GBase 8a MPP Cluster产品架构原理:从分布式联邦架构到高性能分析引擎
在大数据和信创国产化的大背景下,GBase 8a MPP Cluster 作为国内领先的分析型分布式数据库,已经在金融、电信、政务等关键行业的核心分析系统中广泛部署。本文将深入浅出地为你解析 GBase 8a 的产品架构原理,帮助技术团队快速理解其设计思想和技术优势。
产品定位:为大数据分析而生
GBase 8a MPP Cluster 是南大通用自主研发的新一代分析型 MPP 数据库,定位为 PB 级海量数据分析场景的核心引擎。它的核心应用场景包括:
大数据平台
作为数据仓库的底层计算存储引擎。
综合性BI系统
支撑多维分析和报表查询。
数据仓库和数据集市
提供高性能的 OLAP 分析能力。
湖仓一体
融合数据湖与数据仓库能力。
库内数据挖掘
In-database 机器学习算法(K-Means、逻辑回归、SVM 等)
简单来说,如果你的业务面临几百 GB 到上百 PB 的数据分析需求,GBase 8a 就是为这类场景量身打造的。
整体架构:分布式联邦架构
GBase 8a 整体架构的核心设计思想是 "MPP + Shared Nothing 分布式联邦架构",这是它与传统单机数据库最根本的区别。
1. 什么是Shared Nothing?
Shared Nothing 架构意味着集群中的每个节点都是独立的——拥有自己的 CPU、内存和本地磁盘,节点间通过 TCP/IP 网络进行通信。没有任何共享的存储或内存资源。
这种设计带来了几个关键优势:
线性扩展能力
增加节点即可线性提升计算和存储能力
无单点瓶颈
每个节点独立处理自己的数据分片
低成本硬件
可使用普通的 x86 服务器,无需高端共享存储设备
2. 什么是MPP?
MPP(Massively Parallel Processing,大规模并行处理)是指将一项大的计算任务拆分成多个子任务,分发到集群中的多个节点上并行执行,最后汇总结果返回给用户。
打个比方:如果把数据分析比作搬砖,传统单机数据库是一个人搬所有砖,而 MPP 集群是一群人同时搬砖,各搬各的,最后统计总数——效率自然天差地别。
三层解耦、各司其职
从下图可以看到,系统清晰地分为三个层次:
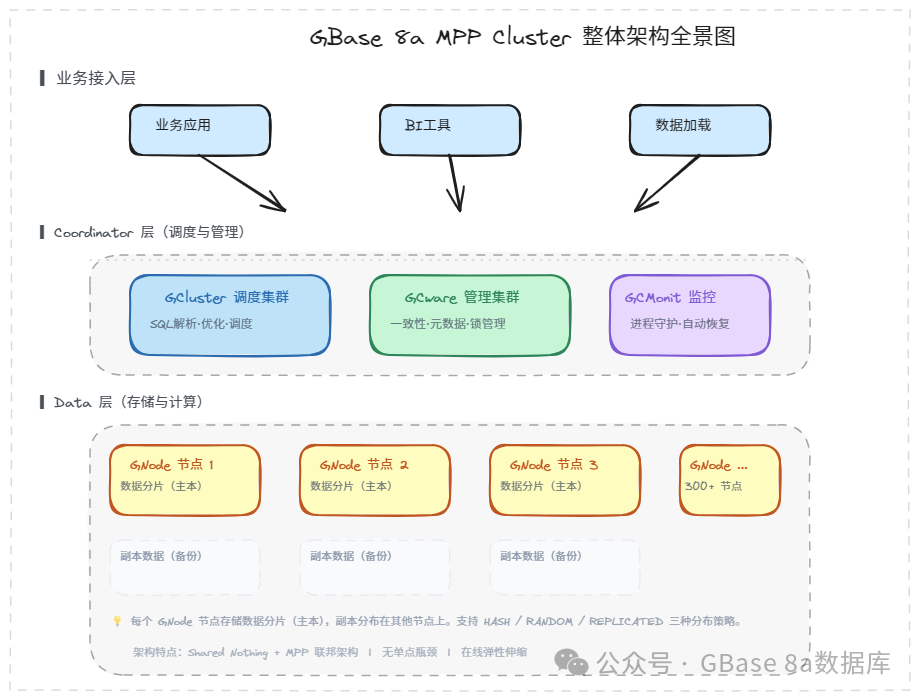
1.业务接入层
