GBase 8a分布式执行计划原理
1.概述
GBase 8a MPP Cluster是一款Shared Nothing架构的分布式并行数据库集群,具备高性能、高可用、高扩展等特性。由于采用了MPP + Shared Nothing架构,集群在执行查询任务时采用分布式并行方式,将一个查询任务分解为集群每个节点上的并行执行任务,因此对于Query中各类算子的实现均采用了分布式的实现方案,本文中将重点介绍查询中最长用的join和group by两类算子的分布式实现原理,并介绍8a中可以影响分布式执行计划的参数及其影响执行计划的具体方式和原理。
2.GBase 8a分布式执行计划原理
2.1GBase 8a表数据分布方式
GBase 8a数据库中数据表对用户暴露的接口与其他单机数据库相同,可以看做一张逻辑表,而表的实际存储支持两种类型的数据分布方式:GBase 8a数据库中数据表对用户暴露的接口与其他单机数据库相同,可以看做一张逻辑表,而表的实际存储支持两种类型的数据分布方式:
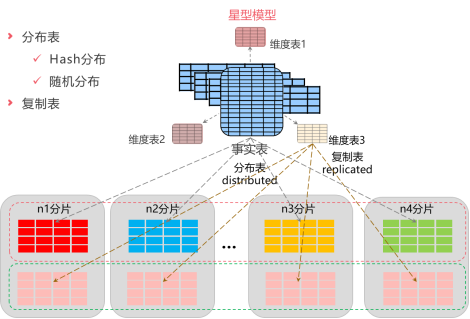
- 分布表:表内的数据分散分布在集群中每个节点上,每个节点存储逻辑表的一个数据分片的数据,数据分片是计算节点上实际存储数据的物理表;对于数据分布的规则,8a支持两种规则,一种为hash散列分布规则,一种为随机分布规则;
- Hash散列分布:创建表定义时使用distributed by关键字指定计算hash散列值的字段,根据hash分布列的散列值确定数据分布在那个节点上,支持单列和多列组合作为hash分布列;
- 随机分布:表内数据随机分布到各节点上;
- 复制表:每个节点上都有一份相同的全量数据;
2.2hash散列数据分布原理
GBase 8a Hash散列分布原理如下图所示,假设表定义如下:
create table emp (pname varchar(50), postion varchar(50), ...) distributed by(‘pname’);
表定义中指定了pname列作为hash分布列,即采用该列数据计算hash散列值。
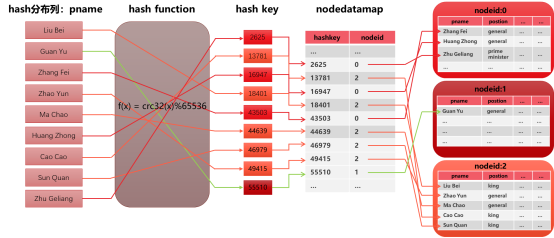
GBase 8a的hash散列值计算函数为f(x)=crc32(x)%65536,即将分布列数据通过crc32函数计算出结果后再与65536取模,因此hash分布列的数据将被散列到0~65535这65536个值的空间中。
hash散列值与数据分片(计算节点)的绑定关系,存储在GBase 8a的系统表gbase.nodedatamap中,表中hashkey字段对应0~65535供65536个hash散列值,nodeid对应该散列值的数据属于哪个逻辑分片,表中nodeid列的值0~N-1对应节点上存储的物理表分片号1~N。
数据分片(物理表)与节点的绑定关系,通过创建集群时执行的gcadmin distribution指令创建,可以通过gcadmin showdistribution指令查看。
2.3分布式join执行计划原理
本节将介绍分布式Join执行计划实现原理,这里的Join算子特指join条件为等值类型的join,不包括between and或大于小于类型的join。
