“G”术时刻:GBase数据库Hint使用秘诀加速你的SQL查询体验
南大通用GBase数据库高性能查询的核心设计思想在于结合其分布式特性,通过索引设计、表类型适配、SQL重写及系统级配置实现性能跃升。在实际应用中需要我们根据业务场景权衡一致性、可用性与性能,并借助运维平台来实现高效管理。
这篇文章我们将代入数据库技术支持工程师的视角,向大家介绍应用Hint提升性能的工作思路。
为了更直观的展示hint的应用效果,我们先建表并插入数据。
准备工作:建表插入数据语句
---创建表CREATE TABLE emp ( empno INT PRIMARY KEY, ename VARCHAR(50), sal DECIMAL, deptno INT);CREATE TABLE dept ( deptno INT PRIMARY KEY, dname VARCHAR(50));CREATE TABLE job ( job_id INT PRIMARY KEY, job_title VARCHAR(50));---插入数据INSERT INTO dept (deptno, dname) VALUES(1, 'Sales'),(2, 'Marketing'),(3, 'HR'),(4, 'IT');INSERT INTO emp (empno, ename, sal, deptno) VALUES(1001, 'John', 50000.00, 1),(1002, 'Jane', 60000.00, 2),(1003, 'Jake', 45000.00, 3),(1004, 'Julia', 55000.00, 4),(1005, 'Jim', 48000.00, 1);INSERT INTO job (job_id, job_title)VALUES(1, 'Manager'),(2, 'Developer'),(3, 'Analyst');---创建索引CREATE INDEX idx_emp_deptno ON emp(deptno);CREATE INDEX idx_emp_sal ON emp(sal);
以下步骤开始,我们将结合具体命令和查询结果向大家示范hint如何使用,并介绍技术支持的破局思路。
1. 强制全表扫描(Seq Scan)
EXPLAIN SELECT /*+ tablescan(e) */ * FROM emp e WHERE empno = 7369

强制走全表扫描:
/*+ tablescan(表名/别名) */
/*+ no indexscan(表名/别名) */
/*+ set(enable_indexscan off) */
2. 禁止全表扫描
EXPLAIN SELECT /*+ no tablescan(e) */ * FROM emp e WHERE empno > 7369;

禁止走全表扫描
/*+ no tablescan(表名/别名) */
/*+ set(enable_seqscan off) */
3. 强制使用索引扫描(有回表)
EXPLAIN SELECT /*+ indexscan(e idx_emp_deptno) */ * FROM emp e WHERE deptno = 10;

强制走索引扫描+回表 :
/*+ indexscan(表名/别名 [索引名]) */,如果where条件列没有合适的索引,会提示unused hint
4.强制仅使用索引扫描(没有回表)
EXPLAIN SELECT /*+ indexonlyscan(e) */ ename FROM emp e WHERE deptno = 10;

大家可能看到了醒目的WARNING: unused hint: IndexOnlyScan(e)提示, 显示执行计划没有走索引,原因是索引中没有ename字段,无法只通过索引获取ename,添加符合的索引继续测试。
create index idx_emp_deptno_ename on emp(deptno,ename);

5. 强制位图索引扫描
EXPLAIN SELECT /*+ no tablescan(e) no indexscan(e) */ * FROM emp e WHERE empno IN (7369, 7499, 7521);

Bitmap Index Scan 位图索引扫描,当where条件中有 or/in(value1,value2) 或者是join条件有or 就会走位图索引扫描,如果只有一个过滤条件,没有or/in(value1,value2),走了Bitmap Index Scan,此时性能会低于Index Scan,Bitmap Index Scan会扫描完所有符合where过滤条件的数据,生成位图信息,然后再回表查询数据(Bitmap索引一般用在性别这种基数比较低的字段上,像主键这种基数很高的B树索引更好)
6. 强制使用嵌套循环连接(Nested Loop)
EXPLAIN SELECT /*+ nestloop(e d) */ * FROM emp e, dept d WHERE e.deptno = d.deptno;

强制走嵌套循环
/*+ nestloop(表名1/别名1 表名2/别名2) */
/*+ set(enable_hashjoin off) set(enable_mergejoin off) */
一般驱动表数据量少(指的是谓词过滤后),被驱动表连接字段有索引,连接后返回数据量不大时,走嵌套循环基本可以秒杀(其实nestloop就是传值,需要多次扫被驱动表,如果被驱动表没有索引,走全表扫,循环次数过多就容易产生SQL性能瓶颈,导致执行计划走错,SQL执行效率低下。
因此,实际工作中我们一般把enable_nestloop参数设置为off、enable_index_nestloop参数设置为on,并为被驱动表连接字段创建索引。
7. 强制使用哈希连接(Hash Join)
EXPLAIN SELECT /*+ hashjoin(e d) */ * FROM emp e, dept d WHERE e.deptno = d.deptno;