企业的各种业务应用、BI 分析工具、数据加载客户端等通过标准的 SQL 接口连接到集群,这些工具完全不需要关心集群内部有多少台机器、数据分布在哪些节点上——对应用来说,这就是"一个数据库"。
2.调度与管理层
这是集群的"大脑",由两大组件组成:
GCluster(调度集群):
集群的统一入口,负责接收客户端发来的 SQL 语句,进行解析、优化,生成分布式执行计划,然后将任务"分拆"下发给各个数据节点并行执行,最后收集结果返回给客户端。
GCware(管理集群):
集群的"大管家",负责维护集群的元数据、节点状态信息、分布式锁等一致性服务。
GCluster 和 GCware 通常部署在同一台服务器上,合称为 Coordinator 节点。这种设计的好处是:
减少服务器数量:3 台 Coordinator 节点即可满足集群管理需求。
通信高效:GCluster 与 GCware 同机部署,心跳延迟最低。
统一管理:只需管理 Data 节点和 Coordinator 节点两类角色。
而 Data 节点(GNode)则独立部署,专注于数据的存储和计算。Coordinator 节点建议部署奇数台(通常为 3、5、7、9 台),以保障 GCware 集群的一致性选举机制。
3. 存储与计算层
这是集群的"肌肉",由大量 GNode(数据节点) 组成。每个 GNode 既是存储单元,也是计算单元——数据存储在本地磁盘上,SQL 执行也在本地完成。
每个节点存储数据的一个或多个分片(主本),同时还会存储其他分片的副本(备份),从而实现数据的高可用。
架构亮点速览:
Shared Nothing 架构:每个节点独立、自治,不共享存储。
MPP 联邦架构:多个节点协同工作,线性扩展。
无单点瓶颈:所有节点对等,水平扩展。
支持 1000+ 数据节点,处理 100PB+ 数据。
三大核心组件:协同作战
如果说 GBase 8a 是一个高效的工厂,那么它的三大核心组件就是三条关键的生产线:
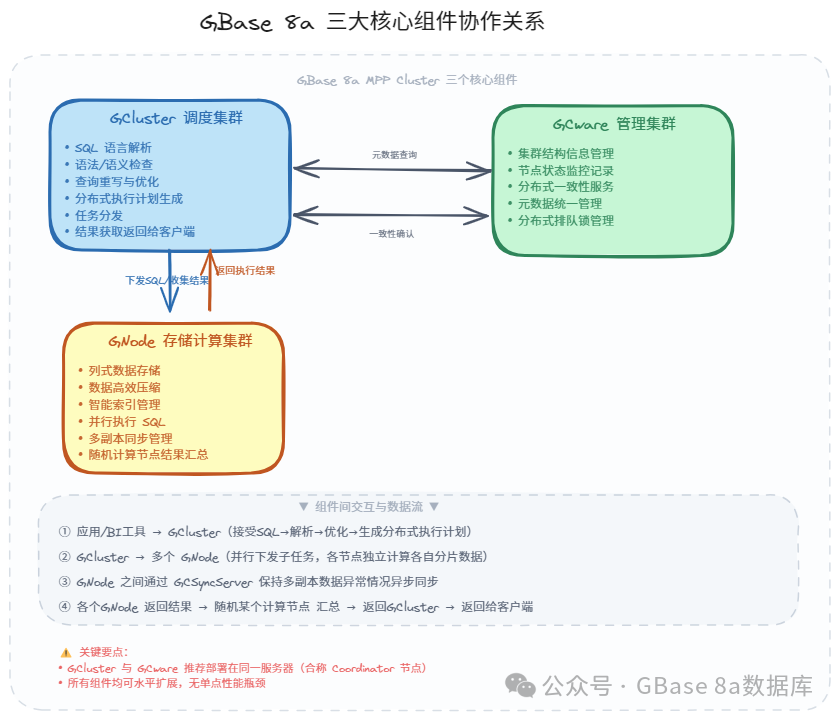
1. GCluster—集群的指挥官
GCluster 是集群对外的统一门户,它做的工作比你想象的要复杂得多:
SQL接收
接受来自客户端的 SQL 语句
查询重写
对 SQL 进行等价变换,找出更优的执行路径
优化器决策
通过基于规则和基于代价两种方式,选择最优的执行计划(比如选择哪个索引、哪种 JOIN 方式)
分布式执行计划生成
