式,UPPER 返回的 NCHAR 值使得 WHERE 子句为真。
- 如果 WHERE 子句中的 'GBASE' 字符串是相同的字符序列的任何其他字母大小写变化形式,因为在此数据库中区分大小写的规则不处理 NCHAR 数据类型。
- 如果大小写转换函数的参数是 NVARCHAR 列 c2,而不是 NCHAR 列 c1,因为在此数据库中 NCHAR 或 NVARCHAR 都是不区分大小写的数据类型。
- 如果将大小写转换函数 LOWER 或 INITCAP,而不是 UPPER,应用于列 c1,因为在此数据库中,那个 NCHAR 列的每个(大小写变化形式)值都与 'GBASE' 相匹配。
- 如果未调用大小写转换函数,但 WHERE 条件反而指定了 c1 = 'GBASE',因为在此 NLSCASE INSENSITIVE 数据库中,大小写转换函数作为查询过滤器对 NCHAR 或 NVARCHAR 参数不起作用。
子字符串函数
内建的 SQL子字符串函数从字符串参数返回子字符串,或返回子字符串上操作的位置信息。
子字符串函数
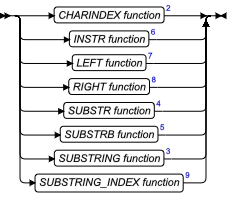
下面的部分描述这些子字符串函数的语法和用法。
CHARINDEX 函数
CHARINDEX 函数搜索字符串,找到目标子字符串的第一次出现,搜索从源字符串内指定的或缺省的字符位置开始。
CHARINDEX 函数有此语法:
CHARINDEX 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_ string | 求值为字符串的表达式 | 必须为一表达式、常量、列或内建的字符类型或可转换为字符类型的类型的主变量 | 表达式 |
| start_ position | 要在 source 中开始搜索的顺序位置,此处的 1 为第一个逻辑字符 | 必须为一表达式、常量、列或内建的字符类型或可转换为字符类型的类型的主变量 | 表达式 |
| substring | 求值为字符串的表达式 | 必须为一表达式、常量、列或内建的字符类型或可转换为字符类型的类型的主变量 | 表达式 |
CHARINDEX 的参数不可为用户定义的数据类型。
如果 source 或 substring 为 NULL,则此函数返回 NULL。
如果可选的 start_position 值小于 1,或如果您省略此参数,则在 source 中的第一个逻辑字符处开始搜索 substring,如同您已指定了 1 作为起始位置一样。
如果找不到与 substring 相匹配的表达式,则 CHARINDEX 返回零(0)。否则,它返回在 substring 第一次出现的第一个逻辑字符的顺序位置。
如果您指定大于 1 的 start_position,则忽略在 start_position 之前开始的任何 substring,该函数返回下列值之一:
- 或者是在第一个相匹配的子字符串中第一个逻辑字符的位置,其顺序位置等于或大于 start_position,
- 或者是零(0),如果开始于 start_position 或跟在 start_position 之后的 source 中没有 substring 出现,或如果 start_position 大于 source 中逻辑字符的数目。
在支持多字节字符集的语言环境中,返回值为 source 中逻辑字符之中的顺序值。在单字节语言环境中,比如缺省的语言环境,返回值等同于字节位置,在此,第一个字节位于位置 1。
在以 NLSCASE INSENSITIVE 选项创建的数据库中,如果 source 或 substring 是 NCHAR 或 NVARCHAR 数据类型,则数据库服务器在确定 source 的给定的子字符串是否与目标 substring 相匹配时,忽略字母大小写的变化形式。
下列函数表达式返回 9:
CHARINDEX('com','www.gbase.com')
在上面的示例中,CHARINDEX 在缺省的起始位置 1 开始它的搜索。
下列函数表达式返回 2:
CHARINDEX('w','www.gbase.com',2)
在上面的示例中,由于最后的参数在位置 2 开始搜索,因此,CHARINDEX 忽略两个其他的相匹配的子字符串:
- 位置 1 中的 'w',因为搜索开始于 2,
- 以及位置 3 的 'w',因为该函数仅返回相匹配的子字符串第一次出现的位置。
INSTR 函数
INSTR 函数从字符串搜索指定的子字符串,并基于子字符串出现的次数返回在那个字符串中子字符串终止出现处的字符位置。
INSTR 函数有此语法:
INSTR 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| count | 求值为 > 0 整数的表达式 | 必须为表达式、常量、列或内建的整数类型或可转换为整数的主变量。 | 表达式 |
| source_string | 求值为字符串的表达式 | 必须为表达式、常量、列或内建的字符数据类型或可转换为字符类型的主变量 | 表达式 |
| start | 在 source_string 中开始搜索的顺序位置,在此,1 是第一个逻辑字符 | 必须为表达式、常量、列或内建的整数类型或可转换为正的或负的整数的主变量 | 表达式 |
| substring | 求值为字符串的表达式 | 必须为表达式、常量、列或内建的字符数据类型或可转换为字符类型的主变量 | 表达式 |
INSTR 的参数不可为用户定义的数据类型。
在这些情况下,该函数返回 NULL:
- count 小于或等于零(0)。
- source_string 为 NULL 或长度为零。
- substring 为 NULL 或长度为零。
在下列情况下,返回值为零(0):
- 如果在 source_string 发现没有出现 substring,
- 如果 start 大于 source_string 的长度。
- 如果在 source_string 中 substring 的出现少于 count,
如果您省略可选的 count 参数,则缺省的 count 值为 1。
在支持多字节字符集的语言环境中,返回值为 source_string 中逻辑字符之中的顺序值。在单字节语言环境中,比如缺省的语言环境,返回值等同于字节位置,在此,第一个字节在位置 1 中。
start 位置
如果省略 start 或指定 start 为零,则对 substring 的搜索从字符位置 1 开始。如果 start 为负的,则在 source_string 结束的位置开始搜索 substring 的出现,并向着开头方向处理。
- 在从左至右的语言环境中,负的 start 值指定从右至左的搜索。
- 在从右至左的语言环境中,负的 start 值指定从左至右的搜索。
然而,在这两种类型的语言环境中,都是在 source_string 之内对应于 start 的绝对值的逻辑字符位置上开始搜索。
在从右至左的语言环境中,负的 start 值指定从左至右的搜索。
INSTR 函数表达式的示例
下列表达式都是基于相同的 source_string 和 substring 的。此示例返回 3,作为第一个 'er' 子字符串的字符位置:
INSTR("wwerw.gbase.cerom", "er")
在上面的示例中,start 和 count 都缺省为 1。
下一个示例在第二个字符位置开始搜索,带有缺省的 count 1:
INSTR("wwerw.gbase.cerom", "er", 2)
上面的表达式返回 3,从左至右的搜索在第一个 'er' 子字符串中遇到的第一个字符的位置。
下一个示例指定 count 2,在 source_string 的第一个字符中开始搜索:
INSTR("wwerw.gbase.cerom", "er", 1, 2)
上面的表达式返回 12,第二个 'er' 开始的位置。
下列示例指定 -5 作为开始的位置,且 count 指定在 source_string 的第 5 个位置与开头之间 "er" 的第一次出现:
INSTR("wwerw.gbase.cerom", "er", -5, 1)
这返回 3,对应于从那个位置开始 "er" 子字符串的第一次出现。负的 start 参数指定从右至左的查询,但返回值为 3,因为在缺省的语言环境中,字符串和子字符串的读方向为从左至右的。
说明及限制:
- instr函数在gbase模式下按字节计算,在oracle模式下按字符计算。
INSTRB函数
INSTRB 函数返回从 source_string 的第 start 个字节开始查找字符串 substring的第 count 次出现的位置。返回类型为数值类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_string | 需要进行查找的源字符串 | 可以为任意字符数据类型。 | 表达式 |
| substring | 需要查找的目标字符串 | 可以为任意字符数据类型。 | 表达式 |
| start | 开始位置 | 可以为任意数值数据类型。参数可选,缺省为1。start为负数时,从source_string的最右边开始。start为0时,返回0。 | 表达式 |
| count | 出现的次数 | 可以为任意数值数据类型。参数可选,缺省为1。不支持小于等于0的数。 | 表达式 |
例如,在zh_CN.utf8编码下查看通用在南大通用数据库第一次出现的位置:
select instrb('南大通用数据库','通用',1,1) from dual;
(constant)
7
1 row(s) retrieved
说明及限制:
- 参数source_string和参数substring都为null时,返回null。
- 不同的编码格式下instrb计算中文字符串的结果不同。
INS函数
INS 函数删除在字符串 char1 中以 begin 参数所指位置开始的n 个字符, 再把 char2 插入到 char1 串的 begin 所指位置。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要被替换的的字符串 | 可以为任意字符数据类型。 | 表达式 |
| begin | char1需要被替换的开始位置 | 可以为任意数值数据类型。begin为0或负数时,按1处理。 | 表达式 |
| n | 需要替换的字符个数 | 可以为任意数值数据类型。n为负数时,按0处理,讲char2添加到char1的第begin个字符前边。 | 表达式 |
| char2 | 需要插入到char1的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,将字符串hello的o替换成good:
select ins('hello',5,1,'good') from dual;
(CONSTANT) hellgood
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
INSERT函数
INSERT 函数将字符串 char1 从 n1 的位置开始删除 n2 个字符,并将 char2 插入到 char1 中 n1 的位置。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要被替换的的字符串 | 可以为任意字符数据类型。 | 表达式 |
| n1 | char1需要被替换的开始位置 | 可以为任意数值数据类型。n1为0或负数时,按1处理。 | 表达式 |
| n2 | 需要替换的字符个数 | 可以为任意数值数据类型。n2为负数时,按0处理,讲char2添加到char1的第n1个字符前边。 | 表达式 |
| char2 | 需要插入到char1的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,将字符串hello的o替换成good:
select insert('hello',5,1,'good') from dual;
(CONSTANT) hellgood
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
INSSTR函数
INSSTR 函数将字符串 char1 从 n1 的位置开始删除 n2 个字符,并将 char2 插入到 char1 中 n1 的位置。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要被替换的的字符串 | 可以为任意字符数据类型。 | 表达式 |
| n1 | char1需要被替换的开始位置 | 可以为任意数值数据类型。n1为0或负数时,按1处理。 | 表达式 |
| n2 | 需要替换的字符个数 | 可以为任意数值数据类型。n2为负数时,按0处理,讲char2添加到char1的第n1个字符前边。 | 表达式 |
| char2 | 需要插入到char1的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,将字符串hello的o替换成good:
select insstr('hello',5,1,'good') from dual;
(CONSTANT) hellgood
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
STUFF函数
STUFF 函数将字符串 char1 从 begin参数所指的位置开始的n 个字符删除,并将 char2 插入到 char1 中 begin 的位置。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要被替换的的字符串 | 可以为任意字符数据类型。 | 表达式 |
| begin | char1需要被替换的开始位置 | 可以为任意数值数据类型。begin为0或负数时,按1处理。 | 表达式 |
| n | 需要替换的字符个数 | 可以为任意数值数据类型。n为负数时,按0处理,讲char2添加到char1的第begin个字符前边。 | 表达式 |
| char2 | 需要插入到char1的字符串 | 可以为任意字符数据类型。 | 表达式 |
例如,将字符串hello的o替换成good:
select stuff('hello',5,1,'good') from dual;
(CONSTANT) hellgood
1 row(s) retrieved.
说明及限制:
- 任意参数为NULL时,返回NULL。
LOCATE函数
LOCATE 函数返回在 char2 串中从位置n开始第一次出现的 char1 的位置,如果 char1 是一个零长度的字符串,LOCATE返回 空,如果 char2 中 char1 没有出现,则返回 0。以字符作为计算单位。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要在char2字符串中查找的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符类型的其他数据类型。 | 表达式 |
| char2 | 需要查找char1的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符类型的其他数据类型。 | 表达式 |
| n | 开始位置 | 取值范围为【-2147483647~2147483647】。参数n为0或负数时,从char2第一个字符开始查找。 | 表达式 |
例如,查看字符串a在字符串南大通用gbase里的位置:
select locate('a','南大通用gbase') from dual;
(EXPRESSION)
7
1 row(s) retrieved.
说明及限制:
- 参数char1为NULL时,返回NULL。
- 参数char2为NULL或空字符串时,返回NULL。
- gbase模式下,该函数以字节为单位。
POSITION函数
POSITION 函数返回在 char2 串中第一次出现的 char1 的位置,如果 char1 是一个零长度的字符串,POSITION 返回 1,如果 char2 中 char1 没有出现,则返回 0。以字节作为计算单位,一个汉字根据编码类型不同可能占据 2 个或多个字节。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char1 | 需要在char2字符串中查找的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符类型的其他数据类型。 | 表达式 |
| char2 | 需要查找char1的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符类型的其他数据类型。 | 表达式 |
例如,查看字符串a在字符串sfdggt a里的位置:
select position('a','sfdggt a') from dual;
(EXPRESSION)
8
1 row(s) retrieved.
说明及限制:
- 目前暂不支持in语法。
- 参数char1为空字符串时,返回1。
- 参数char1为空格字符串时,返回0。
- 参数char2为空字符串或空格字符串时,返回0。
- 当char1或char2为NULL或两个参数都为NULL时,返回NULL。
- 当char1和char2同时为空串时,返回1。
LEFT 函数
LEFT 函数从字符串参数返回由最左边 N 个字符组成的子字符串。
该函数有此语法:
LEFT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| position | 在字符串中的(从左边开始的)顺序位置;要返回此字符及左边的所有字符 | 必须为表达式、常量、列或内建的整数类型或可转换为整数的主变量 | 表达式 |
| source_string | 求值为字符串的表达式 | 必须为表达式、常量、列或可转换为字符类型的数据类型的主变量 | 表达式 |
LEFT 函数的参数不可为用户定义的数据类型。
在从左至右的语言环境中,比如缺省的 U.S. English 语言环境,此函数从 source_string 返回开头字符的子字符串。
LEFT 函数返回的内容依赖于 source_string 中逻辑字符的数目以及 position 的值:
- 如果 source_string 求值为带有多于 position 个字符的字符串,则返回值为 source_string 的子字符串,由指定的 position 左边的所有字符组成。
- 如果 source_string 求值为带有不多于 position 个字符的字符串,则返回值为整个 source_string。
- 如果 source_string 求值为 NULL,或如果 position 为零或负的,则返回 NULL。
- 如果未指定 position 参数,则不返回字符串值,并发出例外。
返回数据类型与它的 source_string 参数相同。如果主变量是源,则返回值为 NVARCHAR 或 NCHAR,根据返回的字符串的长度来定,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
下列函数表达式请求引号括起的字符串的前五个字符:
LEFT('www.gbase.cn',5)
在此示例中,LEFT 函数返回子字符串 www.g
RIGHT 函数
RIGHT 函数从字符串参数返回有最右边的 N 个字符组成的子字符串。
该函数有此语法:
RIGHT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| position | 字符串中的(从右边开始的)顺序位置;返回此字符及右边的所有字符 | 必须为表达式、常量、列或内建的整数类型或可转换为整数的主变量 | 表达式 |
| source_string | 求值为字符串的表达式 | 必须为表达式、常量、列或可转换为数值类型的数据类型的主变量 | 表达式 |
RIGHT 函数的参数不可为用户定义的数据类型。
在从左至右的语言环境中,比如缺省的 U.S. English 语言环境,此函数从 source_string 返回末尾的字符的子字符串。
RIGHT 函数返回的内容依赖于 source_string 中逻辑字符的数目以及 position 的值:
- 如果 source_string 求值为带有多于 position 个字符的字符串,则返回值为 source_string 的子字符串,由指定的 position 右边的所有字符组成。
- 如果 source_string 求值为带有不多于 position 个字符的字符串,则返回值为整个 source_string。
- 如果 source_string 求值为 NULL,或如果 position 为零或负的,则返回 NULL。
- 如果未指定 position 参数,则不返回字符串值,并发出例外。
返回数据类型与它的 source_string 参数相同。如果主变量是源,则返回值为 NVARCHAR 或 NCHAR,根据返回的字符串的长度来定,使用 来自 CONCAT 的返回类型 部分的返回类型提升规则。
下列函数表达式请求由引号括起的字符串的最后五个字符:
RIGHT('www.gbase.cn',5)
在此示例中,RIGHT 函数返回子字符串 se.cn
REPEAT函数
REPEAT 函数返回将字符串 char 重复 n 次的字符串 。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要重复输出的字符串 | 可以为任意字符数据类型或者可以隐式转换为字符数据类型的其他数据类型。 | 表达式 |
| n | 需要重复的次数 | 可以为任意数值类型或者可以隐式转换为数值数据类型的其他数据类型。 | 表达式 |
例如,返回 ABC 重复 3 次的对应字符串:
select repeat('ABC',3) from dual;
(expression)|
------------+
ABCABCABC |
REPEATSTR函数
REPEATSTR 函数返回将字符串 char 重复 n 次的字符串,同 REPEAT 函数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要重复输出的字符串 | 可以为任意字符数据类型。 | 表达式 |
| n | 需要重复的次数 | 可以为任意数值类型。 | 表达式 |
例如,返回 ABC 重复 3 次的对应字符串:
select repeatstr('ABC',3) from dual;
(expression)|
------------+
ABCABCABC |
REPLICATE函数
REPLICATE 函数返回将字符串 char 重复 n 次的字符串,同 REPEAT 函数。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| char | 需要重复输出的字符串 | 可以为任意字符数据类型。 | 表达式 |
| n | 需要重复的次数 | 可以为任意数值类型。 | 表达式 |
例如,返回 ABC 重复 3 次的对应字符串:
select replicate('ABC',3) from dual;
(expression)|
------------+
ABCABCABC |
SUBSTR 函数
SUBSTR 函数与 SUBSTRING 函数有相同的目的(返回源字符串的子集),但它使用不同的语法。
SUBSTR 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| length | 要从 source_string 返回的字符的数目 | 必须为表达式、文字、列或返回整数的主变量 | 表达式 |
| source_string | 作为 SUBSTR 函数的输入的字符串 | 必须为表达式、文字、列或可转换为字符数据类型的数据类型的主变量 | 表达式 |
| start_position | source_string 中的列位置,SUBSTR 函数从此位置开始返回字符 | 必须为整数表达式、文字、列或主变量。可有正号(+)、负号(-)或无符号。 | 精确数值 |
SUBSTR 函数的任何参数都必须为内建的数据类型。
SUBSTR 函数返回 source_string 的子集。该子集从 start_position 指定的列位置开始。下列表格展示数据库服务器如何基于 start_position. 的输入值来确定返回的子集的起始位置
| Start_Position 的值 | 数据库服务器如何确定返回的子集的起始位置 |
|---|---|
| 正的 | 从 source_string 中的第一个字符开始向前计数 |
| 零(0) | 从 source_string 中的第一个字符向前计数(也就是说,将 start_position 0 处理为等同于 1) |
| 负的 | 从紧跟在 source_string 中最后一个字符的原始字符向后计数。值 -1 返回 source_string 中的最后一个字符。 |
length 参数指定子集中逻辑字符的数目(不是字节数)。如果您省略 length 参数,则 SUBSTR 函数返回从 start_position 处开始的 source_string 的整个部分。
如果您指定负的 start_position,其绝对值大于 source_string 中字符的数目,或如果 length 大于从 start_position 至 source_string 的末尾的字符的数目,则 SUBSTR 返回 NULL。(在此情况下,SUBSTR 的行为不同于 SUBSTRING 函数的行为,返回从 start_position 至 source_string 的最后一个字符的所有字符,而不是返回 NULL。)
返回数据类型是 source_string 参数的类型。如果主变量是源,则返回值为 NVARCHAR 或 NCHAR,根据返回的字符串的长度来定,使用 来自 CONCAT 的返回类型 部分描述的返回类型提升规则。
下列示例指定要返回的字符串从 7 个字符的 source_string 结束之前的开始位置 3 个字符开始。这意味着开始的位置是 source_string 的第五个字符。因为用户未指定 length 的值,数据库服务器返回包括从字符位置 5 至 source_string 的结尾的所有字符。
SELECT SUBSTR('ABCDEFG', -3) FROM mytable;
下列表格展示此 SELECT 语句的输出。
(constant)
EFG
SUBSTRB 函数
返回字符串的子字符串,在字符串中指定的位置开始。
SUBSTRB 函数
![]()
| 元素 | 描述 |
|---|---|
| length | 指定以字节计的结果的长度的表达式。如果指定,则表达式必须返回内建的数值、CHAR 或 VARCHAR 数据类型的值。如果该值不是 INTEGER 类型,在对该函数求值之前,隐式地将它强制转型为 INTEGER。 如果 length 的值大于从字符串的起始位置到结束的字节数,则结果的长度等于第一个参数的长度减去起始位置,加一。 如果 length 的值小于或等于零,则 SUBSTRB 的结果为 NULL 字符串。 length 的缺省值是从由 starting_position 指定的位置到字符串最后的字节的字节数。 当指定 length 时,将结果字符串的长度截断为 length 的值。在下列示例中,my_string 是 10 字节的字符串,限定结果字符串为 5 字节: substrB(my_string, 3, 5) 在前面的示例中,如果 my_string 是 4 字节的字符串,且起始位置为第三个字节,则返回 2 字节的字符串。 如果未指定 length,则结果的长度为从 starting_position 开始的 source_string 的长度。在下列示例中,my_string 是 10 字节的字符串,返回 8 字节的字符串: substrB(my_string, 3) |
| source_string | 指定从其派生结果的字符串的表达式。该表达式必须返回内建的字符串、数值或 datetime 数据类型的值。如果该值不是字符串数据类型,则在对该函数求值之前,隐式地将它强制转型为 NVARCHAR。对于零长度结果,返回 NULL 值。 |
| starting_position | 指定结果子字符串的开头的字符串中起始位置的表达式。该表达式必须返回内建的数值、CHAR 或 VARCHAR 数据类型的值。如果该值不是 INTEGER 类型,则在对该函数求值之前,隐式地将它强制转型为 INTEGER。 如果 starting_position 是正的,则从该字符串的开头计算起始位置。如果 starting_position 大于字符串的 length,则返回空字符串。如果 starting_position 是负的,则从该字符串的末尾计算起始位置,且向后对字节数计数。如果 starting_position 的绝对值大于 source_string 的 length,则返回空字符串。如果 starting_position 为 0,则使用起始位置 1。 注: 所有的 length 和 starting_position 的单位都以字节表示,即使对于在多字节代码集中编码的字符串。SUBSTR 使用多字节字符串的逻辑字符大小。例如,如果在传统的 SBSTR 中 starting_position 为 2,且多字节字符串的第一个字符需要 3 字节的存储,则 2 表示字符串中的第四个字节。在 SUBSTRB 中,2 表示字符串中的第二个字节。 |
如果 source_string 是 CHAR 或 VARCHAR 数据类型,则该函数的结果是 VARCHAR 数据类型。 GBase 8s 不支持多代码页;相反, GBase 8s JDBC 或 ODBC 将代码页翻译到数据库。
如果任何参数为空,则结果为空值。
在动态 SQL 中,可由主变量来表示 source_string、starting_position 和 length。如果主变量用作 source_string,则运算对象的数据类型为 VARCHAR,且运算对象可为空。
在上述结果定义中虽未显式地说明,但语义表明,如果 source_string 是多字节字符串,则结果可能包含多字节字符的片段,这依赖于 starting_position 和 length 的值。例如,结果可能起始于多字节字符的第二个字节,或终止于多字节字符的第一个字节。SUBSTRB 函数检测这些部分的字符并以单个空格字符代替不完整字符的每一字节。SUBSTRB 返回固定的字节数;使用 SUBSTR,返回的数目根据多字节字符串而不同。
SUBSTRING 函数
SUBSTRING 函数返回字符串的子集。
SUBSTRING 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| length | 要从 source_string 返回的字符数 | 必须为返回整数的表达式、常量、列或主变量 | 精确数值 |
| source_string | SUBSTRING 函数的字符串参数 | 必须为其值可转换为字符数据类型的表达式、常量、列或主变量 | 表达式 |
| start_position | 在 source_string 中返回首个字符的位置 | 必须为返回整数的表达式、常量、列或主变量 | 精确数值 |
SUBSTRING 函数的任何参数都必须为内建的数据类型。
返回数据类型是 source_string 参数的数据类型。如果主变量是源,则返回值为 NVARCHAR 或 NCHAR,根据返回的字符串的长度来定,使用 来自 CONCAT 函数的返回类型 部分描述的返回类型提升规则。
该子集开始于 start_position 指定的列位置。下列表格展示数据库服务器如何基于 start_position 的输入值来确定返回的子集的起始位置。
| Start_Position 的值 | 数据库服务器如何确定返回子集的起始位置 |
|---|---|
| 正的 | 从 source_string 中的第一个字符向前计数 例如,如果 start_position = 1,则 source_string 中的第一个字符是返回的子集中的第一个字符。 |
| 零(0) | 从 source_string 中的第一个字符之前(即,左边的第一个字符)的一个位置计数 例如,如果 start_position = 0 且 length = 1,则数据库服务器返回 NULL,反之如果 length = 2,数据库服务器返回 source_string 中的第一个字符。 |
| 负的 | 从 source_string 中的最后一个字符之后(即,右边的第一个字符)的一个位置向后计数 例如,如果 start_position = -1,则返回的子集的起始位置是 source_string 中的最后一个字符。 |
由 length 指定子集的大小。length 参数指的是逻辑字符的数目,而不是字节数。如果您省略 length 参数,或如果您指定的 length 大于从 start_position 至 source_string 的末尾的字符数,则 SUBSTRING 函数返回开始于 start_position 的 source_string 的整个部分。下列示例指定起始于列位置 3 的源字符串的子集,且应返回两个字符长。:
SELECT SUBSTRING('ABCDEFG' FROM 3 FOR 2) FROM mytable;
下列表格展示此 SELECT 语句的输出。
(constant)
CD
在下列示例中,用户为返回子集指定负的 start_position:
SELECT SUBSTRING('ABCDEFG' FROM -3 FOR 7) FROM mytable;
数据库服务器在位置 -3 开始(第一个字符之前的四个位置)并向前计数 7 字符。下列表格展示此 SELECT 语句的输出。
(constant)
ABC
SUBSTRING_INDEX 函数
SUBSTRING_INDEX 函数搜索指定的定界符字符的字符串,并基于您指定作为该函数的参数的定界符的计数返回开头或收尾字符的子字符串。
SUBSTRING_INDEX 函数有此语法:
SUBSTRING_INDEX 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_ string | 求值为字符串的表达式 | 必须为内建的字符数据类型,或可转换为字符类型的表达式、常量、列或主变量 | 表达式 |
| count | 求值为正整数或负整数的表达式 | 必须为内建的整数类型,或可转换为整数的表达式、常量、列或主变量。 | 表达式 |
| delimiter | 求值为字符串的表达式 | 必须为内建的字符数据类型,或可转换为字符类型的表达式、常量、列或主变量 | 表达式 |
SUBSTRING_INDEX 的参数不可为用户定义的数据类型。
在下列的每一情况下,此函数返回 NULL:
- source_string 为 NULL
- delimiter 为 NULL
- count = 零(0)。
如果该搜索在 source_string 中找到少于 count 个定界符,则返回值为整个 source_string。
返回值与 source_string 的数据类型相同。
对于 source_string,count 的符号决定返回的值是 source_string 中开头字符的子字符串还是收尾字符的子字符串:
- 对于 N = count,返回的子字符串的最后的字符紧接在开头的字符的子字符串中那个定界符第 N 次出现的前面。
例如函数表达式
SUBSTRING_INDEX("www.gbase.cn", ".", 2)
返回开头字符 www.gbase,因为 count > 0。
- 对于 N = count < 0,返回的子字符串中的第一个字符紧接在收尾字符的子字符串中那个定界符第 N 次出现之前。
例如,函数表达式
SUBSTRING_INDEX("www.gbase.cn", ".", -2)
返回收尾字符 gbase.cn,因为 count < 0。
上述示例适用于诸如缺省的 U.S. English 语言环境这样的从左至右的语言环境,其中 count 的负值导致此函数从 source_string 返回收尾字符的子字符串,而 count 的正值导致此函数从 source_string 返回开头字符的子字符串。
在支持多字节字符集的语言环境中,返回值是 source_string 中的逻辑字符之中的顺序值。在诸如缺省的语言环境这样的语言环境中,返回值等同于字节位置,在此,第一个字节在位置 1。
FORMAT_UNITS 函数
FORMAT_UNITS 函数可解释指定内存或大量存储的单位的数目和缩写名称的字符串。
此内建的函数可接受一个、两个或三个由引号括起的字符串参数。您可调用通过内存或大量存储的字节或更大的单位(比如,kilobyte、megabyte、gigabyte 等等)的标准缩写来表示处理大小规范的 SQL 语句中的 FORMAT_UNITS。
还可通过 SQL 管理 API ADMIN 和 TASK 函数来在 sysadmin 数据库中内部调用 FORMAT_UNITS 函数,在 GBase 8s 管理员参考 中有对其的描述。
FORMAT_UNITS 函数
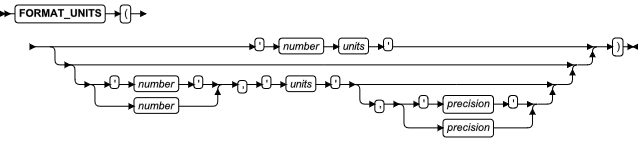
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| number | 求值为存储或内存 units 的数目的表达式 | 必须为文字数值或指定可转换为 FLOAT 的数目的由引号括起的字符串 | 表达式 |
| precision | 要从 number 返回的有效数值的整数数目 | 必须为文字数值或指定整数的引用字符串 | 表达式 |
| units | 存储或内存的单位的缩写;缺省值为 'B'(表示字节) | 必须以 'B'、'K'、'M'、'G'、'T'、'P' 或 'PB'(或这些字母的小写形式)开头。忽略任何收尾字符。 | 引用字符串 |
此内建的函数可接受一个、两个或三个参数。返回的值是展示指定的 number 和展示存储单位的适当的格式标签的字符串。如果您指定 precision 作为最后的参数,则以那个精度返回 number。否则,在缺省情况下,将 number 格式化为精度 3(%3.3lf)。
同样的表示法也适用于所有 SQL 管理 API ADMIN 和 TASK 命令的参数(效仿 Enterprise Replication cdr 实用程序的命令除外),这些参数指定内存、存盘存储或地址偏移量的大小:
表示法 对应的单位
'B' 或 'b' 字节(= 以 2 为底,指数为 0)
'K' 或 'k' 千字节(= 以 2 为底,指数为 10)
'M' 或 'm' Megabyte(= 以 2 为底,指数为 20)
'G' 或 'g' Gigabyte(= 以 2 为底,指数为 30)
'T' 或 't' Terabyte(= 以 2 为底,指数为 40)
'PB' Petabyte(= 以 2 为底,指数为 50)
'P' 页(= 2 千字节或 4 千字节,依赖于系统的基础页大小)
unit 规范中的首字母('B'、'K'、'M'、'G' 或 'T')确定计量的单位,并忽略任何收尾的字符。然而,有一个例外,那就是在字符串中首字母 'P'(或 'p')紧跟着 'B' 或 'b',因为在此情况下,将该字符解释为 petabyte。将任何其他以 "P"(比如 "PA"、"pc"、"PhD"、"papyrus",等等)起始的字符串解释为指定 pages,而不是指定 petabytes。
如果一个参数同时提供 number 和 units 规范,则 GBase 8s 忽略将 number 规范从 FORMAT_UNITS 或 SQL 管理 API ADMIN 或 TASK 函数的同一参数之内的 units 规范分隔开的任何空格。例如,将规范 '128M' 与 '128 m' 都解释为 128 megabyte。
下列示例以单个参数调用 FORMAT_UNITS 函数:
EXECUTE FUNCTION FORMAT_UNITS('1024 M');
返回下列字符串值。
(expression)
1.00 GB
SELECT FORMAT_UNITS('1024 k') FROM systables WHERE tabid=1;
返回下列字符串值。
(expression)
1.00 MB
SELECT FORMAT_UNITS(tabid || 'M') FROM systables WHERE tabid=100;
返回下列字符串值。
(expression)
100 MB
下列示例展示以两个参数调用 FORMAT_UNITS 函数:
EXECUTE FUNCTION FORMAT_UNITS(1024, 'k');
返回下列字符串值。
(expression)
1.00 MB
SELECT FORMAT_UNITS( SUM(chksize), 'P') SIZE,
FORMAT_UNITS( SUM(nfree), 'p') FREE FROM syschunks;
size 117 MB
free 8.05 MB
此查询返回字符串值 size 117 MB 和 free 8.05 MB。
下列示例以三个参数调用 FORMAT_UNITS 函数:
EXECUTE FUNCTION FORMAT_UNITS(1024, 'k', 4);
返回下列字符串值。
(expression)
1.000 MB
SELECT FORMAT_UNITS( SUM(chksize), 'P', 4), SIZE,
FORMAT_UNITS( SUM(nfree), 'p', 4) FREE FROM syschunks;
size 117.2 MB
free 8.049 MB
此查询返回字符串值 size 117.2 MB 和 free 8.047 MB。这些结果与前面仅以它们的非缺省的精度进行查询的示例不同,由 FORMAT_UNITS 的最后一个参数指定精度。
IFX_ALLOW_NEWLINE 函数
IFX_ALLOW_NEWLINE 函数设置换行模式,在当前的会话内在用引号括起来的字符串中允许还是不允许换行字符。
IFX_ALLOW_NEWLINE 函数有下列语法。
IFX_ALLOW_NEWLINE 函数
![]()
如果您输入 't' 作为此函数的参数,则在该会话中启用用引号括起来的字符串中的换行字符。如果您输入 'f' 作为参数,则在该会话中不允许用引号括起来的字符串中的换行字符。
您可通过将 ONCONFIG 文件中的 ALLOW_NEWLINE 参数设置为值 0(不允许换行字符)或值 1(允许换行字符)来为所有会话设置换行模式。如果您未设置此配置参数,则缺省的值为 0。您每一次启动会话时,新的会话继承 ONCONFIG 文件中的换行模式设置。要更改会话的换行模式,请执行 IFX_ALLOW_NEWLINE 函数。一旦您已为会话设置了换行模式,该模式保持有效,直到会话结束为止,或直到您在会话内在此执行 IFX_ALLOW_NEWLINE 函数为止。
在下列示例中,假设您未为 ONCONFIG 文件中的 ALLOW_NEWLINE 指定任何值,因此,在缺省情况下,在任何会话中的用引号括起来的字符串中不允许换行字符。在您启动新的会话之后,您可通过执行 IFX_ALLOW_NEWLINE 函数来启用那个会话中的用引号括起来的字符串中的换行字符:
EXECUTE PROCEDURE IFX_ALLOW_NEWLINE('t');
在 ESQL/C 中,通过 ONCONFIG 文件中 的 ALLOW_NEWLINE 参数设置换行模式,或通过在会话中执行 IFX_ALLOW_NEWLINE 函数设置换行模式,换行模式仅适用于 SQL 语句中的用引号括起来的字符串文字。换行模式不适用于 SQL 语句中包含在主变量中的用引号括起来的字符串。主变量可在字符串数据内包含换行字符,不理会当前生效的换行模式。
例如,您可使用主变量来将包含换行字符的数据插入到列内,即使 ONCONFIG 文件中的 ALLOW_NEWLINE 参数设置为 0。
要获取关于 IFX_ALLOW_NEWLINE 函数如何影响用引号括起来的字符串的更多信息,请参阅 引用字符串。要获取关于 ONCONFIG 文件中的 ALLOW_NEWLINE 参数的更多信息,请参阅 GBase 8s 管理员参考手册。
正则表达式函数
REGEXP_COUNT
匹配字符串在源串中出现的次数。返回pattern 在source_char 串中出现的次数。如果未找到匹配,则函数返回0。