强制走哈希连接
/*+ hashjoin(表名1/别名1 表名2/别名2) */
/*+ set(enable_nestloop off) set(enable_index_nestloop off) set(enable_mergejoin off) */
一般连接后数据比较多,走hash join,hash join连接的表一般不走索引,而使用全表扫描。这是为什么?答案是返回较多数据时,走索引回表更慢,并且驱动表和被驱动表都只扫一次(其实hash join就是批量探测)。
8. 强制使用排序合并连接(Merge Join)
EXPLAIN SELECT /*+ mergejoin(e d) */ * FROM emp e, dept d WHERE e.deptno = d.deptno;
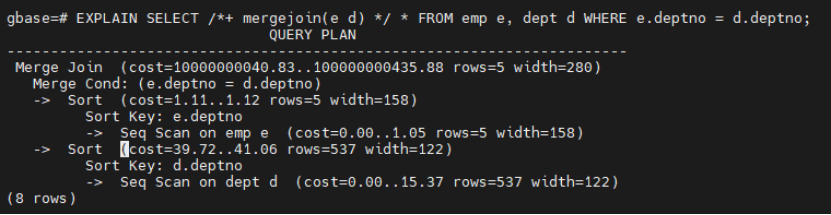
如果数据已排序且查询条件是>、=、<连接,Merge Join 会表现很好,此外SQL中没有order by要求查询结果有序,一般应用的场景不多。这里可以思考一下为什么用的少?这是因为数据较少时走nestloop秒杀,数据多则需要两张表都有序,要么走索引回表,要么全表扫排序,回表和排序数据量大都是性能杀手。(上面的数据少和多是指两张表join后返回的数据,是一个相对的概念,不用过于纠结,一般以5万作为参考)
9. 强制指定连接的驱动表
EXPLAIN SELECT /*+ nestloop(e d) leading((e d)) */ * FROM emp e, dept d WHERE e.deptno = d.deptno;

将e表作为驱动表来执行嵌套循环连接。leading((e d)) 用来指定表的连接顺序。hash join可以随意交换顺序,inner join 同理。 而left join 使用的nestloop连接则不能交换,这是为什么?
答案如下:
EXPLAIN SELECT /*+ nestloop(e d) leading((e d)) */ * FROM emp e, dept d WHERE e.deptno = d.deptno(+);
EXPLAIN SELECT /*+ nestloop(e d) leading((d e)) */ * FROM emp e, dept d WHERE e.deptno = d.deptno(+);
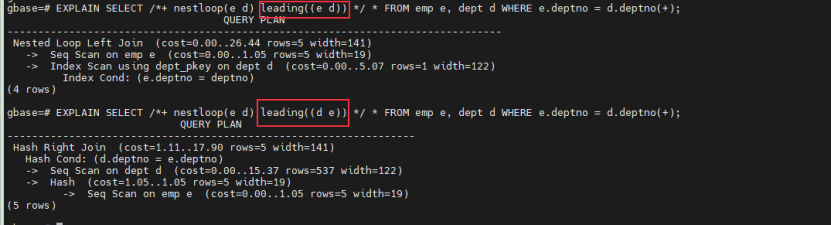
看看第二个强制让走d驱动e ,此时走了hash join。 原因就是传值,nestloop 即传值,left join 要保留左表emp的全部数据,当右表dept有null的话,用右表驱动左表会丢失数据。因为null不等于任何数据,会导致匹配不上。所以下面这SQL就能调整驱动表,推出 d.deptno is not null。
简单总结为:外连接嵌套循环优化器会把驱动表固定,left join固定左表为驱动表,right join固定右表为驱动表。
EXPLAIN SELECT /*+ nestloop(e d) leading((e d)) */ * FROM emp e, dept d WHERE e.deptno = d.deptno(+) where d.deptno>0;