将优化后的查询分解为多个子任务,分配到不同的 GNode 上并行执行
结果返回
将子任务下发到 GNode,收集各节点返回的结果,返回给客户端
2.GCware—集群的大脑中枢
GCware 虽然不直接处理数据,但它的作用至关重要:
记录并保存集群结构、节点状态、资源状态。
管理分布式排队锁和并行控制。
在多副本数据操作时,记录和查询可操作节点。
保障各节点数据的一致性。
3. GNode—集群的执行者
GNode 是真正干活的人,每个 GNode 节点上运行着 gbased 服务进程,负责:
存储数据
采用列式存储,数据按列组织在本地磁盘
执行SQL
接收 GCluster 下发的子任务,在本节点数据上执行计算
数据压缩
自动对数据进行高效压缩,节省存储空间
智能索引
自动维护粗粒度索引,加速数据检索
多副本同步
数据异常时通过 GCSyncServer 进程保持与副本节点间的数据一致性
4. 组件间的协作流程
① 应用/BI 工具 → GCluster(接受 SQL → 解析 → 优化 → 生成分布式执行计划)
② GCluster → 多个 GNode(并行下发子任务,各节点独立计算各自分片数据)
③ GNode 之间通过 GCSyncServer 在异常时保持多副本数据自动同步
④ GNode 返回结果 → GCluster 汇总 → 返回给客户端
5. 辅助组件
除了三大核心组件,GBase 8a 还配备了多个辅助组件,保障集群稳定运行:
GCMonit:实时监测 GCluster 和 GNode 进程状态,异常时自动拉起。
GCware_Monit:实时监测 GCware 进程状态。
GCRecover:多副本间的数据同步与恢复。
GCSyncServer:保证多副本数据文件的一致性。
数据怎么存?分布式存储机制
GBase 8a 在数据存储方面做了大量的优化设计,这也是它能够在分析型场景中表现优异的关键所在。
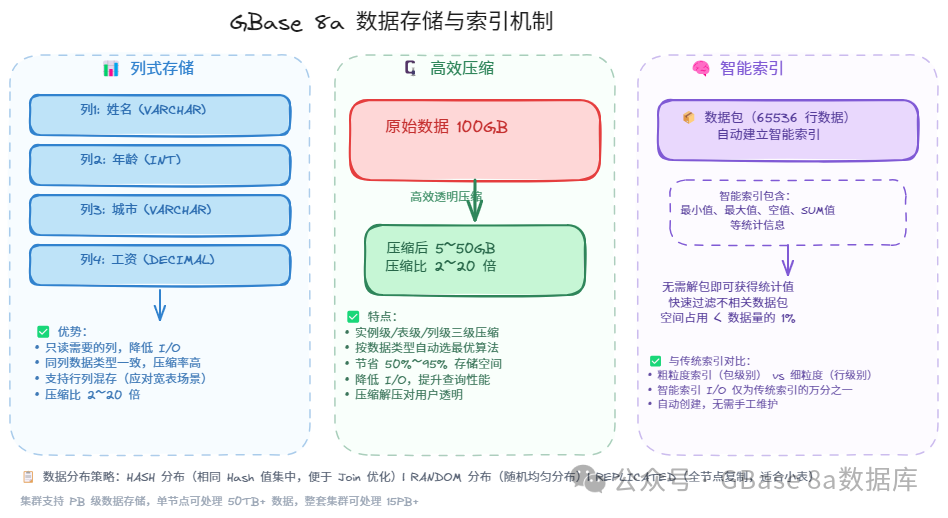
1. 列式存储:只读需要的列
与传统行式数据库不同,GBase 8a 采用列式存储。数据在磁盘上按照列(字段)来组织和存储。
想象一下,你有一张包含 100 个字段的用户表,但你只需要查询"姓名"和"年龄"两列。在行式数据库中,即使只需要两列数据,系统也必须把整行数据(100个字段)都读出来;而在列式数据库中,系统只读取需要的两列,I/O 开销降低到原来的 1/50!
