GBASE金融应用指南5 | 系统开发规范
为帮助金融机构做好分布式分析型数据库产品的选型,推广在金融行业部署应用分布式分析型数据库的成功经验,GBASE南大通用在北京金融科技产业联盟的指导下编写《南大通用GBase 8a金融应用指南》。《指南》深入介绍了分布式分析型数据库从选型规划、开发设计规范、数据安全高可用,直至运维优化的部署全过程,并介绍了GBase 8a MPP Cluster在国家政策性银行和国有大行的代表性部署案例。
GBASE南大通用将陆续推出系列文章,分享解读《指南》内容,希望能够对广大金融用户的数据库选型提供借鉴帮助,助力科技金融的高效实施和高质量发展。
本篇是系列文章的第5期,介绍系统的开发规范。
一、模型设计
GBase 8a产品中提供了多种数据分布策略,如果选择不当后期更改,需要重新建表和导入数据,代价较大。同样,表模型确定后,如果后期要更改结构,也可能会影响到上层的应用变动,代价都较大。模型设计也是项目建设中耗时较长的阶段,需要很好的理解业务,在业务人员和技术人员的良好沟通下共同确定。
1.数据模型
维度模型
GBase 8a产品是关系数据库管理系统,在关系数据库管理系统中实现的维度模型常见有以下三种:
• 星型模型:所有维度表都直接连接到事实表上,为了提高查询性能,会在维度表和事实表之间添加冗余数据,适用于查询性能要求较高的场景。
• 雪花模型:星型模型的扩展,维度表进一步层次化,部分维度表通过其他维度表连接到事实表上,消除了冗余数据,减少数据存储量。适用于存储空间有限、需要节省成本、且对查询性能要求相对较低的场景
• 星座模型:星型模型的扩展,有多个事实表,一个维度表被多个事实表使用。适用于数据和需求需要多个事实表的场景。
2.数据分布策略
GBase 8a产品支持的数据分布模式有复制分布、hash分布、随机分布三种模式,分别对应三种表类型:复制表、hash分布表、随机分布表。在模型设计阶段提前确定好每个表的类型,创建表时根据设计好的类型进行创建。
• 复制表:8a集群每个节点上都存储的是表中全量数据。适用于维度表或者数据量较小的表。优势为便于关联运算时不需跨节点拉取数据。
• Hash分布表:8a集群每个节点上存储的是表的部分数据。需要在建表时选择hash分布列来控制分布到各节点的数据。适用于事实表或者数据量大的表,可以避免热数据倾斜在集群中个别节点带来的性能下降。
• 随机分布表:8a集群每个节点上存储的是表的部分数据。数据随机且均匀的分布于集群各节点,无法控制。可用于事实表或者数据量大的表,因无法控制数据分布所以也无法避免个别节点热查数据多的问题,项目上较少使用。
3.数据压缩算法
GBase 8a产品对库内底层数据压缩存储,并提供多种压缩模式供用户选择,这些压缩算法能将原始数据压缩到3:1至20:1,这取决于业务数据特点选择的压缩算法。
• 压缩比高,数据占用磁盘空间相对小,压缩和解压耗时相对会长一些;
• 压缩比低,数据占用磁盘空间相对大,压缩和解压耗时相对会短一些;
• 用户需根据实际硬件条件和业务性能要求均衡选择合适的压缩模式。
GBase 8a的压缩算法支持全局、库级、表级的设置,如果同时设置,压缩级别的优先级为列级定义压缩 >表级定义压缩 >全局定义压缩方式。
4.字符集
GBase 8a产品当前支持的字符集有utf8、utf8mb4、gbk、gb18030-2022。
GBase 8a产品使用时字符集转换流程如图1所示。
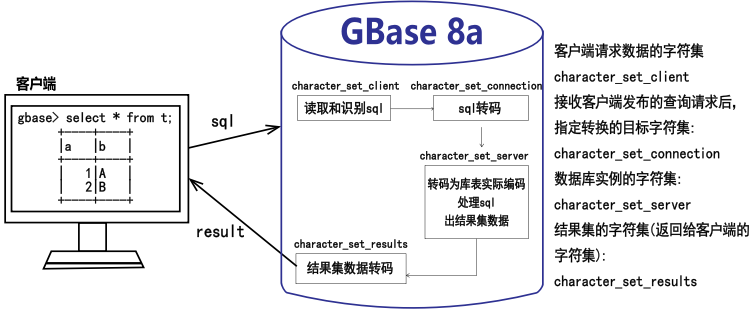
图1字符集转换流程
字符集流转流程中建议编码一致,GBase 8a Server的字符集对以下使用会有一定影响:
• 字符型数据类型的字符上限,不同编码上限有差异;
• 库内数据的比较排序有差异;
不同字符集排序规则如表1所示。
表1 不同字符集排序规则

二、SQL编写规范
GBase 8a产品自身的SQL执行引擎和优化器具有一些特性,以下的SQL编写规范能够更好地利用GBase 8a产品的特性,发挥GBase 8a产品的性能优势。