10. 控制表连接顺序
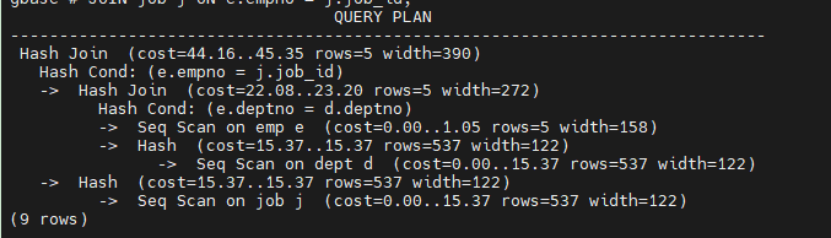
查询顺序 1:emp -> dept -> job
EXPLAIN SELECT /*+ LEADING((e d j)) */ e.empno, e.ename, e.sal, d.dname, j.job_titleFROM emp eJOIN dept d ON e.deptno = d.deptnoJOIN job j ON e.empno = j.job_id;
查询顺序 2:job -> emp -> dept
EXPLAIN SELECT /*+ LEADING((j e d)) */ e.empno, e.ename, e.sal, d.dname, j.job_titleFROM job jJOIN emp e ON j.job_id = e.empnoJOIN dept d ON e.deptno = d.deptno;
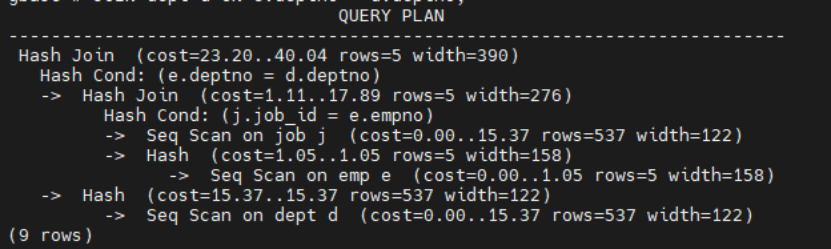
查询顺序 3:dept -> emp -> job
EXPLAIN SELECT /*+ LEADING((d e j)) */ e.empno, e.ename, e.sal, d.dname, j.job_titleFROM dept dJOIN emp e ON d.deptno = e.deptnoJOIN job j ON e.empno = j.job_id;
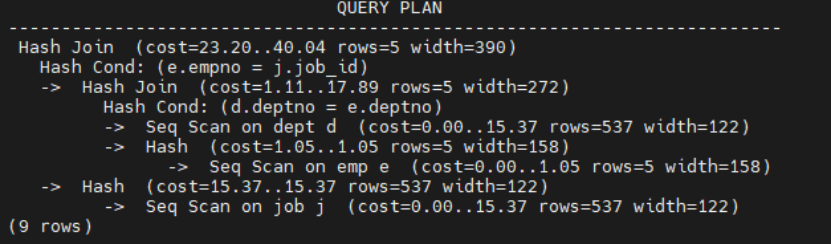
指定连接顺序是为了连接时尽量减少中间的结果集,提高查询速度。一般情况优化器会选择最优顺序,连接顺序为n!,当有10张表连接时,连接顺序就有10的阶乘是3628,800,如果加上连接方式(hashjoin、nestloop、mergejoin),穷举计算成本太大。数据库就会采用启发式策略限制搜索空间,可能导致连接顺序不是最优。所以大家写sql尽量不要join太多表,避免优化器出错。
最后总结:一般join完返回数据很少且没有数据压缩和排序,SQL执行很长,一般是连接顺序或者方式走错了。常见的数据压缩方式有分析函数row_number等,聚合函数count等、去重distinct,group by,排序只有order by。
11. 控制半连接(EXISTS)
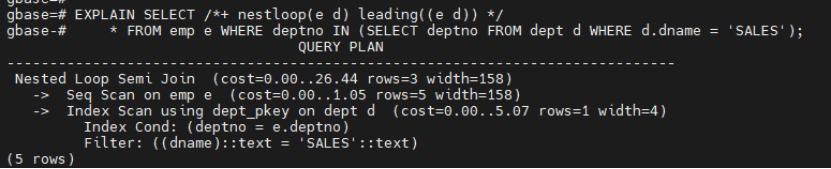
EXPLAIN SELECT /*+ nestloop(e d) leading((e d)) */ * FROM emp e WHERE deptno IN (SELECT deptno FROM dept d WHERE d.dname = 'SALES');
这里使用了嵌套循环连接来优化半连接查询, 连接后数据少,尽量让走nl,被驱动表走索引,数据多走hashjoin(就是大家俗称的大表走hashjoin,小表nestloop,这里大家可以思考下原因,不建议机械记口诀)
12. 控制 WITH AS 子查询
EXPLAIN WITH e AS (SELECT * FROM emp) SELECT /*+ nestloop(d emp) */ * FROM e, dept d WHERE e.deptno = d.deptno;