列式存储的优势:
降低I/O
只读需要的列,大幅减少磁盘读取
高压缩比
同列数据类型一致,压缩率更高(2~20 倍)
支持行列混存
应对宽表场景,兼顾查询灵活性和性能
2. 数据分布:三种策略各显神通
数据如何分布到不同的 GNode 节点上?GBase 8a 提供了三种策略:
HASH分布
原理:按指定列的哈希值将数据分配到不同节点。
适用场景:常用于 JOIN 频繁的列,相同哈希值的数据集中在同一节点。
RANDOM分布
原理:数据随机均匀分布到各个节点。
适用场景:对分布无特殊要求的通用场景。
REPICATED分布
原理:每个节点都保存完整的数据副本。
适用场景:适合数据量小但查询频繁的维度表。
3. 高效压缩:100GB变5GB
GBase 8a 支持实例级、表级、列级三级压缩策略,能够按照数据类型和数据分布规律自动选择最优压缩算法。
压缩比可达到2~20 倍,远高于行存储。
节省50%~95%的存储空间。
降低 I/O 消耗,数据加载和查询性能明显提升。
压缩和解压缩过程对用户完全透明。
4. 智能索引:万亿级加速
GBase 8a 的智能索引是一种粗粒度索引技术,它有这样几个突出特点:
每65536行数据自动生成一个数据包,并建立智能索引。
智能索引包含最小值、最大值、空值、SUM 值等统计信息。
无需解包即可获得统计值,快速过滤不相关的数据包。
索引空间仅占数据量的 1%(传统索引占 20%~50%)。
自动创建,无需手工维护。
查询怎么跑?SQL执行全流程
了解完存储机制,我们来看看一条 SQL 查询在 GBase 8a 中是如何被执行的。
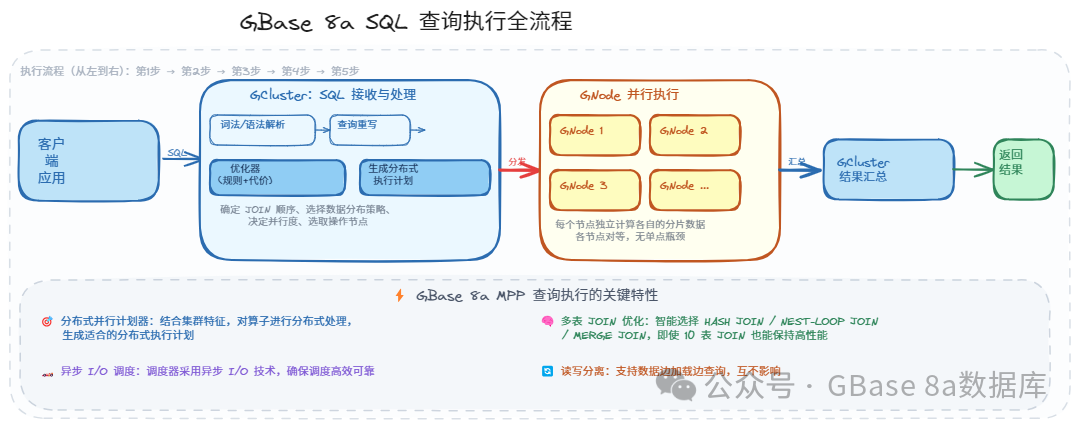
第一步:客户端发起
应用程序通过 JDBC/ODBC 等标准接口向集群发送 SQL 查询请求。
第二步:GBluster处理
GCluster 接收 SQL 后,进行一系列"大脑运算":
1、词法/语法解析:理解 SQL 的含义
2、查询重写:等价变换,优化执行路径
3、优化器决策:基于规则(RBO)和基于代价(CBO)选择最优方案
4、生成分布式执行计划:确定 JOIN 顺序、数据分布策略、并行度、操作节点等