1.GBase 8a标识符规范:
1)标识符是一个限制词或包含特殊字符,必须用` `引用它,比如:SELECT * FROM `select`.id>100;
2)如果标识符长度超过最大长度限制,数据库、表、列、视图、存储过程的命令将报错,推荐sql中使用有意义的别名;
3)GBase 8a默认表名列名不支持中文名,如需支持中文名的列名表名需设置参数;
4)复制表的表名不能以_n[N]结尾,[N]为数字。
2.SQL编写规范:
GBase 8a产品的SQL遵循SQL 92标准(ANSI X3.135-1992,ISO/IEC 9075:1992),支持SQL99 和 SQL2003 中定义的大部分数据类型(ISO/IEC 9075:1999,SQL:1999(SQL3)和 ISO/IEC 9075:2003,SQL:2003(SQL4))。
GBase 8a产品的SQL特性:
1)集群表类型中区分分布表、复制表、临时表,sql建表有关键字标识;
2)每条SQL命令默认以分号 ; 表示结束,可使用DELIMITER进行修改:
DELIMITER 限定符(在存储过程中必须更换);
3)SQL执行默认为自动提交commit;
4)HASH分布字段不支持日期时间类型;
5)支持修改varchar字段长度定义,支持修改表字符集从utf8到utf8mb4;
6)释放空间sql:SHRINK SPACE不适宜频繁执行;
7)禁止对视图进行INSERT、UPDATE和DELETE 操作;
8)INSERT 支持标准sql语法及扩展写法,其中insert into t values(v1,…vn), (v2,…vn),…(vm,…vn)为批量提交,性能佳;
9)UPDATE 不支持更新distributed by定义列的值。不支持多表数据的同时更新,但是update语法中可以进行多表关联操作,只能更新其中一张表的数据。支持快速更新模式;
10)DELETE 不支持多表批量删除;
11)MERGE操作只支持HASH分布表且MERGE语句的条件需包含业务主键和HASH分布列;
12)自定义函数内不支持DML,DDL,创建临时表;
13)单表列数上限2000列,单表列宽总和上限300,000字节,单表索引总数上限64。
3.开发接口使用
GBase 8a集群提供主流开发平台的接口驱动,集群接口驱动可以有效实现对上层应用请求的高可用和负载均衡(应用调用接口驱动的连接串中配置多个集群管理节点的IP,接口驱动的内部进行连接的高可用和负载均衡)。
可以根据需要选择如下合适的接口:GBase ADO.NET、GBase JDBC、GBase ODBC、GBase C-API、GBase Python。
GBase 8a 接口有如下特性,用户可以根据需要选择使用。
• 使用接口执行加载sql,可以通过接口返回的加载信息判断加载的结果;
• JDBC提供数据攒批接口,使用JDBC向集群插入数据较多时,可以使用接口的批量插入参数,一次性批量发送数据给服务端,减少网络传输,同时server端可一次性处理发来的SQL,实现性能的提升;
• 查询的结果集比较大时,可使用接口的流式读取功能,流式读取可以通过数据流的方式,逐条从集群获取数据,减小大结果集对应用内存的影响。流式读取会在集群端生成一个临时表,占用临时表空间,且结果集内的数据未消费完时连接一直保持,开启流式读取对集群有一定影响,使用时需谨慎;
• 应用使用接口连接8a集群,要求安全等级较高时,可根据需要使用接口的SSL加密传输、Kerberos认证连接、SSH隧道连接等安全功能。
4.数据库管理规范
• GBase 8a数据库不适合OLTP事务类型的应用;
• GBase 8a集群内部支持UTF8和GBK字符集的混用,可以同时使用UTF8和UTF8MB4字符集,或GBK和GB18030字符集;
• 应按照数据仓库的开发建设原则,对数据模型进行规范化;
• 开发环境和生产环境分开;
• 构建合理的任务调度机制,在满足业务要求的情况下尽量降低数据库并发;
• 正式上线前,进行性能评估测试。