对于 WITH AS 子查询, nestloop 提示用e和dept 的连接。物化的好处可以提取公共部分,其实还能提前物化一下with这个临时表,缺点就是物化的一般只能走全表扫描,不能走原表的索引,无法将谓词推入,利用基础表的索引。
EXPLAIN WITH e AS materialized (SELECT * FROM emp where empno = 9 ) SELECT * FROM e, dept d WHERE e.deptno = d.deptno;

EXPLAIN WITH e AS not materialized (SELECT * FROM emp where empno = 9 ) SELECT * FROM e, dept d WHERE e.deptno = d.deptno;

13. 强制硬解析
EXPLAIN SELECT /*+ use_cplan */ * FROM emp WHERE empno = 7369;

这个查询强制数据库使用硬解析(hard parse)而不是软解析(soft parse),可以帮助避免缓存问题(一般绑定变量、变量窥视等特性容易导致执行计划走错,需要强制SQL硬解析)。以下为软解析:
EXPLAIN SELECT /*+ use_gplan */ * FROM emp WHERE empno = 7369;

14. 启用并行查询
EXPLAIN SELECT /*+ set(query_dop 4) */ * FROM emp;

create table emp_bak as select * from emp;
---- emp_bak多加一些数据
EXPLAIN SELECT /*+ set(query_dop 4) */ * FROM emp_bak;

这个查询将开启并行查询。query_dop 参数设置为4,表示并行度为4,一般大表全表扫无法优化的时候,加并行扫。这里需要注意并非加的越大越快,一般和cpu核数有关,一般是cpu核数的四分之一。
15. 启用向量化
EXPLAIN SELECT /*+ set(try_vector_engine_strategy force) */ * FROM emp;

这个查询强制启用向量化策略,适用于大数据对查询速度有高要求的场景。受限于测试场景,这里性能提升不明显。
16. 强制WHERE子查询走FILTER
EXPLAIN SELECT * FROM emp WHERE deptno IN (SELECT /*+ no_expand */ deptno FROM dept);

这个查询强制WHERE子查询使用FILTER,避免使用EXPAND,会扫描dept表符合要求的deptno,然后使用deptno过滤emp的数据。不加hint时,优化器提前不知道in 这个子查询会返回多少数据,担心数据量过大,会展开走hash join,实际上数据少不展开走索引扫两次比hash join要快,传统思维中消除FILTER,一般就是数据多时将in改写exist,让执行计划走hash join。
Tips:切勿看到in就改写为exists,其实in和exists如果没有产生filter,都属于半连接。用到连接的话就要分析连接方式和顺序了,其实产生filter相当于执行计划被固化成嵌套循环,类似驱动表固定为in子表的nestloop。
17. rows指定表或结果集返回多少行
EXPLAIN select /*+ rows(e #100) */ * from emp e;
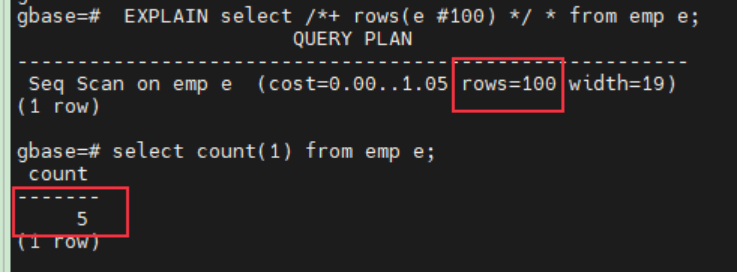
/*+ rows(e #100) */ 指定e返回100行
/*+ rows(e +100) */ 指定e在原来的预估上+100行
/*+ rows(e -100) */ 指定e在原来的预估上-100行
/*+ rows(e *100) */ 指定e在原来的预估上乘以100行
EXPLAIN select /*+ rows(e d #100) */ * from emp e left join dept d on e.deptno = d.deptno;

GBASE有话说
这篇文章的初衷是帮助大家通过使用Hint来纠正SQL执行计划,但是我们不推荐大家在优化SQL的时候,盲目干预执行计划。应该认识到,加Hint是手段,目的是优化SQL,提高数据性能。
一般建议大家拿到SQL先分析,最常见的就是select 第一段 from 第二段 where 第三段,三段式分解:一般select的性能问题集中在自定义函数、分析函数、标量子查询、序列(分布式);from 则要关注的就是大表、视图、子查询、表的连接;where就是过滤列是否走索引,一般函数、表达式,隐式转换会导致索引失效,应当关注。
我们看到的SQL无非子查询和表之间的join,所有的子查询都可以改写成表的连接,SQL的本质就是表连接去重。希望大家在具体使用中多加思考,通过场景或示例来验证自己的思路是否正确,避免机械记规律。