整体上分布式Join执行计划可以归为两种基本模型:
分布表join分布表:两表的数据分布相同,即join的等值条件中包含了join两表的hash分布列的等值条件,具体执行计划示例如下图所示:

分布表join复制表:一张表为分布表,另一张表为复制表,left join时右表为复制表,具体执行计划示例如下图所示:
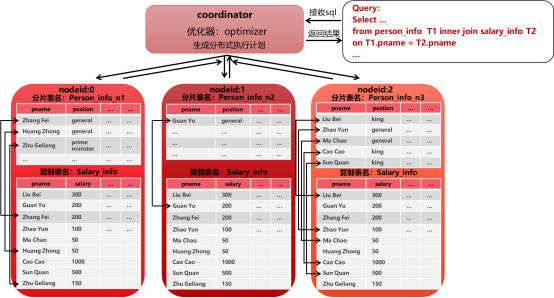
满足上述两种模型时,join可以直接在集群的各计算节点上并行执行。
如果不满足上述两种模型时,将根据情况对参与join的表数据在集群各节点上进行数据重新分布,变换为上述两种模型,再进行模型1或者2的并行join计算。具体分为以下三种情况:
小表拉复制表join执行计划
单表重分布join执行计划
两表重分布join执行计划
以下小节将针对三种执行计划进行详细描述。
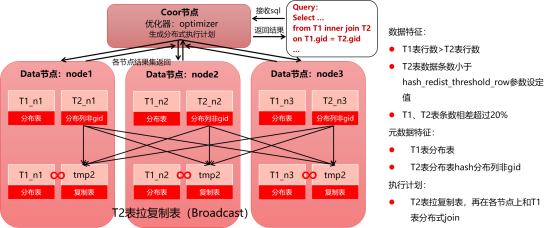
2.3.1小表拉复制表join执行计划
该执行计划的前提条件为:
1)两张分布表做join;
2)T1表为大表(表内数据行数多,或经过单表条件过滤后行数多),T2表为小表(表内数据行数少,或经过单表条件过滤后行数少);
3)Join等值条件不包含T1表和T2表分布列的等值条件;
该模型的执行计划示意为:
1)T2表(小表)在集群节点内进行广播,拉成复制表tmp2;
2)转化为前面描述的基本模型2,分布表join复制表模型,并按照基本模型2进行后续并行执行;
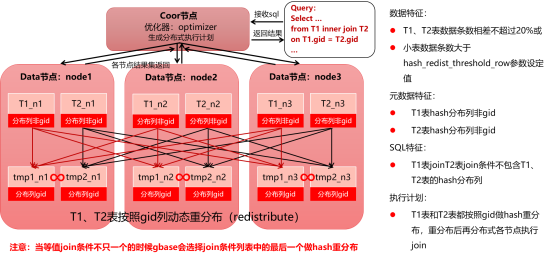
2.3.1单表重分布join执行计划
该执行计划的前提条件为:
1)两张分布表做join;
2)Join等值条件包含T1布列 = T2非分布列的等值条件;
该模型的执行计划示意为:
1)T2表数据在集群节点内进行数据重分布,重分布按照T1布列 = T2非分布列等值条件中T2表的非分布列进行重分布,生成分布表tmp2;
2)转化为前面描述的基本模型1,分布表join分布表模型,并按照基本模型1进行后续并行执行;
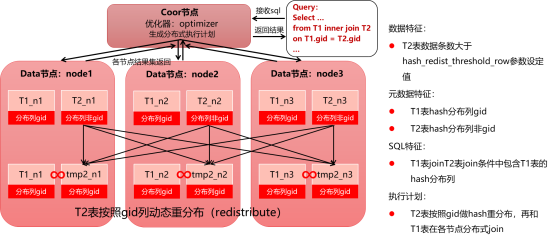
2.3.1两表重分布join执行计划
该执行计划的前提条件为:
1)两张分布表做join;
2)Join等值条件中不包含任何T1或T2表的分布列,假设join等值条件为T1非分布列=T2非分布列;
该模型的执行计划示意为:
1)T1表数据在集群节点内进行数据重分布,重分布按照等值条件列进行,生成分布表tmp1
2)T2表数据在集群节点内进行数据重分布,重分布按照等值条件列进行,生成分布表tmp2
3)转化为前面描述的基本模型1,分布表join分布表模型,并按照基本模型1进行后续并行执行;
注意:当T1表和T2表存在不止一个等值join条件时,会选择join条件中的最后一个等值条件中两表的列,进行T1表和T2表的数据重分布。
2.4分布式group by执行计划原理
以上介绍了GBase 8a分布式join算子的执行计划原理,本章节将介绍GBase 8a分布式group by算子的执行计划原理。