REGEXP_COUNT ( source_char, pattern [, position [, match_param]])
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 源字符串 | 可以是字符串或列名。当源字符串source_char是列名时,支持的类型为char和varchar型。 | 表达式 |
| pattern | 正则表达式 | 支持的数据类型为char和varchar型。每个正则表达式最多可包含512个字节。 | 表达式 |
| position | 开始匹配的位置 | 如果不指定默认为1,即从source_char的第一个字符开始匹配。 | 表达式 |
| match_param | 可通过设置该参数改变默认的匹配功能行为 | 默认情况下“.”不匹配换行符,源字符串被看作一行。参数可选项如下:i:大小写不敏感;c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 | 表达式 |
例如,返回字符串中’s’出现的次数:
SELECT REGEXP_COUNT('gbase 8s', 's') FROM dual
返回结果为:2。
REGEXP_LIKE
模糊匹配指定的字符串,返回源字符串中与pattern指定的正则表达式相匹配的字符串。

REGEXP_LIKE(source_char,pattern[,match_paramater])
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 源字符串 | 可以是字符串或列名。当源字符串source_char是列名时,支持的类型为char和varchar型。 | 表达式 |
| pattern | 正则表达式 | 支持的数据类型为char和varchar型。每个正则表达式最多可包含512个字节。 | 表达式 |
| match_param | 可通过设置该参数改变默认的匹配功能行为 | 默认情况下“.”不匹配换行符,源字符串被看作一行。参数可选项如下:i:大小写不敏感;c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 | 表达式 |
例如,查询表t1中列FName中含有’s’或者’S’的记录:
SELECT * FROM t1 WHERE REGEXP_LIKE(FName, 's', ‘i’)
REGEXP_SUBSTR
提取指定字符串的子串,找出源字符串中与pattern指定的正则表达式相匹配的字符串。
REGEXP_SUBSTR(source_char,pattern[,position[,occurence[,match_option[,subexpr]]])
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 源字符串 | 可以是字符串或列名。当源字符串source_char是列名时,支持的类型为char和varchar型。 | 表达式 |
| pattern | 正则表达式 | 支持的数据类型为char和varchar型。每个正则表达式最多可包含512个字节。 | 表达式 |
| position | 开始匹配的位置 | 如果不指定默认为1,即从source_char的第一个字符开始匹配。 | 表达式 |
| occurrence | 匹配的次数 | 如果不指定,默认为1,即从第一次与pattern匹配上的字符串开始搜索,如果该值大于1,表示忽略第一次的匹配,从指定的次数的第一个字符开始搜索。 | 表达式 |
| match_param | 可通过设置该参数改变默认的匹配功能行为 | 默认情况下“.”不匹配换行符,源字符串被看作一行。参数可选项如下:i:大小写不敏感;c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 | 表达式 |
| subexpr | 对于含有子表达式的pattern,subexpr是0~9的整数,表示pattern中的第几个子串是函数目标 | Subexpr是pattern中圆括号里的字符串片段,子表达式可嵌套。子表达式按照其左括号出现的顺序编号。如果subexpr是0,返回整个与pattern匹配的字符串的位置;如果大于0,返回指定子串的位置。如果没有与pattern匹配的字符串,函数返回0,空subexpr返回null。该值默认为0。 | 表达式 |
例如:
SELECT REGEXP_SUBSTR('192.168.1.100','[^.]+',1,4) FROM dual
返回结果为:100。
REGEXP_INSTR
获得匹配字符串的起始位置,返回与pattern指定的正则表达式相匹配的字符串在源字符串中的位置。
REGEXP_INSTR(source_char,pattern[,position[,occurence[,return_opt[,match_parameter [,subexpr]]]]])
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 源字符串 | 可以是字符串或列名。当源字符串source_char是列名时,支持的类型为char和varchar型。 | 表达式 |
| pattern | 正则表达式 | 支持的数据类型为char和varchar型。每个正则表达式最多可包含512个字节。 | 表达式 |
| position | 开始匹配的位置 | 如果不指定默认为1,即从source_char的第一个字符开始匹配。 | 表达式 |
| occurrence | 匹配的次数 | 如果不指定,默认为1,即从第一次与pattern匹配上的字符串开始搜索,如果该值大于1,表示忽略第一次的匹配,从指定的次数的第一个字符开始搜索。 | 表达式 |
| return_opt | 指定返回值的类型 | 如果该参数为0,则返回值为匹配位置的第一个字符,如果该值为非0则返回匹配值的最后一个位置。 | 表达式 |
| match_param | 可通过设置该参数改变默认的匹配功能行为 | 默认情况下“.”不匹配换行符,源字符串被看作一行。参数可选项如下:i:大小写不敏感;c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 | 表达式 |
| subexpr | 对于含有子表达式的pattern,subexpr是0~9的整数,表示pattern中的第几个子串是函数目标 | Subexpr是pattern中圆括号里的字符串片段,子表达式可嵌套。子表达式按照其左括号出现的顺序编号。如果subexpr是0,返回整个与pattern匹配的字符串的位置;如果大于0,返回指定子串的位置。如果没有与pattern匹配的字符串,函数返回0,空subexpr返回null。该值默认为0。 | 表达式 |
例如,找到字符串中的第一个’e’的位置:
SELECT REGEXP_INSTR('hello world', 'e') FROM dual
返回结果为:2。
REGEXP_REPLACE
将匹配获得的字符串替换成指定的字符串,用replace_string指定的字符串替换字符串中与pattern指定的正则表达式相匹配的字符串。
REGEXP_REPLACE(source_char,pattern[,replace_string[,position[,occurence[match_option]]]])
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_char | 源字符串 | 可以是字符串或列名。当源字符串source_char是列名时,支持的类型为char和varchar型。 | 表达式 |
| pattern | 正则表达式 | 支持的数据类型为char和varchar型。每个正则表达式最多可包含512个字节。 | 表达式 |
| replace_string | 替换字符串 | 可以是字符串或列名,当替换字符串为列名时,支持的类型为char和varchar型。替换字符串至多可以包含500个反向引用的数字表达式(\n,n的取值范围是[1,9])。如果替换字符串中含有“\”,可通过转义字符“\”转义。 | 表达式 |
| position | 开始匹配的位置 | 如果不指定默认为1,即从source_char的第一个字符开始匹配。 | 表达式 |
| occurrence | 匹配的次数 | 如果不指定,默认为1,即从第一次与pattern匹配上的字符串开始搜索,如果该值大于1,表示忽略第一次的匹配,从指定的次数的第一个字符开始搜索。 | 表达式 |
| match_param | 可通过设置该参数改变默认的匹配功能行为 | 默认情况下“.”不匹配换行符,源字符串被看作一行。参数可选项如下:i:大小写不敏感;c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 | 表达式 |
例如,将非数字的数据信息替换成空:
SELECT REGEXP_REPLACE('hjbe8723r8fb938r', '[^0-9]') FROM dual
返回结果为:87238938。
加密和解密函数
GBase 8s 支持内置加密和解密函数。
加密和解密函数支持列级别加密,即对给定列中的所有值都用相同的password 进行加密。并且加密和解密函数不支持对大对象数据进行加解密。
ENCRPYPT_AES 函数
ENCRYPT_AES 函数使用 AES(高级加密标准)算法进行加密。
加密函数语法:

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| data | 要进行加密的明文或列名。 | 不可省略。 | 表达式 |
| password | 加密函数设置的密码。缺省值是由 SET ENCRYPTION PASSWORD语句定义的会话密码值。 | 6 字节≤ password ≤128 字节。 | 表达式 |
| hint | 密码提示信息。缺省值是的是来自定义 password 的 SET ENCRYPTION PASSWORD的 WITH HINT 子句的值。 | 可以省略,0 字节≤ hint ≤32 字节。 | 表达式 |
当使用SET ENCRYPTION PASSWORD语句设置密码时,加密函数的 password参数可以省略,否则不可省略。
hint 的目的是帮助用户记忆password。
如果列定义长度小于加密函数返回的数据大小,则插入此加密值时它就会被截断。在此情况下,加密数据就无法再通过解密函数解密。
例如,下列语句创建名为 customer 的表,其中列 creditcard 可存储加密的信用卡号码:
CREATE TABLE customer (id CHAR(20), creditcard CHAR(107));
指定密码(和可选的提示),使用 ENCRYPT_AES 函数进行加密:
SET ENCRYPTION PASSWORD 'abc123' WITH HINT 'zimushuzi';
INSERT INTO customer VALUES ('1001', ENCRYPT_AES('1234567890123456'));
在此,SET ENCRYPTION PASSWORD 定义的session password 和 hint,用作 ENCRYPT_AES 函数缺省的第二和第三个参数。
ENCRPYPT_TDES 函数
ENCRYPT_TDES 函数使用 TDES(三重数据加密标准)算法进行加密。其用法与ENCRYPT_AES 函数相同。
DECRYPT_CHAR 函数
DECRYPT_CHAR 函数是解密函数,函数的返回值为加密前的原始数据。
DECRYPT_CHAR 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| encrypted_data | 加密函数的返回值,可以是加密后字符串或列。 | 不可省略。 | 表达式 |
| password | 加密函数设置的密码。缺省值是由 SET ENCRYPTION PASSWORD语句定义的会话密码值。 | 6 字节≤ password ≤128 字节。 | 表达式 |
解密需要加密密码 password,当已经使用 SET ENCRYPTION PASSWORD语句设置密码时,可以省略password参数,否则不能省略此参数。
如果用于解密的password与用于加密的password不同,那么会产生错误。
例如,基于前面的示例,使用解密功能,查询加密了的数据:
SELECT id, DECRYPT_CHAR(creditcard,’abc123’) FROM customer;
返回结果如下:
id creditcard
---
1001 1234567890123456
GETHINT 函数
GETHINT 函数获取密码提示信息,返回值为加密函数设置的 hint 值或先前执行SET ENCRYPTION PASSWORD 语句设置的 hint值。
GETHINT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| encrypted_data | 要获取密码提示的数据,可以是加密后的字符串或列。 | 不可省略。 | 表达式 |
例如,基于前面的示例,以下语句获取 customer 表的提示信息:
SELECT GETHINT(creditcard) FROM customer;
返回结果:
zimushuzi
MD5 函数
MD5 函数生成并返回符合 MD5 算法的数据特征值。
MD5 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要获取特征值的数据。 | 不可省略。不能是大对象、布尔类型、集合数据类型。 | 表达式 |
expr 设置为 NULL 时,函数返回 NULL。
例如,假定 tab1 表不为空,执行以下语句:
SELECT MD5(‘abc’) FROM tab1;
汉字转拼音函数
GetHzFullPY 函数
GetHzFullPY 函数将汉字转换为全拼。
GetHzFullPY 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要转换为全拼的汉字。 | 不能为 NULL,可以是字符型、整数型数据。 | 表达式 |
函数返回值为字符型。使用时,除汉字按顺序转换为全拼外,其余字符(包括数字)都不进行转换,保留原值。转换完的拼音字符串缺省为小写。
例如,假定 tab1 表内容不为空,执行以下语句:
SELECT GETHZFULLPY(‘汉字123’) FROM tabl;
返回结果如下:
hanzi123
GetHzPYCAP 函数
GetHzPYCAP 函数将汉字转换为拼音首字母。
GetHzPYCAP 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要转换成拼音首字母的汉字。 | 不能为 NULL,可以是字符型、整数型数据。 | 表达式 |
函数返回值为字符型。使用时,除汉字按顺序转换为拼音首字母外,其余字符(包括数字)都不进行转换,保留原值。转换完的拼音字符串缺省为小写。
例如,假定 tab1 表内容不为空,执行以下语句:
SELECT GETHZPYCAP(‘汉字’) FROM tabl;
返回结果如下:
hz
GetHzFullPYsubstr 函数
GetHzFullPYsubstr函数将汉字转换为拼音后,提取指定个连续字符。
GetHzFullPYsubstr函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| source_string | 要转换为拼音的汉字。 | 不能省略,必须是字符型数据。 | 表达式 |
| start_position | 源字符串转换为拼音后,提取字符的偏移量。 | 不能省略,不能为 0 或负数。必须是数值型数据。 | 表达式 |
| length | 返回的字符个数。 | 可以省略,不能为 0 或负数。必须是数值型数据。 | 表达式 |
GetHzFullPYsubstr函数返回将 source_string 转换为拼音的字符串的子集。该子集从 start_position 指定的位置开始向前计数。start_position 值从 1 开始,值 1 表示字符串第一个字符位置。
length 参数指定提取字符的长度。如果您省略 length 参数,则GetHzFullPYsubstr函数返回从 start_position 处开始的拼音字符串。
例如,假定 tab1 表不为空,执行以下语句:
SELECT GETHZFULLPYSUBSTR(‘汉字’,1,2) FROM tabl;
返回结果如下:
ha
如果 length 为小数,则只取其整数部分。例如,执行以下语句:
SELECT GETHZFULLPYSUBSTR(‘汉字’,1,2.6) FROM tabl;
返回结果如下:
ha
SYS_GUID 函数
SYS_GUID 函数生成并返回一个全球唯一标识符,它由 16 个字节组成。在大多数平台,生成的标识符由主机标识符、执行函数的进程或线程标识符、和进程或线程的一个非重复的值(字节序列)。
SYS_GUID 函数
![]()
以下示例,用户使用 SYS_GUID() 函数获得一个全球唯一标识符。
SELECT sys_guid() FROM sysmaster:sysdual;
返回结果如下:
4A4F072262CC6D8AE050A8C0EB075197
分组统计函数
GROUPING(expr) 函数
GROUPING(expr) 函数表示参数列expr是否为分组列(分组列指参与分组的列),并返回一个数值。当该参数对应的列为分组列时,返回值为0;当该参数对应的列非分组列时,返回值为1。
GROUPING(expr) 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 判断是否参与分组的表达式 | 必须是GROUP BY子句中的表达式之一 | 标识符 |
GROUPING函数的返回值类型为整型数值。
GROUPING函数的参数仅支持一个。
GROUPING函数的参数expr必须是GROUP BY子句中的表达式之一。
GROUPING函数的参数expr不支持为 NULL。
GROUPING_ID 作为分组函数,不能出现在 WHERE 或连接条件中。
当在视图中使用SELECT GROUPING ()时,必须使用别名,否则报错。
使用HAVING GROUPING ()时,不可用别名,须直接使用函数表达式。
示例:
例如,表 tab 1 表结构如下:
CREATE TABLE tab1 (
c1 int,
c2 int,
c3 varchar(20)
);
插入如下数据:
INSERT INTO tab1 values(1,1,'test1');
INSERT INTO tab1 values(1,2,'test2');
INSERT INTO tab1 values(2,1,'test3');
INSERT INTO tab1 values(2,2,'test4');
对表 tab1 的 c1、c2、c3列进行 ROLLUP 分组,统计分组组合包括 (c1,c2,c3),(c1,c2),(c1),全空 四种分组组合。
使用GROUPING()函数返回c1,c2,c3列是否参与分组。
SELECT GROUPING (C1),GROUPING (C2),GROUPING (C3),c1,c2,c3 FROM tab1 GROUP BY ROLLUP (c1,c2,c3);
返回结果如下:
(grouping) |(grouping) |(grouping) |c1 |c2 |c3 |
-----------|-----------|-----------|---|---|------|
0 |0 |0 |2 |2 |test4 |
0 |0 |0 |1 |2 |test2 |
0 |0 |0 |2 |1 |test3 |
0 |0 |0 |1 |1 |test1 |
0 |0 |1 |1 |2 | |
0 |0 |1 |2 |1 | |
0 |0 |1 |2 |2 | |
0 |0 |1 |1 |1 | |
0 |1 |1 |2 | | |
0 |1 |1 |1 | | |
1 |1 |1 | | | |
GROUPING_ID 函数
GROUPING_ID 函数表示参数是否参与分组的向量值(分组统计语法中,分组组合指其中的单列或多列表达式的某种分组情况),返回数值的二进制位对应表示参数列是否为分组列。当参与分组时,参数位为 0 ;否则为 1 。
GROUPING_ID 函数
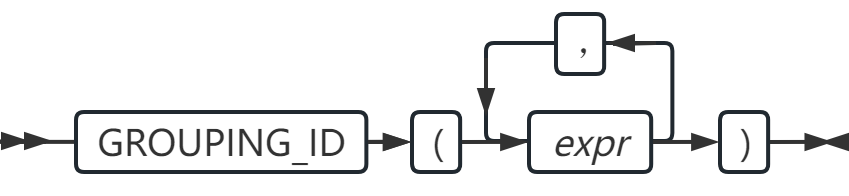
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 判断是否参与分组的表达式 | 必须是GROUP BY子句中的表达式之一 | 标识符 |
返回值计算规则如下:
GROUPING_ID(expr1,expr2,……)中的每个参数expr对应一个列,当该参数对应的列为分组列时,该参数位的值为 0,否则为 1。最后将所有参数位的值串联在一起,组成一个0和1的二进制数,再将该二进制数转换为一个十进制数,即为GROUPING_ID的返回值。
例如,GROUPING_ID(c1,c2) 返回值为 2 ,对应二进制数值为 10 ,表示 c1 列未参与, c2 列参与分组。
GROUPING_ID函数的返回值类型为整型数值。
GROUPING_ID函数的参数支持多个。参数限制和 GROUP BY参数限制保持一致。
GROUPING_ID函数的参数expr必须是GROUP BY子句中的表达式的子集。
GROUPING_ID函数的参数expr不支持为 NULL。
GROUPING_ID 作为分组函数,不能出现在 WHERE 或连接条件中。
当在视图中使用SELECT GROUPING_ID ()时,必须使用别名,否则报错。
使用HAVING GROUPING_ID ()时,不可用别名,需直接使用函数表达式。
示例:
例如,表 tab 1 表结构如下:
CREATE TABLE tab1 (
c1 int,
c2 int,
c3 varchar(20)
);
插入如下数据:
INSERT INTO tab1 values(1,1,'test1');
INSERT INTO tab1 values(1,2,'test2');
INSERT INTO tab1 values(2,1,'test3');
INSERT INTO tab1 values(2,2,'test4');
对表 tab1 的 c1、c2列进行 CUBE分组,统计分组组合包括 (c1,c2),(c1),(c2),全空 四种分组组合。
使用GROUPING_ID(c1,c2) 函数返回c1,c2列是否参与分组的向量值。
SELECT GROUPING (C1),GROUPING (C2),GROUPING_ID (c1,c2),c1,c2 FROM tab1 GROUP BY CUBE (c1,c2);
返回结果如下:
(grouping) |(grouping) |(grouping_id) |c1 |c2 |
-----------|-----------|--------------|---|---|
1 |1 |3 | | |
0 |1 |1 |2 | |
0 |1 |1 |1 | |
1 |0 |2 | |1 |
1 |0 |2 | |2 |
0 |0 |0 |1 |1 |
0 |0 |0 |1 |2 |
0 |0 |0 |2 |2 |
0 |0 |0 |2 |1 |
GROUP_ID 函数
GROUP_ID函数返回重复分组的唯一标识值,用于表示结果集来自于哪一个分组,区别相同分组的结果集。
GROUP_ID 函数