第三步:GNode并行执行
GCluster 将分解后的子任务分发到各个 GNode,每个 GNode 只在自己的数据分片上独立执行计算——这就是MPP 的核心思想:把大任务拆成小任务,让所有节点一起干活。
第四步:GCluster结果汇总
各个 GNode 返回计算结果,GCluster 对其进行合并、排序等处理。
第五步:返回客户端
最终结果返回给客户端应用。
关键特性:
分布式并行计划器:结合集群特征,对算子进行分布式处理。
多表 JOIN 优化:智能选择 HASH JOIN / NEST-LOOP JOIN / MERGE JOIN。
异步 I/O 调度:确保调度高效可靠。
读写分离:数据加载和查询可同时进行,互不影响。
虚拟集群:逻辑隔离的艺术
在企业实际应用中,经常面临这样的场景:多个部门、多套业务系统需要共用一套数据库集群,但又希望各自的数据相互隔离、互不影响。
GBase 8a 的虚拟集群(VC)技术完美解决了这个问题。
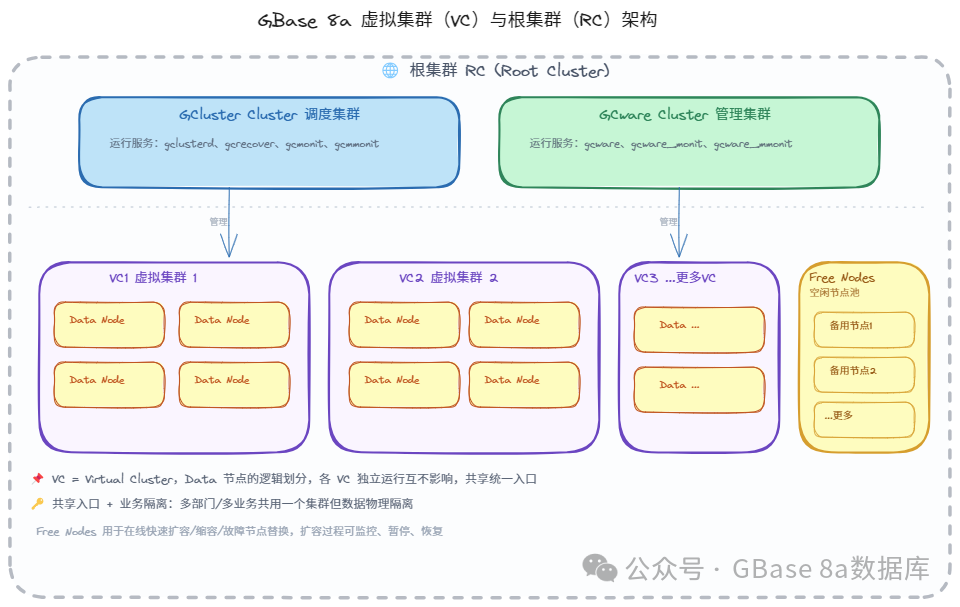
核心概念
RC(Root Cluster / 根集群):
整个集群的"大管家",包含 GCluster Cluster、GCware Cluster 以及所有 Data 节点的集合。RC 不对用户直接提供服务,而是负责统一管理和调度。
VC(Virtual Cluster / 虚拟集群):
对 Data Cluster 节点的逻辑划分。每个 VC 拥有固定数量的 Data 节点,各 VC 在虚拟集群范围内独立运行、互不影响。
Free Nodes(空闲节点池):
预留的备用节点,用于在线快速扩容、缩容或故障节点替换。
三大优势
1.统一管理,统一入口
虽然内部划分了多个 VC,但对应用来说,看到的仍然是"一个数据库"。用户连接任意一个 Coordinator 节点,即可透明访问整个集群。
2.业务隔离,互不影响
不同 VC 之间实现物理资源隔离:VC1 的查询再复杂,也不会影响 VC2 的性能。这让多部门、多业务共用一个集群成为可能。
3.弹性伸缩,按需分配
