系统切换不心慌 GBase数据库让集群迁移变成标准流程
当数据库需要“国产化”,如何把运行多年的南大通用自主研发的云原生数据仓库GBase 8a MPP Cluster(简称:GBase 8a)集群平稳迁移到全信创环境?本文将拆解一套经过验证的改造方案:从“双轨并行”到“灰度切换”,从GVR准实时同步到一键回滚,详细分析怎样在业务无感知的前提下,完成这场数据库的“心脏移植手术”。

为什么要给数据库“动手术”?
想象一下:家里的核心供电系统,核心芯片、操作系统、数据库全是国外品牌。突然有一天,厂家说“不提供升级了”,或者爆出一个高危漏洞。这些问题一旦发生就会带来很多大麻烦。
这就是很多企业面临的现实。国家推动信创(信息技术应用创新),就是要从芯片到服务器、从操作系统到数据库,全部换成自主可控的国产产品。而GBase 8a集群作为很多企业的数据仓库“心脏”,自然也要跟上。
但问题来了:换心脏,意味着不能出任何差错。业务不能中断,数据一条都不能丢,性能还不能下降,这该怎么解决?
GBase 8a已形成一套成熟的技术组合拳。
改造前的“体检报告”:先搞清楚现状
动手之前,得先知道现在的集群长什么样。
硬件:是否是国外品牌的服务器?CPU是Intel还是AMD?存储、交换机有没有依赖国外的?
软件:GBase 8a是哪个版本?操作系统是RedHat还是CentOS?同步工具、监控工具是不是也得换?
业务:高峰期并发多少?跑批任务多久一次?能容忍多长的停机时间?(很多核心业务要求RPO≈0、RTO≤30秒,也就是几乎不丢数据、半分钟内恢复)
做完这份“体检”,才能知道差距在哪里:哪些硬件要换、哪些软件要升级、哪些应用代码要适配。
核心打法:双轨运行 + 灰度切换
这次改造最核心的思路是不搞“一次性切换”,而是采用两步走。
双轨运行
老集群继续干读写活,新集群在旁边同步数据、处于只读状态。两边一起跑,互相验证。
灰度切换
先切一小部分流量(比如报表查询),观察几天没问题,再切更多,直到全部切完。万一出问题,还能秒级切回去。
这套打法能成立,关键靠GBase 8a的一个“利器”——GVR同步工具。它支持表级增量块同步,实现准实时数据同步(同城RPO≈0,延迟秒到分钟级),还具备断点续传、事务一致性检测、冲突检测等功能。正是因为它能保证新旧集群数据高度一致,灰度切换才有了安全底气。
改造四步走:每一步都踩稳
准备与调研:别急着动手,先看路
组建专项小组:架构师、DBA、运维、应用开发、安全,一个不能少。
全面调研现有集群、软硬件、业务,输出《现有环境调研报告》。
采购信创软硬件,搭建测试环境与生产环境。
开展专项培训,掌握GBase 8a信创版本特性及GVR工具使用。
小贴士:如果采用多VC部署,第一个VC的平台必须与gcware、gcluster兼容;其他VC可以独立安装后导入主集群。同一VC内保持同平台同配置,不同VC可以混搭不同平台。
部署与迁移:数据搬家的正确姿势
集群部署:在信创生产环境部署GBase 8a MPP Cluster V9.5.3+,配置管理节点、数据节点、调度节点,调优内存、IO、分片策略。全量迁移:使用GBase数据库迁移工具,业务不停机,优先采用数据文件拷贝方式导出存量数据并导入新集群。
数据校验:通过行数比对、sum/max/min指标比对、关键业务数据对账,确保数据完整准确。
增量同步:配置GVR单向同步任务,实现旧集群到新集群的准实时数据同步。
应用适配:替换数据库驱动,调整不兼容的SQL及存储过程,完成功能测试与接口测试。
完成后,双轨运行正式启动:老集群继续主写主查,新集群处于只读模式,用于业务验证与数据对账。可以配置应用层双发机制,自动比对新旧集群返回结果。
切换与优化:流量慢慢切,油门轻轻踩
双轨验证:运行不少于一个完整业务周期,验证功能、性能、数据一致性、安全性,确保新集群达标。
灰度切换:
第一波:切换20%-30%的非核心流量(如报表查询),运行1-2天无异常。
第二波:切换50%-60%的核心流量,紧盯监控。
第三波:全量切换,新集群转为主写主查,老集群停止写入,转为只读备用。
回滚机制:若新集群出现重大故障,通过负载均衡或VIP漂移,在30秒内将流量切回老集群。问题修复后可再次执行灰度切换。
单轨优化:全量切换后,持续调整集群参数(内存分配、IO调度、分片策略),优化同步链路,完善运维流程。
验收与交付:不是终点,是起点
验收维度:功能、性能、数据、安全、运维,五维全面验收。
交付成果:信创集群环境、运维手册、故障排查手册、备份恢复手册。
人员培训:开展运维人员专项培训,确保能独立承担日常运维。
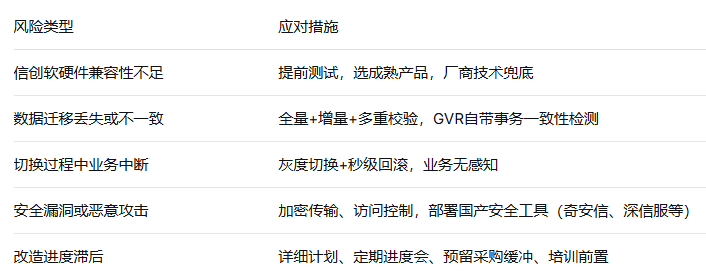
风险清单:提前打好了“预防针”
改造后:运维体系也跟上
换完引擎,还得会开。同步建设新的运维体系:
日常巡检:每日检查节点状态、CPU/内存/磁盘IO、数据同步延迟、应用访问情况。
监控告警:依托国产监控平台(如华为云Stack运维中心、奇安信态势感知),配置分级告警(短信/邮件/平台消息)。
数据备份:采用鼎甲DBackup或爱数AnyBackup,制定全量+增量备份计划,定期验证备份可用性。
知识沉淀:整理故障案例、操作手册,建立内部知识库,提升团队整体运维能力。
时间与成本
改造涉及硬件、软件及服务等多方面投入,具体周期与成本需根据集群规模、业务复杂度等因素在项目启动后详细评估。主要投入方向包括:国产服务器/存储/网络设备、GBase 8a授权、国产操作系统/中间件/安全工具、厂商技术支持、人员培训等。具体金额按实际规模核算。
信创改造不是一次“大拆大建”,而是一场有节奏、可回滚、业务无感知的平滑演进。依托GBase 8a集群的GVR准实时同步、多平台适配能力,以及“双轨+灰度”这套经过实践检验的流程,成功实现了从国外技术栈到全栈自主可控的过渡。GBase数据库作为国产数据库的优秀代表,以稳定、高效、易扩展的特性,持续为信创落地提供坚实支撑,助力企业数字化转型行稳致远。