返回值计算规则如下:
如果有 N 个相同分组,则 GROUP_ID 取值从 0..N-1。每组的初始值为 0。
GROUP_ID函数的返回值类型为整型数值。
GROUP_ID 作为分组函数,不能出现在 WHERE 或连接条件中。
当在视图中使用SELECT GROUP_ID ()时,必须使用别名,否则报错。
ORDER BY选择项使用GROUP_ID时,GROUP_ID必须加别名。例如,select group_id() as gid ,c1,c2 from tab1 group by rollup (c1,c2) order by gid; 。
示例:
例如,表 tab 1 表结构如下:
CREATE TABLE tab1 (
c1 int,
c2 int,
c3 varchar(20)
);
插入如下数据:
INSERT INTO tab1 values(1,1,'test1');
INSERT INTO tab1 values(1,2,'test2');
INSERT INTO tab1 values(2,1,'test3');
INSERT INTO tab1 values(2,2,'test4');
对表 tab1 的 c1、c1、c1列进行 GROUPING SETS分组,统计分组组合包括 (c1),(c1),(c1) 三种分组组合。
使用GROUP_ID () 函数返回重复分组 (c1) 的唯一标识值。
SELECT GROUP_ID(),c1 FROM tab1 GROUP BY GROUPING SETS (c1,c1,c1);
返回结果如下:
group_id() |c1 |
-----------|---|
2 |2 |
2 |1 |
1 |2 |
1 |1 |
0 |2 |
0 |1 |
分析函数
KEEP(DENSE_RANK FIRST/LAST)函数
KEEP(DENSE_RANK FIRST/LAST) 函数首先根据SQL语句中的group by分组(如果没有指定分组则所有结果集为一组),然后在组内进行排序。根据FIRST/LAST计算第一名(最小值)或者最后一名(最大值)的指定字段的值。

| 元素 | 描述 | 限制 |
|---|---|---|
| aggregate_function | 聚集函数名称。 | 不能省略。 |
| exrp | 按照此表达式排序的列名或常量表达式。 | 不能为聚集表达式。 |
FIRST和LAST函数对一组行中的一组值进行聚集操作,这些行根据给定的排序规则排序。如果FIRST或LAST的结果只有一行,则聚集只对一行进行操作。
aggregate_function是MIN、MAX、SUM、AVG、COUNT、RANGE、VARIANCE或STDDEV函数中的任何一个。它对来自FIRST或LAST排序的行的值进行聚集操作。如果FIRST或LAST只有一行结果,则聚集只对一行进行操作。
KEEP关键字用于语义清晰度。它限定了aggregate_function,表示只返回aggregate_function的FIRST或LAST值。
DENSE_RANK FIRST或DENSE_RANK LAST表示仅聚集具有最小(FIRST)或最大(LAST)值的行。
示例:
获取部门内年龄最小的人中,工资最高的记录。首先构造一下临时数据:
WITH workers AS(
SELECT 'DOM1' dept, 'zsan' names , 23 age, 4000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'lisi' names , 35 age, 9000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'wangwu' names , 26 age, 6500 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'maliu' names , 28 age, 6000 salaries FROM dual UNION ALL
SELECT 'DOM2' dept, 'zhaoqi' names , 26 age, 5000 salaries FROM dual UNION ALL
SELECT 'DOM1' dept, 'liba' names , 23 age, 3000 salaries FROM dual
)
在这六条数据中,我们期望的数据是:(DOM1,4000)和(DOM2,6500),SQL如下:
SELECT w.dept, MAX(w.salaries)
KEEP(DENSE_RANK FIRST ORDER BY w.age) max_salary
FROM workers w
WHERE 1=1
GROUP BY dept;
列转行函数
WM_CONCAT 函数
WM_CONCAT 函数可以将结果集中指定列的数据合并成一行。WM_CONCAT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要合并为一行的数据 | 可以是数值型、字符型和日期型数据。 | 表达式 |
函数返回值为 LVARCHAR数据类型。返回值的长度不能超过 16380字节。转换完指定列的多条记录合并到一行,多个记录使用逗号分隔。
如果返回值的长度超过 16380 字节,则会截断超长的字符,保存截断后的结果。所以对于列转行函数返回值长度超过 16380 字节的情况,请使用 WM_CONCAT_TEXT() 函数以保存完整值。
例如,假定 tab1 表内容不为空:
SELECT col1 FROM tabl;
返回结果如下:
col1
-----------
1001
1002
1003
1004
执行以下语句:
SELECT wm_concat (col1) col1 FROM tabl;
返回结果如下:
col1
------------------------
1001,1002,1003,1004
WM_CONCAT_TEXT 函数
WM_CONCAT_TEXT 函数可以将结果集中指定列的数据合并成一行。WM_CONCAT_TEXT 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr | 要转为一行的数据 | 可以是数值型、字符型和日期型数据。 | 表达式 |
函数返回值为 TEXT数据类型。转换完指定列的多条记录合并到一行,多个记录使用逗号分隔。
当函数的返回值超过 16380 字节时,推荐使用该函数。
LISTAGG函数
LISTAGG 函数可以将多行记录合并成单行。LISTAGG函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| measure_expr | 需要合并多行记录的表达式 | 支持列名、常量、列表达式,不支持大对象、集合等复杂数据类型,支持普通函数嵌套,不支持聚合函数嵌套。如果为’’或者Null,则函数返回Null。 | 表达式 |
| delimiter | 分隔多行记录的分隔符 | 使用时,用’’包围,支持字母、数字、下划线及, | *”等字符,不支持’。支持一个或多个字符,多字符不少于3个。支持省略,省略时按空字符处理。 | 引用字符串 |
| order_by_clause | 多行记录合并时,按照该参数指定的列排序 | 支持多个列名,多列名时,按照从前到后的顺序依次排序。不支持省略。 | 表达式 |
函数的返回值类型为字符型,WITHIN GROUP子句不能省略,与group by子句连用时为聚集函数,返回的结果集按照group by子句分组,同一组内measure_expr的多个记录按照order_by_clause指定列名排序合并成一行记录,结果集的条数是组的个数,且投影列必须包含group by子句的列。不带group by子句使用时,函数返回值为单行,此时不能与返回多行的表达式同时出现在投影列中。注意LISTAGG函数暂不支持与OVER子句连用。
例如,用户表TUser,字段FDepartmentID记录了用户所属部门id,可以通过LISTAGG函数得到各个部门下所有用户:
SELECT FDepartmentID, LISTAGG(FName, ',')
WITHIN GROUP(order by FDepartmentID) FName
FROM TUser
GROUP BY FDepartmentID
JSON操作函数
JSON_EXTRACT函数
按照path参数的路径,返回JSON文档中的数据。如果其中任意一个为null或者不能在JSON文档中定位路径时,则返回NULL。当JSON文档无效时抛出错误。匹配路径参数的所有值都会被返回。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| json_doc | JSON文档 | 内容必须符合json格式 | 表达式 |
| path | JSON文档中返回值所在路径 | 满足json路径表达式。 | 表达式 |
例如:提取json文档[10, 20, [30, 40]]中第2个和第3个元素。
> SELECT JSON_EXTRACT('[10, 20, [30, 40]]', '$[1]','$[2]') from dual;
(CONSTANT)
[20,[30,40]]
1 row(s) retrieved.
说明及限制:
- oracle模式下运行
- 返回值为字符类型。
JSON_REPLACE函数
按照path参数的路径,替换JSON文档中的数据。如果其中任意一个为null或者不能在JSON文档中定位路径时,则返回NULL。当JSON文档无效或者path无效或者包含一个或多个通配符*时抛出错误。
文档中现有路径的路径值对会用新值覆盖现有文档值。文档中不存在路径的路径-值对被忽略,并且没有效果。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| json_doc | JSON文档 | 内容必须符合json格式 | 表达式 |
| path | JSON文档中返回值所在路径 | 满足json路径表达式。 | 表达式 |
| expr | 替换后的字符串 | 满足字符串格式 | 字符串 |
例如:对json格式{ "a": 1, "b": [2, 3]}中a的值进行替换,替换为10。对b的值替换为[true, false]
> SELECT JSON_REPLACE('{ "a": 1, "b": [2, 3]}', '$.a', 10, '$.b', '[true, false]') from dual;
(CONSTANT)
{"a":10,"b":[true,false]}
1 row(s) retrieved.
说明及限制:
- oracle模式下运行
- 返回值为字符类型,mysql返回数组。
JSON_UNQUOTE函数
取消引用JSON值,并将结果作为字符串返回。如果参数为NULL,则返回NULL。如果值以双引号开始和结束,但不是有效的JSON字符串文字,则会出现错误。

参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| json_doc | JSON文档 | 内容必须符合json格式 | 表达式 |
例如:将json数据{ "a": 1, "b": [2, 3]}转为字符串。
> SELECT JSON_UNQUOTE('{ "a": 1, "b": [2, 3]}') from dual;
(CONSTANT) {
"a": 1,
"b": [2, 3]
}
1 row(s) retrieved.
说明及限制:
- oracle模式下运行
线性回归函数
REGR_SLOPE
去除含空值的数值对后,计算回归曲线的斜率。返回类型为DECIMAL(32)。计算公式为:COVAR_POP(expr1,expr2)/VAR_POP(expr2)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_SLOPE函数计算线性函数的斜率
> select regr_slope(double_salary,salary) as regr_slope from employees;
REGR_SLOPE
2.00000000000000
1 row(s) retrieved.
REGR_INTERCEPT
去除含空值的数值对后,计算回归曲线的截距。返回类型为DECIMAL(32)。计算公式为:AVG(expr1) - REGR_SLOPE(expr1,expr2) * AVG(expr2)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_INTERCEPT函数计算线性函数的截距
> select regr_intercept(double_salary,salary) as regr_intercept from employees;
REGR_INTERCEPT
0.00000000000000
1 row(s) retrieved.
REGR_COUNT
返回所有非空(expr1,expr2)数值对的个数。返回类型为DECIMAL(32)。等价于COUNT过滤掉expr1为空或者expr2为空的结果。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_COUNT函数计算非空数据对的个数
> select regr_count(double_salary,salary) as regr_count from employees;
REGR_COUNT
107
1 row(s) retrieved.
REGR_R2
去除含空值的数值对后,返回确定系数。返回类型为DECIMAL(32)。计算公式为:If VAR_POP(expr2) = 0 THEN NULL。IF VAR_POP(expr1) = 0 AND VAR_POP(expr2) !=0 THEN 1。IF VAR_POP(expr1) > 0 AND VAR_POP(expr2) !=0 THEN POWER(CORR(expr1,expr2))。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:返回确定系数
> select regr_r2(double_salary,salary) as regr_r2 from employees;
REGR_R2
1.00000000000000
1 row(s) retrieved.
REGR_AVGX
去除含空值的数值对后,计算expr2的平均值。返回类型为DECIMAL(32)。计算公式为:AVG(expr2)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:计算自变量x的平均值。
> select regr_avgx(double_salary,salary) as regr_avgx from employees;
REGR_AVGX
6461.83177570093
1 row(s) retrieved.
REGR_AVGY
去除含空值的数值对后,计算expr1的平均值。返回类型为DECIMAL(32)。计算公式为:AVG(expr1)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:计算因变量y的平均值。
> select regr_avgy(double_salary,salary) as regr_avgy from employees;
REGR_AVGY
12923.6635514019
1 row(s) retrieved.
REGR_SXX
去除含空值的数值对后,计算诊断统计量SXX,通过自变量x的方差乘统计个数。返回类型为DECIMAL(32)。计算公式为:REGR_COUNT(expr1,expr2) * VAR_POP(expr2)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_SXX诊断统计值
> select regr_sxx(double_salary,salary) as regr_sxx from employees;
REGR_SXX
1620190248.97196
1 row(s) retrieved.
REGR_SYY
去除含空值的数值对后,计算诊断统计量SYY,即通过因量y的方差乘统计个数。返回类型为DECIMAL(32)。计算公式为:REGR_COUNT(expr1,expr2) * VAR_POP(expr1)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_SYY诊断统计
> select regr_syy(double_salary,salary) as regr_syy from employees;
REGR_SYY
6480760995.88785
1 row(s) retrieved.
REGR_SXY
去除含空值的数值对后,计算诊断统计量SXY,即通过x,y的总体协方差乘统计个数。返回类型为DECIMAL(32)。计算公式为:REGR_COUNT(expr1,expr2) * COVAR_POP(expr1,expr2)。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expr1 | 因变量y | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
| expr2 | 自变量x | 为数值类型或者能被隐式转化为数字类型的其他类型 | 表达式 |
例如:使用REGR_SXY诊断统计
> select regr_sxy(double_salary,salary) as regr_sxy from employees;
REGR_SXY
3240380497.94393
1 row(s) retrieved.
用户定义的函数
用户定义的函数(UDF)是一个例程,您以 SPL 或诸如 C 或 Java™ 这样的数据库的外部语言编写该例程,且该例程将值返回到它的调用上下文。
作为表达式,UDF 有下列语法:
User-Defined Functions