当某个 VC 需要扩容时,可以从 Free Nodes 池中获取节点加入该 VC。扩容过程在线进行,不影响业务运行,性能近线性提升。
高可用与容灾:多层级保障
多级别高可用体系
对于企业级数据库来说,数据安全和系统可用性是重中之重。GBase 8a 构建了从进程级到集群级的全方位、完善的高可用体系。
集群级:双活集群(同城/异地灾备)、数据同步
节点级:GCluster Failover 机制、GCware 虚同步、GNode 自动同步。
进程级:GCMonit 实时监控,进程故障自动恢复。
数据级:备份恢复工具 gcrcman,支持全量/增量。

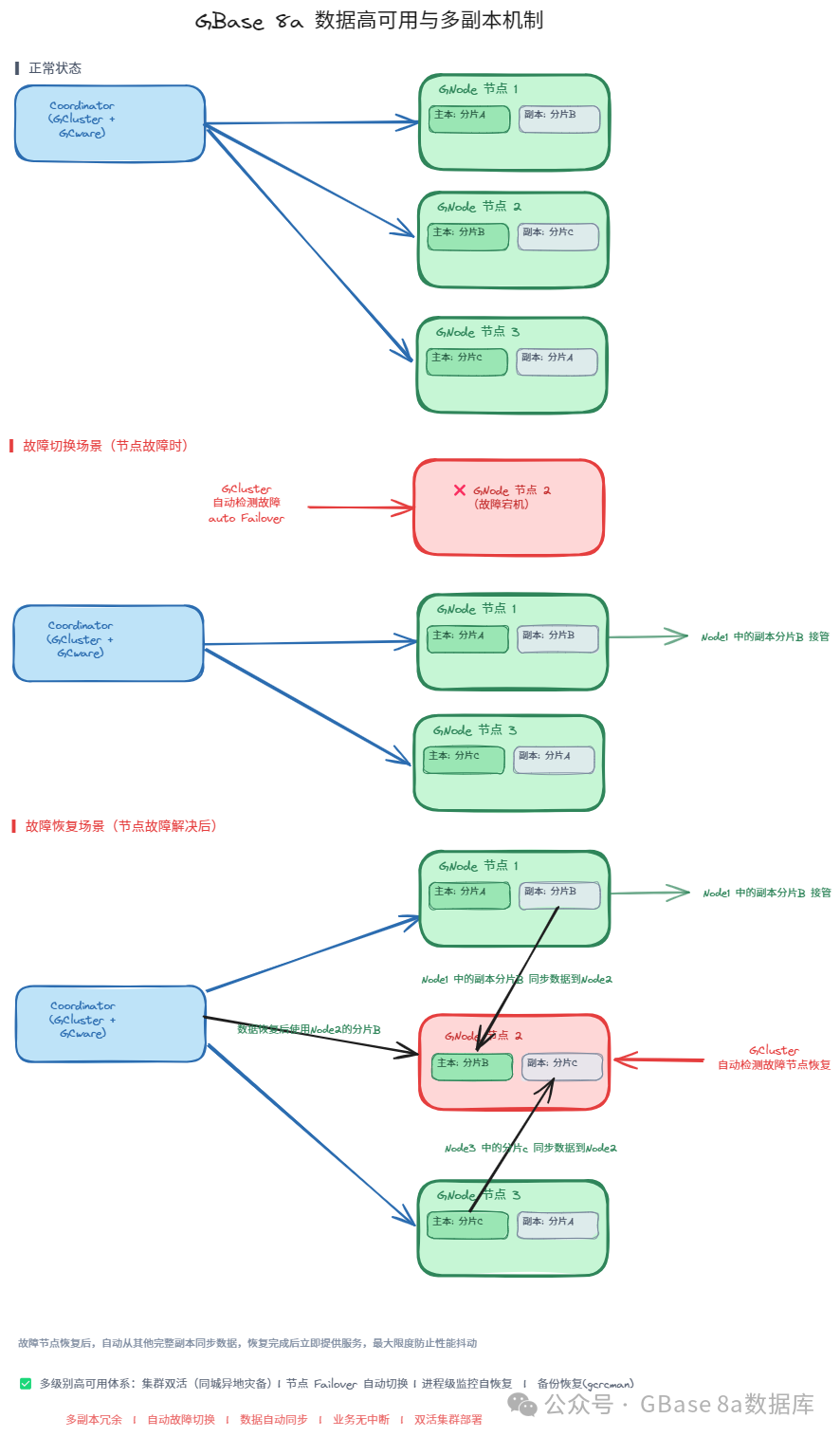
多副本冗余机制
GBase 8a 中的表数据被切分为多个分片(Shard),每个分片默认存储多个副本,分布在不同节点上。
以 3 个节点为例:
Node1:
主本:分片 A | 副本:分片 B
Node2:
主本:分片 B | 副本:分片 C
Node3:
主本:分片 C | 副本:分片 A
每个节点既是某些分片的主本节点,也是其他分片的副本节点。节点之间通过 GCSyncServer 进程自动同步数据,保证多副本数据的一致性。
自动故障切换
当某个节点发生故障时:
1.GCluster 自动检测到节点故障
2.自动触发 Failover,将故障节点的主本服务切换到其副本所在的正常节点
3.集群继续提供服务,业务无中断
4.故障节点恢复后,自动从其他完整副本同步数据,恢复完成后立即提供服务
结语
GBase 8a MPP Cluster 作为一款成熟的国产分析型数据库,其架构设计体现了分布式系统设计的诸多精髓:
三层解耦让各组件各司其职,易于扩展和维护。
MPP + Shared Nothing架构让计算能力可以线性扩展。
列式存储 + 智能索引 + 高效压缩构成了高性能的铁三角。
虚拟集群技术在统一管理和业务隔离之间找到了完美平衡。
多副本 + Failover机制为数据安全和企业级高可用提供了坚实保障。
希望通过这篇文章,你对 GBase 8a 的架构原理有了更深入的理解。如果你正在评估国产数据库选型,或者在使用 GBase 8a 时遇到问题,欢迎留言交流!