分布式group by与分布式join相同,group by分布式执行计划也有基本模型,即可以在集群各节点上直接并行执行的最简单模型,具体包含2个基本模型如下:
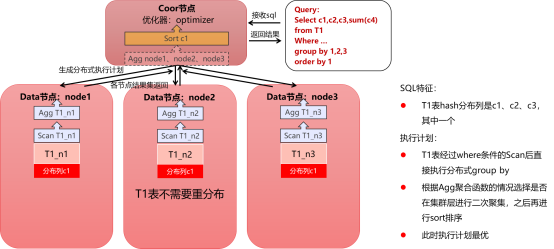
基本模型1的条件为:
1)group by表为hash分布表
2)group by列中包含表的hash分布列
执行计划为:
直接在各节点并行执行group by分组,结果汇总到coordinator节点做结果合并以及后续order by的排序操作。
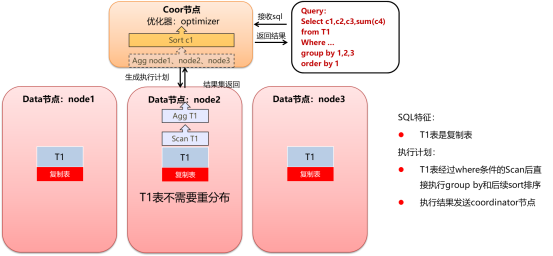
基本模型2的条件为:
group by表为复制表(即单个节点上具备全量数据)
执行计划为:
直接在集群的1个节点执行group by分组和order by操作,结果发送到coordinator节点作为最终结果。
如果group by不满足上述条件,则与join相同,通过数据在节点间的重新分布转化为满足最简模型的模式后按照最简模型的执行计划执行,具体衍生出两种执行计划:
重分布group by执行计划
两阶段group by执行计划
以下章节分别对两张情况进行详细介绍。
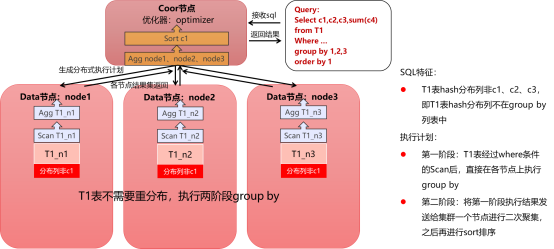
2.4.1重分布group by执行计划
该执行计划的前提条件为:
1)group by表为分布表;
2)group by列中不包含该表hash分布列;
该模型的执行计划示意为:
1)T1表先在各节点上按照group by列进行一次聚集(包括聚集函数的计算),此步目的为减少重分布时节点间网络传输的数据量;
2)选择group by列中的一列作为重分布列,将1)步骤结果数据按照重分布列进行数据重分布,生成tmp1表;
3)转化为前面分布式group by的最简模型1,并按照基本最简模型进行后续并行执行;
注意:当group by列有多个时,上面的执行计划会选择group by列表中的第一列作为重分布的hash分布列。
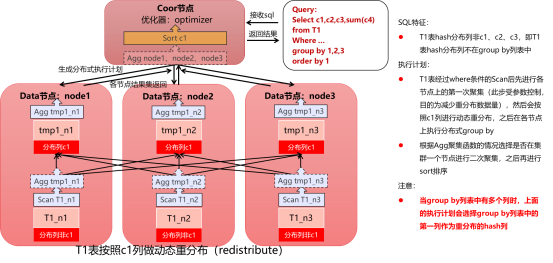
2.4.2l两阶段group by执行计划
该执行计划的前提条件为:
1)group by表为分布表;
2)group by列中不包含该表hash分布列;
该模型的执行计划示意为:
1)T1表先在各节点上按照group by列进行一次聚集(包括聚集函数的计算)为减小单点二次聚集的数据量;
2)各节点将一次聚集的数据发送给集群的一个节点,转化为最简模型2,在这个集群节点上进行二次聚集及后续order by排序等计算。
3.影响执行计划参数介绍
3.1参数介绍
- 当执行SQL时,具体采用上面描述那种类型的执行计划,受到一些参数的影响,下面具体介绍几个重要参数:
gcluster_hash_redistribute_join_optimize:- 控制等值join运算时使用动态重分布计划的开关
- 取值范围:0、1、2
- 参数取值释义:0 - 小表拉复制表,1 - 动态重分布,2 - 自动评估
- 默认值:2
- gcluster_hash_redist_threshold_row:
- 控制gcluster_hash_redistribute_join_optimize = 2时自动评估的规则
- 取值范围:0+自然数
- 参数取值释义:0 - 不限制,具体数值 – 采用动态重分布计划的小表数据条数阀值
- 默认值:0
- gcluster_hash_redistribute_groupby_optimize:、
- 控制group by运算时使用动态重分布计划的开关
- 取值范围:0、1
- 参数取值释义:0 - 禁用,1 – 动态重分布
- 默认值:1
3.2参数影响执行计划方式说明
join场景 | gcluster_hash_redistribute_join_optimize 参数1 | gcluster_hash_redist_threshold_row 参数2 | 执行计划 |
两表均为分布表, join条件为两表hash分布列 | 参数1 =2或=1 | 无影响 | 直接本地进行join运算 走模型1执行计划 |
一表为分布表,一表为复制表 | 无影响 | 无影响 | 直接本地进行join运算 走模型2执行计划 |
两表均为分布表 join条件为其中一表hash分布列 | 参数1 =2 根据参数2判断执行计划 =1 走执行计划1) =0 走执行计划2) | 如参数1 = 2,根据参数2的数值评估,如下: IF 小表条数 < gcluster_hash_redist_threshold_row and 大表和小表的条数差距超过20% Then 走执行计划2) Else 走执行计划1) END | 1)将非join列hash分布表按照join条件列重分布,走单表重分布hash join执行计划 2)将较小的表拉成复制表,走小表拉复制表执行计划 |
两表为分布表, join条件非两表任意一表hash分布列 | =2 根据参数2判断执行计划 =1 走执行计划1) =0 走执行计划2) | 如参数1 = 2,根据参数2的数值评估,如下: IF 小表条数 < gcluster_hash_redist_threshold_row and 大表和小表的条数差距超过20% Then 走执行计划2) Else 走执行计划1) END | 1)将两个非join列hash分布表按照join条件列分别重分布,走两表重分布hash join执行计划 2)将较小的表拉成复制表,走拉小表拉复制表执行计划 |
group by场景 | gcluster_hash_redistribute_groupby_optimize | 执行计划 |
group by列表中含有hash分布列,且非函数(hash列)或表达式包含hash列的形式 | 参数 = 1 | 直接本地进行group by运算 走group by基本模型1执行计划 |
非上述情况 | 参数 = 1,走执行计划1) 参数 = 0,走执行计划2) | 1)将表按照group by第一列(函数或表达式)重分布,走重分布group by执行计划 2)走两阶段group by执行计划 |

热门帖子
- 12025-12-01浏览数:182266
- 22023-05-09浏览数:24518
- 42023-09-25浏览数:17796
- 52020-05-11浏览数:16821