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| function | 函数的名称 | 函数必须存在 | 数据库对象名 |
| parameter | 在 CREATE FUNCTION 语句中声明了的参数的名称 | 对于被调用的函数中的任何参数,如果您使用 parameter = 选项,则您必须对所有参数使用它 | 标识符 |
您可在 SQL 语句内调用用户定义的函数。与内建的函数不一样,仅可由该函数的创建者和 DBA 以及已被授予了对该函数的 Execute 权限的用户可调用用户定义的函数。要获取更多信息,请参阅 例程级权限。
下列示例展示某些用户定义的函数表达式。在第一个示例罗列函数参数时,省略它的 parameter 选项:
read_address('Miller')
第二个示例使用 parameter 选项来指定参数值:
read_address(lastname = 'Miller')
当您使用 parameter 选项时,parameter 名称必须与该函数注册中对应的参数的名称相匹配。例如,前面的示例假设注册了 read_address( ) 函数如下:
CREATE FUNCTION read_address(lastname CHAR(20))
RETURNING address_t ... ;
语句本地的变量(SLV)使得应用能够将值从用户定义的函数调用传递到同一 SQL 语句的另一部分。
随同用户定义的函数调用来使用 SLV
-
为用户定义的函数写一个或多个 OUT 参数(对于以 Java 或以 SPL 语言编写的 UDR,为 INOUT 参数)。
要获取关于如何以 OUT 或 INOUT 参数编写 UDR 的信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
-
当您注册用户定义的函数时,请在每一 OUT 参数之前指定 OUT 关键字,并在每一 INOUT 参数之前指定 INOUT 关键字。
要获取更多信息,请参阅 为用户定义的例程指定 INOUT 参数 和 为用户定义例程指定 OUT 参数。
-
请在以每一 OUT 和 INOUT 参数调用用户定义的函数的函数表达式中声明 SLV。
必须在 WHERE 内进行用户定义的函数的调用。要获取关于声明 SLV 的语法的信息,请参阅 语句本地的变量声明。
-
请在 SQL 语句内使用该用户定义的函数已初始化了的 SLV。
在用户定义的函数的调用已初始化了 SLV 之后,您可在其中声明了 SLV 的同一 SQL 语句的其他部分中使用此值,包括其 WHERE 子句包括该 SLV 声明的查询的子查询。要获取关于在 SELECT 语句内使用 SLV 的信息,请参阅 语句本地的变量表达式。
除了使用 SLV 来从 OUT 或 INOUT 参数检索值之外,您还可使用本地变量或 SPL 例程的参数来从有 OUT 或 INOUT 参数的 SPL 或 C 例程检索值。
语句本地的变量声明
“语句本地的变量声明”在对定义一个或多个 OUT 或 INOUT 参数的用户定义的函数的调用中声明语句本地的变量(SLV)。
“语句本地的变量声明”有此语法:
语句本地的变量声明
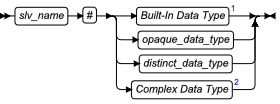
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| distinct_data_type | distinct 数据类型的名称 | distinct 数据类型必须在数据库中已经存在 | 标识符 |
| opaque_data_type | opaque 数据类型的名称 | opaque 数据类型必须在数据库中已经存在 | 标识符 |
| slv_name | 您正在定义的语句本地的变量的名称 | slv_name 仅在该语句的生命期内有效,且 在该语句内必须是唯一的 | 标识符 |
如果下列两个条件都为真,则您可在一个用户定义的函数的调用中声明 SLV:
- UDF 有一个或多个 OUT 或 INOUT 参数
- 当在查询的 WHERE 子句中调用 UDF 时,声明 SLV。
WHERE 子句中的 SLV 声明将 OUT 或 INOUT 参数的值指定到 SLV,使用 SLV 的标识符与它的声明的数据类型之间的井号(#)。可以 SPL、C 或 Java™ 语言编写 UDF。例如,如果您以下列 CREATE FUNCTION 语句注册函数,则可将它的 y 参数(其为 OUT 参数)的值指定到 WHERE 子句中的 SLV:
CREATE FUNCTION find_location(a FLOAT, b FLOAT, OUT y INTEGER)
RETURNING VARCHAR(20)
EXTERNAL NAME "/usr/lib/local/find.so"
LANGUAGE C;
在此示例中,find_location( ) 接受两个表示纬度和经度的 FLOAT 值,并返回带有额外的表示最近城市的人口等级的 INTEGER 类型的值的城市名称。
现在,您可在 WHERE 子句中调用 find_location( ):
SELECT zip_code_t FROM address
WHERE address.city = find_location(32.1, 35.7, rank # INT)
AND rank < 101;
该函数表达式将两个 FLOAT 值传递到 find_location( ) 并声明名为 rank 的 INT 类型的 SLV。在此情况下,find_location( ) 将返回距离纬度 32.1 和经度 35.7 最近的城市(可能是人口稠密的地区)的名称,其人口等级在 1 与 100 之间。然后,该语句返回对应于那个城市的邮政编码。
仅在 SELECT 语句的 WHERE 子句中的 UDR 的调用中可声明 SLV。对该 SLV 的引用的作用域包括同一 SELECT 语句的其他部分。然而,下列 SELECT 语句是无效的,因为 SLV 声明是在 Projection 子句的 projection 列表之中,而不是在 WHERE 子句中:
-- 无效的 SELECT 语句
SELECT title, contains(body, 'dog and cat', rank # INT), rank
FROM documents;
当您声明 SLV 时,您指定的数据类型必须与 CREATE FUNCTION 语句中对应的 OUT 或 INOUT 参数的数据类型相同。如果您使用不同的但相兼容的数据类型,比如 INTEGER 和 FLOAT,则数据库服务器自动地在数据类型之间执行强制转型。
SLV 与 UDR 变量以及涉及 SQL 语句的表的列名称共享该命名空间。 因此,数据库使用下列优先顺序的降序来解决下列对象之间的名称冲突:
- UDR变量
- 列名称
- SLV
在 UDF 的调用将 OUT 或 INOUT 参数的值指定到 SLV 之后,您可在同一查询的其他部分引用该 SLV。要获取更多信息,请参阅 语句本地的变量表达式。
语句本地的变量表达式
“语句本地的变量表达式”指定您可在同一 SELECT 语句中的其他地方使用的语句本地的变量(SLV)。
语句本地的变量表达式
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| SLV_variable | 在同一查询中的用户定义的函数的调用中指定的语句本地的变量(SLV) | SLV_variable 仅在查询执行期间存在。在该查询中它的名称必须是唯一的 | 标识符 |
请您在 SELECT 语句的 WHERE 子句中对用户定义的函数的调用中定义 SLV。必须以一个或多个 OUT 或 INOUT 参数来定义用户定义的函数。对用户定义的函数的调用将 OUT 或 INOUT 参数的值指定到 SLV。要获取更多信息,请参阅 语句本地的变量声明。
一旦用户定义的函数将它的 OUT 或 INOUT 参数指定到 SLV,您可在同一 SELECT 语句的其他部分中使用这些值,服从下列引用的作用域规则:
- 在定义 SLV 的查询(或子查询)中该 SLV 是只读的。
- SLV 的作用域从定义该 SLV 的查询向下扩展至所有嵌套的子查询内。
- 在嵌套的查询中,SLV 的作用域不向上扩展。
换句话说,如果查询包含一个或多个子查询,则在该查询中定义的 SLV 对于那个查询的所有子查询也是可见的。 但如果在子查询中定义 SLV,则它对于父查询是不可见的。
- 在包括 UNION 运算符的查询中,该 SLV 仅在定义它的查询中是可见的。
该 SLV 对于在 UNION 中指定的任何其他查询都不是可见的。
- 对于 INSERT、DELETE 和 UPDATE 语句,在该语句的 SELECT 部分之外,SLV 不是可见的。
在 DML 语句的此 SELECT 部分中,上述作用域规则都适用。
仅对于在单个 SQL 语句期间,语句本地的变量在作用域中。
下列 SELECT 语句调用 WHERE 子句中的 find_location( ) 函数,并定义 rank SLV。在此,find_location( ) 接受表示纬度和经度的两个值,并返回最近的城市的名称,带有表示该城市人口等级的 INTEGER 类型的额外的值。
SELECT zip_code_t FROM address
WHERE address.city = find_location(32.1, 35.7, rank # INT)
AND rank < 101;
当成功地完成 find_location() 函数的执行时,该函数已初始化了 rank SLV。然后,SELECT 在第二个 WHERE 子句条件中使用此 rank 值。在此示例中,“语句本地的变量表达式”是第二个 WHERE 子句条件中的变量 rank:
rank < 101
一个 UDF 可有的 OUT 和 INOUT 城市以及 SLV 的数目不受限制。(早于 Version 9.4 的 GBase 8s 产品将用户定义的函数限制为单个 OUT 参数且没有 INOUT 参数,因此限定 SLV 的数目不超过一个。)
如果在一个语句的迭代中未执行初始化该 SLV 的用户定义的函数,则每一 SLV 有一 NULL 值。跨语句的迭代中,不保持 SLV 的值。在每一迭代的开始时刻,数据库服务器将该 SLV 值设置为 NULL。
下列部分语句调用两个带有 OUT 参数的用户定义的函数,以 SLV 名称 out1 和 out2 引用其值:
SELECT...
WHERE func_2(x, out1 # INTEGER) < 100
AND (out1 = 12 OR out1 = 13)
AND func_3(a, out2 # FLOAT) = "SAN FRANCISCO"
AND out2 = 3.1416;
如果函数将来自本地数据库服务器的另一数据库的一个或多个 OUT 或 INOUT 参数值指定到 SLV,则这些值必须为内建的数据类型,或其基础类型为内建的数据类型(以及您显式地强制转型为内建的数据类型)的 DISTINCT 数据类型,或必须为您显式地强制转型为内建的数据类型的的 opaque UDT。在所有的参与数据库中,所有 opaque UDT、DISTINCT 类型、类型层级和强制转型的定义都必须完全相同。
要获取关于如何编写带有 OUT 或 INOUT 参数的用户定义的函数的信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。
聚集表达式
聚集表达式使用聚集函数来汇总选择的数据库数据。内建的聚集函数有下列语法:
聚集表达式
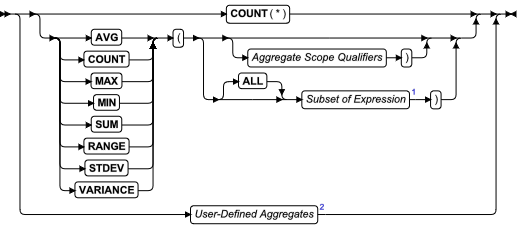
聚集作用域限定符
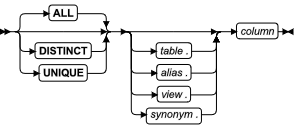
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| column | 要应用聚集函数的列 | 请参阅后面页上的单个关键字的标题 | 标识符 |
| alias、synonym、table、view | 包含 column 的同义词、表、视图或别名 | 同义词 以及它指向的表或视图必须存在 | 标识符 |
您不可在作为 WHERE 子句的一部分的条件中使用聚集表达式,除非您在子查询内使用该聚集表达式。您不可将聚集函数应用于 BYTE 或 TEXT 列。要了解其他一般的限制,请参阅 聚集表达式中有效的表达式的子集。
聚集函数为一组查询到的行返回一个值。下列示例展示 SELECT 语句中的聚集函数:
SELECT SUM(total_price) FROM items WHERE order_num = 1013;
SELECT COUNT(*) FROM orders WHERE order_num = 1001;
SELECT MAX(LENGTH(fname) + LENGTH(lname)) FROM customer;
如果您使用聚集函数以及 Projection 子句的 projection 列表中的一个或多个列,则您必须包括所有列名称,不将这些用作 GROUP BY 子句中的聚集或时间表达式的一部分。
聚集表达式的类型
SQL 语句可包括内建的聚集和用户定义的聚集。内建的聚集包括在 聚集表达式 中的语法图中展示的除了“用户定义的聚集”类别之外的所有聚集。用户定义的聚集是用户以 CREATE AGGREGATE 语句创建的任何新的聚集。
内建的聚集
内建的聚集是由数据库服务器定义的聚集函数,比如 AVG、SUM 和 COUNT。这些聚集仅与诸如 INTEGER 和 FLOAT 这样的内建的数据类型一起工作。您可将这些内建的聚集扩展到与扩展的数据类型工作。要扩展内建的聚集,您必须创建重置若干二目运算符的 UDR。
在仅重置内建的聚集的二目运算符之后,您可在 SQL 语句中随同扩展的数据类型使用那个聚集。例如,如果您已重载了 SUM 聚集的 plus 运算符来与指定的行类型工作,并将此行类型指定到 complex_tab 表的 complex 列,则您可将 SUM 聚集应用到 complex 列:
SELECT SUM(complex) FROM complex_tab;
要获取更多关于如何扩展内建的聚集的信息,请参阅 GBase 8s 用户定义的例程和数据类型开发者指南 。要获取关于如何调用内建的聚集的信息,请参阅下面页中个别内建的聚集的描述。
用户定义的聚集
用户定义的聚集是您定义的来执行数据库服务器不提供的聚集计算的聚集。例如,您可创建名为 SUMSQ 的用户定义的聚集,返回指定列的平方值的合计。用户定义的聚集可与内建的数据类型或扩展的数据类型或两者一起工作,这依赖于您如何为用户定义的聚集定义支持函数。
要创建用户定义的聚集,请使用 CREATE AGGREGATE 语句。在此语句中,您命名新的聚集并为该聚集指定支持函数。一旦您创建了新的聚集及其支持函数,则可在 SQL 语句中使用该聚集。例如,如果您创建了 SUMSQ 聚集并指定了它与 FLOAT 数据类型一起工作,则您可将 SUMSQ 聚集应用于 test 表中名为 digits 的 FLOAT 列:
SELECT SUMSQ(digits) FROM test;
要获取更多关于如何创建用户定义的聚集的信息,请参阅 CREATE AGGREGATE 语句 以及 GBase 8s 用户定义的例程和数据类型开发者指南 中对用户定义的聚集的讨论。要获取如何调用用户定义的聚集的信息,请参阅 用户定义的聚集。
聚集表达式中有效的表达式的子集
如在 聚集表达式 和 用户定义的聚集 的图中指明的那样,当您使用聚集表达式时,不是所有表达式都可用。例如,聚集函数的参数自身不可包含聚集函数。在下列上下文中,您不可使用聚集函数:
- 在 WHERE 子句中,但有这两个例外:
- 除非在 WHERE 子句内的子查询的 Projection 子句中指定该聚集,
- 或除非该查询在来自父查询的相关列上,且 WHERE 子句在 HAVING 子句内的子查询中。
- 作为聚集函数的一个参数。
下列嵌套的聚集表达式不是有效的:
MAX (AVG (order_num))
- 在任何下列数据类型的列上:
- 大对象(BLOB、BYTE、CLOB、TEXT)
- 集合数据类型(LIST、MULTISET、SET)
- ROW 数据类型(命名的或未命名的)
- OPAQUE 数据类型(除了支持 opaque 类型的用户定义的聚集函数)。
您不可使用集合数据类型的列作为下列聚集函数的参数:
- AVG
- SUM
- MIN
- MAX
内建的聚集的表达式或 column 参数(除了 COUNT、MAX、MIN 和 RANGE 之外)必须返回数值或 INTERVAL 数据类型,但 RANGE 也接受 DATE 和 DATETIME 参数。
对于 SUM 和 AVG,可以直接使用两个DATE值之间的差异作为聚集的参数。例如:
SELECT . . . AVG(ship_date - order_date);
SELECT . . . AVG((ship_date - order_date)\*1);
下列查询片段使用有效的语法来为两个列表达式声明别名:
SELECT . . .
SUM(orders.ship_charge) as o2,
COUNT(DISTINCT
CASE WHEN orders.backlog MATCHES 'n'
THEN orders.order_num END ) AS o3,
. . .
在此,SUM 的参数是 MONEY(6) 列值,且 COUNT DISTINCT 聚集采用 CASE 表达式作为它的参数。
包括或排除结果集中的重复值
您可使用 ALL、DISTINCT 或 UNIQUE 关键字来限定聚集函数的作用域。
如果您包括聚集作用域限定符,则它必须为参数列表中的第一项。
ALL 关键字指定在计算中使用从列或表达式选择的所有值,包括任何重复的值。由于 ALL 是聚集函数的缺省的作用域,因此下列两个聚集表达式是等同的,且它们的返回值基于 ship_weight 列中所有符合条件的行的值:
AVG(ship_weight)
AVG(ALL ship_weight)
包括 DISTINCT 关键字作为聚集函数的第一个参数将它的后续的参数限定到来自指定的列的唯一值。在此上下文中,UNIQUE 与 DISTINCT 关键字是同义词。下列两个聚集表达式是等同的,且他们的返回值基于 ship_weight 列的符合条件的行中唯一值的集合:
AVG(DISTINCT ship_weight)
AVG(UNIQUE ship_weight)
如果几个符合条件的行有相同的 ship_weight 值,则在计算该聚集的值中仅包括那个值的一个实例。
如果查询包括 Projection 子句中的 DISTINCT 或 UNIQUE 关键字(而不是 ALL 关键字或没有关键字),其 Select 列表还包括其参数列表以 DISTINCT 或 UNIQUE 关键字开头的聚集函数,则数据库服务器发出错误,如在下列示例中所示:
SELECT DISTINCT AVG(DISTINCT ship_weight)
FROM orders;
也就是说,在 Projection 子句和聚集函数的同一查询中,要将结果集限制到唯一的值是无效的。
然而,如果 Projection 子句为指定 SELECT 语句的 DISTINCT 或 UNIQUE 关键字,则该查询可包括一个或多个聚集函数,每一函数包括 DISTINCT 或 UNIQUE 关键字作为参数列表中的第一个规范,如在下列示例中所示:
SELECT AVG(UNIQUE ship_weight), COUNT (DISTINCT customer_num) FROM orders;
AVG 函数
AVG 函数返回指定的列或表达式中所有值的平均值。
您仅可对数值列应用 AVG 函数。下列示例中的查询找到头盔的平均价格:
SELECT AVG(unit_price) FROM stock WHERE stock_num = 110;
通过将 unit_price 值的总和除以符合条件的行的基数来计算返回值。
如果您使用 DISTINCT 或 UNIQUE 关键字作为第一个参数,则仅从指定的列或表达式中 distinct 值计算平均值(表示平均)。在下列示例中,当计算总和和基数时,仅包括任何重复的值的一个实例:
SELECT AVG(DISTINCT unit_price) FROM stock WHERE stock_num = 110;
如果该数据集不包括重复的值,则上述两个示例都返回同样的 AVG 值。
忽略 NULL 值,除非该列或表达式中的每个值都是 NULL。如果每个值都是 NULL,则 AVG 函数为那个列或表达式返回 NULL。
COUNT 函数概述
COUNT 函数实际是使得您能够根据 COUNT 关键字之后的参数,以不同的方式对列值进行计数的一组函数。
在下列小节中,说明 COUNT 函数的每一形式。要了解 COUNT 函数的不同形式的对比,请参阅 COUNT 函数的参数。
COUNT(*) 函数
COUNT (*) 函数返回满足 SELECT 语句的 WHERE 子句的行数。
下列示例找到在 stock 表中有多少行在 manu_code 列中有值 HRO:
SELECT COUNT(*) FROM stock WHERE manu_code = 'HRO';
下列示例查询“系统监视接口”(SMI)表之一来找到 customer 表中 extent 的数目:
SELECT COUNT(*) FROM sysextents WHERE dbs_name = 'stores' AND tabname = customer";
您可使用 COUNT(*) 作为此一般格式的查询中的 Projection 子句来从 SMI 表获取信息。要了解关于 sysextents 和其他 SMI 表的信息,请参阅描述 sysmaster 数据库的 GBase 8s 管理员参考手册 章节。
如果 SELECT 语句没有 WHERE 子句,则 COUNT (*) 函数返回该表中行的总数。下列示例找到在 stock 表中有多少行:
SELECT COUNT(*) FROM stock;
如果 SELECT 语句包含 GROUP BY 子句,则 COUNT (*) 函数反映在每一组中值的数目。下列示例按第一个名称分组;如果数据库服务器发现同一名称多次出现,则选择这些行:
SELECT fname, COUNT(*) FROM customer GROUP BY fname
HAVING COUNT(*) > 1;
如果一行或多行的值为 NULL,则 COUNT (*) 函数在计数中包括 NULL 列,除非 WHERE 子句显式地省略它们。
COUNT DISTINCT 和 COUNT UNIQUE 函数
COUNT DISTINCT 和 COUNT UNIQUE 函数返回唯一的值。
COUNT DISTINCT 函数返回列或表达式中唯一值的数目,如下例所示。
SELECT COUNT (DISTINCT item_num) FROM items;
如果 COUNT DISTINCT 函数遇到 NULL 值,则它忽略它们,除非指定的列中的每个值都是 NULL。如果每个列值都是 NULL,则 COUNT DISTINCT 函数返回零(0)。
UNIQUE 关键字与 COUNT 函数中的 DISTINCT 关键字有相同的含义。UNIQUE 关键字指导数据库服务器返回列或表达式中唯一的非 NULL 值的数目。下列示例调用 COUNT UNIQUE 函数,但它等同于调用 COUNT DISTINCT 函数的前一示例:
SELECT COUNT (UNIQUE item_num) FROM items;
如果 Projection 子句未指定 SELECT 语句的 DISTINCT 或 UNIQUE 关键字,则该查询可包括多个 COUNT 函数,每一函数包括 DISTINCT 或 UNIQUE 关键字作为参数列表中的第一个规范,如下例所示:
SELECT COUNT (UNIQUE item_num), COUNT (DISTINCT order_num) FROM items;
COUNT 列函数
COUNT 列函数返回列或表达式中非 NULL 值的总数目,如下例所示:
SELECT COUNT (item_num) FROM items;
为清楚起见,可将 ALL 关键字置于指定的列名称前面,但不论您包括 ALL 关键字还是省略它,查询结果都一样。
下列示例展示如何在 COUNT 列函数中包括 ALL 关键字:
SELECT COUNT (ALL item_num) FROM items;
COUNT 函数的参数
COUNT 函数接受其他内建的聚集函数的参数列表中允许的相同的表达式作为它的参数,以及仅 COUNT 支持的星号(*)表示法。支持下列内建的表达式的类别作为 COUNT 的参数,如下列示例所示:
- 算术表达式
COUNT(times(gbasedbt.sysfragments.evalpos,2))
SELECT COUNT(a+1), COUNT(2*a), COUNT(5/a), COUNT(times(a, 2)) FROM myTable;
- 位逻辑函数
COUNT(BITAND(gbasedbt.systables.flags,1))
SELECT COUNT(BITAND(a,1)), COUNT(BITOR(8, 20)), COUNT(BITXOR(41, 33)),
COUNT(BITANDNOT(20,-20)), COUNT(BITNOT(8)) FROM myTable;
- 强制转型表达式
COUNT(NULL::int)
- 条件表达式
COUNT(CASE WHEN stock.description = "baseball gloves" THEN 1 ELSE NULL END)
SELECT COUNT(CASE WHEN s=14 THEN 1 ELSE NULL END) AS cnt14 FROM all_types;
SELECT COUNT(NVL (ch, 'Addr unk')) FROM all_types;
SELECT COUNT(NULLIF(ch, NULL)) FROM all_types;
- 常量表达式
COUNT(CURRENT_ROLE)
COUNT(DATETIME (2007-12-6) YEAR TO DAY)
SELECT COUNT("XX"), COUNT(99),COUNT("t") FROM sysmaster:sysdual;
SELECT COUNT(SET{6, 9, 9, 4}) FROM sysmaster:sysdual;
SELECT COUNT("ROW(7, 3, 6.0, 2.0)") FROM sysmaster:sysdual;
SELECT COUNT(USER), COUNT(CURRENT), COUNT(SYSDATE) from sysmaster:sysdual;
SELECT COUNT(CURRENT_ROLE), COUNT(DEFAULT_ROLE) from sysmaster:sysdual;
SELECT COUNT(DBSERVERNAME), COUNT(TODAY), COUNT(CURRENT) from sysmaster:sysdual;
SELECT COUNT(DATETIME (2007-12-6) YEAR TO DAY) from sysmaster:sysdual;
SELECT COUNT(INTERVAL (16) DAY TO DAY) FROM sysmaster:sysdual;
SELECT COUNT(5 UNITS DAY) FROM sysmaster:sysdual;
- 函数表达式
COUNT(LENGTH ('abc') + LENGTH (stock.description}
COUNT(DBINFO('sessionid'))
COUNT(user_proc()) --> proc() 是用户定义例程列表达式
COUNT(gbasedbt.sysfragauth.fragment)
您还可使用星号(*)字符,或列名称,或带有 ALL、DISTINCT 或 UNIQUE 聚集作用域限定符的列名称作为 COUNT 函数的参数,来检索关于表的不同类型的信息。下面的表格总结带有星号或列名称参数的 COUNT 函数的每一下列形式的含义。
| COUNT 函数 | 描述 |
|---|---|
| COUNT (*) | 返回满足查询的行的数目。如果您未指定 WHERE 子句,此函数返回表中行的总数目。 |
| COUNT (DISTINCT) 或 COUNT (UNIQUE) | 返回指定的类中唯一的非 NULL 值的数目 |
| COUNT (column) 或 COUNT (ALL column) | 返回指定的列中非 NULL 值的总数目 |
有些示例可帮助展示引用一列的不同形式的 COUNT 函数之间的差异。大部分下列示例查询对应的是 stores_demo 演示数据库中 orders 表的 ship_instruct 列。要获取关于 orders 表的模式以及 ship_instruct 列中的数据值的信息,请参阅 《GBase 8s SQL 指南:参考》 中对演示数据库的描述。
COUNT(*) 函数的示例
在下列示例中,用户想要知道 orders 表中行的总数目。于是,用户在不带有 WHERE 子句的 SELECT 语句中调用 COUNT(*) 函数:
SELECT COUNT(*) AS total_rows FROM orders;
下列表格展示此查询的结果。
total_rows
23
在下列示例中,用户想要知道在 orders 表中有多少行在 ship_instruct 列中有 NULL 值。用户在带有 WHERE 子句的 SELECT 语句中调用 COUNT(*) 函数,并在 WHERE 子句中指定 IS NULL 条件:
SELECT COUNT (*) AS no_ship_instruct FROM orders
WHERE ship_instruct IS NULL;
下列表格展示此查询的结果。
no_ship_instruct
2
在下列示例中,用户想要知道在 orders 表中有多少行在 ship_instruct 列中有值 express。 于是,用户在 projection 列表中调用 COUNT(*) 函数,并在 WHERE 子句中指定等于(=)关系运算符。
SELECT COUNT (*) AS ship_express FROM ORDERS
WHERE ship_instruct = 'express';
下列表格展示此查询的结果。
ship_express
6
COUNT DISTINCT 函数的示例
在下一示例中,用户想要知道在 orders 表的 ship_instruct 列中有多少个唯一的非 NULL 值。用户在 SELECT 语句的 projection 列表中调用 COUNT DISTINCT 函数:
SELECT COUNT(DISTINCT ship_instruct) AS unique_notnulls
FROM orders;
下列表格展示此查询的结果。
unique_notnulls
16
COUNT column 函数的示例
在下列示例中,用户想要知道在 orders 表的 ship_instruct 列中有多少非 NULL 值。该用户在 SELECT 语句的 Projection 列表中调用 COUNT(column) 函数:
SELECT COUNT(ship_instruct) AS total_notnulls FROM orders;
下列表格展示此查询的结果。
total_notnulls
21
对于 ship_instruct 列中非 NULL 值的一个类似的查询可在跟在 COUNT 关键字之后的圆括号中包括 ALL 关键字:
SELECT COUNT(ALL ship_instruct) AS all_notnulls FROM orders;
下列表格展示该查询结果,不论您包括还是省略 ALL 关键字(因为缺省值为 ALL),查询结果都一样。
all_notnulls
21
MAX 函数
MAX 函数返回指定的列或表达式中的最大值。
使用 DISTINCT 关键字不会更改结果。在下列示例中的查询找到在库的但已被订购的最贵的项:
SELECT MAX(unit_price) FROM stock
WHERE NOT EXISTS (SELECT * FROM items
WHERE stock.stock_num = items.stock_num AND
stock.manu_code = items.manu_code);
忽略 NULL,除非该列中的每个值都是 NULL。如果每个列值都是 NULL,则 MAX 函数为那个列返回 NULL。
MIN 函数
MIN 函数返回列或表达式中的最低值。使用 DISTINCT 关键字不会更改结果。下列示例找到 stock 表中最廉价的项:
SELECT MIN(unit_price) FROM stock;
忽略 NULL 值,除非该列中的每个值都是 NULL。如果每个列值都是 NULL。则 MIN 函数为那列返回 NULL。
SUM 函数
SUM 返回指定的列或表达式中所有值的总和,如下例所示:
SELECT SUM(total_price) FROM items WHERE order_num = 1013;
如果您包括 DISTINCT 或 UNIQUE 关键字,则返回的值仅对于该列或表达式中的 distinct 值:
SELECT SUM(DISTINCT total_price) FROM items WHERE order_num = 1013;
忽略 NULL 值,除非该列中的每个值都是 NULL。如果每个列值都是 NULL,则 SUM 为那列返回 NULL。您不可使用带有非数值列的 SUM 函数。
RANGE 函数
RANGE 函数返回数值列表达式参数的值的范围。
它计算最大值与最小值之间的差异,如下所示:
range(expr) = max(expr) - min(expr);
您仅可对数值列应用 RANGE 函数。下列查询找到人口的年龄范围:
SELECT RANGE(age) FROM u_pop;
与其他聚集一样,当查询包括 GROUP BY 子句时,RANGE 函数应用于组中的行,如下列示例所示:
SELECT RANGE(age) FROM u_pop GROUP BY birth;
由于将 DATE 值在内部存储为整数,因此,您可对 DATE 列使用 RANGE 函数。对于 DATE 列,返回值是该列中最早日期与最晚日期之间的天数。
忽略 NULL 值,除非列中的每个值都是 NULL。如果每个列值都是 NULL,则 RANGE 函数为那列返回 NULL。
以 32 位数字精度执行 RANGE 函数的所有计算,对于许多输入数据集,这都应足够。然而,当所有输入数据值都有 16 位数字或更高的精度时,该计算会丢失精度或返回不正确的结果。
VARIANCE 函数
VARIANCE 函数返回总体方差的估计值,即标准差的平方。
VARIANCE 计算下列值:
(SUM(Xi2) - (SUM(Xi)2)/N)/(N - 1)
在此公式中,
- Xi 是该列中的每一值,
- N 是该列中非 NULL 值的总数目(除非所有值都是 NULL,在此情况下,逻辑上未定义方差,且 VARIANCE 函数返回 NULL)。
您仅可对数值列应用 VARIANCE 函数。
下列查询估算人口的 age 值的方差:
SELECT VARIANCE(age) FROM u_pop WHERE u_pop.age > 0;
同其他聚集一样,当查询包括 GROUP BY 子句时,对组的行应用 VARIANCE 函数,如此例所示:
SELECT VARIANCE(age) FROM u_pop GROUP BY birth
WHERE VARIANCE(age) > 0;
如前面指出的那样,VARIANCE 忽略 NULL 值,除非对于指定的列每个限定的行都是 NULL。如果每个值都是 NULL,则 VARIANCE 为那列返回 NULL 结果。(这通常表示丢失数据,且不可避免地不是潜在的总体方差的一个好的估计。)
如果限定的非 NULL 列值的总数目 N 等于 1,则 VARIANCE 函数返回零(真实总体方差的另一不可信的估算)。要忽略此特殊情况,您可修改查询。例如,您可以包括 HAVING COUNT(*) > 1 子句。
以 32 位数字精度执行 VARIANCE 函数的所有计算,对于许多输入数据集,这应足够了。然而,当所有输入数据值都有 16 位数字或更高的精度时,该计算会丢失精度或返回不正确的结果。
虽然在内部将 DATE 数据存储为整数,但您不可在 DATE 数据类型的列上使用 VARIANCE 函数。
ESQL/C 中的错误检查
聚集函数往往就返回一行。如果未选择行,则函数返回 NULL。您可使用 COUNT (*) 函数来确定是否选择了任何行,且您可使用指示符变量来确定是否某些选择了的行为空。以与聚集函数相关联的游标取回行,往往返回一行;因此,对于首次 FETCH 尝试,表示数据结束的 100 从不会返回到 sqlcode 变量内。
您还可使用 GET DIAGNOSTICS 语句进行错误检查。
聚集函数行为的总结
一个示例可帮助总结聚集函数的行为。假设 testtable 有单个名为 num 的 INTEGER 列。此表的内容如下。
| num |
|---|
| 2 |
| 2 |
| 2 |
| 3 |
| 3 |
| 4 |
| (NULL) |
您可使用聚集函数来获取关于 num 列和 testtable 表的信息。下列查询使用 AVG 函数来获取 num 列中所有非 NULL 值的平均值:
SELECT AVG(num) AS average_number FROM testtable;
下列表格展示此查询的结果。
average_number
2.66666666666667
您可使用类似于前面示例的 SELECT 语句中的其他聚集函数。 如果您输入一系列在 projection 列表中有不同的聚集函数的 SELECT 语句,且不包括 WHERE 子句,则您收到下列表格展示的结果。
| 函数 | 结果 | 函数 | 结果 |
|---|---|---|---|
| COUNT (*) | 7 | MAX | 4 |
| COUNT (DISTINCT) | 3 | MAX(DISTINCT) | 4 |
| COUNT (ALL num) | 6 | MIN | 2 |
| COUNT ( num ) | 6 | MIN(DISTINCT) | 2 |
| AVG | 2.66666666666667 | RANGE | 2 |
| AVG (DISTINCT) | 3.00000000000000 | SUM | 16 |
| STDDEV | 0.74535599249993 | SUM(DISTINCT) | 9 |
| VARIANCE | 0.55555555555556 |
用户定义的聚集
您可以 CREATE AGGREGATE 语句创建您自己的聚集表达式,然后在您可调用内建的聚集的任何地方调用这些聚集。
下图展示调用用户定义的聚集的语法。
用户定义的聚集
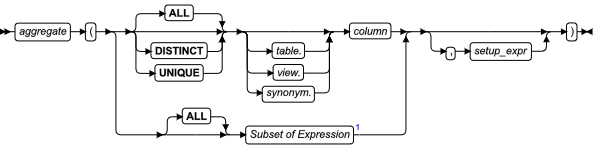
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| aggregate | 要调用的用户定义的聚集的名称 | 聚集以及为聚集定义的支持函数必须存在 | 标识符 |
| column | table 之内列的名称 | 必须存在且有数值数据类型 | 引用字符串 |
| setup_expr | 为特定的调用定制聚集的设置表达式 | 不可为孤立的主变量。在 setup_expr 中引用的任何列都必须在该查询的 GROUP BY 子句中 | 表达式 |
| synonym、table、view | column 在其中发生的同义词、表或视图 | synonym 和它指向的表或视图必须存在 | 标识符 |
使用 DISTINCT 或 UNIQUE 关键字来指定仅将用户定义的聚集应用于命名的列或表达式中唯一的值。使用 ALL 关键字来指定将该聚集应用于命名的列或表达式中所有的值。
如果您省略 DISTINCT、UNIQUE 和 ALL 关键字,则缺省值为 ALL。要获取关于 DISTINCT、UNIQUE 和 ALL 关键字的更多信息,请参阅 包括或排除结果集中的重复值。
当您指定设置表达式时,将此值传递到 INIT 支持函数,在 CREATE AGGREGATE 语句中为用户定义的聚集定义了该支持函数。
在下列示例中,您将名为 my_avg 的用户定义的聚集应用到 items 表中 quantity 列的所有值:
SELECT my_avg(quantity) FROM items
在下列示例中,您将名为 my_sum 的用户定义的聚集应用于 items 表中 quantity 列的唯一的值。您还支持值 5 作为设置表达式。此值可以指定 my_avg 将计算的总和的初始值为 5。
SELECT my_sum(DISTINCT quantity, 5) FROM items
在下列示例中,您将名为 my_max 的用户定义的聚集应用于远程 items 表中 quantity 列的所有值:
SELECT my_max(remote.quantity) FROM rdb@rserv:items remote
如果将 my_max 聚集定义为 EXECUTEANYWHERE,则可将该分布式查询推送到远程数据库服务器 rserv 来执行。如果未将 my_max 聚集定义为 EXECUTEANYWHERE,则该分布式查询扫描远程 items 表,并在本地数据库服务器上计算 my_max 聚集。
您不可以远程数据库服务器的名称来限定用户定义的聚集,如下例所示。在此情况下,数据库服务器返回错误:
SELECT rdb@rserv:my_max(remote.quantity)
FROM rdb@rserv:items remote
要获取关于用户定义的聚集的更多信息,请参阅 CREATE AGGREGATE 语句 以及 GBase 8s 用户定义的例程和数据类型开发者指南 中对用户定义的聚集的讨论。
网格查询中的聚集表达式
网格查询中的聚集表达式要求发出网格查询的数据库服务器从多网格服务器组合聚集结果。
网格查询是在数据库服务器的限定的行上返回逻辑 UNION 或 UNION ALL 的分布式 SELECT 语句,这些表在 GBase 8s 网格的数据库中有相同的模式。在 GRID 子句 主题和在 GBase 8s Enterprise Replication 指南 中描述网格查询。
网格查询中的聚集表达式要求发出该网格查询的数据库服务器组合来自多网格服务器的聚集结果。由于您指定的网格查询转换为跨多网格服务器的 UNION 或 UNION ALL 查询,因此,在指定的网格或区域内在每一参与的服务器上独立地计算每一聚集。将这些单独的聚集返回到发出该网格查询的数据库服务器,其计算它们的组合的 UNION 或 UNION ALL 值。
为了从这些单独的聚集计算全局的聚集,该网格查询必须是子查询。例如,假设我们想要查看东南地区(下列示例中的 SW_USA)的总销售额和平均销售额。因为如果在该网格内跨数据集的限定的行值的数目不同,则采用平均组的平均值是不正确的,因此正确的网格查询需要类似这样:
SELECT SUM(amt) AS total_sales ,
SUM(amt) / SUM(cnt) AS avg_sale FROM
(
SELECT COUNT(\*) cnt, SUM(amt) amt
FROM sales GRID ALL 'SW_USA'
);
total_sales avg_sale
$8300.00 $103.75
在此示例中,网格查询的 projection 列表指定来自东南地区(编码为 'SW_USA')内每一网格数据库的 sales 表的 COUNT(*) 表达式(别名为 cnt)和聚集数量 SUM(amt)(别名为 amt)。使用来自每一远程网格服务器的这些值,本地的网格服务器可计算该地区的平均值。通过把求值表达式 SUM(amt) 的总销售额加起来,并将那个值除以总计数 SUM(cnt) 来实现,此处,cnt 和 amt 是网格子查询的结果集中的列。
GRID ALL 关键字指定来自每一参与的网格服务器的限定的行的 UNION ALL,来避免消除重复的行。
OLAP window 表达式
您可在 SELECT 语句中包括“联机分析处理”(OLAP)表达式来在查询或子查询的结果集中的行的子集上操作。对于数据中的模式、趋势和例外,您可使用 OLAP window 表达式来检测满足条件的行的子集。
OLAP window 表达式允许应用开发人员更简单地和高效地构成分析业务查询。例如,可在各种不同的间隔之上计算移动平均值和移动总和。可随着选择了的列值更改,重置聚集和等级。可以简单的术语表示复杂的比率。
语法
OLAP window 表达式

