南大通用GBase 8a gn层物理存储结构介绍
列存储
GBase 8a MPP并行数据库集群是一款采用列存储的关系型数据库,GNode是GCluster最基本的存储和运算单元。
在进行数据存储时,记录是以列为单位进行映射和存储。即每个表的记录以列的方式进行拆分并分别存储为一组数据文件,每个数据文件最大为2GB,根据表中记录数的多少,每个列的数据文件会表现为一个或多个。
数据包及智能索引
就每个列的数据文件来讲,每个数据文件是由若干数据包(DataCell)构成,每个数据包中包含64K行记录,GNode对数据的存取操作均是以数据包为单位进行,即基本io单位为一个数据包。
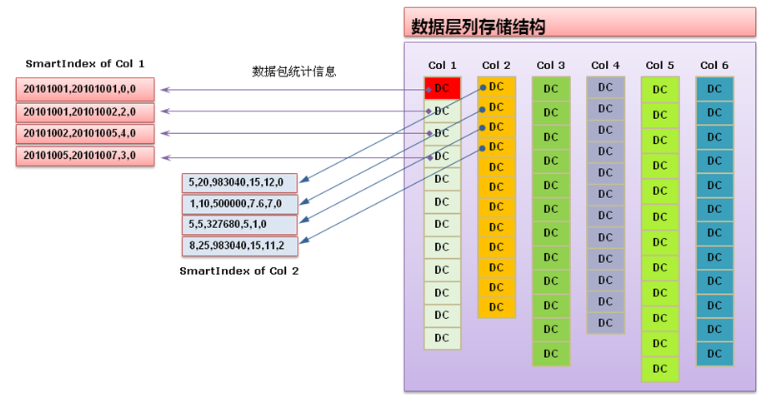
在每个数据包之上会由数据库系统自动创建和维护智能索引(SmartIndex),智能索引记录的是该包中数据的统计信息,包括最大值、最小值、和值、NULL值个数。
在进行查询过滤和统计计算过程中,GNode会借助数据包的智能索引特性提升处理性能。智能索引具有如下特点:
- 空间占用仅为数据的百分之一左右。
- 基于数据包的索引,而不是基于行。
- 所有字段上自动建立索引,保证即席查询、R-OLAP的性能,对复杂查询的优化效果明显。
- 索引信息决定于数据包,数据包本身没有变化,则对应的索引就不需要维护。索引的自动维护成本不会随着表中数据量的增加而变大,保证了大数据量下的加载性能。
存储特性
由于数据文件是以列为单位进行存储的,因此每列文件数据类型统一,规律性更强,压缩率相对会更高,且压缩解压代价会更小。
对于列存储数据库, 由于I/O模型是基于单列建立的,因此对于过滤、join以及物化等操作可根据各个阶段需要基于所需列进行io。以下面的例子进行说明:
select custname, sum(credit) as totalcredit from customeraccount where custcity='BEIJING' group by custname ;
在数据库解析产生执行树的时候, 这条语句大致分解成filter -> {matched row position} -> projection -> aggregation -> results
a) filter = 上面select 语句中where custcity='BEIJING' 部分, 这部分过滤出来符合条件的行 (用行号 rowid记录).
b) projection -> aggregation = 上面语句中 select custname, sum(credit) 部分, 这部分是这条语句需要的结果。
对于行存数据库, 由于其行存特征, 每次必须把一整行数据读入内存, 才可以实现过滤(filtre), 投影操作(projection =选择部分字段),因此行存储无法在I/O上分开上面的 a) 和 b) 步骤。
GNode在上面的操作中,可先读取 a (filter) 部分需要的数据,进行where 操作 或其他join 操作。在获得符合条件的行号后,再进行步骤b 的 投影操作(物化)。
该方式的优点在于:在该示例中,行存需要读取所有列的数据,而GNode仅需读取三个列,且是根据处理阶段的需要,按需读取,因此需要的I/O比行存要小得多,内存使用效率也大大提高。

热门帖子
- 12025-12-01浏览数:35009
- 22023-05-09浏览数:22772
- 32023-09-25浏览数:15767
- 42020-05-11浏览数:15143
- 52019-04-26浏览数:14056