在 SELECT 语句的这些子句中,OLAP window 表达式是有效的:
- Projection 子句的 Select 列表
- SELECT 语句的 ORDER BY 子句
- Projection 子句中的子查询规范
OLAP window 表达式需要 OLAP window 函数和 OVER 子句。
OLAP window 函数
OLAP window 函数为数据库服务器表示一个要在查询结果集中的行上执行的操作。OLAP window 函数分为下列函数类别:
- OLAP 编号函数将唯一的行编号指定到每一行:
- ROW_NUMBER 和 ROWNUMBER,其为同义词
- OLAP 分等级函数为每一行指定等级:
- LAG
- LEAD
- RANK
- DENSE_RANK
- PERCENT_RANK
- CUME_DIST
- NTILE
- OLAP 聚集函数聚集行数据:
- FIRST_VALUE
- LAST_VALUE
- RATIO_TO_REPORT
- AVG
- COUNT
- MAX
- MIN
- RANGE
- STDDEV
- SUM
- VARIANCE
OVER 子句
OVER 子句定义在其上执行指定的操作的结果集。OVER 子句由下列功能:
- 以 PARTITION BY 子句定义 window 分区。OLAP window 分区是查询结果集中行的子集,基于罗列在 PARTITION BY 子句中的一个或多个列表达式的值。
- 以 ORDER BY 子句将行排序。如果您包括 PARTITION BY 子句,则在每一 window 分区内对结果排序。否则,对整个结果排序。
- 以 OLAP window 聚集函数的 ROWS 或 RANGE 规范定义 window 框架。window 框架定义 window 分区内的一组行。聚集函数在移动的 window 框架的内容上操作,而不是在整个分区上操作。
例如,下列查询包含 OLAP 聚集函数 SUM:
SELECT c,d,
SUM(d) OVER(
PARTITION BY a,b
ORDER BY c,d
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM table1;
PARTITION BY 子句为每一组列 a 和 b 的值创建 window 分区。
ORDER BY 子句按照列 c 和 d 的值对每一 window 分区内的数据排序。
以 ROWS 关键字开启的 window 框架子句创建由三行组成的 window 框架:当前行、当前行的前一行,以及当前行的后一行。当前行是 window 框架的引用点。下列表格展示当每一行轮流成为当前行时,window 框架如何在结果集中移动。
表 1. 结果集中的 window 框架.
| 行编号 | 第一个框架 | 第二个框架 | 第三个框架 | 第四个框架 | 第五个框架 | 第六个框架 |
|---|---|---|---|---|---|---|
| 1 | 当前的行 | 当前的行 - 1 | ||||
| 2 | 当前的行 + 1 | 当前的行 | 当前的行 - 1 | |||
| 3 | 当前的行 + 1 | 当前的行 | 当前的行 - 1 | |||
| 4 | 当前的行 + 1 | 当前的行 | 当前的行 - 1 | |||
| 5 | 当前的行 + 1 | 当前的行 | 当前的行 - 1 | |||
| 6 | 当前的行 + 1 | 当前的行 |
SUM 函数为在该查询的作用域中的每一 window 分区加上三行的 d 列的值。
下列图示展示该查询如何对数据分区、排序和聚集。
该查询返回单个的 window 分区的 c 和 d 列的值以及列 d 的三个值的总和:
c d (sum)
1 1 3
1 2 6
1 3 7
2 2 9
2 4 7
3 1 5
sum 列中的第一个值是 d 列中第一个和第二个值的总和 (1 + 2 = 3)。对于第一个值,不存在当前行的前一个值。
sum 列中的第二个值是 d 列中第一个、第二个和第三个值的总和 (1 + 2 + 3 = 6)。
sum 列中的第三个值是 d 列中第二个、第三个和第四个值的总和 (2 + 3 + 2 = 7)。
sum 列中的最后一个值是 d 列中第五个和第六个值的总和 (1 + 4 = 5)。对于最后的值,不存在当前行的下一个值。
OLAP 编号函数表达式
OLAP 编号函数表达式为单个查询的结果集中的每一行返回一序列的编号。
OLAP 编号函数表达式是您可在 SELECT 语句的 Projection 列表中包括,或在 SELECT 语句的 ORDER BY 子句中包括的 OLAP window 表达式。
语法
OLAP OLAP window

编号函数的 OVER 子句
![]()
用法
对于同一函数,关键字 ROW_NUMBER 与 ROWNUMBER 是同义词。此编号函数就像是一个不要求 window ORDER 子句且不检查重复值的简化的 RANK 函数。ROW_NUMBER 函数往往为每一 OLAP window 分区中的每一行返回唯一的值。
ROW_NUMBER 函数不带参数,但您必须在 ROW_NUMBER(或 ROWNUMBER)关键字之后包括空的圆括号。
ROW_NUMBER 函数为每一 OLAP 分区中的每行返回一无符号整数。每一分区中的行编号的序列起始于 1,且每一后续的行增 1,不论 window 分区中连续的行是否有相同的或不同的列值。
如果未指定 window PARTITION 子句,则完整的结果集从 1 至 n 编号,此处,n 是查询或子查询返回的满足条件的行的数目。
OVER 子句为编号函数定义的 OLAP window 有此语法:
- window PARTITION 子句是可选的。如果未指定,则编号函数的作用域为查询或子查询的整个结果集,而不是分区了的子集。
- window ORDER 子句是可选的。如果未指定,则返回的行编号是基于在查询处理时这些行的缺省顺序。如果指定 window ORDER 子句,则 ORDER BY 规范决定行编号的分配。
- 对于 OLAP 编号函数,不支持 window Frame 子句。
如果为 ROW_NUMBER 函数定义 OLAP window 的 OVER 子句省略 window PARTITION 子句和 window ORDER 子句,则您必须在 OVER 关键字之后包括空的圆括号。
示例:ROW_NUMBER 函数
下列查询通过不同的包类型(pkg_type)对产品表中的行进行分区,并为每一分区指定从 1 重新开始的行编号。
SELECT ROW_NUMBER()
OVER(PARTITION BY pkg_type ORDER BY prod_name)
AS rownum, prod_name, pkg_type
FROM product;
ROWNUM PROD_NAME PKG_TYPE
1 Aroma Sounds CD Aroma designer box
2 Aroma Sounds Cassette Aroma designer box
1 Christmas Sampler Gift box
2 Coffee Sampler Gift box
3 Easter Sampler Basket Gift box
4 Spice Sampler Gift box
5 Tea Sampler Gift box
1 Aroma Roma No pkg
2 Aroma baseball cap No pkg
3 Aroma t-shirt No pkg
4 Assam Gold Blend No pkg
5 Assam Grade A No pkg
6 Breakfast Blend No pkg
7 Cafe Au Lait No pkg
8 Coffee Mug No pkg
9 Colombiano No pkg
10 Darjeeling Number 1 No pkg
11 Darjeeling Special No pkg
12 Demitasse Ms No pkg
13 Earl Grey No pkg
...
由于 window ORDER 子句指定 prod_name 列作为排序键,因此,在缺省的(ASC)顺序中,返回的行编号是基于产品名称的字母顺序。例如,在 "No pkg" 分区内,将三个 "Aroma" 产品编号为 1、2 和 3。(在缺省的 ASCII 顺序规则中大写字母排序在小写之上。)
OLAP 分等级函数表达式
您可包括 OLAP 分等级函数表达式来计算可应用于查询或子查询的分区了的结果集中每一行的顺序等级。
OLAP 分等级函数表达式是您可包括在 SELECT 语句的 Projection 列表中,或 SELECT 语句的 ORDER BY 子句中的 OLAP window 表达式。
语法
OLAP 分等级函数表达式
![]()
OLAP 分等级函数
分等级函数的 OVER 子句

用法
这些函数返回的分等级的值依赖于 OVER 子句内的 window ORDER 子句。ORDER 子句定义数据库服务器用来计算分等级的值的列或表达式。
如果您省略 window PARTITION 子句,则分等级函数的作用域是查询或子查询的整个结果集,而不是结果的分区了的子集。
LAG 和 LEAD 函数
LAG 和 LEAD 函数是 OLAP 分等级函数,在从当前 window 分区内的当前行的指定偏移量上,为该行返回它们的 expression 参数的值。
语法
LAG 和 LEAD 函数
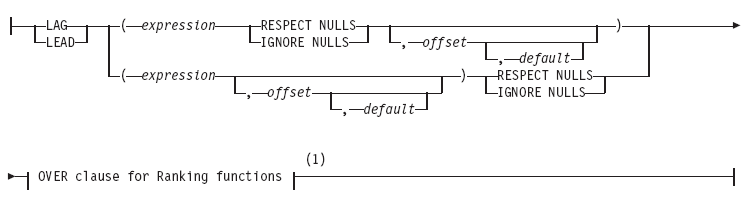
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| default | 如果 offset 超出当前的 window 分区,则返回的值 | 如果未指定 default,则对于任何作用域之外的行返回 NULL 值。 | 列表达式 |
| expression | 为从当前行的 offset 行的行返回的列名称、别名或常量表达式 | 如果 expression 引用一列,则该列必须也在 Projection 子句的选择列表中。 | 列表达式 |
| offset | 定义从当前行的该位置的偏移量的非负整数常量 | 需要 window PARTITION 子句。如果为零,则指定当前的行。如果未指定 offset,则使用值 1。 | 文字整数 |
用法
需要 expression 参数。从 LAG 或 LEAD 函数返回值的数据类型为该表达式的数据类型。
基于 window ORDER 子句对每一 window 分区执行的排序顺序,LEAD 和 LAG 函数返回在从当前行的 offset 行的每行的表达式的值:
- 对于 LAG 函数,offset 表明在当前行前面 offset 行的那一行。
- 对于 LEAD 函数,offset 表明当前行后面 offset 行的那一行。
如果 OVER 子句未包括 window PARTITION 子句,则这些函数为查询的整个结果集返回 expression 值。
如果指定 window PARTITION 子句,则 LAG 函数的第二个参数(offset)意味着当前行之前的 offset 行,且在当前分区内。对于 LEAD 函数,第二个参数意味着当前行之后的 offset 行,且在当前分区内。
对于两个函数,如果未指定 offset,则使用值 1。如果指定可选的第三个参数(default),其可为表达式,则如果 offset 超出当前分区的作用域,则返回它的值。否则,返回 NULL 值。当指定第三个参数时,也必须指定第二个参数。
处理 NULL 值
在 LAG 或 LEAD 函数表达式中,可以在两个位置之一中指定可选的 RESPECT NULLS 或 IGNORE NULLS:
- 在参数列表中
- 紧跟在定界参数列表的收圆括号之后
然而,如果您在同一 LAG 或 LEAD 表达式内在这两个位置都包括 RESPECT NULLS 或 IGNORE NULLS,则数据库服务器发出例外。
RESPECT NULLS 和 IGNORE NULLS 关键字有这些作用:
- 如果您指定 RESPECT NULLS 关键字,则当计数到 offset 行时,包括其 expression 求值为 NULL 的行。
- 如果您指定 IGNORE NULLS 关键字,则当计数到 offset 行时,不包括其 expression 求值为 NULL 的任何行。
如果您指定 IGNORE NULLS,且该 window 分区中行的所有 expression 值都是 NULL,则 LAG 或 LEAD 函数为每一行都返回 default 值。如果未指定 default 参数,则该函数返回 NULL 值。
示例:LEAD 和 LAG 函数
在下列查询中,LAG 函数和 LEAD 函数分别定义了按照部门将员工分区的 OLAP window,并罗列它们的薪资。LAG 函数展示与同一部门中享有下一更低薪资值的员工相比,每一员工收到多少更多的补偿。LEAD 函数指示与同一部门中享有下一更高薪资值的员工相比,每一员工收到的少多少。
SELECT name, salary, LAG(salary)
OVER (PARTITION BY dept ORDER BY salary),
LEAD(salary, 1, 0)
OVER (PARTITION BY dept ORDER BY salary)
FROM employee;
name salary (lag) (lead)
John 35,000 38,400
Jack 38,400 35,000 41,200
Julie 41,200 38,400 45,600
Manny 45,600 41,200 47,300
Nancy 47,300 45,600 49,500
Pat 49,500 47,300 51,300
Ray 51,300 49,500 0
对于 LAG 函数,名称为 John 的第一行有一 NULL 值,因为未指定缺省值。对于 LEAD 函数,名为 Ray 的最后一行有一 0 值,因为在该 LEAD 函数中指定 0 作为第三个参数的缺省值。
RANK 函数
RANK 函数是一个 OLAP 分等级函数,为 OLAP window 中的每一行计算分等级的值。返回值是一个顺序编号,其基于 OVER 子句中所需要的 ORDER BY 表达式。
语法
RANK 函数
![]()
用法
行的等级定义为 1 加上排在该行的等级前面的行数。如果两行或多行有相同的值,则这些行也得到相同的等级。结果在连续的分了等级的值的序列中可有间隔。例如,如果将两行分为等级 1,则下一等级为 3。对于包括非唯一的值的分等级的行,DENSE_RANK 函数使用不同的规则。
RANK 函数没有参数,但必须指定空的圆括号。如果 OVER 子句指定可选的 window PARTITION 子句,则在每一分区定义的行的子集内计算等级。
示例:RANK 函数
下列查询按照销售人员的销售量对他们分等级。这些等级不是连续的,因为销售量相同的人员都指定相同的等级值,且跳过下一等级值。
SELECT emp_num, sales,
RANK() OVER (ORDER BY sales) AS rank
FROM sales;
emp_num sales rank
101 2,000 1
102 2,400 2
103 2,400 2
104 2,500 4
105 2,500 4
106 2,650 6
DENSE_RANK 函数
DENSE_RANK 函数是一个 OLAP 分等级函数,为 OLAP window 中的每一行计算等级值。返回值是一个顺序编号,其基于在 OVER 子句中所需要的 ORDER BY 表达式。
语法
DENSE_RANK 函数

用法
将一行的等级定义为 1 加上该行的等级前面的等级数目。如果两行或多行有相同的值,则这些行得到相同的等级。然而,与 RANK 函数相反,如果两行或多行同级,则在分等级的值的序列中没有间隔。例如,如果两行都分等级为 1,则下一等级仍为 2。
此函数没有参数,但必须指定空的圆括号。如果 OVER 子句指定可选的 window PARTITION 子句,则在每一 window 分区定义的行的子集之内计算 DENSE_RANK 等级。
示例:DENSE_RANK 函数
下列查询按照销售人员的销售量对他们分等级。即使多个销售量有相同的等级,等级也是连续的。
SELECT emp_num, sales,
DENSE_RANK() OVER (ORDER BY sales) AS dense_rank,
FROM sales;
emp_num sales dense_rank
101 2,000 1
102 2,400 2
103 2,400 2
104 2,500 3
105 2,500 3
106 2,650 4
PERCENT_RANK 函数
PERCENT_RANK 函数是一个 OLAP 分等级函数,为 OLAP window 中的每一行计算等级值,规格化为从 0 至 1 的范围。
计算每一 PERCENT_RANK 值为该行的 RANK 减去 1,除以该分区内行的数目减去 1。通常,越接近于 1 的值表示等级越高,而越接近 0 的值通常表示越低的等级。
语法
PERCENT_RANK 函数
![]()
用法
此函数不用参数,但必须指定空的圆括号。如果还指定可选的 window PARTITION 子句,则在每一分区定义的行的子集之内计算等级。如果分区中有单个行,则它的 PERCENT_RANK 值为 0。
示例:PERCENT_RANK 函数
下列查询按照销售人员的销售量将他们分等级。
SELECT emp_num, sales,
PERCENT_RANK() OVER (ORDER BY sales) AS per_rank
FROM sales;
emp_num sales per_rank
101 2,000 0
102 2,400 0.2
103 2,400 0.2
104 2,500 0.6
105 2,500 0.6
106 2,650 1.0
CUME_DIST 函数
CUME_DIST 函数是一个 OLAP 分等级函数,计算累计分布作为每一行的百分比等级。该等级表示为取值范围从 0 至 1 的实际值小数。
语法
CUME_DIST 函数
![]()
用法
CUME_DIST 函数计算等级低于或等于当前的行,包括当前行的行的数目,除以该分区中行的总数。越接近 1 的值表示越高的等级,而越接近 0 的值表示越低的等级。
此函数不用参数,但必须指定空的圆括号。如果还指定可选的 window PARTITION 子句,则在每一分区定义的行的子集之内计算等级。如果在该分区中有单个行,则它的 CUME_DIST 值为 1。
示例:CUME_DIST 函数
下列查询展示每个销售人员的销售量的累计分布。
SELECT emp_num, sales,
CUME_DIST() OVER (ORDER BY sales) AS cume_dist
FROM sales;
emp_num sales cume_dist
101 2,000 0.166666667
102 2,400 0.500000000
103 2,400 0.500000000
104 2,500 0.833333333
105 2,500 0.833333333
106 2,650 1.000000000
NTILE 函数
NTILE 函数是一个 OLAP 分等级函数,将每一分区中的行划分成 N 等级的类别,称为片,每一类别包括大约相等的行数。
语法
NTILE 函数
![]()
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| unsigned | 指定要分等级为多少个类别,或片的无符号整数 | 不可为零 | 文字整数 |
用法
由该函数的无符号整数参数设置分等级的类别,或片的数量,且在 OVER 子句的 ORDER BY 表达式之上。
例如,对于查询结果集中的所有行的 dollars 列中的值,下列分等级函数表达式返回从 1 至 100 的百分比的等级:
NTILE(100) OVER(ORDER BY dollars)
当该参数为 4 时,返回的值将 OVER 子句定义的每一分区中的行排序成四个等分。当一组值不能由指定的整数参数分开时,NTILE 函数将剩余的行放置在低等级的片中。
示例:NTILE 函数
下列查询按照员工薪酬将部门中的员工分等级,并对于每一部门计算 1 至 5 的片数。
SELECT name, salary,
NTILE(5) OVER (PARTITION BY dept ORDER BY salary)
FROM employee;
name salary (ntile)
John 35,000 1
Jack 38,400 1
Julie 41,200 2
Manny 45,600 2
Nancy 47,300 3
Pat 49,500 4
Ray 51,300 5
从最低到最高对薪酬排序,因为 ORDER BY 子句的缺省的排序方向为升序。如果您在 ORDER BY 子句中包括 DESC 关键字,则从最高到最低对薪酬排序。
OLAP 聚集函数表达式
OLAP 聚集函数表达式可返回关于查询的分区了的结果中行的聚集信息。
OLAP 聚集函数表达式是 OLAP window 表达式,您可在 SELECT 语句的 Projection 列表中,或在 SELECT 语句的 ORDER BY 子句中包括它。
语法
OLAP 聚集函数表达式
![]()
OLAP 聚集函数

聚集函数的 OVER 子句

用法
您可通过指定 window 框架将 OLAP 聚集函数应用于 OLAP window 分区中行的子集。
FIRST_VALUE 函数
FIRST_VALUE window 聚集函数为每一 OLAP window 分区中的第一行返回指定的表达式的值。
语法
FIRST_VALUE 函数
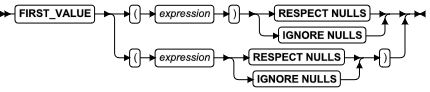
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 列名称、别名或常量表达式 | 如果 expression 引用一列,则该列必须也在该 Projection 子句的选择列表中 | 列表达式 |
用法
FIRST_VALUE 函数返回的数据类型是指定的表达式的数据类型。结果可为 NULL。如果指定 IGNORE NULLS,则在计算中不考虑行的表达式值求值为 NULL 的所有行。如果指定 IGNORE NULLS,且在该 OLAP window 中的所有值都是 NULL,则 FIRST_VALUE 函数返回 NULL 值。
或可在紧跟在表达式之后的圆括号内,或可在圆括号的外部指定 RESPECT NULLS 或 IGNORE NULLS 选项,但仅允许一个这样的规范。
示例:FIRST_VALUE 函数
下列语句返回 window 分区中按天排的存货价格,以及与第一个值 18.25 的存货价格的差异。
SELECT price, price – FIRST_VALUE(price)
OVER (PARTITION BY year ORDER BY tradingday)
AS diff_price
FROM stock_price
WHERE tradingday between '2012-11-01' and '2012'-11-07';
price diff_price
18.25 0
18.37 0.12
19.03 0.78
18.59 0.34
18.21 -0.04
LAST_VALUE 函数
LAST_VALUE window 聚集函数为每一 OLAP window 分区中的最后一行返回指定的表达式的值。
语法
LAST_VALUE 函数
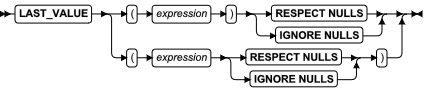
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 列名称、别名或常量表达式 | 如果 expression 应用一列,则该列必须也在该 Projection 子句的选择列表中 | 列表达式 |
用法
LAST_VALUE 函数的返回数据类型是指定的表达式的数据类型。该结果可为 NULL。如果指定 IGNORE NULLS,则在计算中不考虑行的表达式值求值为 NULL 的所有行。如果指定 IGNORE NULLS 且 OLAP window 中的所有值都是 NULL,则 LAST_VALUE 函数返回 NULL 值。
或可在紧跟在该表达式之后的圆括号之内,或可在圆括号外部设置 RESPECT NULLS 或 IGNORE NULLS 选项,但仅允许一个这样的规范。
RATIO_TO_REPORT 函数
RATIO_TO_REPORT 基于该函数的数值参数,计算每一行对于该 window 分区中剩余行的分数比率。
语法
RATIO_TO_REPORT 函数

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| expression | 列名称、别名或常量表达式 | 该 expression 必须求值为数值的数据类型。DATE、DATETIME 和 INTERVAL 列不是有效的。如果 expression 引用一列,则该列也必须在该 Projection 子句的选择列表中。 | 列表达式 |
用法
此函数计算一行中指定的数值列的值对 OLAP window 框架中每一分区中所有行的值的总和的比率。名称 RATIOTOREPORT 是 RATIO_TO_REPORT 的关键字同义词。
同所有 OLAP window 聚集函数一样,Window PARTITION、Window ORDER 和 Window Frame 子句是可选的。可将该比率应用于分区了的行,或应用于整个查询结果集。如果还指定 window Frame 子句,则该比率应用于来自当前 window 框架的所有行。
所需要的 expression 参数必须指定数值数据类型的列,或为求值为数值数据类型的常量表达式。如果 expression 不是数值数据类型,则该函数失败并报错消息 -25862。
如果当前 window 分区中所有行的 expression 值的总和为零,则此函数为那个分区中的每一行返回 NULL 值。
如果诸如 SUM 或 MAX 这样的另一 OLAP 聚集函数有一空的 OVER 子句,或如果 OVER 子句仅包含单个 window PARTITION 规范,则对于该分区中的每行,该 OLAP 函数的结果都一样。然而,对于 RATIO_TO_REPORT,不是这种情况,因为对同一 window 分区中的不同行指定不同的比率,每一分区合计(大约)为 1。要将比率转换为百分率,将该函数表达式乘以 100,如下例所示。
示例:RATIO_TO_REPORT 函数
下列示例基于该查询返回的所有行,计算每一城市的销售额的十进制小数,作为每一城市展示销售额合计的单个报告。
SELECT city, SUM(dollars) AS SALES,
RATIO_TO_REPORT(SUM(dollars)) OVER() *100 AS RATIO_DOLLARS
FROM sales, store, period
WHERE sales.store_id = store.store_id
AND sales.period_id = period.period_id
GROUP BY CITY
ORDER BY SALES DESC;
CITY SALES RATIO_DOLLARS
San Jose 896931.15 12.58
Atlanta 514830.00 7.22
Miami 507022.35 7.11
Los Angeles 503493.10 7.06
Phoenix 437863.00 6.14
New Orleans 429637.75 6.03
Cupertino 424215.00 5.95
Boston 421205.75 5.91
Houston 417261.00 5.85
New York 397102.50 5.57
Los Gatos 394086.50 5.53
Philadelphia 392377.75 5.50
Milwaukee 389378.25 5.46
Detroit 305859.75 4.29
Chicago 294982.75 4.14
Hartford 236772.75 3.32
Minneapolis 165330.75 2.32
在上述示例中,RATIO_TO_REPORT 的 expression 参数是数值的聚集函数表达式 SUM(dollars)。输出的最后一行表明 city Minneapolis 的 sales 值大约是该查询报告的合计销售额的 2.32%。
OLAP window 聚集函数
从查询的结果返回聚集结果的几个函数,诸如总和和平均值,还可用作来自 OLAP window 的上下文的 OLAP 函数。
语法
Window 聚集函数
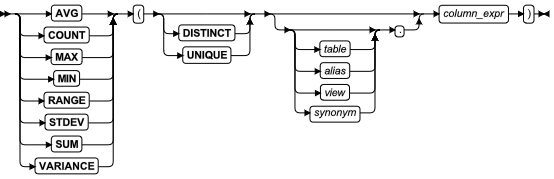
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| column_expr | 聚集函数的列表达式参数 | 请参阅下面的单独函数的标题 | 标识符 |
| alias, synonym, table, view | 包含 column 的同义词、表、视图或别名 | Synonym 以及它指向的 table 或 view 必须存在 | 标识符 |
用法
这些聚集函数不要求 OLAP window 从查询结果集计算聚集值。然而,在调用的上下文中它们的行为像 OLAP window 聚集函数一样,在此,函数表达式中的 OVER 子句定义一个或多个 window 分区,或包括 window ORDER 子句和 window Frame 子句。
当 DISTINCT 或 UNIQUE 关键字是 window 聚集函数规范的一部分时,window 聚集表达式的 OVER 子句不可包括 Window ORDER 子句或 Window Frame 子句。
下列聚集函数可返回关于 OLAP window 分区中的行的信息。
AVG 函数
对于在 OVER 子句中定义的每一分区中的行,AVG 函数返回在查询结果的 window 分区中指定的列或表达式中所有值的平均值。如果 OVER 子句包括 Window Frame 子句,则 AVG 为 window frame 中的每一组行返回一个值。
您仅可将 AVG 函数应用于数值数据类型的列。如果您使用 DISTINCT(或 UNIQUE)关键字,则仅从指定的列或表达式中 distinct 值计算平均值(含义为平均),且 OVER 子句不可包括 Window ORDER 或 Window Frame 子句。
忽略 NULL 值,除非该列或表达式中的每个值都是 NULL。如果每个值都是 NULL。则 AVG 函数为那个列或表达式返回 NULL。
您不可以非数值的列或表达式使用 AVG 函数。
COUNT 函数
对于在 OVER 子句中定义的每一分区,COUNT 函数返回查询结果的 window 分区中指定的列或表达式中非 NULL 值的基数。如果该 OVER 子句包括 Window Frame 子句,则 COUNT 为 window frame 中的每一组行返回一个值。
如果您使用 DISTINCT(或 UNIQUE)关键字,则仅从指定的列或表达式中 distinct 值计算该分区中行的基数,且 OVER 子句不可包括 Window ORDER 或 Window Frame 子句。
忽略 NULL 值,除非该列或表达式中的每个值都是 NULL。如果每个值都是 NULL,则 COUNT 函数为那个列或表达式返回 NULL。
MAX 函数
对于 OLAP window OVER 子句中定义的每一分区中的行,MAX 函数返回查询结果的 window 分区中列或表达式中的最大值。
指定 DISTINCT 或 UNIQUE 关键字,对结果没有影响,但(同其他内建的聚集函数一样)不允许 Window ORDER 或 Window Frame 子句。
如果 OVER 子句包括 Window Frame 子句,则 MAX 为 window frame 中每一组行返回一个值。
当指定列表达式作为 COUNT 的参数时,忽略 NULL 值,除非指定的列表达式中每个值都是 NULL。如果每个值都是 NULL,则 MAX 为那个列或表达式返回 NULL 值。当指定 COUNT(*) 时,如同其他值一样,对 NULL 值计数。
MIN 函数
对于 OLAP window OVER 子句定义的每一分区,MIN 函数返回查询结果的 window 分区中列或表达式中的最小值。如果 OVER 子句包括 Window Frame 子句,则 MIN 函数为每一组行返回一个值。
指定 DISTINCT 或 UNIQUE 关键字,对结果没有影响。但(同其他内建的聚集函数一样)不允许 Window ORDER 或 window Frame 子句。
如果 OVER 子句包括 Window Frame 子句,则 MIN 为 window frame 中的每一组行返回一个值。
忽略 NULL 值,除非指定列表达式中的每个值都是 NULL。如果每个值都是 NULL,则 MIN 为那个列表达式返回 NULL 值。
RANGE 函数
对于 OLAP window OVER 子句定义的每一分区,RANGE 函数返回查询结果的 window 分区中列或表达式中值的范围。如果 OVER 子句包括 Window Frame 子句,则 RANGE 为 window frame 中每一组行返回一个值。
RANGE 函数计算最大值与最小值之间的差,如下:
range(expr) = max(expr) - min(expr)
您仅可将 RANGE 函数应用于数值的列表达式。下列查询找到人口的年龄的范围:
SELECT RANGE(age) OVER () FROM u_pop;
由于 DATE 值在内部作为整数保存,因此您可对 DATE 列使用 RANGE 函数。使用 DATE 列,返回值是该列表达式中最早日期与最晚日期之间的天数。
忽略 NULL 值,除非列表达式中的每个值都是 NULL。如果每个列表达式值都是 NULL,则 RANGE 函数为那个列表达式返回 NULL。
STDDEV 函数
STDDEV 函数返回列或表达式的标准差,使用下列公式:
SQRT((SUM(Xi2) - (SUM(Xi)2)/N)/(N - 1))
在此公式中,Xi 是 OVER 子句指定的 window 分区或 frame 中每一列表达式值,N 是列表达式中非 NULL 值的总数。
如果 OVER 子句包括 Window Frame 子句,则 STDDEV 函数为 window frame 中每一组行返回一个值。
忽略 NULL 值,除非指定的列表达式中每个值都是 NULL。如果每个列表达式都是 NULL,则 STDDEV 函数为那个列表达式返回 NULL。
您仅可对数值的列表达式应用 STDDEV 函数。您不可对 DATE 类型的列表达式使用此函数。
SUM 函数
对于 OLAP window OVER 子句中定义的每一分区中的行,SUM 函数计算并返回查询结果的 window 分区中列表达式的所有值的总和。
如果您使用 DISTINCT(或 UNIQUE)关键字作为参数列表中的第一项,则该总和仅针对于列或表达式中的 distinct 值,且不允许 Window ORDER 或 Window Frame 子句。
忽略 NULL 值,除非每个值都是 NULL。如果每个值都是 NULL,则 SUM 函数为那个列或表达式返回 NULL 值。
您不可以非数值的列或表达式使用 SUM 函数。
VARIANCE 函数
对于跟在 OLAP window VARIANCE 表达式之后的 OVER 子句中定义的查询结果的分区,VARIANCE 函数计算并返回均方差作为对指定的数值列或表达式中值的总体方差的估算。
如果 OVER 子句包括 Window Frame 子句,VARIANCE 函数为每一组行返回一个值,使用下列公式:
(SUM(Xi2) - (SUM(Xi)2)/N)/(N - 1)
在此公式中,
- Xi 是 OVER 子句指定的 window 分区或 frame 中每一列值,
- N 是该列中非 NULL 值的合计数(除非所有值都是 NULL,在此情况下未逻辑地定义该方差,且 VARIANCE 函数返回 NULL)。
您仅可对数值的列应用 VARIANCE 函数。
示例:带有分区的 AVG 函数
在下列示例中,在 OLAP window 聚集表达式中使用 AVG 函数来返回两个 window 分区在 2012 年期间的移动平均数 closeprice 列值,基于 symbol 列中的 ABC 和 XYZ 值作为分区键。
SELECT symbol, tradingdate,
AVG(closeprice) OVER (PARTITION BY symbol
ORDER BY tradingdate
ROWS BETWEEN 29 PRECEDING AND CURRENT ROW)
FROM dailystockdata
WHERE symbol IN ('ABC', 'XYZ')
AND tradingdate BETWEEN '2012-01-01' AND '2012-12-31';
window ORDER 子句指定 tradingdate 列值作为排序键,且 window Frame 子句定义基于 30 个连续的 tradingdate 值的移动 window,以当前行的 tradingdate 结束。
示例:不带有分区的 AVG
下列查询返回按天排序的存货价格以及当前天、前一天和后一天的平均价格。由于该查询未包括 PARTITION BY 子句,因此结果集不分区。
SELECT price, AVG(price) OVER (ORDER BY tradingday
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM stock_price
WHERE tradingday BETWEEN '2012-11-01' AND '2012-11-07';
price (avg)
18.25 18.31
18.37 18.31
18.37
19.03
19.03 18.81
18.59 18.61
18.21 18.40
avg 列中的第一个值是 price 列中前两个值的平均值,因为对于 price 列的第一个值没有前面的值。
avg 列中的第二个值是 price 列中前两个值的平均值,因为 price 列的第三行没有值。
avg 列中的第三个值等于 price 列中的第二个值,因为 price 列中的第三行和第四行没有值。
示例:COUNT 函数
下列查询返回装运日期、装运费用和按客户排列的每一订单的订单数目。按客户编号对查询结果分区,并限定客户编号小于或等于 110。
SELECT customer_num, ship_date, ship_charge,
COUNT(*) OVER (PARTITION BY customer_num)
FROM orders
WHERE customer_num <= 110;
customer_num ship_date ship_charge (count(*))
101 05/26/2008 $15.30 1
104 05/23/2008 $10.80 4
104 07/03/2008 $5.00 4
104 06/01/2008 $10.00 4
104 07/10/2008 $12.20 4
106 05/30/2008 $19.20 2
106 07/03/2008 $12.30 2
110 07/06/2008 $13.80 2
110 07/16/2008 $6.30 2
客户 104 在列表中出现四次。客户 104 在 count 列中的值始终是 4。
OLAP window 表达式的 OVER 子句
OVER 子句定义在其上执行 OLAP window 表达式的结果集。
语法
OVER 子句

编号函数的 OVER 子句
![]()
分等级函数的 OVER 子句
![]()
聚集函数的 OVER 子句

Window PARTITION 子句

Window ORDER 子句
Window Frame 子句
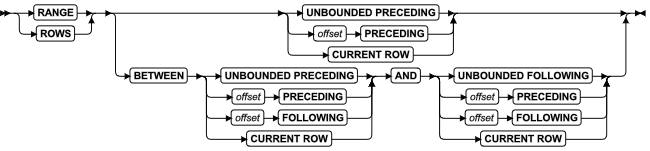
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| offset | 表示从当前行位置的偏移量的无符号整数 | 不可为负的。如果为零,则指定当前的行 | 整数 |
| partition_key | 由其对行分区的列名称、别名或常量表达式 | 必须在 Projection 子句的选择列表中 | 列表达式 |
| sorting_key | 由其对行排序的列名称、别名或常量表达式 | 与对于 partition_key 的限制相同。对于 RANGE window frame,仅允许单个排序键,且数据类型必须为数值的、DATE 或 DATETIME。 | 列表达式 |
如果 OVER 子句为空,则您必须还包括空的圆括号。
Window PARTITION 子句
OLAP window 分区是由查询返回的行的子集。通过定义该 window 的 OVER 子句的 PARTITION BY 规范中的一个或多个列表达式定义每一分区。数据库服务器将指定的 OLAP window 函数应用于每一 window 分区中的所有行。如果在 OVER 子句中未定义分区,则将 window 函数应用于该查询的结果集中的每行。
Window ORDER 子句
数据库服务器根据 window ORDER 子句中的排序键(或多个排序键)对每一 window 分区中的行排序。如果您未指定升序(ASC)或降序(DESC)顺序,则缺省值为 ASC。如果未指定 ORDER 子句,则按照检索到的行的顺序排列符合条件的行。
Window Frame 子句
window Frame 子句返回每一 window 分区中的行的子集,称为聚集组。由特定数目的行或值的范围来定义 window frame。
基于行的 window frame
ROWS 关键字创建基于行的 window frame,这由在当前行之前或之后或之前与之后的特定数量的行组成。该偏移量表示要返回的行的数目。下列示例返回包括当前行以及当前行之前六行的七行:
AVG(price) OVER (ORDER BY year, day
ROWS BETWEEN 6 PRECEDING AND CURRENT ROW)
在基于行的 window frame 子句中,偏移量表示为无符号整数,因为关键字 FOLLOWING 指定从当前行的正偏移量,而关键字 PRECEDING 指定从当前行的负偏移量。关键字 UNBOUNDED 指的是从当前行至该 window 分区的限度的所有行。作为在 window Frame 规范中 ROWS 关键字之后的第一个术语,UNBOUNDED PRECEDING 意味着起始边界为该分区中的第一行, 而 UNBOUNDED FOLLOWING 意味着终止边界为该分区中的最后一行。
基于值的 window frame
RANGE 关键字创建基于值的 frame 子句,由当前行与满足标准的行组成,通过 ORDER 子句中的排序键设置该标准并符合指定的偏移量。偏移量表示排序键的数据类型的单位数目。排序键必须为数值的、DATE 或 DATETIME 数据类型。例如,如果排序键为 DATE 数据类型,则偏移量表示特定的天数。下列示例返回发运日期在当前行的两天之内的行的数目加上当前行的总数:
COUNT(*) OVER (ORDER BY ship_date
RANGE BETWEEN 2 PRECEDING AND 2 FOLLOWING)
基于值的 window frame 定义在包含指定范围的数值值的 window 分区内的行。OVER 函数的 window ORDER 子句定义应用 RANGE 规范的数值的、DATE 或 DATETIME 列,现对于那一列的当前行值。在基于值的 window frame 的 ORDER 子句中仅允许排序键。
在基于行和基于值的这两种情况下,在此 window frame 的内容上计算 OLAP 函数,而不是在整个分区的固定的内容上计算。window frame 不需要包含当前行。例如,下列规范定义仅包含当前行之前的行的 window frame:
ROWS BETWEEN 1 PRECEDING AND 1 PRECEDING
如果您未为 window 聚集函数指定 window ORDER 子句,则在缺省情况下,不限制结果集,其等同于下列 window frame 规范:
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
如果您为 window 聚集函数指定 ORDER 子句但无 window frame 子句,则在缺省情况下,返回当前行之前的所有行以及当前行,其等同于下列 window frame 规范:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
示例:不带有 window frame 的 SUM 函数
下列查询返回按一年的季度的销售额,以及按季度的销售额的累积总和。
SELECT sales, SUM(sales) OVER (ORDER BY quarter)
FROM sales WHERE year = 2012
sales (sum)
120 120
135 255
127 382
153 535
第四季度的销售额的总和等于所有四个季度中的销售额。
由于该查询未包括 window frame 子句,因此,SUM 函数如通过 FROM 子句指定的那样,在整个结果集上操作。
示例:基于行的 window frame
下列查询按照团队分区并按照分数排序来返回运动员。在每一分区内,对该运动员以及与前面的运动员的分数求平均值:
select team, player, points,
AVG(points) OVER(PARTITION BY team ORDER BY points
ROWS 1 PRECEDING AND CURRENT ROW) AS olap_avg
FROM points;
TEAM PLAYER POINTS OLAP_AVG
A Singh 7 7.00000000000
A Smith 14 10.50000000000
B Osaka 8 8.00000000000
B Ricci 12 10.00000000000
B Baxter 18 15.00000000000
C Chun 13 13.00000000000
D Kwan 9 9.00000000000
D Tran 16 12.50000000000
示例:基于范围的 window frame
下列查询按照团队分区并按照年龄排序,返回运动员。在每一分区内,对每一运动员以及最多大 9 岁的运动员的分数求平均值:
SELECT player, age, team, points,
AVG(points) OVER(PARTITION BY team ORDER BY age
RANGE BETWEEN CURRENT ROW AND 9 FOLLOWING) AS olap_avg
FROM points_age;
PLAYER AGE TEAM POINTS OLAP_AVG
Singh 25 A 7 10.50000000000
Smith 26 A 14 14.00000000000
Baxter 27 B 18 13.00000000000
Osaka 35 B 8 10.00000000000
Ricci 40 B 12 12.00000000000
Chun 21 C 13 13.00000000000
Kwan 22 D 9 12.50000000000
Tran 31 D 16 16.00000000000
在分区 A 中,Singh 的平均值包括 Smith 的分数,因为 Smith 比 Singh 大一岁。Smith 的平均值不包括来自 Singh 的分数,因为 Singh 比 Smith 年轻。
在分区 B 中,Baxter 的平均值包括 Osaka 的分数,其比 Baxter 大 8 岁,但不包括 Ricci,其比 Baxter 大 13 岁。
在分区 D 中,Kwan 的平均值包括 Tran 的分数,因为 Tran 比 Kwan 大 9 岁。
示例:不带有当前行的 Window frame
下列查询计算分区中前面两行的分数的平均值:
SELECT player, age, team, points,
AVG(points) OVER(PARTITION BY team ORDER BY age
ROWS BETWEEN 2 PRECEDING AND 1 PRECEDING) AS olap_avg
FROM points_age;
PLAYER AGE TEAM POINTS OLAP_AVG
Singh 25 A 7 NULL
Smith 26 A 14 7.00000000000
Baxter 27 B 18 NULL
Osaka 35 B 8 18.00000000000
Ricci 40 B 12 13.00000000000
Chun 21 C 13 NULL
Kwan 22 D 9 NULL
Tran 31 D 16 9.00000000000
在分区 B 中,Ricci 的平均值是基于 Baxter 和 Osaka 的分数合计:(18 + 8 = 26)/2 = 13。当当前行没有前面的行用于计算时,结果为 NULL。
文字的集合
使用 Literal Collection 段来指定集合数据类型的值。要了解返回集合内的单个元素的值的表达式的语法,请参阅 集合构造函数。
语法
文字的集合

文字的数据

用法
您可为 SET、MULTISET 或 LIST 数据类型指定文字的集合值。
要指定单个文字的集合值,请指定集合类型和文字的值。下列的 SQL 语句将四个整数值插入到声明为 SET(INT NOT NULL) 的名为 set_col 的列内:
INSERT INTO table1 (set_col) VALUES (SET{6, 9, 9, 4});
以一对空的大括号({ })指定空的集合。此示例将空的列表插入到声明为 LIST(INT NOT NULL): 的列 list_col 内:
INSERT INTO table2 (list_col) VALUES ('LIST{}');
一对单引号( ')或双引号(")可定界集合。然而除了定界 SQL 标识符之外,在启用了定界的表达式的数据库中,双引号不是有效的。
如果您将一个文字的集合作为参数传递到 SPL 例程,则请确保在围绕着参数的圆括号与表明文字集合的开头与结尾的引号之间有空格。
元素文字的值
文字的集合 的图引用此部分。对于下列数据类型,集合的元素可为文字的值。
| 对于类型的集合 | 文字的值语法 |
|---|---|
| BOOLEAN | t 或 f,作为引号括起的字符串表示 TRUE 或 FALSE |
| CHAR、VARCHAR、NCHAR、NVARCHAR、CHARACTER VARYING、LVARCHAR、DATE | 引用字符串 |
| DATETIME | 文字的 DATETIME |
| DECIMAL、MONEY、FLOAT、INTEGER、INT8、SMALLFLOAT、SMALLINT | 精确数值 |
| INTERVAL | 文字的 INTERVAL |
| Opaque 数据类型 | 引用字符串。对于相关联的 opaque 类型,输入支持函数必须识别该字符串文字。 |
| Row 类型 | Literal Row。当集合元素类型为命名的 ROW 类型时,您不需要将插入了的值强制转型为命名的 ROW 类型。 |
您不可指定简单大对象数据类型(BYTE 和 TEXT)作为集合的元素类型。
必须以不同类型的引号指定引用字符串,而不是括起集合的引号,以便于数据库服务器可解析引用字符串。因此,如果您使用双引号(")来指定集合,则请使用单引号(')来指定单个的引用字符串元素。(然而,在启用定界的标识符的数据库中,除了用来定界 SQL 标识符之外,双引号不是有效的。)
嵌套的引号
文字的集合 的图引用此部分。
嵌套的集合是为另一集合的元素类型的集合。
无论您何时嵌套集合文字,请使用嵌套的引号。在这些情况下,您必须遵循嵌套的引号的规则。否则,数据库不可正确地解析该字符串。
通用的规则是,对于每一新的嵌套级别,您必须加倍引号的数目。例如,如果您为第一级使用双引号("),则你必须为第二级使用两个双引号,为第三级使用四个双引号,为第四级使用八个,为第五级使用十六个,依此类推。
同样地,如果您对第一级使用单引号('),则您必须为第二级使用两个单引号,为第三级使用四个单引号。对您可嵌套的级数没有限制,只要您遵循此规则即可。
下列示例说明两级嵌套的集合文字的情况,使用双引号(")。在此,表 tab5 是单列表,其唯一的列 set_col 为嵌套的集合类型。
下列语句创建 tab5 表:
CREATE TABLE tab5 (set_col SET(SET(INT NOT NULL) NOT NULL));
下列语句将值插入到表 tab5 内:
INSERT INTO tab5 VALUES ( "SET{""SET{34, 56, 23, 33}""}" );
对于每一文字值,开引号与收引号必须相匹配。因此,如果您以两个双引号开启文字,则您必须以两个双引号关闭那个文字。(""a literal value"")。
要在 GBase 8s ESQL/C 程序中的 SQL 语句内指定嵌套的引号, 对于由单引号定界的字符串之中的每个双引号,请使用 C 转义字符。否则 GBase 8s ESQL/C 预处理器 不可正确地解释文字的集合值。例如,前面的对于 tab5 表的 INSERT 语句会如下出现在 GBase 8s ESQL/C 程序中:
EXEC SQL insert into tab5 values ('set{\"set{34, 56, 23, 33}\"}');
要获取更多信息,请参阅 GBase 8s ESQL/C 程序员手册 中关于复合的数据类型的章节。
如果该集合为嵌套的集合,则您必须为每一级集合类型包括集合构造函数语法。假设您定义下列列:
nest_col SET(MULTISET (INT NOT NULL) NOT NULL);
下列语句将三个元素插入到 nest_col 列内:
INSERT INTO tabx (nest_col)
VALUES ("SET{'MULTISET{1, 2, 3}'}");
文字的 DATETIME
文字的 DATETIME 段指定 DATETIME 值
当您在语法图中看到对文字的 DATETIME 的引用时,请使用此段。
语法
文字的 DATETIME
![]()
数值的日期和时间
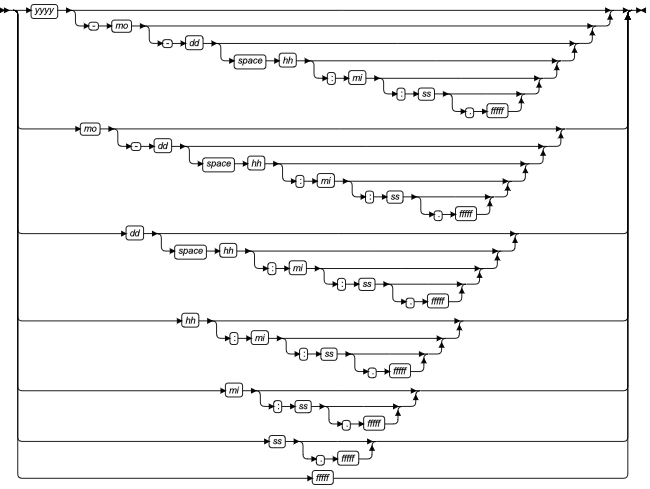
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dd | 月的日,以数字表示 | 1 ≤ dd ≤ 28、29、30 或 31 | 精确数值 |
| fffff | 秒的小数部分,以数字表示 | 0 ≤ fffff ≤ 99999 | 精确数值 |
| hh | 日的小时,以数字表示 | 0 ≤ hh ≤ 23 | 精确数值 |
| mi | 小时的分钟,以数字表示 | 0 ≤ mi ≤ 59 | 精确数值 |
| mo | 年的月,以数字表示 | 1 ≤ mo ≤ 12 | 精确数值 |
| space | 空格(ASCII 32) | 正好 1 空字符 | 文字的空格 |
| ss | 分钟的秒,以数字表示 | 0 ≤ ss ≤ 59 | 精确数值 |
| yyyy | 年,以数字表示 | 不超过 4 位数字 | 精确数值 |
用法
您必须为文字的 DATETIME 段中的此日期既指定数字的日期也指定 DATETIME 字段。DATETIME 字段限定符必须对应于您指定的数值的日期。 例如,如果您指定包括年作为最大单位且分钟作为最小单位的数值的日期,则您必须还指定 YEAR TO MINUTE 作为 DATETIME 字段限定符。
如果您为概念指定两位数字,则数据库服务器使用 DBCENTURY 环境变量的设置来将缩写的年份值扩展为四位数字。 如果未设置 DBCENTURY,则使用当前年份的前两位数值来扩展缩写的年份值。
下列示例展示文字的 DATETIME 值:
DATETIME (07-3-6) YEAR TO DAY
DATETIME (09:55:30.825) HOUR TO FRACTION
DATETIME (07-5) YEAR TO MONTH
下列示例展示随同 EXTEND 函数使用的文字的 DATETIME 值:
EXTEND (DATETIME (2007-8-1) YEAR TO DAY, YEAR TO MINUTE)
- INTERVAL (720) MINUTE (3) TO MINUTE
DATE 和 DATETIME 格式规范的优先顺序
如果不同的设置存在冲突,或如果未指定格式,则其设置可为 DATE 数据类型的值指定显示和数据项格式的 GBase 8s 环境变量有下列优先顺序:
- DBDATE
- GL_DATE
- 在客户端语言环境中定义的信息(如果设置 CLIENT_LOCALE 的话)
- 缺省的日期格式为 %m/%d/%iy(如果未定义 DBDATE 和 GL_DATE,且未指定语言环境的话)
GBase 8s 环境变量可为 DATETIME 数据类型的值指定显示和数据项格式。如果不同的设置存在冲突,或如果未指定格式,则它们的显式的或缺省的设置有下列降序的优先顺序(从最高至最低):
- DBDATE 和 DBTIME
- GL_DATETIME
- 在客户端语言环境中定义的信息(如果设置 CLIENT_LOCALE 的话)
- 缺省的 DATETIME 格式为 %iY-%m-%d %H:%M:%S(如果未设置 CLIENT_LOCALE、DBTIME 和 GL_DATETIME 的话)。
如果将 GL_DATETIME 设置为非缺省的值,则在您可在下列上下文中正确地处理本地化的 DATETIME 值之前,您还必须将 USE_DTENV 环境变量设置为 1:
- dbexport 实用程序
- dbimport 实用程序
- DB-Access 的 LOAD 语句
- DB-Access 的 UNLOAD 语句
- 由 CREATE EXTERNAL TABLE 语句定义的对象上的 DML 操作。
对于按发生时间顺序排列的数据值,要了解您可如何设置这些环境变量来定义格式的详细信息,请参阅 GBase 8s GLS 用户指南 和 《GBase 8s SQL 指南:参考》。
将数值的日期和时间字符串强制转型为 DATE 数据类型
数据库服务器提供内建的强制转型来将 DATETIME 值转换为 DATE 值,如在下列 SPL 程序片段中所示:
DEFINE my_date DATE;
DEFINE my_dt DATETIME YEAR TO SECOND;
. . .
LET my_date = CURRENT;
在此,CURRENT 返回的 DATETIME 被隐式地强制转型为 DATE。您还可显式地将 DATETIME 强制转型为 DATE:
LET my_date = CURRENT::DATE;
这两个 LET 语句将来自 DATETIME 值的 year、month 和 day 指定到 DATE 类型的本地 SPL 变量 my_date。
类似地,如同在 文字的 DATETIME 语法图中定义的那样,您可显示地将有“数值的日期和时间”段的格式的字符串强制转型为 DATETIME 数据类型,如下例所示:
LET my_dt = ('2008-02-22 05\:58\:44.000')::DATETIME YEAR TO SECOND;
然而,对于直接地将有“数值的日期和时间”格式的字符串转换为 DATE 值,既没有隐式的也没有显式的内建的强制转型。 例如,下列两个语句都失败并报错 -1218:
LET my_date = ('2008-02-22 05\:58\:44.000');
LET my_date = ('2008-02-22 05\:58\:44.000')::DATE;
要将指定有效的数值日期和时间值的字符串转换为 DATE 数据类型,您必须首先将该字符串强制转型为 DATETIME,然后再将结果 DATETIME 值强制转型为 DATE,如此例所示:
LET my_date =
('2008-02-22 05\:58\:44.000')::DATETIME YEAR TO SECOND::DATE;
仅当字符串指定有效的 DATE 值时,直接的从字符串到 DATE 的强制转型才可成功。
ORACLE模式下的时间文本表达式
DATE 时间文本表达式
将符合DATE类型格式的字符串指定为DATE类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| date_expr | 需要转换成日期格式的字符串 | 格式必须与系统环境变量GL_DATE设置的一致,如设置export GL_DATE="%Y-%m-%d",日期字符串必须是'2023-10-22' | 表达式 |
字符串中包含了年月日信息,定义从0001-01-01到9999-12-31之间的任何一个有效日期。支持DATE类型相关函数及DATE类型如下的运算规则。
| 参与运算的类型 | 运算符 | 返回类型 |
|---|---|---|
| DATE类型 | - | INTEGER类型 |
| TIMESTAMP类型 | - | INTERVAL DAY TO DAY类型 |
| INTERVAL类型 | +- | DATETIME DAY TO SECOND类型 |
| 数字类型 | +- | DATE类型 |
DATE类型与DATE类型做减法运算。
> select date '2023-10-22' - date '2023-06-22' c1 from dual;
C1
122
1 row(s) retrieved.
DATE类型与TIMESTAMP类型做减法。
> select date '2023-10-22' - timestamp '2023-06-22 11\:12\:11' c1 from dual;
C1
122
1 row(s) retrieved.
DATE类型与INTERVAL类型做加减法。
> select date '2023-10-22' + interval '1 12:12' day to minute c1 from dual;
C1 2023-10-23 12\:12\:00
1 row(s) retrieved.
> select date '2023-10-22' - interval '1 12:12' day to minute c1 from dual;
C1 2023-10-20 11\:48\:00
1 row(s) retrieved.
DATE类型与数字类型做加减,需要注意当数字是小数时会丢弃小数部分。
> select date '2023-10-22'+1.1 c1 from dual;
C1
2023-10-23
1 row(s) retrieved.
> select date '2023-10-22'-1.1 c1 from dual;
C1
2023-10-21
1 row(s) retrieved.
TIMESTAMP 时间文本表达式
将TIMESTAMP类型格式字符串指定为TIMESTAMP类型。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| timestamp_expr | 日期时间格式的字符串 | 格式必须满足yyyy-mm-dd hh24:mi:ss.ff | 字符串 |
字符串中包含了年月日时分秒信息,定义从0001-01-01 00:00:00.000000到9999-12-31 23:59:59.999999之间的任何一个有效日期时间。支持TIMESTAMP类型相关函数及TIMESTAMP类型如下的运算规则。
| 参与运算的类型 | 运算符 | 返回类型 |
|---|---|---|
| DATE类型 | - | INTERVAL DAY TO FRACTION(5)类型 |
| TIMESTAMP类型 | - | DECIMAL类型 |
| INTERVAL类型 | +- | DATETIME YEAR TO FRACTION(5)类型 |
| 数字类型 | +- | DATETIME YEAR TO FRACTION(5)类型 |
TIMESTAMP类型与DATE类型做减法。
> select timestamp '2023-10-22 12\:12\:12' - date '2023-10-22' c1 from dual;
C1
0 12:12:12.00000
1 row(s) retrieved.
TIMESTAMP类型与TIMESTAMP类型做减法。
> select timestamp '2023-10-22 12\:12\:12' - timestamp '2023-10-21 11\:11\:11 ' c1 from dual;
C1
1.04237268518519
1 row(s) retrieved.
TIMESTAMP类型与INTERVAL类型做加减。
> select timestamp '2023-10-22 12\:12\:12' - interval '3 11:11 ' day to minute c1 from dual;
C1 2023-10-19 01\:01\:12
1 row(s) retrieved.
> select timestamp '2023-10-22 12\:12\:12' + interval '3 11:11 ' day to minute c1 from dual;
C1 2023-10-25 23\:23\:12
1 row(s) retrieved.
TIMESTAMP类型与数字类型做加减。
> select timestamp '2023-10-22 12\:12\:12' + 1.1 c1 from dual;
C1 2023-10-23 14\:36\:12
1 row(s) retrieved.
> select timestamp '2023-10-22 12\:12\:12' - 1.1 c1 from dual;
C1 2023-10-21 09\:48\:12
1 row(s) retrieved.
TIMESTAMP WITH TIME ZONE文本表达式
通过时区文本表达式可以指定TIMESTAMP WITH TIME ZONE类型的数据。输出格式由环境变量NLS_TIMESTAMP_TZ_FORMAT控制。
参数说明:
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| timestamp_expr | 日期格式字符串 | 只支持yyyy-mm-ddhh24:mi:ss.ff格式 | 字符串 |
| timezone_expr | 时区格式字符串 | 只支持tzh:tzm格式 | 字符串 |
例如:使用以下格式指定TIMESTAMP WITH TIME ZONE的值。
SQL > select TIMESTAMP '1997-01-31 09\:26\:56.66 +02:00' as c1 from dual;
C1
---
1997-01-31 09\:26\:56 +02:00
文字的 INTERVAL
文字的 INTERVAL 段指定文字的 INTERVAL 值。每当您在语法图中看到对文字的 INTERVAL 引用时,请使用此段。
语法
文字的 INTERVAL
![]()
数值的时间跨度
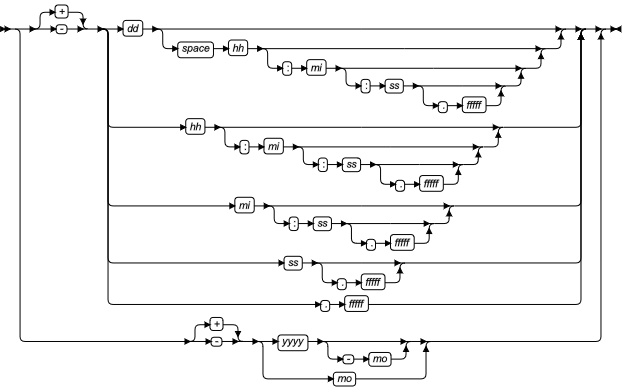
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| dd | 天数 | -10**10 < dd < 10**10 | 精确数值 |
| fffff | 秒的小数部分 | 0 ≤ fffff ≤ 9999 | 精确数值 |
| hh | 小时数 | 如果不是第一个,则 0 ≤ hh ≤ 23 | 精确数值 |
| mi | 分钟数 | 如果不是第一个,则 0 ≤ mi ≤ 59 | 精确数值 |
| mo | 月数 | 如果不是第一个,则 0 ≤ mo ≤ 11 | 精确数值 |
| space | 空格(ASCII 32) | 要求正好 1 个空字符 | 文字的空格 |
| ss | 秒数 | 如果不是第一个,则 0 ≤ ss ≤ 59 | 精确数值 |
| yyyy | 年数 | -10**10 < yyyy < 10**10 | 精确数值 |
用法
不像 DATETIME 文字那样,INTERVAL 文字可包括一元加号(+)或一元减号( -)。如果您未指定加减号,则缺省值为加号。
可由 INTERVAL 限定符指定第一个时间单位的精度。FRACTION 可有不超过 5 位数字的精度,除了 FRACTION 之外,第一个时间单位可有高达 9 位数字的精度,如果您在 INTERVAL 列或变量的声明中指定了非缺省的精度的话。
下列示例展示文字的 INTERVAL 值:
INTERVAL (3-6) YEAR TO MONTH
INTERVAL (09:55:30.825) HOUR TO FRACTION
INTERVAL (40 5) DAY TO HOUR
INTERVAL (299995.2567) SECOND(6) TO FRACTION(4)
仅最后一个示例有非缺省的精度。要了解声明 INTERVAL 数据类型的精度的语法以及每一时间单位的缺省值,请参阅 INTERVAL 字段限定符。
ORACLE模式下的INTERVAL文本表达式
NTERVAL YEAR TO MONTH
指定INTERVAL YEAR TO MONTH类型数据。

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| integer | 间隔值 | 整数。 | 精确数值 |
| precision | 精度 | 取值1到9。 | 精确数值 |
INTERVAL YEAR[(precision)] TO MONTH类型,描述一个若干年若干月的间隔。precision的取值范围是1到9,缺省值为4。年间隔的取值范围是0到999999999,月间隔的取值范围是0-11。如:
> select interval '2012-11' year to month c1 from dual;
C1
2012-11
1 row(s) retrieved.
INTERVAL YEAR[(precision)]类型,描述一个若干年的间隔。precision的取值范围是1到9。取值范围是0到999999999年。如:
> select interval '2012' year c1 from dual;
C1
2012
1 row(s) retrieved.
INTERVAL MONTH[(precision)]类型,描述一个若干月的间隔。precision的取值范围是1到9。取值范围是0到999999999月。如:
> select interval '2012' month c1 from dual;
C1
2012
1 row(s) retrieved.
说明及限制:
- 如果指定尾随字段,则该字段的重要性必须低于前置字段。例如,INTERVAL '0-1' MONTH TO YEAR是无效的。
INTERVAL DAY TO SECOND
将一个字符类型的数据指定为INTERVAL类型。有以下用法

| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| integer | 间隔值 | 整数。 | 精确数值 |
| time_expr | 时间表达式 | 格式如11:20的时间表达式。 | 时间格式串 |
| leading_precision | 精度 | 取值1到9,缺省是2。 | 精确数值 |
| fractional_seconds_precision | 秒的小数位 | 取值1到6,缺省是5。 | 精确数值 |
interval day[(leading_precision)]类型,描述一个若干日的间隔。leading_precision的取值范围是1到9,天间隔的取值范围0到999999999。如:
> select INTERVAL '400' DAY c1 from dual;
C1
400
1 row(s) retrieved.
Interval day[(leading_precision)] to hour类型,描述一个若干日若干小时的间隔,leading_precision的取值是1到9,缺省是2。日间隔的取值范围0到999999999。小时间隔的取值范围是0到23。如:
> select INTERVAL '400 5' DAY(3) TO HOUR c1 from dual;
C1
400 05
1 row(s) retrieved.
Interval day[(leading_precision)] to minute类型,描述一个若干日若干小时若干分钟的间隔。leading_precision取值1到9,缺省是2。日间隔的取值范围是0到999999999。小时间隔的取值范围是0到23。分钟间隔的取值范围是0到59。如:
> select INTERVAL '999999999 23:59' DAY(9) TO MINUTE c1 from dual;
C1
999999999 23:59
1 row(s) retrieved.
Interval day[(leading_precision)] to second[(fractional_seconds_precision)]类型,描述一个若干日若干小时若干分钟若干秒的时间间隔。leading_precision的取值是1到9,缺省是2。fractional_seconds_precision的取值是1到5缺省是5。日间隔的取值范围是0到999999999。小时间隔的取值范围是0到23。分钟间隔的取值范围是0到59。秒的取值范围是0到59.99999。如:
> select interval '4 5:12:10.222' day to second(3) c1 from dual;
C1
4 05:12:10.222
1 row(s) retrieved.
Interval hour[(leading_precision)]类型,描述一个若干小时的间隔。leading_precision的取值是1到9。小时间隔取值范围是0到999999999。如:
> select INTERVAL '10' HOUR c1 from dual;
C1
10
1 row(s) retrieved.
Interval hour[(leading_precision)] to minute类型,描述一个若干小时若干分钟的间隔leading_precision的取值是1到9。缺省是2。小时间隔取值范围是0到999999999。分钟的取值范围是0到59。如:
> select INTERVAL '11:20' HOUR TO MINUTE c1 from dual;
C1
11:20
1 row(s) retrieved.
Interval hour[(leading_precision)] to second[(fractional_seconds_precision)]类型,描述一个若干小时若干分钟若干秒的时间间隔。leading_precision的取值是1到9,缺省是2。fractional_seconds_precision的取值是1到5缺省是5。小时间隔的取值范围是0到999999999。分钟间隔的取值范围是0到59。秒的取值范围是0到59.99999。如:
> select INTERVAL '11:12:10.22' HOUR TO SECOND(2) c1 from dual;
C1
11:12:10.22
1 row(s) retrieved.
Interval minute[(leading_precision)]类型,描述一个若干分钟的间隔。leading_precision的取值范围是1到9。分钟间隔的取值范围是0到999999999。如:
> select INTERVAL '10' MINUTE c1 from dual;
C1
10
1 row(s) retrieved.
Interval minute[(leading_precision)] to second[(fractional_seconds_precision)]类型,描述一个若干分钟若干秒的间隔。leading_precision的取值是1到9,缺省是2。fractional_seconds_precision的取值是1到5缺省是5。分钟间隔的取值范围是0到999999999。秒的取值范围是0到59.99999。如:
> select INTERVAL '10:22' MINUTE TO SECOND c1 from dual;
C1
10:22.00000
1 row(s) retrieved.
Interval second[(fractional_seconds_precision)]类型,描述一个若干秒的时间间隔,fractional_seconds_precision的取值1到6,缺省是5。秒的取值范围是0到999999999.999999。如:
> select interval '1999.2134' second(4) c1 from dual;
C1
1999.21340
1 row(s) retrieved.
精确数值
精确数值是作为整数的、作为定点小数的或以指数计数法的以 10 为基数的实数表示。每当您在语法图中看到对文字数值的引用时,请使用 Literal Number 段。
语法
精确数值
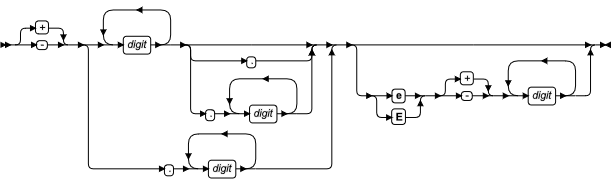
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| digit | 取值范围从 0 至 9 的整数 | 必须为 ASCII 数字 | 从键盘输入的文字。 |
用法
您可包括逗号(,)或空字符(ASCII 32)。一元加号(+)或减号(-)可出现在精确数值、假数或指数之前。
您不可在精确数值中包括非 ASCII 数字,诸如某些非缺省的语言环境支持的 Hindi 数值。
整数
整部没有小数部分且不可包括小数点。可精确地表示为文字的整数的内建的 SQL 数据类型包括 BIGINT、BIGSERIAL、DECIMAL(p, 0)、INT、INT8、SERIAL、SERIAL8 和 SMALLINT。
如果您在文字整数有效的任何上下文中,使用 10 以外的基数(诸如二进制、八进制或十六进制)来表示数目,则数据库服务器会试图将该值解释成以 10 为基本数字的文字整数。对于大多数的数据值,结果将是不正确。
下列示例展示一些有效的整数:
10 -27 +25567
在整数中,千位分隔符(比如逗号)不是有效的,在任何其他精确数值用也无效。
定点小数
定点小数正好可表示 DECIMAL(p,s) 和 MONEY 值。这些可包括小数点:
-123.456 00123456 +123456.0
在这些示例中小数点右边的数字是该数值的小数部分。
浮点小数
浮点小数正好表示 FLOAT、SMALLFLOAT 和 DECIMAL(p) 值,使用小数点或指数表示法,或两者都用。 您可以指数表示法粗略地表示实数。下一示例展示浮点数值:
-123.45E6 1.23456E2 123456.0E-3
在前面的示例中的 E 是指数表示法的符号。跟在 E 之后的数字是指数的值。例如,数值 3E5(或 3E+5)意味着 3 乘以 10 的五次方,而数值 3E-5 意味着 3 乘以 10 的五次方的倒数。
精确数值和 MONEY 数据类型
当您使用精确数值作为 MONEY 值时,请不要包括币种符号或包括逗号。DBMONEY 函数或语言环境文件可确定在输出中如何显示 MONEY 值的格式。
Literal Row
Literal Row 段指定命名的和未命名的 ROW 数据类型的文字的值的语法。
要了解在 ROW 数据类型内求值为字段值的表达式的信息,请参阅 ROW 构造函数。
语法
Literal Row
字段文字的值
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| literal_opaque_type | opaque 数据类型的文字的表示 | 对于相关联的 opaque 数据类型,必须为输入支持函数识别的文字 | 由 opaque 数据类型的开发者定义 |
| literal_BOOLEAN | BOOLEAN 值的文字的表示 | 必须指定 't' (= TRUE) 或 'f' (= FALSE) 作为引用字符串 | 引用字符串 |
用法
您可为命名的 ROW 和未命名的 ROW 数据类型指定文字的值。ROW 构造函数引入文字的 ROW 值,在引号之间可可选地包括它。
ROW 类型的每一字段的值的格式必须与相应的字段的数据类型相兼容。
您不可指定简单大对象(BYTE 或 TEXT)作为一行的字段类型。
一行的字段可为下列表格中数据类型的文字的值。
| 对于类型的字段 | 文字的值语法 |
|---|---|
| BOOLEAN | t 或 f,表示 TRUE 或 FALSE |
| CHAR、VARCHAR、LVARCHAR、NCHAR、NVARCHAR、CHARACTER VARYING、DATE | 引用字符串 |
| DATETIME | 文字的 DATETIME |
| DECIMAL、MONEY、FLOAT、INTEGER、INT8、SMALLFLOAT、SMALLINT | 精确数值 |
| INTERVAL | 文字的 INTERVAL |
| Opaque 数据类型 | 引用字符串 对于相关联的 opaque 类型,该字符串必须是由输入支持函数识别的文字。 |
| 集合类型(SET、MULTISET、LIST) | 文字的集合 要获取关于作为变量或列值的文字的集合值的信息,请参阅 嵌套的引号。要获取关于 ROW 类型的文字的集合值的信息,请参阅 嵌套的 Row 的文字。 |
| 另一 ROW 类型(命名的或未命名的) | 要获取关于 ROW 类型值的信息,请参阅 嵌套的 Row 的文字。 |
未命名的 Row 类型的文字
要为未命名的 ROW 类型指定文字的值,请以 ROW 构造函数引入文字的行;您必须将这些值括在圆括号之间。例如,假设您定义 rectangles 表如下:
CREATE TABLE rectangles
(
area FLOAT,
rect ROW(x INTEGER, y INTEGER, length FLOAT, width FLOAT),
)
下列 INSERT 语句将这些值插入到 rectangles 表的 rect 列内:
INSERT INTO rectangles (rect)
VALUES ("ROW(7, 3, 6.0, 2.0)")
命名的 Row 类型的文字
要为命名的 ROW 类型指定文字的值,请以 ROW 类型构造函数引入文字的行,并将每一字段的文字的值括在圆括号中。此外,您可将行文字强制转型为适合的命名的 ROW 类型,来确保生成行值作为命名的 ROW 类型。下列语句创建命名的 ROW 类型 address_t 以及 employee 表:
CREATE ROW TYPE address_t
(
street CHAR(20),
city CHAR(15),
state CHAR(2),
zipcode CHAR(9)
);
CREATE TABLE employee
(
name CHAR(30),
address address_t
);
下列的 INSERT 语句将值插入到 employee 表的 address 列内:
INSERT INTO employee (address)
VALUES (
"ROW('103 Baker St', 'Tracy','CA', 94060)"::address_t)
嵌套的 Row 的文字
如果是嵌套的row 的文字的值,请为每一行级别指定 ROW 类型构造函数。如果您包括引号作为定界符,则应将它们括在最外面的 row。例如,假设您创建 emp_tab 表:
CREATE TABLE emp_tab
(
emp_name CHAR(10),
emp_info ROW( stats ROW(x INT, y INT, z FLOAT))
);
下列 INSERT 语句将一行添加到 emp_tab 表:
INSERT INTO emp_tab VALUES ('joe boyd', "ROW(ROW(8,1,12.0))" );
类似地,如果 row 字符串文字包含嵌套的集合,则仅可将最外面的文字的 row 括在引号之间。请不要将引号置于嵌套的集合类型的内部。
引用字符串
引用字符串是引号之间的字符串文字。每当您在语法图中看到对引用字符串的引用时,请使用此段。
语法
引用字符串
| 元素 | 描述 | 限制 | 语法 |
|---|---|---|---|
| character | 引用字符串之内的代码集元素 | 如果设置 DELIMIDENT 环境变量,则不可括在双引号之间 | 来自键盘的文字值 |
用法
使用引用字符串来指定在数据操纵语句和其他 SQL 中的字符串文字。例如,您可在 INSERT 语句中使用引用字符串来将值插入到字符数据类型的列内。
对指定用引号括起来的字符串中字符的限制
在用引号括起来的字符串中的 character 上,您必须遵守下列限制:
- 如果您正在使用 ASCII 代码集,则您可指定任何可打印的 ASCII 字符,包括单引号(')或双引号(")。要了解应用于用引号括起来的字符串中使用引号的限制,请参阅 使用字符串中的引号。
- 在某些语言环境中,您可指定非 ASCII 字符,包括该语言环境支持的多字节字符。请参阅 GBase 8s GLS 用户指南 中关于用引号括起来的字符串的讨论。
- 如果您为用引号括起来的字符串启用换行字符,则您可在用引号括起来的字符串中嵌入换行字符。要获取更多信息,请参阅 用引号括起来的字符串中的换行字符。
- 您可输入 DATETIME 和 INTERVAL 数据值作为用引号括起来的字符串。要了解应用于在用引号括起来的字符串中输入的 DATETIME 和 INTERVAL 数据的限制,请参阅 作为字符串的 DATETIME 和 INTERVAL 值。
- 在搜索条件中随同 LIKE 或 MATCHES 关键字使用用引号括起来的字符串,可包括在该搜索条件中有特定含义的通配字符。要了解更多信息,请参阅 条件中的 LIKE 和 MATCHES。
- 当您插入一个用引号括起来的字符串值时,您必须遵守若干限制。要获取更多信息,请参阅 插入值作为用引号括起来的字符串。
DELIMIDENT 环境变量
如果在数据库服务器上设置 DELIMIDENT 环境变量,则您不可使用双引号(")来定界文字的字符串。如果设置 DELIMIDENT,则数据库服务器将括在双引号中的字符串解释为 SQL 标识符,而不是作为文字的字符串。如果未设置 DELIMIDENT,则将双引号之间的字符解释为文字的字符串,而不是标识符。要获取更多信息,请参阅 使用字符串中的引号,以及 《GBase 8s SQL 指南:参考》 中关于 DELIMIDENT 的描述。
在客户端系统上也支持 DELIMIDENT,在此,可将它设置为 y、为 n,或不设置。
- y 指定客户端应用必须使用单引号(')来定界文字的字符串,且必须仅在定界的 SQL 标识符周围使用双引号(")。与未定界的标识符相比,定界的标识符可支持更大的字符集。定界的字符串或定界的标识符之内的字母是区分大小写的。
- n 指定客户端应用可使用双引号(")或单引号(')来定界字符串,但不定界 SQL 标识符。如果数据库服务器在需要 SQL 标识符的上下文中遇到由双引号或单引号定界的字符串,则它发出错误。然而,可由单引号(')定界限定 SQL 标识符的所有者名称。您必须使用一对相同的引号符号来定界字符串。
- 在客户端系统上不带有值地指定 DELIMIDENT,要求客户端应用使用 DELIMIDENT 设置,其为它们的应用编程接口(API)的缺省值。
GBase 8s 的客户端 API 使用下列缺省的 DELIMIDENT 设置:
- 对于 OLE DB 和 .NET,缺省的 DELIMIDENT 设置为 y
- 对于 ESQL/C、JDBC 和 ODBC,缺省的 DELIMIDENT 设置为 n
- 以 ESQL/C 作为底层的 API、DataBlade API (LIBDMI) 以及 C++ API 的行为如同 ESQL/C,并使用 'n' 作为缺省值,如果在客户端系统上未指定 DELIMIDENT 的值的话。
即使设置 DELIMIDENT,您也可使用单引号(')来定界授权标识符作为数据库对象名称的所有者名称组件,如下例所示:
RENAME COLUMN 'Owner'.table2.collum3 TO column3;
然而,通用的规则是,当设置 DELIMIDENT 时,SQL 解析器将由单引号定界的字符串解释为字符串文字,将由双引号(" )定界的字符串解释为 SQL 标识符。
用引号括起来的字符串中的换行字符
在缺省情况下,必须在单行上编写字符串常量。也就是说,您不可在用引号括起来的字符串中使用嵌入的换行字符。然而,您可以两种方法之一来重写此缺省的行为:
- 要在所有会话中启用用引号括起来的字符串中的换行字符,请将 ONCONFIG 文件中的 ALLOW_NEWLINE 参数设置为 1。
- 要为当前的会话的启用用引号括起来的字符串中的换行字符,请执行内建的函数 IFX_ALLOW_NEWLINE。
这为当前的会话启用用引号括起来的字符串中的换行字符:
EXECUTE PROCEDURE IFX_ALLOW_NEWLINE('T');
如果未为会话启用用引号括起来的字符串中的换行字符,则下列语句是无效的并返回错误:
SELECT 'The quick brown fox
jumped over the old gray fence'
FROM customer
WHERE customer_num = 101;
然而,如果您为会话启用用引号括起来的字符串中的换行字符,在前面的使用中的语句是有效的并执行成功。
要获取更多关于 IFX_ALLOW_NEWLINE 函数的信息,请参阅 IFX_ALLOW_NEWLINE 函数。要获取关于 ONCONFIG 文件中 ALLOW_NEWLINE 参数的更多信息,请参阅您的 GBase 8s 管理员参考手册。
使用字符串中的引号
在由双引号定界的字符串文字中,单引号(')没有特别的意义。反过来,在由单引号定界的字符串中,双引号(")没有特别的意义。例如,这些字符串是有效的:
"Nancy's puppy jumped the fence"
'Billy told his kitten, "No!" '
由双引号定界的字符串可通过以另一个双引号在前来包括一双引号字符,如下列字符串所示:
"Enter ""y"" to select this row"
当设置 DELIMIDENT 环境变量时,双引号仅可定界 SQL 标识符,不可定界字符串。要获取关于定界的标识符的更多信息,请参阅 定界标识符。
您可以 文字的 DATETIME 和 文字的 INTERVAL 中描述的文字的形式输入 DATETIME 和 INTERVAL 数据,或者,您可输入它们作为用引号括起来的字符串。
自动地将作为字符串输入的有效的文字转换为 DATETIME 或 INTERVAL 值。
这些语句输入 INTERVAL 和 DATETIME 值作为用引号括起来的字符串:
INSERT INTO cust_calls(call_dtime) VALUES ('2007-5-4 10:12:11');
INSERT INTO manufact(lead_time) VALUES ('14');
在用引号括起来的字符串中的值的格式,必须与由该列的 INTERVAL 或 DATETIME 限定符指定的格式完全相匹配。对于前面的示例中的第一个 INSERT,必须以对于 INSERT 语句为有效的限定符 YEAR TO SECOND 来定义 call_dtime 列。
条件中的 LIKE 和 MATCHES
在条件中带有 LIKE 或 MATCHES 关键字的用引号括起来的字符串可包括通配符字符。要获取如何使用通配符字符的完整描述,请参阅 条件。
插入值作为用引号括起来的字符串
在缺省的语言环境中,如果您正在插入一个为用引号括起来的字符串的值,则您必须遵守下列限制:
- 将 CHAR、VARCHAR、NCHAR、NVARCHAR、DATE、DATETIME、INTERVAL 和 LVARCHAR 值括在引号中。
- 以 mm/dd/yyyy 格式指定 DATE 值(或以 DBDATE 或 GL_DATE 环境变量指定的格式,如果设置了的话)。
- 您不可插入长度大于 2GB 的字符串。
- 带有小数值的数值必须包括小数分隔符。在缺省的语言环境中,逗号(,)不是有效的小数分隔符。
- MONEY 值不可包括美元号($)或逗号。
- 如果一列接受空值,则您可在列中输入 NULL。
在字符列上的数值操作
请避免将数值文字与字符列比较。它要求将所有被比较的字符串转换为数值,这会花费比比较两个字符串长得多的时间。
例如,假设您想要找到 356 电话交换代码内所有的客户:
SELECT lname FROM customer WHERE phone [5,7] = '356';
请注意,将其值为 356 的运算对象括在引号中。该引号表明数据库服务器必须将该过滤器处理为字符串。相反,当该运算对象不在引号中时,服务器将每一检索的值作为数值处理,并必须隐式地将从该表检索到的每一值强制转型为数值的数据类型。
下列示例导致 phone 子字符串的隐式的数据类型转换:
SELECT lname FROM customer WHERE phone [5,7] = 356;
如果已经在此列上运行了 UPDATE STATISTICS MEDIUM 或 UPDATE STATISTICS HIGH 语句,则查询优化器试图通过将查询中的常量与保存在分布 bin 中的子字符串相匹配,来确定谓词的选择性。对字符列中每行进行数据类型转换,以便它可与数值过滤器相比较,与第一个示例中查询的成本相比,这种需要毫无必要地增加了忽略 356 周围的引号定界符的查询的成本。
如果数据库服务器不可转换该字符串,则比较字符串与数值的查询可失败并报错 EM -1213。如果您不可避免地将数值的过滤器应用于字符数值,则请仅在数值列上尝试这种操作,其字符限制为取值范围从 ASCII 0x30 至 0x39 的数字,以及小数点(ASCII 0x2e)。此取值范围又称为半数值的。
当 DML 语句将带有非字符值的字符列与在长度上不等于该字符列的非字符值相比较时,数据库服务器不使用索引。
关系运算符
关系运算符定量地比较两个表达式。每当您在语法图中看到对关系运算符的引用时,请使用 Relational Operator 段。
语法
关系运算符

用法
SQL 的关系运算符有下列含义。
关系运算符 含义
< 小于
<= 小于或等于
> 大于
= 或 == 等于
>= 大于或等于
<> 或 != 不等于
用法
对于数值表达式,大于意味着在实数轴的右边。
对于 DATE 和 DATETIME 表达式,大于意味着时间上较晚。
对于 INTERVAL 表达式,大于意味着更大的时间跨度。
对于 CHAR、VARCHAR 和 LVARCHAR 表达式,大于意味着在代码集顺序之后。
对于 NCHAR 和 NVARCHAR 表达式,大于意味着在本地化的排序顺序之后,如果存在的话;否则,大于意味着在代码集顺序之后。
如果为语言环境定义基于语言环境的排序顺序,则将其用于 NCHAR 和 NVARCHAR 表达式。因此,对于 NCHAR 和 NVARCHAR 表达式,大于意味着在基于语言环境的排序顺序之后。要获取更多关于基于语言环境的排序顺序以及 NCHAR 和 NVARCHAR 数据类型的信息,请参阅 GBase 8s GLS 用户指南。
要获取关于在有 NLCASE INSENSITIVE 属性的数据库中带有 NCHAR 和 NVARCHAR 运算对象的关系运算符表达式与区分大小写的数据库中它们的行为有何差异的信息,请参阅主题 在区分大小写的数据库中的 NCHAR 和 NVARCHAR 表达式。
使用运算符函数代替关系运算符
每一关系运算符都绑定特定的运算符函数,如表格所示。运算符函数接受两个值,并返回真、假或未知的布尔值。
关系运算符 相关联的运算符函数
< lessthan( )
<= lessthanorequal( )
> greaterthan( )
>= greaterthanorequal( )
= 或 == equal( )
<> 或 != notequal( )
以关系运算符连接两个表达式等同于对表达式调用运算符函数。例如,下两个语句都选择运费多于或等于 $18.00 的订单。
第一个语句中的 >= 运算符隐式地调用 greaterthanorequal( ) 运算符函数:
SELECT order_num FROM orders
WHERE ship_charge >= 18.00;
SELECT order_num FROM orders
WHERE greaterthanorequal(ship_charge, 18.00);
对于所有内建的数据类型,数据库服务器提供与关系运算符相关联的运算符函数。当您开发用户定义的数据类型时,您必须为那种数据类型定义运算符函数,以便用户能对该类型使用关系运算符。
如果您为用户定义的类型定义 lessthan( )、greaterthan( ) 以及其他运算符函数,则您还应定义 compare( )。类似地,如果您定义 compare( ),则您还应定义 lessthan( )、greaterthan( ) 和其他运算符函数。必须以一致的方式定义所有这些函数,以避免当在 SELECT 的 WHERE 子句中比较 UDT 值时产生不正确的查询结果的可能性。
U.S. English 数据的排序顺序
如果您正在使用缺省的语言环境(U.S. English),则当数据库服务器比较关系运算符之前与之后的字符表达式时,它使用缺省的代码集的代码集顺序。
在 UNIX™ 上,缺省的代码集是 ISO8859-1 代码集,由下列字符集组成:
- 取值范围在 0 至 127 的代码点的 ASCII 字符。
此范围包含控制字符、标点符号、英语字符和数字。
- 取值范围在 128 至 255 的代码点的 8-bit 字符。
此范围包括许多非英语字符(诸如 é、∾、Ö 和 ñ)和符号(诸如 £、© 和 ¿)。
在 Windows™ 中,缺省的代码集是 Microsoft™ 1252。此代码集既包括 ASCII 代码集,也包括一组 8-bit 字符。
此表格罗列 ASCII 代码集。编号列展示 ASCII 代码点编号,字符 列显示对应的 ASCII 字符。在缺省的语言环境中,根据他们的代码集顺序对 ASCII 字符排序。因此, 小写字母跟在大写字母之后,且都跟在数字之后。在此表格中,ASCII 32 是空字符,插入号(^)代表 CTRL 键。例如,^X 意味着 CONTROL-X。
| 编号 | 字符 | 编号 | 字符 | 编号 | 字符 | 编号 | 字符 | 编号 | 字符 | 编号 | 字符 | 编号 | 字符 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ^@ | 20 | ^T | 40 | ( | 60 | < | 80 | P | 100 | d | 120 | x |
| 1 | ^A | 21 | ^U | 41 | ) | 61 | = | 81 | Q | 101 | e | 121 | y |
| 2 | ^B | 22 | ^V | 42 | * | 62 | > | 82 | R | 102 | f | 122 | z |
| 3 | ^C | 23 | ^W | 43 | + | 63 | ? | 83 | S | 103 | g | 123 | { |
| 4 | ^D | 24 | ^X | 44 | , | 64 | @ | 84 | T | 104 | h | 124 | | |
| 5 | ^E | 25 | ^Y | 45 | - | 65 | A | 85 | U | 105 | i | 125 | } |
| 6 | ^F | 26 | ^Z | 46 | . | 66 | B | 86 | V | 106 | j | 126 | ~ |
| 7 | ^G | 27 | esc | 47 | / | 67 | C | 87 | W | 107 | k | 127 | del |
| 8 | ^H | 28 | ^\ | 48 | 0 | 68 | D | 88 | X | 108 | l | ||
| 9 | ^I | 29 | ^] | 49 | 1 | 69 | E | 89 | Y | 109 | m | ||
| 10 | ^J | 30 | ^^ | 50 | 2 | 70 | F | 90 | Z | 110 | n | ||
| 11 | ^K | 31 | ^_ | 51 | 3 | 71 | G | 91 | [ | 111 | o | ||
| 12 | ^L | 32 | 52 | 4 | 72 | H | 92 | \ | 112 | p | |||
| 13 | ^M | 33 | ! | 53 | 5 | 73 | I | 93 | ] | 113 | q | ||
| 14 | ^N | 34 | " | 54 | 6 | 74 | J | 94 | ^ | 114 | r | ||
| 15 | ^O | 35 | # | 55 | 7 | 75 | K | 95 | _ | 115 | s | ||
| 16 | ^P | 36 | $ | 56 | 8 | 76 | L | 96 | ˋ | 116 | t | ||
| 17 | ^Q | 37 | % | 57 | 9 | 77 | M | 97 | a | 117 | u | ||
| 18 | ^R | 38 | & | 58 | : | 78 | N | 98 | b | 118 | v | ||
| 19 | ^S | 39 | ' | 59 | ; | 79 | O | 99 | c | 119 | w |
对非缺省的代码集(GLS)中 ASCII 字符的支持
大多数非缺省的语言环境的代码集(称为非缺省的代码集)支持 ASCII 字符。在非缺省的语言环境中,对于 CHAR 和 VARCHAR 表达式中的 ASCII 数据,如果该代码集支持这些 ASCII 字符,则数据库服务器使用 ASCII 代码集顺序。然而,如果当前的排序顺序(如由 DB_LOCALE 或由 SET COLLATION 指定的那样)支持本地化的排序顺序,则当数据库服务器对 NCHAR 或 NVARCHAR 值排序时,使用本地化的顺序。
作为运算对象的精确数值
如果您指定作为一个运算对象的精确数值,其正好可表示由关系运算符进行比较的另一值的数据类型,则您会获得意外的结果。例如,由于舍入错误,如果一个运算对象返回 FLOAT 值,而其他返回 INTEGER,则像 = 或 equals( ) 运算符函数一样的关系运算符不可返回 TRUE。要获取关于哪些内建的数据类型存储完全表示为精确数值值的信息,请参阅 精确数值 部分。